非参数统计-趋势存在性检验
- 格式:ppt
- 大小:554.52 KB
- 文档页数:20

常用的非参数检验(NonparametricTests)总结非参数检验(Nonparametric tests)是统计分析方法的重要组成部分,它与参数检验共同构成统计推断的基本内容。
参数检验是在总体分布形式已知的情况下,对总体分布的参数如均值、方差等进行推断的方法。
但是,在数据分析过程中,由于种种原因,人们往往无法对总体分布形态作简单假定,此时参数检验的方法就不再适用了。
非参数检验正是一类基于这种考虑,在总体方差未知或知道甚少的情况下,利用样本数据对总体分布形态等进行推断的方法。
由于非参数检验方法在推断过程中不涉及有关总体分布的参数,因而得名为“非参数”检验。
•两独立样本的非参数检验两独立样本的非参数检验是在对总体分布不甚了解的情况下,通过对两组独立样本的分析来推断样本来自的两个总体的分布等是否存在显著差异的方法。
独立样本是指在一个总体中随机抽样对在另一个总体中随机抽样没有影响的情况下所获得的样本。
SPSS中提供了多种两独立样本的非参数检验方法,其中包括曼-惠特尼U检验、K-S检验、W-W游程检验、极端反应检验等。
某工厂用甲乙两种不同的工艺生产同一种产品。
如果希望检验两种工艺下产品的使用是否存在显著差异,可从两种工艺生产出的产品中随机抽样,得到各自的使用寿命数据。
甲工艺:675 682 692 679 669 661 693乙工艺:662 649 672 663 650 651 646 652(1)曼-惠特尼U检验两独立样本的曼-惠特尼U检验可用于对两总体分布的比例判断。
其原假设:两组独立样本来自的两总体分布无显著差异。
曼-惠特尼U 检验通过对两组样本平均秩的研究来实现判断。
秩简单说就是变量值排序的名次,可以将数据按升序排列,每个变量值都会有一个在整个变量值序列中的位置或名次,这个位置或名次就是变量值的秩。
(2)K-S检验K-S检验不仅能够检验单个总体是否服从某一理论分布,还能够检验两总体分布是否存在显著差异。


肯德尔趋势检验实例-概述说明以及解释1.引言1.1 概述在肯德尔趋势检验实例这篇长文中,本文将对肯德尔趋势检验进行介绍和应用实例的探讨。
肯德尔趋势检验是一种用于分析非参数趋势的统计检验方法,它可以帮助我们判断两个变量是否存在趋势关系。
该检验方法是根据数据中的排序信息进行计算的,因此不需要对数据的分布做出任何假设。
本文的目的是通过具体的实例来展示和解释肯德尔趋势检验的原理和应用。
我们将首先介绍肯德尔趋势检验的基本概念和原理,包括其计算公式和统计量的含义。
然后,我们会通过一个实际案例来说明肯德尔趋势检验的具体应用过程,并对结果进行解读和讨论。
文章将从引言开始,介绍本文的结构和目的,明确读者可以从本文中获得的信息和知识点。
接着,我们将在正文部分详细介绍肯德尔趋势检验的概念和原理,包括其适用范围、计算方法和统计量的含义。
在应用实例部分,我们将选择一个具体的数据集,对其进行分析和检验,以展示肯德尔趋势检验的实际应用。
最后,我们将总结本文的内容,并对肯德尔趋势检验的重要性进行讨论和评价。
通过本文的阅读,读者将能够了解肯德尔趋势检验的基本概念和原理,理解其在实际问题中的应用方法,并掌握如何解读和解释检验结果。
同时,读者还可以通过本文对肯德尔趋势检验的重要性的讨论,深入思考该方法在科学研究和决策分析中的价值和作用。
1.2文章结构文章结构是指文章的整体组织框架,有助于读者更好地理解和阅读全文。
在这篇文章中,我们将按照以下结构展开讨论:第一部分是引言,主要包括概述、文章结构和目的。
在这一部分,我们将提供对肯德尔趋势检验实例文章的简要介绍,明确文章的目标和结构,使读者能够更好地理解文章内容和组织架构。
第二部分是正文,分为两个小节。
2.1小节将详细介绍肯德尔趋势检验的概念、原理和相关背景知识。
