多层线性模型简介两水平模型
- 格式:ppt
- 大小:287.00 KB
- 文档页数:38
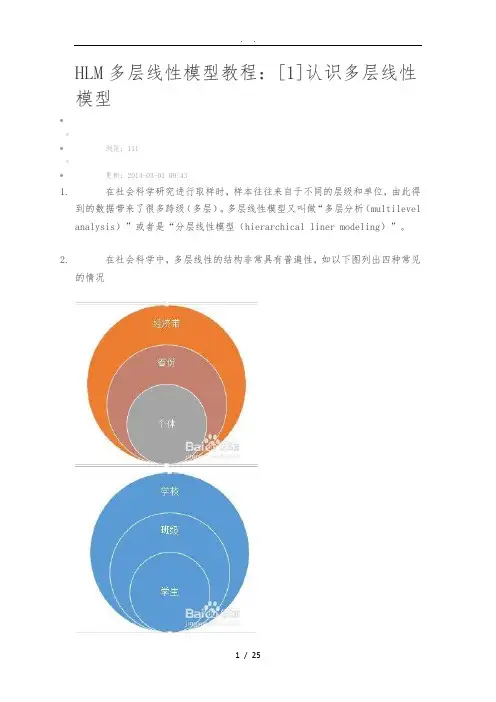
HLM多层线性模型教程:[1]认识多层线性模型••|•浏览:111•|•更新:2014-03-01 09:431.在社会科学研究进行取样时,样本往往来自于不同的层级和单位,由此得到的数据带来了很多跨级(多层)。
多层线性模型又叫做“多层分析(multilevel analysis)”或者是“分层线性模型(hierarchical liner modeling)”。
2.在社会科学中,多层线性的结构非常具有普遍性,如以下图列出四种常见的情况3.拿两层举例子,假如说现在我们考察学生自我效能感对学生成绩的影响,在204.所学校中抽取了1000名学生,那么很有可能的情况就是有些学校学生的自我效能感平均值较高,而这就有可能是因为学校为贵族学校,学生的经济水平很高。
而也可能有民工学校,经济水平较低,自我效能感普遍较低。
那么这就存在一种情况就是学生的成绩受到学生个体的自我效能感影响,而每个学校的自我效能感可能与整个学校的整体经济水平有关。
那么这就是学生嵌套在学校之间的例子。
5.多层线性模型的基本公式6.拿上面的例子我们可以写出对于这个案例的多层线性模型。
第一层:学生成绩=β0+β1*学生自我效能感+r第二层:β0=γ00+γ01*学校社会经济生活水平+μ1β1=γ10+γ11*学校社会经济生活水平+μ27.那么对于这样一类的多层线性的数据,我们该如何进行数据处理呢,小编将持续为大家呈现与讲解。
原delta数据工作室HLM多层线性模型教程:[3]认识HLM6.0界面••|•浏览:186•|•更新:2014-03-04 09:44•••••••分步阅读采用HLM6.0分析多层线性模型能够非常直观的建立方程式,每层变量清晰明了,使用界面友好简洁。
下面我将为大家介绍HLM 6.0的主界面,并告诉大家各界面的主要功能。
工具/原料•HLM6.0方法/步骤1.我们打开HLM的主界面,最上面的工具栏就是我们用到的主要菜单,首先file下面我们可以创建新的hlm/mdtm文件(hlm中最重要的文件),如以下图,假如我们已经建立好了HLM的MDM文件,那么我们在下次打开的时候需要选择"make new mdm from old mdm files",HLM不能直接打开之前的文件,可以从之前的MDM文件中运行。


多层线性模型:HLM(hierarchical linear model)计量模型,为解决传统统计方法如回归分析在处理多层嵌套数据时的局限而产生的,是目前国际上较前沿的一套社会科学数据分析的理论和方法,优势体现两个方面:一是解决了数据嵌套问题;二是为追踪研究或重复测量研究引入了新方法。
传统的线性模型,例如,ANOV A或者回归分析,只能对涉及某一层数据的问题进行分析,而不能将涉及两层或多层数据的问题进行综合分析,而多层线性模型对解决这些问题提供了有效的统计方法。
多层线性模型的参数估计方法与进行两次回归的方法在概念上是相似的, 但二者的统计估计和验证方法却是不同的, 并且多层线性模型的参数估计方法更为稳定。
因此多层模型的应用范围也相当广泛,与传统的用于处理多元重复测量数据的方法相比,该模型具有对数据资料要求低、能够明确表示个体在第一层次的变化情况、可以通过定义第一层次和第二层次的随机变异解释个体随时间的复杂变化情况、可以考虑更高一层次的变量对于个体增长的影响等特点。
多层线性模型( multilevel model ) 由Lindley 等于1972 年提出,是用于分析具有嵌套结构数据的一种统计分析技术。
作为传统方差分析模型的有效扩展Korendijk 等和Duncan 等众多的研究者对多层线性模型进行了广泛研究。
20 多年来,该方法在社会科学领域获得了广泛应用。
近年来,有研究者提出使用多层线性模型进行面板研究,并且已在社会科学领域取得较大进展。
面板研究中多层线性模型的应用优势:由上述分析可知,在面板研究中,传统的数据分析方法会遇到很多难以克服的困难,而多层线性模型可以很好地处理上述问题。
