五多重共线性分布滞后模型或机动
- 格式:pdf
- 大小:724.23 KB
- 文档页数:13


高级计量经济学之第5章分布滞后与动态模型第5章分布滞后与动态模型§5.1 分布滞后模型很多经济模型在回归方程中有滞后项,例如,因为修建桥和高速公路需要很多时间,所以公共投资对GDP 的影响有一个滞后期,而且这个影响可能会持续数年;研发新产品需要时间,而后把这个新产品投入生产也需要时间;在研究消费行为时,一个工资的变化可能影响好几期的消费。
在消费的恒久收入理论中,消费者会用若干期去决定真实可支配收入的变化是暂时的还是永久的。
例如,今年额外的咨询费收入明年是否还会继续?同样,真实可支配收入的滞后值会在回归方程中出现,是因为消费者在平滑其消费行为时十分重视他自身的终身收入。
一个人的终身收入可以用他过去和现在的收入来推测。
换句话说,回归关系可以写为:T t X X X Y ts t s t t t ,,2,1110 =+++++=--εβββα (5.1)其中,t Y 代表被解释变量Y 在第t 期的观测值,t s X -代表解释变量X 第t s -期的观测值,α为截距项,0β,1β,…,s β是t X 当期和滞后期的系数。
方程(5.1)式就是分布滞后模型因为它把收入增长对消费的影响分为s 期。
X 的一个单位变化对Y 的短期影响由0β来表示,而X 的一个单位变化对Y 的长期影响由(s βββ+++ 10)来表示。
假设我们观察从1955年到1995年的t X ,1t X -为相同的变量,但是提前一期的,也就是1954-1994。
因为1954年的数据观察不到,我们就从1955年开始观察1t X -,到1994年结束。
这意味着当我们滞后一期时,t X 序列将从1956年开始到1995年结束。
对于实际的应用来说,也就是当我们滞后一期时,我们将从样本中丢失了一个观测值。
所以如果我们滞后s 期,将丢失s 个观测值。
更进一步,对于每一个滞后值,都要估计出一个额外的β值。
因此,自由度会产生双重损失,即观测值数目的减少(因为引进滞后项),以及所需估计的参数增加。

1、截面数据:截面数据是许多不同的观察对象在同一时间点上的取值的统计数据集合,可理解为对一个随机变量重复抽样获得的数据。
2、时间序列数据:时间序列数据是同一观察对象在不同时间点上的取值的统计序列,可理解为随时间变化而生成的数据。
3、虚变量数据:虚拟变量数据是人为设定的虚拟变量的取值。
是表征政策、条件等影响研究对象的定性因素的人工变量,其取值一般只取“0”或“1”。
4、内生变量与外生变量:内生变量是由模型系统决定同时可能也对模型系统产生影响的变量,是具有某种概率分布的随机变量,外生变量是不由模型系统决定但对模型系统产生影响的变量,是确定性的变量。
5、总体回归函数:是指在给定X i 下Y 分布的总体均值与X i 所形成的函数关系(或者说将 总体被解释变量的条件期望表示为解释变量的某种函数)6、最大似然估计法(ML ): 又叫最大或然法,指用产生该样本概率最大的原则去确定样本 回归函数的方法。
7、OLS 估计法:指根据使估计的剩余平方和最小的原则来确定样本回归函数的方法。
8、残差平方和:用RSS 表示,用以度量实际值与拟合值之间的差异,是由除解释变量之外 的其他因素引起的被解释变量变化的部分。
9、拟合优度检验:指检验模型对样本观测值的拟合程度,用2R 表示,该值越接近1表示拟合程度越好。
10、多元线性回归模型:在现实经济活动中往往存在一个变量受到其他多个变量影响的现象,表现在线性回归模型中有多个解释变量,这样的模型被称做多元线性回归模型,多元是指多个解释变量。
11、调整的可决系数:又叫调整的决定系数,是一个用于描述多个解释变量对被解释变量的联合影响程度的统计量,克服了2R 随解释变量的增加而增大的缺陷,与2R 的关系为2211(1)1n R R n k -=----。
12、偏回归系数:在多元回归模型中,每一个解释变量前的参数即为偏回归系数,它测度了当其他解释变量保持不变时,该变量增加1单位对被解释变量带来的平均影响程度。



丫= 1+ 8人-4人+ 3为=1 + 8人-(3X2+ 2)+ 3为=7+ 8人-9%(1.5)在(1.4)中,X2的系数为12,表示丫与为成正比例关系,即正相关;而在(1.5)中,X2的系数为-9,表示丫与X?成负比例关系,即负相关。
如此看来,同一个方程丫= 1+ 4片+ 3X2变换出的两个等价方程,由于不同的因式分解和替换,导致两个方程两种表面上矛盾的结果。
