HASH函数
- 格式:pdf
- 大小:234.28 KB
- 文档页数:41

什么是哈希函数哈希(Hash)函数在中文中有很多译名,有些人根据Hash的英文原意译为“散列函数”或“杂凑函数”,有些人干脆把它音译为“哈希函数”,还有些人根据Hash函数的功能译为“压缩函数”、“消息摘要函数”、“指纹函数”、“单向散列函数”等等。
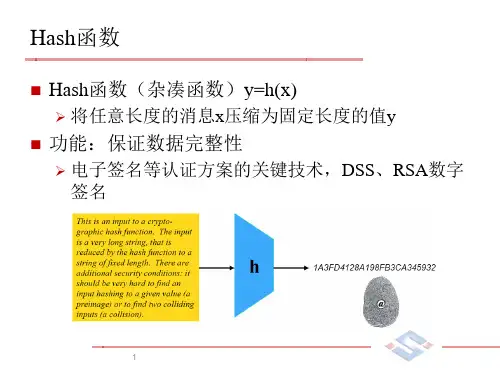
1、Hash算法是把任意长度的输入数据经过算法压缩,输出一个尺寸小了很多的固定长度的数据,即哈希值。
哈希值也称为输入数据的数字指纹(Digital Fingerprint)或消息摘要(Message Digest)等。
Hash函数具备以下的性质:2、给定输入数据,很容易计算出它的哈希值;3、反过来,给定哈希值,倒推出输入数据则很难,计算上不可行。
这就是哈希函数的单向性,在技术上称为抗原像攻击性;4、给定哈希值,想要找出能够产生同样的哈希值的两个不同的输入数据,(这种情况称为碰撞,Collision),这很难,计算上不可行,在技术上称为抗碰撞攻击性;5、哈希值不表达任何关于输入数据的信息。
哈希函数在实际中有多种应用,在信息安全领域中更受到重视。
从哈希函数的特性,我们不难想象,我们可以在某些场合下,让哈希值来“代表”信息本身。
例如,检验哈希值是否发生改变,借以判断信息本身是否发生了改变。
`怎样构建数字签名好了,有了Hash函数,我们可以来构建真正实用的数字签名了。
发信者在发信前使用哈希算法求出待发信息的数字摘要,然后用私钥对这个数字摘要,而不是待发信息本身,进行加密而形成一段信息,这段信息称为数字签名。
发信时将这个数字签名信息附在待发信息后面,一起发送过去。
收信者收到信息后,一方面用发信者的公钥对数字签名解密,得到一个摘要H;另一方面把收到的信息本身用哈希算法求出另一个摘要H’,再把H和H’相比较,看看两者是否相同。
根据哈希函数的特性,我们可以让简短的摘要来“代表”信息本身,如果两个摘要H和H’完全符合,证明信息是完整的;如果不符合,就说明信息被人篡改了。



C语言Hash用法什么是Hash函数在计算机科学中,Hash函数是一种将数据映射到固定大小值的函数。
Hash函数将输入数据(也称为键)映射到一个较小的固定大小的值(也称为哈希值或散列值)。
这个哈希值通常用于快速查找数据结构中的键,例如哈希表。
Hash函数的输出被称为哈希码或散列码。
Hash函数的设计要求是保证输入数据相同,输出的哈希值也相同,而输入数据不同,输出的哈希值也不同。
此外,好的Hash函数应该尽量避免碰撞,即不同的输入数据映射到相同的哈希值。
C语言中的Hash函数在C语言中,没有内置的Hash函数,但我们可以使用一些常见的算法来实现自己的Hash函数。
以下是一些常用的Hash函数算法:1. 直接寻址法直接寻址法是最简单的Hash函数实现方法之一。
它将键直接用作哈希值,即哈希值等于键本身。
这种方法适用于键与哈希表大小相等的情况,但在键的范围很大时不太实用。
unsigned int direct_addressing_hash(int key) {return key;}2. 数字分析法数字分析法是一种根据键的某些特定数字特征来计算哈希值的方法。
例如,如果键是一个电话号码,我们可以用电话号码的前几位数字作为哈希值。
unsigned int digit_analysis_hash(int key) {// 获取键的前几位数字unsigned int hash = 0;while (key > 0) {hash = key % 10;key /= 10;}return hash;}3. 除留余数法除留余数法是一种常用的Hash函数实现方法。
它将键除以哈希表的大小,然后取余数作为哈希值。
