简单线性相关(一元线性回归分析)..
- 格式:doc
- 大小:1.39 MB
- 文档页数:15

一、线性回归分析若是自变数与依变数都是一个,且Y 和X 呈线性关系,这就称为一元线性回归。
例如,以X 表示小麦每667m 2有效穗数,Y 表示小麦每667m 2的产量,有效穗数即属于自变数,产量即属于依变数。
在这种情形下,可求出产量依有效穗数而变更的线性回归方程。
在另一种情形下,两类变数是平行关系很难分出哪个是自变数,哪个是依变数。
例如,大豆脂肪含量与蛋白质含量的关系,依照需要确信求脂肪含量依蛋白质含量而变更的回归方程,或求蛋白质含量依脂肪含量而变更的回归方程。
回归分析要解决的问题要紧有四个方面:一是依如实验观看值成立适当的回归方程;二是查验回归方程是不是适用,或对回归方程中的回归系数的进行估量;三是对未知参数进行假设考试;四是利用成立起的方程进行预测和操纵。
(一)成立线性回归方程用来归纳两类变数互变关系的线性方程称为线性回归方程。
若是两个变数在散点图上呈线性,其数量关系可能用一个线性方程来表示。
这一方程的通式为:上式叫做y 依x 的直线回归。
其中x 是自变数,y ˆ是依变数y 的估量值,a 是x =0时的y ˆ值,即回归直线在y 轴上的截距,称为回归截距,b 是x 每增加一个单位时,y 将平均地增加(b >0时)或减少(b <0时) b 个单位数,称为回归系数或斜率(regression coefficient or slope )。
要使 能够最好地代表Y 和X 在数量上的互变关系,依照最小平方式原理,必需使将Q 看成两个变数a 与b 的函数,应该选择a 与b ,使Q 取得最小值,必需求Q 对a ,b 的一阶偏导数,且令其等于零,即得:()()⎩⎨⎧∑=∑+∑∑=∑+212xyx b x a yx b an ()()∑∑=--=-=nn Q bx a y yy Q 1min212ˆbx a y +=ˆ()1.7ˆbx a y+=由上述(1)解得:将()代入(2),那么得:()的分子 是x 的离均差与y 的离均差乘积总和,简称乘积和(sum of products ),可记为SP ,分母是x 的离均差平方和,也可记为SS x 。
第二节一元线性回归方程的建立一元线性回归分析是处理两个变量之间关系的最简单模型,它所研究的对象是两个变量之间的线性相关关系。
通过对这个模型的讨论,我们不仅可以掌握有关一元线性回归的知识,而且可以从中了解回归分析方法的基本思想、方法和应用。
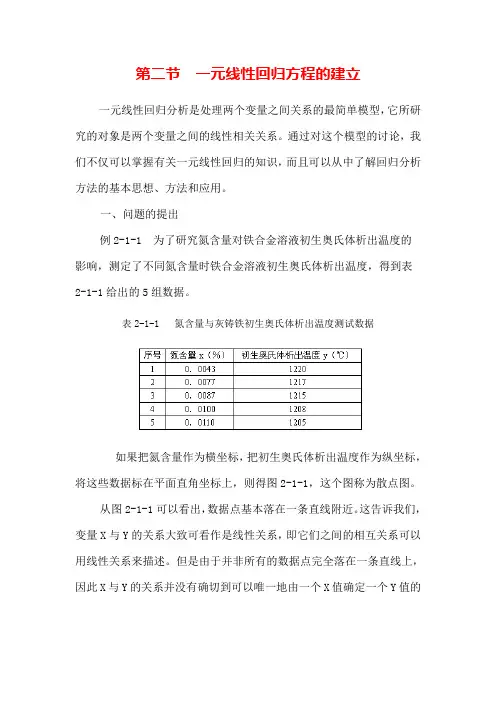
一、问题的提出例2-1-1 为了研究氮含量对铁合金溶液初生奥氏体析出温度的影响,测定了不同氮含量时铁合金溶液初生奥氏体析出温度,得到表2-1-1给出的5组数据。
表2-1-1 氮含量与灰铸铁初生奥氏体析出温度测试数据如果把氮含量作为横坐标,把初生奥氏体析出温度作为纵坐标,将这些数据标在平面直角坐标上,则得图2-1-1,这个图称为散点图。
从图2-1-1可以看出,数据点基本落在一条直线附近。
这告诉我们,变量X与Y的关系大致可看作是线性关系,即它们之间的相互关系可以用线性关系来描述。
但是由于并非所有的数据点完全落在一条直线上,因此X与Y的关系并没有确切到可以唯一地由一个X值确定一个Y值的程度。
其它因素,诸如其它微量元素的含量以及测试误差等都会影响Y 的测试结果。
如果我们要研究X与Y的关系,可以作线性拟合(2-1-1)我们称(2-1-1)式为回归方程,a与b是待定常数,称为回归系数。
从理论上讲,(2-1-1)式有无穷多组解,回归分析的任务是求出其最佳的线性拟合。
二、最小二乘法原理如果把用回归方程计算得到的i值(i=1,2,…n)称为回归值,那么实际测量值y i与回归值i之间存在着偏差,我们把这种偏差称为残差,记为e i(i=1,2,3,…,n)。
