分析化学中的误差和分析数据的处理
- 格式:pdf
- 大小:93.75 KB
- 文档页数:10

分析化学实验中误差及分析数据的处理精讲误差在分析化学实验中扮演着非常重要的角色,它们可以帮助我们评估实验结果的可靠性和精确性。
本文将讨论实验误差的几种类型以及分析数据的处理方法。
首先,我们来看一下误差的分类。
实验误差可以分为系统误差和随机误差两种类型。
系统误差是由于实验设计或仪器故障等原因引起的,并且在多次实验中总是出现相同的偏差。
例如,如果使用的仪器的刻度有错误,或者实验操作中有不可避免的偏差,都会导致系统误差。
这种误差通常是可预测和可修正的,但需要在实验设计和执行过程中加以注意。
为了减小系统误差,我们可以使用标准校正曲线、多次测量和仪器校正等方法。
随机误差是由于实验条件或观察者等因素的变动引起的,并且在多次实验中会出现不同的偏差。
随机误差是不可预测的,它们可以通过多次重复实验来减小,同时使用统计学方法来估算其大小。
例如,如果我们多次测量同一样品的溶解度,由于溶解度的测量值会受到环境温度和湿度等因素的影响,每次测量的结果都会有所不同,这就是随机误差。
在实验数据的处理中,我们需要考虑误差的大小和如何将其纳入计算。
下面是一些常见的数据处理方法:1.均值:计算重复测量值的平均值。
这将有助于减小随机误差,并提供更可靠的结果。
对于有系统误差的情况,可以使用校正因子将均值修正为真实值。
2.方差:计算重复测量值的离散程度。
方差越大,数据的可靠性越低。
方差可以通过计算每个测量值与均值的差的平方,并将这些差值求和后除以测量次数来得到。
3.标准偏差:标准偏差是对方差的开方,它衡量了测量结果的均匀性。
标准偏差越小,数据的可靠性越高。
标准偏差可以通过方差的平方根来计算。
4.置信区间:置信区间是对测量结果的不确定性进行估计的方法。
通过构建一个置信区间,我们可以确定结果可能出现的范围。
置信区间的计算需要考虑样本大小、方差和置信水平等因素。
总之,分析化学实验中的误差是不可避免的,但我们可以通过合适的实验设计和数据处理方法来减小和评估误差的大小。









分析化学中的误差与数据处理分析化学中的误差与数据处理分析化学是科学领域中的一门重要学科,主要涉及物质的定性、定量分析,其结果的准确性对于科研和实际应用具有重要意义。
然而,由于各种因素的影响,分析结果中不可避免地存在误差。
因此,了解误差的来源和处理方法是保证分析化学结果准确性的关键。
一、误差概念误差是指分析结果与真实值之间的差异。
在分析化学中,误差分为系统误差和随机误差。
系统误差是由固定因素引起的,如仪器校准偏差或试剂不纯等,通常需要进行补偿或校正。
随机误差则是由于随机因素引起的,如环境温度和湿度波动等,这种误差通常是无法避免的。
二、数据处理方法1、数据分析:对实验获取的数据进行统计分析,如平均值、标准差、置信区间等,以评估数据的集中程度和离散程度。
2、统计推断:通过样本数据推断总体特征,如假设检验和方差分析等,以判断实验条件是否满足分析要求。
3、数据处理技术:如平滑滤波、微分分析、积分分析等,用于消除数据中的噪声或提取特征信息。
三、减少误差的方法1、选择合适的试剂和设备:使用高纯度试剂和精确的测量设备,有助于降低系统误差。
2、增加重复次数:通过多次实验取平均值,能够降低随机误差,提高结果的准确性。
3、标准化:通过标准物质的测定以及与标准方法的比对,能够发现和纠正系统误差。
4、校准:对仪器进行定期校准,确保仪器性能稳定,从而降低误差。
四、结论误差与数据处理在分析化学中具有重要意义。
了解误差来源和处理方法有助于提高分析结果的准确性。
