使用遗传算法求解多元函数最值(实例)
- 格式:pdf
- 大小:131.77 KB
- 文档页数:7

计算智能导论大作业---遗传算法在求解复杂函数给定区间上最值中的应用一、遗传算法简介遗传算法(Genetic Algorithm)是模拟达尔文生物进化论的自然选择和遗传学机理的生物进化过程的计算模型,是一种通过模拟自然进化过程搜索最优解的方法。
遗传算法是从代表问题可能潜在的解集的一个种群(population)开始的,而一个种群则由经过基因(gene)编码的一定数目的个(individual)组成。
每个个体实际上是染色体(chromosome)带有特征的实体。
染色体作为遗传物质的主要载体,即多个基因的集合,其内部表现(即基因型)是某种基因组合,它决定了个体的形状的外部表现,如黑头发的特征是由染色体中控制这一特征的某种基因组合决定的。
因此,在一开始需要实现从表现型到基因型的映射即编码工作。
由于仿照基因编码的工作很复杂,我们往往进行简化,如二进制编码,初代种群产生之后,按照适者生存和优胜劣汰的原理,逐代演化产生出越来越好的近似解,在每一代,根据问题域中个体的适应度(fitness)大小选择(selection)个体,并借助于自然遗传学的遗传算子(genetic operators)进行组合交叉(crossover)和变异(mutation),产生出代表新的解集的种群。
这个过程将导致种群像自然进化一样的后生代种群比前代更加适应于环境,末代种群中的最优个体经过解码(decoding),可以作为问题近似最优解,对于各种通用问题都可以使用1.1术语说明由于遗传算法是由进化论和遗传学机理而产生的搜索算法,所以在这个算法中会用到很多生物遗传学知识,下面是一些常用术语的说明:染色体染色体又可以叫做基因型个体(individuals),一定数量的个体组成了群体(population),群体中个体的数量叫做群体大小。
基因基因是串中的元素,基因用于表示个体的特征。
例如有一个串S=1011,则其中的1,0,1,1这4个元素分别称为基因。

matlab遗传算法计算函数区间最大值和最小值下面是用matlab实现遗传算法计算函数区间最大值和最小值的示例代码:首先定义函数(此处以f(x)=x*sin(10*pi*x)+1为例):matlabfunction y = myfun(x)y = x*sin(10*pi*x)+1;end然后设置遗传算法参数:matlaboptions = gaoptimset('Generations', 1000, 'PopulationSize', 50,'StallGenLimit', 200, 'TolCon', 1e-10);其中,Generations表示遗传算法的迭代次数,PopulationSize表示种群大小,StallGenLimit表示在连续多少代没有改变时停止迭代,TolCon表示收敛精度。
接着,编写遗传算法主函数:matlab[x, fval] = ga(@myfun, 1, [], [], [], [], -1, 2, [], [], options);其中,第一个参数为要优化的函数,第二个参数为变量维度,后面的参数为变量的取值范围。
最后,输出结果:matlabfprintf('Function maximum is %f\n',-fval);fprintf('Function minimum is %f\n',fval);其中,-fval表示函数最大值,fval表示函数最小值。
完整代码如下:matlabfunction y = myfun(x)y = x*sin(10*pi*x)+1;endoptions = gaoptimset('Generations', 1000, 'PopulationSize', 50, 'StallGenLimit', 200, 'TolCon', 1e-10);[x, fval] = ga(@myfun, 1, [], [], [], [], -1, 2, [], [], options);fprintf('Function maximum is %f\n',-fval);fprintf('Function minimum is %f\n',fval);参考资料:[1][2]。

实验五:遗传算法求解函数最值问题实验一、实验目的使用遗传算法求解函数在及y的最大值。
二、实验容使用遗传算法进行求解,篇末所附源代码中带有算法的详细注释。
算法中涉及不同的参数,参数的取值需要根据实际情况进行设定,下面运行时将给出不同参数的结果对比。
定义整体算法的结束条件为,当种群进化次数达到maxGeneration时停止,此时种群中的最优解即作为算法的最终输出。
设种群规模为N,首先是随机产生N个个体,实验中定义了类型Chromosome表示一个个体,并且在默认构造函数中即进行了随机的操作。
然后程序进行若干次的迭代,在每次迭代过程中,进行选择、交叉及变异三个操作。
1.选择操作首先计算当前每个个体的适应度函数值,这里的适应度函数即为所要求的优化函数,然后归一化求得每个个体选中的概率,然后用轮盘赌的方法以允许重复的方式选择选择N个个体,即为选择之后的群体。
但实验时发现结果不好,经过仔细研究之后发现,这里在x、y 取某些值的时候,目标函数计算出来的适应值可能会出现负值,这时如果按照把每个个体的适应值除以适应值的总和的进行归一化的话会出现问题,因为个体可能出现负值,总和也可能出现负值,如果归一化的时候除以了一个负值,选择时就会选择一些不良的个体,对实验结果造成影响。
对于这个问题,我把适应度函数定为目标函数的函数值加一个正数,保证得到的适应值为正数,然后再进行一般的归一化和选择的操作。
