西北工业大学人工神经网络考试报告
- 格式:docx
- 大小:560.69 KB
- 文档页数:10

题目1:使用神经网络对三叶草分类问题进行仿真答:1.分类问题描述:已知三种类型的三叶草:白三叶,红三叶,杂三叶,将其记为类型1、2、3,现有它们的4种特征数据,要求根据三叶草的特征数据,对其进行分类。
2.数据集描述:数据集共包含150组数据,挑选其中的75组作为训练数据,其余75组作为测试数据,数据集的每行的前4个数据为三叶草特征数据,最后1个数据为三叶草种类。
(详细数据见,最后部分打印)3.前馈神经网络设计:利用MATLAB 中newff( ),函数创建神经网络,神经网络结构如下:图1-1 神经网络结构图输入层:4输入(分别对应4个特征)隐含层:10输出层:3输出(分别对应该样本属于某一品种的可能性大小),输出节点中可能性最大的节点,对应测试样本的种类;隐含层激活函数为:对数S形转移函数输出层激活函数为:线性函数f(x) = x数据处理归一化函数为:y = ( x - min )/( max - min ) ,其中min,max为x的最小、最大值。
神经网络参数:目标误差为0.01,最大迭代次数1000次,学习率0.01.4.仿真结果展示及分析:(1)由仿真性能图1-2可以看出处,在迭代次数达到200次左右,网络的训练趋于收敛;效果。
但是,当遇到非线性或特征数据维度更高的分类问题时,神经网络将会变得非常庞大,网络各层的权值等参数的调试,也会变得复杂。
同时,耗费在网络训练上的时间也会更高,相应的准确率也会降低。
图1-2 三叶草分类神经网络,仿真结果展示图=============================代码实现===============================%读取训练数据fid = fopen('trainData.txt');trainData = textscan(fid , '%f%f%f%f%f');fclose(fid);[f1,f2,f3,f4,class] = trainData{:};[input,minI,maxI] = premnmx( [f1 , f2 , f3 , f4 ]') ; %对训练数据进行归一化len = length( class ) ; %构造输出矩阵output = zeros( len , 3 ) ;for i = 1 : lenoutput( i , class( i ) ) = 1 ;end%创建神经网络net = newff( minmax(input) , [10 3] , { 'logsig' 'purelin' } , 'traingdx' ) ;%设置训练参数net.trainparam.show = 50 ;net.trainparam.epochs = 1000 ;net.trainparam.goal = 0.01 ;net.trainParam.lr = 0.01 ;%开始训练net = train( net, input , output' ) ;%读取测试数据fid = fopen('testData.txt');testData = textscan(fid, '%f%f%f%f%f');fclose(fid);[t1,t2,t3,t4,c] = testData{:};%测试数据归一化testInput = tramnmx ( [t1,t2,t3,t4]' , minI, maxI ) ;%进行仿真Y = sim( net , testInput );%统计识别正确率[s1 , s2] = size( Y ) ;hitNum = 0 ;for i = 1 : s2[m , Index] = max( Y( : , i ) ) ;if( Index == c(i) )hitNum = hitNum + 1 ;endendsprintf('识别率是%3.3f%%',100 * hitNum / s2 )=============================训练数据集=============================== 5.1 3.5 1.4 0.2 14.9 3 1.4 0.2 14.7 3.2 1.3 0.2 14.6 3.1 1.5 0.2 15 3.6 1.4 0.2 15.4 3.9 1.7 0.4 14.6 3.4 1.4 0.3 15 3.4 1.5 0.2 14.4 2.9 1.4 0.2 14.9 3.1 1.5 0.1 15.4 3.7 1.5 0.2 14.8 3.4 1.6 0.2 14.8 3 1.4 0.1 14.3 3 1.1 0.1 15.8 4 1.2 0.2 15.7 4.4 1.5 0.4 15.4 3.9 1.3 0.4 15.1 3.5 1.4 0.3 15.7 3.8 1.7 0.3 15.1 3.8 1.5 0.3 15.4 3.4 1.7 0.2 14.6 3.6 1 0.2 15.1 3.3 1.7 0.5 1 4.8 3.4 1.9 0.2 1 7 3.2 4.7 1.4 26.4 3.2 4.5 1.5 2 6.9 3.1 4.9 1.5 25.5 2.3 4 1.3 26.5 2.8 4.6 1.5 25.7 2.8 4.5 1.3 26.3 3.3 4.7 1.6 2 4.9 2.4 3.3 1 2 6.6 2.9 4.6 1.3 2 5.2 2.7 3.9 1.4 2 5 2 3.5 1 25.9 3 4.2 1.5 26 2.2 4 1 2 6.1 2.9 4.7 1.4 25.6 2.9 3.6 1.3 26.7 3.1 4.4 1.4 2 5.6 3 4.5 1.5 25.8 2.7 4.1 1 26.2 2.2 4.5 1.5 2 5.6 2.5 3.9 1.1 25.9 3.2 4.8 1.8 26.1 2.8 4 1.3 2 6.3 2.5 4.9 1.5 2 6.1 2.8 4.7 1.2 2 6.4 2.9 4.3 1.3 2 6.3 3.3 6 2.5 3 5.8 2.7 5.1 1.9 37.1 3 5.9 2.1 3 6.3 2.9 5.6 1.8 36.5 3 5.8 2.2 37.6 3 6.6 2.1 3 4.9 2.5 4.5 1.7 3 7.3 2.9 6.3 1.8 36.7 2.5 5.8 1.8 37.2 3.6 6.1 2.5 3 6.5 3.2 5.1 2 3 6.4 2.7 5.3 1.9 3 6.8 3 5.5 2.1 3 5.7 2.5 5 2 3 5.8 2.8 5.1 2.4 36.5 3 5.5 1.8 37.7 3.8 6.7 2.2 37.7 2.6 6.9 2.3 36 2.2 5 1.5 36.9 3.2 5.7 2.3 35.6 2.8 4.9 2 37.7 2.8 6.7 2 36.3 2.7 4.9 1.8 36.7 3.3 5.7 2.1 3=============================测试数据集=============================== 5 3 1.6 0.2 15 3.4 1.6 0.4 15.2 3.5 1.5 0.2 15.2 3.4 1.4 0.2 14.7 3.2 1.6 0.2 14.8 3.1 1.6 0.2 15.4 3.4 1.5 0.4 15.2 4.1 1.5 0.1 15.5 4.2 1.4 0.2 14.9 3.1 1.5 0.2 15 3.2 1.2 0.2 15.5 3.5 1.3 0.2 14.9 3.6 1.4 0.1 14.4 3 1.3 0.2 15.1 3.4 1.5 0.2 15 3.5 1.3 0.3 14.5 2.3 1.3 0.3 14.4 3.2 1.3 0.2 15 3.5 1.6 0.6 15.1 3.8 1.9 0.4 14.8 3 1.4 0.3 15.1 3.8 1.6 0.2 14.6 3.2 1.4 0.2 15.3 3.7 1.5 0.2 15 3.3 1.4 0.2 16.6 3 4.4 1.4 26.8 2.8 4.8 1.4 26.7 3 5 1.7 26 2.9 4.5 1.5 25.7 2.6 3.5 1 25.5 2.4 3.8 1.1 25.5 2.4 3.7 1 25.8 2.7 3.9 1.2 26 2.7 5.1 1.6 25.4 3 4.5 1.5 26 3.4 4.5 1.6 2 6.7 3.1 4.7 1.5 2 6.3 2.3 4.4 1.3 2 5.6 3 4.1 1.3 2 5.5 2.5 4 1.3 25.5 2.6 4.4 1.2 26.1 3 4.6 1.4 2 5.8 2.6 4 1.2 2 5 2.3 3.3 1 2 5.6 2.7 4.2 1.3 2 5.7 3 4.2 1.2 25.7 2.9 4.2 1.3 26.2 2.9 4.3 1.3 2 5.1 2.5 3 1.1 2 5.7 2.8 4.1 1.3 27.2 3.2 6 1.8 3 6.2 2.8 4.8 1.8 3 6.1 3 4.9 1.8 36.4 2.8 5.6 2.1 37.2 3 5.8 1.6 3 7.4 2.8 6.1 1.9 3 7.9 3.8 6.4 2 3 6.4 2.8 5.6 2.2 3 6.3 2.8 5.1 1.5 36.1 2.6 5.6 1.4 37.7 3 6.1 2.3 3 6.3 3.4 5.6 2.4 3 6.4 3.1 5.5 1.8 3 6 3 4.8 1.8 3 6.9 3.1 5.4 2.1 3 6.7 3.1 5.6 2.4 3 6.9 3.1 5.1 2.3 35.8 2.7 5.1 1.9 36.8 3.2 5.9 2.3 3 6.7 3.3 5.7 2.5 3 6.7 3 5.2 2.3 3 6.3 2.5 5 1.9 3 6.5 3 5.2 2 3 6.2 3.4 5.4 2.3 3 5.9 3 5.1 1.8 3题目2: 使用遗传算法解决TSP问题答:1.TSP问题描述:TSP(Traveling Salesman Problem,“旅行商问题”)可简单描述为: 一位销售商从n个城市中的某一城市出发,不重复地走完其余n-1个城市并回到原出发点,在所有可能路径中求出路径长度最短的一条.2.TSP数据规模:本问题中共包含51个城市,其x坐标和y坐标分别为:city_x=[37 49 52 20 40 21 17 31 52 51,...42 31 5 12 36 52 27 17 13 57,...62 42 16 8 7 27 30 43 58 58,...37 38 46 61 62 63 32 45 59 5,...10 21 5 30 39 32 25 25 48 56,...30];city_y=[52 49 64 26 30 47 63 62 33 21,...41 32 25 42 16 41 23 33 13 58,...42 57 57 52 38 68 48 67 48 27,...69 46 10 33 63 69 22 35 15 6,...17 10 64 15 10 39 32 55 28 37,...40];3.遗传算法的设计:遗传算法的流程图如下,具体各部分的实现见下部分详细说明。

