化探数理统计
- 格式:doc
- 大小:100.00 KB
- 文档页数:4



数理统计方法数理统计方法是一门研究数据收集、整理、分析和解释的学科,它在各个领域都有着广泛的应用。
无论是在科学研究、经济分析还是社会调查中,数理统计方法都扮演着至关重要的角色。
本文将介绍数理统计方法的基本概念、常用技术和应用领域,希望能够帮助读者更好地理解和运用数理统计方法。
首先,让我们来了解一下数理统计方法的基本概念。
数理统计是通过对已知数据的分析和推断,来对未知总体的特征进行估计和推断的一种方法。
它包括描述统计和推断统计两个方面。
描述统计是通过对数据的整理、汇总和图表展示来描述数据的基本特征,如均值、方差、分布形状等;而推断统计则是通过对样本数据的分析来对总体特征进行推断,如参数估计、假设检验等。
在数理统计方法中,常用的技术包括概率论、数理统计学、抽样调查、实验设计等。
概率论是数理统计方法的基础,它研究随机现象的规律性,为后续的统计推断提供了理论基础。
数理统计学则是通过对数据的分析和推断来对总体特征进行估计和推断,包括参数估计、假设检验、方差分析等。
抽样调查和实验设计则是在实际应用中常用的数据收集方法,通过对样本数据的分析来对总体特征进行推断。
数理统计方法在各个领域都有着广泛的应用。
在自然科学领域,数理统计方法常用于实验数据的分析和解释,如物理实验数据的处理、生物统计学中的生物数据分析等。
在社会科学领域,数理统计方法常用于社会调查数据的分析和解释,如经济学中的经济数据分析、教育学中的教育调查数据分析等。
在工程技术领域,数理统计方法常用于工程实验数据的分析和解释,如质量控制中的质量数据分析、可靠性分析中的可靠性数据分析等。
总之,数理统计方法是一门十分重要的学科,它在各个领域都有着广泛的应用。
通过对数据的收集、整理、分析和解释,数理统计方法能够帮助我们更好地理解和解释数据,为科学研究、经济分析和社会调查提供有力的支持。
希望本文能够帮助读者更好地理解和运用数理统计方法,提高数据分析能力,为各个领域的发展做出贡献。

化探异常圈定、分类、评价及查证目录●1/5万地球化学普查 (1)1.异常圈定 (1)1.1异常下限的确定方法 (1)1.2异常浓度分级(带)方法 (3)2.化探异常分类 (3)2.1 找矿意义分类 (3)2.2按采样介质分类 (4)2.3按引起异常的地质因素划分 (4)2.4按异常范围与强度(浓度)划分 (4)3.化探异常优选及评价 (5)3.1化探异常的特点 (5)3.2异常优选与评价准则 (5)3.3 化探异常本身的评价参数 (6)3.4 化探异常的初步筛选 (8)3.5优选化探异常的方法技术 (9)3.6非找矿目的化探异常评价 (10)3.7异常评价和查证工作程序 (10)3.8异常评价与找矿效果 (12)4.化探异常查证 (12)4.1化探异常查证的目的 (12)4.2化探异常查证方法 (13)4.3化探异常查证须配快速分析 (13)●土壤地球化学测量 (13)1.1原始资料 (13)1.2成果报告 (14)2.资料的检查与验收 (14)3.资料整理的基本步骤和内容 (14)4.异常的解释推断 (14)附录F 土壤测量地球化学异常登记卡 (16)●1/5万地球化学普查1.