unsigned int division_remainder_hash(int key, unsigned int table_size) { return key % table_size;}4. 平方取中法平方取中法是一种将键的平方值的中间几位作为哈希值的方法。



哈希函数名词解释哈希函数(hash function)是解决密码学上的一个很有用的函数,它能将很多不同的信息结合成一个特征向量。
分组密码体制是数据加密和解密所采用的主要方法,是指把需要加密的文件分为若干组,每组给定一个加密密钥,对这些文件进行加密,其余部分对外宣称是无密文件。
这种方法安全性较高,但效率低下,因此,只在少数场合使用。
哈希函数也可用于对任意长度的数据块进行加密,例如,使用一个512位的字符数组,即可将信息长度扩展至32766位(1K字节),因而使用计算机中的哈希函数对任意大小的信息块都可以进行加密,不再受限于密码长度。
哈希函数的基本原理是:根据文件或数据块的特征,生成一个32位的特征向量(公钥),对该特征向量计算,得到两个32位的特征向量(私钥)。
这两个向量相减就是文件或数据块的密文,如果两个特征向量之和等于所要求的密文,那么这个文件或数据块就是被加密了的;否则就是未加密的。
当然,如果特征向量相减后的值不等于所要求的密文,则说明这个文件或数据块还没有被加密。
1.数据预处理方法。
一般分为三步进行:首先,计算数据的安全哈希值,称作SHA1(sha-1)值;其次,对哈希值和文件加密密钥进行比较,以确认哈希值的正确性;最后,用哈希值来加密数据,哈希值就是加密数据的公钥。
2.数据加密方法。
一般包括数据分组、密钥预处理、哈希函数三步:首先对分组数据进行加密;其次是对加密后的数据进行分组;第三步是选取一个具有足够密钥长度并且具有适当排列顺序的哈希函数对数据进行加密。
2.1.1.1.数据分组方法。
分组时,按哈希函数值的大小对分组后的数据块逐个编号,并且使用固定的哈希函数值,作为下一轮分组和计算哈希值的依据。
这样做,可以保证数据被加密的安全性和实现简单。
2.1.2.1.密钥预处理方法。
密钥预处理时,要按哈希函数值从大到小的顺序进行,先对大的密钥执行密钥变换,再将小密钥插入到大的密钥中去。
同时,由于密钥预处理使用了小密钥,为提高哈希值计算速度,要尽量降低小密钥长度,常用的密钥变换有“距离变换”和“数据变换”。


harsh函数-概述说明以及解释1.引言1.1 概述概述部分的内容可以描述一下harsh函数是什么以及它的重要性和作用。
可以参考以下内容:概述:随着计算机科学的快速发展,数据安全和隐私保护变得尤为重要。
在这个数字化时代,我们需要一种可靠的方法来保护数据的完整性和安全性。
在这方面,hash函数扮演着至关重要的角色。
Hash函数是一种常见的密码算法,主要用于将数据转换为固定长度的字符串。
它通过对任意长度的数据应用哈希算法,生成一个唯一的哈希值。
这个哈希值可以用来验证数据的完整性,检测数据的变化和确定数据的唯一性。
在hash函数的世界里,harsh函数是一种特殊类型的hash函数,它具有许多独特的特点和优势。
与传统的hash函数相比,harsh函数不仅具有更高的效率和更低的冲突率,还可以提供更好的数据安全性和隐私保护。
harsh函数的工作原理是将输入数据通过一系列复杂而精确的计算,转换为一个唯一的哈希值。
这个哈希值具有不可逆的特性,即无法通过哈希值来恢复原始数据。
这种不可逆的特性使得harsh函数成为密码学中重要的工具,广泛应用于数字签名、数据验证、身份验证等各个领域。
此外,harsh函数还具有较低的碰撞概率,即不同的输入数据生成相同哈希值的概率非常低。
这使得harsh函数在数据完整性验证等关键应用场景中更加可靠。
另外,harsh函数还具有良好的计算性能和效率,使得它能够承担大规模数据处理的任务。
总的来说,harsh函数在确保数据安全性和完整性方面发挥着重要作用。
它的独特特性使其在各个领域得到广泛应用,同时也推动了数据安全和密码学的发展。
未来,随着计算机技术的不断进步,人们对于更加高效和安全的harsh函数算法的需求也将不断增加。