一、填空题1、人工神经网络是生理学上的真实人脑神经网络的结构和功能,以及若干基本特性的某种理论抽象、简化和模拟而构成的一种信息处理系统。
从系统的观点看,人工神经网络是由大量神经元通过及其丰富和完善的连接而构成的自适应非线性动态系统。
2、神经元(即神经细胞)是由细胞体、树突、轴突和突触四部分组成。
3、NN的特点:信息的分布存储、大规模并行协同处理、自学习、自组织、自适应性、NN大量神经元的集体行为。
4、膜电位:以外部电位作为参考电位的内部电位。
5、神经元的兴奋:产生膜电位约为100mv,时宽约为1ms,分为四个过程:输入信号期、兴奋期、绝对不应期、相对不应期。
6、神经元的动作特征:空间性相加、时间性相加、阀值作用、不应期、疲劳、可塑性。
7、阀值作用:膜电位上升不超过一定值55mv,神经元不兴奋。
8、学习形式按照输出y划分为:二分割学习、输出值学习、无教师学习。
9、权重改变方式:训练期的学习方式、模式学习方式。
10、稳定的平稳状态指当由于某些随机因素的干扰,使平衡状态发生偏移,随着时间的推移,偏移越来越小,系统最后回到平衡状态。
二、简答题1、学习规则可以分为那几类?答:(1)相关规则:仅根据连接间的激活水平改变权系;(2)纠错规则:基于或等效于梯度下降方法,通过在局部最大改善的方向上,按照小步逐次进行修正,力图达到表示函数功能问题的全局解;(3)无导师学习规则:学习表现为自适应与输入空间的检测规则。
2、简述神经网络按照不同标准分类。
答:按网络结构分为前馈型和反馈型;按网络的性能分为连续性和离散性、确定性和随机性网络;按照学习方式分为有导师(指导)和无导师(自组织学习包括在内)学习;按照突触连接性质分为一阶线性关联与高阶非线性关联网络。
3、误差反传算法的主要思想?答:误差反传算法把学习过程分为两个阶段:第一阶段(正向传播过程),给出输入信息通过输入层经隐含层逐层处理并计算每个单元的实际输出值;第二阶段(反向过程),若在输出层未能得到期望的输出值,则逐层递归的计算实际输出与期望输出之差值(即误差),以便根据此差调节权值。

人工神经网络实验报告
本实验旨在探索人工神经网络在模式识别和分类任务中的应用效果。
实验设置包括构建神经网络模型、数据预处理、训练网络以及评估网
络性能等步骤。
首先,我们选择了一个经典的手写数字识别任务作为实验对象。
该
数据集包含了大量手写数字的灰度图片,我们的目标是通过构建人工
神经网络模型来实现对这些数字的自动识别。
数据预处理阶段包括了对输入特征的标准化处理、数据集的划分以
及对标签的独热编码等操作。
通过对原始数据进行预处理,可以更好
地训练神经网络模型,提高模型的泛化能力。
接着,我们构建了一个多层感知机神经网络模型,包括输入层、隐
藏层和输出层。
通过选择合适的激活函数、损失函数以及优化算法,
我们逐步训练网络,并不断调整模型参数,使得模型在训练集上达到
较高的准确率。
在模型训练完成后,我们对网络性能进行了评估。
通过在测试集上
进行预测,计算模型的准确率、精确率、召回率以及F1-score等指标,来全面评估人工神经网络在手写数字识别任务上的表现。
实验结果表明,我们构建的人工神经网络模型在手写数字识别任务
中表现出色,准确率高达95%以上,具有较高的识别准确性和泛化能力。
这进一步验证了人工神经网络在模式识别任务中的强大潜力,展
示了其在实际应用中的广阔前景。
总之,本次实验通过人工神经网络的构建和训练,成功实现了对手写数字的自动识别,为人工智能技术在图像识别领域的应用提供了有力支持。
希望通过本实验的研究,可以进一步推动人工神经网络技术的发展,为实现人工智能的智能化应用做出更大的贡献。

大工22夏《神经网络》大作业
1. 项目介绍
本次《神经网络》大作业旨在让同学们深入理解神经网络的工作原理,并能够独立实现一个简单的神经网络模型。
通过完成本次作业,同学们将掌握神经网络的基本结构,训练过程以及参数优化方法。
2. 任务要求
1. 独立实现一个具有至少三层神经网络的结构,包括输入层、隐藏层和输出层。
2. 选择一个合适的激活函数,并实现其对应的激活和导数计算方法。
3. 实现神经网络的正向传播和反向传播过程,包括权重更新和偏置更新。
4. 在一个简单的数据集上进行训练,评估并优化所实现的神经网络模型。
3. 评分标准
1. 神经网络结构实现(30分)
2. 激活函数实现(20分)
3. 正向传播和反向传播实现(20分)
4. 模型训练与评估(20分)
5. 代码规范与文档说明(10分)
4. 提交要求
1. 提交代码文件,包括神经网络结构、激活函数、正向传播、反向传播以及训练与评估的实现。
2. 提交一份项目报告,包括项目简介、实现思路、实验结果及分析。
3. 请在提交前确保代码的可运行性,并在报告中附上运行结果截图。
5. 参考资料
1. Goodfellow, I. J., Bengio, Y., & Courville, A. C. (2016). Deep learning. MIT press.
2. Russell, S., & Norvig, P. (2016). Artificial intelligence: a modern approach. Pearson Education Limited.
祝大家作业顺利!。

摘要人工神经网络(Artificial Neural Network,即ANN ),是20世纪80 年代以来人工智能领域兴起的研究热点。
它从信息处理角度对人脑神经元网络进行抽象,建立某种简单模型,按不同的连接方式组成不同的网络。
在工程与学术界也常直接简称为神经网络或类神经网络。
神经网络是一种运算模型,由大量的节点(或称神经元)之间相互联接构成。
每个节点代表一种特定的输出函数,称为激励函数(activation function)。
每两个节点间的连接都代表一个对于通过该连接信号的加权值,称之为权重,这相当于人工神经网络的记忆。
网络的输出则依网络的连接方式,权重值和激励函数的不同而不同。
而网络自身通常都是对自然界某种算法或者函数的逼近,也可能是对一种逻辑策略的表达。
【关键词】人工智能、计算智能、神经科学1.人工神经网络的基本特征人工神经网络是由大量处理单元互联组成的非线性、自适应信息处理系统。
它是在现代神经科学研究成果的基础上提出的,试图通过模拟大脑神经网络处理、记忆信息的方式进行信息处理。
人工神经网络具有四个基本特征:1)非线性非线性关系是自然界的普遍特性。
大脑的智慧就是一种非线性现象。
人工神经元处于激活或抑制二种不同的状态,这种行为在数学上表现为一种非线性人工神经网络关系。
具有阈值的神经元构成的网络具有更好的性能,可以提高容错性和存储容量。
2)非局限性一个神经网络通常由多个神经元广泛连接而成。
一个系统的整体行为不仅取决于单个神经元的特征,而且可能主要由单元之间的相互作用、相互连接所决定。
通过单元之间的大量连接模拟大脑的非局限性。
联想记忆是非局限性的典型例子。
3)非常定性人工神经网络具有自适应、自组织、自学习能力。
神经网络不但处理的信息可以有各种变化,而且在处理信息的同时,非线性动力系统本身也在不断变化。
经常采用迭代过程描写动力系统的演化过程。
4)非凸性一个系统的演化方向,在一定条件下将取决于某个特定的状态函数。

