非参数统计分析NonparametricTests菜单详解
- 格式:doc
- 大小:29.00 KB
- 文档页数:10
非参数检验非参数统计分析方法(Non-parametric statistics )是相对参数统计分析方法而言的,又称为不拘分布(distribution-free statistics) 的统计分析方法或无分布形式假定(assumption free statistics )的统计分析方法。
其中包括Wilcoxon 秩和检验、Kruskal-Wallis 秩和检验、friedman 秩和检验等,它们分别对应不同设计类型的资料。
SAS中对于非参数分析方法功能的实现主要由npar1way 过程来完成,从过程名字就可以看出,在此过程的处理进程中,只能一次指定一个因素进行分析。
下面我们先来了解一下npar1way 过程的语句格式以及各语句和选项的基本功能。
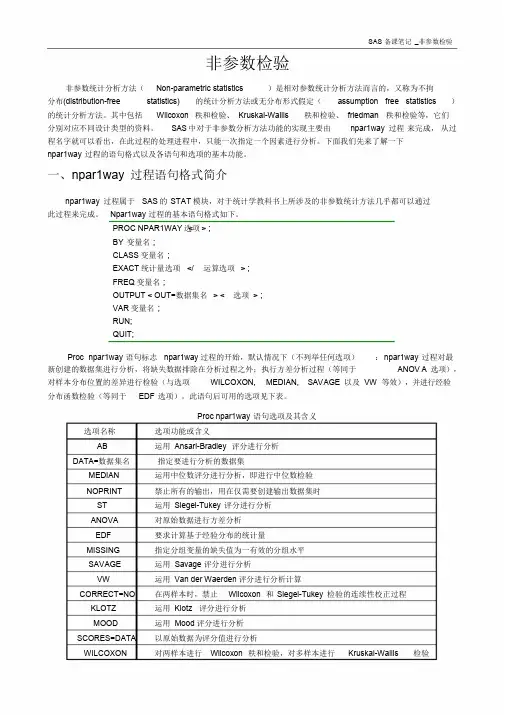
一、npar1way 过程语句格式简介npar1way 过程属于SAS的STAT模块,对于统计学教科书上所涉及的非参数统计方法几乎都可以通过此过程来完成。
Npar1way 过程的基本语句格式如下。
PROC NPAR1WAY选<项> ;BY 变量名;CLASS变量名;EXACT统计量选项</ 运算选项> ;FREQ变量名;OUTPUT < OUT=数据集名> < 选项> ;VAR 变量名;RUN;QUIT;Proc npar1way 语句标志npar1way 过程的开始,默认情况下(不列举任何选项):npar1way 过程对最新创建的数据集进行分析,将缺失数据排除在分析过程之外;执行方差分析过程(等同于ANOV A 选项),对样本分布位置的差异进行检验(与选项WILCOXON, MEDIAN, SAV A GE 以及VW 等效),并进行经验分布函数检验(等同于EDF 选项)。
此语句后可用的选项见下表。
Proc npar1way 语句选项及其含义选项名称选项功能或含义AB 运用Ansari-Bradley 评分进行分析DATA=数据集名指定要进行分析的数据集MEDIAN 运用中位数评分进行分析,即进行中位数检验NOPRINT 禁止所有的输出,用在仅需要创建输出数据集时ST 运用Siegel-Tukey 评分进行分析ANOVA 对原始数据进行方差分析EDF 要求计算基于经验分布的统计量MISSING 指定分组变量的缺失值为一有效的分组水平SAVAGE 运用Savage 评分进行分析VW 运用Van der Waerden评分进行分析计算CORRECT=NO 在两样本时,禁止Wilcoxon 和Siegel-Tukey 检验的连续性校正过程KLOTZ 运用Klotz 评分进行分析MOOD 运用Mood评分进行分析SCORES=DATA 以原始数据为评分值进行分析WILCOXON 对两样本进行Wilcoxon 秩和检验,对多样本进行Kruskal-Wallis 检验1. exact 语句exact 语句要求SAS 对指定的统计量(选项)进行精确概率的计算。

非参数检验(Non-parametric test)是一种统计分析方法,它不需要假设数据满足特定的概率分布。
与参数检验不同,非参数检验不需要对数据的均值、方差等统计量进行假设。
非参数检验主要应用于计量数据,当数据分布未知或不适宜采用参数检验时,可以考虑使用非参数检验来评估数据之间的差异。
非参数检验的主要优点是不依赖于数据的分布假设,因此对数据的适应性较强。
然而,它的缺点是有些非参数检验的效力较低,即在拒绝原假设时,可能存在较高的Type I 错误概率。
常见的非参数检验方法包括:
1. 符号检验(Signed rank test):用于两个样本的顺序数据,检验两个样本的均值是否存在显著差异。
2. 曼- 惠特尼U 检验(Mann-Whitney U test):用于两个样本的顺序数据,检验两个样本的均值是否存在显著差异。
