C语言 顺序查找和折半查找
- 格式:docx
- 大小:14.91 KB
- 文档页数:3
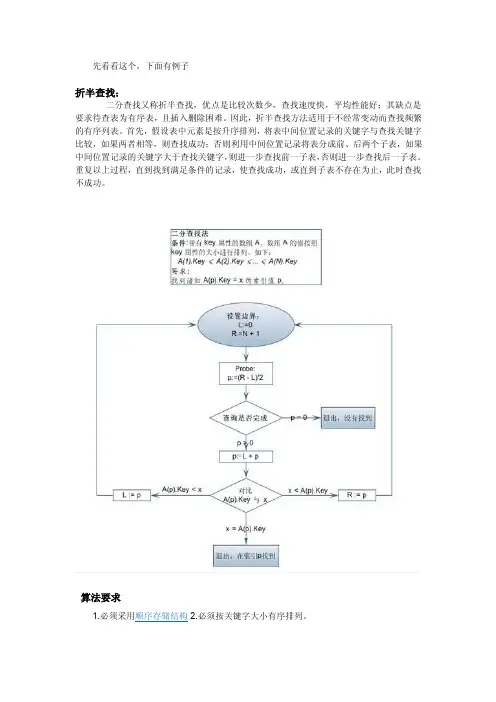
先看看这个,下面有例子折半查找:二分查找又称折半查找,优点是比较次数少,查找速度快,平均性能好;其缺点是要求待查表为有序表,且插入删除困难。
因此,折半查找方法适用于不经常变动而查找频繁的有序列表。
首先,假设表中元素是按升序排列,将表中间位置记录的关键字与查找关键字比较,如果两者相等,则查找成功;否则利用中间位置记录将表分成前、后两个子表,如果中间位置记录的关键字大于查找关键字,则进一步查找前一子表,否则进一步查找后一子表。
重复以上过程,直到找到满足条件的记录,使查找成功,或直到子表不存在为止,此时查找不成功。
算法要求算法复杂度下面提供一段二分查找实现的伪代码:BinarySearch(max,min,des)mid-<(max+min)/2while(min<=max)mid=(min+max)/2if mid=des thenreturn midelseif mid >des thenmax=mid-1elsemin=mid+1return max折半查找法也称为二分查找法,它充分利用了元素间的次序关系,采用分治策略,可在最坏的情况下用O(log n)完成搜索任务。
它的基本思想是,将n个元素分成个数大致相同的两半,取a[n/2]与欲查找的x作比较,如果x=a[n/2]则找到x,算法终止。
如果x<a[n/2],则我们只要在数组a的左半部继续搜索x(这里假设数组元素呈升序排列)。
如果x>a[n/2],则我们只要在数组a的右半部继续搜索x。
二分查找法一般都存在一个临界值的BUG,即查找不到最后一个或第一个值。
可以在比较到最后两个数时,再次判断到底是哪个值和查找的值相等。
C语言代码int BinSearch(SeqList * R,int n , KeyType K ){ //在有序表R[0..n-1]中进行二分查找,成功时返回结点的位置,失败时返回-1int low=0,high=n-1,mid;//置当前查找区间上、下界的初值if(R[low].key==K){return low ;}if(R[high].key==k)return high;while(low<=high){ //当前查找区间R[low..high]非空mid=low+((high-low)/2);//使用(low + high) / 2 会有整数溢出的问题(问题会出现在当low + high的结果大于表达式结果类型所能表示的最大值时,这样,产生溢出后再/2是不会产生正确结果的,而low+((high-low)/2)不存在这个问题if(R[mid].key==K){return mid;//查找成功返回}if(R[mid].key>K)high=mid-1; //继续在R[low..mid-1]中查找elselow=mid+1;//继续在R[mid+1..high]中查找}if(low>high)return -1;//当low>high时表示查找区间为空,查找失败} //BinSeareh折半查找程序举例程序要求:1.在main函数中定义一个20个元素的int数组,完成初始化和显示操作。

c语言查找算法
C语言是一种广泛使用的编程语言,它具有高效、简单、易学等特点,因此在各个领域都有广泛的应用。
在C语言中,查找算法是一种非常
重要的算法,它可以帮助我们在大量数据中快速查找到我们需要的数据。
下面我们将详细介绍C语言中的查找算法。
一、顺序查找算法
顺序查找算法是一种最简单的查找算法,它的基本思想是从数据的第
一个元素开始逐个比较,直到找到目标元素或者遍历完整个数据。
顺
序查找算法的时间复杂度为O(n),其中n为数据的长度。
二、二分查找算法
二分查找算法也称为折半查找算法,它的基本思想是将数据分成两部分,然后判断目标元素在哪一部分中,再在该部分中继续进行查找,
直到找到目标元素或者确定目标元素不存在。
二分查找算法的时间复
杂度为O(logn),其中n为数据的长度。
三、哈希查找算法
哈希查找算法是一种利用哈希表进行查找的算法,它的基本思想是将数据通过哈希函数映射到哈希表中,然后在哈希表中查找目标元素。
哈希查找算法的时间复杂度为O(1),但是它需要额外的空间来存储哈希表。
四、树查找算法
