eviews图像及结果分析教学提纲
- 格式:doc
- 大小:265.00 KB
- 文档页数:18





eviews回归分析结果解读EViews回归分析结果解读:一、模型验证1.残差检验:通过残差的自相关检验来评估模型拟合的效果。
EViews 提供的残差检验的指标主要有自相关系数(AC)、均值偏差(PD)和多元偏差(MD)等,通过综合这三个指标来验证模型的优度。
2.残差的正态性检验:通过对残差的正态检验,来判断模型是否拟合得合适。
EViews绘出的正态性检验图,其上四象限内的残差数据点簇应该尽可能集中在图中心。
3.异方差性检验:这是检验模型拟合优度的另一种用法,主要依靠残差曲线的图形显示。
异方差的判定参考指标主要有自相关(ACF)和偏度(SKEW),此外还可以看“逐步残差图”。
二、系数验证1.系数绝对值:通过检验系数,来确定模型中每个变量的解释力。
系数的绝对值越大,说明该变量对模型影响越大。
2.系数t检验:系数t检验主要用来检验回归分析模型中,系数中存在的显著性关系。
EViews通过给出系数的t值和概率值来做检验,如果概率值小于一定的显著性水平,则该系数的t值就具有统计学显著性,表明变量与目标变量有关系。
3.系数F检验:F检验用来检验模型均方根残差对应回归方程变量对解释能力的贡献程度。
F检验的结果反映了模型在拟合中的效果,当F值较大时,说明模型所用的变量都有较强的解释能力。
三、模型优度1.R平方:R平方指的是回归方程对于平均自变量的拟合程度。
它衡量的是样本内变量和预期值之间的相似程度,R平方越大,模型对数据的拟合度越高。
2.拟合误差:拟合误差指的是拟合出来的模型误差,它反映了独立变量与因变量之间存在的不确定性。
拟合误差越小,说明模型拟合效果越好。
3.解释力:这是一个衡量模型效果的比率,主要反映模型对数据集中变量对解释能力,一般要在0.7以上才有一定的参考价值。
四、回归方程概况回归方程概况意指模型中因变量的各种参数,如常数项a0、斜率a1以及误差项的统计量。
这些参数的准确性和完整度将影响到模型的拟合程度和预测能力。

EViews图像及结果分析EViews软件提供了序列(Series)和序列组(Group)等对象的各种视图、统计分析方法和过程。
当序列对象中输入数据后,就可对序列对象中输入的数据进行统计分析,并且可以通过图、表等形式进行描述。
本章将介绍序列和序列组对象图形的生成和描述性统计量及其检验。
4.1 图形对象图形(Graph)对象可以形成序列和序列组等对象的各种视图,如线图(Line)、散点图(Scatter)以及饼图(Pie)等。
通过图形可以进一步观察和分析数据的变化趋势和规律。
下面介绍图形对象的基本操作。
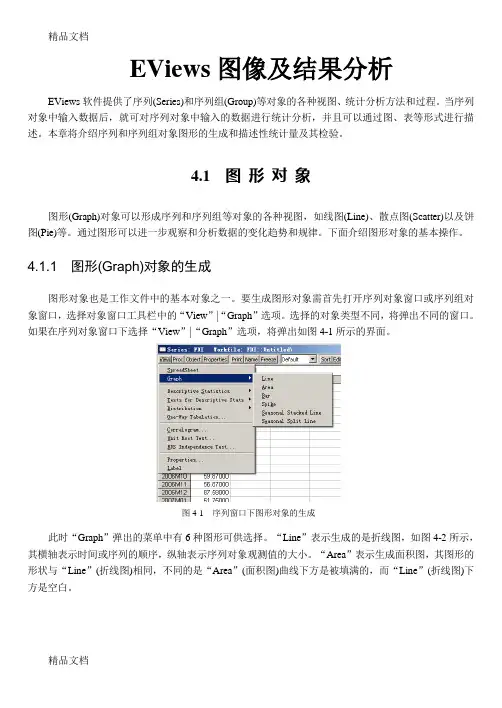
4.1.1 图形(Graph)对象的生成图形对象也是工作文件中的基本对象之一。
要生成图形对象需首先打开序列对象窗口或序列组对象窗口,选择对象窗口工具栏中的“View”|“Graph”选项。
选择的对象类型不同,将弹出不同的窗口。
如果在序列对象窗口下选择“View”|“Graph”选项,将弹出如图4-1所示的界面。
图4-1 序列窗口下图形对象的生成此时“Graph”弹出的菜单中有6种图形可供选择。
“Line”表示生成的是折线图,如图4-2所示,其横轴表示时间或序列的顺序,纵轴表示序列对象观测值的大小。
“Area”表示生成面积图,其图形的形状与“Line”(折线图)相同,不同的是“Area”(面积图)曲线下方是被填满的,而“Line”(折线图)下方是空白。
图4-2 “Line”折线图“Bar”表示为条形图,用条状的高度表示观测值的大小。
“Spike”表示尖峰图,由竖线组成,每根竖线的高度代表观测值的大小。
“Seasonal Stacked Line”表示生成的是季节性堆叠图,“Seasonal Split Line”表示生成的是季节性分割线。
如果在序列组(群)对象窗口下选择“View”|“Graph”选项,将弹出如图4-3所示的界面。
这里有9种图形可供选择。
其前4种与上面讲述的相同。
图4-3 序列组(群)窗口下图对象的生成其中,“Scatter”表示生成散点图。



