AMOS结构方程模型修正解析
- 格式:ppt
- 大小:4.42 MB
- 文档页数:49


AMOS结构方程模型分析AMOS(Analysis of Moment Structures)是一种常用的结构方程模型(SEM)分析软件,可用于研究各种不同领域的问题和假设。
SEM是一种统计方法,用于测试和量化复杂的因果关系假设,以及评估模型拟合优度。
本文将介绍AMOS的基本原理、应用案例和分析步骤。
AMOS的基本原理是使用路径图表示模型中的因果关系,然后通过最小二乘估计法对模型进行参数估计。
AMOS还可以用来评估模型拟合度、进行模型比较,以及检验模型中的因果关系。
一个常见的应用案例是研究变量之间的因果关系。
例如,一个研究者可能想要了解自尊对学术成绩的影响。
在这种情况下,自尊是自变量,学术成绩是因变量。
通过收集数据,研究者可以使用AMOS来构建一个模型,来评估这两个变量之间的因果关系,并确定自尊对学术成绩的影响。
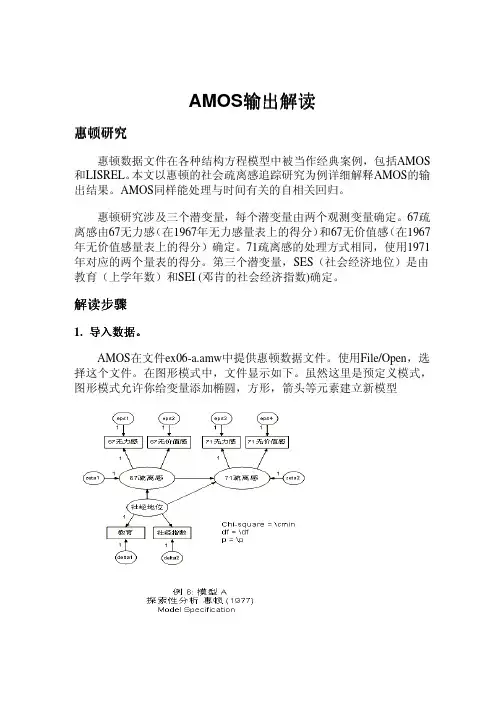
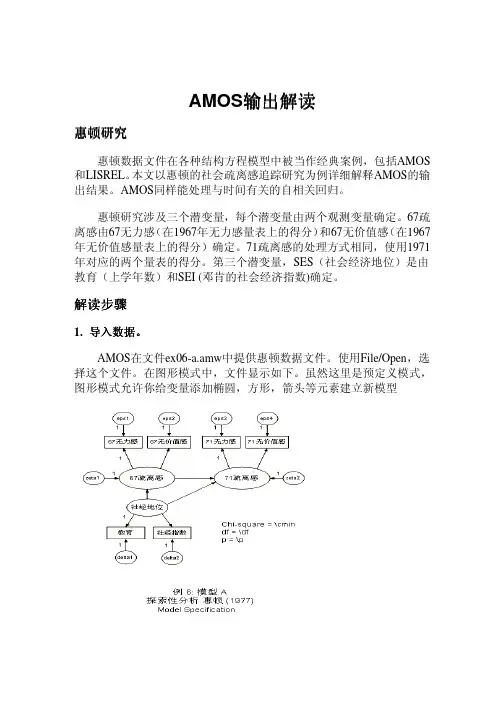
使用AMOS进行结构方程模型分析的步骤如下:1.确定研究目的和问题:首先,需要明确研究的目的和问题,确定需要评估的模型。
2.收集数据:根据研究问题,需要收集相关的数据。
数据可以是自己收集的,也可以是从其他研究中获取的。
3.确定模型的变量和参数:根据研究问题和收集到的数据,需要确定模型中的变量和参数。
变量可以是观察变量(直接测量)或潜变量(隐性构念)。
参数可以是路径系数、截距、测量误差等。
4.构建路径图:使用AMOS的图形界面,根据模型的变量和参数,构建路径图。
路径图可以直观地展示变量之间的因果关系。
5.估计模型参数:根据收集到的数据,使用最小二乘估计法对模型参数进行估计。
AMOS会自动计算最优参数估计和拟合度指标。
6.评估模型拟合度:使用拟合度指标(如X2统计量、均方差逼近指数、规范化拟合指数等),评估模型的拟合度。
较小的X2值、较大的均方差逼近指数和规范化拟合指数表示模型拟合度较好。
7.进行模型修正:如果模型的拟合度不满足要求,可以通过增加、删除或修改模型的路径和变量,进行模型修正。
8.进行统计推断:使用AMOS进行统计推断,来确定模型中的因果关系是否显著。

使用AMOS解释结构方程模型结构方程模型(SEM)是一种统计模型,在社会科学研究中经常使用。
它可以用来分析变量之间的复杂关系,并评估这些关系的强度和方向。
AMOS是一种流行的结构方程模型软件,通过图形用户界面提供了易于使用的界面。
在结构方程模型中,我们通常将变量分为两类:观察变量和潜在变量。
观察变量是直接可测量的变量,而潜在变量是不能直接测量的变量,它们通过观察变量的指标进行测量。
结构方程模型的目标是评估潜在变量之间的关系以及它们与观察变量之间的关系,并给出这些关系的显著性。
AMOS的使用步骤通常包括以下几个步骤:1.指定模型:在AMOS中,可以使用图形界面直观地指定结构方程模型。
可以使用不同的图形符号表示观察变量、潜在变量和它们之间的关系。
在此过程中,也可以指定约束、修正指标和错误项等。
2.估计参数:通过最大似然方法或最小二乘法,可以估计模型的参数。
最大似然方法假设数据是从特定的分布中随机抽取的,而最小二乘法假设变量之间的关系是线性的。
参数估计后,可以得到模型的适应度指标,如拟合度、标准化拟合度指标等。
