生物统计学3-抽样分布4-ok
- 格式:pdf
- 大小:1.43 MB
- 文档页数:26

抽样分布知识点总结抽样分布是统计学中一个重要的概念,它描述了在进行抽样时得到的样本统计量的分布情况。
抽样分布是统计推断的基础,它可以帮助我们理解抽样误差以及估计参数的可信度。
在本文中,我们将对抽样分布的基本概念、性质和相关理论进行总结和讨论。
一、基本概念1.1 抽样与总体在统计学中,总体是指我们想要研究的所有个体的集合,而抽样则是从总体中选取一部分个体作为样本,以获得对总体特征的估计。
抽样可以是随机抽样、分层抽样、系统抽样等方法,目的是代表性地反映总体的特征。
1.2 样本统计量在抽样中,对样本数据进行统计分析得到的统计量称为样本统计量,常见的样本统计量有均值、方差、标准差、比例等。
样本统计量能够提供有关总体参数的估计和推断。
1.3 抽样分布抽样分布是描述样本统计量的分布情况的统计学概念。
当我们从总体中抽取多个样本,并计算每个样本的统计量时,得到的这些统计量的分布就是抽样分布。
抽样分布可以反映出样本统计量的可变性、偏移和分布形态等特征。
二、性质2.1 中心极限定理中心极限定理是抽样分布理论中的重要定理,它描述了在一定条件下,样本均值的抽样分布近似服从正态分布。
中心极限定理对于理解抽样分布的性质和应用具有重要意义,也为许多统计推断方法提供了理论基础。
2.2 大数定律大数定律是另一个重要的抽样分布性质,它描述了当样本容量足够大时,样本均值会收敛于总体均值,即样本均值的抽样分布会集中在总体均值附近。
大数定律为我们理解样本统计量的稳定性和准确性提供了重要参考。
2.3 置信区间置信区间是根据抽样分布推断总体参数的一种方法,通过对抽样分布的分布情况进行分析,我们可以建立对总体参数的置信区间,从而对总体特征进行推断。
置信区间对于统计推断的可信度和精度有着重要的作用。
三、理论基础3.1 样本容量样本容量是影响抽样分布的一个重要因素,在实际抽样中,样本容量的大小对于样本统计量的分布情况有着重要的影响。
通常情况下,样本容量越大,抽样分布的稳定性和准确性越高。







统计学中的抽样分布和抽样误差统计学是一门研究数据收集、处理和分析的学科,而在进行统计分析时,抽样是一项重要的技术。
抽样分布和抽样误差是统计学中关键的概念,本文将具体介绍它们的定义、特点和应用。
一、抽样分布在统计学中,抽样分布指的是从总体中抽取样本的过程中得到的样本统计量的概率分布。
样本统计量可以是样本均值、样本方差等。
抽样分布是由大量不同的样本所形成的,它们具有一定的数学特性。
抽样分布的特点有:1. 抽样分布的中心趋向于总体参数。
当样本容量足够大时,抽样分布的中心会接近总体参数的真值。
2. 抽样分布的形状可能与总体分布相同,也可能近似于正态分布。
中心极限定理是解释抽样分布接近正态分布的重要定理。
3. 样本容量越大,抽样分布的方差越小。
样本容量增大,抽样误差减小。
抽样分布在实际应用中具有重要价值。
通过了解抽样分布的性质,我们可以进行假设检验、构建置信区间以及进行参数估计等统计推断。
二、抽样误差抽样误差是指由于从总体中抽取样本而导致的估计值与总体参数值之间的差异。
它是统计推断中常见的误差来源,也是统计分析中需要控制的重要因素。
抽样误差的大小受到多个因素的影响,包括样本容量、总体变异性以及抽样方法等。
通常情况下,样本容量越大,抽样误差越小,因为更大的样本容量能够更好地代表总体。
为了降低抽样误差,我们可以采取以下策略:1. 增加样本容量。
增大样本容量可以减小抽样误差,提高估计值的准确性。
2. 采用随机抽样方法。
随机抽样可以降低抽样误差,确保样本的代表性。
3. 控制变异性。
尽量减少总体的变异性,可以减小抽样误差。
抽样误差的存在对于统计推断的可靠性有着重要的影响。
在进行数据分析和解释时,我们需要正确理解抽样误差的概念,并将其考虑在内。
总结:统计学中的抽样分布和抽样误差是进行统计推断不可或缺的概念。
抽样分布是样本统计量的概率分布,具有一定的数学特性,可以用于进行假设检验和置信区间估计。
抽样误差是由于从总体中抽取样本而导致的估计值与总体参数值之间的差异,它的大小受到多个因素的影响。


