EM算法(简)
- 格式:ppt
- 大小:102.00 KB
- 文档页数:6


最大期望值EM算法最大期望值(Expectation-Maximization, EM)算法是一种统计学习方法,用于解决带有隐变量的概率模型参数估计问题。
EM算法的主要思想是通过迭代求解局部最优解,并且能够保证每次迭代过程中目标函数值不减。
EM算法广泛应用于数据挖掘、图像处理、自然语言处理等领域,在金融、医学和社会科学等领域也有许多实际应用。
本文将对EM算法的基本原理、迭代过程、理论基础和应用进行详细介绍。
一、基本原理EM算法是一种迭代算法,包含两个步骤:E步和M步。
其中,E步是求期望(expectation)的过程,用于更新隐变量对观测数据的条件概率分布;M步是求最大化(maximization)的过程,用于更新模型的参数。
通过不断交替进行E步和M步,直到收敛为止,即可得到最优的参数估计。
二、迭代过程1.初始化参数:随机给定模型参数的初始值。
2.E步:根据当前参数估计,计算隐变量对观测数据的条件概率分布。
3.M步:根据当前隐变量的条件概率分布,最大化观测数据的对数似然函数,更新模型的参数估计。
4.计算目标函数值:根据当前参数估计,计算目标函数的值。
5.判断是否满足停止条件:如果满足停止条件,则算法结束;否则,返回第2步。
三、理论基础EM算法基于两个基本定理:数据的似然函数下界和KL散度的非负性。
1.数据的似然函数下界:对于给定的观测数据,EM算法通过求解数据的似然函数的下界来进行参数估计。
这个下界是通过引入隐变量来扩展数据模型得到的,因此可以利用EM算法求解。
2.KL散度的非负性:KL散度是衡量两个概率分布之间的差异程度的指标。
在EM算法中,通过最大化观测数据的对数似然函数来更新模型的参数,相当于最小化KL散度。
四、应用领域EM算法在许多领域都有广泛的应用。
以下是一些典型的应用实例:1.聚类分析:EM算法可以用于高斯混合模型的参数估计,从而实现聚类分析。
2.隐马尔可夫模型(HMM):EM算法可以用于HMM模型参数的估计,应用于自然语言处理、语音识别等领域。

分类em算法摘要:1.引言2.EM 算法的基本原理3.EM 算法的分类应用4.结论正文:1.引言EM 算法,全称Expectation-Maximization 算法,是一种常见的概率模型优化算法。
该算法在统计学、机器学习等领域具有广泛的应用,特别是在分类问题上表现出色。
本文将重点介绍EM 算法在分类问题上的应用及其基本原理。
2.EM 算法的基本原理EM 算法是一种迭代优化算法,主要通过两个步骤进行:E 步(Expectation)和M 步(Maximization)。
在E 步中,根据观测数据计算样本的隐含变量的期望值;在M 步中,根据隐含变量的期望值最大化模型参数的似然函数。
这两个步骤交替进行,直至收敛。
EM 算法的基本原理可以概括为:对于一个包含隐含变量的概率模型,通过迭代优化模型参数,使得观测数据的似然函数最大化。
在这个过程中,EM 算法引入了Jensen 不等式,保证了算法的收敛性。
3.EM 算法的分类应用EM 算法在分类问题上的应用非常广泛,典型的例子包括高斯混合模型(GMM)和隐马尔可夫模型(HMM)。
(1)高斯混合模型(GMM)在传统的分类问题中,我们通常使用极大似然估计(MLE)来求解最佳分类模型。
然而,当数据分布复杂时,MLE 可能无法得到一个好的解。
此时,我们可以引入EM 算法,通过迭代优化模型参数,提高分类的准确性。
在GMM 中,EM 算法可以有效地处理数据的多峰分布,从而提高分类效果。
(2)隐马尔可夫模型(HMM)HMM 是一种基于序列数据的概率模型,广泛应用于语音识别、时间序列分析等领域。
在HMM 中,EM 算法被用于求解最优路径和状态转移概率。
通过EM 算法,我们可以有效地处理观测序列与隐状态之间的不确定性,从而提高分类效果。
4.结论EM 算法作为一种强大的概率模型优化算法,在分类问题上表现出色。
通过引入隐含变量和迭代优化,EM 算法可以有效地处理数据的复杂性和不确定性,提高分类的准确性。

EM算法EM算法--应用到三个模型:高斯混合模型,混合朴素贝叶斯模型,因子分析模型判别模型求的是条件概率p(y|x),生成模型求的是联合概率p(x,y).即= p(x|y) ? p(y)常见的判别模型有线性回归、对数回归、线性判别分析、支持向量机、boosting、条件随机场、神经网络等。