近年来,越来越多的面板研究开始采用多层线性模型的分析方法,显示出多层线性模型在面板研究中的独特优势。
首先,多层线性模型通过考察个体水平在不同时间点的差异,明确表达出个体在层次一的变化情况,因而对于数据的解释(个体随时间的增长趋势)是在个体与重复观测交互作用基础上的解释,即不仅包含不同观测时点的差异,也包含个体之间存在的差异。

(完整版)多层线性模型介绍多层线性模型:HLM(hierarchical linear model)计量模型,为解决传统统计方法如回归分析在处理多层嵌套数据时的局限而产生的,是目前国际上较前沿的一套社会科学数据分析的理论和方法,优势体现两个方面:一是解决了数据嵌套问题;二是为追踪研究或重复测量研究引入了新方法。
传统的线性模型,例如,ANOV A或者回归分析,只能对涉及某一层数据的问题进行分析,而不能将涉及两层或多层数据的问题进行综合分析,而多层线性模型对解决这些问题提供了有效的统计方法。
多层线性模型的参数估计方法与进行两次回归的方法在概念上是相似的, 但二者的统计估计和验证方法却是不同的, 并且多层线性模型的参数估计方法更为稳定。
因此多层模型的应用范围也相当广泛,与传统的用于处理多元重复测量数据的方法相比,该模型具有对数据资料要求低、能够明确表示个体在第一层次的变化情况、可以通过定义第一层次和第二层次的随机变异解释个体随时间的复杂变化情况、可以考虑更高一层次的变量对于个体增长的影响等特点。
多层线性模型( multilevel model ) 由Lindley 等于1972 年提出,是用于分析具有嵌套结构数据的一种统计分析技术。
作为传统方差分析模型的有效扩展Korendijk 等和Duncan 等众多的研究者对多层线性模型进行了广泛研究。
20 多年来,该方法在社会科学领域获得了广泛应用。
近年来,有研究者提出使用多层线性模型进行面板研究,并且已在社会科学领域取得较大进展。
面板研究中多层线性模型的应用优势:由上述分析可知,在面板研究中,传统的数据分析方法会遇到很多难以克服的困难,而多层线性模型可以很好地处理上述问题。
近年来,越来越多的面板研究开始采用多层线性模型的分析方法,显示出多层线性模型在面板研究中的独特优势。
首先,多层线性模型通过考察个体水平在不同时间点的差异,明确表达出个体在层次一的变化情况,因而对于数据的解释(个体随时间的增长趋势)是在个体与重复观测交互作用基础上的解释,即不仅包含不同观测时点的差异,也包含个体之间存在的差异。

多层线性分析模型:集体层面结构的类型:集体层面结构的类型是很重要的,因为结构的类型体现了结构的性质,而结构的性质会影响其组合方式和测量方法。
Kozlowski和Klein(2000)[2]认为,集体层面的结构可分为3种:整体(global)结构、共享(shared)结构和生成(configural)结构。
整体结构是那些相对客观的、容易观察到的、源自于集体层面的集体的特征。
整体结构没有低层面的对应物,所以它不依赖于个体的知觉、经验、行为或个体的交互作用而存在。
团队大小就是一个整体结构,它不依赖于个体的特点和交互作用,但它会影响团队内成员的工作。
(我认为如“团队绩效”这种整体变量就属于这种类型,属于直接测量)共享结构是集体成员的共享(共同具有的)特征,只有当集体内的个体共享相似知觉时它才存在。
共享结构来自于集体成员个体的经验、认知和行为,并且在集体成员中发挥某种作用。
共享结构假设结构在不同层面上的有相似的表现,在不同层面上有相似的内容、意义和结构,是以突现(emergence)中的“组合”(composition)方式结合而成的。
James等(1974)就认为,个体可以产生对环境的知觉以形成某种心理气氛,但只有当这些知觉被共享时才会形成某种组织气氛。
因此,当研究者探讨共享结构时,需要阐明个体特征的组内一致性或可信性,以及集体成员之间的交互作用过程。
(本人认为我们课题同属于这种心理感知,个体层面属于个人心理感知,集体层面属于团队成员的一致感知。
属于团队层面和个体层面在测量结构上相似,我认为我们课题的研究应该采用此种结构。
)生成结构则描绘了集体中个体特征的排列方式或组合模式。