3. 肯德尔和谐系数检验(Kendall's tau test):用于评估两组评级数据之间的相关性。
4. 莫里斯符号检验(Morris test):用于多个样本的顺序数据,检验各组之间是否存在显著差异。
5. 克鲁斯卡尔- 沃尔斯检验(Kruskal-Wallis test):用于多组数据的顺序变量,检验各组之间的均值是否存在显著差异。
6. 费希尔精确检验(Fisher's exact test):用于两组分类数据,检验两个分类变量之间的关联性。
在实际应用中,根据数据类型、研究目的和假设检验条件,可以选择合适的非参数检验方法。
在使用非参数检验时,需要注意其对样本量、数据类型和数据分布的要求,以确保检验结果的准确性和可靠性。

常用的非参数检验(NonparametricTests)总结非参数检验(Nonparametric tests)是统计分析方法的重要组成部分,它与参数检验共同构成统计推断的基本内容。
参数检验是在总体分布形式已知的情况下,对总体分布的参数如均值、方差等进行推断的方法。
但是,在数据分析过程中,由于种种原因,人们往往无法对总体分布形态作简单假定,此时参数检验的方法就不再适用了。
非参数检验正是一类基于这种考虑,在总体方差未知或知道甚少的情况下,利用样本数据对总体分布形态等进行推断的方法。
由于非参数检验方法在推断过程中不涉及有关总体分布的参数,因而得名为“非参数”检验。
•两独立样本的非参数检验两独立样本的非参数检验是在对总体分布不甚了解的情况下,通过对两组独立样本的分析来推断样本来自的两个总体的分布等是否存在显著差异的方法。
独立样本是指在一个总体中随机抽样对在另一个总体中随机抽样没有影响的情况下所获得的样本。
SPSS中提供了多种两独立样本的非参数检验方法,其中包括曼-惠特尼U检验、K-S检验、W-W游程检验、极端反应检验等。
某工厂用甲乙两种不同的工艺生产同一种产品。
如果希望检验两种工艺下产品的使用是否存在显著差异,可从两种工艺生产出的产品中随机抽样,得到各自的使用寿命数据。
甲工艺:675 682 692 679 669 661 693乙工艺:662 649 672 663 650 651 646 652(1)曼-惠特尼U检验两独立样本的曼-惠特尼U检验可用于对两总体分布的比例判断。
其原假设:两组独立样本来自的两总体分布无显著差异。
曼-惠特尼U 检验通过对两组样本平均秩的研究来实现判断。
秩简单说就是变量值排序的名次,可以将数据按升序排列,每个变量值都会有一个在整个变量值序列中的位置或名次,这个位置或名次就是变量值的秩。
(2)K-S检验K-S检验不仅能够检验单个总体是否服从某一理论分布,还能够检验两总体分布是否存在显著差异。



非参数统计分析――Nonparametric Tests菜单详解非参数统计分析――Nonparametric Tests菜单详解平时我们使用的统计推断方法大多为参数统计方法,它们都是在已知总体分布的条件下,对相应分布的总体参数进行估计和检验。
比如单样本u检验就是假定该样本所在总体服从正态分布,然后推断总体的均数是否和已知的总体均数相同。
本节要讨论的统计方法着眼点不是总体参数,而是总体分布情况,即研究目标总体的分布是否与已知理论分布相同,或者各样本所在的分布位置/形状是否相同。
由于这一类方法不涉及总体参数,因而称为非参数统计方法。
SPSS的的Nonparametric Tests菜单中一共提供了8种非参数分析方法,它们可以被分为两大类:1、分布类型检验方法:亦称拟合优度检验方法。
即检验样本所在总体是否服从已知的理论分布。
具体包括:Chi-square test:用卡方检验来检验二项/多项分类变量的几个取值所占百分比是否和我们期望的比例有没有统计学差异。
Binomial Test:用于检测所给的变量是否符合二项分布,变量可以是两分类的,也可以使连续性变量,然后按你给出的分界点一分为二。
