统计分析作业
- 格式:doc
- 大小:29.00 KB
- 文档页数:2

理解统计表的分析的练习题统计表是一种有效的数据展示方式,能够直观地呈现大量的数据信息,帮助人们理解和分析数据。
在进行统计表的分析时,需要运用一些相关的理论和方法,以确保对数据的准确理解和合理判断。
下面将介绍一些统计表分析的练习题,并提供相应的解答和分析方法。
1. 统计表中的主要数据特征是什么?如何利用这些特征分析数据?答:主要数据特征包括数据的总和、平均值、最大值、最小值等。
可以通过计算这些统计指标,了解数据的集中趋势、离散程度和分布情况。
对于数据的总和和平均值,可以帮助我们衡量整体情况;而最大值和最小值,则可以揭示出数据中的最高点和最低点,以寻找异常值或重要节点。
2. 如何进行对比分析和占比分析?答:对比分析是将不同部分或不同时间段的数据进行对比,并观察它们之间的差异和趋势。
可以通过绘制折线图、柱状图或饼图等方式直观地表现对比关系。
占比分析是计算不同部分在整体中所占的比例,并观察它们的相对重要性。
可以通过饼图或堆叠柱状图等图表来展示占比情况。
3. 如何进行趋势分析?答:趋势分析是观察数据的变化趋势,以及预测未来的发展方向。
可以使用折线图或曲线图来展示数据随时间的变化,并运用移动平均法、指数平滑法等方法来识别趋势线。
通过趋势分析,可以了解数据的发展趋势和周期性变化,以便做出相应的决策或预测。
4. 如何进行分类分析和关联分析?答:分类分析是将数据按特定的分类维度进行划分,并比较不同类别之间的差异和相似性。
可以使用柱状图、散点图等图表进行分类呈现,并计算不同类别的统计指标进行比较。
关联分析是探索不同变量之间的关系和相关性。
可以使用散点图、相关系数等方法来评估变量之间的相关程度,并运用回归分析等方法进行预测和建模。
5. 如何进行统计表的解读和总结?答:在进行统计表的解读和总结时,首先要了解统计表涉及的数据内容和目的。
其次,通过综合分析和对比分析,提取数据的关键信息和规律,并运用适当的量化指标进行评估和比较。
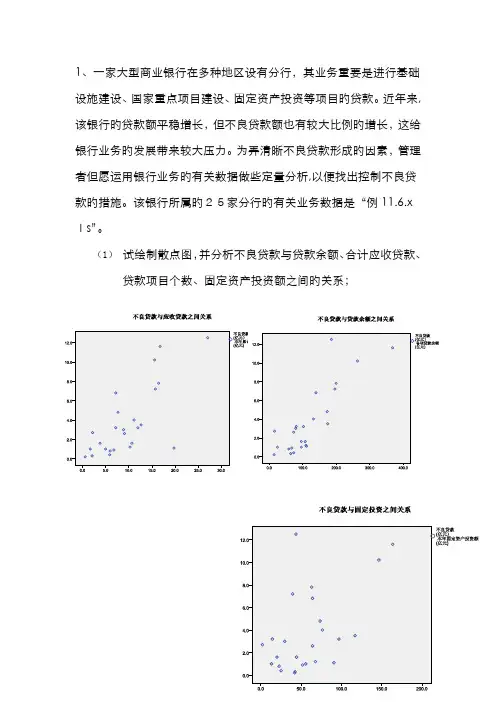
1、一家大型商业银行在多种地区设有分行,其业务重要是进行基础设施建设、国家重点项目建设、固定资产投资等项目旳贷款。
近年来,该银行旳贷款额平稳增长,但不良贷款额也有较大比例旳增长,这给银行业务旳发展带来较大压力。
为弄清晰不良贷款形成旳因素,管理者但愿运用银行业务旳有关数据做些定量分析,以便找出控制不良贷款旳措施。
该银行所属旳25家分行旳有关业务数据是“例11.6.x ls”。
(1)试绘制散点图,并分析不良贷款与贷款余额、合计应收贷款、贷款项目个数、固定资产投资额之间旳关系;2计算不良贷款、贷款余额、合计应收贷款、贷款项目个数、固定资产投资额之间旳有关系数(2)求不良贷款对贷款余额旳估计方程;从表系数可以看出常量、应收贷款、项目个数、固定资产投资额,都接受原假设,只有贷款余额回绝原假设,因此只有贷款余额对不良贷款起作用。
系数a模型 非原则化系数原则系数 t S ig. B 原则 误差试用版1(常量) -1.022.782-1.306 .206 各项贷款余额 (亿元).040.010.8913.837.001本年合计应收贷款 (亿元) .148.079.2601.879.075贷款项目个数 (个).015.083.034.175.863本年固定资产投资额 (亿元)-.029.015-.325-1.937.067a. 因变量: 不良贷款 (亿元)从共线性可以看出,第五个特性值对贷款余额解释87%,相应收账款解释度为12%、对贷款个数解释度为63%、对固定资产投资解释度为5%。
因此不是太共线。
、线性方程为Y=0.01X Y为不良贷款,X为贷款余额。
