matlab语音识别系统(源代码)最新版
- 格式:doc
- 大小:536.00 KB
- 文档页数:19

语音识别课程设计 matlab一、教学目标本课程的教学目标是使学生掌握语音识别的基本原理和MATLAB实现方法,培养学生运用语音识别技术解决实际问题的能力。
具体目标如下:1.知识目标:–了解语音识别的基本概念、发展历程和应用领域;–掌握语音信号处理的基本方法和MATLAB编程技巧;–理解语音特征提取、模式匹配和声学模型等关键技术;–熟悉常用的语音识别算法和MATLAB工具箱。
2.技能目标:–能够运用MATLAB进行语音信号的预处理、特征提取和识别;–具备搭建简单的语音识别系统的能力;–学会分析语音识别过程中的误差和优化方法;–能够阅读和理解相关的英文文献。
3.情感态度价值观目标:–培养学生对语音识别技术的兴趣和好奇心,激发创新精神;–培养学生团队合作意识和沟通交流能力;–使学生认识到语音识别技术在现实生活中的重要性和潜在价值。
二、教学内容本课程的教学内容主要包括以下几个部分:1.语音识别概述:介绍语音识别的定义、发展历程、应用领域和挑战;2.语音信号处理:讲解语音信号的预处理方法,如滤波、端点检测、语音增强等;3.语音特征提取:学习基于MATLAB的语音特征提取方法,如MFCC、PLP等;4.模式匹配与声学模型:探讨模板匹配、高斯混合模型和神经网络等声学模型;5.语音识别算法:介绍隐马尔可夫模型(HMM)、支持向量机(SVM)、深度学习等算法;6.MATLAB语音识别工具箱:学习MATLAB内置的语音识别工具箱,如HTK、SPTK等;7.实践项目:完成一个基于MATLAB的简单语音识别系统的设计和实现。
三、教学方法本课程采用多种教学方法相结合的方式,包括:1.讲授法:讲解基本概念、原理和方法,为学生提供系统的知识结构;2.案例分析法:分析典型的语音识别应用案例,使学生更好地理解实际应用;3.实验法:通过实验操作,让学生亲手实践,培养实际操作能力和问题解决能力;4.讨论法:学生进行小组讨论,激发创新思维和团队合作意识。
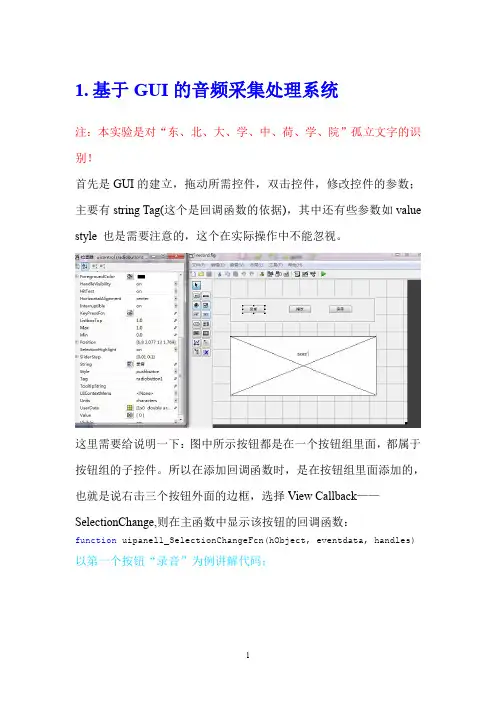
1.基于GUI的音频采集处理系统注:本实验是对“东、北、大、学、中、荷、学、院”孤立文字的识别!首先是GUI的建立,拖动所需控件,双击控件,修改控件的参数;主要有string Tag(这个是回调函数的依据),其中还有些参数如valuestyle也是需要注意的,这个在实际操作中不能忽视。
这里需要给说明一下:图中所示按钮都是在一个按钮组里面,都属于按钮组的子控件。
所以在添加回调函数时,是在按钮组里面添加的,也就是说右击三个按钮外面的边框,选择View Callback——SelectionChange,则在主函数中显示该按钮的回调函数:function uipanel1_SelectionChangeFcn(hObject,eventdata,handles)以第一个按钮“录音”为例讲解代码;下面是“播放”和“保存”的代码:以上就是语音采集的全部代码。
程序运行后就会出现这样的界面:点击录音按钮,录音结束后就会出现相应波形:点击保存,完成声音的保存,保存格式为.wav。
这就完成了声音的采集。
2.声音的处理与识别2.1打开文件语音处理首先要先打开一个后缀为.wav的文件,这里用到的不是按钮组,而是独立的按钮,按钮“打开”的回调函数如下:function pushbutton1_Callback(hObject,eventdata,handles)其中pushbutton1是“打开”按钮的Tag.在回调函数下添加如下代码:运行结果如图:2.2预处理回调函数如下:function pushbutton2_Callback(hObject,eventdata,handles)运行结果如图:2.3短时能量短时能量下的回调函数:function pushbutton3_Callback(hObject,eventdata,handles)其回调函数下的代码是:2.4端点检测这里要先声明一点,为了避免在以后的函数调用中,不能使用前面的变量,所以其实后面的函数都包含了前面的部分。

MATLAB高级编程与工程应用实验四图像处理第一章基础知识1、MATLAB 提供了图像处理工具箱,在命令窗口输入help images 可查看该工具箱内的所有函数。
请阅读并大致了解这些函数的基本功能。
大致了解。
2、利用MATLAB 提供的Image file I/O 函数分别完成以下处理:(a)以测试图像的中心为圆心,图像的长和宽中较小值的一半为半径画一个红颜色的圆;分析:直接利用半径条件,满足条件的点将红色元素置为255,绿色和蓝色元素置为0,于是得到如下图像:源代码:load('hall_color.mat');%首先获得三原数组R = hall_color(:,:,1);G = hall_color(:,:,2);B = hall_color(:,:,3);%将圆上的点改为红色for i = 1:120for j = 1:168a = abs(i - 60.5);b = abs(j - 84.5);d = sqrt(a ^ 2 + b ^ 2);if(abs(d - 60) < 0.5)R(i,j) = 255;G(i,j) = 0;B(i,j) = 0;endendend%生成新的矩阵hall_color1(:,:,1) = R;hall_color1(:,:,2) = G;hall_color1(:,:,3) = B;imshow(hall_color1);(b)将测试图像涂成国际象棋状的“黑白格”的样子,其中“黑”即黑色,“白”则意味着保留原图。