人工神经网络单选练习题一、基本概念1. 下列关于人工神经网络的描述,正确的是:A. 人工神经网络是一种静态的计算模型B. 人工神经网络可以模拟人脑的神经元连接方式C. 人工神经网络只能处理线性问题D. 人工神经网络的学习过程是监督式的2. 下列哪种算法不属于人工神经网络?A. 感知机算法B. 支持向量机算法C. BP算法D. Hopfield网络3. 人工神经网络的基本组成单元是:A. 神经元B. 节点C. 权重D. 阈值二、前向传播与反向传播4. 在前向传播过程中,下列哪个参数是固定的?A. 输入值B. 权重C. 阈值D. 输出值5. 反向传播算法的主要目的是:A. 更新输入值B. 更新权重和阈值C. 计算输出值D. 初始化网络参数6. 下列关于BP算法的描述,错误的是:A. BP算法是一种监督学习算法B. BP算法可以用于多层前馈神经网络C. BP算法的目标是最小化输出误差D. BP算法只能用于解决分类问题三、激活函数7. 下列哪种激活函数是非线性的?A. 步进函数B. Sigmoid函数C. 线性函数D. 常数函数8. ReLU激活函数的优点不包括:A. 计算简单B. 避免梯度消失C. 提高训练速度D. 减少过拟合9. 下列哪种激活函数会出现梯度饱和现象?A. Sigmoid函数B. ReLU函数C. Tanh函数D. Leaky ReLU函数四、网络结构与优化10. 关于深层神经网络,下列描述正确的是:A. 深层神经网络一定比浅层神经网络效果好B. 深层神经网络更容易过拟合C. 深层神经网络可以减少参数数量D. 深层神经网络训练速度更快11. 下列哪种方法可以降低神经网络的过拟合?A. 增加训练数据B. 减少网络层数C. 增加网络参数D. 使用固定的学习率12. 关于卷积神经网络(CNN),下列描述错误的是:A. CNN具有局部感知能力B. CNN具有参数共享特点C. CNN可以用于图像识别D. CNN无法处理序列数据五、应用场景13. 下列哪种问题不适合使用人工神经网络解决?A. 图像识别B. 自然语言处理C. 股票预测D. 线性规划14. 下列哪个领域不属于人工神经网络的应用范畴?A. 医学诊断B. 金融预测C. 智能家居D. 数值计算15. 关于循环神经网络(RNN),下列描述正确的是:A. RNN无法处理长距离依赖问题B. RNN具有短期记忆能力C. RNN训练过程中容易出现梯度消失D. RNN只能处理序列长度相同的数据六、训练技巧与正则化16. 下列哪种方法可以用来防止神经网络训练过程中的过拟合?A. 提前停止B. 增加更多神经元C. 减少训练数据D. 使用更大的学习率17. 关于Dropout正则化,下列描述错误的是:A. Dropout可以减少神经网络中的参数数量B. Dropout在训练过程中随机丢弃一些神经元C. Dropout可以提高模型的泛化能力D. Dropout在测试阶段不使用18. L1正则化和L2正则化的主要区别是:A. L1正则化倾向于产生稀疏解,L2正则化倾向于产生平滑解B. L1正则化比L2正则化更容易计算C. L2正则化可以防止过拟合,L1正则化不能D. L1正则化适用于大规模数据集,L2正则化适用于小规模数据集七、优化算法19. 关于梯度下降法,下列描述正确的是:A. 梯度下降法一定会找到全局最小值B. 梯度下降法在鞍点处无法继续优化C. 梯度下降法包括批量梯度下降、随机梯度下降和小批量梯度下降D. 梯度下降法的学习率在整个训练过程中保持不变20. 下列哪种优化算法可以自动调整学习率?A. 随机梯度下降(SGD)B. Adam优化算法C. Momentum优化算法D. 牛顿法21. 关于Adam优化算法,下列描述错误的是:A. Adam结合了Momentum和RMSprop算法的优点B. Adam算法可以自动调整学习率C. Adam算法对每个参数都使用相同的学习率D. Adam算法在训练初期可能会不稳定八、损失函数22. 在分类问题中,下列哪种损失函数适用于二分类问题?A. 均方误差(MSE)B. 交叉熵损失函数C. Hinge损失函数D. 对数损失函数23. 关于均方误差(MSE)损失函数,下列描述错误的是:A. MSE适用于回归问题B. MSE对异常值敏感C. MSE的输出范围是[0, +∞)D. MSE损失函数的梯度在接近最小值时趋近于024. 下列哪种损失函数适用于多分类问题?A. 交叉熵损失函数B. Hinge损失函数C. 对数损失函数D. 均方误差(MSE)九、模型评估与超参数调优25. 下列哪种方法可以用来评估神经网络的性能?A. 训练误差B. 测试误差C. 学习率D. 隐层神经元数量26. 关于超参数,下列描述正确的是:A. 超参数是在模型训练过程中自动学习的B. 超参数的值通常由经验丰富的专家设定C. 超参数的调整对模型性能没有影响D. 超参数包括学习率、批量大小和损失函数27. 关于交叉验证,下列描述错误的是:A. 交叉验证可以减少过拟合的风险B. 交叉验证可以提高模型的泛化能力C. 交叉验证会降低模型的训练速度D. 交叉验证适用于小规模数据集十、发展趋势与挑战28. 下列哪种技术是近年来人工神经网络的一个重要发展方向?A. 深度学习B. 线性回归C. 决策树D. K最近邻29. 关于深度学习,下列描述错误的是:A. 深度学习需要大量标注数据B. 深度学习模型通常包含多层神经网络C. 深度学习可以处理复杂的非线性问题D. 深度学习不适用于小规模数据集30. 下列哪种现象是训练深度神经网络时可能遇到的挑战?A. 梯度消失B. 参数过多C. 数据不平衡D. 所有上述选项都是挑战答案一、基本概念1. B2. B二、前向传播与反向传播4. B5. B6. D三、激活函数7. B8. D9. A四、网络结构与优化10. B11. A12. D五、应用场景13. D14. D15. C六、训练技巧与正则化16. A17. A18. A七、优化算法19. C20. B八、损失函数22. B23. D24. A九、模型评估与超参数调优25. B26. B27. D十、发展趋势与挑战28. A29. D30. D。

人工神经网络系别:计算机工程系班级: 1120543 班学号: 13 号姓名:日期:2014年10月23日人工神经网络摘要:人工神经网络是一种应用类似于大脑神经突触联接的结构进行信息处理的数学模型。
在工程与学术界也常直接简称为神经网络或类神经网络。
神经网络是一种运算模型,由大量的节点(或称神经元)之间相互联接构成,由大量处理单元互联组成的非线性、自适应信息处理系统。
它是在现代神经科学研究成果的基础上提出的,试图通过模拟大脑神经网络处理、记忆信息的方式进行信息处理。
关键词:神经元;神经网络;人工神经网络;智能;引言人工神经网络的构筑理念是受到生物(人或其他动物)神经网络功能的运作启发而产生的。
人工神经网络通常是通过一个基于数学统计学类型的学习方法(Learning Method )得以优化,所以人工神经网络也是数学统计学方法的一种实际应用,通过统计学的标准数学方法我们能够得到大量的可以用函数来表达的局部结构空间,另一方面在人工智能学的人工感知领域,我们通过数学统计学的应用可以来做人工感知方面的决定问题(也就是说通过统计学的方法,人工神经网络能够类似人一样具有简单的决定能力和简单的判断能力),这种方法比起正式的逻辑学推理演算更具有优势。
一、人工神经网络的基本原理1-1神经细胞以及人工神经元的组成神经系统的基本构造单元是神经细胞,也称神经元。
它和人体中其他细胞的关键区别在于具有产生、处理和传递信号的功能。
每个神经元都包括三个主要部分:细胞体、树突和轴突。
树突的作用是向四方收集由其他神经细胞传来的信息,轴突的功能是传出从细胞体送来的信息。
每个神经细胞所产生和传递的基本信息是兴奋或抑制。
在两个神经细胞之间的相互接触点称为突触。
简单神经元网络及其简化结构如图2-2所示。
从信息的传递过程来看,一个神经细胞的树突,在突触处从其他神经细胞接受信号。
这些信号可能是兴奋性的,也可能是抑制性的。
所有树突接受到的信号都传到细胞体进行综合处理,如果在一个时间间隔内,某一细胞接受到的兴奋性信号量足够大,以致于使该细胞被激活,而产生一个脉冲信号。

08 –09 学第一学:神经网络计算机科学与技术(医学智能方向)06:::v······yy··················yy3. 在MA TLAB中,下面的(○3)命令可以使用得下次绘制的图和已经绘制的图将不在同一张图上。
不在同一张图上。
A) hold on(设置在同一张图绘制多条曲线)(设置在同一张图绘制多条曲线)B) figure (下次的图和已绘制的不在同一张图上)C) plot D) hold off(取消在同一张图绘制多条曲线)3.下面是一段有关向量运算的MA TLAB代码: >>y= [3 7 11 5]; >>y(3) = 2 运算后的输出结果是(○8)A) 3 2 11 5 B) 3 7 2 5C) 2 7 11 5 D) 3 7 11 2 4. 下面是一段有关矩阵运算的MA TLAB代码: >>A = [1 2 3 4; 5 6 7 8; 9 10 11 12];>>B = A(2,1:3)取出矩阵A中第二行第一个到第三个构成矩阵B 若A(2,3)=5将矩阵第二行第三列的元素置为5 A=[A B’]将B转置后,再以列向量并入A A(:,2)=[]删除第二列:代表删除列A([1,4],:)=[]删除第一和第四行:代表删除行A=[A;4,3,2,1]加入第四行那么运算后的输出结果是(○9)A) 5 7 8 B) 5 6 8 C) 5 6 7D) 6 7 8 plot(x,y,s),s)函数叙说正确的是(○10)5.下面对MA TLAB中的中的 plot(x,yA) 绘制以x、y为横纵坐标的连线图(plot(x,y)) B绘制多条不同色彩的连线图绘制多条不同色彩的连线图 (plot(x,y))C) 默认的绘图颜色为蓝色D) 如果s=’r+’,则表示由红色的+号绘制图形6. 如果现在要对一组数据进行分类,我们不知道这些数据最终能分成几类,那么应)来处理这些数据最适合。