Runs Test:用于检验样本序列随机性。
观察某变量的取值是否是围绕着某个数值随机地上下波动,该数值可以是均数、中位数、众数或人为制定。
一般来说,如果该检验P值有统计学意义,则提示有其他变量对该变量的取值有影响,或该变量存在自相关。
One-Sample Kolmogorov-Smirnov Test:采用柯尔莫哥诺夫-斯米尔诺夫检验来分析变量是否符合某种分布,可以检验的分布有正态分布、均匀分布、Poission分布和指数分布。
2、分布位置检验方法:用于检验样本所在总体的分布位置/形状是否相同。
具体包括:Two-Independent-Samples Tests:即成组设计的两独立样本的秩和检验。
Tests for Several Independent Samples:成组设计的多个独立样本的秩和检验,此处不提供两两比较方法。


非参数检验知识引入比较两个总体间的差异,我们比较熟悉的是可依据总体方差是否已知,选择使用正态Z检验或t检验法。
但如果有明显的证据表明,这些参数型检验法不能使用时又该如何呢?非参数检验法对此提供了解决方案。
作为参数检验的一种推广,非参数检验有何特点?它的使用有什么样的要求?本章首先对非参数检验进行概述,接着按照和参数检验对应的原则分别介绍用于两组比较的非参数检验法和用于多组比较的非参数检验法。
第一节非参数检验概述假设检验分为参数检验和非参数检验。
参数检验是在已知总体分布的条件下(一般要求总体服从正态分布)对一些主要的参数(如均值、百分数、方差、相关系数等)进行的检验,有时还要求某些总体参数满足一定条件。
如独立样本的T检验和方差分析不仅要求总体符合正态分布,还要求各总体方差齐性。
教材第八章之前所介绍的统计方法都是参数检验法。
非参数检验则不考虑总体分布是否已知,常常也不是针对总体参数,而是针对总体的某些一般性假设(如总体分布的位置是否相同,总体分布是否正态)进行检验。
非参数检验方法简便,不依赖于总体分布的具体形式因而适用性强,但灵敏度和精确度不如参数检验。
一般而言,非参数检验适用于以下三种情况:①顺序类型的数据资料,这类数据的分布形态一般是未知的;②虽然是连续数据,但总体分布形态未知或者非正态,这和卡方检验一样,称自由分布检验;③总体分布虽然正态,数据也是连续类型,但样本容量极小,如10以下(虽然T检验被称为小样本统计方法,但样本容量太小时,代表性毕竟很差,最好不要用要求较严格的参数检验法)。
因为这些特点,加上非参数检验法一般原理和计算比较简单,因此常用于一些为正式研究进行探路的预备性研究的数据统计中。
当然,由于非参数检验许多牵涉不到参数计算,对数据中的信息利用不够,因而其统计检验力相对参数检验也差得多。
前面所学到的参数检验法在非参数法中都能找到替代的方法,因此按照和参数检验法相对应的原则可对非参数检验法进行如下分类:第二节非参数两组比较法该类方法实际上对应两总体比较的t检验法。


SPSS中非参数检验方法的使用SPSS中非参数检验方法的使用统计软件包SPSS给统计工作者提供了很大方便,SPSS for Windows版本推出后,使用者无需编写程序也可完成分析,使用更广泛了。
然而,面对软件包提供的众多统计过程(或方法),有些使用者感到迷惘。
针对这种情况,本文就如何正确使用SPSS for Windows软件包中Nonparametric Tests过程清单提供的8个非参数检验过程(或方法)逐一介绍。
一、Chi-SquareChi-Square是对单个样本作检验的推断方法,用于推断目前掌握的样本是否来自某特定分布总体,属拟合优度检验〔1〕。
要求提供假定总体的理论频数;默认总体为均匀分布时无需提供理论频数〔2〕。
Chi-Square过程通过分析实际频数与理论频数吻合的程序来完成检验,因此特别适合于频数资料的分析,也只接受和处理频数资料,如病人经治疗后治愈、好转、有效和无效的人数总的说来是否相同(实为治愈、好转、有效和无效的概率或机会是否相同),成绩优、良、中、差的学生人数总的说来是否相同,赞同某种观点的人数总的说来是否达到80%,等等。
