第三章趋势面分析
- 格式:ppt
- 大小:1.92 MB
- 文档页数:61


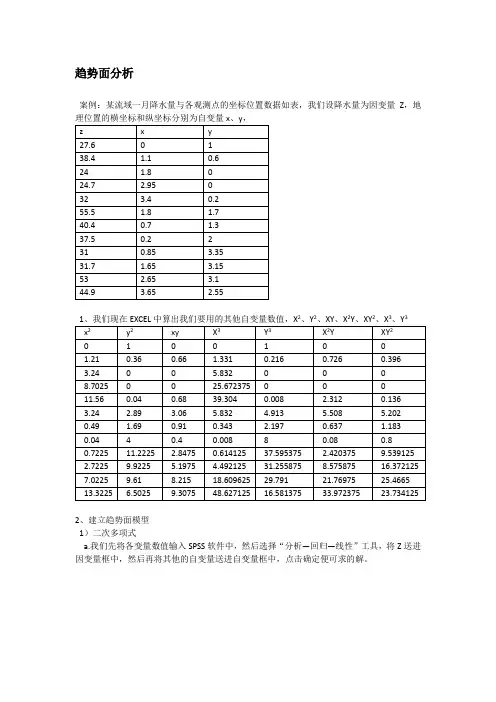
趋势面分析案例:某流域一月降水量与各观测点的坐标位置数据如表,我们设降水量为因变量Z,地2、Y2、XY、X22、X3、Y32、建立趋势面模型1)二次多项式a.我们先将各变量数值输入SPSS软件中,然后选择“分析—回归—线性”工具,将Z送进因变量框中,然后再将其他的自变量送进自变量框中,点击确定便可求的解。
b.运行结果如下图1图1中B列的数据为拟合方程的各系数,根据表中的数值及所对应的常量,我们求得的拟合方程为:Z=5.998+17.438X+29.787Y-3.588X2+0.357XY-8.070Y2图2图2显示该拟合二次趋势面的判定系数R2=0.839,显著性F=6.2322)三次多项式a.方法与二次多项式类似,将所有的变量输入SPSS,选择“分析—回归—线性”工具,将Z 送进因变量框中,然后再将其他的自变量送进自变量框中,点击确定便可求解。
b.运行结果如下图1图1中数列B的数据为拟合方程的各系数,根据表中的数值及所对应的常量,我们求得的拟合方程为:Z=-48.810+37.557X+130.130Y+8.389X2-33.166XY-62.740Y2-4.133X3+6.138X2Y+2.566XY2+9.785Y3图2图2显示,该拟合二次趋势面的判定系数R2=0.965,显著性F=6.0543、检验模型1)趋势面拟合适度检验。
根据两次拟合的输出结果表明,二次趋势面的判定系数为R2=0.839,三次趋势面的判定系数为R2=0.965,可见二者趋势面回归模型的显著性都较高(>0.8),且三次趋势面较二次趋势面具有更高的拟合程度(数值更大)。
2)趋势面适度的显著性检验。
根据两次拟合的输出结果表明,两者趋势面的F值分别为F2=6.236、和F3=6.054,在置信水平a=0.05下,查F分布表得F2a=F0.05(5,6)=4.53,F3a=F0.05(9,2)=19.4,我们得出F2>F2a F3 < F3a,因此我们判定用二次趋势面进行拟合比较合理。

一、趋势面分析法(2007-03-06 14:45:57)转载下面将就趋势面分析、克里金、形函数法三种算法作简单介绍,以后将进一步整理一些资料,介绍更多优秀的实用算法。
一、趋势面分析法趋势面分析法是针对大量离散点信息,从整体插值角度出发,来进行趋势渐变特征分析的最简单的方法。
趋势面分析一般是采取多项式进行回归分析。
趋势面通常应用多项式回归,主要是因为多项式回归的求解比较简单,通常可以得到显示的数学解答。
回归方法采用最小二乘法原理,其本质就是对回归函数在某个区间上的极值求取。
M阶N项多项式趋势面基本可以表示以下形式:要注意在上式中,是参变量,但不是每个参变量都是独立参变量。
在实际分析中,M一般取1,2,3。
一般来说来M不取超过3以上的高阶,主要基于两方面,一是高阶求解相对复杂,二是高级很难赋予物理意义。
N取多参变量在生产实践中是很常见的。
对于任何一组离散型数据,多项式趋势面到底取多少阶和多少个参变量,有一个临界限制:就是不管你取多少阶和多少个参变量,只要待求趋势面中的独立参变量总数小于或者等于已知离散控制点的数量就可以。
事实上,趋势面分析并不限制只取多项式趋势面,可以取任何函数构成的趋势面,如以下形式:上式为任意函数,为待求参变量。
在实际应用中,即使碰到了用一般多项式趋势面解决不了的拟合问题,往往也不采取以上方法,因为其求取复杂和费时。
通常做法是大致估算出其函数形式,将原始数据进行相应转换,然后再采取多项式趋势面方法来进行分析和求解。
在空间分析中,最简单的趋势面分析函数大致有以下一些类型。
1、空间趋势平面模型。
数学函数如下所示:2、简单二次曲面模型。
数学函数如下所示:或3、复杂二次曲面模型。
数学函数如下所示:所谓趋势面,顾名思义只是从趋势上来进行拟合,严格意义说它是平滑函数。
一般趋势面不经过原始数据点,除非趋势面中待求参变量的个数与已知离散控制点所确定的线性不相关方程组的个数相等。
趋势面分析中另一个重要特性就是揭示了分析区域中不同于总趋势的最大偏离部分。


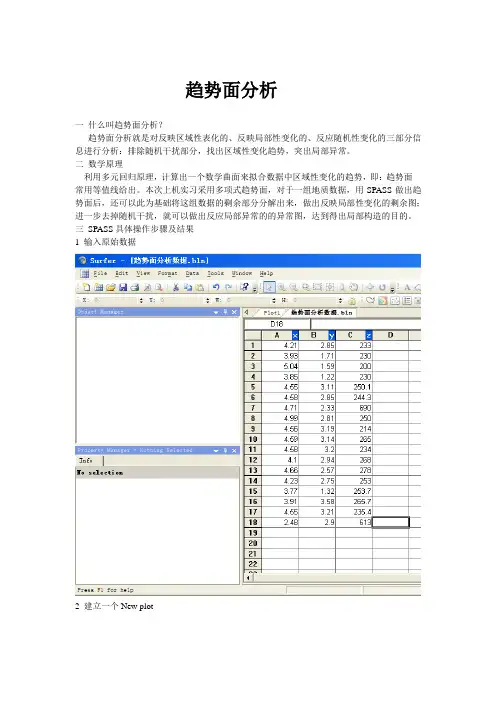
趋势面分析一什么叫趋势面分析?趋势面分析就是对反映区域性表化的、反映局部性变化的、反应随机性变化的三部分信息进行分析:排除随机干扰部分,找出区域性变化趋势,突出局部异常。
二数学原理利用多元回归原理,计算出一个数学曲面来拟合数据中区域性变化的趋势,即:趋势面---常用等值线给出。
本次上机实习采用多项式趋势面,对于一组地质数据,用SPASS做出趋势面后,还可以此为基础将这组数据的剩余部分分解出来,做出反映局部性变化的剩余图;进一步去掉随机干扰,就可以做出反应局部异常的的异常图,达到得出局部构造的目的。