树查找算法是一种利用树结构进行查找的算法,它的基本思想是将数据构建成一棵树,然后在树中查找目标元素。
树查找算法的时间复杂度为O(logn),但是它需要额外的空间来存储树结构。
总结:
C语言中的查找算法有顺序查找算法、二分查找算法、哈希查找算法和树查找算法。
不同的算法适用于不同的场景,我们可以根据实际情况选择合适的算法来进行查找。
在实际应用中,我们还可以将不同的算法进行组合,以达到更高效的查找效果。


一、基本算法1.交换(两量交换借助第三者)例1、任意读入两个整数,将二者的值交换后输出。
main(){int a,b,t;scanf("%d%d",&a,&b);printf("%d,%d\n",a,b);t=a; a=b; b=t;printf("%d,%d\n",a,b);}【解析】程序中加粗部分为算法的核心,如同交换两个杯子里的饮料,必须借助第三个空杯子。
假设输入的值分别为3、7,则第一行输出为3,7;第二行输出为7,3。
其中t为中间变量,起到“空杯子”的作用。
注意:三句赋值语句赋值号左右的各量之间的关系!【应用】例2、任意读入三个整数,然后按从小到大的顺序输出。
main(){int a,b,c,t;scanf("%d%d%d",&a,&b,&c);/*以下两个if语句使得a中存放的数最小*/if(a>b){ t=a; a=b; b=t; }if(a>c){ t=a; a=c; c=t; }/*以下if语句使得b中存放的数次小*/if(b>c) { t=b; b=c; c=t; }printf("%d,%d,%d\n",a,b,c);}2.累加累加算法的要领是形如“s=s+A”的累加式,此式必须出现在循环中才能被反复执行,从而实现累加功能。
“A”通常是有规律变化的表达式,s在进入循环前必须获得合适的初值,通常为0。
例1、求1+2+3+……+100的和。
main(){int i,s;s=0; i=1;while(i<=100){s=s+i; /*累加式*/i=i+1; /*特殊的累加式*/}printf("1+2+3+...+100=%d\n",s);}【解析】程序中加粗部分为累加式的典型形式,赋值号左右都出现的变量称为累加器,其中“i = i + 1”为特殊的累加式,每次累加的值为1,这样的累加器又称为计数器。

c语言折中查找法折中查找法(也称为二分查找法)是一种在有序数组中查找特定元素的搜索算法。
搜索过程从数组的中间元素开始,如果中间元素正好是目标值,则搜索过程结束;如果目标值大于或小于中间元素,则在数组大于或小于中间元素的那一半中查找,而且同样从中间元素开始比较。
如果在某一步骤数组为空,则代表找不到。
这种搜索算法每一次比较都使搜索范围缩小一半。
以下是一个用C语言实现的折中查找法:c复制代码#include<stdio.h>int binarySearch(int arr[], int l, int r, int x){if (r >= l) {int mid = l + (r - l) / 2;if (arr[mid] == x)return mid;if (arr[mid] > x)return binarySearch(arr, l, mid - 1, x); return binarySearch(arr, mid + 1, r, x); }return-1;}int main(void){int arr[] = {2, 3, 4, 10, 40};int n = sizeof(arr) / sizeof(arr[0]);int x = 10;int result = binarySearch(arr, 0, n - 1, x);(result == -1) ? printf("Element is not present in array"): printf("Element is present at index %d", result);return0;}这个程序首先定义了一个数组arr[],然后使用binarySearch()函数查找特定的元素x。
如果x在数组中,函数将返回其索引;否则,返回-1。

实验五查找的应用一、实验目的:1、掌握各种查找方法及适用场合,并能在解决实际问题时灵活应用。
2、增强上机编程调试能力。
二、问题描述1.分别利用顺序查找和折半查找方法完成查找。