常见的生产模型有隐马尔科夫模型、朴素贝叶斯模型、高斯混合模型、LDA、RestrictedBoltzmann Machine等。
所以这里说的高斯混合模型,朴素贝叶斯模型都是求p(x,y)联合概率的。
(下面推导会见原因)套路小结:凡是生产模型,目的都是求出联合概率表达式,然后对联合概率表达式里的各个参数再进行估计,求出其表达式。
下面的EM算法,GMM 等三个模型都是做这同一件事:设法求出联合概率,然后对出现的参数进行估计。
一、EM算法:作用是进行参数估计。
应用:(因为是无监督,所以一般应用在聚类上,也用在HMM 参数估计上)所以凡是有EM算法的,一定是无监督学习.因为EM是对参数聚集给定训练样本是高斯混合模型,混合朴素贝叶斯模型,因子分析模型"> 样例独立,我们想要知道每个样例隐含的类别z,使是p(x,z)最大,(即如果将样本x(i)看作观察值,潜在类别z看作是隐藏变量,则x可能是类别z,那么聚类问题也就是参数估计问题,)故p(x,z)最大似然估计是:高斯混合模型,混合朴素贝叶斯模型,因子分析模型">所以可见用到EM算法的模型(高斯混合模型,朴素贝叶斯模型)都是求p(x,y)联合概率,为生成模型。
对上面公式,直接求θ一般比较困难,因为有隐藏变量z存在,但是一般确定了z后,求解就容易了。
EM是一种解决存在隐含变量优化问题的有效方法。
竟然不能直接最大化?(θ),我们可建立?的下界(E步),再优化下界(M步),见下图第三步,取的就是下界高斯混合模型,混合朴素贝叶斯模型,因子分析模型" action-data="http%3A%2F%%2Fbl og%2F515474%2F201305%2F19180744-0ed136937810 4b548dbee01337f6ba69.jpg" action-type="show-slide"> (总式)解释上式:对于每一个样例i,让Qi表示该样例隐含变量z的某种分布,Qi满足的条件是(如果z 是连续性的,那么Qi是概率密度函数(因子分析模型就是如此),需要将求和符号换成积分符号即:高斯混合模型,混合朴素贝叶斯模型,因子分析模型">因子分析模型是如此,这个会用在EM算法的M步求。


聊聊EM算法~EM算法(Expection Maximuzation)的中文名称叫做期望最大化,我的理解EM算法就是一种引入隐含变量的坐标向上法,它与其他优化方法的目的相同,就是求解一个数学模型的最优参数,不同之处在于EM算法交互迭代的对象是隐含变量与模型参数,一般隐含变量表现为数据的类别。
期望说白了就是数据的权重平均,在EM算法中,可以理解为数据的类别,那么既然确定好了数据的类别,下一步就是想办法求取新数据构成分布的参数,一般采用最大似然法求取最优参数。
剩下的就是最普通的迭代过程,先初始化参数,计算数据的概率分布,再对数据进行重新分类,然后重新计算参数,周而复始。
幸运的是,EM算法的收敛性能够得到保证。
曾经读过一篇特别好的博客,通过举例的方式对EM算法解释的很形象,现摘抄如下:“假设我们需要调查我们学校的男生和女生的身高分布。
你怎么做啊?你说那么多人不可能一个一个去问吧,肯定是抽样了。
假设你在校园里随便地活捉了100个男生和100个女生。
他们共200个人(也就是200个身高的样本数据,为了方便表示,下面,我说“人”的意思就是对应的身高)都在教室里面了。
那下一步怎么办啊?你开始喊:“男的左边,女的右边,其他的站中间!”。
然后你就先统计抽样得到的100个男生的身高。
假设他们的身高是服从高斯分布的。
但是这个分布的均值u和方差?2我们不知道,这两个参数就是我们要估计的。
记作θ=[u, ?]T。
再回到例子本身,如果没有“男的左边,女的右边,其他的站中间!”这个步骤,或者说我抽到这200个人中,某些男生和某些女生一见钟情,已经好上了,纠缠起来了。
咱们也不想那么残忍,硬把他们拉扯开。
那现在这200个人已经混到一起了,这时候,你从这200个人(的身高)里面随便给我指一个人(的身高),我都无法确定这个人(的身高)是男生(的身高)还是女生(的身高)。
也就是说你不知道抽取的那200个人里面的每一个人到底是从男生的那个身高分布里面抽取的,还是女生的那个身高分布抽取的。

Em算法,是指期望最大化算法,是一种迭代算法,用于统计中,以找到概率模型中参数的最大似然估计,该估计依赖于不可观察的隐藏变量。
EM算法由dempster,laind和Rubin于1977年提出,是一种非常简单实用的学习算法,可以通过MLE从不完整的数据集中估计参数。
此方法可广泛用于处理不完整的数据,例如缺陷数据,截断的数据和嘈杂的数据。