通过选择合适的试剂和设备、增加重复次数、标准化和校准等措施,可以有效地降低误差,提高分析结果的准确性。
未来,随着科学技术的不断发展,分析化学中的误差与数据处理方法将会更加完善。
研究人员将继续探索新的方法和技术,以进一步提高分析结果的准确性。
加强分析化学教育和实践,培养专业人才,对于推动分析化学的发展和应用具有重要意义。
总之,误差与数据处理是分析化学中不可或缺的环节。
通过了解误差来源和处理方法,采取有效措施降低误差,可以提高分析结果的准确性,为科学研究和实际应用提供可靠支持。
分析化学实验中误差及分析数据处理误差及分析数据处理在分析化学实验中起着至关重要的作用。
误差是指测量结果和真实值之间的差异,是无法避免的。
因此,在实验中正确评估和处理误差至关重要。
同时,对实验数据进行合理的分析也能提高实验结果的可靠性和准确性。
在分析化学实验中,误差可以分为系统误差和随机误差两种。
随机误差是指由于各种因素的不可避免的影响而导致的测量结果的变化,在统计学上符合正态分布。
随机误差不能通过提高仪器的准确度或操作方法来消除,但可以通过多次重复测量来减小其影响。
在实验中,通常我们使用平均值和标准偏差来描述数据的中心位置和离散程度,以量化随机误差的大小。
在评估和处理误差时,可以采取以下几个步骤:1.确定实验目的和测量对象:明确需要测量的物质及其性质,以及实验目的和要求。
2.选择合适的仪器和方法:根据实验要求和精度要求,选择准确度和灵敏度适当的仪器和方法进行测量。
3.进行仪器的校准和质量控制:在开始实验之前,对仪器进行校准,确保其测量准确性;同时进行质量控制,确保实验过程中的可重复性和可靠性。
4.重复测量和数据处理:进行多次重复测量,取平均值并计算标准偏差,以评估结果的准确性和可靠性。
5.误差分析和不确定度评定:通过误差传递法则,评估各个误差源对最终结果的贡献,并计算出合适的不确定度范围。
不确定度反映了测量结果的可靠程度,可以用于判断实验结果是否符合要求。
在数据处理方面,可以采取以下几个方法:1.数据整理和排序:将测量数据整理为合适的格式,并按大小排序,以便后续处理。
2.均值计算和误差分析:根据重复测量的结果,计算出平均值和标准偏差,并进行误差分析。
3.数据可视化和统计分析:使用适当的图表或图形展示数据分布情况,并进行统计分析,如计算相关系数、回归方程等。
4.结果判断和推导:根据对数据的分析和处理结果,判断实验结果是否符合预期,是否满足实验目的。
在结果推导时,可以利用统计学方法进行数据拟合和求解。
分析化学中的误差及分析数据的处理分析化学中的误差及分析数据的处理第⼆章分析化学中的误差及分析数据的处理本章是分析化学中准确表达定量分析计算结果的基础,在分析化学课程中占有重要的地位。
本章应着重了解分析测定中误差产⽣的原因及误差分布、传递的规律及特点,掌握分析数据的处理⽅法及分析结果的表⽰,掌握分析数据、分析⽅法可靠性和准确程度的判断⽅法。
本章计划7学时。
第⼀节分析化学中的误差及其表⽰⽅法⼀. 误差的分类1. 系统误差(systematic error )——可测误差(determinate error) (1)⽅法误差:是分析⽅法本⾝所造成的;如:反应不能定量完成;有副反应发⽣;滴定终点与化学计量点不⼀致;⼲扰组分存在等。
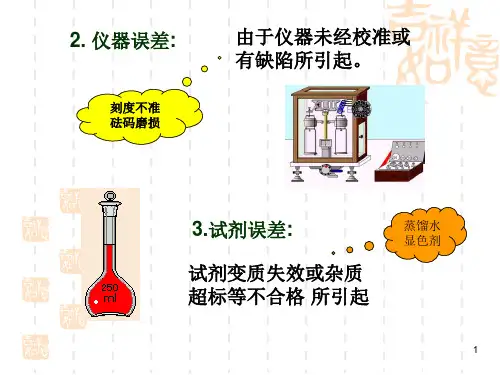
(2)仪器误差:主要是仪器本⾝不够准确或未经校准引起的;如:量器(容量平、滴定管等)和仪表刻度不准。
(3)试剂误差:由于试剂不纯和蒸馏⽔中含有微量杂质所引起; (4)操作误差:主要指在正常操作情况下,由于分析⼯作者掌握操作规程与控制条件不当所引起的。
如滴定管读数总是偏⾼或偏低。
