BP神经网络模型应用实例
- 格式:doc
- 大小:71.00 KB
- 文档页数:10

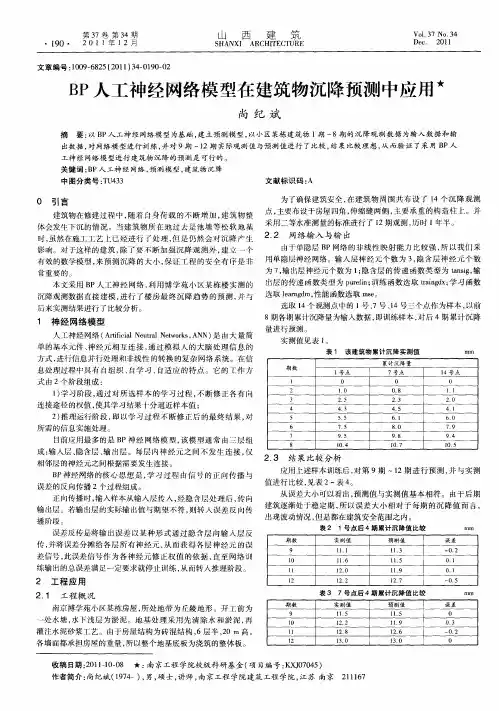



BP人工神经网络的基本原理模型与实例BP(Back Propagation)人工神经网络是一种常见的人工神经网络模型,其基本原理是模拟人脑神经元之间的连接和信息传递过程,通过学习和调整权重,来实现输入和输出之间的映射关系。
BP神经网络模型基本上由三层神经元组成:输入层、隐藏层和输出层。
每个神经元都与下一层的所有神经元连接,并通过带有权重的连接传递信息。
BP神经网络的训练基于误差的反向传播,即首先通过前向传播计算输出值,然后通过计算输出误差来更新连接权重,最后通过反向传播调整隐藏层和输入层的权重。
具体来说,BP神经网络的训练过程包括以下步骤:1.初始化连接权重:随机初始化输入层与隐藏层、隐藏层与输出层之间的连接权重。
2.前向传播:将输入向量喂给输入层,通过带有权重的连接传递到隐藏层和输出层,计算得到输出值。
3.计算输出误差:将期望输出值与实际输出值进行比较,计算得到输出误差。
4.反向传播:从输出层开始,将输出误差逆向传播到隐藏层和输入层,根据误差的贡献程度,调整连接权重。
5.更新权重:根据反向传播得到的误差梯度,使用梯度下降法或其他优化算法更新连接权重。
6.重复步骤2-5直到达到停止条件,如达到最大迭代次数或误差小于一些阈值。
BP神经网络的训练过程是一个迭代的过程,通过不断调整连接权重,逐渐减小输出误差,使网络能够更好地拟合输入与输出之间的映射关系。
下面以一个简单的实例来说明BP神经网络的应用:假设我们要建立一个三层BP神经网络来预测房价,输入为房屋面积和房间数,输出为价格。
我们训练集中包含一些房屋信息和对应的价格。
1.初始化连接权重:随机初始化输入层与隐藏层、隐藏层与输出层之间的连接权重。
2.前向传播:将输入的房屋面积和房间数喂给输入层,通过带有权重的连接传递到隐藏层和输出层,计算得到价格的预测值。
3.计算输出误差:将预测的价格与实际价格进行比较,计算得到输出误差。
4.反向传播:从输出层开始,将输出误差逆向传播到隐藏层和输入层,根据误差的贡献程度,调整连接权重。

BP神经网络模型第1节基本原理简介近年来全球性的神经网络研究热潮的再度兴起,不仅仅是因为神经科学本身取得了巨大的进展.更主要的原因在于发展新型计算机和人工智能新途径的迫切需要.迄今为止在需要人工智能解决的许多问题中,人脑远比计算机聪明的多,要开创具有智能的新一代计算机,就必须了解人脑,研究人脑神经网络系统信息处理的机制.另一方面,基于神经科学研究成果基础上发展出来的人工神经网络模型,反映了人脑功能的若干基本特性,开拓了神经网络用于计算机的新途径.它对传统的计算机结构和人工智能是一个有力的挑战,引起了各方面专家的极大关注.目前,已发展了几十种神经网络,例如Hopficld模型,Feldmann等的连接型网络模型,Hinton等的玻尔茨曼机模型,以及Rumelhart等的多层感知机模型和Kohonen的自组织网络模型等等。
在这众多神经网络模型中,应用最广泛的是多层感知机神经网络。
多层感知机神经网络的研究始于50年代,但一直进展不大。
直到1985年,Rumelhart等人提出了误差反向传递学习算法(即BP算),实现了Minsky的多层网络设想,如图34-1所示。
BP 算法不仅有输入层节点、输出层节点,还可有1个或多个隐含层节点。
对于输入信号,要先向前传播到隐含层节点,经作用函数后,再把隐节点的输出信号传播到输出节点,最后给出输出结果。
节点的作用的激励函数通常选取S 型函数,如Qx e x f /11)(-+=式中Q 为调整激励函数形式的Sigmoid 参数。
该算法的学习过程由正向传播和反向传播组成。
在正向传播过程中,输入信息从输入层经隐含层逐层处理,并传向输出层。