习题2.1什么是感知机?感知机的基本结构是什么样的?解答:感知机是Frank Rosenblatt在1957年就职于Cornell航空实验室时发明的一种人工神经网络。
它可以被视为一种最简单形式的前馈人工神经网络,是一种二元线性分类器。
感知机结构:2.2单层感知机与多层感知机之间的差异是什么?请举例说明。
解答:单层感知机与多层感知机的区别:1. 单层感知机只有输入层和输出层,多层感知机在输入与输出层之间还有若干隐藏层;2. 单层感知机只能解决线性可分问题,多层感知机还可以解决非线性可分问题。
2.3证明定理:样本集线性可分的充分必要条件是正实例点集所构成的凸壳与负实例点集构成的凸壳互不相交.解答:首先给出凸壳与线性可分的定义凸壳定义1:设集合S⊂R n,是由R n中的k个点所组成的集合,即S={x1,x2,⋯,x k}。
定义S的凸壳为conv(S)为:conv(S)={x=∑λi x iki=1|∑λi=1,λi≥0,i=1,2,⋯,k ki=1}线性可分定义2:给定一个数据集T={(x1,y1),(x2,y2),⋯,(x n,y n)}其中x i∈X=R n , y i∈Y={+1,−1} , i=1,2,⋯,n ,如果存在在某个超平面S:w∙x+b=0能够将数据集的正实例点和负实例点完全正确地划分到超平面的两侧,即对所有的正例点即y i=+1的实例i,有w∙x+b>0,对所有负实例点即y i=−1的实例i,有w∙x+b<0,则称数据集T为线性可分数据集;否则,称数据集T线性不可分。
必要性:线性可分→凸壳不相交设数据集T中的正例点集为S+,S+的凸壳为conv(S+),负实例点集为S−,S−的凸壳为conv(S−),若T是线性可分的,则存在一个超平面:w ∙x +b =0能够将S +和S −完全分离。
假设对于所有的正例点x i ,有:w ∙x i +b =εi易知εi >0,i =1,2,⋯,|S +|。

《神经网络原理》一、填空题1、从系统的观点讲,人工神经元网络是由大量神经元通过极其丰富和完善的连接而构成的自适应、非线性、动力学系统。
2、神经网络的基本特性有拓扑性、学习性和稳定收敛性。
3、神经网络按结构可分为前馈网络和反馈网络,按性能可分为离散型和连续型,按学习方式可分为有导师和无导师。
4、神经网络研究的发展大致经过了四个阶段。
5、网络稳定性指从t=0时刻初态开始,到t时刻后v(t+△t)=v(t),(t>0),称网络稳定。
6、联想的形式有两种,它们分是自联想和异联想。
7、存储容量指网络稳定点的个数,提高存储容量的途径一是改进网络的拓扑结构,二是改进学习方法。
8、非稳定吸引子有两种状态,一是有限环状态,二是混沌状态。
9、神经元分兴奋性神经元和抑制性神经元。
10、汉明距离指两个向量中对应元素不同的个数。
二、简答题1、人工神经元网络的特点?答:(1)、信息分布存储和容错性。
(2)、大规模并行协同处理。
(3)、自学习、自组织和自适应。
(4)、人工神经元网络是大量的神经元的集体行为,表现为复杂的非线性动力学特性。
(5)人式神经元网络具有不适合高精度计算、学习算法和网络设计没有统一标准等局限性。
2、单个神经元的动作特征有哪些?答:单个神经元的动作特征有:(1)、空间相加性;(2)、时间相加性;(3)、阈值作用;(4)、不应期;(5)、可塑性;(6)疲劳。
3、怎样描述动力学系统?答:对于离散时间系统,用一组一阶差分方程来描述:X(t+1)=F[X(t)];对于连续时间系统,用一阶微分方程来描述:dU(t)/dt=F[U(t)]。
4、F(x)与x 的关系如下图,试述它们分别有几个平衡状态,是否为稳定的平衡状态?答:在图(1)中,有两个平衡状态a 、b ,其中,在a 点曲线斜率|F ’(X)|>1,为非稳定平稳状态;在b 点曲线斜率|F ’(X)|<1,为稳定平稳状态。
在图(2)中,有一个平稳状态a ,且在该点曲线斜率|F ’(X)|>1,为非稳定平稳状态。

The weight updating rules of the perceptron and Kohonen neural network are _____.The limitation of the perceptron is that it can only model linearly separable classes. The decision boundary of RBF is__________linear______________________whereas the decision boundary of FFNN is __________________non-linear___________________________.Question Three:The activation function of the neuron of the Perceptron, BP network and RBF network are respectively________________; ________________; ______________.Question Four:Please present the idea, objective function of the BP neural networks (FFNN) and the learning rule of the neuron at the output layer of FFNN. You are encouraged to write down the process to produce the learning rule.Question Five:Please describe the similarity and difference between Hopfield NN and Boltzmann machine.相同:Both of them are single-layer inter-connection NNs.They both have symmetric weight matrix whose diagonal elements are zeroes.不同:The number of the neurons of Hopfield NN is the same as the number of the dimension (K) of the vector data. On the other hand, Boltzmann machine will have K+L neurons. There are L hidden neuronsBoltzmann machine has K neurons that serves as both input neurons and output neurons (Auto-association Boltzmann machine).Question Six:Please explain the terms in the above equation in detail. Please describe the weight updating equations of each node in the following FFNN using the BP learning algorithm. (PPT原题y=φ(net)= φ(w0+w1x1+w2x2))W0=w0+W1=w1+W2=w2+Question Seven:Please try your best to present the characteristics of RBF NN.(1)RBF networks have one single hidden layer.(2)In RBF the neuron model of the hidden neurons is different from the one of the output nodes.(3)The hidden layer of RBF is non-linear, the output layer of RBF is linear.(4)The argument of activation function of each hidden neuron in a RBF NN computes the Euclidean distance between input vector and the center of that unit.(5)RBF NN uses Gaussian functions to construct local approximations to non-linear I/O mapping.Question Eight:Generally, the weight vectors of all neurons of SOM is adjusted in terms of the following rule:w j(n+1)=w j(n)+η(n)h i(x)(d i(x)j)(x(n)-w j(n)).Please explain each term in the above formula.: weight value of the j-th neuron at iteration n: neighborhood functiondji: lateral distance of neurons i and j: the learning rate: the winning neuron most adjacent to XX: one input example。

一、实验目的本次实验旨在了解神经网络的基本原理,掌握神经网络的构建、训练和测试方法,并通过实验验证神经网络在实际问题中的应用效果。
二、实验内容1. 神经网络基本原理(1)神经元模型:神经元是神经网络的基本单元,它通过接收输入信号、计算加权求和、应用激活函数等方式输出信号。
(2)前向传播:在神经网络中,输入信号通过神经元逐层传递,每层神经元将前一层输出的信号作为输入,并计算输出。
(3)反向传播:在训练过程中,神经网络通过反向传播算法不断调整各层神经元的权重和偏置,以最小化预测值与真实值之间的误差。
2. 神经网络构建(1)确定网络结构:根据实际问题选择合适的网络结构,包括输入层、隐含层和输出层的神经元个数。
(2)初始化参数:随机初始化各层神经元的权重和偏置。
3. 神经网络训练(1)选择损失函数:常用的损失函数有均方误差(MSE)和交叉熵(CE)等。
(2)选择优化算法:常用的优化算法有梯度下降、Adam、SGD等。
(3)训练过程:将训练数据分为训练集和验证集,通过反向传播算法不断调整网络参数,使预测值与真实值之间的误差最小化。
4. 神经网络测试(1)选择测试集:从未参与训练的数据中选取一部分作为测试集。
(2)测试过程:将测试数据输入网络,计算预测值与真实值之间的误差,评估网络性能。
三、实验步骤1. 数据准备:收集实验所需数据,并进行预处理。
2. 神经网络构建:根据实际问题确定网络结构,初始化参数。
3. 神经网络训练:选择损失函数和优化算法,对网络进行训练。
4. 神经网络测试:将测试数据输入网络,计算预测值与真实值之间的误差,评估网络性能。
四、实验结果与分析1. 实验结果(1)损失函数曲线:观察损失函数随训练轮数的变化趋势,分析网络训练效果。
(2)测试集误差:计算测试集的预测误差,评估网络性能。
2. 结果分析(1)损失函数曲线:从损失函数曲线可以看出,随着训练轮数的增加,损失函数逐渐减小,说明网络训练效果较好。