我们将解释肯德尔趋势检验的基本原理和假设,并提供其计算公式和相关统计量的解释。
此外,我们还将介绍肯德尔趋势检验的一般步骤,以使读者了解如何进行该检验。

mann-kendall检验方法Mann-Kendall检验方法是一种常用的非参数统计方法,用于分析时间序列数据中的趋势特征。
时间序列数据是指按照一定时间顺序排列的数据,常见于气象、经济、环境等领域。
在这些领域中,我们常常需要分析数据中的趋势,以便预测未来的情况或制定相应的措施。
Mann-Kendall检验方法基于先验假设:原假设H0认为数据中不存在趋势,备择假设H1认为存在趋势。
该方法的核心思想是通过比较数据中各观测值的排列顺序,来判断数据中是否存在趋势。
Mann-Kendall检验的具体步骤如下:1.首先,给定一个时间序列数据,对于每个数据点,计算其与其他数据点的差值。
然后,根据差值的正负号,将原始数据点转换为+1或-12.然后,计算转换后的序列中连续的逆序对的数量(即逆序对数)。
逆序对是指序列中相邻两个数据点的顺序与转换后的序列中相应两个数据点的顺序不一致。
3.根据逆序对的数量,计算统计量Z。
其计算公式为:Z=(逆序对数-预期逆序对数)/标准差预期逆序对数和标准差的计算可以在文献中找到相应的公式。
4.最后,根据统计量Z的值,利用指定的显著性水平,判断是否拒绝原假设。
通常,当统计量的绝对值大于临界值时,可以拒绝原假设,认为数据中存在趋势。
Mann-Kendall检验方法的优点在于它不需要对数据的分布进行任何假设,适用于各种类型的时间序列数据。
另外,该方法还可以用于有缺失数据或不等间距观察的情况下。
然而,Mann-Kendall检验方法也存在一些限制。
首先,它只能检测数据中的单调趋势,无法检测非单调趋势。
其次,当数据存在季节性变化或周期性变化时,该方法可能会出现错误的判断结果。
为了提高Mann-Kendall检验的准确性和可靠性,我们可以结合其他统计方法进行分析。
例如,我们可以使用线性回归分析来拟合趋势线,然后使用Mann-Kendall检验来验证趋势的显著性。
总之,Mann-Kendall检验方法是一种常用的非参数统计方法,用于分析时间序列数据中的趋势特征。


mann-kendall趋势检验算法解读[mannkendall趋势检验算法解读]在环境科学、气象学、水文学等领域中,趋势分析是一种常用的统计方法,用来研究时间序列数据中的变化趋势和周期性变化。
Mann-Kendall趋势检验算法是一种常用的非参数方法,用来检测时间序列数据中的趋势变化。
本文将对Mann-Kendall趋势检验算法进行详细解读,介绍其原理、步骤和应用场景。
一、Mann-Kendall趋势检验算法的原理Mann-Kendall趋势检验算法是一种基于秩和统计量的非参数统计方法,用来检验时间序列数据中的单调趋势。
其原理基于观察到的数据值的等级秩次,而不是数据值本身,因此不需要对数据满足特定的分布要求。
其基本思想是对各个数据点进行两两比较,而不是与某个特定数值进行比较,从而能够有效地检测数据中的趋势变化。
二、Mann-Kendall趋势检验算法的步骤Mann-Kendall趋势检验算法包括以下步骤:1. 对观测数据进行排序,得到对应的秩次。
2. 计算各个数据点的等级秩次之差。
3. 计算秩次之差的累积和,并求出统计量的值。
4. 根据所得的统计量值,确定趋势的显著性水平。
5. 根据显著性水平,判断时间序列数据中是否存在趋势变化。
三、Mann-Kendall趋势检验算法的应用场景Mann-Kendall趋势检验算法适用于研究时间序列数据中的趋势变化,常见的应用场景包括但不限于以下几个领域:1. 气候变化研究:通过对气温、降雨量等气候要素的时间序列数据进行趋势分析,可以揭示气候变化的趋势和周期性变化,为气候变化的监测和预测提供依据。
