R 软件中的非参数回归
- 格式:pdf
- 大小:416.79 KB
- 文档页数:17

标题解读非参数回归方法的基本原理与应用非参数回归方法是一种用于建立回归模型的统计方法,与传统的参数回归方法不同,非参数回归方法不对模型参数做出任何假设,从而更加灵活地适应各种数据分布和模型形态的情况。
本文将解读非参数回归方法的基本原理与应用。
一、基本原理非参数回归方法的基本原理是通过对样本数据的直接建模,而不对任何参数进行假设。
这使得非参数回归方法适用于各种数据形态和概率分布情况。
基于此原理,非参数回归方法通过以下几个步骤实现对数据的建模:1. 核密度估计:非参数回归方法通常采用核密度估计来估计数据的密度函数。
核密度估计通过将每个数据点视为一个核函数,并将这些核函数进行叠加,得到整个数据的密度函数。
常用的核函数有高斯核函数和Epanechnikov核函数等。
2. 局部加权回归:非参数回归方法通过局部加权回归来对密度函数进行平滑处理。
局部加权回归将每个数据点周围的数据点加权平均,并以此来估计每个点的函数值。
这样可以缓解由于数据噪声引起的波动性,并得到更平滑的回归曲线。
3. 自适应参数调整:非参数回归方法中,核密度估计和局部加权回归的参数通常是自适应的,即根据数据的特性自动调整。
这使得非参数回归方法能够更好地适应数据的变化和不确定性,并提供更准确的回归结果。
二、应用实例非参数回归方法在诸多领域都有广泛的应用,下面以几个实际应用举例说明:1. 金融领域:非参数回归方法可以用于金融数据的建模和预测。
例如,非参数回归方法可以帮助分析师对股票价格进行预测,根据历史数据构建回归模型,并通过模型预测未来的价格走势。
2. 医学领域:非参数回归方法可以用于分析医学数据和研究疾病的发展趋势。
例如,非参数回归方法可以用于研究一种药物对患者生存时间的影响,通过建立回归模型来估计药物的效果。
3. 经济学领域:非参数回归方法可以用于经济数据的分析和预测。
例如,非参数回归方法可以用于分析GDP与劳动力之间的关系,通过建立回归模型来预测GDP的增长。

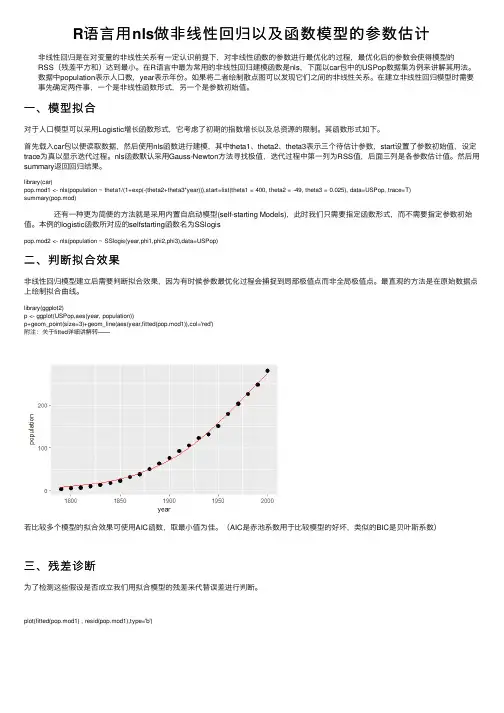
R语⾔⽤nls做⾮线性回归以及函数模型的参数估计⾮线性回归是在对变量的⾮线性关系有⼀定认识前提下,对⾮线性函数的参数进⾏最优化的过程,最优化后的参数会使得模型的RSS(残差平⽅和)达到最⼩。
在R语⾔中最为常⽤的⾮线性回归建模函数是nls,下⾯以car包中的USPop数据集为例来讲解其⽤法。
数据中population表⽰⼈⼝数,year表⽰年份。
如果将⼆者绘制散点图可以发现它们之间的⾮线性关系。
在建⽴⾮线性回归模型时需要事先确定两件事,⼀个是⾮线性函数形式,另⼀个是参数初始值。
⼀、模型拟合对于⼈⼝模型可以采⽤Logistic增长函数形式,它考虑了初期的指数增长以及总资源的限制。
其函数形式如下。
⾸先载⼊car包以便读取数据,然后使⽤nls函数进⾏建模,其中theta1、theta2、theta3表⽰三个待估计参数,start设置了参数初始值,设定trace为真以显⽰迭代过程。
nls函数默认采⽤Gauss-Newton⽅法寻找极值,迭代过程中第⼀列为RSS值,后⾯三列是各参数估计值。
然后⽤summary返回回归结果。
library(car)pop.mod1 <- nls(population ~ theta1/(1+exp(-(theta2+theta3*year))),start=list(theta1 = 400, theta2 = -49, theta3 = 0.025), data=USPop, trace=T)summary(pop.mod) 还有⼀种更为简便的⽅法就是采⽤内置⾃启动模型(self-starting Models),此时我们只需要指定函数形式,⽽不需要指定参数初始值。
本例的logistic函数所对应的selfstarting函数名为SSlogispop.mod2 <- nls(population ~ SSlogis(year,phi1,phi2,phi3),data=USPop)⼆、判断拟合效果⾮线性回归模型建⽴后需要判断拟合效果,因为有时候参数最优化过程会捕捉到局部极值点⽽⾮全局极值点。

非参数回归方法及其应用
非参数回归方法是一种不依赖于数据假设分布形式的回归分析
方法。
相比于传统的线性回归方法,非参数回归方法更加灵活,适用于不规则数据。
非参数回归方法主要包括局部加权回归、核回归、样条回归等。
其中,局部加权回归是一种以目标点为中心,对数据进行加权拟合的方法,其优点是适用于不规则分布的数据,缺点是计算量大。
