留出法:将数据集D划分为两个互斥的集合:训练集S和测试集T
DST且 ST
;.
18
;.
19
预剪枝
训练集:好瓜 坏瓜 1,2,3,6,7,10,14,15,16,17
1,2,3,14
4,5,13 (T,T,F)
6,7,15,17
8,9 (T,F)
精度:正确分类的样本占所有 样本的比例
验证集:4,5,8,9,11,12,13
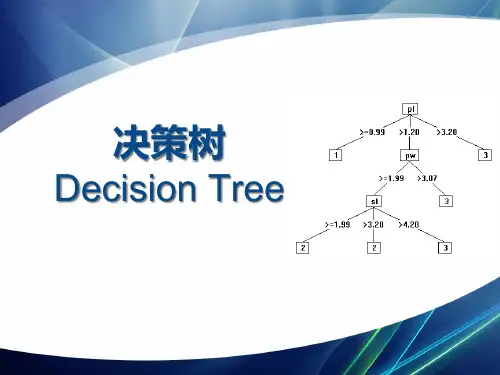
三种度量结点“纯度”的指标: 1. 信息增益 2. 增益率 3. 基尼指数
;.
6
1. 信息增益 信息熵
香农提出了“信息熵”的概念,解决了对信息的量化度量问题。 香农用“信息熵”的概念来描述信源的不确定性。
对于二分类任务 y 2
;.
7
假设我们已经知道衡量不确定性大小的这个量已经存在了,不妨就叫做“信息量”
用“编号”将根结点划分后获得17个 分支结点的信息熵均为:
E n t( D 1 ) E n t(D 1 7 ) ( 1 1 lo g 2 1 1 1 0 lo g 2 1 0 ) 0
则“编号”的信息增益为:
G a in (D ,编 号 ) E n t(D )1 71E n t(D v) 0 .9 9 8
;.
30
1. 属性值缺失时,如何进行划分属性选择?(如何计算信息增益) 2. 给定划分属性,若样本在该属性上的值缺失,如何对样本进行划分?
(对于缺失属性值的样本如何将它从父结点划分到子结点中)
D : D : 训练集
训练集中在属性a上没有缺失值的样本子集
D D v :
被属性a划分后的样本子集
D D k :
;.
2
二分类学习任务 属性 属性值