有序表(3,4,5,7,24,30,42,54,63,72,87,95)输入示例:请输入查找元素:52输出示例:顺序查找:第一次比较元素95第二次比较元素87 ……..查找成功,i=**/查找失败折半查找:第一次比较元素30第二次比较元素63 …..2.利用序列(12,7,17,11,16,2,13,9,21,4)建立二叉排序树,并完成指定元素的查询。
输入输出示例同题1的要求。
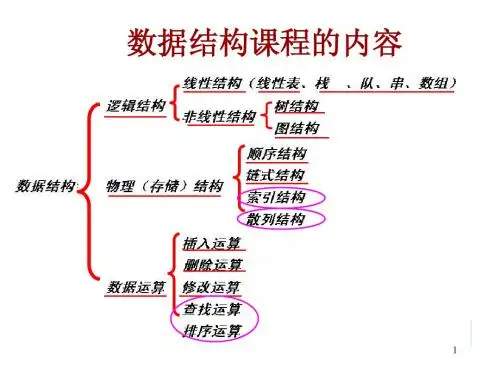
三、数据结构设计(选用的数据逻辑结构和存储结构实现形式说明)(1)逻辑结构设计顺序查找和折半查找采用线性表的结构,二叉排序树的查找则是建立一棵二叉树,采用的非线性逻辑结构。
(2)存储结构设计采用顺序存储的结构,开辟一块空间用于存放元素。
(3)存储结构形式说明分别建立查找关键字,顺序表数据和二叉树数据的结构体进行存储数据四、算法设计(1)算法列表(说明各个函数的名称,作用,完成什么操作)序号 名称 函数表示符 操作说明1 顺序查找 Search_Seq 在顺序表中顺序查找关键字的数据元素2 折半查找 Search_Bin 在顺序表中折半查找关键字的数据元素3 初始化 Init 对顺序表进行初始化,并输入元素4 树初始化 CreateBST 创建一棵二叉排序树5 插入 InsertBST 将输入元素插入到二叉排序树中6 查找 SearchBST在根指针所指二叉排序树中递归查找关键字数据元素 (2)各函数间调用关系(画出函数之间调用关系)typedef struct { ElemType *R; int length;}SSTable;typedef struct BSTNode{Elem data; //结点数据域 BSTNode *lchild,*rchild; //左右孩子指针}BSTNode,*BSTree; typedef struct Elem{ int key; }Elem;typedef struct {int key;//关键字域}ElemType;(3)算法描述int Search_Seq(SSTable ST, int key){//在顺序表ST中顺序查找其关键字等于key的数据元素。

《数据结构(C语言版第2版)》(严蔚敏著)第七章练习题答案第7章查找1.选择题(1)对n个元素的表做顺序查找时,若查找每个元素的概率相同,则平均查找长度为()。
A.(n-1)/2B.n/2C.(n+1)/2D.n答案:C解释:总查找次数N=1+2+3+…+n=n(n+1)/2,则平均查找长度为N/n=(n+1)/2。
(2)适用于折半查找的表的存储方式及元素排列要求为()。
A.链接方式存储,元素无序B.链接方式存储,元素有序C.顺序方式存储,元素无序D.顺序方式存储,元素有序答案:D解释:折半查找要求线性表必须采用顺序存储结构,而且表中元素按关键字有序排列。
(3)如果要求一个线性表既能较快的查找,又能适应动态变化的要求,最好采用()查找法。
A.顺序查找B.折半查找C.分块查找D.哈希查找答案:C解释:分块查找的优点是:在表中插入和删除数据元素时,只要找到该元素对应的块,就可以在该块内进行插入和删除运算。
由于块内是无序的,故插入和删除比较容易,无需进行大量移动。
如果线性表既要快速查找又经常动态变化,则可采用分块查找。
(4)折半查找有序表(4,6,10,12,20,30,50,70,88,100)。
若查找表中元素58,则它将依次与表中()比较大小,查找结果是失败。
A.20,70,30,50B.30,88,70,50C.20,50D.30,88,50答案:A解释:表中共10个元素,第一次取⎣(1+10)/2⎦=5,与第五个元素20比较,58大于20,再取⎣(6+10)/2⎦=8,与第八个元素70比较,依次类推再与30、50比较,最终查找失败。
(5)对22个记录的有序表作折半查找,当查找失败时,至少需要比较()次关键字。
A.3B.4C.5D.6答案:B解释:22个记录的有序表,其折半查找的判定树深度为⎣log222⎦+1=5,且该判定树不是满二叉树,即查找失败时至多比较5次,至少比较4次。
(6)折半搜索与二叉排序树的时间性能()。