实际上,根据X1 = 3为+ 2式中的X1与为的共线性,X1约相当于3X2, 在(1.4)减少了3人,即需要用9个X2来补偿;而在(1.5)增加了4人, 需要用12个X2来抵消,以便保证两个方程的等价性,这样一来使得(1.5)中为的系数变为了负数。
从上述分析看来,由于X i与勺的共线性,使得同一个方程有不同的表达形式,从而使得丫与为间的关系难以用系数解释。
2•对多重线性关系的初步估计与识别如果在实际应用中产生了如下情况之一,则可能是由于多重共线性的存在而造成的,需作进一步的分析诊断。
①增加(或减去)一个变量或增加(或剔除)一个观察值,回归系数发生了较大变化。
②实际经验中认为重要的自变量的回归系数检验不显著。
③回归系数的正负号与理论研究或经验相反。
④在相关矩阵中,自变量的相关系数较大。
⑤自变量回归系数可信区间范围较广等。
3•对多重共线性本质的认识多重共线性可分为完全多重共线性和近似多重共线性(或称高度相关性),现在我们集中讨论多重共线性的本质问题。
多重共线性普遍被认为是数据问题或者说是一种样本现象。
我们认为,这种普遍认识不够全面,对多重共线性本质的认识,至少可从以下几方面解解。
(3)检验解释变量相互之间的样本相关系数。
假设我们有三个解释变量X i、X2、X3,分别以「12、「13、「23 来表示X i 与X2、X i 与X3、X2与X3之间的两两相关系数。
假设r i2 = 0.90,表明X i与X2之间高度共线性,现在我们来看相关系数「12,3,这样一个系数我们定义为偏相关系数,它是在变量X3为常数的情况下,X i与X2之间的相关系数。

第六章分布滞后模型与自回归模型分析分布滞后模型(Distributed Lag Models)和自回归模型(Autoregressive Models)是常用于时间序列分析的两种方法。
本章将分别介绍这两种模型以及其在经济学和社会科学领域中的应用。
分布滞后模型是一种广义的线性回归模型,用于分析变量之间的滞后效应。
它的基本形式可以表示为:Yt = α + β1Xt + β2Xt-1 + ... + βpXt-p + et其中,Yt是被解释变量,Xt是解释变量,β1到βp是与解释变量相关的系数,et是误差项。
模型中的滞后项Xt-1到Xt-p表示X在当前时间以及过去的一段时间内对Y的影响。
分布滞后模型可以用来研究两个或多个变量之间的滞后效应,并帮助研究者了解这些变量之间的动态关系。
分布滞后模型在经济学和社会科学领域中有广泛的应用。
例如,在宏观经济学中,可以用分布滞后模型来研究货币政策对经济增长的长期影响。
在健康经济学中,可以用分布滞后模型来研究疫苗接种对流行病传播的影响。
在社会学研究中,可以用分布滞后模型来研究教育程度对就业机会的影响。
自回归模型是一种基于时间序列的统计模型,用于预测一个变量在时间上的变化。
它的基本形式可以表示为:Yt = α + φ1Yt-1 + φ2Yt-2 + ... + φpYt-p + et其中,Yt是被预测的变量,φ1到φp是自回归系数,et是误差项。
自回归模型假设当前时间的值与过去时间的值有关,并且根据过去时间的值来预测未来时间的值。
自回归模型可以帮助研究者预测变量的趋势和周期性,并提供关于未来值的信息。
自回归模型在经济学和社会科学领域中也有广泛的应用。
例如,在金融学中,可以用自回归模型来预测股票价格的变化。
在气象学中,可以用自回归模型来预测天气变化。
在市场研究中,可以用自回归模型来预测产品销售量。
总之,分布滞后模型和自回归模型是两种常用的时间序列分析方法。
它们可以帮助研究者了解变量之间的滞后效应和趋势,并用于预测未来值。

1. 总体回归函数:在给定解释变量X i 条件下被解释变量Y i 的期望轨迹称为总体回归线,或更一般地称为总体回归曲线。
相应的函数:E(Y 〡X i )=f(X i )称为(双变量)总体回归函数(populationregressionfunction,PRF )2. 样本回归函数:样本散点图近似于一条直线,画一条直线以尽好地拟合该散点图,由于样本取自总体,可以该线近似地代表总体回归线。
该线称为样本回归线。
记样本回归线的函数形式为:i i i X X f Y 10ˆˆ)(ˆββ+==称为样本回归函数(sampleregressionfunction ,SRF )。
3. 随机的总体回归函数:函数 〡 或者在线性假设下, 式称为总体回归函数(方程)PRF 的随机设定形式。
表明被解释变量除了受解释变量的系统性影响外,还受其他因素的随机性影响。
由于方程中引入了随机项,成为计量经济学模型,因此也称为总体回归模型。
4. 线性回归模型:假设1、回归模型是正确设定的。