尽管生成结构(configural)与共享结构一样也产生于个体特征,但不同的是生成结构并没有假设集体中个体成员之间的相似性结合,个体在生成结构中的地位和作用是不同的。
共享结构假设单位成员有某种相似知觉,而生成结构中个体的特征却不是同质的,它体现了个体特征在集体层面上的另一种结合方式:个体特征以间断、复杂而非线形的突现中的“合成”(compilation)方式结合为集体特征。

多水平模型及其在经济分析中的应用 (模型研究与案例分析)石磊云南财经大学统计与数学学院,昆明,6502211. 多水平线性模型理论 1.1 两水平线性分析模型无条件两水平模型假设数据具有两个层次,表示第个个体(subject,第二层次)的第i 次(第一层次)观测变量,此时表示2水平,而代表1水平。
首先考虑最简单的无条件两水平模型,又称为截距模型(intercept -only model)或空模型(empty model),是两水平模型建模的基础。
其模型形式为:ij y i i j 水平1: 0ij i ij y e β=+ (2.3.1) 水平2: 000i u 0i βγ=+ (2.3.2) 将(2.3.2) 式代入(2.3.1)可得总模型为:000ij i ij y u e γ=++ (2.3.3)在总模型中,00γ可称为固定效应部分,0i u e ij +称为随机效应部分,该模型的水平1和水平2均没有解释变量,因此称其为无条件两水平模型。
其中(2.3.1)式中,0i β别表示第i组的平均值,2~(0,ij e N )σ为相互独立的水平1残差;在(2.3.2)式中,00γ表示总截距(即的总平均水平),ij y 20~(0,)i u N 0u σ为相互独立的截距项水平2残差,且。
0cov(,)0i ij u e =通过截距模型可以计算组内相关系数ICC ,根据经典定义(Shrout & Fleiss,1979),ICC被定义为组间方差与总方差之比。
对于截距模型而言,其ICC定义为:22200()u u ICC σσσ=+,其中20u σ表示组间方差或组水平方差,2σ则表示为组内方差或个体水平方差。
ICC既能反映组间变异,也能表示组内个体间的相关,其范围在0到1之间,当ICC值趋于1时表示组间方差相对于组内方差非常大,相反当ICC值趋于0时表示没有组群效应,此时两水平模型可简化为固定效应模型。

多层线性模型摘要在社会科学研究中,调查得来的数据往往具有层次结构(嵌套结构)的特点。
在层次结构数据中,不仅有描述个体的变量,而且有个体组成的更高一层的变量。
如研究学生的学术成绩,要考虑学生的社会经济地位(SES)即个体水平的变量,同时可能还要考虑不同学校间学生/老师比例的差异对学生学术成绩的影响也就是学校层次的预测变量。
这种数据带来了很多跨级(多层)的研究问题,为了解决这些问题,出现了一种新的数据分析方法——多层线性模型。
本文第一部分介绍多层线性模型以及多层模型的类型。
第二部分传统统计技术的局限性及多层线性模型的优势。
第三部分说明多层线性模型的基本原理以及两个应用(直接来自篇文献)。
第四部分是总结和拓展。
1、多层线性模型以及多层模型的类型多水平、多层次的数据结构普遍存在,如学生嵌套于班级,班级有嵌套与学校。
传统的线性模型,如方差分析和回归分析,只能涉及一层数据的问题进行分析,不能综合多层数据问题。
在实际研究中,更令人感兴趣的是学生一层的变量与班级一层的变量之间的交互作用,比如,学生之间的个体差异在不同班级之间可能是相同的、也可能是不同的。
学生数据层中,不同变量之间的关系可能因班级的不同而不同。
因此,学生层的差异可以解释为班级层的变量。
另一种类型的两层嵌套数据来自纵向研究数据,多层(多水平)数据指的是观测数据在单位上具有嵌套的关系。
比如在教育研究中,学生镶嵌于班级,在此,学生代表了数据结构的第一层,而班级代表了数据结构的第二层。
对于第一层的学生数据,研究者可以提出一系列的研究问题,也可以针对第二层的班级又提出一系列的研究问题。
在教育研究中,更为重要和令人感兴趣的正是关于学生层的变量与班级层变量之间的交互作用问题。