数据结构(C语言版)9-12章练习答案清华大学出版社9-12章数据结构作业答案第九章查找选择题1、对n个元素的表做顺序查找时,若查找每个元素的概率相同,则平均查找长度为( A )A.(n+1)/2 B. n/2 C. n D. [(1+n)*n ]/2 2. 下面关于二分查找的叙述正确的是 ( D )A. 表必须有序,表可以顺序方式存储,也可以链表方式存储B. 表必须有序且表中数据必须是整型,实型或字符型 C. 表必须有序,而且只能从小到大排列 D. 表必须有序,且表只能以顺序方式存储3. 二叉查找树的查找效率与二叉树的( (1)C)有关, 在 ((2)C )时其查找效率最低 (1): A. 高度 B. 结点的多少 C. 树型 D. 结点的位置(2): A. 结点太多 B. 完全二叉树 C. 呈单枝树 D. 结点太复杂。
4. 若采用链地址法构造散列表,散列函数为H(key)=key MOD 17,则需 ((1)A)个链表。
这些链的链首指针构成一个指针数组,数组的下标范围为 ((2)C) (1) A.17 B. 13 C. 16 D. 任意(2) A.0至17 B. 1至17 C. 0至16 D. 1至16判断题1.Hash表的平均查找长度与处理冲突的方法无关。
(错) 2. 若散列表的负载因子α<1,则可避免碰撞的产生。
(错)3. 就平均查找长度而言,分块查找最小,折半查找次之,顺序查找最大。
(错)填空题1. 在顺序表(8,11,15,19,25,26,30,33,42,48,50)中,用二分(折半)法查找关键码值20,需做的关键码比较次数为 4 .算法应用题1. 设有一组关键字{9,01,23,14,55,20,84,27},采用哈希函数:H(key)=key mod7 ,表长为10,用开放地址法的二次探测再散列方法Hi=(H(key)+di) mod 10解决冲突。
要求:对该关键字序列构造哈希表,并计算查找成功的平均查找长度。

C语言中的搜索算法详解搜索算法在计算机科学中起着重要的作用,它们可以帮助我们在大量数据中迅速找到目标元素。
在C语言中,有多种搜索算法可供选择。
本文将深入探讨一些常用的搜索算法,包括线性搜索、二分搜索和哈希表搜索。
一、线性搜索线性搜索是最简单的搜索算法之一,也被称为顺序搜索。
它逐个比较列表中的元素,直到找到目标元素或搜索完整个列表。
这种算法适用于无序列表,并且其时间复杂度为O(n),其中n为列表的长度。
在C语言中,我们可以使用for循环来实现线性搜索算法。
下面是一个示例代码:```c#include <stdio.h>int linear_search(int arr[], int n, int target) {for(int i = 0; i < n; i++) {if(arr[i] == target) {return i;}}return -1;}int main() {int arr[] = {1, 2, 3, 4, 5};int n = sizeof(arr) / sizeof(arr[0]);int target = 3;int result = linear_search(arr, n, target);if(result != -1) {printf("目标元素在列表中的索引为:%d\n", result);} else {printf("目标元素不在列表中。
\n");}return 0;}```二、二分搜索二分搜索是一种更有效的搜索算法,前提是列表已经按照升序或降序排列。
它通过将目标元素与列表的中间元素进行比较,并根据比较结果将搜索范围缩小一半。
这种算法的时间复杂度为O(logn),其中n 为列表的长度。
在C语言中,我们可以使用递归或迭代的方式实现二分搜索算法。
下面是一个使用迭代方式实现的示例代码:```c#include <stdio.h>int binary_search(int arr[], int low, int high, int target) {while(low <= high) {int mid = (low + high) / 2;if(arr[mid] == target) {return mid;} else if(arr[mid] < target) {low = mid + 1;} else {high = mid - 1;}}return -1;}int main() {int arr[] = {1, 2, 3, 4, 5};int n = sizeof(arr) / sizeof(arr[0]);int target = 3;int result = binary_search(arr, 0, n - 1, target);if(result != -1) {printf("目标元素在列表中的索引为:%d\n", result);} else {printf("目标元素不在列表中。