EViews图像及结果分析EViews软件提供了序列(Series)和序列组(Group)等对象的各种视图、统计分析方法和过程。
当序列对象中输入数据后,就可对序列对象中输入的数据进行统计分析,并且可以通过图、表等形式进行描述。
本章将介绍序列和序列组对象图形的生成和描述性统计量及其检验。
4.1 图形对象图形(Graph)对象可以形成序列和序列组等对象的各种视图,如线图(Line)、散点图(Scatter)以及饼图(Pie)等。
通过图形可以进一步观察和分析数据的变化趋势和规律。
下面介绍图形对象的基本操作。
4.1.1 图形(Graph)对象的生成图形对象也是工作文件中的基本对象之一。
要生成图形对象需首先打开序列对象窗口或序列组对象窗口,选择对象窗口工具栏中的“View”|“Graph”选项。
选择的对象类型不同,将弹出不同的窗口。
如果在序列对象窗口下选择“View”|“Graph”选项,将弹出如图4-1所示的界面。
图4-1 序列窗口下图形对象的生成此时“Graph”弹出的菜单中有6种图形可供选择。
“Line”表示生成的是折线图,如图4-2所示,其横轴表示时间或序列的顺序,纵轴表示序列对象观测值的大小。
“Area”表示生成面积图,其图形的形状与“Line”(折线图)相同,不同的是“Area”(面积图)曲线下方是被填满的,而“Line”(折线图)下方是空白。
图4-2 “Line”折线图“Bar”表示为条形图,用条状的高度表示观测值的大小。
“Spike”表示尖峰图,由竖线组成,每根竖线的高度代表观测值的大小。
“Seasonal Stacked Line”表示生成的是季节性堆叠图,“Seasonal Split Line”表示生成的是季节性分割线。
如果在序列组(群)对象窗口下选择“View”|“Graph”选项,将弹出如图4-3所示的界面。
这里有9种图形可供选择。
其前4种与上面讲述的相同。
图4-3 序列组(群)窗口下图对象的生成其中,“Scatter”表示生成散点图。

eviews图像及结果分析(同名23076)EViews图像及结果分析EViews软件提供了序列(Series)和序列组(Group)等对象的各种视图、统计分析方法和过程。
当序列对象中输入数据后,就可对序列对象中输入的数据进行统计分析,并且可以通过图、表等形式进行描述。
本章将介绍序列和序列组对象图形的生成和描述性统计量及其检验。
4.1 图形对象图形(Graph)对象可以形成序列和序列组等对象的各种视图,如线图(Line)、散点图(Scatter)以及饼图(Pie)等。
通过图形可以进一步观察和分析数据的变化趋势和规律。
下面介绍图形对象的基本操作。
4.1.1 图形(Graph)对象的生成图形对象也是工作文件中的基本对象之一。
要生成图形对象需首先打开序列对象窗口或序列组对象窗口,选择对象窗口工具栏中的“View”|“Graph”选项。
选择的对象类型不同,将弹出不同的窗口。
如果第4章图形和统计量分析• 43 •在序列对象窗口下选择“View”|“Graph”选项,将弹出如图4-1所示的界面。
图4-1 序列窗口下图形对象的生成此时“Graph”弹出的菜单中有6种图形可供选择。
“Line”表示生成的是折线图,如图4-2所示,其横轴表示时间或序列的顺序,纵轴表示序列对象观测值的大小。
“Area”表示生成面积图,其图形的形状与“Line”(折线图)相同,不同的是“Area”(面积图)曲线下方是被填满的,而“Line”(折线图)下方是空白。
• 44 •第4章图形和统计量分析图4-2 “Line”折线图“Bar”表示为条形图,用条状的高度表示观测值的大小。
“Spike”表示尖峰图,由竖线组成,每根竖线的高度代表观测值的大小。
“Seasonal Stacked Line”表示生成的是季节性堆叠图,“Seasonal Split Line”表示生成的是季节性分割线。
如果在序列组(群)对象窗口下选择“View”|“Graph”选项,将弹出如图4-3所示的界面。
第一章绪论EVIEWS为我们提供了基于WINDOWS平台的复杂的数据分析、回归及预测工具,通过EVIEWS能够快速从数据中得到统计关系,并根据这些统计关系进行预测。