西安建筑科技大学研究生课程考试试卷考试科目:人工神经网络课程编码:071032任课教师:谷立臣考试时间:2014.4.30学号:1307841390学生姓名:李宇峰SOM神经网络在滚动轴承振动诊断中的应用摘要:SOM网络是一种重要的无导师学习训练算法的神经网络,使用该算法进行训练后,可以将高维输入空间映射到二维空间上,并对故障现象进行自动分类,从而得出它们对应的故障原因。
本文归纳和总结了SOM神经网络多参数诊断法的实施步骤,阐述了轴承故障与振动信号之间的关系以及神经网络的工作原理和实现过程,通过实验研究,提取了反映滚动轴承故障类型的振动信号的特征参数,以构建训练神经网络的特征向量,利用MATLAB人工神经网络工具箱模拟和仿真SOM神经网络,然后用训练后的SOM神经网络对故障模式进行识别。
关键词:振动;滚动轴承;故障诊断;SOM神经网络1 故障轴承振动与信号的关系故障滚动轴承在受载运转时,当缺陷部位与工作表面接触,都将产生一次冲击力。
这种冲击力将激起轴承系统的振动,并通过适当的振动传递通道,以振动和声音的形式传出。
信号传递过程,如图1所示。
滚动轴承工作时,由传感器拾取的振动信号成分比较复杂,损伤引起的固有衰减振动只是其中的组成部分。
当损伤微小时,往往被其他信号淹没而难以被发现。
信号处理的目的就是突出这些损伤特征成分。
图1轴承振动信号传递过程2 SOM神经网络的结构和学习算法2.1神经网络结构自组织特征映射神经网络是芬兰神经网络专家Kohnen于1981年提出的,网络结构由输入层和输出层组成。
输入层为单层神经元排列,其作用是通过权向量将外界信息转到输出层神经元。
输出层也叫竞争层,输出层的神经元同它周围的神经元侧向连接,成棋盘状平面。
其神经元排列有多种形式,其最典型的是二维形式。
在初始状态下,这些二维的处理单元阵列上没有这些信号特征的分布拓扑图。
利用SOM模型的这一特性,可以从外界环境中按照某种测度或者是某种可有序化的拓扑空间来抽取特征或者是表达信号的、概念性的元素。

人工智能实验上机报告三班级:130811学号:********姓名:潘**上机实验(三)小型专家系统一.定义题目(包含图)短跑运动员水平测试系统刘翔:史冬鹏:黄晓明:系统要根据属性识别运动员特质,例如,皮肤黄色,有胡子,高个子。
二.谓词定义databasexpositive( symbol, symbol) .xnegative( symbol, symbol) .predicatesrun.animal- is( symbol) .it- is( symbol) .positive( symbol, symbol) .negative( symbol, symbol) .clear- facts.remember( symbol, symbol) .ask( symbol, symbol) .三.程序代码traceDababaseSpositive(symbol,symbol)Snegative(symbol,symbol)PredicatesRunPerson_is(symbol)Positive(symbol,symbol)Negative(symbol,symbol)Clear_facesRemember(symbol,symbol,symbol)Ask(symbol,symbol)GoalRunClausesRun:-Person_is(x),!,write(“THIS IS ”, X),nl,nl,clear_facts.Run:-write (“can not determine this person”), clear_facts.Positive(X,Y);-xpositive(X,Y),!Positive(X,Y):-not(xnegetive(X,Y)),ask(X,Y).Negative(X,Y):-xnegative(X,Y),!Negative(X,Y):-not(xpositive(X,Y)),ask(X,Y).ask(X,Y):-write("How about his ",X,"?\nPress yes, if ",Y, ", press no for others.\n"), readln(Reply),remember(X,Y,Reply).remember(X,Y,yes):-asserta(xpositive(X,Y)).remember(X,Y,no):-asserta(xnegative(X,Y)),fail.clear_facts:-retract(xpositive(_,_)),fail.clear_facts:-retract(xnegative(_,_)),fail.clear_facts:-write("\n\nPlease press space bar to quit"), readchar(_). Person_is(“liuxiang”):-Positive(“face color”,”red”),Positive(“Stature”, “high”),Positive(“mustache”,”exist”).Positive(“face feature”, “long”).Positive(“zhengshu”, “sword”).Person_is(“huangxiaoming”):-Positive(“face color”,”black”),Positive(“mustache”,”exist”).Positive(“voice”,”high”).Positive(“zhengshu”, “spear”).Positive(“stature”, “short”).Person_is(“shidongpeng”):-Positive(“mustache”,”exist”).Positive(“zhengshu”, “gun”).Positive(“Stature”, “high”)四.给出运行结果。

人工神经网络练习题
1. 什么是人工神经网络?
人工神经网络是一种模仿人类神经系统结构和功能的计算模型。
它由许多人工神经元组成,通过模拟神经元之间的相互连接和信息
传递来研究和处理数据。
2. 人工神经网络的优点是什么?
人工神经网络具有以下优点:
- 能够进行非线性建模,适用于处理复杂的非线性问题。
- 具有自适应研究能力,能够通过反馈机制不断优化性能。
- 对于模式识别、分类和预测等任务表现良好。
- 具有容错性,即使部分神经元损坏,网络仍然可以正常工作。
3. 人工神经网络的主要组成部分有哪些?
人工神经网络主要由以下组成部分构成:
- 输入层:接收外部输入数据。
- 隐藏层:进行数据处理和特征提取。
- 输出层:给出最终的结果。
- 权重:神经元之间的连接强度。
- 激活函数:用于处理神经元的输入和输出。
4. 请解释反向传播算法的工作原理。
反向传播算法是一种用于训练人工神经网络的方法。
它通过将
输入数据传递给网络,并比较输出结果与期望结果之间的差异,然
后根据差异调整网络中的权重和偏置值。
该过程从输出层开始,逐
渐向前传播误差,然后通过梯度下降法更新权重和偏置值,最终使
网络逼近期望输出。
5. 请列举几种常见的用途人工神经网络的应用。
人工神经网络可以应用于许多领域,包括但不限于:
- 机器研究和模式识别
- 金融市场预测
- 医学诊断和预测
- 自动驾驶汽车
- 语音和图像识别
以上是关于人工神经网络的练习题,希望对您的学习有所帮助。

1.简述什么是人工神经网络。
简单地讲,人工神经网络就是基于模仿生物大脑的结构和功能,采用数学和物理方法进行研究而构成的一种信息处理系统或计算机。
目前关于人工神经网络还尚未有一个严格的统一的定义,不同的科学家从各个不同侧面指出了人工神经网络的特点。
例如,美国神经网络学家Hecht Nielsen关于人工神经网络的定义是:“人工神经网络是由多个非常简单的处理单元彼此按照某种方式相互连接形成的计算机系统,该系统是靠其状态对外部输入信息的动态响应来处理信息的”。
美国国防部高级研究计划局关于人工神经网络的定义是:“人工神经网络是一个由许多简单的并行工作的处理单元组成的系统,其功能取决于网络的结构、连接强度以及各个单元的处理方式”。
2.人工神经网络研究处于低潮的原因是什么?重新兴起的动因是什么?处于低潮的原因:1969年,美国著名人工智能学者M. Minsky和S. Papert出版的《感知机》(Perception)一书指出,简单的人工神经网络只能用于线性问题求解,能够求解非线性问题的人工神经网络应该具有中间层,但是在理论上还不能证明将感知机模型扩展到多层网络是有意义的。
重新兴起的动因:1982年,美国加州理工学院的生物物理学家J.Hopfield教授提出了Hopfield网络模型,并于1984年对Hopfield模型进行了电子电路实现。
Hopfield模型引入了物理力学分析方法,阐明了神经网络与动力学之间的关系,建立了神经网络稳定性判断依据,指出了信息存储在网络中各个神经元之间的连接上。
3.人工神经网络的特点是什么?人工神经网络擅长解决哪类问题?特点:(1) 固有的并行结构和并行处理特性;(2) 知识的分布存储特性;(3) 良好的容错特性;(4) 高度非线性及计算的非精确性;(5) 自学习、自组织和自适应性。
擅长解决的问题类型:联想记忆、非线性映射、分类与识别、优化计算等。
4.人工神经网络的信息处理能力体现在那些方面?体现在存储和计算两方面,其中信息存储能力取决于不同的神经网络模型,神经网络的拓扑结构、网络连接权值的设计方法等都可以影响一个神经网络的信息存储容量;计算能力主要表现为神经网络的非线性映射能力、并行分布计算能力等。