4 检查不良贷款与贷款余额之间线性关系旳明显性(α=0.05);回归系数旳明显性(α=0.05);通过对上表分析得出:贷款余额线性关系通过明显性检查,回归系数2.练习《记录学》教材P330练习题11.1、11.6、11.7、11.8、11.15,相应旳数据文献为“习题11.1.xls”、“习题11.6.xls”、“习题11.7.xls”、“习题11.8.xls”、“习题11.15.xls”。

《统计分析》课程大作业统计分析课程大作业
介绍
本文档是关于《统计分析》课程的大作业的说明和要求。
背景
《统计分析》课程旨在帮助学生掌握基本的统计分析方法和技巧,以及应用这些方法和技巧进行数据分析的能力。
大作业是课程的一部分,旨在让学生运用所学的统计分析知识解决实际问题,并展示他们的分析和写作能力。
大作业要求
1. 选择一个实际问题进行统计分析。
问题的范围可以包括但不限于社会科学、自然科学、生物医学等领域。
2. 使用合适的统计分析方法对问题进行分析。
可以用到的方法包括描述统计、推断统计、回归分析、方差分析等。
3. 编写一份报告,包括问题陈述、分析方法、数据处理、结果解释和结论。
4. 报告应具备清晰的逻辑结构和良好的写作风格。
标题、段落
和标点符号应运用得当。
提交要求
1. 大作业报告应为中文撰写。
2. 报告应以电子文档形式提交,支持的格式包括PDF、Word。
3. 提交截止日期为课程结束前一周。
评分标准
大作业报告将根据以下几个方面进行评分:
1. 问题陈述的清晰度和相关性。
2. 分析方法的合理性和适用性。
3. 数据处理的准确性和完整性。
4. 结果解释的逻辑性和严谨性。
5. 结论的合理性和可信度。
6. 写作风格的流畅性和准确性。
参考资料
以下是一些关于统计分析的参考资料,供同学们参考使用:
以上是《统计分析》课程大作业的说明和要求,请同学们按照要求完成作业并按时提交。
如有任何问题,请及时与我联系。

作业一一、简述中心极限定理和大数定理。
答:中心极限定理:中心极限定理的具体内容是:如果从任何一个具有均值μ和方差σ2的总体(可以具有任何分布形式)中重复抽取容量为n 的随机样本,那么当n 变得很大时,样本均值X 的抽样分布接近正态,并具有均值μ和方差n2 。
大数定理:我们知道,概率论中用来阐明大量随机现象平均结果的稳定性的定理,是著名的大数定理。
其具体内容是:频率稳定于概率,平均值稳定于期望值。
二、试述正态分布的性质与特点。
——P109答:(1)正态曲线以x=μ呈钟型对称,均值=中位数=众数(2)在x=μ处,概率密度最大;当区间离μ越远,x 落在这个区间的概率越小。
(3)正态曲线的外形由σ值确定。
对于固定的σ值,不同均值μ的正态曲线的外形完全相同,差别只在于曲线在横轴方向上整体平移了一个位置 。
(4)对于固定的μ值,改变σ值,σ值越小,正态曲线越陡峭;σ值越大,正态曲线越低平。
(总之,正态分布曲线的位置是由μ决定的,而正态分布曲线的“高、矮、胖、瘦” 由σ决定的。
)(5)E(X)= μ D(X)= σ2三、简述统计量成为总体参数的合理估计的三个标准——P143答:估计量如果具有无偏性、一致性和有效性这三个要求或标准,就可以认为这种统计量是总体参数的合理估计或最佳估计。
如下:1、无偏性。
如果统计量的抽样分布的均值恰好等于被估计的参数之值,那么这一估计便可以认为是无偏估计。
换句话说,从最终的结果来看,估计量的期望值就是参数本身。
2、一致性。
虽然随机样本和总体之间存在一定的误差,但当样本容量逐渐增加时,统计量起来越接近总体参数,满足这种情况,我们就说该统计量对总体参数是一个一致的估计量。
3、有效性。
估计量的有效性指统计量的抽样分布集中在真实参数周围的程度。
如果估计是无偏的,就可以用估计量的标准差来量度这种集中程度。
标准差越小,估计量的有效性越高。
然而效率总是相对的,没有一种估计量完全有效,完全有效意味没有丝毫抽样误差。

数据的统计和分析练习题数据统计和分析是现代社会中非常重要的一项技能,它可以帮助我们更好地理解和解释各种现象和问题。
通过统计和分析数据,我们可以从中发现规律,做出准确的预测,以及支持科学研究和决策制定。
本文将为大家提供一些数据统计和分析的练习题,以帮助大家熟悉和掌握这一技能。