核回归是一种以核函数为基础进行回归分析的方法,可以克服传统回归方法无法适用于非线性数据的问题。
样条回归则是一种通过连接多个小段函数拟合数据的方法,可以克服传统回归方法插值效果差的问题。
非参数回归方法在金融、生态学、医学等领域都有着广泛的应用。
例如,可以用于金融市场的波动性分析,生态学中物种多样性与环境因素的关系研究,医学中对疾病发生率的预测等。
总之,非参数回归方法是一种适用于不同领域的灵活、有效的回归分析方法。
- 1 -。

由詹鹏整理 ,仅供交流和学习根据南京财经大学统计系孙瑞博副教授的课件修改 ,在此感谢孙老师的辛勤付出!教材为:Luke Keele: Semiparametric Regression for the Social Sciences. John Wiley & Sons, Ltd. 2008.-------------------------------------------------------------------------第一章 introduction: Global versus Local Statistic一、主要参考书目及说明1、Hardle(1994). Applied Nonparametic Regresstion. 较早的经典书2、Hardle etc (2004). Nonparametric and semiparametric models: an introduction. Springer. 结构清晰3、Li and Racine(2007). Nonparametric econometrics: Theory and Practice. Princeton. 较全面和深入的介绍 ,偏难4、Pagan and Ullah (1999). Nonparametric Econometrics. 经典5、Yatchew(2003). Semiparametric Regression for the Applied Econometrician. 例子不错6、高铁梅(2009). 计量经济分析方法与建模:EVIEWS应用及实例(第二版). 清华大学出版社. (P127/143)7、李雪松(2008). 高级计量经济学. 中国社会科学出版社. (P45 ch3)8、陈强(2010). 高级计量经济学及Stata应用. 高教出版社. (ch23/24)【其他参看原ppt第一章】二、内容简介方法:——移动平均(moving average)——核光滑(Kernel smoothing)——K近邻光滑(K-NN)——局部多项式回归(Local Polynormal)——Loesss and Lowess——样条光滑(Smoothing Spline)——B-spline——Friedman Supersmoother模型:——非参数密度估计——非参数回归模型——非参数回归模型——时间序列的半参数模型——Panel data 的半参数模型——Quantile Regression三、不同的模型形式1、线性模型linear models2、Nonlinear in variables3、Nonlinear in parameters四、数据转换 Power transformation(对参数方法)In the GLM framework, models are equally prone(倾向于) to some misspecification (不规范) from an incorrect functional form.It would be prudent(谨慎的) to test that the effect of any independent variable of a model does not have a nonlinear effect. If it does have a nonlinear effect, analysts in the social science usually rely on Power Transformations to address nonlinearity.[ADD: 检验方法见Sanford Weisberg. Applied Linear Regression (Third Edition). A John Wiley & Sons, Inc., Publication.