算法设计与分析各种查找算法的性能测试目录摘要 (2)第一章:简介(Introduction) (3)1.1 算法背景 (3)第二章:算法定义(Algorithm Specification) (4)2.1 数据结构 (4)2.2顺序查找法的伪代码 (4)2.3 二分查找(递归)法的伪代码 (5)2.4 二分查找(非递归)法的伪代码 (6)第三章:测试结果(Testing Results) (8)3.1 测试案例表 (8)3.2 散点图 (9)第四章:分析和讨论 (11)4.1 顺序查找 (11)4.1.1 基本原理 (11)4.2.2 时间复杂度分析 (11)4.2.3优缺点 (11)4.2.4该进的方法 (12)4.2 二分查找(递归与非递归) (12)4.2.1 基本原理 (12)4.2.2 时间复杂度分析 (13)4.2.3优缺点 (13)4.2.4 改进的方法 (13)附录:源代码(基于C语言的) (15)摘要在计算机许多应用领域中,查找操作都是十分重要的研究技术。
查找效率的好坏直接影响应用软件的性能,而查找算法又分静态查找和动态查找。
我们设置待查找表的元素为整数,用不同的测试数据做测试比较,长度取固定的三种,对象由随机数生成,无需人工干预来选择或者输入数据。
比较的指标为关键字的查找次数。
经过比较可以看到,当规模不断增加时,各种算法之间的差别是很大的。
这三种查找方法中,顺序查找是一次从序列开始从头到尾逐个检查,是最简单的查找方法,但比较次数最多,虽说二分查找的效率比顺序查找高,但二分查找只适用于有序表,且限于顺序存储结构。
关键字:顺序查找、二分查找(递归与非递归)第一章:简介(Introduction)1.1 算法背景查找问题就是在给定的集合(或者是多重集,它允许多个元素具有相同的值)中找寻一个给定的值,我们称之为查找键。
对于查找问题来说,没有一种算法在任何情况下是都是最优的。
有些算法速度比其他算法快,但是需要较多的存储空间;有些算法速度非常快,但仅适用于有序数组。
第八章选择题1. C2.A3.B4.C5.D6.B7.B8.A9.D 10.D 11.C 12.C填空题1.n、n+12. 43.8.25( 折半查找所在块 )4.左子树、右子树5.266.顺序、(n+1)/2、O(log2n)7.m-1、[m/2]-18.直接定址应用题1.进行折半查找时,判定树是唯一的,折半查找过程是走了一条从根节点到末端节点的路径,所以其最大查找长度为判定树深度[log2n]+1.其平均查找长度约为[log2n+1]-1.在二叉排序树上查找时,其最大查找长度也是与二叉树的深度相关,但是含有n个节点的二叉排序树不是唯一的,当对n个元素的有序序列构造一棵二叉排序树时,得到的二叉排序树的深度也为n,在该二叉树上查找就演变成顺序查找,此时的最大查找长度为n;在随机情况下二叉排序树的平均查找长度为1+4log2n。
因此就查找效率而言,二分查找的效率优于二叉排序树查找,但是二叉排序树便于插入和删除,在该方面性能更优。
3. 评价哈希函数优劣的因素有:能否将关键字均匀的映射到哈希表中,有无好的处理冲突的方法,哈希函数的计算是否简单等。
冲突的概念:若两个不同的关键字Ki和Kj,其对应的哈希地址Hash(Ki) =Hash(Kj),则称为地址冲突,称Ki和K,j为同义词。
(1)开放定址法(2)重哈希法(3)链接地址法4.(1)构造的二叉排序树,如图(2)中序遍历结果如下:10 12 15 20 24 28 30 35 46 50 55 68(4)平均查找长度如下:ASLsucc = (1x1+2x2+3x3+4x3+5x3)/12 = 41/128.哈希地址如下:H(35) = 35%11 = 2H(67) = 67%11 = 1H(42) = 42%11 = 9H(21) = 21%11 = 10H(29) = 29%11 = 7H(86) = 86%11 = 9H(95) = 95%11 = 7H(47) = 47%11 = 3H(50) = 50%11 = 6H(36) = 36%11 = 3H(91) = 91%11 = 3第九章选择题1. D2.C3.B4.D5.C6.B7.A8.A9.D 10.D填空题1.