假设2、解释变量X 是确定性变量,不是随机变量,在重复抽样中取固定值。
假设3、解释变量X 在所抽取的样本中具有变异性,而且随着样本容量的无限增加,解释变量X 的样本方差趋于一个非零的有限常数,即假设4、随机误差项具有零均值、同方差和不序列相关性:E(i )=0i=1,2,…,nVar(i )=2i=1,2,…,nCov(i,j )=0i≠ji,j=1,2,…,n假设5、随机误差项与解释变量X 之间不相关:Cov(X i ,i )=0i=1,2,…,n假设6、服从零均值、同方差、零协方差的正态分布i ~N(0,2)i=1,2,…,n以上假设也称为线性回归模型的经典假设,满足该假设的线性回归模型,也称为经典线性回归模型5. 随机误差项( )和残差项( ):(1)i 为观察值Y i 围绕它的期望值E(Y |X i )的离差,是一个不可观测的随机变量,又称为随机干扰项或随机误差项。

计量经济学课程教案第7章 分布滞后模型与自回归模型7.1 滞后效应与滞后变量模型在经济运行过程中,广泛存在时间滞后效应。
某些经济变量不仅受到同期各种因素的影响,而且也受到过去某些时期的各种因素甚至自身的过去值的影响。
通常把这种过去时期的,具有滞后作用的变量叫做滞后变量(Lagged Variable ),含有滞后变量的模型称为滞后变量模型。
滞后变量模型考虑了时间因素的作用,使静态分析的问题有可能成为动态分析。
含有滞后解释变量的模型,又称动态模型(Dynamical Model )。
一、滞后效应与与产生滞后效应的原因因变量受到自身或另一解释变量的前几期值影响的现象称为滞后效应。
表示前几期值的变量称为滞后变量。
如:消费函数通常认为,本期的消费除了受本期的收入影响之外,还受前1期,或前2期收入的影响: C t =β0+β1Y t +β2Y t-1+β3Y t-2+μt Y t-1,Y t-2为滞后变量。
产生滞后效应的原因1、心理因素:人们的心理定势,行为方式滞后于经济形势的变化,如中彩票的人不可能很快改变其生活方式。
2、技术原因:如当年的产出在某种程度上依赖于过去若干期内投资形成的固定资产。
3、制度原因:如定期存款到期才能提取,造成了它对社会购买力的影响具有滞后性。
二、滞后变量模型以滞后变量作为解释变量,就得到滞后变量模型。
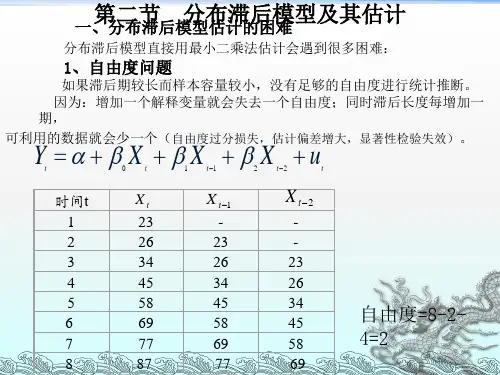
它的一般形式为:ts t s t t q t q t t t X X X Y Y Y Y μαααββββ+++++++++=----- 11022110q ,s :滞后时间间隔自回归分布滞后模型(autoregressive distributed lag model, ADL ):既含有Y 对自身滞后变量的回归,还包括着X 分布在不同时期的滞后变量有限自回归分布滞后模型:滞后期长度有限 无限自回归分布滞后模型:滞后期无限,(1)分布滞后模型(distributed-lag model )分布滞后模型:模型中没有滞后被解释变量,仅有解释变量X 的当期值及其若干期的滞后值:ti t i si t X Y μβα++=-=∑0β0:短期(short-run)或即期乘数(impact multiplier),表示本期X 变化一单位对Y 平均值的影响程度。
第5章 分布滞后与动态模型分布滞后模型是指,回归模型不仅包含自变量的当前值,也包含自变量的滞后值和/或因变量的滞后值。
根据自变量滞后数目,模型可分为有限和无穷分布滞后模型。
为此,分别介绍多项式分布滞后模型(Almon 模型)和几何分布滞后模型(Koyck 模型)。
另外,还简单介绍自回归分布滞后模型(ARDL ,包含因变量滞后值的模型)。
§5.1 多项式分布滞后模型(Almon)(自变量有限滞后) 0110..., 1,...,t t t s t s t st i t i t i Y X X X t s T Y X αβββεαβε---==+++++=+=++∑1.估计一些情况下,自变量有限滞后模型可直接估计。
问题:(1) 由于滞后了s 期,观察值少了s 期,参数又多了s 个,造成自由度(T -k )双重损失;(2) 解释变量与其滞后值之间一般高度相关,产生共线性问题。
尽管如此,OLS 估计量仍是BLUE ,只不过估计量的标准差通常会偏大。
为此,考虑采用其他适当方法。
一般地,各期的反应系数β i 呈规律性变化,为此,可对系数施加一些约束。
这样,一方面,可降低待估计参数个数,以减少自由度的损失;另一方面,在一定程度上降低多重共线性程度。