用一种看图软件浏览上述两个图,看是否达到了目标。
分析:首先设置标记flag在进行循环,对不同方格实行颜色更改就行。
效果:源代码:clear all;load('hall_color.mat');R = hall_color(:,:,1);G = hall_color(:,:,2);B = hall_color(:,:,3);flag = 1;for i = 1:8flag = mod((flag + 1),2);for j = 1:8if(flag == 1)for m = 15*(i - 1) + 1:15*ifor n = 21*(j - 1) + 1:21*jR(m,n) = 0;G(m,n) = 0;B(m,n) = 0;endendendflag = mod((flag + 1),2);endendword格式-可编辑-感谢下载支持hall_color1(:,:,1) = R;hall_color1(:,:,2) = G;hall_color1(:,:,3) = B;imshow(hall_color1);用看图软件打开成功:第二章图像压缩编码1、图像的预处理是将每个像素灰度值减去128 ,这个步骤是否可以在变换域进行?请在测试图像中截取一块验证你的结论。

(威海)《智能仪器》课程设计题目: MATLAB实现语音识别功能班级:学号:姓名:同组人员:任课教师:完成时间:2012/11/3目录一、设计任务及要求 (1)二、语音识别的简单介绍语者识别的概念 (2)特征参数的提取 (3)用矢量量化聚类法生成码本 (3)的说话人识别 (4)三、算法程序分析函数关系 (4)代码说明 (5)函数mfcc (5)函数disteu (5)函数vqlbg (6)函数test (6)函数testDB (7)函数train (8)函数melfb (8)四、演示分析 (9)五、心得体会 (11)附:GUI程序代码 (12)一、设计任务及要求用MATLAB实现简单的语音识别功能;具体设计要求如下:用MATLAB实现简单的数字1~9的语音识别功能。
二、语音识别的简单介绍基于VQ的说话人识别系统,矢量量化起着双重作用。
在训练阶段,把每一个说话者所提取的特征参数进行分类,产生不同码字所组成的码本。
在识别(匹配)阶段,我们用VQ方法计算平均失真测度(本系统在计算距离d时,采用欧氏距离测度),从而判断说话人是谁。
语音识别系统结构框图如图1所示。
图1 语音识别系统结构框图语者识别的概念语者识别就是根据说话人的语音信号来判别说话人的身份。
语音是人的自然属性之一,由于说话人发音器官的生理差异以及后天形成的行为差异,每个人的语音都带有强烈的个人色彩,这就使得通过分析语音信号来识别说话人成为可能。
用语音来鉴别说话人的身份有着许多独特的优点,如语音是人的固有的特征,不会丢失或遗忘;语音信号的采集方便,系统设备成本低;利用电话网络还可实现远程客户服务等。
因此,近几年来,说话人识别越来越多的受到人们的重视。
与其他生物识别技术如指纹识别、手形识别等相比较,说话人识别不仅使用方便,而且属于非接触性,容易被用户接受,并且在已有的各种生物特征识别技术中,是唯一可以用作远程验证的识别技术。
因此,说话人识别的应用前景非常广泛:今天,说话人识别技术已经关系到多学科的研究领域,不同领域中的进步都对说话人识别的发展做出了贡献。

清华大学电子工程系MATLAB高级编程与工程应用实验二语音处理1.2.1(1)给定e(n) 假设e(n) 是输入信号,s(n) 是输出信号,上述滤波器的传递函数是什么?如果a1 = 1.3789,a2 = 0.9506 ,上述合成模型的共振峰频率是多少?用zplane ,freqz ,impz 分别绘出零极点图,频率响应和单位样值响应。
用filter 绘出单位样值响应,比较和impz 的是否相同。
分析:上述滤波器的传递函数是:H=11−1.3789z−1+0.9506z−2可以求出传递函数的极点为p = 0.6895 ±0.6894 i由此可以计算出模拟频率为Ω = pi/4,又因为T = 1/8000s,则可以得到共振峰频率f = 1000Hz。
