伍德里奇《计量经济学导论》(第5版)笔记和课后习题详解-第11章 OLS用于时间序列数据的其他问题【
- 格式:pdf
- 大小:8.06 MB
- 文档页数:36



第1章解决问题的办法1.1(一)理想的情况下,我们可以随机分配学生到不同尺寸的类。
也就是说,每个学生被分配一个不同的类的大小,而不考虑任何学生的特点,能力和家庭背景。
对于原因,我们将看到在第2章中,我们想的巨大变化,班级规模(主题,当然,伦理方面的考虑和资源约束)。
(二)呈负相关关系意味着,较大的一类大小是与较低的性能。
因为班级规模较大的性能实际上伤害,我们可能会发现呈负相关。
然而,随着观测数据,还有其他的原因,我们可能会发现负相关关系。
例如,来自较富裕家庭的儿童可能更有可能参加班级规模较小的学校,和富裕的孩子一般在标准化考试中成绩更好。
另一种可能性是,在学校,校长可能分配更好的学生,以小班授课。
或者,有些家长可能会坚持他们的孩子都在较小的类,这些家长往往是更多地参与子女的教育。
(三)鉴于潜在的混杂因素 - 其中一些是第(ii)上市 - 寻找负相关关系不会是有力的证据,缩小班级规模,实际上带来更好的性能。
在某种方式的混杂因素的控制是必要的,这是多元回归分析的主题。
1.2(一)这里是构成问题的一种方法:如果两家公司,说A和B,相同的在各方面比B公司à用品工作培训之一小时每名工人,坚定除外,多少会坚定的输出从B 公司的不同?(二)公司很可能取决于工人的特点选择在职培训。
一些观察到的特点是多年的教育,多年的劳动力,在一个特定的工作经验。
企业甚至可能歧视根据年龄,性别或种族。
也许企业选择提供培训,工人或多或少能力,其中,“能力”可能是难以量化,但其中一个经理的相对能力不同的员工有一些想法。
此外,不同种类的工人可能被吸引到企业,提供更多的就业培训,平均,这可能不是很明显,向雇主。
(iii)该金额的资金和技术工人也将影响输出。
所以,两家公司具有完全相同的各类员工一般都会有不同的输出,如果他们使用不同数额的资金或技术。
管理者的素质也有效果。
(iv)无,除非训练量是随机分配。
许多因素上市部分(二)及(iii)可有助于寻找输出和培训的正相关关系,即使不在职培训提高工人的生产力。

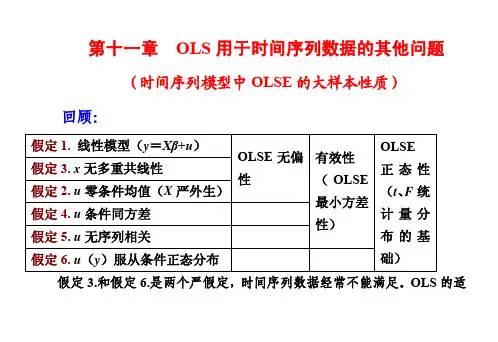
第12章 时间序列回归中的序列相关和异方差12.1 复习笔记一、含序列相关误差时OLS 的性质 1.无偏性和一致性在时间序列回归的前3个高斯-马尔可夫假定(TS.1~TS.3)之下,OLS 估计量是无偏的。
特别地,只要解释变量是严格外生的,无论误差中的序列相关程度如何,ˆj β都是无偏的。
这类似于误差中的异方差不会造成ˆjβ产生偏误。
把严格外生性假定放松到()0t t E u X =,并证明了当数据是弱相关的时候,ˆjβ仍然是一致的(但不一定无偏)。
这一结论不以对误差中序列相关的假定为转移。
2.效率和推断高斯-马尔可夫定理要求误差的同方差性和序列无关性,所以,在出现序列相关时,OLS 便不再是BLUE 的了。
通常的OLS 标准误和检验统计量也不再确当,而且连渐近确当都谈不上。
在序列相关的时候,通常的方差估计量都是()1ˆVar β的有偏估计。
因为ˆj β的标准误是ˆjβ的标准差的估计值,所以在出现序列相关的时候,使用通常的OLS 标准误就不再确当。
因此,检验单个假设的t 统计量也不再确当。
因为较小的标准误意味着较大的t 统计量,所以当ρ>0时,通常的统计量常常过大。
用于检验多重假设的通常的F 统计量和LM 统计量也不再可靠。
3.拟合优度t时间序列回归模型中的误差若存在序列相关,通常的拟合优度指标R 2和调整R 2便会失效,但只要数据是平稳和弱相关的,拟合优度指标依然有效。
在横截面背景中将总体R 2定义为221/u y σσ-。