实验结果表明,之前的实验结果很不稳定,修正后的结果比较稳定,趋于最大值。
2.交叉操作首先是根据交叉概率probCross选择要交叉的个体进行交叉。
这里根据交叉参数crossnum进行多点交叉,首先随机生成交叉点位置,允许交叉点重合,两个重合的交叉点效果互相抵消,相当于没有交叉点,然后根据交叉点进行交叉操作,得到新的个体。
3.变异操作首先是根据变异概率probMutation选择要变异的个体。
变异时先随机生成变异的位置,然后把改位的01值翻转。



matlab遗传算法求多元方程系数
在MATLAB中,可以使用遗传算法求解多元方程的系数。
以下是一个简单的示例:
1.首先,定义目标函数和约束条件。
例如,求解以下多元方程组的系数:
```
x1+2*x2-3*x3=1
2*x1+x2+3*x3=2
-x1+x2-x3=0
```
2.然后,编写遗传算法的代码。
这里我们使用MATLAB内置的`gamultiobj`函数。
```matlab
%定义目标函数
fun=@(x)[x(1)+2*x(2)-3*x(3)-1;...
2*x(1)+x(2)+3*x(3)-2;...
-x(1)+x(2)-x(3)];
%定义变量范围
lb=[-10,-10,-10];%下界
ub=[10,10,10];%上界
%设置遗传算法参数
options=optimoptions('gamultiobj','Display','iter');
%运行遗传算法
[x,fval]=gamultiobj(fun,3,[],[],[],[],[],[],[],[],[],[],lb,ub, options);
```
3.最后,输出结果。
```matlab
disp('最优解:');
disp(x);
disp('目标函数值:');
disp(fval);
```
这个示例将求解给定的多元方程组,并输出最优解和目标函数值。
注意,这里的变量范围和目标函数可能需要根据实际情况进行调整。
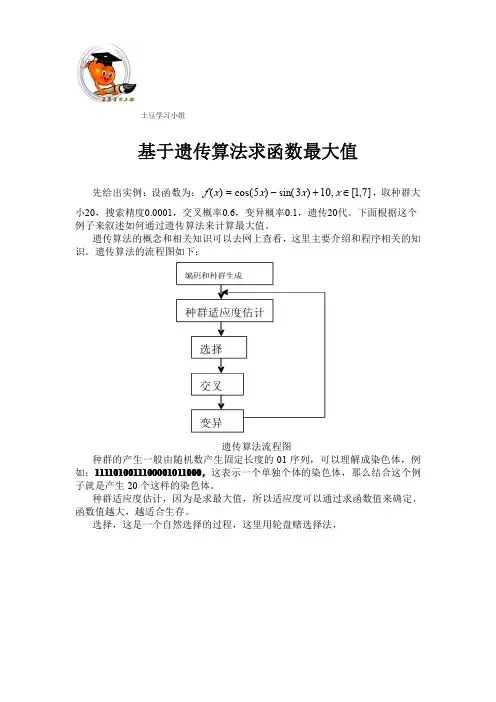
土豆学习小组基于遗传算法求函数最大值先给出实例:设函数为:]7,1[,10)3sin()5cos()(∈+−=x x x x f ,取种群大小20,搜索精度0.0001,交叉概率0.6,变异概率0.1,遗传20代。
下面根据这个例子来叙述如何通过遗传算法来计算最大值。
遗传算法的概念和相关知识可以去网上查看,这里主要介绍和程序相关的知识。
遗传算法的流程图如下:遗传算法流程图种群的产生一般由随机数产生固定长度的01序列,可以理解成染色体,例如:1111010011100001011000,这表示一个单独个体的染色体,那么结合这个例子就是产生20个这样的染色体。
种群适应度估计,因为是求最大值,所以适应度可以通过求函数值来确定,函数值越大,越适合生存。
选择,这是一个自然选择的过程,这里用轮盘赌选择法,土豆学习小组轮盘赌选择法交叉用单点交叉:单点交叉变异的形式如下:变异当然变异的概率相对较低。
注意:选择和交叉方法还很多,也比这来的有效,只是这种方法较为简单,易于程序实现。
MATLAB命令窗口:>>[xv,fv]=GA(@fitness,1,7,20,20,0.6,0.1,0.0001)xv=3.6723土豆学习小组fv=11.8830函数图形结果基本符合。
函数文件1:fitness.m用于存放需要求的函数function F=fitness(x)F=cos(5*x)-sin(3*x)+10;函数文件2:GA.m遗传算法文件function[xv,fv]=GA(fitness,a,b,NP,NG,pc,pm,eps) %上限a%下限b%种群大小:NP%遗传代数:NG%交叉概率:pc%变异概率:pm%离散精度:eps%第一步产生初始种群x,产生之前需要根据离散精度确定串长L L=ceil(log2((b-a)/eps));x=Initial(L,NP);for i=1:NPxdec(i)=dec(a,b,x(i,:),L);end%第二步选择交叉变异要循环好几代for i=1:NG%选择轮盘赌选择法fx=fitness(xdec);%适应度fxp=fx/sum(fx);%选择概率fxa(1)=fxp(1);%累计概率土豆学习小组for j=2:NPfxa(j)=fxa(j-1)+fxp(j);end%开始选择父体sat=rand();for k=1:NPif sat<=fxa(k)father=k;break;endend%随机选取母体mother=ceil(rand()*NP);nx=x;%单点交叉cutp=ceil(rand()*L);r1=rand();if r1<=pcnx(i,1:cutp)=x(father,1:cutp);nx(i,cutp+1:L)=x(mother,cutp+1:L);r2=rand();%是否变异if r2<pmcum=ceil(rand()*L);nx(i,cum)=~nx(i,cum);endendx=nx;for i=1:NPxdec(i)=dec(a,b,x(i,:),L);end%选择较好的子代fv=-inf;for i=1:NPfitx=fitness(dec(a,b,x(i,:),L));if fitx>fvfv=fitx;xv=dec(a,b,x(i,:),L);endendend土豆学习小组%种群初始化函数function t=Initial(L,NP)t=zeros(NP,L);for i=1:NPfor j=1:Ltemp=rand();t(i,j)=round(temp);endend%解码函数转换成十进制function d=dec(a,b,num,L)i=L-1:-1:0;dd=sum((2.^i).*num);d=a+dd*(b-a)/(2^L-1);其中:dec函数将某个个体转换到【1,7】之间的数000000000000=1;111111111111=7;。

