08 构建进化树 17-18
- 格式:ppt
- 大小:3.95 MB
- 文档页数:18

构建进化树的步骤通常包括以下几个关键环节:
1. 数据收集:收集相关的生物序列数据,这些数据可以来自于公共数据库,如NCBI的GenBank,也可以通过实验获得。
序列数据包括DNA或蛋白质序列。
2. 序列alignment(序列比对):使用比对软件如Clustal Omega、MAFFT、MUSCLE等,将收集到的序列进行比对,以确保序列的同源性,并消除由于序列变异导致的噪音。
3. 序列拼接和校正:对测序得到的正向和反向序列进行拼接和校正,以获得完整的序列。
常用的拼接软件有Contig Express、Geneious 和Sequencher等。
4. 选择合适的模型:根据序列数据选择合适的进化模型。
可以使用软件如Modeltest来评估不同的进化模型,选择BIC(Bayesian Information Criterion)分数最低的模型。
5. 建树:选择合适的软件和建树方法来构建进化树。
常用的软件有MEGA、PhyML、MrBayes等,建树方法包括NJ(邻接法)、MP (最大简约法)、ML(最大似然法)等。
6. 建树检验:使用如Bootstrap方法等来检验所建树的稳定性和可靠性。
Bootstrap方法通过重复抽样来检验建树的节点支持度。
7. 绘制进化树:使用软件如TreeDraw、FigTree或在线工具来绘制进化树的图像,以便于分析和展示。


生物大数据分析中的进化遗传树构建方法与技巧进化遗传树(Phylogenetic Tree)是生物学研究中用于分析物种关系和演化历程的重要工具。
通过构建进化树,我们可以了解不同物种之间的进化关系,揭示物种的演化历史以及预测它们之间的共同祖先。
在生物大数据分析中,构建进化遗传树有着重要的意义,因为它可以帮助我们理解生物的遗传多样性、物种起源以及群体分化等重要生物学问题。
在构建进化遗传树的过程中,我们需要根据生物学数据来推断物种间的关系。
这些生物学数据可以是DNA或RNA序列、蛋白质序列、形态特征等。
为了准确地构建进化遗传树,我们需要选择合适的方法和技巧。
下面将介绍一些常用的进化遗传树构建方法和技巧。
1. 距离法(Distance-based methods):距离法是通过计算物种间的相似度或差异度来构建进化遗传树的方法。
常用的距离法包括最邻近法(Neighbor Joining)、最小进化法(Minimum Evolution)和最大简约法(Maximum Parsimony)等。
这些方法根据不同的算法和模型,通过计算物种间的距离矩阵来构建进化关系。
2. 贝叶斯方法(Bayesian methods):贝叶斯方法是一种基于统计模型和概率推断的进化遗传树构建方法。
它通过采用贝叶斯推断和蒙特卡洛马尔科夫链蒙特卡洛算法(MCMC)来估计进化树的拓扑结构和参数。
贝叶斯方法具有高度灵活性和更准确的模型,适用于复杂的进化树推断问题。
3. 最大似然方法(Maximum likelihood methods):最大似然方法是一种常用的基于概率统计的进化遗传树构建方法。
它通过最大化观测到的数据出现的概率,推断出可能的进化树。
最大似然方法考虑了模型中的参数估计问题,并用参数化的模型来描述进化过程,从而提高了推断结果的准确性。
在进行进化遗传树构建时,还有一些技巧需要注意,以保证结果的准确性和可靠性:1. 数据质量的控制:数据质量是构建进化遗传树的关键因素之一。

极为详细的建树方法,新手入门推荐生物进化树的构建目录前言 (2)一、 NCBI (6)二、 Mega (9)三、 DNAMAN (15)四、DNAStar (18)五、 Bio edit (21)前言1.背景资料进化树(evolutionary tree)又名系统树(phylogenetie tree)进化树,用来表示物种间亲缘关系远近的树状结构图。