使用zplane函数画出零极点图如下:使用freqz函数画出频率响应如下:使用impz函数画出单位样值响应如下:最后使用filter函数画出其单位样值响应如下:编写文件sounds_2_1.m,画出所有图像如下,可以直接比较filter函数和impz函数画出的单位样值响应几乎是一模一样的:sounds_2_1.m:clear;clc;close all;b = 1;a = [1,-1.3789,0.9506];n = [0:1:50];freqz(b,a); %画出频率响应图figure; %新建画布subplot(3,1,1);zplane(b,a); %画出零极点图subplot(3,1,2);impz(b,a,n); %利用impz函数画出单位样值响应subplot(3,1,3);x = (n == 0);stem(n,filter(b,a,x)); %利用filter函数画出单位样值响应(3)运行该程序到27 帧时停住,用(1)中的方法观察零极点图。
添加代码如下:运行程序得到零极点图如下:(4) 在循环中添加程序:对每帧语音信号s(n) 和预测模型系数fa i g ,用filter 计算激励信号e(n) 。

如何使用MATLAB进行语音信号处理与识别引言:语音信号处理与识别是一项应用广泛的领域,它在语音通信、语音识别、音频压缩等方面发挥着重要作用。
在本文中,我们将介绍如何使用MATLAB进行语音信号处理与识别。
首先,我们将讨论语音信号的特征提取,然后介绍常用的语音信号处理方法,最后简要概述语音信号的识别技术。
一、语音信号的特征提取语音信号的特征提取是语音信号处理与识别的重要一环。
在MATLAB中,我们可以通过计算音频信号的频谱特征、时域特征以及声学特征等方式来进行特征提取。
其中,最常见的特征提取方法是基于傅里叶变换的频谱分析方法,比如短时傅里叶变换(STFT)和梅尔频谱倒谱系数(MFCC)。
1. 频谱特征:频谱特征主要包括功率谱密度(PSD)、频谱包络、谱熵等。
在MATLAB中,我们可以使用fft函数来计算信号的频谱,使用pwelch函数来计算功率谱密度,使用spectrogram函数来绘制语谱图等。
2. 时域特征:时域特征主要包括幅度特征、能量特征、过零率等。
在MATLAB中,我们可以使用abs函数来计算信号的幅度谱,使用energy函数来计算信号的能量,使用zcr函数来计算信号的过零率等。
3. 声学特征:声学特征主要包括基频、共振频率等。
在MATLAB中,我们可以通过自相关函数和Cepstral分析等方法来计算声学特征。
二、语音信号处理方法语音信号处理方法主要包括降噪、去除回声、语音增强等。
在MATLAB中,我们可以通过滤波器设计、自适应噪声抑制和频谱减法等方法来实现这些功能。
1. 降噪:降噪通常包括噪声估计和降噪滤波两个步骤。
在MATLAB中,我们可以使用统计模型来估计噪声,然后使用Wiener滤波器或者小波阈值法来降噪。
2. 去除回声:回声是语音通信中的常见问题,我们可以使用自适应滤波器来抑制回声。
在MATLAB中,我们可以使用LMS算法或者NLMS算法来实现自适应滤波。
3. 语音增强:语音增强通常包括增加语音信号的声音清晰度和提高语音的信噪比。

语音识别的MATLAB实现声控小车结题报告小组成员:关世勇吴庆林一、项目要求:声控小车是科大华为科技制作竞赛命题组的项目,其要求是编写一个语言识别程序并适当改装一个小型机动车,使之在一个预先不知道具体形状的跑道上完全由声控来完成行驶比赛。
跑道上可以有坡面,坑,障碍等多种不利条件,小车既要具有较快的速度,也要同时具有较强的灵活性,能够克服上述条件。
二、项目分析:由于小车只要求完成跑道上的声控行驶,所以我们可以使用简单的单音命令来操作,如“前”、“后”、“左”、“右”等。
由于路面有各种不利条件,而且规则要求小车尽可能不越过边线,这就决定了我们的小车不能以较高的速度进行长时间的快速行驶。
所以我们必须控制小车的速度和行进距离。
由于外界存在噪声干扰,所以我们必须对噪声进行处理以减小其影响。
鉴于上诉各种要求,我们决定对购买的遥控小车进行简单改造,使用PC机已有的硬件条件编写软件来完成语音的输入,采集,处理和识别,以实现对小车的控制。
三、解决思路与模块:整个程序大致可划分为三个模块,其结构框图如下图所示:整个程序我们在Visual C++ 环境下编写。
四、各模块的实现:1 声音的采集:将声音信号送入计算机,我们利用了声卡录音的低层操作技术,即对winmm.lib进行API调用。
具体编程时这一部分被写在一个类中(Soundin类)。
在构造函数中设定包括最大采样率(11025),数据缓存(作为程序一次性读入的数据,2048),声卡本身所带的一些影响采样数据等的各种参数;调用API函数waveInGetNumDevs(返回UNIT,参数为空)检察并打开声音输入设备,即声卡;并进而使用waveInGetDevCaps得到声卡的容量(在waveInCaps中存有该数据,对其进行地址引用,从DWORD dwFormats得到最大采样率、声道数和采样位);创建一个叫WaveInThreadEvent的事件对象,并赋予一个Handle,叫m_WaveInEvent,开始利用线程指针m_WaveInThread调用自定义的线程WaveInThreadProc;对结构WAVEFORMATEX中WaveInOpen开始提供录音设备。


matlab声音模拟代码
当我们谈到在MATLAB中进行声音模拟时,通常涉及到使用信号处理技术和音频处理工具箱。
下面是一个简单的示例代码,用于生成和播放一个简单的声音信号:
matlab.