这样,我们就可以用残差平方和来度量测量值与回归直线的接近或偏差程度。
残差平方和定义为:(2-1-2) 所谓最小二乘法,就是选择a和b使Q(a,b)最小,即用最小二乘法得到的回归直线是在所有直线中与测量值残差平方和Q最小的一条。
由(2-1-2)式可知Q是关于a,b的二次函数,所以它的最小值总是存在的。
下面讨论的a和b的求法。
三、正规方程组根据微分中求极值的方法可知,Q(a,b)取得最小值应满足(2-1-3)由(2-1-2)式,并考虑上述条件,则(2-1-4)(2-1-4)式称为正规方程组。



从统计学看线性回归(1)——⼀元线性回归⽬录1. ⼀元线性回归模型的数学形式2. 回归参数β0 , β1的估计3. 最⼩⼆乘估计的性质 线性性 ⽆偏性 最⼩⽅差性⼀、⼀元线性回归模型的数学形式 ⼀元线性回归是描述两个变量之间相关关系的最简单的回归模型。
⾃变量与因变量间的线性关系的数学结构通常⽤式(1)的形式:y = β0 + β1x + ε (1)其中两个变量y与x之间的关系⽤两部分描述。
⼀部分是由于x的变化引起y线性变化的部分,即β0+ β1x,另⼀部分是由其他⼀切随机因素引起的,记为ε。
该式确切的表达了变量x与y之间密切关系,但密切的程度⼜没有到x唯⼀确定y的这种特殊关系。
式(1)称为变量y对x的⼀元线性回归理论模型。
⼀般称y为被解释变量(因变量),x为解释变量(⾃变量),β0和β1是未知参数,成β0为回归常数,β1为回归系数。
ε表⽰其他随机因素的影响。
⼀般假定ε是不可观测的随机误差,它是⼀个随机变量,通常假定ε满⾜:(2)对式(1)两边求期望,得E(y) = β0 + β1x, (3)称式(3)为回归⽅程。
E(ε) = 0 可以理解为ε对 y 的总体影响期望为 0,也就是说在给定 x 下,由x确定的线性部分β0 + β1x 已经确定,现在只有ε对 y 产⽣影响,在 x = x0,ε = 0即除x以外其他⼀切因素对 y 的影响为0时,设 y = y0,经过多次采样,y 的值在 y0 上下波动(因为采样中ε不恒等于0),若 E(ε) = 0 则说明综合多次采样的结果,ε对 y 的综合影响为0,则可以很好的分析 x 对 y 的影响(因为其他⼀切因素的综合影响为0,但要保证样本量不能太少);若 E(ε) = c ≠ 0,即ε对 y 的综合影响是⼀个不为0的常数,则E(y) = β0 + β1x + E(ε),那么 E(ε) 这个常数可以直接被β0 捕获,从⽽变为公式(3);若 E(ε) = 变量,则说明ε在不同的 x 下对 y 的影响不同,那么说明存在其他变量也对 y 有显著作⽤。




一元线性回归公式一元线性回归(SimpleLinearRegression)是一种简单的回归分析方法,用于研究两个定量变量之间的关系。
一元线性回归是指一个定量变量Y和一个自变量X之间的线性回归模型,它有一个参数β,用来表示X对Y的影响程度。
一元线性回归的公式如下:Y =0 +1X其中,β0表示Y的偏移量或均值,是X=0时Y的值;β1表示X对Y的影响程度,是X的系数。
一元线性回归的原理是通过拟合一条线来求解X和Y的关系,并计算出X对Y的影响程度。
通常,我们需要用到两个原则:最小二乘法(Least Squares)和最大似然估计(Maximum Likelihood)。
最小二乘法是一种优化方法,其目标是最小化残差的平方和。
残差是Y实际值与拟合模型计算值的差,残差的平方和就是拟合的均方差(Mean Squared Error,MSE)。
因此,最小二乘法的目标是最小化拟合均方差。
最大似然估计是一种概率模型估计方法,其目标是最大化模型似然函数。
似然函数是模型参数取某一特定值时,样本出现的概率,因此,最大似然估计的目标是最大化似然函数。
一元线性回归公式的应用非常广泛,可用于检测两个变量之间的因果关系,或者对比不同变量对另一变量的影响程度,或者预测变量值。