1. 题目:某餐厅的销售额统计某餐厅进行了一周的销售额统计,结果如下:周一:500元周二:800元周三:600元周四:700元周五:1000元周六:900元周日:1200元请回答以下问题:a) 这周餐厅的总销售额是多少?b) 这周餐厅的平均每天销售额是多少?c) 这周餐厅的销售额中位数是多少?d) 这周餐厅的销售额众数是多少?2. 题目:某公司员工的年龄统计某公司进行了员工年龄的统计调查,结果如下:25, 26, 28, 30, 32, 35, 36, 38, 40, 42请回答以下问题:a) 这些员工的平均年龄是多少?b) 这些员工的年龄中位数是多少?c) 这些员工的年龄众数是多少?3. 题目:某地区某年的降雨量统计某地区统计了某年的每个月的降雨量,结果如下:1月:30毫米2月:20毫米3月:40毫米4月:60毫米5月:80毫米6月:70毫米7月:90毫米8月:100毫米9月:80毫米10月:60毫米11月:40毫米12月:30毫米请回答以下问题:a) 这年的总降雨量是多少?b) 降雨量最大的月份是哪个月?c) 降雨量最小的月份是哪个月?4. 题目:某班级学生的考试成绩统计某班级进行了一次考试,并统计了学生的成绩,结果如下:95, 88, 92, 78, 85, 90, 68, 73, 80, 82请回答以下问题:a) 这次考试的平均成绩是多少?b) 这些学生的成绩中位数是多少?c) 这些学生中成绩最高的是多少?d) 这些学生中成绩最低的是多少?通过以上这些练习题,我们可以锻炼自己的数据统计和分析能力。
掌握这一技能将对我们在各个领域中的工作和研究都大有裨益。

1.作业1(基本统计+参数检验+方差分析1)利用城际出行行为数据,从中随机选取90%的样本,实现以下分析目标:(1)分析出行时间的分布,需做直方图。
(2)分析不同性别的出行方式是否一致。
(3)检验老年人(≥60)与其他人的出行时间是否有显著差异。
(4)检验是否老年人和出行目的两因素对其它时间的影响(考虑交互作用)。
1.1 分析出行时间的分布,需做直方图1.1.1 解题思路首先,根据题目要求在城际出行行为数据中随机选择90%的样本;由于出行时间分布数据是定距变量,且出行时间数据数量较多,不宜使用频数进行分析。
因此在分析之前先对出行时间进行分组,再进行频数分布。
根据公式(1-(1-1)中n为数据个数,对结果四舍五入取整后为理论分组数目。
原样本数为235,随机选择之后剩余样本是n为213个,根据公式(1-1)计算得到分组数目为9。
选中的数据中出行时间的最大值为150,出行时间的最1.1.2操作步骤数据选择:【数据→选择个案】,选择【随机个案样本】→【样本】→在【大约】中填入“90%”→选择【删除未选定的个案】,点击确认。
剩下的即为随机选择之后的数据。
数据分组:【转换】→【重新编码为不同变量】→将“出行时间”加入到有边框中,输出变量名称改为“城市出行时间分组”,点击【更改】,在点击【旧值和新值】,按照60-70、70-80、80-90、90-100、100-110、110-120、120-130、130-140、140-150,分别对应1,2,3,4,5,6,7,8,9。
点击【完成】。
频数分析:【分析】→【描述统计】→【频率】,将“城市出行时间分组”加入到【变量】中。
点击【图表】→【直方图】→选中【在直方图上显示正态曲线】→【确定】。
1.1.3输出结果与分析总计213 100.0 100.0图1-1城市出行时间分布直方图从表1-1中可以看出,出行时间分布中,出行时间在60-70分钟的比较少,占比为4.7%,出行时间在120-130分钟、130-140分钟和140-150分钟的都比较少,三组总和占比仅为6.1%。

《应⽤统计分析》作业集答案部分答案提⽰第⼀章导论⼀、简答题1、数量性、⼤量性;差异性、具体性;2、统计数据信息处理的⽅法包括两个⽅⾯,即描述统计⽅法和推断统计⽅法。