比如,学生之间的个体差异在不同班级之间可能是相同的,也可能是不同的;在学生层数据中,不同变量之间的关系也可能因班级的不同而不同,这些学生层的差异可以解释为班级层的变量的函数。
多层线性模型由Lindley等于1972年提出,是用于分析具有嵌套结构数据的一种统计分析技术。



两水平模型结果解释1. 引言在统计学中,两水平模型(Two-level Model)是一种用于分析多层次数据的统计模型。
多层次数据是指被嵌套在其他数据层次中的数据,例如学生嵌套在班级中,班级嵌套在学校中等。
两水平模型可以帮助我们理解各个层次之间的关系,并对每个层次的影响进行建模和解释。
本文将以一个具体的案例为例,详细解释两水平模型的结果及其解释。
2. 案例描述假设我们研究了某个地区的学生数学成绩,并收集了以下数据: - 学生级别:每个学生有一个唯一的学生ID。
- 班级级别:每个班级有一个唯一的班级ID。
-学校级别:每所学校有一个唯一的学校ID。
我们感兴趣的是探索不同层次之间的影响,例如班级对学生成绩的影响、学校对班级平均成绩的影响等。
3. 模型设定为了分析这些数据,我们使用了两水平线性回归模型。
模型设定如下:第一层级(学生级别):Y ij=β0j+β1j X ij+e ij其中,Y ij表示第j个班级中第i个学生的数学成绩,β0j是第j个班级的截距,β1j是第j个班级的斜率,X ij是第j个班级中第i个学生的解释变量(例如学生的背景信息),e ij是误差项。
第二层级(班级级别):β0j=γ00+u0jβ1j=γ10+u1j其中,γ00表示所有班级共享的截距,γ10表示所有班级共享的斜率,u0j和u1j分别表示第j个班级特定的随机效应。
4. 模型结果解释通过拟合上述模型并进行统计推断,我们可以得到以下模型结果:固定效应(Fixed Effects)固定效应描述了不同层次之间的平均差异。
在本案例中,固定效应包括所有班级共享的截距γ00和斜率γ10。
•γ00:表示所有班级的平均数学成绩。
该系数的显著性检验可以告诉我们是否存在班级之间的平均差异。
如果γ00显著不为零,则说明不同班级之间的平均数学成绩存在显著差异。
•γ10:表示所有班级数学成绩与解释变量之间的关系。
该系数的显著性检验可以告诉我们解释变量对数学成绩的整体影响是否显著。
多层线性模型的原理与应用1. 简介多层线性模型是一种数据分析和建模方法,适用于解决复杂的非线性关系问题。
本文将介绍多层线性模型的原理和应用,并提供一些实际案例。
2. 原理多层线性模型基于线性回归模型的基本思想,通过添加多个隐藏层来实现对非线性关系的拟合。
具体步骤如下:2.1 数据准备首先,需要准备一组有标签的训练数据作为模型的输入。
训练数据应包括输入特征和对应的输出标签。
2.2 构建模型多层线性模型由输入层、隐藏层和输出层组成。
输入层接受输入特征,将其传递给隐藏层。
隐藏层通过计算加权和并经过一个激活函数得到输出。
输出层将隐藏层的输出进行线性组合得到最终的预测值。
2.3 定义损失函数为了评估模型的准确性,需要定义一个损失函数来衡量预测值与真实值之间的差异。
常用的损失函数包括平方损失和交叉熵损失。
2.4 模型优化使用优化算法,如梯度下降法,来最小化损失函数,找到模型参数的最优解。
通过反复迭代更新参数,逐渐优化模型性能。
3. 应用案例多层线性模型在许多领域都有广泛的应用。
以下是几个常见的应用案例:3.1 信用评分在金融领域,多层线性模型可用于信用评分模型的构建。
通过收集借贷者的相关信息,如年龄、收入、负债情况等,可以预测借贷者的信用风险。
3.2 图像识别多层线性模型也可应用于图像识别任务中。
通过将图像像素作为输入特征,使用多层线性模型可以对图像进行分类。
例如,可以将猫和狗的图像分别作为正样本和负样本,训练模型来识别图像中的动物种类。
3.3 自然语言处理在自然语言处理领域,多层线性模型可用于情感分析和文本分类任务。
通过将文本转换为向量表示,并使用多层线性模型进行分类,可以对文本进行情感判断或分类。
3.4 推荐系统多层线性模型在推荐系统中也有重要应用。
通过分析用户的历史行为和兴趣特征,可以构建个性化的推荐模型,为用户提供个性化的推荐内容。