特性:重复出现、恒定不变(⼀定条件下)、单向性、⼤⼩可测出并校正,故有称为可定误差。
可以⽤对照试验、空⽩试验、校正仪器等办法加以校正。
2. 随机误差(random error)——不可测误差(indeterminate error)产⽣原因与系统误差不同,它是由于某些偶然的因素所引起的。
如:测定时环境的温度、湿度和⽓压的微⼩波动,以其性能的微⼩变化等。
特性:有时正、有时负,有时⼤、有时⼩,难控制(⽅向⼤⼩不固定,似⽆规律)但在消除系统误差后,在同样条件下进⾏多次测定,则可发现其分布也是服从⼀定规律(统计学正态分布),可⽤统计学⽅法来处理。
⼆. 准确度与精密度(⼀)准确度与误差(accuracy and error)准确度:测量值(x)与真值(,)之间的符合程度。
它说明测定结果的可靠性,⽤误差值来量度:绝对误差 = 个别测得值 - 真实值E=x- , (1) a但绝对误差不能完全地说明测定的准确度,即它没有与被测物质的质量联系起来。
第一章 分析化学中的误差和分析数据的处理教学要求:1、了解误差的意义和误差的表示方法2、了解定量分析处理的一般规则3、掌握有效数字表示法和运算规则重点、难点:误差的表示方法随机误差的正态分布有效数字及运算规则教学内容:第一节 分析化学中的误差一、误差:测定结果与待测组分的真实含量之间的差值。
二、分类:㈠、系统误差:由某些确定的、经常性的原因造成的。
在重复测定中,总是重复出现,使测定结果总是偏高或偏低1、特点:重现性:在相同的条件下,重复测定时会重复出现单向性:测定结果系统偏高或偏低可测性:数值大小有一定规律2、原因:① 方法误差② 仪器和试剂误差③ 操作误差㈡、随机误差(偶然误差):有不固定的因素引起的,是可变的,有时大,有时小,有时正,有时负。
1、特点:符合正态分布2、规律:对称性:绝对值相同的正、负误差出现的几率相等;单峰性:小误差出现的几率大,大误差出现的几率小。
很大的误差出现的几率近于零;有界性:随机误差的分布具有有限的范围,其值大小是有界的,并具有向μ集中的趋势。
第二节 测定值的准确度与精密度以准确度与精密度来评价测定结果的优劣一、准确度与误差:1、准确度:真值是试样中某组分客观存在的真实含量。
测定值X与真值T相接近的程度称为准确度。
测定值与真值愈接近,其误差(绝对值)愈小,测定结果的准确度愈高。
因此误差的大小是衡量准确度高低的标志。
2、表示方法:绝对误差:E a ===x-T(如果进行了数次平行测定,X为平均值) 相对误差:E r ===100×TE a% 3、误差有正、负之分。
当测定值大于真值时误差为正值,表示测定结果偏高; 当测定值小于真值时误差为负值,表示测定结果偏低; 二、精密度与偏差1、精密度:一组平行测定结果相互接近的程度称为精密度2、表示方法:用偏差表示如果测定数据彼此接近,则偏差小,测定的精密度高; 如果测定数据分散,则偏差小,测定的精密度低; ⑴、绝对偏差、平均偏差和相对平均偏差:绝对偏差:d i =x i -(i=1,2,…,n) −x 平均偏差:d =nd d d n±±±…21=∑=ni i d n 11相对平均偏差:d r =100×xd%⑵、标准偏差和相对标准偏差总体:一定条件下无限多次测定数据的全体 样本:随机从总体中抽出的一组测定值称为样本样本容量:样本中所含测定值的数目称为样本的大小或样本容量。
若样本容量为n,平行测定数据为x 1、x 2、 …、x n ,则此样本平均值为x=∑i x n1当测定次数无限多时,所得的平均值即总体平均值μx n ∞→lim =μ当测定次数趋于无限时,总体标准偏差σ表示了各测定值x 对总体平均值μ的偏离程度:σ=nxi∑−2)(µ σ2称为方差但一般情况下μ是不知道的,故只有采用样本标准偏差来衡量该组数据的精密度,从而表示各测定值对样本平均值的偏离程度。