每一层神经元的状态只影响下一层神经输入层 中间层 输出层 图34-1 BP 神经网络模型元的状态。
如果输出层得不到期望的输出,则转入反向传播,将误差信号沿原来的连接通道返回,通过修改各层神经元的权值,使得误差信号最小。
社含有n 个节点的任意网络,各节点之特性为Sigmoid 型。

bp神经网络算法步骤结合实例
BP神经网络算法步骤包括以下几个步骤:
1.输入层:将输入数据输入到神经网络中。
2.隐层:在输入层和输出层之间,通过一系列权值和偏置将输入数据进行处理,得到输出
数据。
3.输出层:将隐层的输出数据输出到输出层。
4.反向传播:通过反向传播算法来计算误差,并使用梯度下降法对权值和偏置进行调整,
以最小化误差。
5.训练:通过不断地进行输入、隐层处理、输出和反向传播的过程,来训练神经网络,使
其达到最优状态。
实例:
假设我们有一个BP神经网络,它的输入层有两个输入节点,隐层有三个节点,输出层有一个节点。
经过训练,我们得到了权值矩阵和偏置向量。
当我们给它输入一组数据时,它的工作流程如下:
1.输入层:将输入数据输入到神经网络中。
2.隐层:将输入数据与权值矩阵相乘,再加上偏置向量,得到输出数据。
3.输出层:将隐层的输出数据输出到输出层。
4.反向传播:使用反向传播算法计算误差,并使用梯度下降法调整权值和偏置向量,以最
小化误差。
5.训练:通过不断地输入、处理、输出和反向传播的过程,来训练神经网络,使其达到最
优状态。
这就是BP神经网络算法的基本流程。
在实际应用中,还需要考虑许多细节问题,如权值和偏置的初始值、学习率、激活函数等。
但是,上述流程是BP神经网络算法的基本框架。

BP神经网络在乳腺癌诊断中的应用Introduction随着医疗技术的不断发展,人们对于疾病的认知和诊治手段也在不断进步。
乳腺癌是一种常见的恶性肿瘤疾病,早期的确诊和治疗可以有效地延长患者的生命、提高治疗效果。
BP神经网络是一种基于反馈的人工神经网络模型,可以通过训练自动学习规律和特征,广泛应用于医学领域的疾病诊断和医疗数据分析中。
本文将介绍BP神经网络在乳腺癌诊断中的应用。
Literature ReviewBP神经网络最早于1975年由美国的保罗·威廉姆斯和大卫·鲁梅尔哈特提出,其核心思想是通过反向传播算法,使网络能够学习并自适应地调整权值,以逐步提高分类和诊断准确度。
BP神经网络在医学领域的应用包括肿瘤分类和预测、心脏病诊断、脑部疾病诊断等方面,特别是在乳腺癌的诊断中,由于BP神经网络的高精确性和优异的性能,在医学领域的应用得到了越来越广泛的推广。
MethodologyBP神经网络在乳腺癌诊断中的应用主要分为以下几个步骤:1. 数据收集和预处理从公开数据集或实际的病例数据中获取乳腺癌相关的临床资料,包括患者基本信息、乳腺X线片、超声和病理检查结果等。
对数据进行清洗和预处理,去除异常和无效数据,对数据进行标准化和归一化的处理,以便在神经网络模型中更好地进行训练和学习。
2. 网络结构和参数设计根据收集到的临床资料,设计相应的神经网络结构,包括输入层、隐层和输出层,考虑到不同的影响因素和特征,可以设定不同数量和大小的隐层和神经元节点,以便更好地拟合和拟合数据。
另外,还需要设置训练参数和学习算法,例如学习率、动量因子和误差函数等,以优化神经网络的训练和调整权重。
3. 神经网络训练和测试将预处理后的数据集分为训练集和测试集两部分,分别用于训练和测试神经网络模型。
训练阶段通过反向传播算法计算误差和更新权重,以不断调整神经网络的输出结果和预测准确度。
测试阶段将训练好的神经网络模型用于新的数据样本中,以验证神经网络的泛化能力和准确度。

神经网络原理及BP网络应用实例摘要:本文主要对神经网络原理进行系统地概述,再列举BP网络在曲线逼近中的应用。
神经网络是一门发展十分迅速的交叉学科,它是由大量的处理单元组成非线性的大规模自适应动力系统。
神经网络具有分布式存储、并行处理、高容错能力以及良好的自学习、自适应、联想等特点。