1.2文章结构文章结构部分的内容可以描述整篇文章的组织架构和章节安排:在本文中,我将按照如下结构来阐述关于harsh函数的相关知识。
首先,我将在引言部分进行概述,简要介绍harsh函数的定义、背景和应用领域。

常用的哈希函数1. 定义哈希函数(Hash Function)是一种将任意大小的数据映射到固定大小值的函数。
它接收输入数据,经过计算后生成一个固定长度的哈希值(也称为散列值或摘要)。
哈希函数具有以下特点:•输入数据可以是任意长度的•输出的哈希值长度固定•相同输入产生相同输出•不同输入产生不同输出•哈希值不能被逆向计算出原始输入2. 用途2.1 数据完整性校验哈希函数可以用于校验数据的完整性,确保数据在传输或存储过程中没有被篡改。
发送方在发送数据之前,通过计算数据的哈希值并将其附加到数据中。
接收方在接收到数据后,重新计算接收到数据的哈希值,并与附加的哈希值进行比较。
如果两个哈希值一致,则说明数据没有被篡改。
2.2 密码存储和验证在用户注册和登录系统时,通常需要对用户密码进行存储和验证。
为了保护用户密码,在存储时可以使用哈希函数对密码进行散列处理,并将散列后的结果存储在数据库中。
当用户登录时,系统会对用户输入的密码进行哈希处理,并与数据库中存储的散列值进行比较,以验证密码的正确性。
2.3 数据唯一标识哈希函数可以将数据映射为唯一的哈希值,用作数据的唯一标识符。
在分布式系统中,可以使用哈希函数将数据分配到不同的节点上,实现负载均衡和高效查询。
2.4 加密和数字签名哈希函数在加密和数字签名领域也有广泛应用。
例如,在数字证书中,哈希函数用于生成证书的签名,以确保证书的完整性和真实性。
在对称加密算法中,哈希函数用于生成消息认证码(MAC)来保证数据完整性。
3. 常见的哈希函数3.1 MD5(Message Digest Algorithm 5)MD5是一种广泛使用的哈希算法,它接收任意长度的输入,并输出128位(16字节)长度的哈希值。
MD5具有以下特点:•高度不可逆:无法通过已知的MD5值反推出原始输入•快速计算:对于给定输入,计算MD5值非常快速•冲突概率较高:由于固定输出长度限制,在大量数据中存在可能产生相同MD5值(冲突)的概率MD5的应用已经逐渐减少,因为其安全性较低。
哈希函数(hash函数)
hash,—般译为“散列”,也可以直接⾳译为“哈希”,是对输⼊的任意长度(⼜称预映射),通过哈希算法,转换成固定长度的哈希值输出。
这种转换是⼀种压缩映射,即,哈希值空间通常⽐输⼊空间⼩得多,不同的输⼊可能会散列到相同的输出,但对于给定的⼀个散列值,⽆法唯⼀确定其输⼊值,也就是说这个过程是不可逆的。
简单的说就是⼀种将任意长度的消息⽤⼀个固定长度的消息摘要函数来概括。
hash值可以通过公式h=H(M)计算。
⼀般来说,函数应该满⾜以下条件:
(1)Hash可⽤于任意⼤⼩的数据块;
(2)hash可以接受任意长度的信息,并将其输出成固定长度的消息摘要;
(3)单向性。
给定⼀个输⼊M,⼀定有⼀个h与其对应,满⾜H(M)=h,反之,则不⾏,算法操作是不可逆的。
(4)抗碰撞性。
给定⼀个M,要找到⼀个M’满⾜是不可H(M)=H(M’)是不可能的。
即不能同时找到两个不同的输⼊使其输出结果完全⼀致。
(5)低复杂性:算法具有运算的低复杂性。
什么是Hash?什么是Hash算法或哈希函数?什么是map?什么是HashMap?Hash。
1、什么是HashHash也称散列、哈希,对应的英⽂都是Hash。
基本原理就是把任意长度的输⼊,通过Hash算法变成固定长度的输出。
这个映射的规则就是对应的Hash算法,⽽原始数据映射后的⼆进制串就是哈希值。
2.什么是Hash算法或哈希函数?(1)Hash函数(Hash算法):在⼀般的线性表、树结构中,数据的存储位置是随机的,不像数组可以通过索引能⼀步查找到⽬标元素。