3.模型拟合度:模型拟合度指标可以用来评估模型与数据之间的一致性。
可以使用不同的拟合度指标,如卡方拟合度、比率拟合度、均方根残差等来评估模型的拟合度。
一般来说,拟合度指标的数值越接近1,表示模型与数据之间的一致性越好。
4.异常值和不良拟合指标:在AMOS中,也可以检查是否存在异常值和不良拟合指标。
异常值是指不符合模型假设的数据点,而不良拟合指标是指模型与数据之间的不相符点。
5.修改模型:如果模型与数据之间的拟合度不理想,可以修改模型以提高拟合度。
可以尝试添加或删除路径、重新指定变量间的关系、修复测量误差等。
通过AMOS软件,我们可以进行多个结构方程模型的比较、多组模型的比较以及计算不同变量之间的路径系数和直接效应。
此外,AMOS还提供了可视化工具,如路径图和直观的拟合度统计图,以帮助用户更好地理解和解释模型。

Amos软件操作1.模型设定结构方程模型分析过程可以分为模型构建、模型运算、模型修正以及模型解释四个步骤。
下面以一个研究实例作为说明,使用Amos软件进行计算,阐述在实际应用中结构方程模型的构建、运算、修正与模型解释过程。
2.模型构建的思路根据构建的理论模型,通过设计问卷对留学生学习汉语的学习动机、学习策略和焦虑调查得到实际数据,然后利用对缺失值进行处理后的数据进行分析,并对文中提出的模型进行拟合、修正和解释。
3.潜变量和可测变量的设定模型中共包含2个因素(潜变量):学习动机、学习策略,7个可测变量:融入型动机、工具型动机、焦虑、记忆策略、认知策略、情感策略和社交策略。
4.关于调查数据的收集本次问卷调研的对象为不同国家的留学生5.缺失值的处理采用表列删除法,即在一条记录中,只要存在一项缺失,则删除该记录。
数据的的信度和效度检验1).数据的信度检验信度(reliability)指测量结果(数据)一致性或稳定性的程度。
一致性主要反映的是测验内部题目之间的关系,考察测验的各个题目是否测量了相同的内容或特质。
稳定性是指用一种测量工具(譬如同一份问卷)对同一群受试者进行不同时间上的重复测量结果间的可靠系数。
如果问卷设计合理,重复测量的结果间应该高度相关。
由于本案例并没有进行多次重复测量,所以主要采用反映内部一致性的指标来测量数据的信度。
Cronbach在1951年提出了一种新的方法(Cronbach's Alpha系数),这种方法将测量工具中任一条目结果同其他所有条目作比较,对量表进行内部一致性估计。
2).数据的效度检验效度(validity)指测量工具能够正确测量出所要测量的特质的程度,分为内容效度(content validity)、效标效度(criterion validity)和结构效度(construct validity)三个主要类型。
内容效度也称表面效度或逻辑效度,是指测量目标与测量内容之间的适合性与相符性。

AMOS结构方程模型解读AMOS是一种统计分析工具,用于构建和评估结构方程模型(SEM)。
结构方程模型是一种多变量统计模型,用于研究变量之间的因果关系。
AMOS通过图形界面和最大似然估计方法,帮助研究人员对结构方程模型进行建模、分析和解释。
在利用AMOS进行结构方程模型分析时,首先需要明确研究目的,确定模型的理论基础和构建逻辑。
然后,根据理论框架和变量之间的关系,绘制出模型图。
模型图可以使用AMOS的绘图工具进行绘制,它能够清晰展示变量之间的因果关系。
在模型图绘制完成后,需要进行模型估计。
AMOS使用最大似然估计方法来对模型进行拟合,估计模型中的参数值。