随着计算机的发展,目前已经提出了多种训练算法和网络模型,其中应用最广泛的是前馈型神经网络。
本文将介绍人工神经网络的基本概念、基本原理、BP神经网络、自适应竞争神经网络以及神经网络的应用改进方法。
关键字:神经网络;收敛速度;BP网络;改进方法The principle of neural network and the applicationexamples of BP networkAbstract:Neural network is a cross discipline which now developing very rapidly, it is the nonlinearity adaptive power system which made up by abundant of the processing units . The neural network has features such as distributed storage, parallel processing, high tolerance and good self-learning, adaptive, associate, etc. Currently various training algorithm and network model have been proposed , which the most widely used type is Feedforward neural network model. Feedforward neural network training type used in most of the method is back-propagation (BP) algorithm. This paper will introduces the basic concepts, basic principles, BP neural network, adaptive competitive neural network and the application of artificial neural network.Keywords:neural network,convergence speed,BP neural network,improving method1 神经网络概述1.1 生物神经元模型人脑是由大量的神经细胞组合而成的,它们之间相互连接。

基于BP神经网络的股票价格预测模型股票市场是一个高度波动的市场,股票价格每天都发生着变化,投资者需要在这个市场中赚取利润,但是要预测股票价格的变化是非常困难的。
传统的基本面分析和技术分析方法虽然可以对市场产生一定的影响,但是对于股票价格预测的准确性并不高。
近年来,随着神经网络技术的发展,越来越多的学者开始利用神经网络模型来进行股票价格预测。
BP神经网络作为一种最为基础的神经网络模型在股票价格预测中得到了广泛的应用。
本文将基于BP神经网络模型,探讨其在股票价格预测中的应用和优缺点。
一、BP神经网络模型概述BP神经网络模型是一种前向反馈的多层神经网络模型,由输入层、隐层和输出层组成。
输入层接收外部输入数据,隐层对输入值进行一定的特征提取和转换后输出到输出层,输出层则给出最终结果。
在训练过程中,BP神经网络利用反向传播算法,不断调整网络的权重和阈值,使得网络的输出结果与实际结果尽可能的接近。
二、BP神经网络在股票价格预测中的优缺点1.优点(1)非线性映射能力:BP神经网络模型能够非线性地拟合股票价格的变化趋势,能够更好的适应复杂和非线性的市场环境。
(2)自适应性:神经网络模型能够自动地对权重和阈值进行调整,对于不同的市场环境和数据情况都能够有一定的适应性。
(3)数据处理能力:神经网络模型具有较好的数据处理能力,能够识别并利用大量的数据和变量进行预测,这为股票价格预测提供了很大的便利。