可能会有一些生动的隐喻可以清楚地解释该算法。
例如,食堂的厨师炒了一道菜,不得不将它分成两部分,以便两个人一起吃。
显然,没有必要以很小的平衡来精确称量它。
最简单的方法是将一个盘子随机分成两个碗,然后观察是否有很多盘子,然后再取其中的一些放到另一个碗中。
这个过程是反复进行的,直到每个人都看不到两个碗中所盛菜肴的重量差异。
EM算法就是这样。
假设我们知道两个参数a和b,它们在初始状态下是未知的。
如果我们知道a的信息,那么我们可以得到b的信息,如果我们知道b,那么我们可以得到a。
可以考虑给定某个初始值以获得b的估计值,然后从b的当前值重新估计a的值,直到当前值收敛为止。
在统计中,最大期望(EM)算法是一种算法,用于根据概率模型中的参数来找到参数的最大似然估计或最大后验估计。
在机器学习和计算机视觉的数据集群领域中经常使用最大期望值。

em算法的概念-回复EM算法的概念是什么?EM算法,全称为Expectation-Maximization algorithm,是一种通过迭代求解含有隐变量的概率模型参数的方法。
该算法是由Arthur Dempster, Nan Laird, 和Donald Rubin在1977年提出的,被广泛应用于统计学和机器学习领域。
EM算法的基本思想是通过最大化一个不完全数据似然函数来估计模型参数。
在一些概率模型中,数据不完整是常见的情况,由于存在未观测到的隐变量,无法直接使用传统的最大似然估计方法。
EM算法通过引入隐变量,将不完全数据的似然函数拆解为两个步骤:E步骤(Expectation)和M步骤(Maximization),通过迭代这两个步骤直至收敛,得到参数的估计值。
具体来说,EM算法包括以下几个步骤:1. 初始化参数:首先,需要对待估计的模型参数进行初始化。
通常情况下,可以通过一些启发式的方法选择初始参数值。
2. E步骤(Expectation):在E步骤中,根据当前参数值计算隐变量的后验概率。
这一步骤的目的是计算隐变量的期望。
3. M步骤(Maximization):在M步骤中,根据E步骤计算得到的隐变量的后验概率,最大化似然函数。
该步骤的目的是找到使得模型在当前观测数据上似然函数最大化的参数。
4. 计算似然函数的增加量:通过计算两次迭代中似然函数的差值,判断是否满足收敛条件。
如果收敛条件不满足,则回到E步骤,继续迭代。
如果收敛条件满足,则停止迭代。
EM算法的理论基础是Jensen不等式,通过不断迭代最大化似然函数,在每一次迭代中,EM算法都能保证似然函数的增加,从而逐步趋近于局部最优解。
EM算法的优点是可以在存在隐变量的情况下进行参数估计,并且能够保证似然函数的单调增加。
缺点是需要对模型的初值进行合理的设定,对初始值敏感,并且有可能陷入局部最优解。
总结来说,EM算法是一种通过迭代最大化不完全数据的似然函数来估计模型参数的方法。
EM算法的英文全称是 Expectation-maximization algorithm,即最大期望算法,或者是期望最大化算法。
EM算法号称是十大机器学习算法之一,听这个名头就知道它非同凡响。
从本质上来说EM算法是最大似然估计方法的进阶版。
最大似然估计假设当下我们有一枚硬币,我们想知道这枚硬币抛出去之后正面朝上的概率是多少,于是我们抛了10次硬币做了一个实验。
发现其中正面朝上的次数是5次,反面朝上的次数也是5次。
所以我们认为硬币每次正面朝上的概率是50%。
从表面上来看,这个结论非常正常,理所应当。
但我们仔细分析会发现这是有问题的,问题在于我们做出来的实验结果和实验参数之间不是强耦合的。
也就是说,如果硬币被人做过手脚,它正面朝上的概率是60%,我们抛掷10次,也有可能得到5次正面5次反面的概率。
同理,如果正面朝上的概率是70%,我们也有一定的概率可以得到5次正面5次反面的结果。
现在我们得到了这样的结果,怎么能说明就一定是50%朝上的概率导致的呢?那我们应该怎么办,继续做实验吗?显然不管我们做多少次实验都不能从根本上解决这个问题,既然参数影响的是出现结果的概率,我们还是应该回到这个角度,从概率上下手。
我们知道,抛硬币是一个二项分布的事件,我们假设抛掷硬币正面朝上的概率是p,那么反面朝上的概率就是1-p。
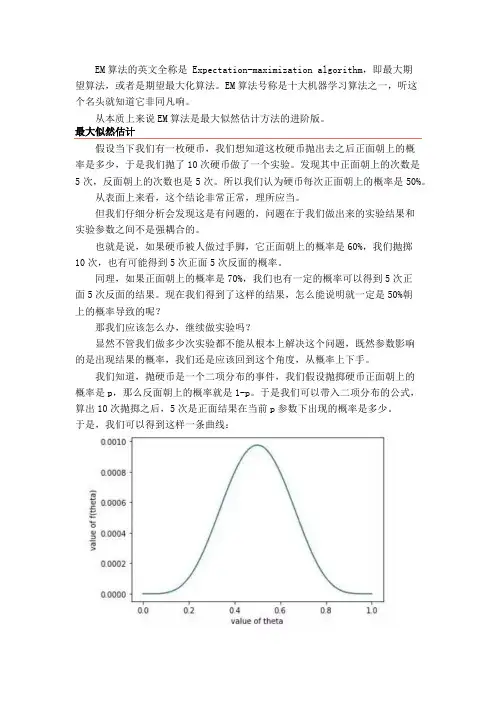
于是我们可以带入二项分布的公式,算出10次抛掷之后,5次是正面结果在当前p参数下出现的概率是多少。
于是,我们可以得到这样一条曲线:也就是正面朝上的概率是0.5的时候,10次抛掷出现5次正面的概率最大。