为了能快速地在没有索引之类的结构中找到⽬标元素,需要为存储地址和值之间做⼀种映射关系h(key),这个h就是哈希函数,⽤公式表⽰:h(key)=Addrh:哈希函数key:关键字,⽤来唯⼀区分对象的把线性表中每个对象的关键字通过哈希函数h(key)映射到内存单元地址,并把对象存储到该内存单元,这样的线性表存储结构称为哈希表或散列表。
(2)在设置哈希函数时,通常要考虑以下因素: ○计算函希函数所需的时间 ○关键字的长度 ○哈希表的长度 ○关键字的分布情况 ○记录的查找频率(3)Hash碰撞的解决⽅案①链地址法链表地址法是使⽤⼀个链表数组,来存储相应数据,当hash遇到冲突的时候依次添加到链表的后⾯进⾏处理。
链地址在处理的流程如下:添加⼀个元素的时候,⾸先计算元素key的hash值,确定插⼊数组中的位置。
如果当前位置下没有重复数据,则直接添加到当前位置。
当遇到冲突的时候,添加到同⼀个hash值的元素后⾯,⾏成⼀个链表。
这个链表的特点是同⼀个链表上的Hash值相同。
java的数据结构HashMap使⽤的就是这种⽅法来处理冲突,JDK1.8中,针对链表上的数据超过8条的时候,使⽤了红⿊树进⾏优化。
②开放地址法开放地址法是指⼤⼩为 M 的数组保存 N 个键值对,其中 M > N。
我们需要依靠数组中的空位解决碰撞冲突。
基于这种策略的所有⽅法被统称为“开放地址”哈希表。
哈希函数的含义哈希函数(Hash Function)是一种用于加密、检索、索引和验证数据完整性的算法。
它接收一个输入数据(通常是一段文本),并输出一个固定长度、不可逆的哈希值作为结果。
这个哈希值通常被用于代表输入数据。
哈希函数主要用于密码学、数据结构、网络安全等领域。
1. 哈希函数是一种单向函数。
即从哈希值无法推算出原始输入数据。
2. 不同的输入数据会产生不同的哈希值,相同的输入数据产生相同的哈希值。
3. 哈希值的长度是固定的,通常是32位或64位。
4. 即使输入数据的长度不同,生成的哈希值长度是一样的。
哈希函数的应用非常广泛,在计算机领域中常用的应用包括:1. 数据加密:哈希函数可以用来对明文进行加密。
将明文输入哈希函数中,产生的哈希值便可以作为密文,用以保护数据的隐私性。
2. 数据完整性检测:通过对数据进行哈希运算,得到一段固定长度的哈希值。
如果数据被篡改,哈希值也会发生变化,从而实现对数据完整性的检查。
3. 数据索引:哈希函数可以将数据映射到一个固定范围的哈希表中。
这样可以快速地在哈希表中查找、删除、修改数据。
4. 身份验证:将用户的密码进行哈希运算,得到一段哈希值保存在数据库中。
当用户输入密码时,将其通过哈希函数运算后,再与数据库中保存的哈希值进行比较,以验证用户身份。
哈希函数主要包括MD5、SHA1、SHA256等。
MD5和SHA1已经被证明是不安全的,因为它们易于被暴力破解。
所以,在安全性要求较高的场合,通常使用SHA256等更安全的哈希函数。
哈希函数是一种十分重要的算法,它在加密、数据完整性检测、数据索引、身份验证等领域都有着广泛的应用。
也需要注意选择安全可靠的哈希函数,以保证数据的安全性。
哈希函数也常常用于信息摘要和数字签名等领域,以防止信息被篡改或冒充。
信息摘要是指通过哈希函数将任意长度的信息变换成固定长度的哈希值,并且只由信息摘要的接收方能够验证消息的完整性和真实性。
数字签名则是一种能够保证文档的完整性和真实性的保障措施,其中哈希值和消息的签名密钥一起被应用于对消息进行数字签名,以保证消息的真实不被篡改。
消息认证和散列(Hash)函数1 散列函数1.1散列函数的概念1.2 简单散列函数的构造1.3 作为消息认证的散列函数应具有的特性2 基于散列函数的消息认证方式2.1 对称密钥加密方式2.2 公开密钥与对称密钥结合的加密方式2.3公共秘密值方式在网络通信环境中,可能存在下述攻击:1.泄密:将消息透露给没有合法密钥的任何人或程序。
2.传输分析:分析通信双方的通信模式。
在面向连接的应用中,确定连接的频率和持续时间;在面向业务或无连接的环境中,确定双方的消息数量和长度。