实验五:遗传算法求解函数最值问题实验一、实验目的使用遗传算法求解函数在及y的最大值。
二、实验内容使用遗传算法进行求解,篇末所附源代码中带有算法的详细注释。
算法中涉及不同的参数,参数的取值需要根据实际情况进行设定,下面运行时将给出不同参数的结果对比。
定义整体算法的结束条件为,当种群进化次数达到maxGeneration时停止,此时种群中的最优解即作为算法的最终输出。
设种群规模为N,首先是随机产生N个个体,实验中定义了类型Chromosome表示一个个体,并且在默认构造函数中即进行了随机的操作。
然后程序进行若干次的迭代,在每次迭代过程中,进行选择、交叉及变异三个操作。
1.选择操作首先计算当前每个个体的适应度函数值,这里的适应度函数即为所要求的优化函数,然后归一化求得每个个体选中的概率,然后用轮盘赌的方法以允许重复的方式选择选择N个个体,即为选择之后的群体。
但实验时发现结果不好,经过仔细研究之后发现,这里在x、y 取某些值的时候,目标函数计算出来的适应值可能会出现负值,这时如果按照把每个个体的适应值除以适应值的总和的进行归一化的话会出现问题,因为个体可能出现负值,总和也可能出现负值,如果归一化的时候除以了一个负值,选择时就会选择一些不良的个体,对实验结果造成影响。
对于这个问题,我把适应度函数定为目标函数的函数值加一个正数,保证得到的适应值为正数,然后再进行一般的归一化和选择的操作。
实验结果表明,之前的实验结果很不稳定,修正后的结果比较稳定,趋于最大值。
2.交叉操作首先是根据交叉概率probCross选择要交叉的个体进行交叉。
这里根据交叉参数crossnum进行多点交叉,首先随机生成交叉点位置,允许交叉点重合,两个重合的交叉点效果互相抵消,相当于没有交叉点,然后根据交叉点进行交叉操作,得到新的个体。
3.变异操作首先是根据变异概率probMutation选择要变异的个体。
变异时先随机生成变异的位置,然后把改位的01值翻转。


遗传算法简单实例为更好地理解遗传算法的运算过程,下面用手工计算来简单地模拟遗传算法的各个主要执行步骤。
例:求下述二元函数的最大值:(1) 个体编码遗传算法的运算对象是表示个体的符号串,所以必须把变量x1, x2 编码为一种符号串。
本题中,用无符号二进制整数来表示。
因 x1, x2 为 0 ~ 7之间的整数,所以分别用3位无符号二进制整数来表示,将它们连接在一起所组成的6位无符号二进制数就形成了个体的基因型,表示一个可行解。
例如,基因型 X=101110 所对应的表现型是:x=[ 5,6 ]。
个体的表现型x和基因型X之间可通过编码和解码程序相互转换。
(2) 初始群体的产生遗传算法是对群体进行的进化操作,需要给其淮备一些表示起始搜索点的初始群体数据。
本例中,群体规模的大小取为4,即群体由4个个体组成,每个个体可通过随机方法产生。
如:011101,101011,011100,111001(3) 适应度汁算遗传算法中以个体适应度的大小来评定各个个体的优劣程度,从而决定其遗传机会的大小。
本例中,目标函数总取非负值,并且是以求函数最大值为优化目标,故可直接利用目标函数值作为个体的适应度。
(4) 选择运算选择运算(或称为复制运算)把当前群体中适应度较高的个体按某种规则或模型遗传到下一代群体中。
一般要求适应度较高的个体将有更多的机会遗传到下一代群体中。
本例中,我们采用与适应度成正比的概率来确定各个个体复制到下一代群体中的数量。
其具体操作过程是:•先计算出群体中所有个体的适应度的总和fi ( i=1.2,…,M );•其次计算出每个个体的相对适应度的大小 fi / fi ,它即为每个个体被遗传到下一代群体中的概率,•每个概率值组成一个区域,全部概率值之和为1;•最后再产生一个0到1之间的随机数,依据该随机数出现在上述哪一个概率区域内来确定各个个体被选中的次数。
(5) 交叉运算交叉运算是遗传算法中产生新个体的主要操作过程,它以某一概率相互交换某两个个体之间的部分染色体。

遗传算法MATLAB实现(3):多元函数优化举例多峰的Shubert为:求f(x,y)在[-10,10]x[-10,10]上的最⼤值。
MATLAB代码:fun_mutv函数为:function my=fun_mutv(x,y)t1=zeros(size(x));t2=t1;for i=1:5t1=t1+i*cos((i+1)*x+i);t2=t2+i*cos((i+1)*y+i);endmy=t1.*t2;opt_minmax=1; %优化⽬标类型:1最⼤化 0最⼩化num_ppu=60; %种群规模,个体个数。
num_gen=100; %最⼤遗传代数num_v=2; %变量个数len_ch=20; %基因长度gap=0.9; %代沟sub=-10; %变量取值下限up=10; %变量取值上限cd_gray=1; %是否选择格雷码编码⽅式 1是,0否sc_log=0; %是否选择对数标度:1是,0否trace=zeros(num_gen,2); %遗传迭代性能跟踪器%区域描述器,rep为矩阵复制函数fieldd=[rep([len_ch],[1,num_v]);rep([sub;up],[1,num_v]);rep([1-cd_gray;sc_log;1;1],[1,num_v])];chrom=crtbp(num_ppu,len_ch*num_v); %初始化⽣产种群k_gen=0;x=bs2rv(chrom,fieldd); %翻译初始化种群为10进制fun_v=fun_mutv(x(:,1),x(:,2)); %计算⽬标函数值[tx,ty]=meshgrid(-10:1:10);mesh(tx,ty,fun_mutv(tx,ty));xlabel('x');ylabel('y');zlabel('z');title('多元函数优化结果');hold