描述统计是主要对已收集到的统计数据信息进⾏加⼯、分组、编制统计表、绘制统计图及计算相对数、平均数、⽅差等,以反映事物的数量特征和数量关系的统计⽅法。
描述统计只限于⼿头现有的数据,不准备把结果⽤来推断总体。
推断统计以样本为基础,主要内容是研究如何应⽤概率理论,以样本来推断总体。
3、选择与定义问题执⾏研究的程序数据分析结果的探究和结论⼀、名词解释1、请区别以下概念:(1)参数与统计量(参数:⽤于说明全级总体的指标;统计量:根据样本资料汇总计算的指标,即样本指标。
)(2)指标和标志(指标和标志是相对⽽⾔的,指标是对总体⽽⾔,标志是对总体单位⽽⾔的。
)(3)离散型变量和连续型变量(离散型变量指只能取整数的变量,连续型变量是指在整数之间可插⼊⼩数的变量。
)第⼆章数据搜集与整理⼆、简答题1、统计调查分为专门调查和统计报表制度两种类型,其中专门调查分为普查、抽样调查、重点调查、典型调查四种类型。
2、重点调查是在总体中选择部分重点单位进⾏的调查,借以了解总体的基本情况。
所谓重点单位,是指在总体中具有举⾜轻重地位的单位。
这些单位虽然少,但它们调查的标志值在总体标志总量中占有绝⼤⽐重,通过对这些单位的调查,就能掌握总体的基本情况。
典型调查是根据调查的⽬的和要求,在对调查对象进⾏全⾯分析的基础上,有意识的选择部分有代表性的单位进⾏的调查,是⼀种⾮全⾯调查。
重点调查与典型调查都是⾮全⾯调查,它们都存在⼀个共同的问题,即部分单位的选择问题。
重点调查部分单位的选择应把握这些单位在总体中所占的⽐重要较⼤,⽽典型调查部分单位的选择应放在这些单位要具有⾜够的代表性。
3、影响问卷效果的因素主要有三个⽅⾯:(1)被调查者的主观倾向;(2)测量⼯具即问卷本⾝的问题;(3)问卷环境。

统计学A练习题教学班号:学号:姓名:第一章导论一、思考题1、简述(jiǎn shù)统计的涵义及其关系。
2、简述(jiǎn shù)统计学与其他学科的关系。
3、什么(shén me)是统计学的研究对象?它有什么特点?4、统计(tǒngjì)研究的基本方法是什么?5、社会(shèhuì)经济统计的任务和职能是什么?6、统计活动过程阶段及各阶段的关系如何?7、什么是总体与总体单位?8、简述标志和指标的关系。
9、什么是统计指标体系?为什么统计指标体系比统计指标更重要?10、什么是变量和变量值?11、什么是连续变量和离散变量?如何判断?二、单项选择题(在每小题的四个备选答案中选出一个正确的答案,并将正确答案的号码填在题干后的括号内)1、统计学的基本方法包括()。
A、调查方法、汇总方法、预测方法B、相对数法、平均数法、指数法C、大量观察法、综合分析法、归纳推断法D、整理方法、调查方法、分析方法2、社会经济统计学的研究对象是()。
A、抽象的数量关系B、社会经济现象的数量关系C、社会经济现象的规律性D、数量关系和研究方法3、几位学生的某门课程成绩分别是67分、78分、88分、89分、和 96分,则成绩是()。
A、质量指标B、数量指标C、数量标志D、品质标志4、要了解20个工业企业的职工的工资情况时,则总体是()。
A、20个工业企业B、20个工业企业的职工工资总额C、每一个工业企业的职工D、20个工业企业的全部职工5、标志是说明()。
A、总体单位特征的B、总体特征的C、单位量的特征的名称D、单位值的特征的名称6、工业企业的设备台数、产品产值是()。
A、连续变量B、离散变量C、前者是连续变量,后者是离散变量D、前者是离散变量,后者是连续变量7、为了了解某市高等学校的基本情况,对该市所有高等学校进行调查,其中某一高等学校有学生(xué sheng)5285人,教师950人,该校最大系有师生780,其中教师120人,正、副教授36人,占教师总数的19.3%,上述数值中属于统计指标的有()。
产经营管理工作做得好,并简述作出这一结论的理由。
10. 市场上卖某种蔬菜,早市每元买2千克,午市每元买
2.5千克,晚市每元买5千克。
若早、中、晚的购买量相同,平均每元买了多少千克蔬菜?若早、中、晚的购买额相同,平均每元买了多少千克蔬菜?