三SPASS具体操作步骤及结果1 输入原始数据2 建立一个New plot然后在Plot界面用Grid打开之前建立的数据(可以修改各种参数设定)之后得到一个grid格式的数据和一个分析报告,下一步使用,进行趋势面绘制,用Map工具打开该数据Active Data: 18Univariate Statistics————————————————————————————————————————————X Y Z ————————————————————————————————————————————Count: 18 18 181%%-tile: 2.48 1.22 2005%%-tile: 2.48 1.22 20010%%-tile: 3.77 1.32 21425%%-tile: 3.93 2.33 23350%%-tile: 4.55 2.85 25075%%-tile: 4.58 3.11 26590%%-tile: 4.71 3.2 27895%%-tile: 4.99 3.21 61399%%-tile: 4.99 3.21 613Minimum: 2.48 1.22 200 Maximum: 5.04 3.58 690Mean: 4.29388888889 2.62611111111 289.288888889 Median: 4.55 2.85 250.05 Geometric Mean: 4.24766170066 2.51385012227 271.255793835 Harmonic Mean: 4.19054009746 2.37707222857 260.43837365 Root Mean Square: 4.33183756236 2.71356980951 317.188853664 Trim Mean (10%%): N/A N/A N/A Interquartile Mean: 4.36555555556 2.79 246.5 Midrange: 3.76 2.4 445 Winsorized Mean: 4.33166666667 2.61 248.566666667 TriMean: 4.4025 2.785 249.5Variance: 0.346589869281 0.494472222222 17916.0433987 Standard Deviation: 0.588718837206 0.703187188608 133.85082517 Interquartile Range: 0.65 0.78 32Range: 2.56 2.36 490Mean Difference: 0.610392156863 0.771045751634 104.483660131 Median Abs. Deviation: 0.33 0.315 16.55Average Abs. Deviation: 0.401666666667 0.498333333333 59.2111111111 Quartile Dispersion: 0.0763807285546 0.1433823529410.0642570281124Relative Mean Diff.: 0.142153691597 0.293607436628 0.3611741209Standard Error: 0.138762360667 0.165742809836 31.5489420484 Coef. of Variation: 0.137106211278 0.267767493018 0.462689132943 Skewness: -1.44662719199 -0.822714806649 2.2207762572 Kurtosis: 5.36832306757 2.26851523564 6.39084247191Sum: 77.29 47.27 5207.2Sum Absolute: 77.29 47.27 5207.2Sum Squares: 337.7667 132.5423 1810957.84 Mean Square: 18.7648166667 7.36346111111 100608.768889 ————————————————————————————————————————————Inter-Variable Covariance————————————————————————————————X Y Z ————————————————————————————————X: 0.34658987 0.041551307 -30.09019Y: 0.041551307 0.49447222 2.7437778Z: -30.09019 