(本科的应用回归分析课教材)]----------------------------------------------------------------------------第二章Nonparametric Density Estimation非参数密度估计一、三种方法1、直方图 Hiatogram2、Kernel density estimate3、K nearest-neighbors estimate二、Histogram 对直方图的一个数值解释Suppose x1,…xN – f(x), the density function f(x) is unknown.One can use the following function to estimate f(x)【与x的距离小于h的所有点的个数】三、Kernel density estimateBandwidth: h; Window width: 2h.1、Kernel function的条件The kernel function K(.) is a continuous function, symmetric(对称的) around zero, that integrates(积分) to unity and satisfies additional bounded conditions:(1) K() is symmetric around 0 and is continuous;(2) ,,;(3) Either(a) K(z)=0 if |z|>=z0 for z0Or(b) |z|K(z) à0 as;(4) , where is a constant.2、主要函数形式3、置信区间其中 ,4、窗宽的选择实际应用中 ,。

非参数回归r语言-概述说明以及解释1.引言1.1 概述非参数回归是一种不依赖于特定函数形式的回归分析方法,它不需要对数据的分布做出假设。
相比于传统的参数回归方法,非参数回归更加灵活,能够更好地拟合复杂的数据模式。
在实际应用中,非参数回归可以有效地处理非线性关系、异常值和数据噪音等问题,因此受到越来越多研究者和数据分析师的青睐。
本文将重点介绍在R语言中如何进行非参数回归分析,包括常用的非参数回归方法、分析步骤以及如何利用R语言中的工具进行非参数回归分析。
同时,我们将讨论非参数回归的优缺点,以及对R语言在非参数回归中的意义和展望非参数回归的发展。
希望本文能够帮助读者更加深入地了解非参数回归方法,并在实践中灵活运用。
1.2 文章结构本文分为引言、正文和结论三部分。
在引言部分,将包括概述、文章结构和目的等内容,为读者提供对非参数回归和R语言的整体了解。
在正文部分,将介绍什么是非参数回归、在R语言中如何进行非参数回归分析以及非参数回归的优缺点。
最后,在结论部分将对非参数回归的应用进行总结,探讨R语言在非参数回归中的意义,以及展望非参数回归的发展前景。
通过以上结构,读者将逐步深入了解非参数回归和R语言在该领域的应用和发展。
1.3 目的本文旨在探讨非参数回归在数据分析中的应用,特别是在R语言环境下的实现方法。
通过深入了解非参数回归的概念、原理和优缺点,读者可以更全面地了解这一方法在处理不确定性较大、数据分布不规律的情况下的优势和局限性。
此外,本文还旨在介绍R语言中如何进行非参数回归分析,帮助读者学习如何利用这一工具进行数据建模和预测分析。
最终,通过对非参数回归的应用和发展的展望,希望能够激发更多的研究者和数据分析师对于这一领域的兴趣,推动非参数回归方法在实际应用中的进一步发展和创新。
2.正文2.1 什么是非参数回归非参数回归是一种用于建立数据之间关系的统计方法,它不对数据的分布做出任何假设。
在传统的参数回归中,我们通常会假设数据服从某种特定的分布,比如正态分布,然后通过参数估计来拟合模型。

用R语言做非参数非参数统计是一种统计学方法,不依赖于数据的分布假设。
相比于参数统计,非参数统计更加灵活,可以处理各种类型的数据。
在R语言中,有很多函数和包可以用来进行非参数统计分析。
首先,我们可以使用Wilcoxon秩和检验(Mann-Whitney U检验)来比较两组独立样本的中位数差异。
Wilcoxon秩和检验是一种非参数的假设检验方法,适用于两组样本的中位数比较。
在R语言中,使用wilcox.test(函数可以进行Wilcoxon秩和检验。
例如,假设我们有两组样本x和y,我们可以使用以下代码进行Wilcoxon秩和检验:```Rx<-c(1,2,3,4,5)y<-c(6,7,8,9,10)result <- wilcox.test(x, y)print(result)```这段代码将计算两组样本的Wilcoxon秩和检验结果,并打印输出。
除了Wilcoxon秩和检验,我们还可以使用Kruskal-Wallis检验来比较多组样本的中位数差异。