on;while k_gen<num_genfit_v=ranking(-opt_minmax*fun_v); %计算⽬标函数适应度selchrom=select('rws',chrom,fit_v,gap); %使⽤轮盘赌⽅式选择selchrom=recombin('xovsp',selchrom); %交叉selchtom=mut(selchrom); %变异x=bs2rv(selchrom,fieldd); %⼦代个体翻译fun_v_sel=fun_mutv(x(:,1),x(:,2)); %计算⼦代个体对应⽬标函数值fit_v_sel=ranking(-opt_minmax*fun_v_sel);[chrom,fun_v]=reins(chrom,selchrom,1,1,opt_minmax*fun_v,opt_minmax*fun_v_sel); %根据⽬标函数值将⼦代个体插⼊新种群[f,id]=max(fun_v); %寻找当前种群最优解x=bs2rv(chrom(id,:),fieldd);f=f*opt_minmax;fun_v=fun_v*opt_minmax;plot3(x(1,1),x(1,2),f,'k*');hold on;k_gen=k_gen+1;trace(k_gen,1)=f;trace(k_gen,2)=mean(fun_v);endfigure;plot(trace(:,1),'r-*');hold on;plot(trace(:,2),'b-o');legend('各⼦代种群最优解','各⼦代种群平均值');xlabel('迭代次数');ylabel('⽬标函数优化情况');title('多元函数优化过程');。
利用遗传算法求函数的极大值function[BestSfi,BestS,x1,x2]=GenericAlgorithm(Size,G,Codel,umax,umin,pc,pm)----------------------------------------------------------------------------------------------------------------------%主要符号说明% Size 种群大小,选为60% G 终止进化代数,选为100% Codel 用二进制编码串表示决策变量x1,x2,选为10位% umax 决策变量上限2.048% umin 决策变量下限2.048% pc 交叉概率,选为0.8% pm 变异概率,选为0.01----------------------------------------------------------------------------------------------------------------------E=round(rand(Size,2*Codel)); %随机生成二十位的编码,前十位为x1,后十位为x2for k=1:1:Gtime(k)=k;for s=1:1:Sizem=E(s,:);y1=0;y2=0; %初始化m1=m(1:1:Codel);for i=1:1:Codely1=y1+m1(i)*2^(i-1); %二进制转化为十进制endx1=(umax-umin)*y1/1023+umin; %解码后x1的实际值m2=m(11:1:2*Codel);for i=1:1:Codely2=y2+m2(i)*2^(i-1);endx2=(umax-umin)*y2/1023+umin; %解码后x2的实际值F(s)=100*(x1^2-x2)^2+(1-x1)^2; %所求函数endJi=1./F; %目标函数,此处取适应度的倒数%第一步,算出最优染色体BestJ(k)=min(Ji);fi=F;[Oderfi,Indexfi]=sort(fi);Bestfi=Oderfi(Size);BestS=E(Indexfi(Size),:);bfi(k)=Bestfi;%第二步,选择和复制过程fi_sum=sum(fi);fi_Size=(Oderfi/fi_sum)*Size;fi_S=floor(fi_Size); %适配值大的被复制kk=1;for i=1:1:Sizefor j=1:1:fi_S(i)TempE(kk,:)=E(Indexfi(i),:);kk=kk+1;endend%第三步,交叉过程n=ceil(20*rand);for i=1:2:(Size-1)temp=rand;if pc>tempfor i=n:1:20TempE(i,j)=E(i+1,j);TempE(i+1,j)=E(i,j);endendendTempE(Size,:)=BestS;E=TempE;%第四步,变异过程for i=1:1:Sizefor j=1:1:Codeltemp=rand;if pc>tempif TempE(i,j)==0TempE(i,j)=1;elseTempE(i,j)=0;endendendend%保证TempPop(30,:)是最大适应度的代码TempE(Size,:)=BestS;E=TempE;end%输出结果Max_Value=Bestfi;Bestfi %显示最大适应度值BestS %显示对应的染色体x1x2subplot(1,2,1);plot(time,BestJ); %目标函数title('目标函数J的优化过程')xlabel('Times');ylabel('Best J');subplot(1,2,2);plot(time,bfi); %适应度函数title('适应度F的优化过程')xlabel('times');ylabel('Best F');在Matlab下运行的结果为:GenericAlgorithm(60,100,10,2.048,-2.048,0.80,0.01),回车Bestfi = 3.9059e+003。