要求样本足够大,按观察值从小到大的顺序提供理论频数。
理论频数通过主对话框中Expected Values的Values选项提供,All categories equal是默认项,即均匀分布。
若只想推断样本中某一范围内的频数是否来自某种特定分布总体,可通过主对话框中ExpectedRange的Use speciffied range选项提供范围的上、下限。
上述理论频数需根据假定总体分布计算或问题的实际背景确定。
二、BinomialBinomial过程对二值变量的单个样本作检验,推断总体中两类个体的比例是否分别为π和(1-π),π值通过T est Proportion选项提供,默认值是π=0.5〔2〕。
可借助于主对话框中Define Dichotomy的Cut point选项提供截断点,将连续变量转化成二值变量作分析;若提供的变量已经是二值变量,则不需提供截断点。

第十二章 非参数检验――Nonparametric Tests菜单详解(医学统计之星:张文彤)§12.1 概论作为二十一世纪统计理论的三大发展方向之一,非参数统计是统计分析的重要组成部分。
可是与之很不相称的是他针对一般性统计分析的理论发展远远不及参数检验完善,因而比较完善的可供使用的方法也不多。
比如多组均数间的两两比较,虽然已有好几种方法可资利用,但由于在理论上仍存在争议,几种权威的统计软件(如SAS和SPSS)均没有提供这方面的方法。
虽然这些洋统计软件没有提供两两比较的非参数方法,但国产的统计软件大都是提供了的(国情不同嘛),因此建议大家:如果真的要做这方面的非参数分析,不如直接用PEMS、SPLMWIN、NOSA等国产软件,免得用SPSS等只能做一半。
在SPSS中,几乎所有的非参数分析方法都被放入了Nonparametric Tests菜单中,具体来讲有以下几种:∙Chi-square test:用卡方检验来检验变量的几个取值所占百分比是否和我们期望的比例没有统计学差异。
比如我们在人群中抽取了一个样本,可以用该方法来分析四种血型所占的比例是否相同(都是25%),或者是否符合我们所给出的一个比例(如分别为10%、30%、40%和20%,我随便写的)。
请注意该检验和我们一般所用的卡方不太一样,我们一般左的卡方要用crosstable菜单来完成,而不是这里。
∙Binomial Test:用于检测所给的变量是否符合二项分布,变量可以是两分类的,也可以使连续性变量,然后按你给出的分界点一刀两断。
∙Runs Test:用于检验某变量的取值是否是围绕着某个数值随机地上下波动,该数值可以是均数、中位数、众数或人为制定。
一般来说,如果该检验P值有统计学意义,则提示有其他变量对该变量的取值有影响,或该变量存在自相关。
∙One-Sample Kolmogorov-Smirnov Test:采用柯尔莫诺夫-斯米尔诺夫检验来分析变量是否符合某种分布,可以检验的分布有正态分布、均匀分布、Poission分布和指数分布。
非参数检验非参数统计分析方法(Non-parametric statistics)是相对参数统计分析方法而言的,又称为不拘分布(distribution-free statistics)的统计分析方法或无分布形式假定(assumption free statistics)的统计分析方法。
其中包括Wilcoxon秩和检验、Kruskal-Wallis秩和检验、friedman秩和检验等,它们分别对应不同设计类型的资料。
SAS中对于非参数分析方法功能的实现主要由npar1way过程来完成,从过程名字就可以看出,在此过程的处理进程中,只能一次指定一个因素进行分析。
下面我们先来了解一下npar1way过程的语句格式以及各语句和选项的基本功能。