% 设置参数。
fs = 44100; % 采样率。
duration = 3; % 声音持续时间(秒)。
% 生成时间向量。
t = 0:1/fs:duration;
% 生成声音信号。
f1 = 440; % 第一个频率为440Hz.
f2 = 880; % 第二个频率为880Hz.
y = sin(2pif1t) + sin(2pif2t); % 生成两个频率的正弦波信号叠加。
% 播放声音。
sound(y, fs);
在这个示例中,我们首先设置了采样率和声音的持续时间。
然后生成了一个时间向量t,用于表示声音的时间轴。
接下来,我们生成了两个频率为440Hz和880Hz的正弦波信号,并将它们叠加起来。
最后,使用`sound`函数播放生成的声音信号。
当然,这只是一个简单的示例。
在实际的声音模拟中,可能涉及到更复杂的信号处理和音频特征提取。
MATLAB提供了丰富的工具箱和函数,用于处理和分析声音信号,包括滤波、频谱分析、时域分析等。
你可以根据具体的需求和应用场景,进一步探索和应用这些工具来进行声音模拟和分析。

如何使用MATLAB进行语音识别与合成引言:随着人工智能技术的迅速发展,语音识别与合成逐渐成为我们日常生活中不可或缺的一部分。
借助于MATLAB这一强大的工具,我们可以轻松实现语音识别与合成的功能。
本文将介绍如何使用MATLAB进行语音识别与合成,以及一些相关的算法和技巧。
一、MATLAB中的语音处理工具箱MATLAB提供了一系列强大的语音处理工具箱,其中包括音频数据导入、音频显示、频谱分析、语音识别、语音合成等功能。
我们可以使用这些工具箱来快速进行语音处理的各个环节。
二、语音信号的特征提取与预处理语音信号是一种时间序列信号,我们需要将其转化为数值特征来进行处理。
常用的语音特征包括语音音素、频率、时域和频域特征等。
在MATLAB中,我们可以使用MFCC(Mel-Frequency Cepstral Coefficients)来提取语音信号的特征。
MFCC是一种重要且有效的语音特征提取方法,可以在一定程度上帮助我们区分不同的语音信号。
三、语音识别算法的实现语音识别是将语音信号转化为相应的文本或命令的过程。
常见的语音识别算法包括模型基于高斯混合模型(Gaussian Mixture Model,GMM)的HMM(Hidden Markov Model)、深度神经网络(Deep Neural Networks,DNN)等。
在MATLAB 中,我们可以使用Speech Recognition Toolbox来实现这些算法。
例如,我们可以使用HMM来训练一个语音识别模型,然后将新的语音信号输入模型中进行识别。
四、语音合成算法的实现语音合成是将文本或命令转化为相应的语音信号的过程。
主流的语音合成算法包括基于规则的方法和基于统计的方法。
基于规则的方法是通过事先定义一些语音合成的规则来实现,而基于统计的方法则是通过学习大量的语音样本来生成合成语音。
在MATLAB中,我们可以使用Speech Synthesis Toolbox来实现语音合成算法。

使用Matlab进行实时语音处理与语音识别的实践指南实时语音处理与语音识别是人工智能领域一个重要而复杂的研究方向。
而Matlab作为一种强大的科学计算软件,提供了丰富的工具箱和函数库,为语音处理与语音识别的研究和实践提供了极大的便利。
本文将介绍如何使用Matlab进行实时语音处理与语音识别并给出一些实践指南。
一、Matlab的语音处理工具箱Matlab的语音处理工具箱(Speech Processing Toolbox)是Matlab中专门用于语音信号的处理和分析的工具箱。
它提供了一系列函数和工具,包括语音信号的录制和播放、声音特征提取、声音增强和去噪、语音识别等。
在进行实时语音处理与语音识别之前,我们需要先安装并激活语音处理工具箱。
二、实时语音处理的基本步骤实时语音处理通常由以下几个基本步骤组成:声音录制、语音信号分帧、对每帧信号进行加窗处理、进行傅里叶变换得到频谱信息、对频谱信息进行处理和特征提取、进行语音识别。
1. 声音录制Matlab提供了`audiorecorder`函数来实现声音的录制功能。
下面是一个简单的示例代码:```fs = 44100; % 采样率nBits = 16; % 采样精度nChannels = 1; % 声道数recorder = audiorecorder(fs, nBits, nChannels);record(recorder);pause(5); % 录制5秒stop(recorder);y = getaudiodata(recorder); % 获取录音数据```2. 语音信号分帧语音信号在进行处理之前需要进行分帧处理,将连续的语音信号分成若干个小的时间窗口。
分帧的目的是提取局部语音特征,常用的窗口函数包括矩形窗、汉明窗等。