在使用平稳而又弱相关数据的时间序列回归背景中,这个定义依然确当:误差和因变量的方差都不随时间而变化。
根据大数定律,R 2和调整R 2都是总体R 2的一致估计。
拟合优度指标仍是总体参数的一致估计量。
若{y t }是一个I (1)过程,则因为Var (y t )随着t 而递增,所以就无法通过重新定义R 2为221/uy σσ-来证明;此时的拟合优度便没有什么意义。
4.出现滞后因变量时的序列相关回归中出现滞后因变量时,误差有序列相关的危险。

伍德⾥奇《计量经济学导论》笔记和课后习题详解(⼀个经验项⽬的实施)【圣才出品】第19章⼀个经验项⽬的实施19.1 复习笔记⼀、问题的提出提出⼀个⾮常明确的问题,其重要性不容忽视。
如果没有明确阐述假设和将要估计的模型类型,那么很可能会忘记收集某些重要变量的信息,或是从错误的总体中取样,甚⾄收集错误时期的数据。
1.查找数据的⽅法《经济⽂献杂志》有⼀套细致的分类体系,其中每篇论⽂都有⼀组标识码,从⽽将其归于经济学的某⼀⼦领域之中。
因特⽹(Internet)服务使得搜寻各种主题的已发表论⽂更为⽅便。
《社会科学引⽤索引》(Social Sciences Citation Index)在寻找与社会科学各个领域相关的论⽂时⾮常有⽤,包括那些时常被其他著作引⽤的热门论⽂。
⽹络搜索引擎“⾕歌学术”(Google Scholar)对于追踪各类专题研究或某位作者的研究特别有帮助。
2.构思题⽬时⾸先应明确的⼏个问题(1)要使⼀个问题引起⼈们的兴趣,并不需要它具有⼴泛的政策含义;相反地,它可以只有局部意义。
(2)利⽤美国经济的标准宏观经济总量数据来进⾏真正原创性的研究⾮常困难,尤其对于⼀篇要在半个或⼀个学期之内完成的论⽂来说更是如此。
然⽽,这并不意味着应该回避对宏观或经验⾦融模型的估计,因为仅增加⼀些更新的数据便对争论具有建设性。
⼆、数据的收集1.确定适当的数据集⾸先必须确定⽤以回答所提问题的数据类型。
最常见的类型是横截⾯、时间序列、混合横截⾯和⾯板数据集。
有些问题可以⽤任何⼀种数据结构进⾏分析。
确定收集何种数据通常取决于分析的性质。
关键是要考虑能够获得⼀个⾜够丰富的数据集,以进⾏在其他条件不变下的分析。
同⼀横截⾯单位两个或多个不同时期的数据,能够控制那些不随时间⽽改变的⾮观测效应,⽽这些效应通常使得单个横截⾯上的回归失效。
2.输⼊并储存数据⼀旦你确定了数据类型并找到了数据来源,就必须把数据转变为可⽤格式。
通常,数据应该具备表格形式,每次观测占⼀⾏;⽽数据集的每⼀列则代表不同的变量。
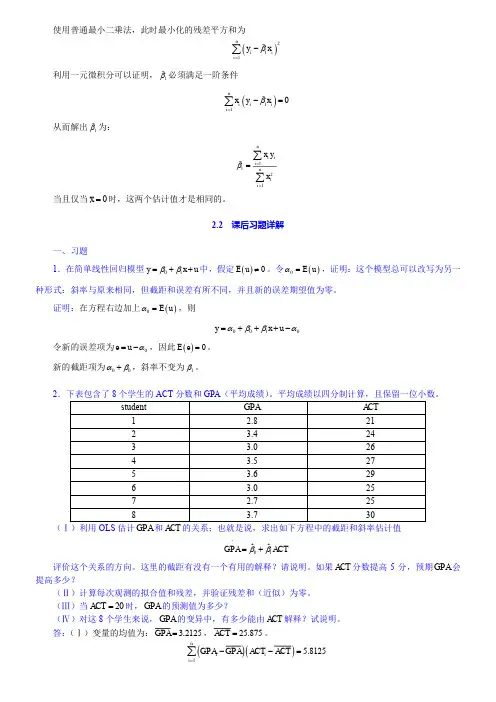
使用普通最小二乘法,此时最小化的残差平方和为()211niii y x β=-∑利用一元微积分可以证明,1β必须满足一阶条件()110niiii x y x β=-=∑从而解出1β为:1121ni ii nii x yxβ===∑∑当且仅当0x =时,这两个估计值才是相同的。
2.2 课后习题详解一、习题1.在简单线性回归模型01y x u ββ=++中,假定()0E u ≠。
令()0E u α=,证明:这个模型总可以改写为另一种形式:斜率与原来相同,但截距和误差有所不同,并且新的误差期望值为零。
证明:在方程右边加上()0E u α=,则0010y x u αββα=+++-令新的误差项为0e u α=-,因此()0E e =。
新的截距项为00αβ+,斜率不变为1β。
2(Ⅰ)利用OLS 估计GPA 和ACT 的关系;也就是说,求出如下方程中的截距和斜率估计值01ˆˆGPA ACT ββ=+^评价这个关系的方向。
这里的截距有没有一个有用的解释?请说明。
如果ACT 分数提高5分,预期GPA 会提高多少?(Ⅱ)计算每次观测的拟合值和残差,并验证残差和(近似)为零。
(Ⅲ)当20ACT =时,GPA 的预测值为多少?(Ⅳ)对这8个学生来说,GPA 的变异中,有多少能由ACT 解释?试说明。