EVIEWS在系统数据分析和评价、金融分析、宏观经济预测、模拟、销售预测及成本分析等领域中有着广泛的应用。
EVIEWS操作手册共分五部分:第一部分:EVIEWS基础——介绍EVIEWS的基本用法。
另外对基本的WINDOWS操作系统进行讨论,解释如何使用EVIEWS来管理数据。
第二部分:基本的数据分析——描述使用EVIEWS来完成数据的基本分析及利用EVIEWS画图和造表来描述数据。
第三部分:基本的单方程分析——讨论标准回归分析:普通最小二乘法、加权最小二乘法、二阶最小二乘法、非线性最小二乘法、时间序列分析、方程检验及预测。
第四部分:扩展的单方程分析——介绍自回归条件异方差(ARCH)模型、离散和受限因变量模型、和对数极大似然估计。
第五部分:多方程分析——描述利用方程组来估计和预测、向量自回归、误差修正模型、状态空间模型、截面数据/ 时间序列数据、及模型求解。
第二章EVIEWS简介§2.1 什么是EVIEWSEVIEWS是在大型计算机的TSP (Time Series Processor) 软件包基础上发展起来的新版本,是一组处理时间序列数据的有效工具,1981年QMS (Quantitative Micro Software) 公司在Micro TSP基础上直接开发成功EVIEWS并投入使用。
虽然EVIEWS是由经济学家开发的并大多在经济领域应用,但它的适用范围不应只局限于经济领域。
EVIEWS得益于WINDOWS的可视的特点,能通过标准的WINDOWS菜单和对话框,用鼠标选择操作,并且能通过标准的WINDOWS技术来使用显示于窗口中的结果。
此外,还可以利用EVIEWS的强大的命令功能和它的大量的程序处理语言,进入命令窗口修改命令,并可以将计算工作的一系列操作建立成相应的计算程序,并存储,则可以通过直接运行程序来完成你的工作。
e v i e w s图像及结果分析EViews图像及结果分析EViews软件提供了序列(Series)和序列组(Group)等对象的各种视图、统计分析方法和过程。
当序列对象中输入数据后,就可对序列对象中输入的数据进行统计分析,并且可以通过图、表等形式进行描述。
本章将介绍序列和序列组对象图形的生成和描述性统计量及其检验。
4.1 图形对象图形(Graph)对象可以形成序列和序列组等对象的各种视图,如线图(Line)、散点图(Scatter)以及饼图(Pie)等。
通过图形可以进一步观察和分析数据的变化趋势和规律。
下面介绍图形对象的基本操作。
4.1.1 图形(Graph)对象的生成图形对象也是工作文件中的基本对象之一。
要生成图形对象需首先打开序列对象窗口或序列组对象窗口,选择对象窗口工具栏中的“View”|“Graph”选项。
选择的对象类型不同,将弹出不同的窗口。
如果在序列对象窗口下选择“View”|“Graph”选项,将弹出如图4-1所示的界面。
图4-1 序列窗口下图形对象的生成此时“Graph”弹出的菜单中有6种图形可供选择。
“Line”表示生成的是折线图,如图4-2所示,其横轴表示时间或序列的顺序,纵轴表示序列对象观测值的大小。
“Area”表示生成面积图,其图形的形状与“Line”(折线图)相同,不同的是“Area”(面积图)曲线下方是被填满的,而“Line”(折线图)下方是空白。
收集于网络,如有侵权请联系管理员删除收集于网络,如有侵权请联系管理员删除图4-2 “Line ”折线图“Bar ”表示为条形图,用条状的高度表示观测值的大小。
“Spike ”表示尖峰图,由竖线组成,每根竖线的高度代表观测值的大小。
“Seasonal Stacked Line ”表示生成的是季节性堆叠图,“Seasonal Split Line ”表示生成的是季节性分割线。
如果在序列组(群)对象窗口下选择“View ”|“Graph ”选项,将弹出如图4-3所示的界面。
这里有9种图形可供选择。
其前4种与上面讲述的相同。
图4-3 序列组(群)窗口下图对象的生成其中,“Scatter ” 表示生成散点图。