AMOS通过计算各个路径系数的标准误差、置信区间和显著性水平,来评估模型的拟合程度,判断模型对实际数据的拟合优度。
拟合指标是评估模型拟合度的重要指标之一、AMOS提供了多种拟合指标,包括卡方拟合指数(χ²),比较度指数(CFI)、均方根误差逼近度(RMSEA)等。
这些指标可以告诉研究人员模型是否拟合得良好,是否能够解释变量之间的关系。
在解释模型结果时,需要注意各个路径系数的显著性,判断变量之间的关系是否具有统计学意义。
AMOS会给出路径系数的显著性水平,通常使用α=0.05作为显著性水平进行判断。
如果路径系数的显著性水平小于0.05,说明该路径系数具有统计学意义,反之则没有统计学意义。
此外,在模型结果解释时,还需要考虑到模型的解释力和预测力。
解释力是指模型对变量之间关系的解释程度,包括直接效应和间接效应。
预测力是指模型对未来数据的预测能力,通过模型估计出的参数值,可以用于预测变量的取值。
总之,利用AMOS进行结构方程模型的构建和评估,需要明确研究目的,绘制模型图,估计模型参数,评估模型拟合度和解释模型结果。
使用AMOS可以帮助研究人员深入了解变量之间的关系,为决策提供有力的支持。

结构方程模型(Structural Equation Modeling, SEM)是一种统计分析方法,适用于探究变量之间的直接和间接关系。
在这篇文章中,我们将对amos软件中的结构方程模型结果进行解读,以便更好地理解研究中所使用的模型和数据。
1. 模型拟合度分析在进行结构方程模型分析时,首先需要对模型的拟合度进行评估,以确定模型是否能够较好地拟合数据。
在amos中,常用的拟合度指标包括χ²值、df值、χ²/df比值、RMSEA、CFI和TLI等。
这些指标可以帮助我们判断模型的适配程度,通常情况下,χ²/df比值小于3、RMSEA值小于0.08、CFI和TLI值大于0.90则表示模型的拟合度较好。
2. 变量间关系分析在确定模型的拟合度较好之后,接下来需要分析变量之间的直接和间接关系。
结构方程模型能够同时考虑观测变量和潜在变量之间的关系,从而更全面地分析变量之间的影响。
在amos中,我们可以查看路径系数(path coefficient)和标准化间接效应值(standardized indirect effect)来了解变量之间的关系强度和方向。
3. 因果关系验证结构方程模型可以用于验证因果关系,即确定一个变量是否能够直接或间接地影响另一个变量。
在amos中,我们可以通过观察路径系数的显著性水平和间接效应值的大小来判断变量之间的因果关系。
通过验证因果关系,我们可以更深入地理解变量之间的作用机制。
4. 模型修正与改进在对结构方程模型的结果进行初步解读后,我们还可以进一步对模型进行修正与改进,以提高模型的拟合度和解释力。
通过添加或删除路径、改进测量模型、引入中介变量等方式,可以进一步优化模型的结构和效果。
在amos中,我们可以使用模型修改指数(modification indices)来指导模型的修正与改进。
5. 结果解释与实际意义对结构方程模型的结果进行解释与实际意义的探讨非常重要。

AMOS结构方程模型修正经典案例第一节模型设定结构方程模型分析过程可以分为模型构建、模型运算、模型修正以及模型解释四个步骤。
下面以一个研究实例作为说明,使用Amos7软件1进行计算,阐述在实际应用中结构方程模型的构建、运算、修正与模型解释过程。
一、模型构建的思路本案例在著名的美国顾客满意度指数模型(ASCI)的基础上,提出了一个新的模型,并以此构建潜变量并建立模型结构。