答:(Ⅰ)变量的均值为: 3.2125GPA =,25.875ACT =。
()()15.8125niii GPA GPA ACT ACT =--=∑根据公式2.19可得:1ˆ 5.8125/56.8750.1022β==。
根据公式2.17可知:0ˆ 3.21250.102225.8750.5681β=-⨯=。
因此0.56810.1022GPA ACT =+^。
此处截距没有一个很好的解释,因为对样本而言,ACT 并不接近0。
如果ACT 分数提高5分,预期GPA 会提高0.1022×5=0.511。
(Ⅱ)每次观测的拟合值和残差表如表2-3所示:根据表可知,残差和为-0.002,忽略固有的舍入误差,残差和近似为零。

伍德里奇《计量经济学导论》复习笔记和课后习题详解-含有定性信息的多元回归分析:二值变量第7章含有定性信息的多元回归分析:二值(或虚拟)变量7.1复习笔记考点一:带有虚拟自变量的回归★★★★★1.对定性信息的描述定性信息是指通常以二值信息(0-1)的形式出现的信息,如性别、是否结婚等。
在计量经济学中,二值变量又称为虚拟变量。
2.只有一个虚拟自变量(1)只有一个虚拟自变量的简单模型考虑决定小时工资的简单模型:wage=β0+δ0female+β1educ +u。
根据多元回归的解释方式,δ0表示控制educ不变时,female 变化1单位给wage带来的变化。
假定零条件均值假定E(u|female,educ)=0成立,那么:δ0=E(wage|female=1,educ)-E (wage|female=0,educ),其中female=1表示女性,female =0表示男性。
可以发现,在任意教育水平下,男性与女性的工资差异是固定的,女性工资比男性工资多δ0。
除了β0之外,模型中只需要引入一个虚拟变量。
因为female+male=1,所以引入两个虚拟变量会导致完全多重共线性,即虚拟变量陷阱。
(2)当因变量为log(y)时,对虚拟解释变量系数的解释当变量中有一个或多个虚拟变量,且因变量以对数的形式存在时,虚拟变量的系数可以理解为百分比的变化。
将虚拟变量的系数乘以100,表示的是在保持所有其他因素不变时y 的百分数差异,精确的百分数差异为:100·[exp(∧β1)-1]。
其中∧β1是一个虚拟变量的系数。
3.使用多类别虚拟变量(1)在方程中包括虚拟变量的一般原则如果回归模型具有g 组或g 类不同截距,一种方法是在模型中包含g-1个虚拟变量和一个截距。
基组的截距是模型的总截距,某一组的虚拟变量系数表示该组与基组在截距上的估计差异。
如果在模型中引入g 个虚拟变量和一个截距,将会导致虚拟变量陷阱。
另一种方法是只包括g 个虚拟变量,而没有总截距。


伍德里奇《计量经济学导论》(第5版)笔记和课后习题详解-第11章OLS用于时间序列数据的其他问题【第11章OLS 用于时间序列数据的其他问题11.1复习笔记一、平稳和弱相关时间序列1.平稳和非平稳时间序列平稳时间序列过程,就是概率分布在如下意义上跨时期稳定的时间序列过程:如果从这个序列中任取一个随机变量集,并把这个序列向前移动h 个时期,那么其联合概率分布仍然保持不变。
(1)平稳随机过程对于随机过程{ 1 2 }t x t =:,,…,如果对于每一个时间指标集121m t t t ≤<<12 m t h t h t h x x x +++,,,的联合分布相同,那么这个随机过程就是平稳的。
这种平稳经常称为严平稳,它是从概率分布的角度去定义的。
其含义之一是(取m=1和t 1=1):对所有t=2,3,…,x 1与x t 都有相同的分布。
序列{ 1 2 }t x t =:,,…是同分布的。
不平稳的随机过程称为非平稳过程。
因为平稳性是潜在随机过程而非其某单个实现的性质,所以很难判断所搜集到的数据是否由一个平稳过程生成。