第一章网络技术入门一、计算机网络定义计算机网络是计算机硬件、线缆、网络设备和让计算机能相互通信的计算机软件的集合。
二、Internet定义世界上最大的数据网络是不同类型、不同大小的网络所组成网络边缘是计算机三、计算机基本的网络部件网卡,调制解调器四、二进制数与十进制数换算第二章网络技术基础五、计算机网络发展的三个阶段及代表性网络类型面向终端的计算机网络——单个计算机为中心的远程联机系统美国半自动地面防空系统SAGE多个自主计算机通过通信线路互连——形成计算机网络ARPANET国际标准化的网络具有统一的网络体系结构遵循国际标准化协议的计算机网络ISO/OSI 网络7层模型六、LAN WAN MAN各自特点和区别LAN 由计算机、网络接口卡、外围设备、网络介质以及网络通信控制设备组成;主要完成的工作:1、在有限的地理范围内运作;2、允许多个用户同时接入高带宽介质;3、提供实时的本地服务的连接;MAN 在一个城市里由一个或多个LAN组成的大型网络群七、常见的几种网络设备Repeater Hub Bridge Switch八、网络拓扑结构物理拓扑:总线型拓扑星型拓扑环型拓扑树型拓扑网状拓扑逻辑拓扑:广播拓扑---每台主机都把所要发送的数据的目标地址设为某个特定的NIC或多播地址、广播地址,然后把数据发送到传输介质中。
令牌传递----通过向各个节点顺序传递一个电子令牌来控制网络介质的访问。
九、数据与信号的概念数据、数据形式数字、字母、符号的集合。
数据被用来表示一定的信息。
模拟数据和数字数据。
信号将数据转换成电信号的形式模拟信号数字信号十、通信系统模型十一、模拟通信、数字通信和数据通信的区别模拟通信-信源为模拟数据,信道中为模拟信号,为模拟通信数字通信-信源为模拟数据,信道中为数字信号,为数字通信数据通信-信源发出数字数据十二、基带传输和频带传输的区别和典型例子基带传输数据信息被转换成电信号时,使用信号固有频率和波形传输。
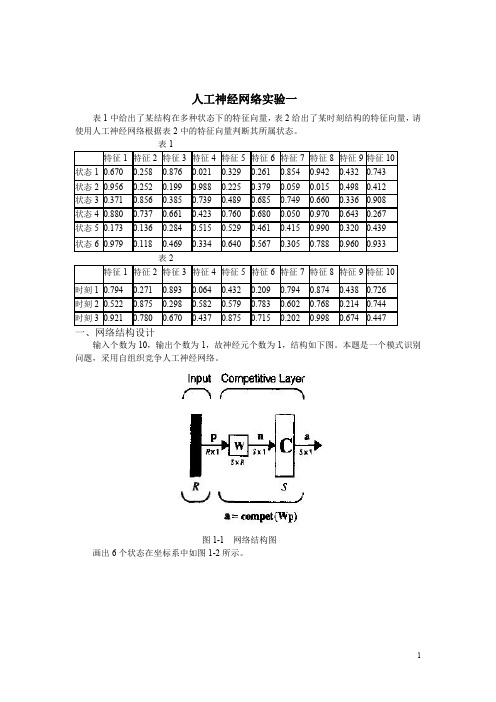
人工神经网络实验一表1中给出了某结构在多种状态下的特征向量,表2给出了某时刻结构的特征向量,请使用人工神经网络根据表2中的特征向量判断其所属状态。
表1特征1特征2特征3特征4特征5特征6特征7特征8特征9特征10状态10.6700.2580.8760.0210.3290.2610.8540.9420.4320.743状态20.9560.2520.1990.9880.2250.3790.0590.0150.4980.412状态30.3710.8560.3850.7390.4890.6850.7490.6600.3360.908状态40.8800.7370.6610.4230.7600.6800.0500.9700.6430.267状态50.1730.1360.2840.5150.5290.4610.4150.9900.3200.439状态60.9790.1180.4690.3340.6400.5670.3050.7880.9600.933表2特征1特征2特征3特征4特征5特征6特征7特征8特征9特征10时刻10.7940.2710.8930.0640.4320.2090.7940.8740.4380.726时刻20.5220.8750.2980.5820.5790.7830.6020.7680.2140.744时刻30.9210.7800.6700.4370.8750.7150.2020.9980.6740.447一、网络结构设计输入个数为10,输出个数为1,故神经元个数为1,结构如下图。
本题是一个模式识别问题,采用自组织竞争人工神经网络。
图1-1网络结构图画出6个状态在坐标系中如图1-2所示。
-0.20.20.40.60.811.2Input Vectorsp(1)p (2)图1-2状态向量图二、实验源程序如下(或见附件中M 文件):%创建输入向量X=[01;01]>>clusters=6;>>points=10;>>std_dev=0.05;>>P=nngenc(X,clusters,points,std_dev);>>plot(P(1,:),P(2,:),'+r')>>title('Input Vectors');>>xlabel('p(1)');>>ylabel('p(2)');%创建自组织竞争神经网络>>net=newc([01;01],6,.1);>>net=init(net);>>w=net.IW{1};>>hold off;>>plot(P(1,:),P(2,:),'+r');>>hold on;plot(w(:,1),w(:,2),'ob');>>xlabel('p(1)');>>ylabel('p(2)');>>hold off;>>net.trainParam.epochs=7;>>hold on;>>net=init(net);>>more off;>>net=train(net,P);TRAINR,Epoch0/7TRAINR,Epoch7/7TRAINR,Maximum epoch reached.%训练该网络hold on;net=init(net);more off;>>w=net.IW{1};>>delete(findobj(gcf,'color',[001]));>>hold off>>plot(P(1,:),P(2,:),'+r');>>hold off;>>hold on;plot(w(:,1),w(:,2),'ob');>>xlabel('p(1)');>>ylabel('p(2)');>>hold off;%仿真该网络>>p=[0.794;0.271];>>a=sim(net,p);>>ac=vec2ind(a)三、实验结果通过仿真计算得出时刻1属于状态1,时刻2属于状态3,时刻3属于状态4.各时刻对应的仿真状态图如下。