比如,在多重回归中,可以用一元线性回归来研究某一变量的影响程度;在财务分析中,可以用它来预测股票价格;在销售分析中,可以用它来预测某一产品的销售量;在投资分析中,可以利用它来估计投资回报率;在决策分析中,可以利用它来估计某一政策的收益;以及在其他应用中也可以利用它来预测变量值。
此外,一元线性回归还可以用于检验变量之间的关系,比如,用相关分析来检验两个变量之间的关系或使用显著性检验来检验X对Y 的影响是否有效。
对于一元线性回归而言,可以通过以下步骤来建模:首先,分析变量间的关系,看看X是否和Y有线性关系;其次,计算拟合系数β1和β0;最后,检验拟合模型的精度。


第十三讲简单线性相关(一元线性回归分析)对于两个或更多变量之间的关系,相关分析考虑的只是变量之间是否相关、相关的程度,而回归分析关心的问题是:变量之间的因果关系如何。
回归分析是处理一个或多个自变量与因变量间线性因果关系的统计方法。
如婚姻状况与子女生育数量,相关分析可以求出两者的相关强度以及是否具有统计学意义,但不对谁决定谁作出预设,即可以相互解释,回归分析则必须预先假定谁是因谁是果,谁明确谁为因与谁为果的前提下展开进一步的分析。
一、一元线性回归模型及其对变量的要求(一)一元线性回归模型1、一元线性回归模型示例两个变量之间的真实关系一般可以用以下方程来表示:Y=A+BX+方程中的 A 、B 是待定的常数,称为模型系数,是残差,是以X预测Y 产生的误差。
两个变量之间拟合的直线是:y a bxy 是y的拟合值或预测值,它是在X 条件下 Y 条件均值的估计a 、b 是回归直线的系数,是总体真实直线距,当自变量的值为0 时,因变量的值。
A、B 的估计值, a 即 constant 是截b 称为回归系数,指在其他所有的因素不变时,每一单位自变量的变化引起的因变量的变化。
可以对回归方程进行标准化,得到标准回归方程:y x为标准回归系数,表示其他变量不变时,自变量变化一个标准差单位( Z XjXj),因变量 Y 的标准差的平均变化。
S j由于标准化消除了原来自变量不同的测量单位,标准回归系数之间是可以比较的,绝对值的大小代表了对因变量作用的大小,反映自变量对Y 的重要性。
(二)对变量的要求:回归分析的假定条件回归分析对变量的要求是:自变量可以是随机变量,也可以是非随机变量。
自变量 X 值的测量可以认为是没有误差的,或者说误差可以忽略不计。
回归分析对于因变量有较多的要求,这些要求与其它的因素一起,构成了回归分析的基本条件:独立、线性、正态、等方差。
(三)数据要求模型中要求一个因变量,一个或多个自变量(一元时为 1 个自变量)。
一元线性回归模型案例分析一、研究的目的要求居民消费在社会经济的持续发展中有着重要的作用。
居民合理的消费模式和居民适度的消费规模有利于经济持续健康的增长,而且这也是人民生活水平的具体体现。
改革开放以来随着中国经济的快速发展,人民生活水平不断提高,居民的消费水平也不断增长。
但是在看到这个整体趋势的同时,还应看到全国各地区经济发展速度不同,居民消费水平也有明显差异。
例如,2002年全国城市居民家庭平均每人每年消费支出为6029.88元, 最低的黑龙江省仅为人均4462.08元,最高的上海市达人均10464元,上海是黑龙江的2.35倍。
为了研究全国居民消费水平及其变动的原因,需要作具体的分析。
影响各地区居民消费支出有明显差异的因素可能很多,例如,居民的收入水平、就业状况、零售物价指数、利率、居民财产、购物环境等等都可能对居民消费有影响。
为了分析什么是影响各地区居民消费支出有明显差异的最主要因素,并分析影响因素与消费水平的数量关系,可以建立相应的计量经济模型去研究。
二、模型设定我们研究的对象是各地区居民消费的差异。