2.7437778 17916.043 ————————————————————————————————Inter-Variable Correlation————————————————————————————————X Y Z ————————————————————————————————X: 1.000 0.100 -0.382Y: 0.100 1.000 0.029Z: -0.382 0.029 1.000 ————————————————————————————————Inter-Variable Rank Correlation————————————————————————————————X Y Z ————————————————————————————————X: 1.000 0.010 -0.097Y: 0.010 1.000 0.113Z: -0.097 0.113 1.000 ————————————————————————————————Principal Component Analysis————————————————————————————————————————PC1 PC2 PC3 ————————————————————————————————————————X: 0.216419756651 0.216419756651 0.976298964503Y: 0.976300385716 0.976300385716 -0.216419808238Z: 0.000213968453371 0.000213968453371 -0.216419808238Lambda: 17916.0943565 0.504284372067 0.285819896505 ————————————————————————————————————————Planar Regression: Z = AX+BY+CFitted Parameters ————————————————————————————————————————A B C ————————————————————————————————————————Parameter Value: -88.3733860188 12.9750614884 634.680436047 Standard Error: 54.3839287184 45.5310389559 253.339971028 ————————————————————————————————————————Inter-Parameter Correlations ————————————————————————————A B C ————————————————————————————A: 1.000 -0.100 -0.874B: -0.100 1.000 -0.379C: -0.874 -0.379 1.000 ————————————————————————————ANOVA Table ————————————————————————————————————————————————————Source df Sum of Squares Mean Square F ————————————————————————————————————————————————————Regression: 2 45811.1345603 22905.56728021.32779942978Residual: 15 258761.603217 17250.7735478Total: 17 304572.737778 ————————————————————————————————————————————————————Coefficient of Multiple Determination (R^2): 0.150411146101 Nearest Neighbor Statistics—————————————————————————————————Separation |Delta Z| —————————————————————————————————1%%-tile: 0.022********* 2.35%%-tile: 0.022********* 2.310%%-tile: 0.022********* 5.825%%-tile: 0.05 2050%%-tile: 0.128062484749 21.475%%-tile: 0.261725046566 2890%%-tile: 0.667607669219 41295%%-tile: 0.810246875958 41299%%-tile: 0.810246875958 412Minimum: 0.022********* 