4. 总结多层线性模型通过添加多个隐藏层,可以有效解决非线性问题。
它在信用评分、图像识别、自然语言处理和推荐系统等领域都有广泛应用。
多层线性模型的解读:原理与应用浙江师范大学心理研究所陈海德********************一、多层数据结构的普遍性多水平、多层次的数据结构普遍存在,如学生嵌套于班级,班级有嵌套与学校。
传统的线性模型,如方差分析和回归分析,只能涉及一层数据的问题进行分析,不能综合多层数据问题。
在实际研究中,更令人感兴趣的是学生一层的变量与班级一层的变量之间的交互作用,比如,学生之间的个体差异在不同班级之间可能是相同的、也可能是不同的。
学生数据层中,不同变量之间的关系可能因班级的不同而不同。
因此,学生层的差异可以解释为班级层的变量。
另一种类型的两层嵌套数据来自纵向研究数据,不同时间观测数据形成了数据结构的第一层,而被试之间的个体差异形成了第二层。
可以探索个体在发展趋势上的差异。
二、传统技术处理多层数据结构的局限如果把变量分解到个体水平,在个体水平上分析。
但是我们知道这些学生是来自同一班级的,不符合观察独立原则。
导致个体间随机误差相互独立的假设不能满足。
如果把个体变量集中到较高水平,在较高水平上进行分析。
这样丢弃了组内信息,而组内变异可能占了大部分。
三、原理☆水平1(学生)的模型与传统的回归模型类似,所不同的是回归方程的截距和斜率不再是一个常数,而是水平2变量水平不同(不同的班级),其回归方程的截距和斜率也不同的,是一个随机变量。
如,每个班级的回归方程的截距和斜率都直接依赖于班级教师教学方法。
☆多层线性模型分为“随机截距模型”和“随机截距和随机斜率模型”。
“随机截距模型”假定因变量的截距随着群体的不同而不同,但各群体的回归斜率是固定,因此不同层次因素之间缺乏互动。
“随机截距和随机斜率模型”假定截距和回归斜率都因群体而异,允许不同层次因素之间的互动。
参数估计方法有:迭代广义最小二乘法、限制性的广义最小二乘估计、马尔科夫链蒙特卡罗法。
这些方法代替了传统的最小二乘法估计,更为稳定和精确。
比如,当第二层的某单位只有少量的被试,或不同组样本量不同时,多层线性模型进行了加权估计、迭代计算。
多层线性模型介绍多层线性模型(Multilayer Linear Model)是一种机器学习模型,也是人工神经网络(Artificial Neural Network)的一种特例。
它由多个线性层组成,每个线性层之间通过非线性函数进行连接,以实现更强大的模型学习能力。
多层线性模型的基本结构如下:输入层(Input Layer)接收原始数据,中间层(Hidden Layer)进行特征转换,输出层(Output Layer)给出预测结果。
输入层、中间层和输出层的每个节点都是线性层,由多个输入值和对应的权重相加,并加上一个偏置项得到输出值。
而输入层、中间层和输出层之间的节点通过非线性函数激活,得到非线性模型输出。
多层线性模型的每一层都可以看作是特征提取器,通过学习不同的权重和偏置,每一层都能够将输入数据进行非线性映射。
中间层的节点数可以根据需要自定义,而层数一般较深。
模型的输出结果通过输出层的节点给出,可以是一个标量或向量,用于分类、回归等任务。
多层线性模型的训练过程非常重要。
通常使用反向传播算法进行训练,即通过计算损失函数对模型参数的偏导数,根据梯度下降法来迭代调整模型参数,使损失函数最小化。
训练过程中还会选择合适的学习率、正则化方法、优化算法等来提高模型的泛化能力和学习效率。
然而,多层线性模型也存在一些缺点。
首先,模型的结构较为复杂,参数较多,训练时间较长。
其次,模型的训练过程容易受到梯度消失和梯度爆炸等问题的影响,需要选择合适的激活函数和优化算法来解决。
此外,模型的解释性较弱,很难解释每个特征对结果的具体影响。
针对多层线性模型的缺点,研究人员提出了一系列的改进方法。
如引入卷积层、循环层等特殊层结构,可以更好地处理时空信息和序列数据;使用批标准化等技术,可以提高模型的训练效率和鲁棒性;引入残差连接、注意力机制等技术,可以提高模型的学习能力和泛化能力。
总而言之,多层线性模型作为一种机器学习模型,具有一定的应用价值和研究前景。