我们把正面朝上的概率看成是实验当中的参数,我们把似然看成是概率。
那么最大似然估计,其实就是指的是使得当前实验结果出现概率最大的参数。
也就是说我们通过实验结果和概率,找出最有可能导致这个结果的原因或者说参数,这个就叫做最大似然估计。
原理理解了,解法也就顺水推舟了。
首先,我们需要用函数将实验结果出现的概率表示出来。

EM算法原理一、简介EM(Expectation Maximization)算法是一种常见的统计学习方法,用于估计参数和解决一些难以处理的问题,特别是在存在隐变量的情况下。
EM算法最初由数学家罗伯特·卢德米勒(RobertLushmiller)和理查德·贝尔曼(RichardBellman)在20世纪50年代提出,后来由 statisticiansDempster, Laird, and Rubin 进一步发展,因此也被命名为Dempster-Laird-Rubin算法。
EM算法在许多领域都有广泛的应用,如混合高斯模型、隐马尔可夫模型、高斯过程回归等。
二、EM算法的步骤EM算法主要由两个步骤组成:E步(ExpectationStep)和M步(Maximization Step),这两个步骤在迭代过程中交替进行。
1.E步:计算隐变量的条件期望。
给定当前的参数估计值,计算隐变量的条件期望,通常表示为参数的函数。
这个步骤中,隐变量对数似然函数的参数更新起着关键作用。
2.M步:最大化期望值函数。
在E步计算出期望值之后,M步将尝试找到一组参数,使得这个期望值函数最大。
这个步骤中,通常使用优化算法来找到使期望值函数最大的参数值。
这两个步骤在迭代过程中交替进行,每次迭代都更新了参数的估计值,直到满足某个停止准则(如参数收敛或达到预设的最大迭代次数)。
三、EM算法的特点与优点1.处理隐变量:EM算法能够处理数据中存在的隐变量问题,这是它与其他参数估计方法相比的一大优势。
通过估计隐变量的概率分布,EM算法能够更准确地描述数据的生成过程。
2.简单易行:相对于其他优化算法,EM算法相对简单易懂,也容易实现。
它的主要目标是最优化一个简单的对数似然函数,这使得EM算法在许多情况下都能给出很好的结果。
3.稳健性:对于一些数据异常或丢失的情况,EM算法往往表现出较好的稳健性。
这是因为EM算法在估计参数时,会考虑到所有可用的数据,而不仅仅是正常的数据点。

EM算法实验报告一、算法简单介绍EM 算法是Dempster,Laind,Rubin于1977年提出的求参数极大似然估计的一种方法,它可以从非完整数据集中对参数进行MLE估计,是一种非常简单实用的学习算法。
这种方法可以广泛地应用于处理缺损数据、截尾数据以及带有噪声等所谓的不完全数据,可以具体来说,我们可以利用EM算法来填充样本中的缺失数据、发现隐藏变量的值、估计HMM中的参数、估计有限混合分布中的参数以及可以进行无监督聚类等等。
本文主要是着重介绍EM算法在混合密度分布中的应用,如何利用EM算法解决混合密度中参数的估计。
二、算法涉及的理论我们假设X是观测的数据,并且是由某些高斯分布所生成的,X是包含的信息不完整(不清楚每个数据属于哪个高斯分布)。
,此时,我们用k维二元随机变量Z(隐藏变量)来表示每一个高斯分布,将Z引入后,最终得到:,,然而Z的后验概率满足(利用条件概率计算):但是,Z nk为隐藏变量,实际问题中我们是不知道的,所以就用Z nk的期望值去估计它(利用全概率计算)。
然而我们最终是计算max:最后,我们可以得到(利用最大似然估计可以计算):三、算法的具体描述3.1 参数初始化对需要估计的参数进行初始赋值,包括均值、方差、混合系数以及。
3.2 E-Step计算利用上面公式计算后验概率,即期望。
3.3 M-step计算重新估计参数,包括均值、方差、混合系数并且估计此参数下的期望值。
3.4 收敛性判断将新的与旧的值进行比较,并与设置的阈值进行对比,判断迭代是否结束,若不符合条件,则返回到3.2,重新进行下面步骤,直到最后收敛才结束。