但是,要指出某些序列不是平稳的却很容易。
(2)协方差平稳过程(宽平稳,弱平稳)对于一个具有有限二阶矩()2t E x ??∞??<的随机过程{ 1 2 }t x t =:,,…,若:(i)E(x t )为常数;(ii)Var(x t )为常数;(iii)对任何t,h≥1,Cov(x t ,x t+h )仅取决于h,而不取决于t,那它就是协方差平稳的。
协方差平稳只考虑随机过程的前两阶矩:这个过程的均值和方差不随着时间而变化,而且,x t 和x t+h 的协方差只取决于这两项之间的距离h,与起始时期t 的位置无关。
由此立即可知x t 与x t+h 之间的相关性也只取决于h。
如果一个平稳过程具有有限二阶矩,那么它一定是协方差平稳的,但反过来未必正确。
由于严平稳的条件比较苛刻,在实际中从概率分布的角度去验证是无法实现的,所以在实际运用中所指的平稳都是指宽平稳,即协方差平稳。

2.10(iii) From (2.57), Var(1ˆβ) = σ2/21()n i i x x =⎛⎫- ⎪⎝⎭∑. 由提示:: 21n ii x =∑ ≥ 21()n i i x x =-∑, and so Var(1β) ≤ Var(1ˆβ). A more direct way to see this is to write(一个更直接的方式看到这是编写) 21()ni i x x =-∑ = 221()n i i x n x =-∑, which is less than21n i i x=∑unless x = 0.(iv)给定的c 2i x 但随着x 的增加, 1ˆβ的方差与Var(1β)的相关性也增加.0β小时1β的偏差也小.因此, 在均方误差的基础上不管我们选择0β还是1β要取决于0β,x ,和n 的大小 (除了 21n i i x=∑的大小).3.7We can use Table 3.2. By definition, 2β > 0, and by assumption, Corr(x 1,x 2) < 0. Therefore, there is a negative bias in 1β: E(1β) < 1β. This means that, on average across different random samples, the simpleregression estimator underestimates the effect of the training program. It is even possible that E(1β) isnegative even though 1β > 0. 我们可以使用表3.2。
根据定义,> 0,由假设,科尔(X1,X2)<0。
因此,有一个负偏压为:E ()<。
这意味着,平均在不同的随机抽样,简单的回归估计低估的培训计划的效果。
第11章OLS用于时间序列数据的其他问题11.1复习笔记考点一:平稳和弱相关时间序列★★★★1.时间序列的相关概念(见表11-1)表11-1时间序列的相关概念2.弱相关时间序列(1)弱相关对于一个平稳时间序列过程{x t:t=1,2,…},随着h的无限增大,若x t和x t+h“近乎独立”,则称为弱相关。
对于协方差平稳序列,如果x t和x t+h之间的相关系数随h的增大而趋近于0,则协方差平稳随机序列就是弱相关的。
本质上,弱相关时间序列取代了能使大数定律(LLN)和中心极限定理(CLT)成立的随机抽样假定。
(2)弱相关时间序列的例子(见表11-2)表11-2弱相关时间序列的例子考点二:OLS的渐近性质★★★★1.OLS的渐近性假设(见表11-3)表11-3OLS的渐近性假设2.OLS的渐近性质(见表11-4)表11-4OLS的渐进性质考点三:回归分析中使用高度持续性时间序列★★★★1.高度持续性时间序列(1)随机游走(见表11-5)表11-5随机游走(2)带漂移的随机游走带漂移的随机游走的形式为:y t=α0+y t-1+e t,t=1,2,…。