(1) 反应系数的线性约束无约束模型:0s t i t i t i Y X αβε-==++∑反应系数的线性约束:[(1)]i s i ββ=+-,0,1,...,i s =011(1)...s s s s βββββββ+=+===将约束条件代入模型:00[(1)]s st i t i t t i t i i Y X s i X αβεαβε--===++=++-+∑∑约束模型:t t t Y Z αβε=++ 其中,10[(1)](1)s t t i t t t s i Z s i X s X sX X ---=≡+-=++++∑(2) 反应系数的多项式约束(Almon)设5s =,反应系数β i 关于i 为二阶多项式,即五步二阶多项式。
计量经济学各章习题及答案第一章习题一、单项选择1.( ) 是经济计量学的主要开拓者人和奠基人。
A.费歇(fisher) B .费里希(frisch)C.德宾(durbin)D.戈里瑟(glejer)2.随机方程又称为()。
A.定义方程 B.技术方程C.行为方程 D.制度方程3.计量经济分析工作的研究对象是()。
A.社会经济系统B.经济理论C.数学方法在经济中的应用D.经济数学模型二、多项选择1.经济计量学是下列哪些学科的统一()。
A.经济学B.统计学C.计量学D.数学E.计算机2.对一个独立的经济计量模型来说,变量可分为()、A.内生变量B独立变量C外生变量D.相关变量E虚拟变量3.经济计量学分析工作的工作步骤包括()。
A设定模型B估计参数C检验模型D应用模型E收集数据三、名词解释1.时序数据2.横截面数据3.内生变量4.解释变量5.模型6.外生变量第一章习题答案一、单项选择B\C\A二、多项选择1C\D 2A\C 3A\B\C\D三、名词解释1.时序数据指同一指标按时间顺序记录的数据列,在同一数据列中的数据必须是同口径的,有可比性2.横截面数据同一时间,在不同统计单位的相同统计指标组成的数据列,要求统计的时间相同,不要求统计对象及范围相同。
要求数据统计口径和计算方法具有可比性 3.内生变量具有一定概率分布的随机变量,数据由模型本身决定 4.解释变量在模型中方程右边作为影响因素的变量,即自变量 5.模型对经济系统的数学抽象 6.外生变量非随机变量,取值由模型外决定,是求解模型时的已知数第二章习题一、单项选择1.一元线性回归分析中有TSS=RSS+ESS 。
则RSS 的自由度为()。
A nB 1C n-1D n-22.一元线性会规中,0β∧、1β∧的值为( )∑∑---=∧2i)()(0X X Y Y X X ii )(βXY 01∧∧-=ββ XY 10∧∧-=ββ∑∑---=∧2i)()(1X X Y Y X X ii )(βY X =+∧∧10ββ∑∑---=∧2i)()(0X X Y Y X X ii )(βXY 10∧∧+=ββ∑∑---=∧2i)()(1X X Y Y X X ii )(β3.一元线性回归中,相关系数r=( ) A.∑∑∑----222)()()))(Y Y X X Y Y X X i i i i (( B.∑∑∑----22)()())(Y Y X X Y Y X X iiii( C ∑∑∑----22)()())(Y Y X XY Y X X iii i ( D∑∑∑---222)()()(Y Y X XY Y iii4.对样本相关系数r,以下结论中错误的是ABDC( )。
名词解释1.经济变量:经济变量是用来描述经济因素数量水平的指标。
2.解释变量:是用来解释作为研究对象的变量(即因变量)为什么变动、如何变动的变量。
它对因变量的变动做出解释,表现为方程所描述的因果关系中的“因”。
3.被解释变量:是作为研究对象的变量。
它的变动是由解释变量做出解释的,表现为方程所描述的因果关系的果。
4.内生变量:是由模型系统内部因素所决定的变量,表现为具有一定概率分布的随机变量,是模型求解的结果。
5.外生变量:是由模型系统之外的因素决定的变量,表现为非随机变量。
它影响模型中的内生变量,其数值在模型求解之前就已经确定。
6.滞后变量:是滞后内生变量和滞后外生变量的合称,前期的内生变量称为滞后内生变量;前期的外生变量称为滞后外生变量。
7.前定变量:通常将外生变量和滞后变量合称为前定变量,即是在模型求解以前已经确定或需要确定的变量。
8.控制变量:在计量经济模型中人为设置的反映政策要求、决策者意愿、经济系统运行条件和状态等方面的变量,它一般属于外生变量。
9.计量经济模型:为了研究分析某个系统中经济变量之间的数量关系而采用的随机代数模型,是以数学形式对客观经济现象所作的描述和概括。