四、算法的流程图五、实验结果a_best=0.8022 0.1978mu_best=2.71483.93074.9882 3.0102cov_best=(:,:,1) =5.4082 -0.0693-0.0693 0.2184(:,:,2) =0.0858 -0.0177-0.0177 0.0769f=-1.6323数据X的分布每次迭代期望值利用EM估计的参量值与真实值比较(红色:真实值青绿色:估计值)六、参考文献1.M. Jordan. Pattern Recognition And Machine Learning2.Xiao Han. EM Algorithm七、附录close all;clear;clc;% 参考书籍Pattern.Recognition.and.Machine.Learning.pdf% % lwm@% 2009/10/15%%M=2; % number of GaussianN=200; % total number of data samplesth=0.000001; % convergent thresholdK=2; % demention of output signal% 待生成数据的参数a_real =[4/5;1/5];mu_real=[3 4;5 3];cov_real(:,:,1)=[5 0;0 0.2];cov_real(:,:,2)=[0.1 0;0 0.1];% generate the datax=[ mvnrnd( mu_real(:,1) , cov_real(:,:,1) , round(N*a_real(1)) )' , mvnrnd(mu_real(:,2),cov_real(:,:,2),N-round(N*a_real(1)))'];% for i=1:round(N*a_real(1))% while (~((x(1,i)>0)&&(x(2,i)>0)&&(x(1,i)<10)&&(x(2,i)<10)))% x(:,i)=mvnrnd(mu_real(:,1),cov_real(:,:,1),1)';% end% end%% for i=round(N*a_real(1))+1:N% while (~((x(1,i)>0)&&(x(2,i)>0)&&(x(1,i)<10)&&(x(2,i)<10)))% x(:,i)=mvnrnd(mu_real(:,1),cov_real(:,:,1),1)';% end% endfigure(1),plot(x(1,:),x(2,:),'.')%这里生成的数据全部符合标准%% %%%%%%%%%%%%%%%% 参数初始化a=[1/3,2/3];mu=[1 2;2 1];%均值初始化完毕cov(:,:,1)=[1 0;0 1];cov(:,:,2)=[1 0;0 1];%协方差初始化%% EM Algorothm% loopcount=0;figure(2),hold onwhile 1a_old = a;mu_old = mu;cov_old= cov;rznk_p=zeros(M,N);for cm=1:Mmu_cm=mu(:,cm);cov_cm=cov(:,:,cm);for cn=1:Np_cm=exp(-0.5*(x(:,cn)-mu_cm)'/cov_cm*(x(:,cn)-mu_cm));rznk_p(cm,cn)=p_cm;endrznk_p(cm,:)=rznk_p(cm,:)/sqrt(det(cov_cm));endrznk_p=rznk_p*(2*pi)^(-K/2);%E step%开始求rznkrznk=zeros(M,N);%r(Zpikn=zeros(1,M);%r(Zpikn_sum=0;for cn=1:Nfor cm=1:Mpikn(1,cm)=a(cm)*rznk_p(cm,cn);% pikn_sum=pikn_sum+pikn(1,cm);endfor cm=1:Mrznk(cm,cn)=pikn(1,cm)/sum(pikn);endend%求rank结束% M stepnk=zeros(1,M);for cm=1:Mfor cn=1:Nnk(1,cm)=nk(1,cm)+rznk(cm,cn);endenda=nk/N;rznk_sum_mu=zeros(M,1);% 求均值MUfor cm=1:Mrznk_sum_mu=0;%开始的时候就是错在这里,这里要置零。
EM算法⼀、EM简介EM(Expectation Mmaximization) 是⼀种迭代算法,⽤于含隐变量(Latent Variable) 的概率模型参数的极⼤似然估计,或极⼤后验概率估计 EM算法由两步组成,求期望的E步,和求极⼤的M步。
EM算法可以看成是特殊情况下计算极⼤似然的⼀种算法。
现实的数据经常有⼀些⽐较奇怪的问题,⽐如缺失数据、含有隐变量等问题。
当这些问题出现的时候,计算极⼤似然函数通常是⽐较困难的,⽽EM算法可以解决这个问题。