Matlab提供了`buffer`函数用于分帧处理。
示例代码如下:```frameSize = 256; % 窗口大小overlap = 128; % 帧之间的重叠部分frames = buffer(y, frameSize, overlap);```3. 加窗处理加窗处理是对每一帧信号进行加窗操作,以减少频谱泄漏。
基于MATLAB人脸识别系统的设计与实现1.1题目的主要研究内容(宋体四号加粗左对齐)(1)对于一幅图像可以看作一个由像素值组成的矩阵,也可以扩展开,看成一个矢量。
如一幅N*N象素的图像可以视为长度为N2的矢量,这样就认为这幅图像是位于N2维空间中的一个点,这种图像的矢量表示就是原始的图像空间,但是这个空间仅是可以表示或者检测图像的许多个空间中的一个。
不管子空间的具体形式如何,这种方法用于图像识别的基本思想都是一样的,首先选择一个合适的子空间,图像将被投影到这个子空间上,然后利用对图像的这种投影间的某种度量来确定图像间的相似度,最常见的就是各种距离度量。
因此,本次采用PCA 算法确定一个子空间,最后使用最小距离法进行识别,并用matlab实现。
(2)系统流程图1.2题目研究的工作基础或实验条件(1)给出所需图像,软件实现中已知程序代码的设计和算法应用。
(2)软件环境(开发工具用MATLAB)。
1.3数据集描述计算数据库中每张图片在子空间中的坐标,得到一组坐标,作为下一步识别匹配的搜索空间。
计算新输入图片在子空间中的坐标,采用最小距离法,遍历搜索空间,得到与其距离最小的坐标向量,该向量对应的人脸图像即为识别匹配的结果。
假设一幅人脸图像包含N个像素点,它可以用一个N维向量Γ表示。
这样,训练样本库就可以用Γi(i=1,...,M)表示。
协方差矩阵C的正交特征向量就是组成人脸空间的基向量,即特征脸。
将特征值由大到小排列:λ1≥λ2≥...≥λr,其对应的特征向量为μk。
这样每一幅人脸图像都可以投影到由u1,u2,...,ur张成的子空间中。
因此,每一幅人脸图像对应于子空间中的一点。
同样,子空间的任意一点也对应于一幅图像。
1.4特征提取过程描述通过人脸特征点的检测与标定可以确定人脸图像中显著特征点的位置(如眼睛、眉毛、鼻子、嘴巴等器官),同时还可以得到这些器官及其面部轮廓的形状信息的描述。
根据人脸特征点检测与标定的结果,通过某些运算得到人脸特征的描述(这些特征包括:全局特征和局部特征,显式特征和统计特征等)。
基于matlab的语音识别系统专业综合课程设计系: 信息与通信工程专业: 通信工程班级: 081班设计题目: 基于matlab的语音识别系统学生姓名:指导教师:完成日期:2011年12月27日一(设计任务及要求1.1设计任务作为智能计算机研究的主导方向和人机语音通信的关键技术,语音识别技术一直受到各国科学界的广泛关注。
以语音识别开发出的产品应用领域非常广泛,有声控电话交换、语音拨号系统、信息网络查询、家庭服务、宾馆服务、旅行社服务系统、订票系统、声控智能玩具、医疗服务、银行服务、股票查询服务、计算机控制、工业控制、语音通信系统、军事监听、信息检索、应急服务、翻译系统等,几乎深入到社会的每个行业、每个方面,其应用和经济社会效益前景非常广泛。
本次任务设计一个简单的语音识别系。
1.2设计要求要求:使用matlab软件编写语音识别程序二(算法方案选择2.1设计方案语音识别属于模式识别范畴,它与人的认知过程一样,其过程分为训练和识别两个阶段。
在训练阶段,语音识别系统对输入的语音信号进行学习。
学习结束后,把学习内容组成语音模型库存储起来;在识别阶段,根据当前输入的待识别语音信号,在语音模型库中查找出相应的词义或语义。
语音识别系统与常规模式识别系统一样包括特征提取、模式匹配、模型库等3个基本单元,它的基本结构如图1所示。
图1 语音识别系统基本结构图本次设计主要是基于HMM模型(隐马尔可夫模型)。
这是在20世纪80年代引入语音识别领域的一种语音识别算法。
该算法通过对大量语音数据进行数据统计,建立识别词条的统计模型,然后从待识别语音信号中提取特征,与这些模型进行匹配,通过比较匹配分数以获得识别结果。
通过大量的语音,就能够获得一个稳健的统计模型,能够适应实际语音中的各种突发情况。
并且,HMM算法具有良好的识别性能和抗噪性能。
2.2方案框图图2 HMM语音识别系统2.3隐马尔可夫模型HMM过程是一个双重随机过程:一重用于描述非平稳信号的短时平稳段的统计特征(信号的瞬态特征);另一重随机过程描述了每个短时平稳段如何转变到下一个短时平稳段,即短时统计特征的动态特性(隐含在观察序列中)。
科学技术创新2020.21的推广来完成。
经实验分析,软件无线电在无线通信中,可发挥控制硬件电路的功能,因此通过该软件的创新应用与推广,可有效削弱无线通信对硬件设备的依赖程度,从而实现更为独立和灵活的发展。