$10.函数关系:如果一个变量y的取值可以通过另一个变量或另一组变量以某种形式惟一地、精确地确定,则y与这个变量或这组变量之间的关系就是函数关系。
11.相关关系:如果一个变量y的取值受另一个变量或另一组变量的影响,但并不由它们惟一确定,则y与这个变量或这组变量之间的关系就是相关关系。
12.最小二乘法:用使估计的剩余平方和最小的原则确定样本回归函数的方法,称为最小二乘法。
13.高斯-马尔可夫定理:在古典假定条件下,OLS估计量是模型参数的最佳线性无偏估计量,这一结论即是高斯-马尔可夫定理。
14.总变差(总离差平方和):在回归模型中,被解释变量的观测值与其均值的离差平方和。
15.回归变差(回归平方和):在回归模型中,因变量的估计值与其均值的离差平方和,也就是由解释变量解释的变差。
实验五多重共线性、分布滞后模型(或机动)[实验目的]让学生掌握如何辨别模型中是否存在多重共线性现象,并能够对多重共线性加以处理。
[实验内容]①相关系数矩阵计算;②方差膨胀因子计算;③多重共线性处理。
[实验步骤]数据导入—查看t 统计量值和F 统计量值以及R 平方的值--计算相关系数矩阵和方差膨胀因子—对多重共线问题加以处理(改变模型、去除不重要的变量、岭回归主成分分析等)问题:对于1960年至1982年期间美国人均鸡肉消费量(Y),人均实际可支配收入(X1),鸡肉的实际零售价格(X2),猪肉的实际零售价格(X3),牛肉的实际零售价格(X4)等数据,见表4-1,利用它们的对数估计如下模型:表4-11960年至1982年期间美国人均鸡肉消费量等数据y x1x2x3x427.8397.542.250.778.329.9413.338.15279.229.8439.240.35479.230.8459.739.555.379.231.2492.937.354.777.433.3528.638.163.780.235.6560.339.369.880.436.4624.637.865.983.936.7666.438.464.585.538.4717.840.17093.740.4768.238.673.2106.140.3843.339.867.8104.841.8911.639.779.111440.4931.152.195.4124.140.71021.548.994.2127.640.11165.958.3123.5142.942.71349.657.9129.9143.644.11449.456.5117.6139.246.71575.563.7130.9165.550.61759.161.6129.8203.350.11994.258.9128219.651.72258.166.4141221.652.92478.770.4168.2232.6把数据导入GRETL 软件,产生各变量的对数变量,分别为ly、lx1、lx2、lx3、lx4,估计要求的模型,参数估计的结果为:εβββββ+++++=443322110ln ln ln ln ln X X X X Y图4-1模型估计的结果需求的收入弹性和需求的价格弹性都是高度显著的,但两个交叉弹性均不显著。
模型的决定系数为0.98,F统计量对应的P值很小,但lx3和lx4都不显著。
不过由此得出鸡肉的需求不受猪肉和牛肉价格的影响显然是不对的,模型中可能存在多重共线性问题。
为了诊断模型中是否存在共线性,首先来计算出自变量的相关矩阵,结果如下:图4-2自变量的相关矩阵相关系数都较大,说明可能存在共线性。
再计算各自变量的方差膨胀因子和自变量矩阵的矩阵条件数,GRETL软件会给出矩阵条件数的倒数。
Variance Inflation FactorsMinimum possible value=1.0Values>10.0may indicate a collinearity problemlx165.115lx217.486lx341.433lx442.307VIF(j)=1/(1-R(j)^2),where R(j)is the multiple correlation coefficientbetween variable j and the other independent variablesBelsley-Kuh-Welsch collinearity diagnostics:---variance proportions---lambda cond const lx1lx2lx3lx44.994 