EM算法已经有很多应⽤,⽐如最经典的Hidden Markov模型等。
经济学中,除了逐渐开始受到重视的HMM模型(例如Yin and Zhao, 2015),其他领域也有可能涉及到EM算法,⽐如在Train的《Discrete Choice Methods with Simulation》就给出了⼀个mixed logit 模型的EM算法。
⼆、EM算法的预备知识1、极⼤似然估计(1)举例说明:经典问题——学⽣⾝⾼问题我们需要调查我们学校的男⽣和⼥⽣的⾝⾼分布。
假设你在校园⾥随便找了100个男⽣和100个⼥⽣。
他们共200个⼈。
将他们按照性别划分为两组,然后先统计抽样得到的100个男⽣的⾝⾼。
假设他们的⾝⾼是服从⾼斯分布的。
但是这个分布的均值u和⽅差∂2我们不知道,这两个参数就是我们要估计的。
记作θ=[u, ∂]T。
问题:我们知道样本所服从的概率分布的模型和⼀些样本,⽽不知道该模型中的参数。
我们已知的有两个:(1)样本服从的分布模型(2)随机抽取的样本需要通过极⼤似然估计求出的包括:模型的参数总的来说:极⼤似然估计就是⽤来估计模型参数的统计学⽅法。
(2)如何估计问题数学化:(1)样本集X={x1,x2,…,xN} N=100 (2)概率密度:p(xi|θ)抽到男⽣i(的⾝⾼)的概率 100个样本之间独⽴同分布,所以我同时抽到这100个男⽣的概率就是他们各⾃概率的乘积。
EM算法实验报告一、算法简单介绍EM 算法是Dempster,Laind,Rubin于1977年提出的求参数极大似然估计的一种方法,它可以从非完整数据集中对参数进行MLE估计,是一种非常简单实用的学习算法。
这种方法可以广泛地应用于处理缺损数据、截尾数据以及带有噪声等所谓的不完全数据,可以具体来说,我们可以利用EM算法来填充样本中的缺失数据、发现隐藏变量的值、估计HMM中的参数、估计有限混合分布中的参数以及可以进行无监督聚类等等。
本文主要是着重介绍EM算法在混合密度分布中的应用,如何利用EM算法解决混合密度中参数的估计。
二、算法涉及的理论我们假设X是观测的数据,并且是由某些高斯分布所生成的,X是包含的信息不完整(不清楚每个数据属于哪个高斯分布)。
,此时,我们用k维二元随机变量Z(隐藏变量)来表示每一个高斯分布,将Z引入后,最终得到:,,然而Z的后验概率满足(利用条件概率计算):但是,Z nk为隐藏变量,实际问题中我们是不知道的,所以就用Z nk的期望值去估计它(利用全概率计算)。
然而我们最终是计算max:最后,我们可以得到(利用最大似然估计可以计算):三、算法的具体描述3.1 参数初始化对需要估计的参数进行初始赋值,包括均值、方差、混合系数以及。
3.2 E-Step计算利用上面公式计算后验概率,即期望。
3.3 M-step计算重新估计参数,包括均值、方差、混合系数并且估计此参数下的期望值。
3.4 收敛性判断将新的与旧的值进行比较,并与设置的阈值进行对比,判断迭代是否结束,若不符合条件,则返回到3.2,重新进行下面步骤,直到最后收敛才结四、算法的流程图五、实验结果a_best=0.8022 0.1978 mu_best=2.71483.93074.9882 3.0102cov_best=(:,:,1) =5.4082 -0.0693-0.0693 0.2184(:,:,2) =0.0858 -0.0177-0.0177 0.0769f=-1.6323数据X的分布每次迭代期望值-50510利用EM估计的参量值与真实值比较(红色:真实值青绿色:估计值)六、参考文献1.M. Jordan. Pattern Recognition And Machine Learning2.Xiao Han. EM Algorithm七、附录close all;clear;clc;% 参考书籍Pattern.Recognition.and.Machine.Learning.pdf% % lwm@% 2009/10/15%%M=2; % number of GaussianN=200; % total number of data samplesth=0.000001; % convergent thresholdK=2; % demention of output signal% 待生成数据的参数a_real =[4/5;1/5];mu_real=[3 4;5 3];cov_real(:,:,1)=[5 0;0 0.2];cov_real(:,:,2)=[0.1 0;0 0.1];% generate