2.3Maximum: 1.58344561005 490Mean: 0.300678589751 107.561111111 Median: 0.135094594392 22.55Geometric Mean: 0.150505839521 34.1962482825 Harmonic Mean: 0.0760795138321 15.183145853Root Mean Square: 0.484349506498 198.11587939Trim Mean (10%%): N/A N/AInterquartile Mean: 0.156027058614 22.4333333333 Midrange: 0.802903144915 246.15Winsorized Mean: 0.241874303774 103.422222222 TriMean: 0.141962504016 22.7Variance: 0.152668408352 29308.774281 Standard Deviation: 0.390728049098 171.198055716 Interquartile Range: 0.211725046566 8Range: 1.56108493028 487.7Mean Difference: 0.367671560345 153.080392157 Median Abs. Deviation: 0.111396166834 6.55Average Abs. Deviation: 0.230993279821 91.9277777778 Quartile Dispersion: 0.6792044749 0.166666666667 Relative Mean Diff.: 1.2228059226 1.42319459678Standard Error: 0.0920954843723 40.3517687077 Coef. of Variation: 1.29948743415 1.59163524761 Skewness: 2.020******** 1.28865622044 Kurtosis: 6.73356292285 2.76519475547Sum: 5.41221461551 1936.1Sum Absolute: 5.41221461551 1936.1Sum Squares: 4.2227 706498.23Mean Square: 0.234594444444 39249.9016667 —————————————————————————————————Complete Spatial RandomnessLambda: 2.97934322034Clark and Evans: 1.0379*******Skellam: 79.0479539757Gridding RulesGridding Method: KrigingKriging Type: PointPolynomial Drift Order: 0Kriging std. deviation grid: noSemi-Variogram ModelComponent Type: LinearAnisotropy Angle: 0Anisotropy Ratio: 1Variogram Slope: 1Search ParametersNo Search (use all data): trueOutput GridGrid File Name: C:\Documents and Settings\Administrator\桌面\趋势面分析数据.grdGrid Size: 92 rows x 100 columnsTotal Nodes: 9200Filled Nodes: 9200Blanked Nodes: 0Blank Value: 1.70141E+038Grid GeometryX Minimum: 3.22X Maximum: 4.95X Spacing: 0.017474747474747Y Minimum: 1.66Y Maximum: 2.49Y Spacing: 0.0091208791208791Univariate Grid Statistics——————————————————————————————Z ——————————————————————————————Count: 92001%%-tile: 243.6708247515%%-tile: 270.52537986610%%-tile: 289.3649401625%%-tile: 320.7816334150%%-tile: 346.69170079275%%-tile: 403.41375589490%%-tile: 