1.0000.0000.0000.0000.0000.0000.00531.9150.1950.0020.0000.0040.0020.000111.9180.1680.0620.2120.0560.0400.000136.9730.1770.0210.1080.2300.2100.000334.3720.4600.9140.6800.7100.748lambda=eigenvalues of X'X,largest to smallestcond=condition indexnote:variance proportions columns sum to 1.0图4-3共线性诊断结果几个变量对应的方差膨胀因子都挺大,一般大于10就表明存在模型中比较严重的共线性问题。
而且,自变量矩阵的条件数为334.372,一般认为矩阵条件数超过30就表明模型存在共线性问题。
这样,可以断定模型中存在多重共线性问题。
对于多重共线性的处理方法主要有:剔除P值大的自变量、增加样本容量、重新建模,此外还有主成分分析及岭回归等,我们这里只给出简单的处理办法,剔除不显著变量,结果如下图:图4-4共线性的处理结果和前面的回归结果比较,收入弹性增大了,但是价格弹性的绝对值却下降了。
不过需要注意的是,简化了的模型的系数估计是有偏的。
[实验方法]上机[实验条件]利用统计计量软件Gretl [实验指导]1.导入数据建立模型,根据模型结果判断是否存在多重共线性。
2.利用函数corr 计算相关系数矩阵。
3.Gretl 中能够直接判断共线性问题。
[问题思考]1.哪些现象反映模型中存在多重共线性?2.为什么根据方差膨胀因子能够判断是否存在多重共线性?3.为什么有时我们可以不太关注多重共线性问题?分布滞后模型(或机动)[实验目的]使学生掌握分布滞后模型的应用,能够解释估计结果,关键是可以对所建立的模型进行分析。
[实验内容]①分布滞后模型参数估计;②回归结果的解释[实验步骤]数据导入—模型参数估计—回归结果的解释案例6.1以1996-2005年全国广义货币供应量和物价指数的月度数据(见表6-1)利用分布滞后模型研究了货币增长率对消费价格的影响问题。
为了考察货币供应量的变化对物价的影响,我们用广义货币M2的月增长量M2Z 作为解释变量,以居民消费价格月度同比指数TBZS 为被解释变量进行研究。
首先估计如下回归模型:tt t Z M TBZS εβα++=20表6-11996-2005年全国广义货币供应量及物价指数月度数据月度广义货币M2(千亿元)广义货币增长量M2Z (千亿元)居民消费价格同比指数TBZS月度广义货币M2(千亿元)广义货币增长量M2Z (千亿元)居民消费价格同比指数TBZS Jan-9658.401Oct-00129.522-0.9518100Feb-9663.778 5.377109.3Nov-00130.9941 1.4721101.3Mar-9664.5110.733109.8Dec-00134.6103 3.6162101.5Apr-9665.723 1.212109.7Jan-01137.5436 2.9333101.2May-9666.88 1.157108.9Feb-01136.2102-1.3334100Jun-9668.132 1.252108.6Mar-01138.7445 2.5343100.8Jul-9669.346 1.214108.3Apr-01139.9499 1.2054101.6Aug-9672.3092.963108.1May-01139.0158-0.9341101.7Sep-9669.643-2.666107.4Jun-01147.80978.7939101.4 Oct-9673.1522 3.5092107Jul-01149.2287 1.419101.5 Nov-9674.1420.9898106.9Aug-01149.94180.7131101 Dec-9676.0949 1.9529107Sep-01151.8226 1.880899.9 Jan-9778.648 2.5531105.9Oct-01151.4973-0.3253100.2 Feb-9778.9980.35105.6Nov-01154.0883 2.59199.7 Mar-9779.8890.891104Dec-01158.3019 4.213699.7 Apr-9780.8180.929103.2Jan-02159.6393 1.337499 May-9781.1510.333102.8Feb-02160.9356 1.2963100 Jun-9782.789 1.638102.8Mar-02164.0646 