一、npar1way过程语句格式简介npar1way过程属于SAS的STAT模块,对于统计学教科书上所涉及的非参数统计方法几乎都可以通过此过程来完成。
Npar1way过程的基本语句格式如下。
PROC NPAR1WAY <选项> ;BY 变量名;CLASS变量名;EXACT 统计量选项 </ 运算选项 > ;FREQ变量名;OUTPUT < OUT=数据集名 > < 选项 > ;VAR 变量名;RUN;QUIT;Proc npar1way语句标志npar1way过程的开始,默认情况下(不列举任何选项):npar1way过程对最新创建的数据集进行分析,将缺失数据排除在分析过程之外;执行方差分析过程(等同于ANOVA选项),对样本分布位置的差异进行检验(与选项WILCOXON, MEDIAN, SAVAGE以及VW等效),并进行经验分布函数检验(等同于EDF选项)。
此语句后可用的选项见下表。
Proc npar1way语句选项及其含义1. exact 语句exact 语句要求SAS 对指定的统计量(选项)进行精确概率的计算。
其后的统计量选项可为以下项目,分别对应相应的统计计算方式(可参见上表)。
非参数统计分析――Nonparametric Tests菜单详解非参数统计分析――Nonparametric Tests菜单详解平时我们使用的统计推断方法大多为参数统计方法,它们都是在已知总体分布的条件下,对相应分布的总体参数进行估计和检验。
比如单样本u检验就是假定该样本所在总体服从正态分布,然后推断总体的均数是否和已知的总体均数相同。
本节要讨论的统计方法着眼点不是总体参数,而是总体分布情况,即研究目标总体的分布是否与已知理论分布相同,或者各样本所在的分布位置/形状是否相同。
由于这一类方法不涉及总体参数,因而称为非参数统计方法。
SPSS的的Nonparametric Tests菜单中一共提供了8种非参数分析方法,它们可以被分为两大类:1、分布类型检验方法:亦称拟合优度检验方法。
即检验样本所在总体是否服从已知的理论分布。
具体包括:Chi-square test:用卡方检验来检验二项/多项分类变量的几个取值所占百分比是否和我们期望的比例有没有统计学差异。
Binomial Test:用于检测所给的变量是否符合二项分布,变量可以是两分类的,也可以使连续性变量,然后按你给出的分界点一分为二。
Runs Test:用于检验样本序列随机性。
观察某变量的取值是否是围绕着某个数值随机地上下波动,该数值可以是均数、中位数、众数或人为制定。
一般来说,如果该检验P值有统计学意义,则提示有其他变量对该变量的取值有影响,或该变量存在自相关。
One-Sample Kolmogorov-Smirnov Test:采用柯尔莫哥诺夫-斯米尔诺夫检验来分析变量是否符合某种分布,可以检验的分布有正态分布、均匀分布、Poission分布和指数分布。
2、分布位置检验方法:用于检验样本所在总体的分布位置/形状是否相同。
具体包括:Two-Independent-Samples Tests:即成组设计的两独立样本的秩和检验。
Tests for Several Independent Samples:成组设计的多个独立样本的秩和检验,此处不提供两两比较方法。
Two-Related-Samples Tests:配对设计的两样本秩和检验。
Tests for Several Related Samples:配伍设计的多样本秩和检验,此处同样不提供两两比较。
一、分布位置检验方法1、Two Independent Samples Test与 K Independent Samples Test用于检验两独立样本/多独立样本所在总体是否相同。
Two-lndependent-Samples Test对话框:(1) Test Variable框,指定检验变量。
(2) Grouping Variable框,指定分组变量。