2.缺点(1)过拟合问题:当神经网络模型的训练数据过多或者网络结构过于复杂时,容易出现过拟合问题,导致模型的泛化能力下降。
(2)训练时间长:传统的BP神经网络需要进行大量的迭代训练,对计算机资源和时间的要求较高。
(3)参数选择困难:BP神经网络的训练结果受到很多参数的影响,需要进行不断的试错才能得到最优的参数选择,影响模型的实用性。
三、BP神经网络模型的应用案例1.利用BP神经网络预测股票趋势李果等人利用BP神经网络,以2014年沪深300个股为样本,建立了股票价格预测模型,结果显示BP神经网络具有较好的精度和稳定性。

BP神经网络的简要介绍及应用BP神经网络(Backpropagation Neural Network,简称BP网络)是一种基于误差反向传播算法进行训练的多层前馈神经网络模型。
它由输入层、隐藏层和输出层组成,每层都由多个神经元(节点)组成,并且每个神经元都与下一层的神经元相连。
BP网络的训练过程可以分为两个阶段:前向传播和反向传播。
前向传播时,输入数据从输入层向隐藏层和输出层依次传递,每个神经元计算其输入信号的加权和,再通过一个激活函数得到输出值。
反向传播时,根据输出结果与期望结果的误差,通过链式法则将误差逐层反向传播至隐藏层和输入层,并通过调整权值和偏置来减小误差,以提高网络的性能。
BP网络的应用非常广泛,以下是一些典型的应用领域:1.模式识别:BP网络可以用于手写字符识别、人脸识别、语音识别等模式识别任务。
通过训练网络,将输入样本与正确的输出进行匹配,从而实现对未知样本的识别。
2.数据挖掘:BP网络可以用于分类、聚类和回归分析等数据挖掘任务。
例如,可以用于对大量的文本数据进行情感分类、对客户数据进行聚类分析等。
3.金融领域:BP网络可以用于预测股票价格、外汇汇率等金融市场的变动趋势。
通过训练网络,提取出对市场变动有影响的因素,从而预测未来的市场走势。
4.医学诊断:BP网络可以用于医学图像分析、疾病预测和诊断等医学领域的任务。
例如,可以通过训练网络,从医学图像中提取特征,帮助医生进行疾病的诊断。
5.机器人控制:BP网络可以用于机器人的自主导航、路径规划等控制任务。
通过训练网络,机器人可以通过感知环境的数据,进行决策和规划,从而实现特定任务的执行。
总之,BP神经网络是一种强大的人工神经网络模型,具有较强的非线性建模能力和适应能力。
它在模式识别、数据挖掘、金融预测、医学诊断和机器人控制等领域有广泛的应用,为解决复杂问题提供了一种有效的方法。
然而,BP网络也存在一些问题,如容易陷入局部最优解、训练时间较长等,因此在实际应用中需要结合具体问题选择适当的神经网络模型和训练算法。
BP神经网络模型第1节基本原理简介近年来全球性的神经网络研究热潮的再度兴起,不仅仅是因为神经科学本身取得了巨大的进展.更主要的原因在于发展新型计算机和人工智能新途径的迫切需要.迄今为止在需要人工智能解决的许多问题中,人脑远比计算机聪明的多,要开创具有智能的新一代计算机,就必须了解人脑,研究人脑神经网络系统信息处理的机制.另一方面,基于神经科学研究成果基础上发展出来的人工神经网络模型,反映了人脑功能的若干基本特性,开拓了神经网络用于计算机的新途径.它对传统的计算机结构和人工智能是一个有力的挑战,引起了各方面专家的极大关注.目前,已发展了几十种神经网络,例如Hopficld模型,Feldmann等的连接型网络模型,Hinton等的玻尔茨曼机模型,以及Rumelhart等的多层感知机模型和Kohonen的自组织网络模型等等。
在这众多神经网络模型中,应用最广泛的是多层感知机神经网络。
多层感知机神经网络的研究始于50年代,但一直进展不大。
直到1985年,Rumelhart等人提出了误差反向传递学习算法(即BP算),实现了Minsky的多层网络设想,如图34-1所示。
BP 算法不仅有输入层节点、输出层节点,还可有1个或多个隐含层节点。
对于输入信号,要先向前传播到隐含层节点,经作用函数后,再把隐节点的输出信号传播到输出节点,最后给出输出结果。