Kruskal-Wallis检验是一种非参数的方差分析方法,适用于多组样本的中位数比较。
在R语言中,使用kruskal.test(函数可以进行Kruskal-Wallis检验。
例如,假设我们有三组样本x、y和z,我们可以使用以下代码进行Kruskal-Wallis检验:```Rx<-c(1,2,3,4,5)y<-c(6,7,8,9,10)z<-c(11,12,13,14,15)result <- kruskal.test(list(x, y, z))print(result)```这段代码将计算三组样本的Kruskal-Wallis检验结果,并打印输出。
另外,对于变量间的相关性检验,我们可以使用Spearman秩相关系数。
Spearman秩相关系数是一种非参数的相关性分析方法,适用于非线性关系的变量间的相关性分析。

r语言3组非参数检验-回复R语言是一个功能强大的统计编程语言,广泛应用于数据分析、统计建模和可视化等领域。
在数据分析中,我们经常需要进行假设检验来判断样本数据是否符合某种分布或两个样本数据是否具有显著差异。
其中一种常用的假设检验方法是非参数检验,它不对数据的分布做出要求,因此适用于各种类型的数据。
本文将以R语言为工具,介绍非参数检验的相关概念和步骤,并以具体例子进行演示。
一、非参数检验的基本概念非参数检验是一种统计方法,不对数据的分布做出假设,根据样本数据的秩次或拟合程度进行假设检验。
它的优势在于能够处理非正态分布或存在异常值的数据。
常见的非参数检验方法包括Wilcoxon符号秩检验、Mann-Whitney U检验、Kruskal-Wallis单因素方差分析等。
二、Wilcoxon符号秩检验Wilcoxon符号秩检验是一种非参数检验方法,用于比较两个相关样本的差异性。
它的原假设是两个样本的差异性中位数为零,备择假设是两个样本差异性的中位数不为零。
下面是Wilcoxon符号秩检验的步骤:1.导入数据和包:使用R语言进行数据分析时,首先需要导入相关的数据和包。
如有需要,可以使用install.packages()函数安装所需的包。
2.准备数据:将需要进行Wilcoxon符号秩检验的数据存储为两个向量或数据框的形式。
3.执行Wilcoxon符号秩检验:使用wilcox.test()函数执行Wilcoxon符号秩检验,并将两个样本的数据作为输入。
4.解读结果:根据检验结果的p值,判断两组样本差异是否显著。
通常取显著性水平为0.05,若p值小于0.05,可以拒绝原假设,认为两个样本的差异是显著的。
三、Mann-Whitney U检验Mann-Whitney U检验是一种非参数检验方法,用于比较两个独立样本的差异性。
它的原假设是两个样本的分布相同,备择假设是两个样本的分布不同。
Mann-Whitney U检验的步骤如下:1.导入数据和包:与Wilcoxon符号秩检验一样,首先需要导入相关的数据和包。

非参数统计r语言非参数统计是一种统计学方法,它不依赖于数据的具体分布形式,而是通过对数据的排序、排列、秩次等进行分析来得出结论。
在统计学中,非参数统计方法常常用于处理那些不满足正态分布假设的数据,或者对数据分布形式不确定的情况下进行分析。
R语言是一种广泛应用于数据分析和统计学领域的编程语言,它提供了丰富的数据处理、统计分析和可视化工具,使得非参数统计方法的应用变得更加方便和高效。
下面将介绍一些常见的非参数统计方法在R语言中的实现。
首先是Wilcoxon秩和检验,也称为Mann-Whitney U检验,用于比较两组独立样本的中位数是否有显著差异。
在R语言中,可以使用wilcox.test()函数进行计算,通过设置参数来指定要进行的检验类型,例如单侧检验、双侧检验等。
其次是Kruskal-Wallis检验,用于比较多组独立样本的中位数是否有显著差异。
在R语言中,可以使用kruskal.test()函数进行计算,通过将多组数据传入函数中进行比较,得出检验的结果和统计量。
另外,对于非参数统计中的秩相关检验,如Spearman秩相关系数检验和Kendall秩相关系数检验,也可以在R语言中进行计算。
通过使用cor.test()函数,可以计算两组数据的秩相关系数并进行假设检验,得出相关性的显著性。
除此之外,R语言中还提供了一些其他非参数统计方法的实现,如符号检验、秩和检验、秩秩相关检验等。
这些方法的应用可以帮助研究人员在数据分析中更全面地考虑数据的性质和假设,从而得出更可靠的统计结论。
总的来说,非参数统计方法在R语言中的应用丰富多样,可以满足不同数据分析的需求,帮助研究人员更好地理解数据的特征和结构,为科学研究和决策提供支持。