2. 河流径流变化研究:通过对河流流量的时间序列数据进行趋势分析,可以了解河流径流的长期变化趋势,为水资源管理和水文预测提供参考。
3. 环境监测:通过对环境监测数据中的各项指标进行趋势分析,可以评估环境质量的变化趋势,为环境保护和治理提供科学依据。
四、Mann-Kendall趋势检验算法的优缺点Mann-Kendall趋势检验算法具有以下优点:1. 非参数方法:不要求数据满足特定的分布要求,适用范围广。
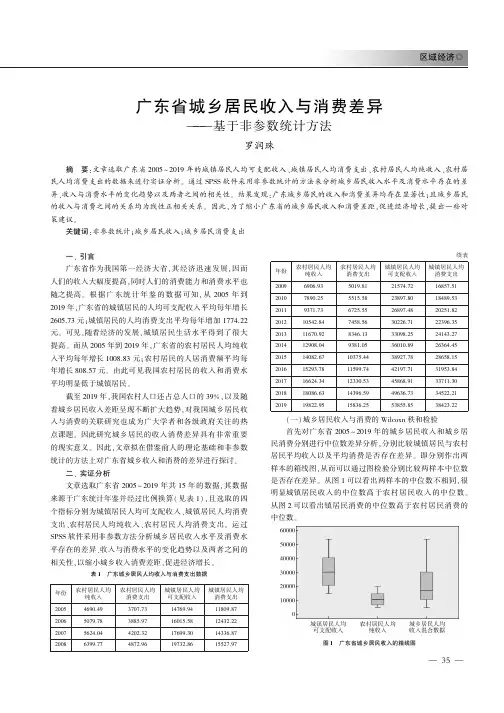
区域经济Һ㊀广东省城乡居民收入与消费差异基于非参数统计方法罗润珠摘㊀要:文章选取广东省2005~2019年的城镇居民人均可支配收入㊁城镇居民人均消费支出㊁农村居民人均纯收入㊁农村居民人均消费支出的数据来进行实证分析ꎮ通过SPSS软件采用非参数统计的方法来分析城乡居民收入水平及消费水平存在的差异㊁收入与消费水平的变化趋势以及两者之间的相关性ꎮ结果发现:广东城乡居民的收入和消费差异均存在显著性ꎻ且城乡居民的收入与消费之间的关系均为线性正相关关系ꎮ因此ꎬ为了缩小广东省的城乡居民收入和消费差距ꎬ促进经济增长ꎬ提出一些对策建议ꎮ关键词:非参数统计ꎻ城乡居民收入ꎻ城乡居民消费支出一㊁引言广东省作为我国第一经济大省ꎬ其经济迅速发展ꎬ因而人们的收入大幅度提高ꎬ同时人们的消费能力和消费水平也随之提高ꎮ根据广东统计年鉴的数据可知ꎬ从2005年到2019年ꎬ广东省的城镇居民的人均可支配收入平均每年增长2605.73元ꎻ城镇居民的人均消费支出平均每年增加1774.22元ꎮ可见ꎬ随着经济的发展ꎬ城镇居民生活水平得到了很大提高ꎮ而从2005年到2019年ꎬ广东省的农村居民人均纯收入平均每年增长1008.83元ꎻ农村居民的人居消费额平均每年增长808.57元ꎮ由此可见我国农村居民的收入和消费水平均明显低于城镇居民ꎮ截至2019年ꎬ我国农村人口还占总人口的39%ꎬ以及随着城乡居民收入差距呈现不断扩大趋势ꎬ对我国城乡居民收入与消费的关联研究也成为广大学者和各级政府关注的热点课题ꎮ因此研究城乡居民的收入消费差异具有非常重要的现实意义ꎮ因此ꎬ文章拟在借鉴前人的理论基础和非参数统计的方法上对广东省城乡收入和消费的差异进行探讨ꎮ二㊁实证分析文章选取广东省2005~2019年共15年的数据ꎬ其数据来源于广东统计年鉴并经过比例换算(见表1)ꎬ且选取的四个指标分别为城镇居民人均可支配收入㊁城镇居民人均消费支出㊁农村居民人均纯收入㊁农村居民人均消费支出ꎮ运过SPSS软件采用非参数方法分析城乡居民收入水平及消费水平存在的差异㊁收入与消费水平的变化趋势以及两者之间的相关性ꎬ以缩小城乡收入消费差距ꎬ促进经济增长ꎮ表1㊀广东城乡居民人均收入与消费支出数据年份农村居民人均纯收入农村居民人均消费支出城镇居民人均可支配收入城镇居民人均消费支出20054690.493707.7314769.9411809.8720065079.783885.9716015.5812432.2220075624.044202.3217699.3014336.8720086399.774872.9619732.8615527.97续表年份农村居民人均纯收入农村居民人均消费支出城镇居民人均可支配收入城镇居民人均消费支出20096906.935019.8121574.7216857.5120107890.255515.5823897.8018489.5320119371.736725.5526897.4820251.82201210542.847458.5630226.7122396.35201311670.928346.1333098.2524143.27201412908.049381.0536010.8926364.45201514082.6710375.4438927.7828658.15201