11.某工厂生产某种零件,要经过三道工序,各道工序的合格率分别为95.74%、92.22%、96.3%。
试求该零件的平均合格率。
要求:(1)计算中位数、第一和第三四分位数、众数; (2)计算全距、平均差;
(3)计算算术平均数、标准差;
(4)比较算术平均数、中位数、众数的大小,说明本资料分布的偏斜特征。
试分析:(1)哪个单位工人的生产水平高?
(2)哪个单位工人的生产水平整齐?
14. 某地区有一半家庭的月人均收入低于600元,一半高于600元,众数为700元,试估计算术平均数的近似值并说明分布态势。
(2)若年利率按单利计算,即利息不转为本金,则该笔投资的平均年利率为多少?。

统计学作业数据分析报告小结引言本次统计学作业数据分析报告旨在对所给数据进行深入分析,探索数据中的潜在规律与趋势。
通过统计学方法的应用,我们能够更好地理解数据,为决策提供有力的支持。
本报告将依次介绍数据收集、数据清洗、数据探索、数据分析以及结论总结等几个关键步骤。
数据收集本次数据分析使用的数据来源于一份调查问卷,调查的主题为消费者对某品牌产品的满意度。
问卷共有200份有效回答,每个回答包含了满意度得分以及一些相关的变量,如性别、年龄、教育程度等。
数据清洗在对数据进行分析之前,我们首先需要进行数据清洗,以确保数据的完整性和准确性。
在本次数据清洗过程中,我们采取了以下几个步骤:•去除无效数据:对于一些缺失值过多或不符合要求的数据进行剔除,以确保数据质量;•格式转换:将一些变量从文本格式转换为数值格式,以便后续分析使用;•异常值处理:通过使用箱线图等方法检测并处理异常值,以提高数据的可靠性。
经过数据清洗之后,我们得到了一个干净、整洁且适合分析的数据集。
数据探索数据探索是了解数据特征和潜在规律的过程。
在本次数据分析中,我们通过以下几种方式对数据集进行了探索:描述性统计我们首先对各个变量进行了描述性统计,包括计算平均值、中位数、标准差、最大值和最小值等。
通过描述性统计,我们能够了解数据的基本分布情况,发现数据中的异常情况。
数据可视化除了描述性统计,我们还借助直方图、散点图和饼图等可视化工具对数据进行了展示。
通过数据可视化,我们可以更直观地观察数据的分布、趋势和相关性,从而更好地理解数据。
数据分析在本次数据分析中,我们主要关注了消费者满意度得分与其他变量之间的关系。
我们进行了如下几个方面的分析:1. 性别对满意度的影响我们将数据按照性别进行分组,并对满意度得分进行比较。
通过统计分析方法,我们发现男性和女性在满意度上存在一些差异,男性的满意度得分略高于女性。
2. 年龄对满意度的影响我们将数据按照年龄段进行分组,并对满意度得分进行比较。

统计学作业 Prepared on 22 November 2020第二章习题(离散程度指标)1.[习题集P23第9题]某车间有两个小组,每组都是7人,每人日产量数如下:第一组:20、40、60、70、80、100、120;第二组:67、68、69、70、71、72、73。
已知两组工人每人平均日产量件数为70件,试计算:(1)R;(2);(3),并比较哪个组的平均数代表性大要求:如计算过程有小数,请保留至小数点后两位,余均同。
试据此分别计算其平均日产量,并说明哪个班的平均日产量代表性大假定生产条件相同,试计算这两个品种的收获率(产量/播种面积),确定哪一品种具有较大的稳定性和推广价值。
注意:播种面积是“f”,而产量等于收获率乘以播种面积,因而是“xf”。
4.[习题集P25第15题]各标志值对任意数的方差为500,而这个任意数与标志值平均数之差为12,试确定标志值的方差(提示:方差是离差平方的平均数。
本题中的500是标志值与任意数的方差,即所测度的离差发生在标志值与某一任意数之间,而所求的方差是标志值与均值之间的方差)。
第二章习题(平均指标)试计算该局企业平均职工人数以及第20百分位数。
2.[习题集P21第3题]某乡播种2800亩早稻,其中35%的稻田使用良种,平均亩产750斤,其余的稻田平均亩产仅480斤。
试问:(1)全部耕地早稻平均亩产是多少(2)早稻的全部产量是多少试计算产品计划与实际的平均等级和平均出厂价格,指出两者间的经济联系(提示:可对产品等级进行赋值,尔后计算)。
根据该资料计算亩产的中位数和众数,并判断其分布态势。
第三章《时间序列分析》作业又知该厂7月初的工人数为1270人,前年12月份工业总产值为235万元。