异常圈定1.1异常下限的确定方法地质情况较简单,元素呈单峰分布,或者可以看出分布中有一个单一的背景全域和一个异常全域,就可以在全测区内(剔除高值点)计算出一个统一的背景平均值及异常下限,单峰分布时其计算式为:对数背景平均值:∑∑=ffXX L 对数标准离差:1)(22--=∑∑n nfX fX L L λ对数异常下限:λ2+=L L X T∑=57f ∑=9.83L fX ∑=53.1252L fX ∑=21.7039)(2L fX 对数背景平均值: g g f fXX L /lg 4719.1579.83μ===∑∑其反对数,即背景平均值 g g X /64.29μ= 对数标准离差:)/(lg 1909.0565721.703953.1251)(22g g n n fX fX L L μλ=-=--=∑∑ 对数异常下限: )/(40.71)/(lg 8537.11909.024719.12g g g g X T L L μμλ==⨯+=+=当1:5万化探普查区部署在异常区或矿区外围时,往往在频率分布中有一个单一的背景全域和一个异常全域交迭而出现双峰,或频率分布曲线呈不对称的正向偏斜,此时一般可利用众值m 。



立志当早,存高远项目研判的工作程序分为三大阶段六个步骤项目研判要考虑的因素有三个:矿业权的唯一性和合法性、工作地区的人为环境、矿业权地的资源情况。
项目研判分排查与初判、会诊与详判、终审与决策三大阶段和六个步骤。
排查与初判(投资的可能性研究)。
根据成矿地质条件和成矿地质特征的分析对找矿前景作出初步研判,即项目可能性决策。
这一阶段分两大步骤:——资料收集与基本分析。
收集工作区地理、交通、水电、人文环境;区域矿权设置及本矿区矿权设置;矿区地质勘查历史及前人工作程度;1∶20 万矿产地质调查报告及矿产图、地质图;1∶5 万水系沉积物地球化学测量成果;各种比例尺地质填图等;基本分析区域矿床矿点分布规律,大地构造背景及构造演化,矿区构造地质特征,地层层序、岩性及所反映的成岩环境,岩浆活动、岩浆分异及演化,火山活动,岩石变质程度,热液蚀变,矿化地质特征,可能的矿床类型等。
确定项目是否能满足本企业的要求和发展。
这个过程需1~2 周。
——初次野外地质调研。
路线地质踏查,矿点检查,重点矿化带或蚀变带、铁帽编录和采样。
少量岩石地球化学和土壤地球化学剖面剖面(1∶2000),少量探槽或浅井揭露。
了解现有工作程度、工程布置情况、核实资料、考察矿化规模和强度,重点地段拣快取样化验,大体了解矿化强度和规模,确定矿床类型,确定是否有必要开展普判。
这个过程需时约1 周。
会诊与详判(投资的充分性、科学性研究)。
全面收集资料,根据资料综合和系统取样,对矿区矿化强度和规模作出评价,即为研判提供客观的、真实的、科学的依据。
详判是整个研判过程的最后一个阶段,是决定项目投资的关键。
主要目的如下:矿床类型或矿化类型的确定;形成大型、超大型矿床的充。

内蒙古扎赉特旗东芒合矿和哈拉街吐矿化探数据处理及图件编制方法1 化探数据质量评价的数据处理(分矿区)⑴统计重采样和重分析抽查样所占样品总数的比例比例 = (重采样和重分析抽查样数/工作样总数)100%⑵作出SSPS数据文件将重采样和重分析样分别作成SSPS数据文件。
文件中列出项目为:①重采抽查样重采样号元素含量相应的工作样号元素含量②重分析抽查样重分析样号元素含量相应的工作样号元素含量⑶计算各元素相对误差重采样和重分析抽查样相对误差均按RE(%) = |C1-C2|/0.5×(C1+C2)×100%计算。
C1为重采样或重分析抽查样的分析含量C2为重采样或重分析抽查样的相应的工作样的分析含量| |为绝对值RE(%)≤30%为合格,>30为超差(不合格);(Au:RE(%)≤50%为合格,>50为超差)⑷计算各元素的合格率η= (抽查样品中合格的样品数/抽查样品的总数)100%合格率(η)应>80%,即这批样品的分析结果是可信的。