3.伪装:欺诈源向网络中插入一条消息,如攻击者产生一条消息并声称这条消息是来自某合法实体,或者非消息接受方发送的关于收到或未收到消息的欺诈应答。
4.内容修改:对消息内容的修改,包括插入、删除、转换和修改。
5.顺序修改:对通信双方消息顺序的修改,包括插入、删除和重新排序。
6.计时修改:对消息的延时和重放。
7.发送方否认:发送方否认发送过某消息。
8.接收方否认:接收方否认接收到某消息。
其中,对付前两种攻击的方法属于消息保密性范畴;对付第3种至第6种攻击的方法一般称为消息认证;对如第7种攻击的方法属于数字签名;对付第8种攻击需要使用数字签名和为抗此种攻击而涉及的协议。
这样归纳起来,消息认证就是验证所收到的消息确实来自真正的发送方且未被修改的消息,它也可验证消息的顺序和及时性。
任何消息认证在功能上基本可看做有两层。
下层中一定有某种产生认证符的函数,认证符是一个用来认证消息的值;上层协议中将该函数作为原语使接收方可以验证消息的真实性。
产生认证符的函数类型通常可以分为以下三类:1.消息加密:整个消息的密文作为认证符。
2.Hash函数:它是将任意长的消息映射为定长的hash值得公开函数,以该hash 值作为认证符。
3.消息认证码(MAC):它是消息和密钥的公开函数,它产生定长的值,以该值作为认证符。
实际上消息认证码也属于Hash函数的范畴,它是带密钥的Hash函数。
密码学(第十三讲)HASH函数张焕国武汉大学计算机学院目录密码学的基本概念1、密码学2、古典、古典密码3、数据加密标准()DES)、数据加密标准(DES4、高级)AES)数据加密标准(AES高级数据加密标准(5、中国商用密码()SMS4)、中国商用密码(SMS46、分组密码的应用技术7、序列密码8、习题课:复习对称密码、公开密钥密码(11)9、公开密钥密码(目录公开密钥密码(22)1010、11、数字签名(1)12、数字签名(2)13、、HASH函数131414、15、15PKI技术1616、、PKI17、习题课:复习公钥密码18、总复习一、HASH 函数函数的概念的概念1、Hash Hash的作用的作用•Hash Hash码也称报文摘要码也称报文摘要。
•它具有极强的错误检测能力错误检测能力。
•用Hash Hash码作码作MAC ,可用于认证认证。
•用Hash Hash码辅助码辅助数字签名数字签名。
•Hash Hash函数可用于函数可用于保密保密。
一、HASH 函数的概念2、Hash Hash函数的定义函数的定义①Hash Hash函数将任意长的数据函数将任意长的数据M 变换为定长的码h ,记为记为::h=HASH(M)h=HASH(M)或或h=H(M)h=H(M)。
②实用性:对于给定的数据对于给定的数据M M ,计算,计算h=HASH(M)h=HASH(M)是是高效的。
③安全性安全性::•单向性:对给定的对给定的Hash Hash值值h ,找到满足H(x)H(x)==h 的x 在计算上是不可行的计算上是不可行的。
否则否则,,设传送数据为设传送数据为C=C=<<M ,H(M||K )>,K 是密钥。
攻击者可以截获攻击者可以截获C,C,求出求出Hash 函数的逆函数的逆,,从而得出M||S =H -1(C),然后从M 和M ||K即可即可得出得出K。
一、HASH 函数的概念2、Hash Hash函数的定义函数的定义③安全性安全性::•抗弱碰撞性:对任何给定的对任何给定的x x ,找到满足找到满足y≠x y≠x且H(x)=H(y)H(x)=H(y)的的y 在计算上是不可行的在计算上是不可行的。
否则否则,,攻击者可以截获报文M 及其Hash 函数值H(M),并找出另一报文M ′使得H(M ′)=H(M)。
这样攻击者可用M ′去冒充M ,而收方不能发现而收方不能发现。
•抗强碰撞性:找到任何满足H(x)=H(y)的偶对(x,y)在计算上是不可行的在计算上是不可行的。