节点的作用的激励函数通常选取S 型函数,如Qx e x f /11)(-+=式中Q 为调整激励函数形式的Sigmoid 参数。
该算法的学习过程由正向传播和反向传播组成。
在正向传播过程中,输入信息从输入层经隐含层逐层处理,并传向输出层。
每一层神经元的状态只影响下一层神经元的状态。
如果输出层得不到期望的输出,则转入反向传播,将误差信号沿原来的连接通道返回,通过修改各层神经元的权值,使得误差信号最小。
社含有n 个节点的任意网络,各节点之特性为Sigmoid 型。
为简便起见,指定网络只有一个输出y ,任一节点i 的输出为O i ,并设有N 个样本(x k ,y k )(k =1,2,3,…,N ),对某一输入x k ,网络输出为y k 节点i 的输出为O ik ,节点j 的输入为net jk =∑i ik ij O W 并将误差函数定义为∑=-=N k k k y y E 12)(21其中k y 为网络实际输出,定义E k =(y k -ŷk )2, jk kjk E net ∂∂=δ,且O jk =f (net jk ),于是ik jk k ij jk jk k ij k O E W E W E net net net ∂∂=∂∂∂∂=∂∂=δjk O ik当j 为输出节点时,O jk =ŷk)net ()(net jk k k jk k k k jk f y y y y E '--=∂∂∂∂= δ (34.1)若j 不是输出节点,则有∑∑∑∑∑∑=∂∂=∂∂∂∂=∂∂∂∂=∂∂'∂∂=∂∂∂∂=∂∂=m i m mj mk mj mk k m iik mi jk mk k m jkmk mk k jk k jk jkk jk jk jk k jk k jk W W E O W O E O E O E f O E O O E E δδnet net net net )net (net net 因此⎪⎩⎪⎨⎧=∂∂'=∑ik mk ij k m mj mk jk jk O W E W f δδδ)net ( (34.2)如果有M 层,而第M 层仅含输出节点,第一层为输入节点,则BP 算法为:第一步,选取初始权值W 。
第二步,重复下述过程直至收敛:a. a. 对于k =1到Na ). 计算O ik , net jk 和ŷk 的值(正向过程);b ). 对各层从M 到2反向计算(反向过程);b. b. 对同一节点j ∈M ,由式(34.1)和(34.2)计算δjk ;第三步,修正权值,W ij =W ij -μij W E ∂∂, μ>0, 其中∑∂∂=∂∂N k ij kij W E W E 。
从上述BP 算法可以看出,BP 模型把一组样本的I/O 问题变为一个非线性优化问题,它使用的是优化中最普通的梯度下降法。
如果把神经网络的看成输入到输出的映射,则这个映射是一个高度非线性映射。
设计一个神经网络专家系统重点在于模型的构成和学习算法的选择。
一般来说,结构是根据所研究领域及要解决的问题确定的。
通过对所研究问题的大量历史资料数据的分析及目前的神经网络理论发展水平,建立合适的模型,并针对所选的模型采用相应的学习算法,在网络学习过程中,不断地调整网络参数,直到输出结果满足要求。
第2节DPS数据处理系统操作步骤在DPS数据处理系统中,数据的输入格式是一行为一个样本,一列为一个变量,输入节点(变量)放在数据块左边,输出节点(因变量)放在数据块右边,输完一个样本后再输下一个样本。
对于待识别(预测)的样本,不需要输入输出变量(因变量)。
数据输入完毕后,定义数据块。
如有待识别(预测)的样本,可在按下Ctrl键时再按下并拖动鼠标,将待预测的样本定义成第二个数据块。
在进行神经网络学习之前,系统出现如图34-2所示界面,这时需要你提供若干参数,各个参数取值的基本原则是:图34-2 神经网络参数设置对话框网络参数确定原则:①、网络节点网络输入层神经元节点数就是系统的特征因子(自变量)个数,输出层神经元节点数就是系统目标个数。