615293.7811599.7442197.7131953.84201716624.3412330.5345868.9133711.30201818086.6314396.5949636.7334522.21201919822.9515836.2553855.8538423.22㊀㊀(一)城乡居民收入与消费的Wilcoxn秩和检验首先对广东省2005~2019年的城乡居民收入和城乡居民消费分别进行中位数差异分析ꎬ分别比较城镇居民与农村居民平均收入以及平均消费是否存在差异ꎮ即分别作出两样本的箱线图ꎬ从而可以通过图检验分别比较两样本中位数是否存在差异ꎮ从图1可以看出两样本的中位数不相同ꎬ很明显城镇居民收入的中位数高于农村居民收入的中位数ꎮ从图2可以看出镇居民消费的中位数高于农村居民消费的中位数ꎮ图1㊀广东省城乡居民收入的箱线图53图2㊀广东省城乡居民消费的箱线图然后根据以上问题对城乡居民收入和城乡居民消费分别做出如下假设检验问题:H0:MX=MYꎬ城乡居民收入不存在差异H1:MX>MYꎬ城镇居民收入高于农村居民收入H0:MX1=MY1ꎬ城乡居民消费不显著差异H1:MX1>MY1ꎬ城镇居民消费高于农村居民消费表2是城镇居民收入(X)数据和农村居民收入(Y)数据分别在它们在混合样本中的秩ꎬ求其秩和W分别为335和130ꎮ由此可得两样本的秩和存在明显差异ꎬ拒绝原假设即城镇居民收入与农村居民收入不存在显著差异ꎮ然后在SPSS软件中我们进行非参数检验中的Wilcoxon秩和检验ꎬ得到检验统计量的p值为0.001ꎬ因此ꎬ在0.01的显著性水平下ꎬ我们不接受原假设ꎬ即城镇居民收入显著高于农村居民收入ꎮ表3是城镇居民消费(X1)数据和农村居民消费(Y1)数据分别在它们在混合样本中的秩ꎬ求其秩和W分别为337和128ꎮ由此可得两样本数据秩和存在显著性差异ꎬ拒绝原假设即城镇居民消费与农村居民消费不存在显著差异ꎬ接受备择假设即城镇居民消费高于农村居民消费支出ꎮ然后在SPSS软件中我们进行非参数检验中的Wilcoxon秩和检验ꎬ得到检验统计量的p值为0.001ꎬ因此ꎬ在0.01的显著性水平下ꎬ我们不接受原假设ꎬ即城镇居民消费显著高于农村居民消费支出ꎮ表2㊀城镇居民和农村居民收入数据在混合样本中的秩农村居民人均纯收入秩城镇居民人均可支配收入秩4690.49114769.94125079.78216015.58145624.04317699.30166399.77419732.86186906.93521574.72207890.25623897.80219371.73726897.482210542.84830226.712311670.92933098.252412908.041036010.8925续表农村居民人均纯收入秩城镇居民人均可支配收入秩14082.671138927.782615293.781342197.712716624.341545868.912818086.631749636.732919822.951953855.8530表3㊀城镇居民和农村居民消费数据在混合样本中的秩农村居民人均消费支出秩城镇居民人均消费支出秩3707.73111809.87133885.97212432.22154202.32314336.87164872.96415527.97185019.81516857.51205515.58618489.53216725.55720251.82227458.56822396.35238346.13924143.27249381.051026364.452510375.441128658.152611599.741231953.842712330.531433711.32814396.591734522.212915836.251938423.2230㊀㊀(二)城乡居民收入与消费的趋势检验在非参数统计中ꎬ运用