一、HASH 函数的概念3、安全安全Hash Hash函数的一般结构函数的一般结构•Merkle Merkle提出了安全提出了安全Hash Hash函数主处理的一般结构函数主处理的一般结构•对数据压缩对数据压缩,,产生产生Hash Hash码码。
b 位分组位分组,,f 为压缩函数,L 轮链接迭代,n 位输出位输出。
f f f M 0M L -1M 1b 位b 位b 位n 位n 位n 位n 位IV=CV 0CV 1CV L -1HASH 值CV L一、HASH 函数的概念3、安全安全Hash Hash函数的一般结构函数的一般结构•分组:将输入分为L -1个大小为b 位的分组位的分组。
•填充:若第L -1个分组不足b 位,则将其填充为b 位。
•附加:再附加上一个表示输入的总长度分组。
•共L 个大小为b 位的分组位的分组。
•由于输入中包含长度由于输入中包含长度,,所以攻击者必须找出具有相同Hash 值且长度相等的两条报文值且长度相等的两条报文,,或者找出两条长度不等但加入报文长度后Hash 值相同的报文的报文,,从而增加了攻击的难度。
•目前大多数Hash 函数均采用这种结构。
二、SHA SHA--1 HASH 函数1、SHA 系列系列Hash Hash函数函数•SHA 系列系列Hash Hash函数函数是由美国标准与技术研究所(NIST)设计的设计的。
•1993年公布了SHA SHA--0(FIPS PUB 180180)),后来发现它不安全安全。
•1995年又公布了SHA SHA--1(FIPS PUB 180180--1)。
•2002年又公布了SHA SHA--2(FIPS PUB 180180--2)。
SHA SHA--2包括3个Hash Hash函数:函数:SHA SHA--256,SHA SHA--384,SHA SHA--512•2005年王小云给出一种攻击SHA SHA--1的方法的方法,,用269操作找到一个碰撞找到一个碰撞,,以前认为是280。
•NIST 打算2010年废弃SHA SHA--1。
二、SHA SHA--1 HASH 函数1、SHA 系列系列Hash Hash函数函数•SHA SHA--1是在MD MD55的基础上发展起来的的基础上发展起来的。
它采用Merkle Merkle提出了安全提出了安全Hash Hash结构结构。
已被美国政府和许多国际组织采纳作为标准。
•SHA SHA--1的输入为长度小于264位的报文,输出为160位的报文摘要,该算法对输入按512位进行分组位进行分组,,并以分组为单位进行处理处理。
2、SHA SHA--1的结构•采用采用Merkle Merkle提出了安全提出了安全Hash Hash结构结构输入填充初始化缓冲区主处理160位HASH 值二、SHA SHA--1 HASH 函数输出报文长度< 2643、运算算法⑴输入输入填充填充•目的是使填充后的报文长度满足目的是使填充后的报文长度满足::长度=448mod 512。
①填充方法是在报文后附加一个一个11和若干个和若干个00。
②然后附上表示填充前报文长度的64位数据(最高有效位在前)。
•若报文本身已经满足上述长度要求若报文本身已经满足上述长度要求,,仍然需要进行填充(例如例如,,若报文长度为若报文长度为448448位位,则仍需要填充则仍需要填充512512位位使其长度为使其长度为960960位位),因此填充位数在因此填充位数在11到512512之间之间。
二、SHA SHA--1 HASH 函数3、运算算法⑵初始化缓冲区•缓冲区由5个32位的寄存器(A ,B ,C ,D ,E )组成组成,,用于保存160位的中间结果和最终结果位的中间结果和最终结果。
•将寄存器初始化为下列32位的整数:A :67452301B :EFCDAB EFCDAB8989C :9898BADCFE BADCFE D :10325476E :C 3D 2E 1F 0注意:高有效位存于低地址注意:高有效位存于低地址。