the datax=[ mvnrnd( mu_real(:,1) , cov_real(:,:,1) , round(N*a_real(1)) )' , mvnrnd(mu_real(:,2),cov_real(:,:,2),N-round(N*a_real(1)))'];% for i=1:round(N*a_real(1))% while (~((x(1,i)>0)&&(x(2,i)>0)&&(x(1,i)<10)&&(x(2,i)<10)))% x(:,i)=mvnrnd(mu_real(:,1),cov_real(:,:,1),1)';% end% end%% for i=round(N*a_real(1))+1:N% while (~((x(1,i)>0)&&(x(2,i)>0)&&(x(1,i)<10)&&(x(2,i)<10)))% x(:,i)=mvnrnd(mu_real(:,1),cov_real(:,:,1),1)';% end% endfigure(1),plot(x(1,:),x(2,:),'.')%这里生成的数据全部符合标准%% %%%%%%%%%%%%%%%% 参数初始化a=[1/3,2/3];mu=[1 2;2 1];%均值初始化完毕cov(:,:,1)=[1 0;0 1];cov(:,:,2)=[1 0;0 1];%协方差初始化%% EM Algorothm% loopcount=0;figure(2),hold onwhile 1a_old = a;mu_old = mu;cov_old= cov;rznk_p=zeros(M,N);for cm=1:Mmu_cm=mu(:,cm);cov_cm=cov(:,:,cm);for cn=1:Np_cm=exp(-0.5*(x(:,cn)-mu_cm)'/cov_cm*(x(:,cn)-mu_cm));rznk_p(cm,cn)=p_cm;endrznk_p(cm,:)=rznk_p(cm,:)/sqrt(det(cov_cm));endrznk_p=rznk_p*(2*pi)^(-K/2);%E step%开始求rznkrznk=zeros(M,N);%r(Zpikn=zeros(1,M);%r(Zpikn_sum=0;for cn=1:Nfor cm=1:Mpikn(1,cm)=a(cm)*rznk_p(cm,cn);% pikn_sum=pikn_sum+pikn(1,cm);endfor cm=1:Mrznk(cm,cn)=pikn(1,cm)/sum(pikn);endend%求rank结束% M stepnk=zeros(1,M);for cm=1:Mfor cn=1:Nnk(1,cm)=nk(1,cm)+rznk(cm,cn);endenda=nk/N;rznk_sum_mu=zeros(M,1);% 求均值MUfor cm=1:Mrznk_sum_mu=0;%开始的时候就是错在这里,这里要置零。
em算法基本原理宝子!今天咱来唠唠EM算法这个超有趣的东西。
EM算法啊,就像是一个超级侦探,在处理那些有隐藏信息的数据的时候特别厉害。
想象一下,你面前有个神秘的盒子,里面装着一些数据,但是有些关键的小秘密是隐藏起来的,就像捉迷藏一样。
EM算法呢,就是要把这些隐藏的小秘密找出来,让整个数据的情况都明明白白的。
那这个算法到底是怎么个运作法呢?咱先来说说这个E步,也就是期望步(Expectation step)。
这一步就像是在猜谜呢。
它根据现有的一些初步信息,对那些隐藏的变量先做一个大概的估计。
比如说,你知道一群人里有男生和女生,但是你不知道具体谁是男生谁是女生,不过你知道一些关于身高、体重之类的大概信息。
E 步就会根据这些信息去猜一猜,这个人是男生的概率有多大,是女生的概率有多大。
它会算出一个期望的值,就像是在黑暗里先摸一摸方向。
接着就是M步啦,也就是最大化步(Maximization step)。
这一步可就像个贪心的小宝贝,它拿到E步猜出来的那些东西,然后就想办法让某个目标函数达到最大。
还拿男女生的例子来说,M步就会根据E步猜出来的概率,去调整一些参数,比如说男生的平均身高、女生的平均体重这些参数,让这个模型能更好地符合现有的数据。
这就好像是根据之前的猜测,调整一下自己的判断,让这个判断更加准确。
你看,EM算法就是这么在E步和M步之间来回折腾。
就像跳舞一样,跳了一步,再根据这一步的情况调整下一个舞步。
它这样反复循环,每一次循环都会让对隐藏变量的估计和整个模型的参数变得更准确一点。