在“Scatter ”弹出的菜单中有5个选项,分别是“Simple Scatter ”(简单散点图)、“Scatter with Regression ”(带有回归线的散点图)、“Scatter withNearest Neighbor Fit ”(近邻匹配散点图)、“Scatter with Kernel Fit ”(核心匹配散点图)、“XY Pairs ”(XY 成对散点图)。
当序列组中包含两个序列对象时,第一个序列对象的观测值构成散点图的横坐标,第二个序列对象的观测值构成散点图的纵坐标,如图4-4所示。
当收集于网络,如有侵权请联系管理员删除序列组中有三个以上的序列对象时,第一个序列对象构成散点图的横坐标,其余序列对象构成散点图的纵坐标。
图4-4 简单散点图(“Simple Scatter ”)“XY line ”表示X 与Y 的折线图,横纵坐标分别表示两个序列对象的观测值。
“Error Bar ”表示误差长条图,“High-Low ”表示高低图,“Pie ”表示饼图。
另外,在序列组(群)对象窗口下还可通过选择“View ”|“Multiple Graphs ”选项来生成图形。
此时图形显示在不同的坐标系中,即每个序列对象各形成一个图形,并显示在同一个窗口中。
除上面介绍的在序列对象窗口中生成图对象外,还可以通过选择EViews 主菜单中的“Quick ”|“Graph ”选项来生成。
在“Graph ”的菜单中选择图的类型,将弹出图4-5所示的文本框。
在文本框内输入序列或序列组的名称,例如“fdi ”,然后单击“OK ”按钮,即可打开相应的图。
此时所生成的图对象未被命名,单击图对象窗口中的“Name ”按钮即可命名。
图4-5 生成图对象的文本框4.1.2 图形的冻结在上面所介绍的两种图对象生成方法中,通过“Quick ”|“Graph ”选项生成图形对象,单击图对象窗口工具栏中的“Name ”选项,在弹出的对话框中输入该对象的名称,单击“OK ”按钮后该对象即可被保存,并在工作文件窗口中显示图对象的图标。
但直接在序列对象窗口中形成的图形未被保存,当序列对象中的观测值发生改变时,或当前工作文件的样本范围发生变化时,图形也将随之改变。
如果要保留所建立的图形,使之不随样本及观测值的改变而发生变化,则可以通过序列对象窗口中的“Freeze”键来冻结图形。
EViews软件将被冻结的图形以一个图(Graph)对象的形式保存在工作文件中。
当选择序列对象窗口中的“Freeze”键时,会弹出图对象窗口。
其中有几个键值得关注,一个是“AddText”功能键,通过它可以将文字显示在图形中,并且可以选择显示的位置。
一个是“Line/Shade”功能键,通过它可以改变图形的背景颜色,横纵坐标轴的线条类型和颜色等。
还有一个是“Remove”功能键,可以用来删除图形中的一些附加要素。
例如,将在图形中所建立的文字删除,应首先用鼠标单击所需删除的内容,使其被选中,然后单击“Remove”键,则文字即被删除。
用同样的方法也可以删除为图形所设置的颜色等。
4.1.3 图形的复制如果需要将图形保存到其他文件中,例如放在Word文档中,则选择图对象窗口中的“Proc”|“Copy”选项,然后在弹出的对话框中单击“OK”按钮。
或者将鼠标移动到图形上,右击,在弹出的快捷菜单中选择“Copy”命令。
再打开需要粘贴的文件,进行粘贴即可。
4.2 描述性统计量EViews软件中包含一些基本的描述性统计量,有直方图、均值、方差、协方差、自相关等。
本节主要介绍序列和序列组对象窗口下的描述性统计量及其检验。
4.2.1 描述性统计量概述序列窗口下的描述性统计量和序列组窗口下的描述性统计量有所不同。
在序列窗口下有4种描述性统计量,分别是“Histogram and Stats”(直方图和统计量)、“Stats Table”(统计表)、“Stats by Classification”(分类统计量)和“Boxplots by Classification”(箱线图/箱尾图分类)。
序列组窗口下有3种描述性统计量,分别是“Common Sample”(普通样本)、“Individual Samples”(个体样本)和“Boxplots”(箱线图/箱尾图)。
下面分别进行详细介绍。