多元函数遗传算法建模求最小值以下是编写的用遗传算法求多元函数的最小值程序,此多元函数为y=x1^2+x2^2………+x20^2,x∈[-800,800],最下面附有每一代对应的目标函数最小值与平均值的变化图形。
NIND=40;%初始种群的个数PRICE=20;%每个个体转化为二进制位数NVAR=20;%一个染色体有多少基因(个体)MAXGEN=200;%遗传代数GGAP=0.8;%代沟,以一定概率选择父代遗传到下一代trace=zeros(MAXGEN,2);Chrom=crtbp(NIND,PRICE*NVAR);FieldD=[rep([PRICE],[1,NVAR]);rep([-800;800],[1,NVAR]);rep([1;0;1;1],[1,NVAR])];%确定每个变量的二进制位数,取值范围,及取值范围是否包括边界等。
Objv=objfun(bs2rv(Chrom,FieldD))gen=1;while gen<=MAXGENFitv=ranking(Objv);Sel=select('sus',Chrom,Fitv,GGAP);Sel=recombin('xovsp',Sel,0.7);Sel=mut(Sel);Objvsel=objfun1(bs2rv(Sel,FieldD));[Chrom,Objv]=reins(Chrom,Sel,1,1,Objv,Objvsel) ;trace(gen,1)=min(Objv);trace(gen,2)=sum(Objv)/length(Objv);gen=gen+1;endplot(trace(:,1));hold onplot(trace(:,2),'.')gridlegend('解的变化','平均值的变化')functionObjVal = objfun(Chrom,rtn_type)% Dimension of objective functionDim = 20;% Compute population parameters[Nind,Nvar] = size(Chrom);% Check size of Chrom and do the appropriate thing% if Chrom is [], then define size of boundary-matrix and values ifNind == 0% return text of title for graphic outputifrtn_type == 2ObjVal = ['DE JONG function 1-' int2str(Dim)];% return value of global minimumelseifrtn_type == 3ObjVal = 0;% define size of boundary-matrix and valueselse% lower and upper bound, identical for all n variablesObjVal = 100*[-8; 8];ObjVal = ObjVal(1:2,ones(Dim,1));end% if Dim variables, compute values of functionelseifNvar == Dim% function 1, sum of xi^2 for i = 1:Dim (Dim=30)% n = Dim, -8<= xi <= 8% global minimum at (xi)=(0) ; fmin=0ObjVal = sum((Chrom .* Chrom)')';% ObjVal = diag(Chrom * Chrom'); % both lines produce the same % otherwise error, wrong format of Chromelseerror('size of matrix Chrom is not correct for function evaluation');end。
python实现遗传算法求函数最⼤值(⼈⼯智能作业)题⽬:⽤遗传算法求函数f(a,b)=2a x sin(8PI x b) + b x cos(13PI x a)最⼤值,a:[-3,7],b:[-4:10]实现步骤:初始化种群计算种群中每个个体的适应值淘汰部分个体(这⾥是求最⼤值,f值存在正值,所以淘汰所有负值)轮盘算法对种群进⾏选择进⾏交配、变异,交叉点、变异点随机分析:为了⽅便,先将⾃变量范围调整为[0,10]、[0,14]有两个变量,种群中每个个体⽤⼀个列表表⽰,两个列表项,每项是⼀个⼆进制字符串(分别由a、b转化⽽来)种群之间交配时需要确定交叉点,先将个体染⾊体中的两个⼆进制字符串拼接,再确定⼀个随机数作为交叉点为了程序的数据每⼀步都⽐较清晰正确,我在select、crossover、mutation之后分别都进⾏了⼀次适应值的重新计算具体代码:import mathimport randomdef sum(list):total = 0.0for line in list:total += linereturn totaldef rand(a, b):number = random.uniform(a,b)return math.floor(number*100)/100PI = math.pidef fitness(x1,x2):return 2*(x1-3)*math.sin(8*PI*x2)+(x2-4)*math.cos(13*PI*x1)def todecimal(str):parta = str[0:4]partb = str[4:]numerical = int(parta,2)partb = partb[::-1]for i in range(len(partb)):numerical += int(partb[i])*math.pow(0.5,(i+1))return numericaldef tobinarystring(numerical):numa = math.floor(numerical)numb = numerical - numabina = bin(numa)bina = bina[2:]result = "0"*(4-len(bina))result += binafor i in range(7):numb *= 2result += str(math.floor(numb))numb = numb - math.floor(numb)return resultclass Population:def __init__(self):self.pop_size = 500 # 设定种群个体数为500self.population = [[]] # 种群个体的⼆进制字符串集合,每个个体的字符串由⼀个列表组成[x1,x2]self.individual_fitness = [] # 种群个体的适应度集合self.chrom_length = 22 # ⼀个染⾊体22位self.results = [[]] # 记录每⼀代最优个体,是⼀个三元组(value,x1_str,x2_str)self.pc = 0.6 # 交配概率self.pm = 0.01 # 变异概率self.distribution = [] # ⽤于种群选择时的轮盘def initial(self):for i in range(self.pop_size):x1 = rand(0,10)x2 = rand(0,14)x1_str = tobinarystring(x1)x2_str = tobinarystring(x2)self.population.append([x1_str,x2_str]) # 添加⼀个个体fitness_value = fitness(x1,x2)self.individual_fitness.append(fitness_value) # 记录该个体的适应度self.population = self.population[1:]self.results = self.results[1:]def eliminate(self):for i in range(self.pop_size):if self.individual_fitness[i]<0:self.individual_fitness[i] = 0.0def getbest(self):"取得当前种群中的⼀个最有个体加⼊results集合"index = self.individual_fitness.index(max(self.individual_fitness))x1_str = self.population[index][0]x2_str = self.population[index][1]value = self.individual_fitness[index]self.results.append((value,x1_str,x2_str,))def select(self):"轮盘算法,⽤随机数做个体选择,选择之后会更新individual_fitness对应的数值""第⼀步先要初始化轮盘""选出新种群之后更新individual_fitness"total = sum(self.individual_fitness)begin = 0for i in range(self.pop_size):temp = self.individual_fitness[i]/total+beginself.distribution.append(temp)begin = tempnew_population = []new_individual_fitness = []for i in range(self.pop_size):num = random.random() # ⽣成⼀个0~1之间的浮点数j = 0for j in range(self.pop_size):if self.distribution[j]<num:continueelse:breakindex = j if j!