在进化树中,各个分类单元(物种)依据进化关系的远近,被安放在树状图表上的不同位置。
所以,进化树简单地表示生物的进化历程和亲缘关系。
已发展成为多学科(包括生命科学中的进化论、遗传学、分类学、分子生物学、生物化学、生物物理学和生态学,又包括数学中的概率统计、图论、计算机科学和群论)交叉形成的一个边缘领域。
归纳总结生物进化的总趋势有以下几类:①结构上:由简单到复杂②生活环境上:由水生到陆生③进化水平上:由低等到高等一般来说,进化树是一个二叉树。
它由很多的分支和节点构成。
根据位置的不同,进化树的节点分为外部节点和内部节点,外部节点就是我们要进行分类的分类单元(物种)。
而物种之间的进化关系则用节点之间的连线表示。
内部节点表示进化事件发生的地方,或表示分类单元进化的祖先。
在同一个进化树中,分类单元的选择应当标准一致。
进化树上不同节点之间的连线称为分支,其中有一端与叶子节点相连的分支称为外枝,不与叶子节点相连的分支称为内枝。
进化树一般有两种:有根树和无根树。
有根树有一个鲜明的特征,那就是它有一个唯一的根节点。
这个根节点可以理解为所有其他节点的共同祖先。
所以,有根树能可以准确地反映各个物种的进化顺序,从根节点进化到任何其他节点只有能有一条惟一的路径。
无根树则不能直接给出根节点,无根树只反映各个不同节点之间的进化关系的远近,没有物种如何进化的过程。
但是,我们可以在无根树种指派根节点,从而找出各个物种的进化路径。
无根树有根树放射树分子进化树(以分子数据为依据构建的进化树)不仅精确地反映物种间或群体间在进化过程中发生的极微细的遗传变异(小至一个氨基酸或一个核昔酸差异),而且借助化石提供的大分子类群的分化年代能定量地估计出物种间或群体间的分化年代,这对进化论的研究而言无疑是一场革命。

分子进化学中的进化树构建方法随着科技的进步和生物技术的广泛应用,分子生物学的研究逐渐深入,成为生物学、生物技术和医药学等领域的重要研究方向。
而分子进化学作为分子生物学中的一个重要分支,研究物种间的分子差异和进化关系。
其中,构建进化树是分子进化学研究中的重要工作,下面我们来了解一下进化树构建的方法。
一、进化树的基本概念进化树是描述不同物种、不同基因或不同蛋白质之间进化关系的图形化表示。
在进化树中,每一个分支代表了一个物种、一个基因或一个蛋白质序列,分支的长度表示了物种、基因或序列的进化距离,而进化距离则是衡量不同物种或不同序列之间关系的基本参数。
而构建进化树的过程则是根据分子序列数据的重构得到物种或基因的进化树。
二、进化树的构建方法构建进化树有多种方法,主要有距离矩阵法、系统发育学法、最大似然法和贝叶斯法等。
下面我们逐一介绍这些方法的基本原理。
1.距离矩阵法距离矩阵法是最早采用的一种构建进化树的方法,它基于序列之间的距离矩阵计算和聚类方法来得到进化树。
该方法首先计算所有分子序列之间的距离(距离可由序列相似性计算得出),然后根据聚类方法构建进化树。
聚类方法包括单链接聚类、均链接聚类和最大链接聚类等。
距离矩阵法的优点是构建速度快、适用性广,但是对于高变异的序列来说,该方法可能会产生误导性的结果。
2.系统发育学法系统发育学法是基于系统学原理,采用系统发生学的理论和方法来构建进化树。
该方法主要是通过分子序列的相似性构建系统发育分析矩阵,然后利用不同的计算方法(如UPGMA、NJ和ML等)推断进化树。
系统发育学法的优点是能够更准确地反映分子序列的演化,并且可以通过不同的方法比较结果,但是该方法需要大量的计算资源和长时间的计算。
3.最大似然法最大似然法是一种统计学上的方法,通过最大化序列数据与观测数据的相似度,来推断出最可能的进化树。
该方法需要整合进化模型和数据,然后计算不同进化模型下数据的似然函数,最终选择似然度最大的进化树。
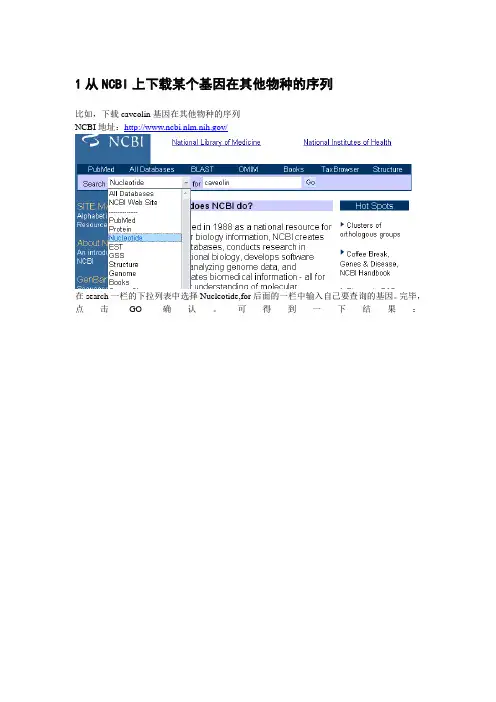
1从NCBI上下载某个基因在其他物种的序列比如,下载caveolin基因在其他物种的序列NCBI地址:/在search一栏的下拉列表中选择Nucleotide,for后面的一栏中输入自己要查询的基因。