实验报告人工神经网络实验报告人工神经网络实验原理:利用线性回归和神经网络建模技术分析预测。
实验题目:利用给出的葡萄酒数据集,解释获得的分析结论。
library(plspm); data(wines); wines实验要求:1、探索认识意大利葡萄酒数据集,对葡萄酒数据预处理,将其随机划分为训练集和测试集,然后创建一个线性回归模型;2、利用neuralnet包拟合神经网络模型;3、评估两个模型的优劣,如果都不理想,提出你的改进思路。
分析报告:1、线性回归模型> rm(list=ls())> gc()used (Mb) gc trigger (Mb) max used (Mb)Ncells 250340 13.4 608394 32.5 408712 21.9Vcells 498334 3.9 8388608 64.0 1606736 12.3>library(plspm)>data(wines)>wines[c(1:5),]class alcohol malic.acid ash alcalinity magnesium phenols flavanoids1 1 14.23 1.71 2.43 15.6 127 2.80 3.062 1 13.20 1.78 2.14 11.2 100 2.65 2.763 1 13.16 2.36 2.67 18.6 101 2.80 3.244 1 14.37 1.95 2.50 16.8 113 3.85 3.495 1 13.24 2.59 2.87 21.0 118 2.80 2.69nofla.phen proantho col.intens hue diluted proline1 0.28 2.29 5.64 1.04 3.92 10652 0.26 1.28 4.38 1.05 3.40 10503 0.30 2.81 5.68 1.03 3.17 11854 0.24 2.18 7.80 0.86 3.45 14805 0.39 1.82 4.32 1.04 2.93 735> data <- wines> summary(wines)class alcohol malic.acid ashMin. :1.000 Min. :11.03 Min. :0.740 Min. :1.3601st Qu.:1.000 1st Qu.:12.36 1st Qu.:1.603 1st Qu.:2.210Median :2.000 Median :13.05 Median :1.865 Median :2.360 Mean :1.938 Mean :13.00 Mean :2.336 Mean :2.3673rd Qu.:3.000 3rd Qu.:13.68 3rd Qu.:3.083 3rd Qu.:2.558Max. :3.000 Max. :14.83 Max. :5.800 Max. :3.230alcalinity magnesium phenols flavanoids Min. :10.60 Min. : 70.00 Min. :0.980 Min. :0.340 1st Qu.:17.20 1st Qu.: 88.00 1st Qu.:1.742 1st Qu.:1.205 Median :19.50 Median : 98.00 Median :2.355 Median :2.135 Mean :19.49 Mean : 99.74 Mean :2.295 Mean :2.029 3rd Qu.:21.50 3rd Qu.:107.00 3rd Qu.:2.800 3rd Qu.:2.875 Max. :30.00 Max. :162.00 Max. :3.880 Max. :5.080 nofla.phen proantho col.intens hue Min. :0.1300 Min. :0.410 Min. : 1.280 Min. :0.4800 1st Qu.:0.2700 1st Qu.:1.250 1st Qu.: 3.220 1st Qu.:0.7825 Median :0.3400 Median :1.555 Median : 4.690 Median :0.9650 Mean :0.3619 Mean :1.591 Mean : 5.058 Mean :0.9574 3rd Qu.:0.4375 3rd Qu.:1.950 3rd Qu.: 6.200 3rd Qu.:1.1200 Max. :0.6600 Max. :3.580 Max. :13.000 Max. :1.7100 diluted prolineMin. :1.270 Min. : 278.01st Qu.:1.938 1st Qu.: 500.5Median :2.780 Median : 673.5Mean :2.612 Mean : 746.93rd Qu.:3.170 3rd Qu.: 985.0Max. :4.000 Max. :1680.0Num Variable Description 解释1 class Type of wine 葡萄酒的种类2 alcohol Alcohol 醇3 malic.acid Malic acid 苹果酸4 ash Ash 灰5 alcalinity Alcalinity 碱度6 magnesium Magnesium 镁7 phenols Total phenols 酚类8 flavanoids Flavanoids 黄酮9 nofla.phen Nonflavanoid phenols 非黄烷类酚类10 proantho Proanthocyanins 花青素11 col.intens Color intensity 颜色强度12 hue Hue 色调13 diluted OD280/OD315 of diluted wines 稀释的葡萄酒14 proline Proline 脯氨酸> apply(data,2,function(x) sum(is.na(x)))class alcohol malic.acid ash alcalinity magnesium phenols 0 0 0 0 0 0 0 flavanoids nofla.phen proantho col.intens hue diluted proline 0 0 0 0 0 0 0> dim(wines)[1] 178 14> set.seed(2)> test=sample(1:nrow(wines),100)> wines.train<-wines[-test,]> wines.test<-wines[test,]> dim(wines.train);dim(wines.test)[1] 78 14[1] 100 14> lm.fit <- glm(alcohol~., data=wines.train)> summary(lm.fit)Call:glm(formula = alcohol ~ ., data = wines.train)Deviance Residuals:Min 1Q Median 3Q Max-0.98017 -0.31067 -0.00405 0.36184 1.23885Coefficients:Estimate Std. Error t value Pr(>|t|)(Intercept) 13.0661361 1.2664910 10.317 3.04e-15 ***class -0.4043994 0.2389115 -1.693 0.09538 .malic.acid 0.1612962 0.0730559 2.208 0.03085 *ash 0.2621448 0.3669235 0.714 0.47755alcalinity -0.0591380 0.0328684 -1.799 0.07670 .magnesium 0.0003567 0.0052733 0.068 0.94628phenols 0.1719659 0.2078450 0.827 0.41110flavanoids -0.1780915 0.1815817 -0.981 0.33039nofla.phen -0.4623220 0.7409499 -0.624 0.53487proantho -0.2402948 0.1449535 -1.658 0.10226col.intens 0.1580059 0.0447835 3.528 0.00078 ***hue 0.1226260 0.4205420 0.292 0.77154diluted -0.0889085 0.1967579 -0.452 0.65289proline 0.0008112 0.0003943 2.058 0.04371 *---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1(Dispersion parameter for gaussian family taken to be0.2968956)Null deviance: 57.473 on 77 degrees of freedomResidual deviance: 19.001 on 64 degrees of freedomAIC: 141.2Number of Fisher Scoring iterations: 2> pr.lm <- predict(lm.fit,wines.test)> MSE.lm <- sum((pr.lm - wines.test$alcohol)^2)/nrow(wines.test)> print(MSE.lm)[1] 0.30436252、神经网络模型> maxs <- apply(wines, 2, max)> mins <- apply(wines, 2, min)> scaled <- as.data.frame(scale(wines, center = mins, scale = maxs - mins))> index <- sample(1:nrow(wines),round(0.75*nrow(wines))) > train_ <- scaled[index,]> test_ <- scaled[index,]> library(neuralnet)> n <- names(train_)> f <- as.formula(paste("alcohol~", paste(n[!n %in% "alcohol"], collapse = " + ")))> nn <- neuralnet(f,data=train_,hidden=c(5,3),linear.output=T) > plot(nn)>pr.nn <- compute(nn,test_[,1:13])>pr.nn__<-pr.nn$net.result*(max(test_$alcohol)-min(test_$alcohol))+mi n(test_$alcohol)>test.r1<-(test_$alcohol)*(max(test_$alcohol)-min(test_$alcohol))+min (test_$alcohol)> MSE.nn1 <- sum((test.r1 - pr.nn__)^2)/nrow(test_)> print(paste(MSE.lm,MSE.nn1))[1] "0.304362456679839 0.14726865189892"3、模型修正>par(mfrow=c(1,2))>plot(test_$alcohol,pr.nn__,col='red',main='Real vs predicted NN',pch=18,cex=0.7)>abline(0,1,lwd=2)>legend('bottomright',legend='NN',pch=18,col='red',bty='n')>plot(wines.test$alcohol,pr.lm,col='blue',main='Real vs predictedlm',pch=18, cex=0.7) >abline(0,1,lwd=2)>legend('bottomright',legend='LM',pch=18,col='blue',bty='n', cex=0.7)0.00.40.80.00.20.40.60.81.01.2Real vs predicted NN test_$alcohol p r .n n _ _11.512.513.511.512.012.513.013.514.014.5Real vs predicted lmwines.test$alcoholp r .lm> par(mfrow=c(1,1))> plot(test_$alcohol,pr.nn__,col='red',main='Real vs predicted NN',pch=18,cex=0.7)>points(wines.test$alcohol,pr.lm,col='blue',pch=18,cex=0.7) > abline(0,1,lwd=2)>legend('bottomright',legend=c('NN','LM'),pch=18,col=c('r