通过掌握R语言中的非参数统计方法,可以更好地应对实际数据分析中的挑战,为数据科学的发展和应用做出贡献。


由詹鹏整理,仅供交流和学习根据南京财经大学统计系孙瑞博副教授的课件修改,在此感谢孙老师的辛勤付出!教材为:Luke Keele: Semiparametric Regression for the Social Sciences. John Wiley & Sons, Ltd. 2008.-------------------------------------------------------------------------第一章introduction: Global versus Local Statistic一、主要参考书目及说明1、Hardle(1994). Applied Nonparametic Regresstion. 较早的经典书2、Hardle etc (2004). Nonparametric and semiparametric models: an introduction. Springer. 结构清晰3、Li and Racine(2007). Nonparametric econometrics: Theory and Practice. Princeton. 较全面和深入的介绍,偏难4、Pagan and Ullah (1999). Nonparametric Econometrics. 经典5、Yatchew(2003). Semiparametric Regression for the Applied Econometrician. 例子不错6、高铁梅(2009). 计量经济分析方法与建模:EVIEWS应用及实例(第二版). 清华大学出版社. (P127/143)7、李雪松(2008). 高级计量经济学. 中国社会科学出版社. (P45 ch3)8、陈强(2010). 高级计量经济学及Stata应用. 高教出版社. (ch23/24)【其他参看原ppt第一章】二、内容简介方法:——移动平均(moving average)——核光滑(Kernel smoothing)——K近邻光滑(K-NN)——局部多项式回归(Local Polynormal)——Loesss and Lowess——样条光滑(Smoothing Spline)——B-spline——Friedman Supersmoother模型:——非参数密度估计——非参数回归模型——非参数回归模型——时间序列的半参数模型——Panel data 的半参数模型——Quantile Regression三、不同的模型形式1、线性模型linear models2、Nonlinear in variables3、Nonlinear in parameters四、数据转换Power transformation(对参数方法)In the GLM framework, models are equally prone(倾向于) to some misspecification(不规范)from an incorrect functional form.It would be prudent(谨慎的)to test that the effect of any independent variable of a model does not have a nonlinear effect. If it does have a nonlinear effect, analysts in the social science usually rely on Power Transformations to address nonlinearity.[ADD: 检验方法见Sanford Weisberg. Applied Linear Regression (Third Edition). A John Wiley & Sons, Inc., Publication.