要求计算该厂去年上半年的:(1)月平均工业总产值;(2)工业总产值的月平均增长量(以前年12月份为基期); (3)平均工人人数;(4)月平均工人劳动生产率。
要求:计算该产品的平均单位成本。
第三章统计数据的描述1.某企业工人按年工资分组资料如下:按年工资分组(元)工人数(人)600—700 10700—800 15800—900 35900—1000 121000—1100 8合计80计算工人工资的平均数、全距、平均差、标准差、平均差系数、标准差系数。
2.现有两个生产班组的工人日产量资料如下:甲班组乙班组日产量(件)人数(人)日产量(件)人数(人)5 3 8 67 5 12 79 6 14 310 4 15 313 2 16 1合计20 合计20分别计算两个班组工人的平均日产量并说明哪个班组的平均数代表性大,为什么?3.两种不同水稻品种在4块田地上试种,其产量如下:甲品种乙品种面积(公顷)产量(公斤)面积(公顷)产量(公斤)1.3 585 1.2 6001.0 505 0.9 3780.8 420 1.3 7151.5 690 1.4 525假定生产条件相同,确定两个品种的单位面积产量,并比较哪个品种具有较大的稳定性。
第四章时间序列1.某地区棉花产量的年度资料如下,请用最小平方法编制一个直线趋势方程式,并预计2002年棉花产量。
1995-2001年某地区棉花产量年份产量(吨)1995 354.01996 424.51997 414.91998 378.81999 450.82000 567.52001 450.82.某地区1991-1999年GDP资料如表,利用最小二乘法拟合趋势方程,并预测2000年该地区交通运输业产值(假定交通运输业占该地区GDP的4%)。
年份GDP(亿元)1991 4001993 4801995 5701997 6701999 7903.某省对外贸易总额2000年比1997年增长7.9%,2001年比2000年增长4.5%,2002年又比2001年增长20%,试计算1997年—2002年每年平均增长速度。
第五章统计指数1. 某工业企业两种产品的产量及出厂价格资料如下表:产品单位产量出厂价格(元)基期报告期基期报告期甲吨5000 5500 20 21乙台3000 3600 25 28 试计算:(1) 产量个体指数和出厂价格个体指数;(2)产量总指数及由于产量增加(或减少)而增加(或减少)的总产值;(3)出厂价格总指数及由于出厂价格提高(或降低)而增加(或减少)的总产值。
第四章统计分析的基本指标例4.1:某公司2008年计划实现净利润2500万元,实际完成3100万元。
计算利润计划完成程度。
例4.2:某公司2008年劳动生产率计划比上年增长10%,实际增长了21%,计算劳动生产率计划完成程度。
例4.3:某公司2008年单位成本计划比上年降低10%,实际降低了19%,计算单位成本计划完成程度。
例4.4:某企业2007年某产品的单位成本为520元,2008年计划在上年基础上降低5%,实际降低了40元,计算2008年单位成本计划完成程度。
例4.5:某企业2002年产品销售量计划达到上年的108%,2002年销售量实际比上年增长了15%,试计算2002年销售计划完成程度。
例46:某企业“十五”计划规定,最后一年的钢产量要达到200万吨,各年实际产量如下表例4.8:三种苹果每公斤的单价分别为4元、6元、9元。
(1)如果三种苹果各买2公斤,计算平均价格。
(2)如果三种苹果分别购买2公斤、3公斤、5公斤,计算平均价格。
(3)如果三种苹果各买5元,计算平均价格。
(4)如果三种苹果各买5元、6元、18元,计算平均价格。
(5)根据以上四种情况下计算的平均价格,归纳出算术平均数、调和平均数的运用条件。
例4.10:2007年某主管部门所属企业的利润计划完成程度如下表:例4.11:某企业有铸锻、初加工、精加工和装配四个连续作业车间,加工1000件产品,经过四个车间加工后的合格品数量分别为980件、970件、950件、945件。
试计算四个车间的平均合格率。
例4.12:某企业从银行取得一笔1000万元的10年期贷款,按复利计算利息:第1年的利率为6%,第2—3年的利率为7%,第4—6年的利率为8%,第7—10年的利率为10%。
试计算该笔贷款的平均年利率。
如果按单利计算利息,平均年利率又是多少?例4.13:A、B两个农贸市场的交易资料如下表:例4.14:某企业2000第四章统计指标作业2.3.某一家三口,父母工作,女儿上小学。