ed','blue'))> library(boot)> set.seed(200)> lm.fit <- glm(alcohol~.,data=data)> cv.glm(data,lm.fit,K=10)$delta[1][1] 0.3058061679>set.seed(450)>cv.error <- NULL>k <- 10>library(plyr)>pbar <- create_progress_bar('text')>pbar$init(k)>for(i in 1:k){index <- sample(1:nrow(data),round(0.9*nrow(data)))train.cv <- scaled[index,]test.cv <- scaled[-index,]nn <- neuralnet(f,data=train.cv,hidden=c(5,2),linear.output=T) pr.nn <- compute(nn,test.cv[,1:13])pr.nn__<-pr.nn$net.result*(max(test_$alcohol)-min(test_$alcohol))+min (test_$alcohol)test.cv.r <- (test.cv$alcohol)*(max(test.cv$alcohol)-min(test.cv$alcohol))+min(tes t.cv$alcohol)cv.error[i] <- sum((test.cv.r - pr.nn__)^2)/nrow(test.cv)pbar$step()}> mean(cv.error)[1] 0.06900470043> cv.error[1] 0.0791******* 0.10556665990 0.05904083258 0.0714******* 0.0992******* [6] 0.03239406600 0.048074664370.0999******* 0.0355******* 0.0596*******> par(mfrow=c(1,1))> par(mfrow=c(1,1))> boxplot(cv.error,xlab='MSE CV',col='cyan',+ border='blue',names='CV error (MSE)',+ main='CV error (MSE) for NN',horizontal=TRUE)0.040.060.080.10MSE CV> cv.error[i] [1] 0.0596547757。
研究生专业课程考试答题册学号姓名考试课程人工神经网络及其应用考试日期西北工业大学研究生院基于AlexNet的图像分类近几年,随着深度学习的崛起,越来越多的科研工作者开始使用深度学习的方法进行实验,并且取得了非常不错的成绩。
目前,深度学习算法主要应用在语音识别、图像识别以及自然语言处理领域。
本文根据所给的训练样本,选取深度学习方法进行图像分类。
1.图像分类1.1传统方法图像分类是机器视觉中的一个基本问题。
针对这一问题的模型框架主要包括图像预处理、图像特征提取、分类器设计三个步骤。
其中特征提取是生成图像表示的过程,也是图像分类中最重要的一步,鲁棒的特征表示是提高分类正确率的关键。
关于图像表示,相关学者提出了许多特征表示法,例如基于部位模型[1]、BOW[2]模型等等,在这些模型当中,BOW模型的鲁棒性最强,具有尺度不变性、平移不变性以及旋转不变性等优点,使其在实际问题中得到广泛应用,包括图像分类、图像标注、图像检索以及视频事件检索等,并且在Caltechl01等库中取得很好的分类效果。
1.2卷积神经网络模型在传统的图像分类方法中,首先对原始图片进行预处理,然后根据BOW最后选择合适的分类器进行分类,如图1.1所示。
然而,在传统方法中,特征都是人为设计的,包括底层特征的选择、码本长度的设置、编码策略的设计、池化方法的选择以及空间金字塔区域的划分形式等,这些人为因素对特征产生很大的影响,目前没有理论上的公式给出最优的设计因素组合,所以只能从经验上进行判别和设计,降低了特征的表达能力和可靠性,并且针对不同的数据库,需要重新设计以上因素,导致传统特征模型的通用性不强,关于特征的表达能力也未能给出理论上的估计。
图1.1传统分类与卷积神经网络分类模型如图1.1所示,在卷积神经网络中,直接输入原始图像,在网络的最后一层加上分类器,根据分类器的预测结果使用反馈传播(Back Propagation,BP)算法更新权值参数,最后得到的网络模型能够自动学习给定数据集的样本特征。
所以,与传统图像分类模型不同,CNN是一个特征学习模型,从原始图像到类别预测整个过程都是自动训练和学习的过程,不需要人为参与和设计,具有很强的鲁棒性和表达能力,在图像分类中的性能远远超过SIFT和HOG等传统特征。
在模式分类中,为了获得非线性的、自适应的、自组织的识别系统,美国心理学家麦卡洛克(W.McCulloch)和数学家皮茨(W.Pitts)最早使用数学模型对人脑神经系统中的神经元建模,提出神经网络数学模型的概念;随后,美国计算机科学家罗森布拉特(F.Rosenblatt)最早于1957年提出感知机模型,使用阈值激活函数,并在神经网络数学模型中引入学习和训练的概念和功能,通过连续调节和更新网络的权值参数来学习网络模型;到1959年,美国的威德罗(B.Widrow)和霍夫(M.Hom)提出自适应线性元件,对每个神经元使用线性激活函数,并采用W-H 学习规则训练权值,从而得到比感知机更低的测试误差以及更快的收敛速度;到了1986年,美国的心理学家麦克利兰(McClelland)和人工智能专家鲁梅尔哈特(Rumelhart)提出了经典的反馈传播神经网络模型,即BP神经网络模型,使用误差反传和梯度下降法逐层更新网络的权值参数,从而逼近任意的非线性可微函数,实现模式识别、函数逼近等功能。
后来,在人工神经网络的实践应用中,接近80%到90%的研究工作均采用BP网络模型或者它的变化形式[3]。
尽管选择非线性激活函数以及多层前向网络可以学习复杂的、高度非线性的模型,实现模式识别或分类等功能。
但是传统人工神经网络仍然存在很多局限性:第一,参数太多,传统人工神经网络的逐层连接方式均为全连接,每一层都涉及到大量的矩阵乘积运算,参数个数与节点数呈倍数增长,导致传统神经网络模型的参数过多,容易引起过拟合问题,为了防止过拟合,传统神经网络模型的层数一般设置的很少,限制了网络深度的增长和网络学习能力的增强;第二,局部极小值问题突出,训练传统人工神经网络模型的方法中,并没有提出良好的参数初始化策略,导致网络收敛到局部极小值的问题比较突出;第三,训练过程缓慢,BP网络的隐含层通常使用sigmoid或者tanh等激活函数,这些非线性激活函数存在非常广泛的饱和区域,当神经元输入值落于函数的饱和区时,得到的函数导数值非常小,使得训练过程中,根据梯度下降法更新的网络权值基本不变,从而出现神经元“麻痹”的现象,导致训练过程非常缓慢针对传统神经网络存在的问题,在图像分类中,引入卷积神经网络模型。
与统神经网络模型相同,CNN模型是由多个网络层以有向无环图形式连接而成的网络结构,针对传统人工神经网络存在的缺点,CNN模型在结构和训练方法上做出如下改进:第一,通过权值共享和局部感受野连接来减少参数个数。
为了减少参数个数,CNN模型的大部分网络层(通常是网络前面的层)采用卷积层结构,而不是全连接结构,卷积层的每个节点仅与前一层的部分神经元连接,并且属于同一通道的所有神经元共享一个卷积核参数,从而大幅度减少网络的参数个数。
第二,增加网络的层数,从而增强网络的学习能力。
卷积神经网络通过权值共享大大减少了参数个数,所以在CNN中可以增加网络层数从而增加模型的深度,目前常用的传统人工神经网络模型大多包含3个网络层,而常用的卷积神经网络结构则大多包含8个以上的网络层,使用较深的结构可以获得更好的非线性特征以及更好的表达能力。
第三,使用更好的权值初始化策略和激活函数,提高训练速度和精度。
文献[4]提出高斯权值初始化策略,提供较好的初始权值,使得网络收敛于全局最优点或者更好的局部极值点;此外,Krizhevsky等人在CNN模型中引入RELU激活函数,从而获得比sigmoid、tanh等非线性激活函数更快的收敛速度和更低的误差,避免传统BP神经网络中的麻痹现象。
第四,通过dropout、逐层学习技术来避免过拟合以及梯度弥散问题。
在训练CNN模型的过程中,随机选择全连接层的部分神经元,将激活值设置为0,从而加快训练速度,避免产生过拟合问题;此外,对于深度网络的训练,首先使用大规模未标记数据对每一层参数进行无监督逐层学习,再利用标记数据对整个网络进行微调,从而学习更复杂的、深层的网络结构,避免梯度弥散问题,获得更加非线性的、鲁棒的特征和更好的网络表达能力。
目前,大部分文献都是根据以上各方面的改进,构建和训练多层的CNN模型实现图像的分类研究。
其中,最常使用的CNN网络结构大体分为两类,分别为Zeiler类型与Inception类型网络。
最典型的Zeiler类网络为AlexNet[4],而最典型的Inception类网络则为GoogLeNet[5]。
由于Alexnet网络参数较少,且分类效果好,因此,文本选择AlexNet这个网络来做图像分类,下文将详细分别AlexNet网络的结构和特点。
2.Alexnet网络介绍AlexNet是由Krizhevsky等人提出的Zeiler类型卷积神经网络模型,关于CNN模型在图像分类、图像分割、目标检测、图像检索等任务中的应用,大部分研究工作都使用AlexNet或者是它的变化形式,例如,VGG[6]网络是在AlexNet 网络上固定卷积核大小,增加层数得到的CNN模型;RCNN[7]是在图像子区域中使用AlexNet得到的网络模型;SPPNet[4]是在最后一个卷积层后增加金字塔网络层得到的网络模型。
AlexNet网络结构包含8个网络层,分别为5个卷积层和3个全连接层。
每个卷积层依次包含卷积运算、逐元素RELU运算、标准化运算以及最大池化运算。
在三个全连接层中,前两个全连接层的神经元个数为4096,通常对这两层使用dropout操作。
最后一个全连接层的神经元个数与目标数据库的类别数一致。
在AlexNet中,使用的损失函数通常是Softmax负对数损失函数,根据BP算法来训练网络的参数,首先初始化网络参数,在每一次迭代中,根据网络的预测值计算损失函数值,再根据损失值和梯度下降法算法逐层更新滤波器的值,所以获取良好的网络初始化权值是加快网络收敛速度和减少训练误差的关键。
具体的网络结构如图2.1所示,输入图片大小为227×227×3,包含8层结构,前五层为卷积层,分别为蓝色矩形框中的Convl到Conv5,其中Convl(11x11+4s)表示该层的滤波器大小为11 X 11,滑动步长为4像素或神经元,下方的数字表示该层包含的通道数目,后面三个绿色的矩形框表示全连接层,最后一层的L表示目标数据库包含己个类别。
该网络模型在ImageNet-1K测试集上的top-5平均分类错误率为15.3%,远远低于传统模型的26.2%。
图2.1AlexNet结构示意图AlexNet网络结构有6000万个参数,要学习如此多的参数而不带相当大的过拟合,这就需要非常多的样本数据。
减少图像数据过拟合最简单最常用的方法,是人为地扩大数据集。
AlexNet使用数据增强的两种不同形式,这两种形式都允许转换图像用很少的计算量从原始图像中产生,所以转换图像不需要存储在磁盘上。
数据增强的第一种形式由生成图像转化和水平镜像组成。
AlexNet网络从256×256的图像中提取随机的224×224的碎片(还有它们的水平镜像),并在这些提取的碎片上训练网络。
这使得网络训练集规模扩大了2048倍,但是由此产生的训练样例高度地相互依赖。
在测试时,该网络通过提取五个224×224的碎片(四个边角碎片和中心碎片)连同它们的水平镜像(因此总共是十个碎片)做出了预测,并在这十个碎片上来平均该网络的softmax层做出的预测。
数据增强的第二种形式包含改变训练图像中RGB通道的强度。
具体来说,ALexNet遍及训练集的RGB像素值集合中执行PCA。
对于每个训练图像,成倍增加已有主成分,比例大小为对应特征值乘以一个从均值为0,标准差为0.1的高斯分布中提取的随机变量。
这样一来,对于每个RGB图像像素,通过增加其中与分别是RGB像素值的3×3协方差矩阵的第i个特征向量与特征值,是前面提到的随机变量。
每个对于特定训练图像的全部像素只提取一次,直到那个图像再次被用于训练,在那时它被重新提取。
这个方案大致抓住了自然图像的一个重要属性,即,光照强度与颜色是变化的,而对象识别是不变的。
该方案将top-1误差率减少了1%以上。
3.实验本次实验环境为i7处理器,CPU为GTX1080,ubuntu14.04.样本共有13501张图片,包含10个大类,共计100个小类的生物图片。
首先对数据集进行划分,将13501张照片按分为训练集,验证集,数据集三部分,训练集为8542张,验证集为950张,测试集4009张。