居民消费可分为城市居民消费和农村居民消费,由于各地区的城市与农村人口比例及经济结构有较大差异,最具有直接对比可比性的是城市居民消费。
而且,由于各地区人口和经济总量不同,只能用“城市居民每人每年的平均消费支出”来比较,而这正是可从统计年鉴中获得数据的变量。
所以模型的被解释变量Y 选定为“城市居民每人每年的平均消费支出”。
因为研究的目的是各地区城市居民消费的差异,并不是城市居民消费在不同时间的变动,所以应选择同一时期各地区城市居民的消费支出来建立模型。
因此建立的是2002年截面数据模型。
影响各地区城市居民人均消费支出有明显差异的因素有多种,但从理论和经验分析,最主要的影响因素应是居民收入,其他因素虽然对居民消费也有影响,但有的不易取得数据,如“居民财产”和“购物环境”;有的与居民收入可能高度相关,如“就业状况”、“居民财产”;还有的因素在运用截面数据时在地区间的差异并不大,如“零售物价指数”、“利率”。
第十三讲 简单线性相关(一元线性回归分析)对于两个或更多变量之间的关系,相关分析考虑的只是变量之间是否相关、相关的程度,而回归分析关心的问题是:变量之间的因果关系如何。
回归分析是处理一个或多个自变量与因变量间线性因果关系的统计方法。
如婚姻状况与子女生育数量,相关分析可以求出两者的相关强度以及是否具有统计学意义,但不对谁决定谁作出预设,即可以相互解释,回归分析则必须预先假定谁是因谁是果,谁明确谁为因与谁为果的前提下展开进一步的分析。
一、一元线性回归模型及其对变量的要求 (一)一元线性回归模型 1、一元线性回归模型示例两个变量之间的真实关系一般可以用以下方程来表示: Y=A + BX + ε方程中的A 、B 是待定的常数,称为模型系数,ε是残差,是以X 预测Y 产生的误差。
两个变量之间拟合的直线是:y a bx ∧=+y ∧是 y 的拟合值或预测值,它是在X 条件下Y 条件均值的估计a 、b 是回归直线的系数,是总体真实直线A 、B 的估计值,a 即 constant 是截距,当自变量的值为0时,因变量的值。
b 称为回归系数,指在其他所有的因素不变时,每一单位自变量的变化引起的因变量的变化。
可以对回归方程进行标准化,得到标准回归方程:y x ∧=ββ 为标准回归系数,表示其他变量不变时,自变量变化一个标准差单位(Z X X S j jj=-),因变量Y 的标准差的平均变化。
由于标准化消除了原来自变量不同的测量单位,标准回归系数之间是可以比较的,绝对值的大小代表了对因变量作用的大小,反映自变量对Y的重要性。
(二)对变量的要求:回归分析的假定条件回归分析对变量的要求是:自变量可以是随机变量,也可以是非随机变量。
自变量X值的测量可以认为是没有误差的,或者说误差可以忽略不计。
回归分析对于因变量有较多的要求,这些要求与其它的因素一起,构成了回归分析的基本条件:独立、线性、正态、等方差。
(三)数据要求模型中要求一个因变量,一个或多个自变量(一元时为1个自变量)。
因变量:要求间距测度,即定距变量。
自变量:间距测度(或虚拟变量)。
二、在对话框中做一元线性回归模型例1:试用一元线性回归模型,分析大专及以上人口占6岁及以上人口的比例(edudazh)与人均国内生产总值(agdp)之间的关系。
本例使用的数据为st2004.sav,操作步骤及其解释如下:(一)对两个变量进行描述性分析在进行回归分析以前,一个比较好的习惯是看一下两个变量的均值、标准差、最大值、最小值和正态分布情况,观察数据的质量、缺少值和异常值等,缺少值和异常值经常对线性回归分析产生重要影响。
最简单的,我们可以先做出散点图,观察变量之间的趋势及其特征。
通过散点图,考察是否存在线性关系,如果不是,看是否通过变量处理使得能够进行回归分析。
如果进行了变量转换,那么应当重新绘制散点图,以确保在变量转换以后,线性趋势依然存在。