Cox-Stuart趋势存在性检验来检验一组数据的变化趋势ꎬ该方法是一种不依赖于趋势结构的快速判断趋势是否存在的方法ꎮ为保证数对同分布且不受局部干扰ꎬCox-Stuart提出最好的拆分点是数列中位于中间位置的数ꎬ在无趋势的原假设下ꎬ检验统计量服从参数为数对个数和发生概率为0.5的二项分布ꎮ因此对此问题做出以下假设检验问题:H0:数据序列无趋势ꎬH1:数据序列有增长趋势表4㊀广东省城乡居民人均收入与消费的Cox-Stuart检验序号农村之间的差额Di=xi-xi+cꎬc=7城镇之间的差额Di=xi-xi+cꎬc=7人均纯收入人均消费支出人均可支配收入人均消费支出1-6980.43-4638.40-18328.31-12333.402-7828.26-5495.08-19995.31-13932.233-8458.63-6173.12-21228.48-14321.284-8894.01-6726.78-22464.85-16425.875-9717.41-7310.72-24294.19-16853.796-10196.38-8881.01-25738.93-16032.687-10451.22-9110.70-26958.37-18171.40㊀㊀由表4可知ꎬ广东省的城乡居民人均收入与消费的前后不同时期的差值都为负ꎬ都存在上升趋势ꎮ同样ꎬ通过计算ꎬ63区域经济Һ㊀知道上述4个检验的统计量都是K=min(S+ꎬS-)=S+=0ꎬ其中S+表示正的Di数目ꎬS-表示负的Di的数目ꎮ在SPSS软件中用回归分析检验ꎬ得到检验的p值为0.0078ꎬ在0.01的显著性水平下ꎬ拒绝原假设ꎬ即数据序列有增长趋势ꎮ因此也说明符合经济理论和经济发展规律ꎮ(三)城乡居民收入与消费的相关性分析在非参数统计中ꎬ常用Spearman秩相关性检验来检验对不服从正态分布㊁总体分布未知等情况下来描述变量之间的相关性ꎮ那么Spearman秩相关性检验的假设检验问题为:H0:X与Y不相关ꎬH1:X与Y是相关的ꎮ采用Spearman秩相关检验具体分析城镇居民和农村居民的人均收入与消费的关系的散点图分别如图3和图4所示ꎮ图3㊀城镇居民人均收入与消费的散点图图4㊀农村居民人均收入与消费的散点图从图3和图4可知ꎬ无论是城镇居民还是农村居民ꎬ其人均收入与消费都呈现了高度的正相关关系ꎮ为了验证其显著性ꎬ在SPSS软件中进行相关性检验ꎮ城镇居民人均收入与消费和农村居民人均收入与消费的Spearman秩相关系数都是1ꎬ再进行单边检验ꎬ由结果可知两者的相关性在0.01都显著ꎬ因此在显著性水平拒绝原假设ꎬ认为城镇居民人均收入与消费之间以及农村居民人均收入与消费之间都存在正相关关系ꎮ换句话说随着城镇居民人均收入水平的提高ꎬ居民人均消费水平也会提高ꎻ随着农村居民人均收入水平的提高ꎬ居民人均消费水平也会提高ꎮ三㊁总结文章运用非参数统计的方法对广东省的2005~2019年的城乡居民人均收入与消费水平差异分析后ꎬ则有以下结论:1)城乡的收入和消费水平存在较大的差距ꎻ2)城乡居民收入和消费水平均随着我国经济水平的上升而呈现上升的趋势ꎻ3)广东省城乡的收入与消费均呈现高度的正相关关系ꎬ即随着收入水平的提高ꎬ消费水平也会随之提高ꎮ根据许多学者的研究成果可知ꎬ收入是决定消费水平的主要因素ꎮ因此城乡居民的消费差异的根本原因是城乡居民多年来的收入差距ꎮ因此ꎬ缩小城乡居民的收入水平差距将会促进城乡居民消费水平的缩小ꎬ而缩小城乡居民收入水平差距实质上就是充分提高农民的收入水平ꎬ即缩小了城乡居民的收入差距ꎮ因此ꎬ文章提出了以下对策建议:1)稳定农民农业收入ꎬ做好农村剩余劳动力转移工作ꎬ增加农民非农业收入ꎮ2)对农民的扶贫工作要精准到位ꎬ加大帮扶力度ꎮ3)加大对农村的财政投入力度ꎬ并鼓励社会投资的跟进和参与ꎮ4)全面推动农业生产模式改革ꎬ为现代农业的发展营造条件ꎮ5)加速构建新型农村金融服务体系ꎬ为农民收入的快速增加提供支撑等ꎮ参考文献:[1]刘瀑.河南城乡居民收入与消费差异的非参数检验[J].统计与决策ꎬ2017(16):115-117.[2]吴喜之ꎬ赵博娟.非参数统计[M].北京:中国统计出版社ꎬ2013.[3]夏蓉.我国城乡居民消费差异实证分析[J].消费导刊ꎬ2008(5):2.[4]李景海ꎬ王克林.基于状态空间模型和多层模型的广东城乡消费差异研究[J].统计与信息论坛ꎬ2013ꎬ28(7):76-81.作者简介:罗润珠ꎬ广东财经大学ꎮ73。