其中,e t(t=1,2,…)和y0满足随机游走模型的同样性质;参数α0被称为漂移项。
通过反复迭代,发现y t的期望值具有一种线性时间趋势:y t=α0t+e t+e t-1+…+e1+y0。
当y0=0时,E(y t)=α0t。
若α0>0,y t的期望值随时间而递增;若α0<0,则随时间而下降。
在t时期,对y t+h的最佳预测值等于y t加漂移项α0h。
y t的方差与纯粹随机游走情况下的方差完全相同。
带漂移随机游走是单位根过程的另一个例子,因为它是含截距的AR(1)模型中ρ1=1的特例:y t=α0+ρ1y t-1+e t。
2.高度持续性时间序列的变换(1)差分平稳过程I(1)弱相关过程,也被称为0阶单整或I(0),这种序列的均值已经满足标准的极限定理,在回归分析中使用时无须进行任何处理。
伍德里奇《计量经济学导论》(第5版)笔记和课后习题详解第4章多元回归分析:推断4.1复习笔记一、OLS 估计量的抽样分布1.假定MLR.6(正态性)总体误差u 独立于解释变量12 k x x x ,,…,,而且服从均值为零和方差为2σ的正态分布:()2Normal 0 u σ~,。
2.经典线性模型就横截面回归中的应用而言,从假定MLR.1~MLR.6这六个假定被称为经典线性模型假定。
将这六个假定下的模型称为经典线性模型(CLM)。
在CLM 假定下,OLS 估计量01ˆˆˆ kβββ,,…,比在高斯—马尔可夫假定下具有更强的效率性质。
可以证明,OLS 估计量是最小方差无偏估计,即在所有的无偏估计中,OLS 具有最小的方差。
总结CLM 总体假定的一种简洁方法是:()201122|Normal k k y x x x x ββββσ++++~…,误差项的正态性导致OLS 估计量的正态抽样分布。
3.用中心极限定理去推导u 的分布的缺陷(1)虽然u 是影响y 而又观测不到的众多因素之和,且各因素可能各有极为不同的总体分布,但中心极限定理(CLT)在这些情形下仍成立。
正态近似的效果取决于u 中有多少因素,以及u 中包含因素分布的差异。
(2)更严重的问题是,正态近似假定所有不可观测因素都以独立而可加的方式影响着Y。
因此如果u 是不可观测因素的一个复杂函数,那么CLT 论证并不真正适用。
4.误差项的正态性导致OLS 估计量的正态抽样分布定理4.1:正态抽样分布在CLM 假定MLR.1~MLR.6下,以自变量的样本值为条件,有:()ˆˆ~Normal Var j j j βββ⎡⎤⎣⎦,因此()()()ˆˆ/sd ~Normal 0 1j j j βββ-,注:除ˆj β服从正态分布外,01ˆˆˆ k βββ,,…,的任何线性组合也都是正态分布,而且ˆjβ的任何一个子集也都具有一个联合正态分布。
二、检验对单个总体参数的假设:t 检验1.总体回归函数总体模型可写作:11o k k y x x uβββ=++⋯++假定它满足CLM 假定,OLS 得到j β的无偏估计量。
第11章
OLS 用于时间序列数据的其他问题11.1复习笔记
一、平稳和弱相关时间序列
1.平稳和非平稳时间序列
平稳时间序列过程,就是概率分布在如下意义上跨时期稳定的时间序列过程:如果从这个序列中任取一个随机变量集,并把这个序列向前移动h 个时期,那么其联合概率分布仍然保持不变。
(1)平稳随机过程
对于随机过程{ 1 2 }t x t =:,,…,如果对于每一个时间指标集121m t t t ≤<<⋅⋅⋅<和任意整数h≥1,()12m t t t x x x ⋅⋅⋅,,,的联合分布都与()
12 m t h t h t h x x x ++⋅⋅⋅+,,,的联合分布相同,那么这个随机过程就是平稳的。
这种平稳经常称为严平稳,它是从概率分布的角度去定义的。