501.89518357495%%-tile: 550.0838342899%%-tile: 623.854749712Minimum: 231.02350996Maximum: 684.239353028Mean: 371.755313657Median: 346.697198378Geometric Mean: 363.519621072Harmonic Mean: 356.180238449Root Mean Square: 380.919972359Trim Mean (10%%): 365.903516549Interquartile Mean: 351.617078065Midrange: 457.631431494Winsorized Mean: 368.205042418TriMean: 354.394697722Variance: 6898.76197525Standard Deviation: 83.0587862616Interquartile Range: 82.6321224834Range: 453.215843068Mean Difference: 87.9557978576Median Abs. Deviation: 36.2856362208Average Abs. Deviation: 59.6216971292Quartile Dispersion: 0.114101972622Relative Mean Diff.: 0.236595939927Standard Error: 0.865947707481Coef. of Variation: 0.223423265816Skewness: 1.19083933754Kurtosis: 4.0676520973Sum: 3420148.88565Sum Absolute: 3420148.88565Sum Squares: 1334920233.15Mean Square: 145100.025342 ——————————————————————————————然后得到趋势面:然后加上颜色表示地下:还可以重点突出某一小区域的构造,改变参数即可; 两趋势面的对比如下:然后做出三维模型:这就是局部构造。

空间分析方法总结1. 引言空间分析是地理信息系统(GIS)中一个重要的研究领域,它主要关注地理现象在空间环境中的关联性和分布规律。
通过空间分析方法,可以揭示地理现象之间的关系、预测未来趋势、辅助决策等。
本文将对几种常用的空间分析方法进行总结和介绍。
2. 点线面分析方法2.1 缓冲区分析缓冲区分析是一种常用的空间分析方法,它用于确定一个点、线或面周围的固定距离范围内的地理特征。
缓冲区分析在城市规划、环境保护等方面具有广泛的应用。
在缓冲区分析中,可以通过设定不同的缓冲区半径来探索不同区域的影响范围。
2.2 点聚类分析点聚类分析用于识别地理空间上的热点区域。
它通过计算点的密度和邻近性来确定热点区域。
点聚类分析能够帮助分析人员确定人口聚集区、犯罪高发区等地理现象的空间分布规律。
2.3 空间插值分析空间插值分析用于推测地理现象在未知位置的数值。
它通过已知点的观测值来估计未知点的属性值。
空间插值分析广泛应用于地质勘探、气象预测等领域。
3. 空间关联分析方法3.1 空间自相关分析空间自相关分析用于衡量地理现象之间的相似性和关联性。
它通过计算各个地理单元的值与周围地理单元值的相似程度,来评估地理现象的空间分布特征。
3.2 空间回归分析空间回归分析用于了解地理现象之间的因果关系。
它考虑了地理空间的特殊关系,并利用空间邻近性和空间自相关等因素来拟合回归模型。
3.3 趋势面分析趋势面分析用于揭示地理现象随着空间变化的趋势。
通过分析地理现象的空间分布趋势,可以预测未来的发展趋势和变化。
4. 空间数据挖掘方法4.1 空间聚类分析空间聚类分析用于发现地理空间中的聚类模式。
它通过计算地理特征之间的相似度,将地理特征划分为具有相似特征的群组。
4.2 空间关联规则挖掘空间关联规则挖掘用于发现地理空间中的关联规则。
它通过挖掘地理特征之间的关联关系,找出具有共同特征的地理空间中的模式和规律。
5. 总结空间分析是地理信息系统中的一项重要工作,它通过运用各种空间分析方法,帮助我们揭示地理现象的分布特征、关联关系和趋势变化。

35第三章空间平滑和空间插值本章介绍基于GIS的空间分析中两个常用操作:空间平滑和空间插值。
空间平滑和空间插值关系密切,它们都可以用于显示空间分布态式及空间分布趋势,二者还共享某些算法(如核密度估计法Find/Replace All)。
空间平滑和空间插值的方法有很多种,本章只介绍其中最常用的几种。
空间平滑与移动平均在概念上类似(移动平均是求一个时间段内的均值),而空间平滑术是一个空间窗口内计算平均值。