关于用Cox-Stuart 检验对实例的分析摘要:随着中国经济的快速发展,综合国力的大幅度提高,人民生活水平得到极大改善。
为了检验某村年收入高于5000元的人群是否得到提高,现用Cox-Stuart 方法对收集到的数据进行分析检验。
关键词:非参数统计 Cox-Stuart 趋势检验 变化趋势引言:通过对某村1975——2004年期间,每年收入5000元以上户数的变化,来分析预测该村高于5000元的人群是否有增长趋势。
从而检测该村的经济是否在逐步改善。
一,实例数据下面是某村1975——2004年,每年收入5000元以上的户数: 表一 33 32 46 36 40 40 40 36 41 39 43 35 45 39 42 434751454546594751554251496957从这组数据之中不能明确的看出户数的变化,所以根据表一数据绘制折线图二,数据分析 图一根据图一可以看出,总趋势似乎呈现增长趋势,但并不总是增长的。
所以用 Cox-Stuart 方法对数据进行进一步分析检验。
建立假设:H 0:无增长趋势 H 1:有增长趋势步骤:把每一个观测值和相隔230的另一个观测值配对比较。
因此有15个对子。
然后看增长的对子和减少的对子各有多少来判断总的趋势。
取i x 和c i x +组成一对),(c i i x x +。
这里152==nc 。
所以,本例中的对子为: ),(),(),,(),,(),,(),(),,(),,(),(),,(),,(),,(),,(),,(),,(3015291428132712261125,10249238227216205194183172161x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x 即为: (33,43),(32,47),(46,51),(36,45),(40,45),(40,46),(40,59),(36,47),(41,51), (39,55),(43,42),(35,51),(45,49),(39,69),(42,57) 用每一对的两元素差c i i i x x D +-=的符号来衡量增减 表二(x i ,x i+c ) D i =x i -x i+c (33,43) -10 (32,47) -15 (46,51) -5 (36,45) -9 (40,45) -5 (40,46) -6 (40,59) -19 (36,47) -11 (41,51) -10 (39,55) -16 (43,42) 1 (35,51) -16 (45,49) -4 (39,69) -30 (42,57)-15令+S 为正的i D 的数目,而令-S 为负的i D 的数目。

简述MK趋势检验的原理应用领域什么是MK趋势检验MK趋势检验是一种常用的非参数统计方法,用于检验时间序列数据是否存在趋势。
MK趋势检验不依赖于分布假设,适用于各种类型的数据。
MK趋势检验的原理MK趋势检验基于秩和差的思想,通过计算时间序列的秩次差数来判断序列的趋势性。
其原理可以简述如下:1.计算时间序列数据中两两数据之间的差值,得到差值序列。
2.对差值序列进行排序,得到排序序列。
3.统计排序序列中前后两个数据的关系,通过计算逆序对的个数推测序列的趋势性。