打开st2004.sav数据→单击Graphs → S catter →打开Scatterplot对话框→单击Simple →单击 Define →打开 Simple Scatterplot对话框→点选 agdp到 Y Axis框→点选 edudazh到 X Aaxis框内→单击 OK 按钮→在SPSS的Output窗口输出所需图形。
图12-1 大专及以上人口占6岁及以上人口比例与人均国内生产总值的散点图判断:线性趋势较明显。
(二)SPSS线性回归主对话框介绍打开线性回归主对话框的操作方法是:在st2004.sav数据界面上单击Analyze → Regression→Linear→打开Linear Regression主对话框图12-2 Linear Regression 命令位置图12-3 Linear Regression主对话框Linear Regression 主对话框的功能有:1、选择因变量Dependent框:放置因变量,一次只能放一个因变量。
本例点选agdp进入Dependent框。
2、选择自变量Independent框:放置自变量,可以放置多个自变量。
本例点选edudazh 进入Independent框。
3、对自变量进行分组Block按钮组:由Previous 和Next两个按钮组成,用来对自变量框中的自变量进行分组,在多元回归时会用到。
4、变量进入方式Method框:Enter:一元回归时,只选择这种方法,强行进入。
所有变量依次进入。
Stepwise:逐步回归,将所有满足条件的都进入方程,不满足的剔除。
Remove:强行移出法,这一方法必须在这一组自变量在前面一步已经纳入到回归时才用,否则没有可以剔除的。
Backward:自后消除法,将满足剔除标准的剔除Forward:向前加入法,所有满足进入回归方程的变量都可以进入。
在一元回归时,只用Enter即可。
本例选择变量进入的方式为Enter。
5、选择筛选变量Selection Variable框:选入一个筛选变量,并利用右侧的Rules建立条件,这样,只有满足这个条件的记录才会进入回归分析,当然,我们也可以用Data菜单中的Select Case过程来做,效果相同。
6、个案标签Case Labels 选择一个变量,其取值作为每条记录的标签,最典型的是使用记录ID个案号的变量。
7、加权最小二乘法计算WLS Weight框;利用该按钮可进行加权最小二乘法的计算。
选入权重变量进入该框即可。
使用条件:当应变量的变异程度具有某种趋势,即不是等方差时,通过加权,进行分析,是一种有偏估计。
8、选择统计量Statistics框:可以选择回归系数、残差诊断、模型拟合度等多种回归分析非常重要的统计量,在下文将详细介绍。
9、输出图形Plots框:可输出多种用于检验回归分析假定条件的图形,在下文将将详细介绍。
10、保存回归分析结果Save框:可以把回归分析的结果存起来,然后用得到的残差、预测值等做进一步的分析。
单击图12-3中的Save…按钮,打开Linear Regression的Save 对话框(见图12-4),研究者可以根据自己的需要进行选择。
图12-4 Linear Regression的Save对话框图12-4中:可以保持的回归分析结果主要有:Predicated values:各种预测值.#Unstandardized 保存模型对因变量的原始预测值.#Standardized:保存进行标准化后的预测值,均数0,方差1.#Adjusted:保存调整后的残差。
#S.E. #of mean predictions:保存预测值的标准差.Residuals:残差。