⑸列表表示检查或分析质量结果表××化探重采样抽查各元素的合格率(%)Cu Pb Zn Cr Ni Co Sn V Ag Ti2 矿区地球化学特征研究的数据处理(以哈拉街吐为例)⑴作出SSPS数据文件作出下列SSPS数据文件:①文件1:整个矿区数据文件;②文件2:矿区地层数据文件;③文件3:矿区岩浆岩数据文件;④文件4 :下二叠统大石寨组(P1d)数据文件;⑤文件5 :下白垩统大磨拐河含煤组(K1d)数据文件;⑥文件6 :华力西晚期侵入岩数据文件;⑦文件7 :燕山期早期侵入岩数据文件;⑧文件8 :燕山期晚期侵入岩数据文件;⑨文件9:已知矿附近一定范围数据文件每一数据文件的内容项目包括:序号野外号 X坐标 Y坐标各元素的含量⑵整个矿区和各地质单元(各地层、各岩浆岩)样品各元素含量特征统计统计的参数包括:①元素含量平均值;②最大值;③最小值;④标准离差;⑤变化系数(标准离差/含量平均值);⑥浓度克拉克值(元素含量平均值/该元素的克拉克值)整个矿区和各地质单元统计结果含量平均值、最小值、最大值用表表示。
![化探数据处理原理及方法[精制材料]](https://uimg.taocdn.com/1a3a9520960590c69ec376b1.webp)

化学分析中的数理统计数理统计方法在现代化企业管理中是必不可少的有力工具。
同样数理统计方法在化学分析中也可得到广泛的应用。
下面就化学分析中经常遇到的一些问题谈谈数理统计方法的应用。
一、化学分析的测试及其误差。
我们知道化学分析测试的目的,是从欲研究对象中抽取部分样品进行测试,由测试结果来研究,推断对象的全体的性能。
但是在分析测试过程中,不可避免地会受到各种未知因素的影响而使测试结果参差不齐。
亦即我们常称之为误差。
这种误差,不仅由于某些偶然因素作用出现单次测定围绕多次测定平均值在一定范围内波动,而且也会由于某些恒定的因素的作用使多次测定平均值与真值之间产生差异。
因此,判断误差性质是件特别慎重的事情。
要作到这一点,除必需具备必要的理论知识和实践经验外,正确的应用数理统计方法则是完成这一任务的有力工具。
就误差的性质和产生的原因,大体可分为:偶然误差(随机误差)和系统误差两大类。
偶然误差是指在一组测定值中,由于某种因素的偶然变化而引起的单次测定值对多次测定平均值的偏离,它决定了测试结果的精度。
常用标准差来表征。
其特点是:当测定次数足够多时出现数值相等,符号相反的偏差概率近似相等。
引起偶然误差的因素是无法控制的。
但通过增加测定次数可以减少误差。
系统误差是指在一定试验条件下,由于某个固定因素的作用,使测试结果对真值按一个方向偏离。
它决定了测试结果的准确度,可用绝对误差或相对误差来表示。
系统误差可按其作用规律对它进行校正或设法消除。
而增加测定次数不能减少系统误差。
显然,对于一个理想的测试结果,既要求精度好,又要求准确度好。
二、偶然误差的分布特征。
如前所述,引起偶然误差的因素是无法控制的,因此,在化学分析中即使在严格控制的试验条件下,对一个样品多次测定其测定结果并非完全相同,那么误差是否无规可循?我们可以通过下例来分析:例:在相同条件下对某物料的某种成分含量测定50 次,得到如下一组数据:这些数据表面看来杂乱无章,然而,如果我们将这些数据按大小排列起来,也有一定规律可循,即全部测定值有明显的集中趋势,大多数测定值集中在平均值60.05 左右。
化探-异常下限-计算方法大全及详解谭亲平地球化学研究所目录1.传统方法,均值加标准差 (1)2.直方图解法 (2)3.概率格纸图解法.34.多重分形法。
(6)5.85%累计频率法。
(7)小结 (8)传统方法,均值加标准差在excel中用过函数,求均值,求标准差,先对数据中的极大/极小值进行剔除,大于/小于三倍标准差的剔除掉,直到无剔除点。
然后用均值加2倍标准差求异常下限。
图,D列中的函数,E列中的结果。
图一中的化探数据的异常下限114.86.。
直方图解法图2首先,做频率直方图,(图1的数据是某化探区数据)含量频率分布图上呈现双峰曲线,左边是背景部分,右边是异常部分,双峰间谷底处(0.7)为异常下限。
求真值得5.所以,异常下限位5。