3.12999.2 Jul-9783.460.671102.7Apr-02164.57060.50698.7 Aug-9784.746 1.286101.9May-02166.061 1.490498.9 Sep-9785.892 1.146101.8Jun-02169.6012 3.540299.2 Oct-9786.6440.752101.5Jul-02170.8511 1.249999.1 Nov-9787.590.946101.1Aug-02173.2509 2.399899.3 Dec-9790.9953 3.4053100.4Sep-02176.9824 3.731599.3 Jan-9892.2114 1.2161100.3Oct-02177.29420.311899.2 Feb-9892.024-0.187499.9Nov-02179.7363 2.442199.3 Mar-9892.015-0.009100.7Dec-02185.0073 5.27199.6 Apr-9892.6620.64799.7Jan-03190.4883 5.481100.4 May-9893.936 1.27499Feb-03190.1084-0.3799100.2 Jun-9894.6580.72298.7Mar-03194.4873 4.3789100.9 Jul-9896.314 1.65698.6Apr-03196.1301 1.6428101 Aug-9897.2990.98598.6May-03199.5052 3.3751100.7 Sep-9899.795 2.49698.5Jun-03204.9314 5.4262100.3 Oct-98100.8752 1.080298.9Jul-03206.1931 1.2617100.5 Nov-98102.229 1.353898.8Aug-03210.5919 4.3988100.9 Dec-98104.4985 2.269599Sep-03213.5671 2.9752101.1 Jan-99105.5 1.001598.8Oct-03214.46940.9023101.8 Feb-99107.778 2.27898.7Nov-03216.3517 1.8823103 Mar-99108.4380.6698.2Dec-03221.2228 4.8711103.2 Apr-99109.2180.7897.8Jan-04225.10193 3.87913103.2 May-99110.0610.84397.8Feb-04227.05072 1.94879102.1 Jun-99111.363 1.30297.9Mar-04231.6546 4.60388103 Jul-99111.4140.05198.6Apr-04233.62786 1.97326103.8 Aug-99112.827 1.41398.7May-04234.8424 1.21454104.4 Sep-99115.079 2.25299.2Jun-04238.42749 3.58509105 Oct-99115.390.31199.4Jul-04234.8424-3.58509105.3 Nov-99116.559 1.16999.1Aug-04239.72919 4.88679105.3 Dec-99119.898 3.33999Sep-04243.757 4.02781105.2 Jan-00121.22 1.32299.8Oct-04243.74-0.017104.3 Feb-00121.58340.3634100.7Nov-04247.13558 3.39558102.8Mar-00122.58070.997399.8Dec-04253.2077 6.07212102.4 Apr-00124.1219 1.541299.7Jan-05257.75283 4.54513101.9 May-00124.0533-0.0686100.1Feb-05259.3561 1.60327103.9 Jun-00126.6053 2.552100.5Mar-05264.5889 5.2328102.7 Jul-00126.3239-0.2814100.5Apr-05266.99266 2.40376101.8 Aug-00127.79 1.4661100.3May-05269.2294 2.23674101.8 Sep-00130.4738 2.6838100数据来源:中经网统计数据库/导入数据,拟合得到如下的回归结果。