样本的标准偏差:S =11)(22−=−−∑∑n d n x x iin-1称为自由度,用f 表示。
标准偏差比平均偏差能更灵敏地反映数据的精密度。
P 47例 两组数据:9.6,9.7,9.7,9.8,10.0,10.1,10.2,10.2,10.3,10.4; 9.3,9.8,9.8,9.9,9.9,10.0,10.1,10.2,10.3,10.5。
样本的相对标准偏差(变异系数):S r = %100×xs⑶、平均值的标准偏差:多个样本测定,平均值的精密度比单次测定值的更高。
用平均值的标准偏差来衡量平均值的标准偏差:nx σσ=(∞→n )对于有限次数的测定则: S x =ns 样本平均值的标准偏差由上式可知:增加测定次数可以减小随机误差的影响,提高测定的精密度。
⑷、极差:又称全距,是测定数据中的最大值与最小值之差。
R=x max -x min其值愈大表明测定值愈分散。
三、准确度与精密度的关系:系统误差影响测定的准确度,而随机误差对精密度和准确度均有影响;评价测定结果的优劣,要同时衡量其准确度和精密度。
精密度高,准确度不一定高; 准确度高,精密度必然高。
第三节 随机误差的正态分布一、频率分布:1、频数:测定值落在每组内的个数。
2、频率(相对频数):数据出现在各组内的频率。
即频数与样本容量之比。
3、测定值出现在平均值附近的频率相当高,具有明显的集中趋势。
4、频率分布图显示了测定数据既有分散性而又具有集中趋势的分布特性。
二、正态分布:㈠、正态分布的特点:又称高斯分布,它的数学表达式即正态分布概率密度函数式为y=f(x)=22221σµπσ)(−−x ey表明测定次数趋于无限时,测定值x i 出现的概率密度若以x 值表示横坐标,y 值表示纵坐标,就得到测定值的正态分布曲线。
曲线分析:1、曲线有最高点,它对应的横坐标值µ即为总体平均值。
2、µ的数值决定了正态分布曲线在横坐标上的位置,反映了来自某一总体的测定值向某具体数值集中的趋势。
3、σ为总体标准偏差,是曲线两侧的拐点之一到直线x=µ的距离,它表征了测定值的分散程度。
4、σ值越小,表明测定值位于µ附近的概率越大,测定的精密度越高; σ值越大,表明测定值位于µ附近的概率越小,测定的精密度越低; 综上所述:一旦σ和µ确定后,正态分布曲线的位置和形状也就确定了,因此σ和µ是正态分布的两个基本参数,这种正态分布用N()表示。
2,σµ㈡、定量分析中,来自同一总体的随机误差一般也是服从正态分布的。
正态分布曲线关于直线x=µ呈钟形对称,形象地反映了随机误差具有以下的特点和规律:(随机误差的分布规律)1、对称性:绝对值相同的正、负误差出现的几率相等2、单峰性:小误差出现的几率大,大误差出现的几率小。
很大的误差出现的几率近于零3、有界性:随机误差的分布具有有限的范围,其值大小是有界的,并具有向μ集中的趋势。
三、标准正态分布:将正态分布曲线的横坐标改用u 来表示(以σ为单位表示随机误差)u=σµχ− (u 的定义式) 将上式代入高斯方程并微分得f(x)dx=du u du eu )(ϕπ=−2221u 称为标准正态变量,那麽高斯方程即转化为 y=2221u eu −=πϕ)(结论:总体平均值为µ、总体标准偏差为σ得任一正态分布均可化为µ=0,σ2=1的标准正态分布,以N(0,1)表示。
曲线的形状与µ和σ的大小无关。
四、随机误差的区间概率 概率积分表:正态分布曲线与横坐标之间所夹的总面积,就等于概率密度函数从-∞至+∞的积分值。
它表示来自同一总体的全部测定值或随机误差在上述区间出现概率的总和为100%,即为1。