图2另一个化探区的数据,是单峰曲线,在频率极大值的0.6倍处画一条平行直线,与曲线一侧相交,其横坐标长度即为σ。
用Ca=Co+2*σ=0.16+2*0.665=1.49,求得为真值为31。
概率格纸图解法.图3,图3是概率格纸。
发现纵坐标(累计频率)是不均匀的。
把样本值小于或等于某个样本ni的数据频率累加,即得到小于或等于ni的累积频率。
概率格纸用excel能轻松的做出来。
制造方法如下。
图4.图4显示了概率格纸的制造过程。
原理就是把标准正态分布曲线投影到纵坐标上。
首先确定纵坐标数值,如B列,0.1、1、5、10、20、30、40、50、60、70、80、90、95、99、99.9.。
如果想要纵坐标线密一点,也可以插入更多的数。
然后在C列中用NORMSINV 函数,求对应频率的分位数(如果把标准正态分布,正着放,分位数就是横坐标)。
这时的原点(0)在50%处,我们想要原点在0处,那么把C列的数统一加-03.090232(C5),---(处理化探数据的时候,加的也是相同的数)。
即输入公式”D5” =C5-$C$5…。
E列为x 值,根据实际化探数据,设定最大和最小值。
我们这里随便设为0、25。
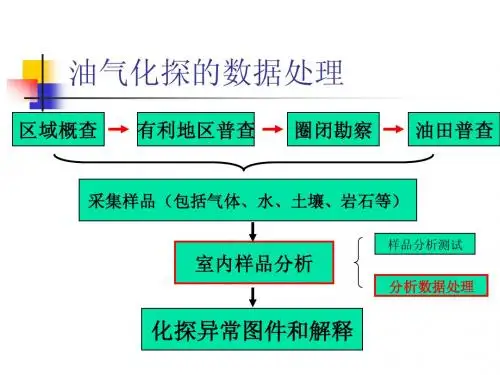
油气地球化学勘探的基本原理及典型方法油气化探主要是通过探测到的各种地球化学异常来揭示地下油气藏的存在。
如何从地表检测出各种烃类和烃类蚀变产物、从检测到的各项组分中提取深部油气信息以及尽可能排除各种地表因素的干扰一直是油气化探的主要发展方向。
目前背景和异常的识别主要是通过各种数理统计的方法,如采用区域均值加减几倍方差作为异常的下限等来确定异常的。
这些方法在小比例尺低精度油气化探的概查和普查阶段(背景较为统一)是可行的,然而在大比例尺高精度的详查和精查阶段(存在较大背景差异),异常和背景的区分需要更为科学的标准和方法。
改进应用的数学模型来确定异常是一种思路,另外通过有机地球化学方法,利用烃类的组成和同位素特征从成因方面对背景和异常进行精细判识是另一个发展思路。
经过多年的发展,人们在检测技术上取得了较大的发展,为地表烃类和烃类蚀变产物的研究奠定了基础。
地表烃类的地球化学分析方法已有许多种,如顶空气、酸解烃、游离烃、吸附烃,吸着烃、溶解烃以及热释烃等,这些方法有些已相对成熟,建立了比较完善的分析实验流程并开发了相应的仪器设备。
由于不同阶段、不同成因产生的烃类不仅组成上存在一定的差异(如地表生物地球化学作用产生的烃类以甲烷含量为主,且明显贫13C;深部油气中重烃含量相对较多,且相对富集13C),而且进入土壤先后次序以及存在的烃类-水-土壤相互作用的不同,都为从油气化探异常中提取深部油气信息提供了理论基础和研究对象。
如包裹在土壤颗粒内部的吸着烃以早期形成的烃类为主;存在于颗粒之间的游离烃以晚期渗逸的烃类和地表形成的烃类为主。
然而由于已有的一些地球化学分析方法在测定对象上存在明显的交叉混合现象,妨碍了许多关键信息的提取,从而影响了成因方面的研究。
如酸解烃实际上包括了土壤中颗粒物表面和内部严格意义上的吸附烃和吸着烃,这样得到的酸解烃具有较高的信噪比;活性碳吸附烃法分析测定的实际上是土壤中的游离烃,即包括了地下油气来源的烃类也包含了由地表生物化学作用产生的烃类,因此游离烃测定的稳定性和重现性较差,易遭受气候、土壤含水饱和度以及地表各种污染(包括人为和表生地球化学作用两方面)的影响;顶空气缺点是解吸的烃类量很小;热释烃也包括了吸附烃和部分吸着烃,并且热释温度不易控制,温度低了,烃类释放不完全,温度高了,可能产生裂解,故热释烃指标也不够稳定,应用效果不甚理想。
化探数据处理方法对比研究作者:张明宇来源:《环球市场》2017年第12期摘要:众所周知,矿产资源是人类生产和生活的必需原料,是人类赖以生存和发展的物质基础,是经济社会可持续发展的重要物质保证。