Define Groups对话框,Groupl和Groupl后的栏中,可指定分组变量的值。
(3) TestType框,确定用来进行检验的方法。
Mann-Whitney U:默认值,相当于两样本秩和检验。
Kolmogorov-Smimov Z:K-S检验的一种。
Moses extreme reactions:如果施加的处理使得某些个体出现正向效应,而另一些个体出现负向效应,就应当采用该检验方法。
Wald-Wolfowitz runs:游程检验的一种,检验总体分布是否相同。
(4) Options对话框,选择输出结果形式及缺失值处理方式。
多个独立样本检验中不同之处:Define Range对话框,定义分组变量值范围。
Minimum:分组变量范围的下限。
Maximum:上限。
Test Type框,确定用来进行检验的方法。
Kruskal-WallisH:默认值,单向方差分析,检验多个样本在中位数上是否有差异; Median:中位数检验,检验多个样本是否来自具有相同中位数的总体。
2、Two Related Samples Test与 K Related Samples TestTwo Related Samples Test是考察配对样本的总体分布是否相同,或者说差值总体是否以0为中心分布;K Related Samples Test则用于检验多个配伍样本所在总体的分布是否相同。
Two-Related-SamplesTests对话框:(1)Test Pair(s)List框,指定检验变量对。
可有多对。
(2)TestType框,确定检验的方法。
Wilcoxon:默认值,配对设计差值的秩和检验,利用次序大小。
Sign:符号检验,利用正负号。
McNemar:配对卡方检验,适用于两分类资料,特别适合自身对照设计。
Marginal Homogeneity:适用于资料为有序分类情况。
(3)Options对话框中,选择输出结果形式及缺失值处理方式,K Related SamplesTest 用于多组间的非参数检验,不同之处在于:A、比较方法不同:☆ Friedman:系统默认值,即最常用的随机区组设计资料的秩和检验,也被称为M检验。
☆ Kendall's W:该指标也被称为Kendall和谐系数,它表示的是K个指标间相互关联的程度(一致性程度),取值在0~1之间。
☆ Cochrarl's Q:是两相关样本McNemar检验在多样本情形下的推广,只适用于二分类变量。
B、Statistics对话框: Descriplive,描述统计量。
Quartiles,四分位数。
二、分布类型检验方法原理:计算实际分布与理论分布间的差异,根据某种统计量求出 P 值。
1、Chi-square test与行×列表卡方检验区别:Chi-square test是检验分类数据样本所在总体分布(各类别所占比例)是否与已知总体分布相同,是一个单样本检验。
行×列表卡方检验是比较两个分类资料样本所在的总体分布是否相同,在spss中要用crosstable菜单来完成。
具体做法:先按照已知总体的构成比分布计算出样本中各类别的期望频数,然后求出观测频数与期望频数的差值,最后计算出卡方统计量,利用卡方分布求出P值,得出检验结论。
例某地一周内各日死亡数的分布如表所示,请检验一周内各日的死亡危险性是否相同周日一二三四五六日死亡数 11 19 17 15 15 16 19数据文件为:day 周日,death 死亡数。
Chi-Square Test对话框:(1)Test Variable List框,指定检验变量,可为多个变量。
(2)ExpectedRange栏,确定检验值的范围。
Get from data选项,即最小值和最大值所确定的范围,系统默认该项。
Use specified range选项,只检验数据中一个子集的值,在Lower和Upper参数框中键入检验范围的下限和上限。