二、SHA SHA--1 HASH 函数3、运算算法⑶主处理•主处理是SHA SHA--1HASH 函数的核心函数的核心。
•每次处理一个512位的分组,循环次数为填充后报文的分组数L 。
二、SHA SHA--1 HASH 函数3、运算算法⑶主处理•主处理的结构:f 为SHA SHA--1的压缩函数的压缩函数。
f ffBLK 0BLK L -1BLK 1512位512位512位160位160位160位160位IV=CV 0CV 1CV L -1HASH 值二、SHA SHA--1 HASH 函数CV L3、运算算法⑶主处理•压缩函数是主处理的核心压缩函数是主处理的核心。
•它由四层运算它由四层运算((每层20步迭代步迭代))组成组成,,四层的运算结构相同构相同。
•每轮的输入是当前要处理的512位的分组BLK 和160位缓冲区ABCDE 的内容的内容,,每层都对ABCDE 的内容更新的内容更新,,而且每轮使用的逻辑函数不同而且每轮使用的逻辑函数不同,,分别为f 1,f 2,f 3和f 4。
•第四层的输出与第一层的输入相加得到压缩函数的输出。
二、SHA SHA--1 HASH 函数二、SHA SHA--1 HASH 函数第一轮使用函数f 1第二轮使用函数f 2第三轮使用函数f 3第四轮使用函数f 4A B CD E A B CD E A B CD E A B CD E +++++CV i 160位BLK i 160位512位Cv i+1Cv i20步迭代20步迭代20步迭代20步迭代3、运算算法⑷输出•所有的L 个512位的分组处理完后,第L 个分组的输出即是160位的报文摘要位的报文摘要。
二、SHA SHA--1 HASH 函数3、运算算法⑸归纳•CV 0=IV (ABCDE 的初值的初值))•CV i+i+11=CV i0≤i ≤L -1CV i+i+11(0)=CV i (0)+A iCV i+i+11(1)=CV i (1)+B iCV i+i+11(2)=CV i (2)+C i CV i+i+11(3)=CV i (3)+D i CV i+i+11(4)=CV i (4)+E iz h =CV L二、SHA SHA--1 HASH 函数+ 为模232加法3、运算算法⑹压缩函数缺点:输出B=输入A输出D=输入C 输出E=输入DA 、C 、D 没有运算二、SHA SHA--1 HASH 函数ABC DE A B C D E++++f t <<5<<30W t K t3、运算算法⑹压缩函数•每步具有下述形式:A,B,C,D,E ←(E+f t (B,C,D)+(A<<(B,C,D)+(A<<55)+W t +K t ),A,(B<<),A,(B<<3030),C,D ),C,D •每轮对A,B,C,D,E 进行20次迭代次迭代,,四轮共80次迭代次迭代。
t 为迭代次数编号为迭代次数编号,,所以0≤t ≤79。
•其中其中,,f t (B,C,D)=第t 步使用的基本逻辑函数;<<s =32位的变量循环左移s 位W t =从当前分组BLK 导出的32位的字K t =加法常量加法常量,,共使用4个不同的加法常量个不同的加法常量。
+为模232加法二、SHA SHA--1 HASH 函数3、运算算法⑹压缩函数•逻辑函数f t每层使用一个逻辑函数每层使用一个逻辑函数,,其输入均为B,C,D(每个32位),输出为一个32位的字位的字。
定义分别为:第一层0≤t ≤19f 1=f t (B,C,D)=(B ∧C)∨(¬B ∧D)第二层20≤t ≤39f 2=f t (B,C,D)=B ⊕C ⊕D第三层40≤t ≤59f 3=f t (B,C,D)=(B ∧C)∨(B ∧D) ∨(C ∧D)第三层60≤t ≤79f 4=f t (B,C,D)=B ⊕C ⊕D•缺点:f 2和f 4都是线性函数。
二、SHA SHA--1 HASH 函数3、运算算法⑹压缩函数•加法常量K t每层使用一个加法常量每层使用一个加法常量。