再打个比方吧,你要做一个蛋糕,但是你不知道面粉和糖的最佳比例,而且还有一些神秘的调料是隐藏起来的。
E步呢,就像是你先根据以往做蛋糕的经验,大概猜一猜面粉和糖的比例,还有那些隐藏调料可能的量。
然后M步就像是你真的去做这个蛋糕,根据做出来的味道,调整面粉、糖还有那些隐藏调料的量,让这个蛋糕变得超级美味。
然后再进行下一轮的E步和M步,不断地调整,直到这个蛋糕达到你心中最完美的状态。
EM算法及其应用实例EM算法(Expectation-Maximization algorithm)是一种迭代算法,用于解决含有隐变量的概率模型的参数估计问题。
EM算法被广泛应用于许多领域,如机器学习、数据挖掘、自然语言处理等。
EM算法的主要思想是通过迭代的方式,交替进行两个步骤:E步骤(expectation)和M步骤(maximization)。
在每一次迭代中,E步骤用于计算模型在当前参数下对观测数据的期望,M步骤则用于更新模型参数,使得模型的对数似然函数得到最大化。
通过不断重复这两个步骤,最终获得模型的最优参数估计。
EM算法的应用实例有很多,下面以两个典型的应用实例进行说明。
1.高斯混合模型(GMM):高斯混合模型是一种概率密度模型,由多个高斯分布组成。
每个高斯分布对应一个隐藏变量,表示观测数据来自于哪个分布。
因此,高斯混合模型包含两部分参数:高斯分布的参数和隐藏变量的分布。
EM算法可以用于估计高斯混合模型的参数。
在E步骤中,根据当前参数,计算每个观测数据来自于每个高斯分布的概率。
在M步骤中,根据E步骤得到的概率,更新高斯混合模型的参数。
通过不断迭代E步骤和M步骤,最终可以得到高斯混合模型的最优参数估计。
2.隐马尔可夫模型(HMM):隐马尔可夫模型是一种概率图模型,用于描述时间序列数据的生成过程。
隐马尔可夫模型由两部分参数组成:状态转移概率和观测概率。
EM算法可以用于估计隐马尔可夫模型的参数。
在E步骤中,根据当前参数,计算观测数据在每个时间步上处于每个隐藏状态的概率。
在M步骤中,根据E步骤得到的概率,更新隐马尔可夫模型的参数。
通过不断迭代E步骤和M步骤,最终可以得到隐马尔可夫模型的最优参数估计。
除了高斯混合模型和隐马尔可夫模型,EM算法还可以应用于其他概率模型的参数估计问题,如朴素贝叶斯分类器、混合朴素贝叶斯分类器等。
总之,EM算法是一种有效的参数估计算法,广泛应用于各个领域。
它通过迭代的方式,交替进行E步骤和M步骤,不断更新模型参数,最终得到模型的最优参数估计。
分类 em算法(原创版)目录1.引言2.EM 算法的概念和原理3.EM 算法的应用实例4.总结正文1.引言EM 算法,全称 Expectation-Maximization 算法,是一种常见的概率模型优化算法。
该算法通过迭代更新参数,使得模型的似然函数最大化,从而得到最优参数。
EM 算法广泛应用于各种领域,如机器学习、模式识别、自然语言处理等。
本文将从 EM 算法的概念和原理入手,结合实际应用实例,介绍 EM 算法的特点和优势。
2.EM 算法的概念和原理EM 算法是一种用于求解概率模型参数的迭代算法。
它的基本思想是:先对模型的似然函数进行期望计算,得到一个关于参数的函数;然后对这个函数进行极大值求解,得到新的参数估计;接着用新的参数估计替换原来的参数,重复上述过程,直至收敛。
具体来说,EM 算法包含两个步骤:E 步和 M 步。
E 步(Expectation step):对观测数据进行期望计算,得到一个关于参数的函数。
M 步(Maximization step):对这个函数进行极大值求解,得到新的参数估计。
重复 E 步和 M 步,直至收敛。
3.EM 算法的应用实例EM 算法在实际应用中有很多实例,下面我们介绍两个典型的应用:(1)聚类:K-means 聚类算法是一种基于距离的聚类方法。
传统的K-means 算法通过迭代计算每个数据点与各个簇心的距离,将数据点分配给距离最近的簇心。
然而,当数据集存在噪声或者簇形状不规则时,传统的 K-means 算法效果不佳。
而基于 EM 算法的 K-means 聚类方法,通过将数据点视为隐含变量的观测值,利用 EM 算法求解数据点的潜在分布,从而实现聚类。
这种方法具有较强的鲁棒性,对数据噪声和不规则形状具有较好的适应性。
(2)隐马尔可夫模型(HMM):隐马尔可夫模型是一种统计模型,用于描述具有马尔可夫性质的随机序列。
在 HMM 中,观测序列和状态序列之间存在一种隐含关系,通过这种关系可以推测状态序列。