其含义之一是(取m=1和t 1=1):对所有t=2,3,…,x 1与x t 都有相同的分布。
序列{ 1 2 }t x t =:,,…是同分布的。
不平稳的随机过程称为非平稳过程。
因为平稳性是潜在随机过程而非其某单个实现的性质,所以很难判断所搜集到的数据是否由一个平稳过程生成。
但是,要指出某些序列不是平稳的却很容易。
(2)协方差平稳过程(宽平稳,弱平稳)
对于一个具有有限二阶矩()2t E x ⎡⎤∞⎣⎦<的随机过程{ 1 2 }t x t =:,
,…,若:(i)E(x t )为常数;(ii)Var(x t )为常数;(iii)对任何t,h≥1,Cov(x t ,x t+h )仅取决于h,而不取决于t,那它就是协方差平稳的。
协方差平稳只考虑随机过程的前两阶矩:这个过程的均值和方差不随着时间而变化,而且,x t 和x t+h 的协方差只取决于这两项之间的距离h,与起始时期t 的位置无关。
由此立即可知x t 与x t+h 之间的相关性也只取决于h。
如果一个平稳过程具有有限二阶矩,那么它一定是协方差平稳的,但反过来未必正确。
由于严平稳的条件比较苛刻,在实际中从概率分布的角度去验证是无法实现的,所以在实际运用中所指的平稳都是指宽平稳,即协方差平稳。
一个时间序列是严平稳的不一定是宽平稳,只有当它的二阶矩存在时,才是宽平稳。
2.弱相关时间序列
(1)弱相关
对于一个平稳时间序列过程{ 1 2 }t x t =:,,…,若随着h 无限增大,x t 和x t+h “近乎独立”,则称之为弱相关的。
对于协方差平稳序列,可以用相关系数来刻画弱相关:如果随着h →∞,x t 和x t+h 之间的相关系数“足够快”地趋于0,这个协方差平稳的时间序列就是弱相关的。
换言之,随着变量在时间上的距离变大,它们之间的相关系数变得越来越小。
随着h →∞,()Corr 0t t h x x →+,的协方差平稳序列被称为渐近无关的。
(2)弱相关对回归分析重要的原因
本质上,它取代了能使大数定律(LLN)和中心极限定理(CLT)成立的随机抽样假定。
对于时间序列数据,中心极限定理要求平稳性和某种形式的弱相关,因此,在多元回归分析中使用平稳而又弱相关的时间序列最为理想。
(3)弱相关时间序列的例子
①独立同分布序列:一个独立序列无疑是弱相关序列。
②弱相关的例子是:MA(1)过程
11 1 2 t t t x e e t α-=+=,,,…
其中,()0 1 t e t =:,
,…是均值为0和方差为2e σ的独立同分布序列。
过程{}t x 被称为一阶移动平均过程[movingaverageprocessoforderone,MA(1)]:x t 是e t 和e t-1的一个加权平均;在下一期,去掉e t-1,x t+1便取决于e t+1和e t 。
MA(1)过程是弱相关的原因是序列中相邻两项之间是相关的:因为
111t t t
x e e α++=+()()2
111Cov Var t t t e x x e αασ+==,又因为
()()22
1Var 1t e x ασ=+所以
()()
2111Corr /1t t x x αα+=+,但是序列中距离在两期和两期以上的变量时,因为它们是相互独立的,所以显然无关。
因此,MA(1)是平稳弱相关的。
③AR(1)过程:
11 1 2 t t t y y e t ρ=+⋯
-,=,,序列的初始点是y 0(t=0),且(e t :t=1,2,…)是均值为0和方差为2e σ的独立同分布序列。
假定e t 独立于y 0和E(y 0)=0。
上式被称为一阶自回归过程[AR(1)]。
将上式进行迭代得到:
21111211211111111()........t h t h t h t h t h t h t h t h t h
h h t t t h t h