#Unstandardized :保存非标准化的残差,#Standardized:保存进行标准化后的残差#Studentlized:保存学生化残差#Deleted:它保存被排除进入相关系数计算的观察量的残差,是因变量与预测值之间的差值,通过它可以发现可疑的强影响点#Studentlized Deleted:对上一个预测值进行t变换Distances:用来测量数据点离拟合模型距离的指标#Mahalanobis:个案值离样本平均值的距离,如果某个个案多个自变量出现大的这种距离,可以认为它是离群值#Cook’s 表示去除这个个案后,模型的残差会发生多大的变化,一般认为如果这个值大于1,则有离群值或强影响点#Leverage values:用来测量数据点的影响强度,如中心杠杠值的变动范围是0―――(N-1)/NInfluence statistics:用来判断强影响点的统计量#DfBeta :Difference in Beta 去除某个观测值后回归系数的变化#standardized DfBeta 标准化的DfBeta 值,当它大于1/Sqrt(N)时,该点为强影响点,#DfFit. :Difference in fit value 去除这个观测值后预测值的变化值#Covariance ratio 去除这个观测值后,斜方差阵与包含全部观测值的斜方差阵的比率,如果绝对值大于3*P/N,这个观测值为强影响点或离群值。
11、置信水平和缺少值处理方式选择Options框:当自变量进入方式采取逐步回归时,打开Options对话框可以设定选择变量进入的和剔除的条件。
可以对缺少值的处理方式进行选择。
(三)回归分析统计量选择单击图12-3中的Statistics…按钮,打开一个Linear Regression的Statistics对话框(见图12-5),研究者可以根据自己的需要进行选择。
图12-5 Linear Regression的Statistics对话框1、回归系数及其基本含义图12-5中的Regression Coefficients,提供了关于回归系数的三种选项。
Estimates选项:点选后可输出回归方程中关于回归系数的基本情况,输出的数值有:B值、 Beta、 t值、t值的双尾检验。
来看例1关于“大专及以上人口占6岁及以上人口比例与人均国内生产总值”线性回归方程的回归系数(见表12-1)。
2、置信区间点选图12-5中的Confidence intervals ,可以求得回归系数的95%置信区间,在置信度95%时,置信区间为:b t s b t s j j j j -+αα/,/22式中s j 为样本标准差,j b 为回归系数。
来看例1关于“大专及以上人口占6岁及以上人口比例与人均国内生产总值”线性回归方程的回归系数(见表12-2)。
表13-2给出了回归系数B 的95%的置信区间,置信区间的下限为1593.071,上限为2849.639。
3、模型拟合度点选图12-5中的 Model Fit ,可以输出对模型拟合度进行评价的统计量。
模型拟合统计量主要有:R 、 RRsquare 、 R adj 。
这些值主要用来判断模型的拟合度或解释力怎么样。
表13-3和表13-4为“大专及以上人口占6岁及以上人口比例与人均国内生产总值”线性回归方程模型的拟合度统计量。
(1)相关系数 R表13-3中的相关系数R =0.802,反映了真实数据与回归直线靠近的程度,直接反映了一元线性回归或多元性回归预测效果的好坏程度。
(2)判定系数 R SquareR Square 也叫判定系数或确定系数(Coefficient of Determination ),它等于(总平方和- 余差平方和)/总平方和 总平方和(Total Sum of Square )的计算公式是; TSS= ()y y -∑2表示观察值围绕均值的情况,表示总的分散程度。
TSS 相当于PRE 中的E1,因为当不知道自变量 x 和因变量y 有关系时,对因变量的最好的估计就是因变量的均值,而每一个真实的因变量的观察值和因变量的均值的差,就构成了每次估计的误差。