完毕,点击GO确认。
可得到一下结果:每一条记录分别是某个物种的caveolin的序列,以第10条记录为例,称为GenBank 登录号。
为拉丁文的人类的字母,表示物种,表示基因名称(caveolin基因家族共有3个主要基因,分别称为1,2,3)表示此序列为cDNA,不含内含子。
下图中的NEXT表示翻页,查看剩余的记录。
打开第10条记录可看到下图:现在你需要保存下来得就是上面的这一串(碱基)核酸序列。
复制黏贴(包括上面表示顺序的数字)到TXT文本中备用。
打开DNAMAN软件,左上角点击file-new,出现下图:可以把先前从NCBI下载的序列(保存到TXT文本中得)复制到箭头指示处,得到:并按照上图左上角file-save as(注意此文件得保存名称为保存的此物中得名称),已上是DNAMAN软件中seq序列格式的保存方法。
2 序列编辑和比对(DNAMAN软件)你们实验PCR得到的序列只是某个基因上的一部分,所以为了进行不同物种间的比对,要把下载下来的其他物种的某个基因的序列进行删减,以使两段基因是大约相同长度的片段进行比对。
以人类caveolin1基因为例说明一下。
按照1,2,3得顺序依次打开,得到下图:点击上图中的1,你会得到下图,点击2是清楚所有刚才选进比对的序列(为了重新选择序列),3是有选择的删除某个序列。
当然,把你的所有准备的序列保存好以后,从查找范围这个下拉列表中寻找你要比对的序列。
可以按住ctrl点击你要比对的几个序列(同时选中)选完点击打开。
再点下图中得确定键。
得到下图:找好这两个物种重合的那个核苷酸的序号(前后两段都是),然后打开你保存的seq格式的序列,数出刚才比对重合部分的后端的碱基数,把这个碱基后面的序列删掉,再用此方法把比对重合部分前段得序列删掉,保存。


构建系统进化树的详细步骤1. 建树前的准备工作1.1 相似序列的获得——BLASTBLAST是目前常用的数据库搜索程序,它是Basic Local Alignment Search Tool 的缩写,意为“基本局部相似性比对搜索工具”(Altschul et al.,1990[62];1997[63])。
国际著名生物信息中心都提供基于Web的BLAST服务器。
BLAST算法的基本思路是首先找出检测序列和目标序列之间相似性程度最高的片段,并作为核向两端延伸,以找出尽可能长的相似序列片段。
首先登录到提供BLAST服务的常用,比如国的CBI、美国的NCBI、欧洲的EBI和日本的DDBJ。
这些提供的BLAST服务在界面上差不多,但所用的程序有所差异。
它们都有一个大的文本框,用于粘贴需要搜索的序列。
把序列以FASTA格式(即第一行为说明行,以“>”符号开始,后面是序列的名称、说明等,其中“>”是必需的,名称及说明等可以是任意形式,换行之后是序列)粘贴到那个大的文本框,选择合适的BLAST程序和数据库,就可以开始搜索了。
如果是DNA序列,一般选择BLASTN搜索DNA数据库。
这里以NCBI为例。
登录NCBI主页-点击BLAST-点击Nucleotide-nucleotide BLAST (blastn)-在Search文本框中粘贴检测序列-点击BLAST!-点击Format-得到result of BLAST。
BLASTN结果如何分析(参数意义):>gi|28171832|gb|AY155203.1| Nocardia sp. ATCC 49872 16S ribosomal RNA gene, completesequenceScore = 2020 bits (1019), Expect = 0.0Identities = 1382/1497 (92%), Gaps = 8/1497 (0%) Strand = Plus / PlusQuery: 1 