软件无线电与传统有线系统相比,具有明显的特征优势:一是各方面的功能可通过软件来发挥;二是其自身的兼容性较好,可同时容纳不同的功能类型,协同完成既定的传输任务;三是硬件的结构布局具有良好的通用性特征。
基于上述特征,该技术的应用可有效增加通信方式的种类,体现出更好的性能。
但需注意,在使用该类技术时,需要重点开发线电技术的侦查和对抗等方面的功能,这样才能有效提升通信途径的安全性与稳定性,并且提高传输信息的保密程度。
2.5基于蓝牙技术的信号传感器除了上述的创新方式外,蓝牙技术也是实现无线通信方式创新的有效途径。
基于蓝牙技术应用信号传感设备,能够极大推进无线通信传输方式的拓展。
从研究结果分析,信号传感设备主要使用分散式的网络方式来实现组网,在算法方面也能够凸显出较高的效率优势。
但需注意,在使用蓝牙技术的同时,可兼顾完善网络的系统协议内容,从而提高对系统的使用率,同时优化运用效果。
将蓝牙技术应用于通信中,可极大提升信息传输的效率和质量,最大限度保证信息内容的完整性与可靠性。
而蓝牙作为信息传输的介质,可及时反馈不同用户的信息需求点,这样在实行信息传输时,设备便能够迅速而准确地定位信号接受位置,从而总体提升信号的传输效果。
结束语结合以上实践探索,在有效的总结无线电通信技术过程,要重视技术创新研究,通过不断采取更加高效的无线电通信手段,才能有效的掌握更加高效的技术措施,希望进一步研究能够总结更加高效的无线电技术方法,从而为无线电技术的实践应用水平提高提供保证。
参考文献[1]庞世勇.探讨提升无线电通信质量的技术[J].传播力研究,2018,2(31):248.[2]刘堂伟.提升无线电通信质量的技术研究[J].中国新通信,2017,19(24):25.[3]李鹏鸣.关于无线电设备电磁屏蔽技术的探讨[J].科技创新与应用,2016(8):54.一种基于MATLAB 的智能语音识别系统设计陈后全(西北民族大学电气工程学院,甘肃兰州730030)本文设计的目的是使得机械可以进行语音识别,从而帮助人们方便快捷又安全有效的生活。
Matlab中的语音识别算法引言:语音识别是对人类语言进行自动识别和理解的技术,旨在将语音信号转化为文本或其他形式的可理解信息。
随着科技的不断发展,语音识别技术在人工智能、智能音箱、无线通信等领域得到广泛应用。
在语音识别算法中,Matlab作为一个功能强大且易于使用的编程工具,提供了多种算法和函数,为语音识别的研究和实现提供了便捷的支持。
一、语音特征提取语音信号在识别前需要进行特征提取,以减少数据量和保留关键信息。
Matlab提供了多种方法来提取语音特征,其中最常用的是倒谱系数和MFCC(Mel频率倒谱系数)。
1. 倒谱系数(Cepstral Coefficients)倒谱系数是语音信号的谱包络特征。
在Matlab中,倒谱系数的计算可以通过对语音信号进行窗函数切片、进行傅里叶变换、取对数谱、进行倒谱变换得到。
这些过程都可以使用Matlab的信号处理工具箱中的函数轻松实现。
2. MFCC(Mel频率倒谱系数)MFCC是一种基于人耳听觉模型的语音特征提取方法。
它通过将声音信号转换为频谱图,并将频谱数据通过Mel滤波器组进行加权,再进行对数变换和离散余弦变换得到。
Matlab中可以使用音频处理工具箱中的函数来实现MFCC特征提取,例如melSpectrogram和mfcc函数。
二、语音识别算法语音识别算法是通过对语音信号进行处理和分析,利用模式匹配和统计学习的方法来区分不同的语音信息。
在Matlab中,可以使用一些经典的语音识别算法来实现,例如隐马尔可夫模型(HMM)和深度学习算法。
1. 隐马尔可夫模型(Hidden Markov Model)隐马尔可夫模型是一种常用的语音识别算法,它利用状态转移概率和输出概率来描述语音信号的特征变化和语音单元之间的关系。
在Matlab中,可以使用HMM工具箱中的函数来构建和训练隐马尔可夫模型,并通过Viterbi算法进行语音识别。
2. 深度学习算法深度学习算法是近年来在语音识别领域取得突破的一种方法。
matlab语音识别系统(源代码)最新版目录一、设计任务及要求 (1)二、语音识别的简单介绍2.1语者识别的概念 (2)2.2特征参数的提取 (3)2.3用矢量量化聚类法生成码本 (3)2.4VQ的说话人识别 (4)三、算法程序分析3.1函数关系 (4)3.2代码说明 (5)3.2.1函数mfcc (5)3.2.2函数disteu (5)3.2.3函数vqlbg (6)3.2.4函数test (6)3.2.5函数testDB (7)3.2.6 函数train (8)3.2.7函数melfb (8)四、演示分析 (9)五、心得体会 (11)附:GUI程序代码 (12)一、设计任务及要求用MATLAB实现简单的语音识别功能;具体设计要求如下:用MATLAB实现简单的数字1~9的语音识别功能。
二、语音识别的简单介绍基于VQ的说话人识别系统,矢量量化起着双重作用。