(本科的应用回归分析课教材)]----------------------------------------------------------------------------第二章 Nonparametric Density Estimation非参数密度估计一、三种方法1、直方图Hiatogram2、Kernel density estimate3、K nearest-neighbors estimate二、Histogram 对直方图的一个数值解释Suppose x1,…xN – f(x), the density function f(x) is unknown.One can use the following function to estimate f(x)【与x的距离小于h的所有点的个数】三、Kernel density estimateBandwidth: h; Window width: 2h.1、Kernel function的条件The kernel function K(.) is a continuous function, symmetric(对称的) around zero, that integrates(积分) to unity and satisfies additional bounded conditions:(1) K() is symmetric around 0 and is continuous;(2) ,,;(3) Either(a) K(z)=0 if |z|>=z0 for z0Or(b) |z|K(z) à0 as ;(4) , where is a constant.2、主要函数形式3、置信区间其中,4、窗宽的选择实际应用中,。
r语言多组数据非参数检验-回复R语言多组数据非参数检验是一种常用的统计分析方法,适用于未满足正态分布假设的情况。
本文将以此为主题,从介绍非参数检验的背景和原理,到详细讲解R语言中多组数据非参数检验的步骤,一步一步回答读者的疑问。
一、非参数检验的背景和原理非参数检验是一种不基于总体分布假设的统计方法,主要用于比较两个或多个组之间的差异。
相比于参数检验,非参数检验更为灵活,适用范围更广。
非参数检验的原理是通过对数据进行排序和秩次变换,来忽略数据分布的形状和特征,只关注于数据的顺序关系,从而进行统计推断。
二、R语言中多组数据非参数检验的步骤在R语言中,进行多组数据的非参数检验可以使用多种函数,下面将一步一步介绍具体的操作步骤。
1. 导入数据首先,需要将数据导入R语言中,并将其存储为矩阵或数据框的形式。
可以使用`read.csv()`或`read.table()`函数将数据从外部文件导入,也可以直接使用`data.frame()`函数手动创建数据框。
2. 定义分组变量根据研究设计,将数据分组。
通常可以使用向量或因子变量的形式定义分组变量,例如:group <- c("A", "A", "A", "B", "B", "B")。
3. 进行非参数检验R语言中有多个函数可以进行非参数检验,根据研究目的和数据类型的不同,选择合适的函数。
常用的函数有:- wilcox.test(): 用于比较两个独立样本之间的差异,返回Wilcoxon秩和检验的结果。
- kruskal.test(): 用于比较多个独立样本之间的差异,返回Kruskal-Wallis 检验的结果。
- friedman.test(): 用于比较多个相关样本之间的差异,返回Friedman 秩和检验的结果。
这些函数都有相似的参数,包括x(数据向量或因子)、y(分组变量)和alternative(备择假设),可以根据需要进行设置。
R语⾔差异检验:⾮参数检验操作⾮参数检验是在总体⽅差未知或知道甚少的情况下,利⽤样本数据对总体分布形态进⾏推断的⽅法。
它利⽤数据的⼤⼩间的次序关系(秩Rank),⽽不是具体数值信息,得出推断结论。
它是参数检验所需要的某些条件不满⾜时所使⽤的⽅法。
和参数检验相⽐,⾮参数检验的优势如下:稳健性。
对总体分布的条件要求放宽对数据类型要求不严格,适⽤有序分类变量适⽤范围⼴劣势:没有利⽤实际数值,损失了部分信息,检验的有效性较差。
⾮参数性检验的⽅法⾮常多,基于⽅法的检验功效性⾓度,本⽂只涉及双独⽴样本:Mann-Whitney U检验双配对样本:Wilcoxon配对秩和检验多独⽴样本:Kruskal-Wallis检验多配对样本:Friedman检验Mann-Whitney U检验曼-惠特尼U检验(曼-惠特尼秩和检验),是由H.B.Mann和D.R.Whitney于1947年提出的。
它假设两个样本分别来⾃除了总体均值以外完全相同的两个总体,⽬的是检验这两个总体的均值是否有显著的差别。
适⽤条件双独⽴样本检验R语⾔⽰例函数及格式:wilcox.test(y~x,data)其中,y是连续变量,x是⼀个⼆分变量。
也可以使⽤这种形式:wilcox.test(y1,y2)其中,y1和y2为变量名。
可选参数data的取值为⼀个包含这些变量的矩阵或数据框。