地球化学勘查是区域矿产地质调查中快速发现地球化学异常、确定成矿远景和找矿靶区最有效的手段之一,其基本原理是通过研究成矿元素和相关元素在不同地质体中的含量和分布,发现异常,解释和评价异常,确定找矿远景区和找矿靶区。
其中,元素地球化学异常下限的确定是地球化学勘查的基本研究内容,同时,也是地球化学勘查的难点和热点问题。
关键词:化探法;数据处理;方法比较勘查地球化学是通过地质体中元素分布的研究,发现异常,解释评价异常,进而圈定找矿远景区和找矿靶区的一种找矿方法。
其中,元素异常下限的确定是勘查地球化学的基本内容,同时也是勘查地球化学的关键问题。
本文以新疆地区为例进行研究。
1 地球化学样品采集与测试分析1.1 采样介质与测网布置勘查地球化学采样介质多种多样,有岩石、土壤、水系沉积物、气体、生物等多种测量对象。
新疆地区属干旱荒漠的地球化学景观,干旱荒漠地区地表物质受到了盐类、卤化物风化壳以及风成沙的严重干扰,形成类型复杂性质各异的地球化学障,为排除这一障碍,开发了岩屑地球化学测量。
此类景观采取粗粒级物质,即-5~+20目(-5.13~+0.96mm),该方法为岩屑区域地球化学勘查。
研究区为较典型的干旱荒漠景观,因此针对阿克巴斯陶、野马井、克尔巴依以及协别克斯套4幅面积近1450km2区域采取岩屑勘查地球化学方法。
1:20万岩屑区域勘查地球化学设计的采样密度为每平方公里2个样[80],属低密度地球化学测量,适用于小比例尺区域地球化学异常。
由于研究区按1:5万图幅进行取样,故应加大取样密度,设计为线距500m×点距250m网度布样。
全区布设样点11929个,由于某些地段经后期局部加密,实际共取样12011个。
1.2 样品采集与分析使用1:5万地形图为工作手图,用地形图、罗盘及GPS定位仪进行综合定点。
数理统计方法数理统计是一门研究数据收集、分析和解释的学科,它在各个领域都有着广泛的应用。
在现代科学和工程领域,数理统计方法被广泛应用于数据分析、预测和决策等方面。
本文将介绍数理统计方法的基本概念和常用技术,帮助读者更好地理解和应用数理统计。
首先,我们来介绍一些基本概念。
数理统计主要包括描述统计和推断统计两个方面。
描述统计是指通过图表、平均数、标准差等指标来描述数据的分布和特征,它能够帮助我们直观地了解数据的情况。
而推断统计则是利用样本数据对总体参数进行估计和假设检验,从而进行科学的推断和决策。
这两个方面相辅相成,是数理统计的基础。
在数理统计方法中,常用的技术包括概率分布、参数估计、假设检验、方差分析等。
概率分布是描述随机变量取值的规律,常见的概率分布包括正态分布、均匀分布、泊松分布等。
参数估计是利用样本数据对总体参数进行估计,常用的方法包括最大似然估计、贝叶斯估计等。
假设检验是用来检验总体参数的假设是否成立,通过设定显著性水平来进行判断。
方差分析是用来比较多个总体均值是否相等的方法,它在实验设计和数据分析中有着重要的应用。
除了上述基本技术外,数理统计方法还涉及到数据的收集和整理、模型的建立和评价等内容。
数据的收集和整理是数理统计的第一步,它需要注意样本的代表性和数据的准确性。
模型的建立和评价则是数理统计的核心内容,它需要根据实际问题选择合适的模型,并对模型进行检验和评价,以保证模型的有效性和可靠性。
在实际应用中,数理统计方法常常与计算机技术相结合,利用计算机软件进行数据分析和模型建立。
例如,R语言、Python等编程语言都提供了丰富的数理统计工具包,可以帮助研究人员快速高效地进行数据分析和建模工作。
同时,大数据和人工智能的发展也为数理统计方法的应用提供了更广阔的空间,例如在金融、医疗、市场营销等领域都有着重要的应用价值。
总之,数理统计方法是一门重要的学科,它在现代科学和工程领域有着广泛的应用。