根据构建的理论模型,通过设计问卷对某超市顾客购物服务满意度调查得到实际数据,然后利用对缺失值进行处理后的数据2进行分析,并对文中提出的模型进行拟合、修正和解释。
二、潜变量和可测变量的设定本文在继承ASCI模型核心概念的基础上,对模型作了一些改进,在模型中增加超市形象。
它包括顾客对超市总体形象及与其他超市相比的知名度。
它与顾客期望,感知价格和顾客满意有关,设计的模型见表7-1。
模型中共包含七个因素(潜变量):超市形象、质量期望、质量感知、感知价值、顾客满意、顾客抱怨、顾客忠诚,其中前四个要素是前提变量,后三个因素是结果变量,前提变量综合决定并影响着结果变量(Eugene W. Anderson & Claes Fornell,2000;殷荣伍,2000)。
2.1、顾客满意模型中各因素的具体范畴1本案例是在Amos7中完成的。
2见spss数据文件“处理后的数据.sav”。
参考前面模型的总体构建情况、国外研究理论和其他行业实证结论,以及小范围甄别调查的结果,模型中各要素需要观测的具体范畴,见表7-2。
三、关于顾客满意调查数据的收集本次问卷调研的对象为居住在某大学校内的各类学生(包括全日制本科生、全日制硕士和博士研究生),并且近一个月内在校内某超市有购物体验的学生。
调查采用随机拦访的方式,并且为避免样本的同质性和重复填写,按照性别和被访者经常光顾的超市进行控制。
问卷内容包括7个潜变量因子,24项可测指标,3正向的,采用Likert10级量度从“非常低”到“非常高”本次调查共发放问卷500份,收回有效样本436份。

amos结构方程结果解读
Amos 是一个用于结构方程模型分析的软件,它可以用于探究变量之间的关系,特别是在地理空间分析领域。
当使用 Amos 进行结构方程模型分析时,输出结果会包括一些参数和信息,这些参数和信息可以帮助我们更好地理解模型,以及确定模型是否拟合良好。
以下是Amos 输出结果的一些参数和信息:
1. Outputpath diagram:在 Outputpath diagram 模块中,可以查看模型的非标准化结果和标准化结果。
非标准化结果表示模型中的变量和残差,而标准化结果则表示变量之间的回归系数的 R 方。
这些结果可以帮助我们了解变量之间的因果关系和权重大小。
2. Amos Output:在 Amos Output 模块中,可以查看模型的分析摘要和其他详细信息。
分析摘要包括模型的时间、标题和其他相关信息。
其他详细信息包括模型的拟合指数、变量总结和备注等信息,这些信息可以帮助更好地理解模型。
3. Notes for Group:在 Notes for Group 模块中,可以查看模型的备注。
这些备注包括模型的类型、内生变量间的因果关系、样本大小等信息,这些信息可以帮助更好地理解模型。
4. Variable Summary:在 Variable Summary 模块中,可以查看模型中的变量总结。
这些总结包括变量的类型、观测变量和内生变量等信息,这些信息可以帮助更好地理解模型中的变量。
通过以上参数和信息,我们可以更好地理解 Amos 输出的结果,从而更好地评估模型拟合度和确定模型的研究方向。

amos结构方程结果解读
结构方程模型(Structural Equation Modeling, SEM)是一种
统计分析方法,用于探索变量之间的因果关系。
Amos是一种常用的
结构方程建模软件,可以用来估计和验证结构方程模型。