(3)ExpectedValues栏,指定期望值。
All categories equal选项,系统默认的检验值是所有组对应的期望值都相同,这意味着你要检验的总体是否服从均匀分布。
Values选项,选定所要检验的与总体是否服从某个给定的分布,并在其右边的框中键人相应各组所对应的由给定分布所计算而得的期望值。
“Add”按钮,增加刚键入的期望值,必须大于0。
“Remove”按钮,移走错误值。
“Change”按钮,替换错误值。
(4)Options对话框。
A、Statistics栏,选择输出统计量。
Descriptive:输出变量的均值、标准差、最大值、最小值、非缺失个体的数量。
Quartiles 复选项,输出结果将包括四分位数的内容。
显示第25、50与75百分位数。
B、在MissingValues栏中选择对缺失值的处理方式。
具体操作如下:Data →Weight Case → Weight Case by:→ Frequency Variable: death →OK;Analyze→Nonparametic Test→Chi-Square→Test variable list:day→OK。
卡方值X2=,自由度(DF)=6,P=,可认为一周内各日的死亡性是相同的。
2、Binomial Test(二项分布检验)调用Binomial过程可对样本资料进行二项分布分析,检验二项分类变量是否来自概率为P的二项分布。
例5-2 某地某一时期内出生40名婴儿,其中女性12名(Sex=0),男性28名(sex=1)。
问该地出生婴儿的性比例与通常的男女性比例(总体概率约为是否不同数据文件为。
Binomial Test对话框:(1) Test Variable框,指定检验变量。
(2) Define Dichotomy栏,定义二分值。
Get from data选项,适用于指定的变量只有两个有效值,无缺失值。
Cut point选项,如果指定的变量超过两个值,选择该项,并在参数框中键入一个试算点的值。
(3)Test参数框,指定检验概率值。
默认的检验概率值是,这意味着要检验的二项是服从均匀分布的。
(3) Options对话框,选择输出结果形式及缺失值处理方式。
具体操作如下:Binomial TestTest → Test Variable List → sex → Test Proportion →→OK。
二项分布检验表明,女婴12名,男婴28名,观察概率为(即男婴占70%,检验概率为,二项分布检验的结果是双侧概率为,可认为男女比例的差异有高度显著性,即与通常的的性比例相比,该地男婴比女婴明显多。
3、Runs Test(游程检验)一个游程是指某序列中同类元素的一个持续的最大主集,或者说一个游程是指依时间或其他顺序排列的有序数列中,具有相同的事件或符号的连续部分。
游程检验用于检验样本或任何序列的随机性。
例5-3 某村发生一种地方病,其住户沿一条河排列,调查时对发病的住户标记为1,非发病住户为0,共26户,如下表所示。
0 1 1 0 0 0 1 0 0 1 0 O 0 0 1 1 O 0 1 0 0 0 0 1 0 l数据文件为:住户变量为epi。
Runs Test 对话框:(1) Test Variable框,指定检验变量。
(2) Cut Point栏,确定划分二分类的试算点。
中位数、众数、均数及用户指定临界割点。
(3) Options对话框,选择输出结果形式及缺失值处理方式。
具体操作如下:Runs Test → Test Variable → epi → 1 → OK从检验结果可见,本例游程个数为14,小于1有17个案例;而大于或等于1有9个案例。
Z=,双尾检验概率P=。
所以认为此地方病的病户沿河分布的情况无聚集性,而是呈随机分布。
4、单样本K-S检验又称单样本柯尔莫哥洛夫-斯米诺夫检验(one-sample Kolmogorov-Smirmov tes)。