=0 else (self.pop_size-1)new_population.append(self.population[index])new_individual_fitness.append(self.individual_fitness[index])self.population = new_populationself.individual_fitness = new_individual_fitnessdef crossover(self):"选择好新种群之后要进⾏交配""注意这只是⼀次种群交配,种群每⼀次交配过程,会让每两个相邻的染⾊体进⾏信息交配"for i in range(self.pop_size-1):if random.random()<self.pc:cross_position = random.randint(1,self.chrom_length-1)i_x1x2_str = self.population[i][0]+self.population[i][1] # 拼接起第i个染⾊体的两个⼆进制字符串i1_x1x2_str = self.population[i+1][0]+self.population[i+1][1] # 拼接起第i+1个染⾊体的两个⼆进制字符串 str1_part1 = i_x1x2_str[:cross_position]str1_part2 = i_x1x2_str[cross_position:]str2_part1 = i1_x1x2_str[:cross_position]str2_part2 = i1_x1x2_str[cross_position:]str1 = str1_part1+str2_part2str2 = str2_part1+str1_part2self.population[i] = [str1[:11],str1[11:]]self.population[i+1] = [str2[:11],str2[11:]]"然后更新individual_fitness"for i in range(self.pop_size):x1_str = self.population[i][0]x2_str = self.population[i][1]x1 = todecimal(x1_str)x2 = todecimal(x2_str)self.individual_fitness[i] = fitness(x1,x2)def mutation(self):"个体基因变异"for i in range(self.pop_size):if random.random()<self.pm:x1x2_str = self.population[i][0]+self.population[i][1]pos = random.randint(0,self.chrom_length-1)bit = "1" if x1x2_str[pos]=="0" else "0"x1x2_str = x1x2_str[:pos]+bit+x1x2_str[pos+1:]self.population[i][0] = x1x2_str[:11]self.population[i][1] = x1x2_str[11:]"然后更新individual_fitness"for i in range(self.pop_size):x1_str = self.population[i][0]x2_str = self.population[i][1]x1 = todecimal(x1_str)x2 = todecimal(x2_str)self.individual_fitness[i] = fitness(x1, x2)def solving(self,times):"进⾏times次数的整个种群交配变异""先获得初代的最优个体"self.getbest()for i in range(times):"每⼀代的染⾊体个体和适应值,需要先淘汰,然后选择,再交配、变异,最后获取最优个体。
利用遗传算法求解函数的最大值蒋赛赵玉芹1 遗传算法的基本原理遗传算法是模拟生物遗传学和自然选择机理,通过人工方式构造的一类优化搜索算法,是对生物进化过程进行的一种数学仿真,是进化计算的一种重要形式。
遗传算法与传统数学模型截然不同,它为那些难以找到传统数学模型的难题找出了一个解决方法。
同时,遗传算法借鉴了生物科学中的某些知识,从而体现了人工智能的这一交叉学科的特点。
遗传算法是一种通用的优化算法,其编码技术和遗传操作比较简单,优化不受限制条件的约束,不需要有先验条件。
其搜索过程是从问题解的一个随机产生的集合开始的,而不是从单个个体开始的,具有隐含并行搜索特性,也就大大减少可陷入局部极小值的可能。
在解决可能在求解过程中产生组合爆炸的问题时会产生很好的效果。
遗传算法需选择一种合适的编码方式表示解, 并选择一种评价函数用来每个解的适应值, 适应值高的解更容易被选中并进行交叉和变异, 然后产生新的子代。
选择、交叉和变异的过程一直循环 , 直到求得满意解或满足其他终止条件为止。
算法的运行过程具有很强的指向性, 适合众多复杂问题的求解。
具体操作步骤如下:1)初始化种群;2)计算种群上每个个体的适应度值;3)按由个体适应度值所决定的某个规则选择将进入下一代的个体进行交叉操作4)按概率PC进行变异操作5)按概率PC6)若没有满足某种停止条件,则转步骤2),否则进入下一步;7)输入种群中适应度值最优的染色体作为问题的满足解或最优解本例运用遗传算法求解函数优化的问题2 遗传求解举例(Rosenbrock函数的全局最大值计算)2.0 求解函数介绍函数f(x1,x2) = 100 (x21-x2)2 + (1-x2)2是非凸函数,又称Rosenbrock函数,是由De Jong提出的,现已成为测试遗传算法的标准函数。
该函数在极小值附近沿曲线x2=x12有陡峭的峡谷,很容易陷入局部极小,它的全局最小点是(1,1),最小值是0.该函数有两个局部极大点,分别是:f(2.048, -2.048)=3897.7342 和 (-2.048,-2.048)=3905.9262其中后者为全局最大值点。
遗传算法求函数最大值(matlab实现)一、题目:寻找f(x)=x2,,当x在0~31区间的最大值。