隐层节点选按经验选取,一般设为输入层节点数的75%。
如果输入层有7个节点,输出层1个节点,那么隐含层可暂设为5个节点,即构成一个7-5-1 BP神经网络模型。
在系统训练时,实际还要对不同的隐层节点数4、5、6个分别进行比较,最后确定出最合理的网络结构。
②、初始权值的确定初始权值是不应完全相等的一组值。
已经证明,即便确定存在一组互不相等的使系统误差更小的权值,如果所设W ji的的初始值彼此相等,它们将在学习过程中始终保持相等。
故而,在程序中,我们设计了一个随机发生器程序,产生一组一0.5~+0.5的随机数,作为网络的初始权值。
③、最小训练速率在经典的BP算法中,训练速率是由经验确定,训练速率越大,权重变化越大,收敛越快;但训练速率过大,会引起系统的振荡,因此,训练速率在不导致振荡前提下,越大越好。
因此,在DPS中,训练速率会自动调整,并尽可能取大一些的值,但用户可规定一个最小训练速率。
该值一般取0.9。
④、动态参数动态系数的选择也是经验性的,一般取0.6 ~0.8。
⑤、允许误差一般取0.001~0.00001,当2次迭代结果的误差小于该值时,系统结束迭代计算,给出结果。
⑥、迭代次数一般取1000次。
由于神经网络计算并不能保证在各种参数配置下迭代结果收敛,当迭代结果不收敛时,允许最大的迭代次数。
⑦、Sigmoid参数该参数调整神经元激励函数形式,一般取0.9~1.0之间。
⑧、数据转换。
在DPS系统中,允许对输入层各个节点的数据进行转换,提供转换的方法有取对数、平方根转换和数据标准化转换。
第3节应用实例原始数据整理:本例令影响棉铃虫发生程度的因素指标集序列由麦田1代幼虫量、6月降水天数、5月积温、6月积温、5月相对湿度、5月降水天数和6月相对湿度等7个生态和生物因子构成,2代发生程度按照全国植保站颁发的标准分级,并规定发生程度重、偏重、中、偏轻和轻分别赋值为0.9、0.7、0.5、0.3和0.1。
在建立BP神经网络模型时,取1982~1991年的数据作为学习、训练样本,1992和1993年为试报样本。
在数据分析前将数据定义成数据块(图34-3).图34-3 BP神经网络数据编辑定义示意图进入BP神经网络训练时, 系统会显示如图34-3所示界面。
这时我们可按网络的结构确定网络的参数,这里输入层节点数为7,隐含层1层,最小训练速率取0.1,动态参数0.7,Sigmoid参数为0.9, 允许误差0.00001,最大迭代次数1000。
并对输入节点的数值进行标准化转换。
点击“确定”按钮后,设置隐层的神经元个数(这里取5),运行1000次后,样本误差等于0.0001427。
输出各个神经元(节点)的权值如下:第1隐含层各个结点的权重矩阵1.6327102.4498203.089710 0.2127105.3923701.6274202.600110 1.987550 5.2404103.1461801.7438302.056300 5.238480 0.550590学习样本的拟合值和实际观察值, 以及根据BP神经网络对1992、1993年2代棉铃虫发生程度进行预测的结果与实际值的比较列于表34-1。
结果表明,应用BP神经网络进行二代棉铃虫发生程度预测,不仅历史资料的拟合率高,而且2年的试报结果与实际完全符合。
表34-1 神经元网络训练结果及试报结果年份19821983 1984 1985 1986 1987训练输出值0.69970.89520.50040.3000.8900.1014实际值0.70000.90000.5000.3000.9000.100年份19881989 1990 1991 1992 1993训练输出值0.88620.50110.70260.87330.8955*0.8985*实际值0.90000.50000.7000.9000.9000.9000 *1992~1993年为试报结果。