gacgaacgctggcggcgtgcttaacacatgcaagtcgagcggaaaggccctttcgggggt 60|||||||||||||||||||||||||||||||||||||||||| ||||||||| ||||| Sbjct: 1 gacgaacgctggcggcgtgcttaacacatgcaagtcgagcggtaaggcccttc--ggggt 58Query: 61 actcgagcggcgaacgggtgagtaacacgtgggtaacctgccttcagctctgggataagc 120|| ||||||||||||||||||||||||||||||| | |||||| ||||||||||||| Sbjct: 59 acacgagcggcgaacgggtgagtaacacgtgggtgatctgcctcgtactctgggataagc 118Score :指的是提交的序列和搜索出的序列之间的分值,越高说明越相似; Expect:比对的期望值。

基因进化树的构建
基因进化树(Phylogenetic tree)是用来描述不同物种或个体之间基因演化关系的一种图形表示方法。
构建基因进化树可以帮助我们了解物种之间的亲缘关系和演化历史。
以下是构建基因进化树的一般步骤:
1.收集基因序列数据:首先,需要收集感兴趣物种或个体的基因序列数据。
这些基因序列可以是DNA序列、蛋白质序列或其他分子标记。
2.序列比对:将收集到的基因序列进行比对,找出相同的区域。
这可以通过使用比对算法(如ClustalW、MAFFT等)来完成。
比对后的序列将有助于确定物种或个体之间的相似性。
3.构建进化模型:选择适合你的数据的进化模型。
进化模型描述了基因在演化过程中的变化方式。
常见的进化模型包括Jukes-Cantor模型、Kimur a模型、GTR模型等。
选择适当的模型可以提高进化树的准确性。
4.构建进化树:使用构建进化树的方法,如最大似然法(Maximum Li kelihood)、贝叶斯推断(Bayesian Inference)或距离法(Distance-based m ethods)来构建进化树。
这些方法基于序列的相似性和进化模型来计算物种或个体之间的进化距离或相似性。
5.进化树评估和解释:评估构建的进化树的可靠性和准确性。
可以使用统计方法(如Bootstrap分析)来评估节点的支持度。
解释进化树的结果,包括物种或个体之间的亲缘关系和演化历史。

氨基酸序列构建进化树构建进化树听起来好像是一件严肃的事情,但其实这背后充满了趣味和故事。
想象一下,科学家们像探险家一样,穿越在氨基酸的世界里,追寻着生命的起源。
氨基酸,就像是生命的“建筑块”,从单细胞生物到复杂的动物,人类都是由这些小家伙串联而成的。
每一个氨基酸都有自己的性格,简直就像是个个性鲜明的朋友。
咱们先聊聊什么是进化树。
它就像是一个家族树,记录着各种生物是怎么从共同的祖先演化而来的。
科学家们通过分析氨基酸序列,可以找出不同物种之间的亲缘关系。
就像朋友聚会,总有一些人有着相似的嗜好和习惯,进化树就是把这些相似性一一列出来,让大家一目了然。
通过对比,我们可以看到某些物种有多亲近,甚至可以推测出它们的“家庭历史”。
氨基酸序列的比对其实就像是一场侦探游戏。
想象一下,科学家们拿着放大镜,一边观察一边记录。
他们会把不同生物的氨基酸序列拿出来,像拼图一样拼在一起。
每个序列都是独一无二的,充满了信息。
通过这些信息,他们能发现哪些氨基酸是相似的,哪些又是独特的。
就像侦探根据指纹找到嫌疑犯,科学家们通过这些序列找到了生物间的关系。
做这些分析的时候,细心可是一门绝对不可或缺的艺术。
氨基酸的变化,可能意味着物种的分化。
举个例子,如果你在某个氨基酸位置上发现了个小变化,这可不简单,这可能意味着这两个生物已经走上了不同的进化道路。
简直就像朋友之间因为某个小争执而渐行渐远。
科学家们发现的差异简直像是从一个乡村到大都市的转变,那种差别大得让人瞠目结舌。