–如果逆序对的个数较多,则表明序列趋势下降;–如果逆序对的个数较少,则表明序列趋势上升;–如果逆序对的个数相对较小,则表明序列无明显趋势。
4.根据逆序对的个数进行统计推断,判断序列是否存在趋势。
MK趋势检验的应用领域MK趋势检验广泛应用于各个领域,特别是时间序列数据分析的相关研究和应用中。
以下是几个常见的应用领域:•气象学:在气象学中,MK趋势检验常被用来分析气温、降雨量、风速等气象要素的趋势性,从而预测天气变化和极端气候事件。
•水文学:在水文学研究中,MK趋势检验被用于分析河流流量、水位变化等水文要素的趋势性,评估水资源可持续利用和水灾风险等问题。
•环境监测:在环境监测领域,MK趋势检验被用来分析环境参数的变化情况,如大气颗粒物浓度、水质指标等,从而评估环境污染状况和进行环境管理决策。
•金融市场:在金融市场研究中,MK趋势检验被用来分析股票价格、汇率等金融数据的趋势性,帮助投资者进行投资决策和风险管理。
•生态学:在生态学研究中,MK趋势检验被用来分析物种数量、生境质量等生态指标的变化趋势,评估生态系统的健康状况和环境变化对生物多样性的影响。
•交通规划:在交通规划领域,MK趋势检验被用来分析交通流量、道路通行速度等交通数据的趋势性,评估交通拥堵状况和设计交通规划方案。
总结MK趋势检验是一种常用的非参数统计方法,通过计算时间序列数据的秩次差数来判断序列的趋势性。


mk趋势检验原理
MK趋势检验原理是一种常用的非参数统计方法,用于检验时间序列数据中的趋势性。
它的原理是基于一种叫做“斯普尔曼等级相关系数”的统计指标,该指标可以衡量两个变量之间的相关性,而不需要考虑它们的具体数值。
MK趋势检验的基本思想是,将时间序列数据中的每个观测值与其前面的所有观测值进行比较,计算出每个观测值的“等级”,然后根据这些等级计算出斯普尔曼等级相关系数。
如果该系数显著不为零,则说明时间序列数据中存在趋势性。
MK趋势检验的优点是可以处理非正态分布的数据,而且不需要对数据进行任何假设。
它的缺点是计算比较复杂,需要较长的计算时间。
此外,MK趋势检验只能检验数据中的单一趋势,无法检验多个趋势的存在。
MK趋势检验的应用范围非常广泛,例如气象学、水文学、环境科学等领域都可以使用该方法来分析时间序列数据中的趋势性。
在气象学中,MK趋势检验可以用来检验气温、降水量等气象要素的变化趋势;在水文学中,MK趋势检验可以用来检验河流流量、水位等水文要素的变化趋势;在环境科学中,MK趋势检验可以用来检验大气污染物、水质等环境要素的变化趋势。
MK趋势检验是一种非常有用的统计方法,可以帮助我们分析时间
序列数据中的趋势性,从而更好地理解数据的变化规律。
虽然它的计算比较复杂,但是在实际应用中,我们可以使用现成的软件来进行计算,从而方便快捷地进行分析。
趋势性检验趋势性检验(Trend Analysis)是一种常用的统计方法,用于分析一组数据是否存在时间趋势。
趋势性检验可以帮助我们了解数据的演变趋势,预测未来的走势,并且对于决策和规划也具有重要意义。
下面将对趋势性检验进行详细介绍。
趋势性检验的基本原理是假设数据存在一定的时间趋势,然后通过统计方法验证这个假设。
常见的趋势性检验方法有线性趋势检验、非线性趋势检验和季节性趋势检验等。
线性趋势检验是最简单和常用的方法。
它的基本原理是假设数据具有线性关系,并通过线性回归模型来验证这个假设。
在线性回归模型中,可以通过计算残差(实际值与拟合值之差)来判断数据是否存在线性趋势。
如果残差接近于零,说明数据接近线性关系,即存在线性趋势;反之,如果残差远离零,则说明数据不符合线性关系,即不存在线性趋势。
非线性趋势检验是一种相对复杂和常用的方法。
非线性趋势检验的基本原理是假设数据具有非线性关系,并通过非线性回归模型来验证这个假设。
非线性回归模型的参数估计和模型的选择都需要通过复杂的计算方法来实现。