通过本文的介绍,相信读者对数理统计方法有了更深入的了解,希望能够帮助读者更好地应用数理统计方法解决实际问题。
化探单元素异常统计内容1、异常ID ID2、样品个数 N3、异常面积 S4、样品最大值 Max5、样品最小值 Min6、异常下限 T7、算术平均值 nXiX n∑=18、几何平均值 ∑=ng Xi n X 1log 19、标准离差 1)X X(n1i 2__0--∑=n S i=10、异常衬度 TX A c =11、异常规模 ()T X S A d -⨯= 12、异常NAP 值 S A NAP c ⨯=浓集克拉克值(C)计算公式: 某元素的克拉克值XC =变化系数(Cv)计算公式: XS Cv o=致矿系数(Z)计算公式:Z =Cv(全区)+10×Cv(剔高值后)+100×高值比例+C ,高值是大于3倍的标准离差。
化探背景分析 中位数:505050)50(f F H X Me -+=偏度:24)(1)(13231nX X f n X X f nR i i ii ∙⎪⎪⎭⎫ ⎝⎛--=∑∑ 峰度:963)(1)(14242n X X f n X X f nR i i i i ∙⎪⎪⎪⎪⎪⎪⎭⎫⎝⎛-⎪⎪⎭⎫ ⎝⎛--=∑∑正态检验: ∑∙-=ifx F x F |)()(|max 1λXi :组中值或含量值;f i :Xi 所对应的频数;H :组距;X50:包括累计频率50%在内的所在组的组下限;F 50:累计频率50%所在组之前的累计频率;f 50:包括累计频率50%所在组的组频率;F(X):为经验累计频率;F 1(X):为理论累计频率。
R 型聚类分析iiij ij S X X X -='其中:∑==nj ij X n X 11;1)(12--=∑=n X (XS nj i iji∑∑∑===-⋅---=⋅=ni ni k kij jik kini j jikkjj jk jk X (X X (X X (X X (XS S S r 11221)())()(式中:r kj 为第j 个变量和第k 个变量的相关系数;X ji 为第j 个变量第i 个样品的观测值; X j 与X k 为第j 个和第k 个变量的平均值。
第三节 数据处理
将14种元素的原始数据及坐标属性等全部输入计算机,完成以下数据处理。
一、地球化学特征参数
地球化学特征参数有四类,代表集中性的、代表分散程度的及上述二类综合的和代表元素分布型式的。
其中,代表集中性的参数有算数平均值、几何平均值、中位数、众数等,代表分散程度的特征参数有均方差、极差,综合特征参数有变化系数、分位数等,代表元素分布型式的偏度、峰度等。
随着地球化学理论的发展和找矿实践经验的积累,除上述通用的地球化学特征参数外,有些化探工作者从地球化学找矿的角度出发衍生了与找矿潜力评价有关的地球化学参数,如叠加强度、蚀变-矿化强度、矿化系数、矿化强度、矿化规模等,这些参数从不同的角度论述了元素成矿潜力的大小。
据此,本报告首先选用前三种参数,并根据实际情况部分的选用与找矿潜力大小有关的参数一并作为本报告选用的地球化学特征参数。
二、异常下限计算
采用叠代剔除大于x +3S 的计算方法求取14个元素平均值及标准离差,作为计算异常下限及划分地球化学色区的依据,异常下限计算公式为T=x +2S 。
三、主要特征参数计算公式
本报告涉及下列地球化学特征参数,计算公式如下。
1、平均值(x )
∑=⨯=
N
i Xi N
X 1
1
2、标准离差(S )
∑=--=
n
i x xi n s 1
2
)
(1
1
3、变异系数
%100⨯=
X
S Cv
4、浓集克拉克值(K 1)
01X X
K =
,式中X 为调查区平均值,0X 为新疆地区元素平均值
5、区域浓集克拉克值(K2)
12X X
K =
,式中X 为调查区平均值,1X 为调查区元素的平均值