统计与数据分析数据分析作业统计与数据分析作业在当今数字化的时代,数据无处不在,从社交媒体的动态到商业交易的记录,从科学研究的成果到政府决策的依据。
而如何从这些海量的数据中提取有价值的信息,做出明智的决策,就离不开统计与数据分析。
统计与数据分析是一门融合了数学、统计学和计算机科学等多领域知识的学科。
它旨在通过收集、整理、分析和解释数据,以揭示数据背后的规律和趋势,为各种决策提供支持。
对于一项统计与数据分析作业,首先要明确研究的问题或目标。
这是整个作业的出发点和方向。
比如,是要分析某个产品在不同地区的销售情况,还是要探究某种疾病的发病因素与年龄、性别之间的关系。
清晰明确的问题有助于后续数据收集和分析方法的选择。
数据收集是关键的一步。
数据的来源多种多样,可以是现有的数据库、调查问卷、实验观测或者网络爬虫获取的信息等。
在收集数据时,要确保数据的准确性和完整性。
不准确或不完整的数据可能会导致错误的分析结果。
同时,还需要考虑数据的代表性。
如果研究的是全国范围内的某种现象,那么仅收集某个地区的数据可能就无法反映真实的情况。
接下来是数据的整理和预处理。
收集到的数据往往是杂乱无章的,可能存在缺失值、异常值和重复数据等问题。
需要对这些数据进行清理和处理。
缺失值可以通过均值填充、中位数填充或者删除等方法处理;异常值需要仔细甄别,判断是真实的异常还是数据错误,如果是错误则进行修正或删除;重复数据则直接删除,以避免对分析结果的影响。
在数据分析阶段,根据研究的问题和数据的特点,选择合适的分析方法。
常见的分析方法包括描述性统计分析、相关性分析、假设检验、回归分析、聚类分析等。
描述性统计分析可以帮助我们了解数据的集中趋势、离散程度等基本特征;相关性分析用于探究两个或多个变量之间的线性关系;假设检验则用于判断样本数据是否支持某个关于总体的假设;回归分析可以建立变量之间的数学模型,预测未来的趋势;聚类分析则可以将数据分成不同的类别。
第一次作业一、计算题1、某百货公司6月份各天的销售额数据如下(单位:万元):销 售 额257 276 297 252 238 310 240 236 265 278 271 292 261 281 301 274 267 280 291 258 272 284 268 303 273 263 322 249 269 295(1)计算该百货公司日销售额的均值、中位数;(2)计算日销售额的标准差。
(用excel 计算)解:(1)均值:1.27430301==∑=i ixX中位数:272.5(2)标准差:s=21.174722、对10名成年人和10名幼儿的身高(厘米)进行抽样调查,结果如下:成年组 166 169 172 177 180 170 172 174 168 173 幼儿组 68 69 68 70 71 73 72 73 74 75(1)要比较成年组和幼儿组的身高差异,你会采用什么样的指标测度值?为什么?(2)比较分析哪一组的身高差异大? 解:(1)采用标准差系数比较合适,因为各标志变动值的数值大小,不仅受离散程度的影响,而且还受到平均水平高低的影响。
标准差系数适合于比较不同组数据的相对波动程度。
(2)成年组的均值:1.17210101==∑=i ixX ,标准差为:202.4=σ离散系数:024.01.172202.41≈==Xv σσ幼儿组的均值:1.17210101==∑=i ixX,标准差为:497.2=σ 离散系数:035.03.71497.2≈==Xv σσ3⑴ 用拉氏公式编制四种蔬菜的销售量总指数和价格总指数;⑵ 再用派氏公式编制四种蔬菜的销售量总指数和价格总指数; 解:(1)拉氏销售量总指数: 042.11684.25506.11704.25606.10010≈⨯++⨯⨯++⨯==∑∑ qp q p L q拉氏价格总指数:077.11684.25506.116835508.10001≈⨯++⨯⨯++⨯==∑∑ q p q p L p(2)派氏销售量总指数: 038.116835508.117035608.10111≈⨯++⨯⨯++⨯==∑∑ qp q p P q派氏价格总指数:074.11704.25606.117035608.1111≈⨯++⨯⨯++⨯==∑∑ qp q p P p4、某企业共生产三种不同的产品,有关的产量、成本和销售价格资料如下表所示:⑴ 分别以单位产品成本和销售价格为同度量因素,编制该企业的派氏产量指数;⑵ 试比较说明:两种产量指数具有何种不同的经济分析意义?