(1) 序列窗口下的描述性统计量在序列(Series)对象窗口下选择工具栏中的“View”|“Descriptive Statistics”(描述性统计量)选项,将出现4个选项。
第一个选项是“Histogram and Stats”(直方图和统计量),能显示序列对象的直方图和描述性统计量的值。
下面以建立好的序列对象“fdi”为例来进行说明。
收集于网络,如有侵权请联系管理员删除收集于网络,如有侵权请联系管理员删除如图4-6所示,图的左侧显示的是该序列对象的直方图,为观测值的频率分布。
右侧分三个部分,最上面显示的是序列对象的名称、样本的范围和样本数量。
中间部分显示的是各统计量的值。
其中,“Mean ”表示均值,即序列对象观测值的平均值;“Median ”表示中位数,即从小到大排列的序列对象观测值的中间值,是对序列分布中心的一个大致估计;“Maximum ”和“Minimum ”表示的是该序列观测值中的最大值和最小值;“Std.Dev ”表示标准差,用来衡量序列观测值的离散程度。
其计算公式为∑=--=N i x x N i 1)(112σ (4-1)式中,σ为标准差,N 为样本观测值个数,x i 是样本观测值,x 为样本均值。
图4-6 序列对象“fdi ”的直方图分布形状和相关统计量的描述“Skewness ”表示偏度,用来衡量观测值分布偏离均值的状况。
其计算公式为31ˆ1∑=⎪⎭⎫ ⎝⎛-=N i x x N S i σ (4-2)式中,σˆ是变量方差的有偏估计。
当S =0时,序列的分布是对称的,如正态分布;当S >0时,序列分布为右偏;当S <0时,序列分布为左偏。
例如图4-6中的偏度为1.422 500>0,所以我国的外商直接投资(fdi)的分布是不对称的,为右偏分布形态。
“Kurtosis ”表示峰度,用来衡量序列分布的凸起状况。
其计算公式为41ˆ1∑=⎪⎭⎫ ⎝⎛-=N i x x N K i σ (4-3)正态分布的K值为3,当K >3时,序列对象的分布凸起程度大于正态分布的凸起程度;当K <3时,序列对象的分布凸起程度要比正态分布小。
例如,图4-6中的峰度为4.898 917>3,外商直接投资(fdi)的分布呈尖峰状态。
最下方是JB(Jarque-Bera)统计量及其相应的概率(Probability)。
JB统计量用来检验序列观测值是否服从正态分布,该检验的零假设为样本服从正态分布。
在零假设下,JB统计量服从χ2(2)分布。
根据第1章所介绍的假设检验,P(Probability)值为拒绝原假设所犯第Ⅰ类错误的概率。
在本例中P值接近于0,因而可在1%的显著性水平下拒绝零假设,即序列不服从正态分布。
第二个选项是“Stats Table”(统计表),它将描述性统计量值通过电子表格的形式显示在对象窗口中。
第三个选项是“Stats by Classification”(分类统计量),它将样本分为若干组后再对各组观测值分别进行描述统计。
选择此项后将弹出如图4-7所示的对话框,其中包括三部分内容。
在左边“Statistics”选项中勾选需要显示的统计量,其中“# of NAs”为无观测个数,“Observations”为观测值个数。
在“Series/Group for classify”中输入需分类的序列或序列组对象名称,右侧“Output Layout”为输出结果的显示形式。
选择好后单击“OK”按钮即可。
图4-7 “Stats by Classification”(分类统计量)对话框第四个选项是“Boxplots by Classification”(分类箱线图/箱尾图),将序列分布按照箱线图/箱尾图进行分类。
箱线图(Boxplot)也称为箱尾图,是利用数据统计量来描述数据的一种方法,它可以粗略地看出数据是否具有对称性,分布的分散程度等。
图4-8所示为fdi序列的分类箱线图。
收集于网络,如有侵权请联系管理员删除图4-8 fdi序列对象的分类箱线图(“Boxplots by Classification”)(2) 序列组窗口下的描述性统计量在序列组(Group)对象窗口下选择工具栏中的“View”| “Descriptive Statistics”(描述性统计量)选项,将弹出3个选项。