插入排序、交换排序、选择排序、归并排序2.移动(或者交换)3.归并排序、快速排序、堆排序4.保存当前要插入的记录,可以省去在查找插入位置时的对是否出界的判断5.O(n)、O(log2n)6.直接插入排序或者改进了的冒泡排序、快速排序7.Log2n、n8.完全二叉树、n/29.1510.{12 38 25 35 50 74 63 90}应用题11.(1)Shell排序(步长为5 3 1)每趟的排序结果初始序列为100 87 52 61 27 170 37 45 61 118 14 88 32步长为5的排序14 37 32 61 27 100 87 45 61 118 170 88 52步长为3的排序结果14 27 32 52 37 61 61 45 88 87 170 100 118步长为1的排序结果14 27 32 37 45 52 61 61 87 88 100 118最后结果14 27 32 37 45 52 61 61 87 88 100 118 170(2)快速排序每趟的排序结果如图初始序列100 87 52 61 27 170 37 45 61 118 14 88 32第一趟排序[32 87 52 61 27 88 37 45 61 14]100[118 170]第二趟排序[14 27]32[61 52 88 37 45 61 87]100 118[170]第三趟排序14[27]32[45 52 37]61[88 61 87]100 118[170]第四趟排序14[27]32[37]45[52]61[87 61]88 100 118[170]第五趟排序14[27]32[37]45[52]61[87 61]88 100 118[170]最后结果14[27]32[37]45[52]61[61]87 88 100 118[170](3)二路归并排序每趟的排序结果初始序列[100][87][52][61][27][170][37][45][61][118][14][88][32]第一趟归并[87 100][52 61][27 170][37 45][61 118][14 88][32]第二趟归并[52 61 87 100][27 37 45 170][14 61 88 118][32]第三趟归并排序[27 37 45 52 61 87 100 170][14 32 61 88 118]第四趟归并排序[14 27 32 37 45 52 61 61 87 88 100 118 170]最后结果14 27 32 37 45 52 61 61 87 88 100 118 17012.采用快速排序时,第一趟排序过程中的数据移动如图:算法设计题1.分析:为讨论方便,待排序记录的定义为(后面各算法都采用此定义):#define MAXSIZE 100 /* 顺序表的最大长度,假定顺序表的长度为100 */ typedef int KeyType; /* 假定关键字类型为整数类型 */typedef struct {KeyType key; /* 关键字项 */OtherType other; /* 其他项 */}DataType; /* 数据元素类型 */typedef struct {DataType R[MAXSIZE+1]; /* R[0]闲置或者充当哨站 */int length; /* 顺序表长度 */}sqList; /* 顺序表类型 */设n个整数存储在R[1..n]中,因为前n-2个元素有序,若采用直接插入算法,共要比较和移动n-2次,如果最后两个元素做一个批处理,那么比较次数和移动次数将大大减小。
折半查找所描述的算法折半查找,也称为二分查找,是一种在有序数组中查找目标元素的算法。
它的基本思想是在每一步中将目标值与数组中间元素进行比较,从而缩小待查找范围,直到找到目标值或者确定目标值不存在。
具体的折半查找算法可以描述为以下几个步骤:1.确定查找范围:首先确定待查找元素所在的起始和结束位置。
一般情况下,初始条件下起始位置为0,结束位置为数组的长度减12. 计算中间位置:通过计算起始位置和结束位置的中间索引,可以得到中间位置mid。
中间位置可以通过如下公式获得:mid = (start + end) / 23. 检查中间元素:将目标元素与中间元素进行比较。
如果目标元素等于中间元素,则查找成功并返回中间位置。