概论名词:生物统计:将概率论和数理统计的原理应用到生物学中以分析和解释其数量资料的科学试验设计:试验工作未进行之前应用生物统计原理,来制定合理的试验方案,包括选择动物,分组和对比以及相应的资料搜集整理和统计分析的方法。
总体与样本⏹数据具有不齐性。
⏹根据研究目的确定的研究对象的全体称为总体(population);⏹含有有限个个体的总体称为有限总体;⏹包含有无限多个个体的总体叫无限总体;⏹总体中的一个研究单位称为个体(individual);⏹从总体中随机抽出一部分具有代表性的个体称为样本(sample);⏹样本中所包含的个体数目叫样本容量或大小,常记为n。
⏹通常把n≤30的样本叫小样本,n >30的样本叫大样本。
随机抽取(random sampling) 的样本是指总体中的每一个个体都有同等的机会被抽取组成样本。
变数与变异数列、变量:⏹变数:研究中对样本个体的观察值。
⏹变量:相同性质的事物间表现差异性的某种特征。
如:身高、体重。
⏹变异数列:将变数按从小到大的顺序排列的一组数列。
参数与统计量⏹由总体计算的特征数叫参数(parameter);⏹由样本计算的特征数叫统计量(staistic)。
准确性与精确性⏹准确性(accuracy)也叫准确度,指观测值与其真值接近的程度。
若x与μ相差的绝对值|x-μ|小,则观测值x的准确性高;反之则低。
⏹精确性(precision)也叫精确度,指重复观测值彼此接近的程度。
若观测值彼此接近,即任意二个观测值xi、xj相差的绝对值|xi -xj |小,则观测值精确性高;反之则低。
⏹调查或试验的准确性、精确性合称为正确性。
由于真值μ常常不知道,所以准确性不易度量,但利用统计方法可度量精确性。
随机误差与系统误差随机误差也叫抽样误差(sampling error) ,是由于许多无法控制的内在和外在的偶然因素所造成。
带有偶然性质,在试验中,即使十分小心也难以消除。
随机误差影响试验的精确性。
生物统计学1.总体:我们研究的全部对象2.样本:从总体中抽出的一个部分3.方差:4.对立事件:如果事件A1和A2必发生其一,但不能同时发生,我们称事件A1和A2为对立事件。
5.小概率事件:若随机事件的概率很小,例如小于0.05、0.01、0.001,称之小概率事件。
6.小概率事件:原理小概率事件在一次试验中几乎是不会发生的。
若根据一定的假设条件计算出来该事件发生的概率很小,而在一次试验中竟然发生了,则可以认为假设的条件不正确,从而否定假设。
7.抽样分布:从一个已知的总体中,独立随机地抽取含量为 n 的样本,研究所得样本的各种统计量的概率分布。
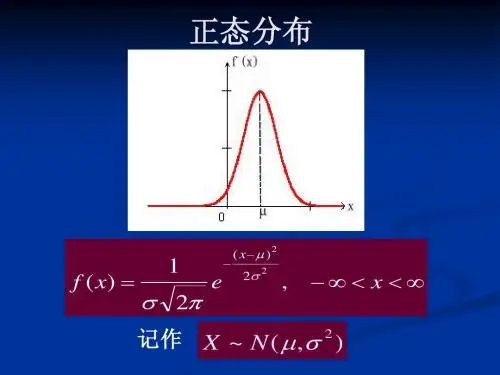
8.标准正态分布:期望值μ=0,即曲线图象对称轴为Y 轴,标准差σ=1条件下的正态分布,记为N(0,1)。
9.统计推断:根据抽样分布律和概率理论,由样本结果(统计数)来推论总体特征(参数)。
10.单尾测验:否定区位于分布的一尾的测验。
11.备择假设:与零假设相对立的假设称为备择假设。
12.接受区:接受无效假设的区间。
13.数学期望:随机变量Y 或者Y 的函数的理论平均数。
14.点估计:用样本数据所计算出来的单个数值,对总体参数所做的估计称为点估计1.算术平均数的重要特征之一是离均差之和( C )A 最小B 最大C 等于零D 接近零2.统计推断过程中,若我们拒绝H0,则( C )A 犯α错误B 犯β错误C 犯α错误或不犯错误D 犯β错误或不犯错误3.两个平均数的假设测验用测验。
( C )A uB tC u 或tD F4.总体参数在区间[L1,L2]内的概率为1-α,其中L1和L2在统计上称为( D )A 置信区间B 区间估计C 置信距D 置信限5.下列不是方差分析基本假定的是假定。
( C )A 可加性B 正态性C 无偏性D 同质性6.人口调查中,以人口性别所组成的总体是( C )总体A 正态分布B 对数正态C 二项分布D 指数分布7.下列有关标准正态分布概率公式的计算中错误的是( D )A P (0<u</uB P (U>u )=f (-u)C P (| U| > u )= 2 f (-u)D P (u1<u<="" -="" =="" bdsfid="119" f="" p=""></u8.在抽样分布的研究中,当总体标准差σ未知时样本平均数分布服从( B )分布。