二、源程序:%遗传算法求解函数最大值%本程序用到了英国谢菲尔德大学(Sheffield)开发的工具箱GATBX,该工具箱比matlab自带的GATOOL使用更加灵活,但在编写程序方面稍微复杂一些Close all;Clear all;figure(1);fplot('variable*variable',[0,31]); %画出函数曲线%以下定义遗传算法参数GTSM=40; %定义个体数目ZDYCDS=20; %定义最大遗传代数EJZWS=5; %定义变量的二进制位数DG=0.9; %定义代沟trace=zeros(2, ZDYCDS); %最优结果的初始值FieldD=[5;-1;2;1;0;1;1]; %定义区域描述器的各个参数%以下为遗传算法基本操作部分,包括创建初始种群、复制、交叉和变异Chrom=crtbp(GTSM, EJZWS); %创建初始种群,即生成给定规模的二进制种群和结构gen=0; %定义代数计数器初始值variable=bs2rv(Chrom, FieldD); %对生成的初始种群进行十进制转换ObjV=variable*variable; %计算目标函数值f(x)=x2 while gen<ZDYCDS %进行循环控制,当当前代数小于定义的最大遗传代数时,继续循环,直至代数等于最大遗传代数FitnV=ranking(-ObjV); %分配适应度值SelCh=select('sus', Chrom, FitnV, DG); %选择,即对个体按照他们的适配值进行复制SelCh=recombin('xovsp', SelCh, 0.7); %交叉,即首先将复制产生的匹配池中的成员随机两两匹配,再进行交叉繁殖SelCh=mut(SelCh); %变异,以一个很小的概率随机地改变一个个体串位的值variable=bs2rv(SelCh, FieldD); %子代个体的十进制转换ObjVSel=variable*variable; %计算子代的目标函数值[Chrom ObjV]=reins(Chrom, SelCh, 1, 1, ObjV, ObjVSel);%再插入子代的新种群,其中Chrom为包含当前种群个体的矩阵,SelCh为包好当前种群后代的矩阵variable=bs2rv(Chrom, FieldD); %十进制转换gen=gen+1; %代数计数器增加%输出最优解及其序号,并在目标函数图像中标出,Y为最优解,I 为种群的%序号[Y, I]=max(ObjV);hold on; %求出其最大目标函数值plot(variable(I), Y, 'bo');trace(1, gen)=max(ObjV); %遗传算法性能跟踪trace(2, gen)=sum(ObjV)/length(ObjV);end%以下为结果显示部分,通过上面计算出的数值进行绘图variable=bs2rv(Chrom, FieldD); %最优个体进行十进制转换hold on, grid;plot(variable,ObjV,'b*'); %将结果画出三、运行结果:由图可见该函数为单调递增函数,即当X=31时,该取得最大值f(x)max=961。
实验五:遗传算法求解函数最值问题实验实验五:遗传算法求解函数最值问题实验一、实验目的使用遗传算法求解函数f优y)=x*sin(6*y)+y*cos(8*x)在m及yDll的最大值。
使用遗传算法进行求解,篇末所附源代码中带有算法的详细注释。
算法中涉及不同的参数,参数的取值需要根据实际情况进行设定,F面运行时将给出不同参数的结果对比。
//参数constintN-2种群的个休数constintlen=30;每个个体的染色体的长度,xffiyS占一半constintcrossnum=4;交叉操作B孩点交叉曲支叉点个数constintmaxGeneration=19000;//最大进化代^constdoubleprobCross=9.85;//概率constdoubleprobMutation-15;//豈异IK率定义整体算法的结束条件为,当种群进化次数达到maxGeneration时停止,此时种群中的最优解即作为算法的最终输出。
//融饶for(intg=0jgmaxGeneration;g++)(设种群规模为N,首先是随机产生N个个体,实验中定义了类型Chromosome表示一个个体,并且在默认构造函数中即进行了随机的操作。
//初始化种群for(inti=0;iN;i++)grcup[i]=Chrcmc50me();实验内容然后程序进行若干次的迭代,在每次迭代过程中,进行选择、交叉及变异三个操作。
1选择操作首先计算当前每个个体的适应度函数值,这里的适应度函数即为所要求的优化函数,然后归一化求得每个个体选中的概率,然后用轮盘赌的方法以允许重复的方式选择选择N个个体,即为选择之后的群体。
//选择操作Elvoidselect(匚hromosoraegroup[mxn])计算每个个体的询?概率doublefitnessVal[mxn];for(inti=ii++)0;//使用轮蛊賭算法困环体doublerandNum=randoiT01();intj;for(j-B;jN-1;j++)if(randNump rab[j])selectld[i]*j;break;(jN-1)selectld[i]=j;//把种群更新为新选挥的个体集合for(inti=0;itemGroup[i]=g^oup[i]for(intift;igroup[i]=temOrc upfselectId[i]];但实验时发现结果不好,经过仔细研究之后发现,这里在取某些值的时候,目标函数计算出来的适应值可能会出现负值,这时如果按照把每个个体的适应值除以适应值的总和的进行归一化的话会出现问题,因为个体可能出现负值,总和也可能出现负值,如果归一化的时候除以了一个负值,选择时就会选择一些不良的个体,对实验结果造成影响。