如果目标元素小于中间元素,则新的结束位置为mid-1、如果目标元素大于中间元素,则新的起始位置为mid+14.更新查找范围:根据目标元素与中间元素的比较结果,更新起始位置和结束位置,然后重复步骤2和步骤3,直到查找成功或者待查找范围为空。
5.查找失败:如果查找范围为空,即起始位置大于结束位置,则表示查找失败。
折半查找算法的时间复杂度是O(logn),其中n是数组的长度。
这是由于每一次迭代都将查询范围缩小一半,所以最多需要进行logn次迭代。
下面是一个使用折半查找算法查找目标元素在有序数组中的位置的示例代码:```pythondef binary_search(arr, target):start = 0end = len(arr) - 1while start <= end:mid = (start + end) // 2if arr[mid] == target:return midelif arr[mid] < target:start = mid + 1else:end = mid - 1return -1#测试arr = [1, 3, 5, 7, 9, 11]target = 7result = binary_search(arr, target)if result != -1:print("目标元素在数组中的位置为", result)else:print("数组中不存在目标元素")```在上面的示例代码中,我们首先定义了一个binary_search函数。
C语⾔实现顺序表的顺序查找和折半查找本⽂实例为⼤家分享了C语⾔实现顺序表的顺序查找和折半查找的具体代码,供⼤家参考,具体内容如下顺序查找:#include <iostream>using namespace std;int SeqSearch(int r[],int n,int k){r[0]=k;//下标0⽤作哨兵存放要查询的数int i=n;while(r[i]!=k)//不⽤判断下标i是否越界{i--;}return i;}int main(){int n;cout<<"请输⼊数组元素个数:"<<endl;cin>>n;int a[n+1];cout<<"请输⼊数组元素:"<<endl;for(int i=1;i<=n;i++){cin>>a[i];}int k;cout<<"请输⼊要查询的数:"<<endl;cin>>k;for(int i=1;i<=n;i++){cout<<a[i]<<" ";}cout<<endl;cout<<"该数在数组中的位置为:";cout<<SeqSearch(a,n,k);return 0;}折半查找:#include<iostream>using namespace std;int BinSearch1(int r[],int n,int k)//⾮递归{int low=1,high=n;//设置查找区间while(low<=high)//如果区间存在{int mid=(low+high)/2;if(k<r[mid])high=mid-1;//查找在左半区进⾏,回到while那⼀步else if(k>r[mid])low=mid+1;else return mid;}return 0;//如果区间不存在,则返回0,查找失败}int BinSearch2(int r[],int low,int high,int k)//递归{int mid=(low+high)/2;if(low>high) return 0;else{if(k<r[mid])BinSearch2(r,low,mid-1,k);else if(k>r[mid])BinSearch2(r,mid+1,high,k);else return mid;}}int main(){int n;cout<<"请输⼊数组元素个数:";cout<<endl;cin>>n;int a[n+1];cout<<"请输⼊数组元素:";cout<<endl;for(int i=1;i<=n;i++){cin>>a[i];}cout<<"请输⼊要查找的数:";cout<<endl;int k;cin>>k;cout<<"该数在数组中的位置是:"<<endl;cout<<BinSearch1(a,n,k);cout<<endl;cout<<BinSearch2(a,1,n,k);}以上就是本⽂的全部内容,希望对⼤家的学习有所帮助,也希望⼤家多多⽀持。