第 3.1节介绍空间平滑的概念和方法,第 3.2节是案例分析3A,用空间平滑法研究中国南方/泰语地名(Find/Replace all)分布。
空间插值是用某些点的已知数值来估算其他点的未知数值。
第3.3节介绍了基于点的空间插值,第3.4节为案例3B,演示了一些常用的点插值法。
案例3B所用数据与3A相同,是案例3A工作的延伸。
第3.5节介绍基于面的空间插值,用一套面域数值(一般面单元较小)来估算另一个面域的数值(范围较大)。
面插值可用于数据融合以及不同面域单元的数据整合。
第 3.6节为案例3C,介绍两种简单的面插值法。
第3.7节为小结。
3.1空间平滑与移动平均法计算一个时间段的平均值(例如:五日平均温度)相似,空间平滑是将某点周围地区(定义为一个空间窗口)的平均值作为该点的平滑值,以此减少空间变异。
空间平滑适用面很广。
其中一种应用是处理小样本问题,我们在第八章会详细讨论。
对于那些人口较少的地区,由于小样本事件中随机误差的影响,癌症或谋杀等稀有事件发生率的估算不够可靠。
对于某些地区,这样的事情发生一次就可导致一个高发生率,而对于另外许多地区,没有发生这种事情的结果是零发生率。
另外一种应用是将离散的点数据转化为连续的密度图,从而考察点数据的空间分布模式,可参见下面的第3.2节。
本节介绍两种空间平滑方法(移动搜索法及核密度估计法),附录3介绍经验贝叶斯估计。
3.1.1移动搜索法移动搜索法(FCA)是以某点为中心画一个圆或正方形作为滤波窗口,用窗口内的平均值(或数值密度)作为该点的值。


断裂的趋势面分析
断裂的趋势面分析是地质学中的一种方法,用于研究地球上的断裂构造及其运动趋势。
断裂是地壳中的断裂面,由于地壳内部的应力作用导致岩石断裂并产生滑动。
断裂构造在地质学中具有重要意义,它们是地球壳运动和板块构造的重要表现形式,也是许多地质灾害的主要原因,如地震、地面变形等。
趋势面是指断裂面上垂直的面,在地质学中一般用倾角和倾向来描述。
断裂的趋势面分析包括以下几个方面:
1. 断裂的识别和测量:通过野外地质调查和测量,识别出断裂构造并测定其趋势面的倾角和倾向。
2. 断裂的分类和分析:根据断裂面的特征和运动方式,将断裂分为不同的类型,如正断裂、逆断裂、走滑断裂等。
通过分析不同类型的断裂,可以揭示地球内部的应力状态和构造演化过程。
3. 断裂与地质事件的关系:通过研究断裂与其他地质事件(如岩浆喷发、沉积物堆积等)的空间关系,可以推断断裂的形成时期和地壳变形的历史。
4. 断裂的运动趋势分析:根据断裂面的倾角和倾向,结合地质地球物理数据,
推断断裂的运动方式和方向,以及地震活动的可能性。
断裂的趋势面分析是地质学研究中的重要内容,可以帮助我们理解地壳的运动和演化过程,为地质灾害的预测和防治提供科学依据。
区域降水量的趋势面模拟1.趋势面分析基本原理与方法1.1趋势面分析原理趋势面分析,是利用数学曲面模拟地理系统要素在空间上的分布及变化趋势的一种数学方法。
它实质上是通过回归分析原理,运用最小二乘法拟合一个二维非线性函数,模拟地理要素在空间上的分布规律,展示地理要素在地域空间上的变化趋势。
趋势面分析的观测面由趋势面部分和残差部分组成。
趋势面部分反映区域性大范围内的变化情况,残差部分是实测值与趋势函数对应值之差,反映局部变化情况,二者结合其就有助于深入分析。
趋势面分析的一个基本要求,就是所选择的趋势面模型应该是剩余值最小,而趋势值最大,这样拟合度精度才能达到足够的准确性。
空间趋势面分析,正是从地理要素分布的实际数据中分解出趋势值和剩余值,从而揭示地理要素空间分布的趋势与规律。
对于变化较缓和的资料,可用低次数的趋势面进行分析;而对于变化复杂、起伏较多的资料,可用多项式阶次高些的趋势面;1.2趋势面模型的建立本例将降雨量(,)(1,2,...,)i i i z x y i n =作为因变量,地理位置坐标(,)i i x y 作为自变量,趋势拟合值为(,)i i iz x y ,则有: (,)(,)i i i i i iz x y z x y ε=+ (1) 趋势面分析的核心:从实际观测值出发推算趋势面,一般采用回归分析方法,使得残差平方和趋于最小,即:(2)2211[(,)(,)]min n ni i i i i ii i Q z x y z x y ε====-→∑∑这就是在最小二乘法意义下的趋势面拟合。
1.3趋势面模型的适度检验21R R T TSS SSR SS SS ==- (3) 其中,21()ni D ii SS z z==-∑21()ni R i SS zz ==-∑ 2211()()nni i T i D R i i SS z z z z SS SS ===-+-=+∑∑式中:SS D 为剩余平方和,它表示随机因素对z 的离差的影响;SS R 为回归平方和,它表示p 个自变量对因变量z 的离差的总影响。