在训练阶段,把每一个说话者所提取的特征参数进行分类,产生不同码字所组成的码本。
在识别(匹配)阶段,我们用VQ方法计算平均失真测度(本系统在计算距离d时,采用欧氏距离测度),从而判断说话人是谁。
语音识别系统结构框图如图1所示。
图1 语音识别系统结构框图2.1语者识别的概念语者识别就是根据说话人的语音信号来判别说话人的身份。
语音是人的自然属性之一,由于说话人发音器官的生理差异以及后天形成的行为差异,每个人的语音都带有强烈的个人色彩,这就使得通过分析语音信号来识别说话人成为可能。
用语音来鉴别说话人的身份有着许多独特的优点,如语音是人的固有的特征,不会丢失或遗忘;语音信号的采集方便,系统设备成本低;利用电话网络还可实现远程客户服务等。
因此,近几年来,说话人识别越来越多的受到人们的重视。
与其他生物识别技术如指纹识别、手形识别等相比较,说话人识别不仅使用方便,而且属于非接触性,容易被用户接受,并且在已有的各种生物特征识别技术中,是唯一可以用作远程验证的识别技术。
因此,说话人识别的应用前景非常广泛:今天,说话人识别技术已经关系到多学科的研究领域,不同领域中的进步都对说话人识别的发展做出了贡献。
说话人识别技术是集声学、语言学、计算机、信息处理和人工智能等诸多领域的一项综合技术,应用需求将十分广阔。
在吃力语音信号的时候如何提取信号中关键的成分尤为重要。
语音信号的特征参数的好坏直接导致了辨别的准确性。
2.2特征参数的提取对于特征参数的选取,我们使用mfcc 的方法来提取。
MFCC 参数是基于人的听觉特性利用人听觉的屏蔽效应,在Mel 标度频率域提取出来的倒谱特征参数。
MFCC 参数的提取过程如下:1. 对输入的语音信号进行分帧、加窗,然后作离散傅立叶变换,获得频谱分布信息。
设语音信号的DFT 为:10,)()(112-≤≤=∑-=-N k en x k X N n N nk j a π(1)其中式中x(n)为输入的语音信号,N 表示傅立叶变换的点数。
2. 再求频谱幅度的平方,得到能量谱。
3. 将能量谱通过一组Mel 尺度的三角形滤波器组。
我们定义一个有M 个滤波器的滤波器组(滤波器的个数和临界带的个数相近),采用的滤波器为三角滤波器,中心频率为f(m),m=1,2,3,···,M本系统取M=100。
4. 计算每个滤波器组输出的对数能量。
N 12a m k 1S(m)ln(|(k)|H (k)),0m M 1X -==≤≤-∑ (2)其中m H (k)为三角滤波器的频率响应。
5. 经过离散弦变换(DCT )得到MFCC 系数。
10C(n)()cos((0.5/)),(3)01M m S m n m m n N π-==-≤≤-∑MFCC 系数个数通常取20—30,常常不用0阶倒谱系数,因为它反映的是频谱能量,故在一般识别系统中,将称为能量系数,并不作为倒谱系数,本系统选取20阶倒谱系数。
2.3用矢量量化聚类法生成码本我们将每个待识的说话人看作是一个信源,用一个码本来表征。
码本是从该说话人的训练序列中提取的MFCC 特征矢量聚类而生成。
只要训练的序列足够长,可认为这个码本有效地包含了说话人的个人特征,而与讲话的内容无关。
本系统采用基于分裂的LBG 的算法设计VQ 码本,(1,2,,)k X k K =⋅⋅⋅为训练序列,B 为码本。
具体实现过程如下:1. 取提取出来的所有帧的特征矢量的型心(均值)作为第一个码字矢量B1。
2. 将当前的码本Bm 根据以下规则分裂,形成2m 个码字。
)1()1({εε-=+=-+m m m m B B B B (4) 其中m 从1变化到当前的码本的码字数,ε是分裂时的参数,本文ε=0.01。
3. 根据得到的码本把所有的训练序列(特征矢量)进行分类,然后按照下面两个公式计算训练矢量量化失真量的总和[]n D 以及相对失真(n 为迭代次数,初始n=0,[1]D -=∞,B 为当前的码书),若相对失真小于某一阈值ε,迭代结束,当前的码书就是设计好的2m 个码字的码书,转5。
否则,转下一步。
量化失真量和:()1min (,)Kn k k D d X B ==∑ (5)相对失真:(1)||n nn D D D-- (6) 4. 重新计算各个区域的新型心,得到新的码书,转3。
5. 重复2 ,3 和4步,直到形成有M 个码字的码书(M 是所要求的码字数),其中D0=10000。
2.4 VQ 的说话人识别设是未知的说话人的特征矢量1{,,}T X X ,共有T 帧是训练阶段形成的码书,表示码书第m 个码字,每一个码书有M 个码字。
再计算测试者的平均量化失真D ,并设置一个阈值,若D 小于此阈值,则是原训练者,反之则认为不是原训练者。
∑=≤≤=11]min[/1),(j Mm m j T D B x d (7) 三、 算法程序分析在具体的实现过程当中,采用了matlab 软件来帮助完成这个项目。