在这个过程中,技术的力量不可小觑。
现在的科学家可以使用一些高科技工具,比如基因测序,帮助他们更快地获取氨基酸序列。
想象一下,那些昔日靠手工比对的人,现在可以轻松点击几下鼠标,便能获取大量数据。
这就像是从原始打猎变成了今天的网上购物,简直是“科技改变生活”的真实写照。
构建进化树不仅仅是为了满足好奇心,它还有实际应用。
比如说,在医学上,通过分析病原体的氨基酸序列,可以帮助科学家了解病毒是如何演化的。

进化树构建参数一、概述进化树构建是生物信息学中的一个重要研究领域,它涉及到许多参数的选择和优化。
进化树构建是基于已知序列的演化关系,通过计算分子进化模型的距离或相似度,从而推断不同物种之间的进化关系。
本文将详细介绍构建进化树时需要考虑的参数。
二、参数种类1. 样本选择:样本选择是构建进化树时必须考虑的第一个因素。
样本数量和种类的选择对于构建出准确可靠的进化树至关重要。
2. 进化模型:不同基因序列在演变过程中所遵循的进化模型是不同的,常见有Jukes-Cantor模型、Kimura 2-parameter模型、HKY85模型等。
3. 距离度量方法:距离度量方法包括无权法(UPGMA)、加权法(WPGMA)、最小演化法(ME)、最大简约法(MP)等。
4. 系统发育假设:系统发育假设包括分子钟假说和非分子钟假说两种,分别应用于有无时间信息两种情况下。
5. 支持率阈值:支持率阈值指代各节点的支持率,通常以Bootstrap值或Bayesian后验概率等指标表示。
支持率阈值越高,节点的可靠性越高,但会导致树的拓扑结构出现偏差。
三、参数选择1. 样本选择:样本应该代表各个物种的演化历史,并且应该包含足够数量的序列以减少噪音和随机误差对结果的影响。
2. 进化模型:进化模型应该选择最适合数据集特征的模型。
可以使用模型比较方法(如AIC、BIC等)来确定最优模型。
3. 距离度量方法:距离度量方法应该根据不同数据集和研究问题进行选择。
UPGMA适用于相对简单的数据集,而ME和MP适用于复杂的数据集。
4. 系统发育假设:系统发育假说应该根据具体情况进行选择。
分子钟假说适用于有时间信息的数据集,而非分子钟假说则适用于无时间信息或时间信息不可靠的数据集。
5. 支持率阈值:支持率阈值应该根据具体情况进行选择。
通常建议设置在70%以上。
四、参数优化1. 交叉验证法:交叉验证法可以用来选择最优的进化模型和距离度量方法。
2. Bootstrap分析:Bootstrap分析可以用来评估节点的支持率阈值,并且可以用来检测树的拓扑结构是否稳定。
一、获取序列一般自己通过测序得到一段序列(已知或未知的都可以),通过NCBI的BLAST获取相似性较高的一组序列,下载保存为FASTA格式。
用BIOEDIT等软件编辑序列名称,注意PHYLIP 在DOS下运行,文件名不能超过10位,超过的会自动截留前面10位。
二、多序列比对目前一般应用CLASTAL X进行,注意输出格式选用PHY格式。
生成的指导树文件(DND文件)可以直接用TREEVIEW打开编辑,形式上和最终生成的进化树类似,但是注意不是真正的进化树。
三、构建进化树1.N-J法建树依次应用PHYLIP软件中的SEQBOOT.EXE、DNA DIST.EXE、NEIGHBOR.EXE和CONSENSE.EXE打开。
具体步骤如下:(1)打开seqboot.exe输入文件名:输入你用CLASTAL X生成的PHY文件(*.phy)。
R为bootstrap的次数,一般为1000 (设你输入的值为M,即下两步DNA DIST.EXE、NEIGHBOR.EXE中的M值也为1000)odd number: (4N+1)(eg: 1、5、9…)改好了y得到outfile(在phylip文件夹内)改名为2(2)打开Dnadist.EXE输入2修改M值,再按D,然后输入1000(M值)y得到outfile(在phylip文件夹内)改名为3(3)打开Neighboor.EXE输入3M=1000(M值)按Y得到outfile和outtree(在phylip文件夹内)改outtree为4,outfile改为402(4)打开consense.exe输入4y得到outfile和outtree(在phylip文件夹内)Outfile可以改为*.txt文件,用记事本打开阅读。