⽰例:#载⼊MASS包library(MASS)#使⽤UScrime数据集#Prob为监禁率,So为是否南⽅地区#检验美国监禁率是否存在南⽅和⾮南⽅差异#wilcox.test检验wilcox.test(Prob~So,data = UScrime)#结果Wilcoxon rank sum testdata: Prob by SoW = 81, p-value = 8.488e-05alternative hypothesis: true location shift is not equal to 0#结果显⽰P⼩于0.001,美国监禁率存在南⽅和⾮南⽅地区差异。
r语言多组数据非参数检验-回复主题:R语言中多组数据的非参数检验引言:在统计学中,我们经常需要对不同组别的数据进行比较和分析。
而非参数检验是一种常用的方法,可以用于比较不同组别的数据,而不需要对数据具有特定的分布形式。
R语言是一种强大的统计分析工具,提供了多种非参数检验方法,使得我们可以轻松地进行多组数据的比较。
本文将以R语言为工具,一步一步介绍多组数据的非参数检验方法。
一、读取数据:首先,我们需要从外部文件或者直接在R中定义数据,用于后续的分析。
在R中,可以使用read.csv()函数读取csv格式的文件,或者使用read.table()函数读取其他格式的文件。
在本文中,我们假设我们已经读取了两组数据,分别命名为group1和group2。
二、描述性统计分析:在进行非参数检验之前,我们需要先对数据进行一定的描述性统计分析,以了解数据的分布状况和基本特征。
在R语言中,可以使用summary()函数来计算数据的各种统计量,如均值、中位数、四分位数等。
此外,我们还可以使用hist()函数绘制直方图,来观察数据的分布情况。
三、非参数检验方法选择:在进行非参数检验之前,我们需要根据数据的特点选择合适的非参数检验方法。
常用的非参数检验方法包括Wilcoxon秩和检验、Mann-Whitney U检验、Kruskal-Wallis单因素方差分析等。
在R语言中,可以使用wilcox.test()函数进行Wilcoxon秩和检验,使用wilcox.test()或者kruskal.test()函数进行多组数据的比较。
四、Wilcoxon秩和检验:假设我们要比较group1和group2两组数据之间的差异。
我们可以使用wilcox.test()函数进行Wilcoxon秩和检验。
该检验假设两组数据的分布形状相同,只有位置参数不同。
在R语言中,我们可以使用如下代码进行Wilcoxon秩和检验:wilcox.test(group1, group2, paired = FALSE)其中,group1和group2分别表示两组数据的向量,paired = FALSE表示两组数据是不相关的。
r语言多因素非参数检验标题:以R语言多因素非参数检验引言:在统计学中,非参数方法是一种不依赖于总体分布形态的统计检验方法。
与参数方法相比,非参数方法更加灵活,适用于各种数据类型以及假设条件的情况。
本文将介绍如何使用R语言进行多因素非参数检验,以帮助研究者更好地分析数据并得出准确的结论。
一、什么是多因素非参数检验?多因素非参数检验是一种用于比较两个或多个因素对于变量的影响是否显著的统计方法。
与单因素非参数检验相比,多因素非参数检验可以同时考虑多个因素的影响,更加全面地分析数据。
二、R语言中的多因素非参数检验函数R语言提供了多个包来进行多因素非参数检验,常用的包包括“stats”、“coin”和“nparLD”等。
下面以两个常用的多因素非参数检验方法为例进行介绍。
1. 基于秩和的多因素方差分析(Kruskal-Wallis Test)Kruskal-Wallis检验用于比较两个或多个独立样本组之间的中位数是否存在差异。
在R语言中,可以使用“kruskal.test()”函数进行计算。
示例代码:```# 导入数据data <- read.csv("data.csv")# 进行Kruskal-Wallis检验result <- kruskal.test(value ~ factor1 * factor2, data=data)# 输出结果print(result)```2. 基于秩和的多因素重复测量方差分析(Friedman Test)Friedman检验用于比较两个或多个重复测量样本组之间的中位数是否存在差异。
在R语言中,可以使用“friedman.test()”函数进行计算。
示例代码:```# 导入数据data <- read.csv("data.csv")# 进行Friedman检验result <- friedman.test(value ~ factor1 + factor2 | subject,data=data)# 输出结果print(result)```三、案例分析为了进一步说明多因素非参数检验的应用,我们以一个假设情景为例进行分析。