Amos的结构方程结果包括路径系数、标准误、t值和p值等。
路径系数表示变量之间的关系强度和方向,标准误表示路径系数的抽样误差,t值表示路径系数显著性检验的结果,p值表示路径系数是否显著。
解读Amos结构方程结果时,首先要关注路径系数。
路径系数的正负
值表示变量之间的正向或负向关系,数值越大表示关系强度越大。
如果路径系数为0,则表示两个变量之间没有直接关系。
其次要关注标准误和t值。
标准误表示路径系数的抽样误差,数值越小表示结果越稳定。
t值表示路径系数的显著性检验结果,一般认为当t值大于1.96时,路径系数是显著的(p < 0.05)。
最后要关注p值。
显著性检验的p值表示路径系数是否显著。
当p值小于0.05时,表示路径系数显著;当p值大于0.05时,表示路径系数不显著。
除了路径系数,Amos还可以提供模型拟合度指标,如卡方值、自由
度、适配度指数(如比较拟合指数CFI、规范化拟合指数NFI等)等。
这些指标用于评估构建的模型与观测数据的拟合程度。
通常情况下,较小的卡方值、较大的适配度指数表示模型的拟合度较好。
对于Amos结构方程结果的解读,需要综合考虑路径系数、标准误、t 值、p值以及模型拟合度指标等多个因素。
通过对这些结果的综合分析,可以得出结论并进行进一步解释和讨论。
AMOS构造方程模型修正经典案例第一节模型设定构造方程模型分析过程可以分为模型构建、模型运算、模型修正以及模型解释四个步骤。
下面以一个研究实例作为说明,使用Amos7软件1进展计算,阐述在实际应用中构造方程模型的构建、运算、修正与模型解释过程。
一、模型构建的思路本案例在著名的美国顾客满意度指数模型(ASCI)的根底上,提出了一个新的模型,并以此构建潜变量并建立模型构造。
根据构建的理论模型,通过设计问卷对某超市顾客购物效劳满意度调查得到实际数据,然后利用对缺失值进展处理后的数据2进展分析,并对文中提出的模型进展拟合、修正和解释。
二、潜变量和可测变量的设定本文在继承ASCI模型核心概念的根底上,对模型作了一些改进,在模型中增加超市形象。
它包括顾客对超市总体形象及与其他超市相比的知名度。
它与顾客期望,感知价格和顾客满意有关,设计的模型见表7-1。
模型中共包含七个因素(潜变量):超市形象、质量期望、质量感知、感知价值、顾客满意、顾客抱怨、顾客忠诚,其中前四个要素是前提变量,后三个因素是结果变量,前提变量综合决定并影响着结果变量(Eugene W. Anderson & Claes Fornell,2000;殷荣伍,2000)。
1本案例是在Amos7中完成的。
2见spss数据文件“处理后的数据.sav〞。
表7-1 设计的构造路径图和根本路径假设2.1、顾客满意模型中各因素的具体畴参考前面模型的总体构建情况、国外研究理论和其他行业实证结论,以及小围甄别调查的结果,模型中各要素需要观测的具体畴,见表7-2。
表7-2 模型变量对应表三、关于顾客满意调查数据的收集本次问卷调研的对象为居住在某大学校的各类学生〔包括全日制本科生、全日制硕士和博士研究生〕,并且近一个月在校某超市有购物体验的学生。
调查采用随机拦访的方式,并且为防止样本的同质性和重复填写,按照性别和被访者经常光临的超市进展控制。
问卷容包括7个潜变量因子,24项可测指标,7个人口变量,量表采用了Likert10级量度,如对超市形象的测量:3正向的,采用Likert10级量度从“非常低〞到“非常高〞本次调查共发放问卷500份,收回有效样本436份。