6、叠加强度(D )
21
21s s x x D ⨯=
,式中1x 、s1及2x 、s2为剔除前后平均值与标准离差
7、蚀变-矿化强度(KQ )
n
x x kq ⨯=
21,式中1x 、2x 分别为剔除前后平均值,n 为剔除的异常点数。
8、面积(S ):计算机直接读取 9、衬度(Ac) T X
AC =
,式中X 为平均值、T 为异常下限
10、规模(NAP )
Ac S NAP ⨯=,式中S 为面积、Ac 为衬度
11、离散度(Cg)
x Cg δ
=
,式中δ为标准离差、x 为平均值
12、矿化系数(F ) Cg Ac
F =
,Ac 为衬度、Cg 为离散度
13、矿化强度(I )
%
100⨯=
G X I ,式中X 为平均值、G 为元素成矿的边界品位
14、矿化规模(D)
S I
D =
,式中I 为矿化强度、S 为面积
15偏度(Cs )
3
3
S C =
μσ
,式中μ3为三阶中心矩,
3
3
1()
i x x n
=
-∑
μ
;σ为标准离差;
16、峰度(Ct ) 44
3t C =
-μσ
,式中μ4为四阶中心矩,
4
4
1()
i x x n
=
-∑
μ
;σ为标准离差;
地球化学图色区划分按照表3-11执行。
色区划分表表3-11
第二节元素分布及富集特征
一、研究方法
元素分布及富集特征研究方法较多,常用的地球化学参数有变异系数(Cv)、浓集克拉克值(K1)、区域浓集克拉克值(K2)、叠加强度(D)、蚀变矿化强度(Kq)等五个。
其中,富集系数(K)描述的是元素含量的富集程度,叠加强度(D)反映了地质体遭受后期各种地质作用叠加的影响强度,变异系数(Cv)反映了元素在岩石中的活化或分异程度。
一般而言,除同生沉积矿床之外,矿床的形成均要经过成矿元素的活化、迁移或后期多种地质作用的叠加,在一定的条件下才能富集成矿。
但是,由于成矿作用过程具有长期性、多期性和复杂性,导致部分元素的含量在地质体中呈现富集或贫化。
这种富集或贫化是基于元素背景值基础上的高低变化,是地质-地球化学共同作用的结果。
同时,“异常点”是高于背景值+2倍标准离差的含量值,“异常点”越多,说明蚀变-矿化越强烈,越有利于成矿。
上述关系可以通过“蚀变-矿化强度(Kq)”来表述。
一般而言,此值越高,表明该种元素成矿潜力较大。
因此,本报告采用上述五个参数进行元素分布类型划分,力求把元素在岩石或地质体中的活动性、富集程度、多种地质作用的叠加程度及多种成矿作用形成的蚀变-矿化强度有机的结合在一起进行描述。
(一)特征参数计算
应用相关软件分别计算了调查区(表4-2)、各个地层单元(表4-3)、侵入岩(表4-4)等主要地质单元中14个元素的变异系数(Cv)、浓集克拉克值(K1)、区域浓集克拉克值(K2)、叠加强度(D)、蚀变-矿化强度(Kq)等五个地球化学参数。
(二)元素分布类型划分
1、分布类型等级确定
根据Cv、K1、K2、D、Kq值的大小将元素分布类型进一步划分若干等级,方案如下。
(1)元素分异程度等级划分
①均匀型:Cv<0.5
②弱分异型:0.8>Cv>0.5
③强分异型:1.2>Cv>0.8
④极强分异型:Cv>1.2
(2)富集程度等级划分
①贫乏型或亏损型:K<0.5
②低背景型:0.8>K>0.5
③背景型:1.2>K>0.8
④弱富集型:1.5>K>1.2
⑤强富集型:K>1.5
(3)叠加强度等级划分
①同生型:K<1.5
②改造型::3.5>K>1.5
③叠加型:7.0>K>3.5
④强叠加型:14.0>K>7.0
⑤极强叠加型:K>14.0
(4)蚀变-矿化强度划分等级
①弱蚀变-矿化型:Kq<50
②一般蚀变-矿化类型:100>Kq>50
③较强蚀变-矿化型:150>Kq>100
④强烈蚀变-矿化类型:Kq>150。