y y e y e e y e e y e e e ρρρρρρρρ++-++-+-++-+-+-++-+=+=++=++==++++
因为E(y t )=0,所以:
()()()()()()2122
11111,....h h h h t t h t t h t t t t t h t y Cov y y E y y E y E y e E y e E y ρρρρσ-++++==+++==y t 和y t+h 的相关系数为:
()()()1,,/h
t t h t t h y y Corr y y Cov y y σσρ++==AR (1)过程弱相关的一个关键假定是稳定性条件11ρ<。
一旦条件满足,随着h →∞,10h ρ→,称{)t y 是一个稳定的AR(1)过程,是弱相关的。
若一个序列是弱相关的,而且围绕着其时间趋势是平稳的,则可以称为趋势—平稳过程。
二、OLS 的渐近性质
1.假定TS.1'(线性与弱相关)
除了增加假定(){}1 2t t x y t =⋯,:,
是平稳和弱相关的芝外,假定TS.1'和假定TS.1完全相同。
具体而言,大数定律和中心极限定理可适用于样本均值。
线性于参数的要求意味着可以把模型写成:
011t t k tk t
y x x u βββ=++⋅⋅⋅++其中j β是待估参数,x tj 可以包含滞后因变量与解释变量的滞后项。
2.假定TS.2'(无完全共线性)
在样本中(并因而在潜在的时间序列过程中),没有任何自变量是恒定不变的,或者是其他自变量的一个完全线性组合。
3.假定TS.3'(零条件均值)
解释变量()12 t t t tk X x x x =⋯,
,,是同期外生的:()|0t t E u X =。
4.定理11.1(OLS 的一致性)
在假定TS.1'、TS.2'和TS.3'成立时,OLS 估计量是一致的:ˆplim j j
ββ=,0 1 j k =⋯,,,。
定理10.1和定理11.1之间有一些关键的区别:
(1)在定理11.1中,得到OLS 估计量的一致性结论,但并不一定是无偏的。
(2)在定理11.1中,弱化了解释变量必须外生的假定,转而要求潜在的时间序列是弱相关的。
5.假定TS.4'(同方差)
误差是同期同方差的,即对所有的t,都有
()2
Var |t t u x σ=6.假定TS.5'(无序列相关)
对所有的t s ≠,有
()|,0
t s t s E u u x x =7.定理11.2(OLS 的渐近正态性)
在假定TS.1'~TS.5'下,OLS 估计量是渐近正态分布的。
而且,通常的OLS 标准误、
t 统计量、F 统计量和LM 统计量是渐近确当的。
即使经典线性模型假定不成立,OLS 依然是一致的,通常的推断程序也是确当的。
它的前提是假定TS.1'~TS.5'都成立。
三、回归分析中使用高度持续性时间序列
1.高度持续性时间序列
(1)随机游走
①定义
在简单的AR(1)模型11 1 2 t t t y y e t ρ=+=⋅⋅⋅-,,,中,假定11ρ<能保证序列的是弱相关和平稳的。
事实表明,许多经济时间序列最好用11ρ=的AR(1)模型来刻画。
这时,可以写成:
1 1
2 t t t y y e t =+=⋅⋅⋅
-,,,假定()1 2 t e t =⋯:,
,是均值为0和方差为2e σ的独立同分布序列。
假定初始值y 0是独立于e t (t≥1)的。
上式的过程被称为一个随机游走。
在这个过程中,t 时期的y 等于上一期值y t-1加上一个独立于y t-1的零均值随机变量。
②随机游走的期望值
利用反复迭代很容易得到:
110
t t t y e e e y =++⋅⋅⋅++-两边取期望值,便得到:
()()()()()()11001
t t t E y E e E e E e E y E y t =++⋅⋅⋅++=∀≥-,因此,随机游走的期望值不取决于t 0。