四、进化树编辑和阅读outtree可改为*.tre文件,直接双击在treeview里看;也可以不改文件扩展名,直接用treeview、PHYLODRAW、NJPLOT等软件打开编辑。
邻接法构建系统进化树
邻接法是一种常用的构建系统进化树的方法。
该方法通过研究不同物种之间的形态、生理、生态等方面的差异,以及它们的遗传距离和进化历史,将它们之间的关系以树形结构表示出来,以更好地理解和研究它们之间的演化关系。
邻接法的核心思想是基于“邻接矩阵”的概念来构建进化树。
邻接矩阵是一种方阵,其中每个元素代表两个物种之间的相似性或差异性。
通过计算不同物种之间的相似性或差异性,可以得到一个N×N 的邻接矩阵,其中N代表物种数目。
在构建进化树的过程中,邻接矩阵会不断被更新和改变。
首先,根据邻接矩阵中不同物种之间的相似性或差异性,可以将相似性较高的物种聚为一类。
然后,通过计算不同类之间的相似性或差异性,可以得到新的邻接矩阵。
这个过程不断迭代,直到只剩下一个类为止。
最终,得到的进化树就是基于邻接矩阵构建出来的。
邻接法构建系统进化树的优点是计算速度快,而且结果可靠。
与此同时,它也存在一些缺陷,比如无法处理物种之间的多样性,以及缺乏模型支持等问题。
因此,在使用邻接法时,需要根据研究的具体问题和数据特点来选择合适的方法。
- 1 -。
⼀步⼀步教你构建进化树(ML树)⼤多数⼈习惯了利⽤MEGA构建NJ树,速度快,准确性也不是很差。
但是⽐较严格做法是,构建多种树进⾏⽐较,⽐较常⽤的那就是ML树。
⾼质量期刊⼀般会采⽤NJ树和ML树相互验证的⽅法。
构建ML树,速度较慢,⼤家需要注意。
构树常⽤的软件流程基本上可以采⽤MUSCLE+PhyML了。
1. MUSCLE由于利⽤PhyML构建ML树,需要phy格式的⽐对⽂件,因此需要⽤MUSCLE产⽣。
需要注意的⼀点是phy格式⽐对⽂件对序列ID要求最多10个字符,因此构树之前要进⾏更改。
如下图,Glyma.10G0这个ID如果不更改,最终⽐对完成后会显⽰ID的前⼗个字符,其全部的ID是Glyma.10G010000。
修改的脚本参照下⾯:my $num=1;`mkdir $od` unless (-d '$od');$od=“Change_ID”###输出⽬录,可以⾃定义$fa=“test.fa”;###序列⽂件名字,改成你⾃⼰的即可$index='mapk';###4个字符以内的任意前缀my %VS;open (OUT,'>$od/VS.txt')|| die 'cannot open $od:$!';###ID 改前后对照表open (SEQ,'>$od/change_name.fa')|| die 'cannot open $od/change_name.fa:$!';my $ina = Bio::SeqIO->new(-file => $fa, -format => 'fasta');while(my $obj = $ina->next_seq()){my $id = $obj->id;my $seq = $obj->seq;my $id2='$index$num';$VS{$id}=$id2;$num++;print SEQ '>$id2\n$seq\n';}close SEQ;foreach my $key(keys %VS){print OUT '$key\t$VS{$key}\n';}修改完成后进⾏MUSCLE⽐对,注意⽐对输出格式选择:muscle -in change_name.fa -phyiout change_name.fa.phy2. ML树构建。