在matlab 中主要由采集,分析,特征提取,比对几个重要部分。
以下为在实际的操作中,具体用到得函数关系和作用一一列举在下面。
3.1函数关系主要有两类函数文件Train.m 和Test.m在Train.m 调用Vqlbg.m 获取训练录音的vq 码本,而Vqlbg.m 调用mfcc.m 获取单个录音的mel 倒谱系数,接着mfcc.m 调用Melfb.m---将能量谱通过一组Mel 尺度的三角形滤波器组。
在Test.m 函数文件中调用Disteu.m 计算训练录音(提供vq 码本)与测试录音(提供mfcc)mel倒谱系数的距离,即判断两声音是否为同一录音者提供。
Disteu.m调用mfcc.m获取单个录音的mel倒谱系数。
mfcc.m调用Melfb.m---将能量谱通过一组Mel尺度的三角形滤波器组。
3.2具体代码说明3.2.1函数mffc:function r = mfcc(s, fs)---m = 100;n = 256;l = length(s);nbFrame = floor((l - n) / m) + 1; %沿-∞方向取整for i = 1:nfor j = 1:nbFrameM(i, j) = s(((j - 1) * m) + i); %对矩阵M赋值endendh = hamming(n); %加 hamming 窗,以增加音框左端和右端的连续性M2 = diag(h) * M;for i = 1:nbFrameframe(:,i) = fft(M2(:, i)); %对信号进行快速傅里叶变换FFTendt = n / 2;tmax = l / fs;m = melfb(20, n, fs); %将上述线性频谱通过Mel 频率滤波器组得到Mel 频谱,下面在将其转化成对数频谱n2 = 1 + floor(n / 2);z = m * abs(frame(1:n2, :)).^2;r = dct(log(z)); %将上述对数频谱,经过离散余弦变换(DCT)变换到倒谱域,即可得到Mel 倒谱系数(MFCC参数)3.2.2函数disteu---计算测试者和模板码本的距离function d = disteu(x, y)[M, N] = size(x); %音频x赋值给【M,N】[M2, P] = size(y); %音频y赋值给【M2,P】if (M ~= M2)error('不匹配!') %两个音频时间长度不相等endd = zeros(N, P);if (N < P)%在两个音频时间长度相等的前提下copies = zeros(1,P);for n = 1:Nd(n,:) = sum((x(:, n+copies) - y) .^2, 1);endelsecopies = zeros(1,N);for p = 1:Pd(:,p) = sum((x - y(:, p+copies)) .^2, 1)';end%%成对欧氏距离的两个矩阵的列之间的距离endd = d.^0.5;3.2.3函数vqlbg---该函数利用矢量量化提取了音频的vq码本function r = vqlbg(d,k)e = .01;r = mean(d, 2);dpr = 10000;for i = 1:log2(k)r = [r*(1+e), r*(1-e)];while (1 == 1)z = disteu(d, r);[m,ind] = min(z, [], 2);t = 0;for j = 1:2^ir(:, j) = mean(d(:, find(ind == j)), 2);x = disteu(d(:, find(ind == j)), r(:, j));for q = 1:length(x)t = t + x(q);endendif (((dpr - t)/t) < e)break;elsedpr = t;endendend3.2.4函数testfunction finalmsg = test(testdir, n, code)for k = 1:n % read test sound file of each speaker file = sprintf('%ss%d.wav', testdir, k);[s, fs] = wavread(file);v = mfcc(s, fs); % 得到测试人语音的mel倒谱系数distmin = 4; %阈值设置处% 就判断一次,因为模板里面只有一个文件d = disteu(v, code{1}); %计算得到模板和要判断的声音之间的“距离”dist = sum(min(d,[],2)) / size(d,1); %变换得到一个距离的量%测试阈值数量级msgc = sprintf('与模板语音信号的差值为:%10f ', dist);disp(msgc);%此人匹配if dist <= distmin %一个阈值,小于阈值,则就是这个人。