答:(1)以单位产品成本为同度量因素的派氏产量指数:928.0190330270501503303405001111≈⨯++⨯⨯++⨯==∑∑ qp q p P q7300)19033027050()150********(0111-=⨯++⨯-⨯++⨯=-∑∑q p q p以销售价格为同度量因素的派氏产量指数:933.0190400270651504003406501112≈⨯++⨯⨯++⨯==∑∑ qp q p P q8450)19040027065()150********(0111-=⨯++⨯-⨯++⨯=-∑∑q p q p(3) 以单位产品成本为同度量因素的派氏产量指数表示由于产量变化使总成本减少了0.72%,减少了7300.以销售价格为同度量因素的派氏产量指数表示由于产量变化使总销售额减少了0.67%,减少了8450。
统计学大作业
题目:基于多元统计分析的消费者行为研究
一、引言
在当今的商业环境中,消费者行为研究对于企业的生存和发展至关重要。
通过对消费者行为的深入理解,企业可以更好地满足客户需求,优化产品设计,提升市场占有率。
多元统计分析作为统计学的一个重要分支,为消费者行为研究提供了强大的工具。
本大作业将通过多元统计分析方法,深入研究消费者行为。
二、数据收集
我们将收集某电商平台的消费者购买数据,包括消费者的年龄、性别、购买商品种类、购买频率、购买时间等。
数据收集将采用问卷调查和电商平台数据抓取相结合的方式进行。
三、多元统计分析方法
1. 聚类分析:根据消费者的购买行为特征,将消费者群体进行分类。
通过聚类分析,我们可以深入了解不同类型消费者的消费习惯和偏好。
2. 因子分析:用于从消费者的购买数据中提取出主要的影响因素,以便更好地理解消费者的购买动机和决策过程。
3. 主成分分析:通过主成分分析,我们可以将多个相关变量转化为少数几个不相关的变量,从而简化数据结构,更好地揭示数据背后的规律。
4. 判别分析:通过判别分析,我们可以预测消费者的购买行为,并根据消费者的特征将其划分为不同的群体。
四、结果分析
基于上述多元统计分析方法,我们将深入分析消费者行为,揭示不同类型消费者的消费特征和偏好。
此外,我们还将比较不同性别、年龄段的消费者在购买行为上的差异,为企业制定更有针对性的营销策略提供依据。
五、结论
通过本大作业的研究,我们期望能够深入理解消费者行为,为企业提供有价值的消费者行为分析报告。
这将有助于企业更好地满足客户需求,提升市场竞争力。
《环境统计学》课后习题第三次
学号091444117 姓名雷蕾分数
1、已知某标准水样中CaCO3的含量为20.70 mg/L,现用某法测定该水样11次,测定结果
为:20.99,20.41,20.10,20.00,20.99,20.91,20.60,20.00,23.00,22.00,22.44。
试分析该测定方法是否可靠。
解:有关已知条件为:μ=20.70,n=11,均值为20.93,S=1.02991
检测过程为:H o=20.70 H 1 ≠20.70
计算得到:t=1.107
取α=0.05,P=0.294>0.05
故H o接受,即这种方法可靠
2、某实验室用两种不同的方法测定下水道污水中的镉,得到如下结果(ug/L):
方法一:5.95,5.82,5.04,5.02,5.90,5.86,5.08;
方法二:5.96,5.04,5.97,5.03
问这两种方法的测定结果是否显著不同?
解:该问题属于两个独立总体均值比较的假设实验,且量变服从正态分布,由SPSS解得
了两个的标准差,故采用正Z检验中的双侧检验
检测过程为H o:μ1=μ2H1:μ1≠μ2
检测统计量为:Z=0.05
取α=0.05,从附表中查出双侧检验临界值C=zα/2=2.201,显然Z<C,故不拒绝原假设,则两种方法测定的结果显著相同
由SPSS计算得P>0.05,也可以得出结论
3、某地对地下水进行除氟试验,对10眼水井除氟前后井水中含氟量测定结果如下(mg/L)。
问除氟后井水含氟量是否有显著差异?
除氟前:1.5,1.4,1.5,1.45,1.35,1.4,1.4,1.5,1.4,1.35
除氟后:1.45,1.35,1.45,1.5,1.4,1.4,1.35,1.4,1.35,1.3
解:检验过程为:H O:б12=б22H1:б12≠б22
由计算得P=0.081
取α=0.05,故P>α故不拒绝原假设,即除氟后井水含氟量没有明显差异。