常用的非线性趋势检验方法有多项式回归、指数回归和对数回归等。
季节性趋势检验是一种特殊的趋势性检验方法。
它的基本原理是假设数据具有季节性的周期性变化,并通过时间序列分析方法来验证这个假设。
时间序列分析方法可以通过计算季节指数、拟合季节模型和分解时间序列等步骤来实现。
季节性趋势检验方法可以帮助我们了解数据的季节性变化规律,从而进行更准确的预测和决策。
趋势性检验在实际应用中具有广泛的应用价值。
通过趋势性检验,我们可以判断数据是否存在时间趋势,从而进行更准确的分析和预测。
例如,在金融领域中,趋势性检验可以帮助我们判断股票价格和指数是否存在上涨或下跌趋势,从而进行投资决策。
在环境保护领域中,趋势性检验可以帮助我们判断环境污染程度是否在改善或恶化,从而制定相应的环境保护政策。
综上所述,趋势性检验是一种常用的统计方法,用于分析一组数据是否存在时间趋势。
统计检验中的检验趋势
在统计检验中,检验趋势是用来判断数据是否呈现某种趋势的一种统计方法。
常见的检验趋势的方法有Mann-Kendall检验和Sen's斜率检验。
Mann-Kendall检验是一种非参数检验方法,用来检验数据是否存在单调的趋势,无论是增加还是减少。
它基于数据的等级变化来计算检验统计量,然后进行假设检验,判断数据是否存在趋势。
Sen's斜率检验也是一种非参数方法,用来检验数据中的趋势。
它计算数据中每两个观测值之间的斜率,然后通过对这些斜率进行假设检验,判断数据是否存在趋势。
这种方法特别适用于数据中存在离群值的情况。
这两种方法都可以用来检验数据中的趋势,但适用的条件和假设不同。
在应用中需要根据具体问题选择合适的方法进行检验。
需要注意的是,这些方法只能判断数据是否存在趋势,不能给出趋势的方向或程度。
如果需要进一步分析趋势的性质,可以使用回归分析等方法。
在社会科学领域,调查是非常重要的一种研究方法。
通过调查,社会科学家可以获取大量的数据,并通过数据分析来揭示社会现象和规律。
而非参数统计方法在社会调查中的应用也日益受到重视。
一、非参数统计方法的意义首先,我们需要了解非参数统计方法的意义。
与参数统计方法相比,非参数统计方法不对总体分布的形式做出假设,而是利用数据本身的性质进行统计推断。
这种方法在样本容量较小或总体分布未知的情况下尤为重要。
在社会调查中,往往无法得知总体分布的具体形式,因此非参数统计方法能够更好地处理社会调查数据。
二、非参数统计方法在社会调查中的应用非参数统计方法在社会调查中的应用非常广泛。
首先,它可以用于处理名义数据和顺序数据。
在社会调查中,我们经常会遇到被调查者的性别、民族、职业等信息,这些信息通常是名义数据。
而非参数统计方法可以通过卡方检验、列联表分析等手段来分析名义数据之间的关系。
此外,非参数统计方法还可以用于分析顺序数据,如教育程度、收入水平等。
通过秩和检验、秩相关分析等方法,可以揭示顺序数据之间的关系。
其次,非参数统计方法还可以用于处理偏态数据和离群值。
在社会调查中,数据往往具有偏态分布,且可能存在一些离群值。
传统的参数统计方法对这种数据处理起来比较困难,而非参数统计方法则能够更好地应对这些问题。
例如,采用中位数而非均值作为数据的度量标准,可以减少偏态数据的影响;采用分位数回归而非最小二乘回归,可以更好地处理离群值的影响。
最后,非参数统计方法还可以用于处理复杂的多变量数据。
在社会调查中,往往需要考虑多个变量之间的关系。
非参数统计方法可以通过相关分析、回归分析等手段,揭示多个变量之间的关系,从而更全面地理解社会现象。
三、非参数统计方法的局限性及发展趋势然而,非参数统计方法也存在一些局限性。
首先,非参数统计方法通常需要更大的样本容量才能获得相同的统计效果。
其次,非参数统计方法在处理连续变量和大样本数据时效率较低。
此外,非参数统计方法的假设较弱,因此在特定条件下可能会导致较大的置信区间。