du edu u u ∫∫∞+∞−−∞+∞−=2221πϕ)(=1欲求测定值或随机误差在某区间出现的概率P,可取不同的u 值对上式积分求面积而得到,从而可得到概率积分表供直接查用。
若区间为u ±值,则应将所查得的值乘以2。
第四节 有限测定数据的统计处理一、置信度与μ的置信区间1、置信区间:根据有限的测定结果来估计μ可能存在的范围 测量值所在±µu σ的范围称为置信区间。
该范围愈小,说明测定值与μ愈接近,即测定的准确度愈高。
2、置信度:置信区间不可能以百分之百的把握将μ包含在内,有一定的概率。
测量值落在±µu σ范围内的概率称为置信度。
㈠、已知总体标准偏差σ时x=±µu σ 由u 值则确定不同的区间概率。
1、如果用单次测定值来估计 μ可能存在的范围,则可以认为区间x±1.96σ能以0.95的概率将真值包含在内。
即 μ= x±u σ2、以样本平均值表示(因平均值较单次测定值的精密度更高),则μ=x nux u x σσ±=±3、上述两式分别表示了在一定的置信度时,以单次测定值x 或以平均值x 为中心的包含真值的取值范围,即μ的置信区间。
在置信区间内包含μ的概率称为置信度,它表明了人们对所作的判断有把握的程度,由P 表示。
4、在对真值进行区间估计时,置信度的高低要定得恰当。
在定量分析中,一般将置信度定为0.95或0.90。
5、置信区间的大小取决于测定的精密度和对置信度的选择,对于平均值来说还与测定的次数有关。
当σ一定时,置信度定的愈大,u 值愈大,即置信区间也愈大,过大的置信区间将使其失去实际意义。
若将置信度固定,当测定的精密度越高和测定次数越多时,置信区间越小,表明x 或x 越接近真值,即测定的准确度越高。
㈡、已知样本标准偏差s 时:1、t 分布:由英国统计学家兼化学家戈塞特(Gosset W S)在1908年提出。
当时他采用的笔名为student,故称为t 分布法。
t p,f =sµχ−(其中t p,f 是随置信度P和自由度f而变化的统计量)t 分布是有限测定数据及其随机误差的分布规律。
随着测定次数增加,t 分布曲线愈来愈陡峭,测定值的集中趋势亦更加明显。
当f→∞时,t 分布曲线就与正态分布曲线合为一体,因此可以认为标准正态分布就是t 分布的极限。
3、t 值的计算值:t 值与标准正态分布中的u 值不同,它不仅与概率还与测定次数有关。
随着自由度的增加,t 值逐渐减小并与u 值接近。
当f=20时,t 与u 已经比较接近。
当f→∞时,t→u,s→σ。
3、计算公式:① μ= x±t p,f s② μ= x±t p,f s x =μ= x±t p,fn s由上式可知,P一定时,置信区间的大小与t p,f 、s、n均有关,而且t p,f 与s实际也都受n的影响,即n值越大,置信区间越小。
二、可疑测定值的取舍 1、可疑值:在平行测定的数据中,有时会出现一二个与其它结果相差较大的测定值,称为可疑值或异常值(离群值、极端值) 2、方法㈠、Q 检验法:由迪安(Dean)和狄克逊(Dixon)在1951年提出。
步骤:1、将测定值由小至大按顺序排列:x 1,x 2,x 3,…x n-1,x n ,其中可疑值为x 1或x n 。
2、求出可疑值与其最邻近值之差x 2-x 1或x n -x n-1。
3、用上述数值除以极差,计算出QQ=11χχχχ−−−n n n 或Q=112χχχχ−−n4、根据测定次数n和所要求的置信度P查Q p,n 值。
(分析化学中通常取0.90的置信度)5、比较Q和Q p,n 的大小:若Q>Q p,n ,则舍弃可疑值;若Q<Q p,n ,则保留可疑值。
中位数:将全部测定值按大小顺序排列,当n 为奇数时,位于正中间的数值即为中位值;当n 为偶数时,中位数为正中间两数的平均值。