eviews图像及结果分析
- 格式:doc
- 大小:120.50 KB
- 文档页数:19
F检验的假设、对F值的判断、对F值的概率值的判断。
T检验的假设、对t值的判断、对t值的概率值的判断。
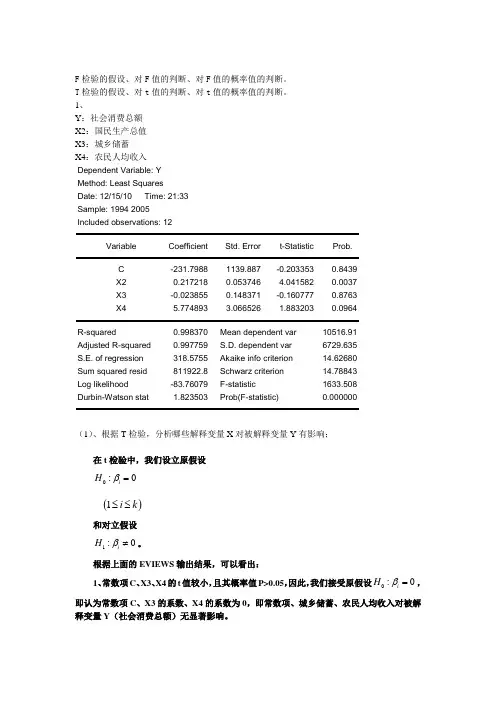
1、Y:社会消费总额X2:国民生产总值X3:城乡储蓄X4:农民人均收入Dependent Variable: YMethod: Least SquaresDate: 12/15/10 Time: 21:33Sample: 1994 2005Included observations: 12Variable Coefficient Std. Error t-Statistic Prob.C -231.7988 1139.887 -0.203353 0.8439X2 0.217218 0.053746 4.041582 0.0037X3 -0.023855 0.148371 -0.160777 0.8763X4 5.774893 3.066526 1.883203 0.0964R-squared 0.998370 Mean dependent var 10516.91 Adjusted R-squared 0.997759 S.D. dependent var 6729.635 S.E. of regression 318.5755 Akaike info criterion 14.62680 Sum squared resid 811922.8 Schwarz criterion 14.78843 Log likelihood -83.76079 F-statistic 1633.508 Durbin-Watson stat 1.823503 Prob(F-statistic) 0.000000(1)、根据T检验,分析哪些解释变量X对被解释变量Y有影响;在t检验中,我们设立原假设0:0iHβ= ()1i k≤≤和对立假设1:0iHβ≠。
根据上面的EVIEWS输出结果,可以看出:1、常数项C、X3、X4的t值较小,且其概率值P>0.05,因此,我们接受原假设0:0iHβ=,即认为常数项C、X3的系数、X4的系数为0,即常数项、城乡储蓄、农民人均收入对被解释变量Y(社会消费总额)无显著影响。
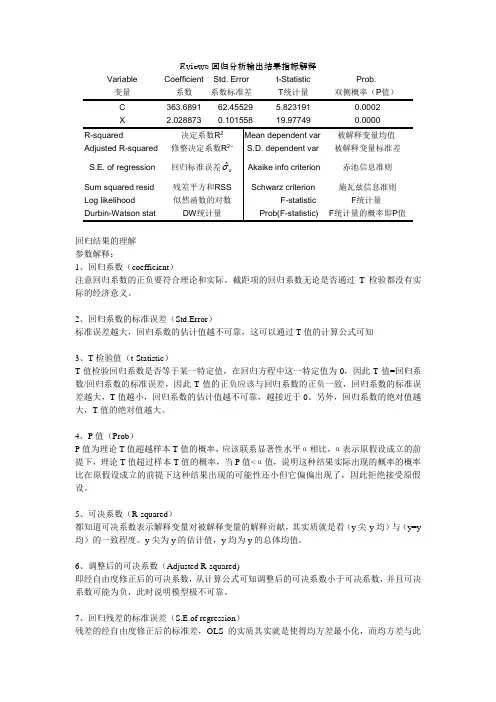
Eviews回归分析输出结果指标解释Variable 变量Coefficient系数Std. Error系数标准差t-StatisticT统计量Prob.双侧概率(P值)C 363.6891 62.45529 5.823191 0.0002回归结果的理解参数解释:1、回归系数(coefficient)注意回归系数的正负要符合理论和实际。
截距项的回归系数无论是否通过T检验都没有实际的经济意义。
2、回归系数的标准误差(Std.Error)标准误差越大,回归系数的估计值越不可靠,这可以通过T值的计算公式可知3、T检验值(t-Statistic)T值检验回归系数是否等于某一特定值,在回归方程中这一特定值为0,因此T值=回归系数/回归系数的标准误差,因此T值的正负应该与回归系数的正负一致,回归系数的标准误差越大,T值越小,回归系数的估计值越不可靠,越接近于0。
另外,回归系数的绝对值越大,T值的绝对值越大。
4、P值(Prob)P值为理论T值超越样本T值的概率,应该联系显著性水平α相比,α表示原假设成立的前提下,理论T值超过样本T值的概率,当P值<α值,说明这种结果实际出现的概率的概率比在原假设成立的前提下这种结果出现的可能性还小但它偏偏出现了,因此拒绝接受原假设。
5、可决系数(R-squared)都知道可决系数表示解释变量对被解释变量的解释贡献,其实质就是看(y尖-y均)与(y=y 均)的一致程度。
y尖为y的估计值,y均为y的总体均值。
6、调整后的可决系数(Adjusted R-squared)即经自由度修正后的可决系数,从计算公式可知调整后的可决系数小于可决系数,并且可决系数可能为负,此时说明模型极不可靠。
7、回归残差的标准误差(S.E.of regression)残差的经自由度修正后的标准差,OLS的实质其实就是使得均方差最小化,而均方差与此的区别就是没有经过自由度修正。
8、残差平方和(Sum Squared Resid)见上79、对数似然估计函数值(Log likelihood)首先,理解极大似然估计法。


Eviews实验报告
本次实验使用Eviews对数据进行了分析和建模,主要分为以下几个部分:
一、数据预处理
1. 数据清洗:对数据进行了初步的检查和清洗,处理了数据中的缺失值和异常值;
2. 数据变换:对原始数据进行了对数化处理,使其符合正态分布。
二、数据分析
1. 描述性统计:通过统计均值、标准差、相关系数等指标,对数据进行了分析和描述;
2. 单因素分析:使用单因素方差分析对不同自变量与因变量之间的关系进行了检验。
三、建模分析
1. 模型选择:根据变量相关性和变量显著性等因素,最终选择了一组自变量,建立了多元线性回归模型;
2. 模型检验:对建立的模型进行了残差分析,验证了模型的可靠性和稳定性;
3. 预测分析:利用建立的模型对新数据进行了预测,并进行了模型预测精度的评估。
四、实验结论
通过Eviews的分析和建模,得出了以下结论:
1. 数据清洗和变换可以提高数据分析的准确性和可靠性;
2. 描述性统计和单因素分析可以为建模提供有用的参考和决策依据;
3. 多元线性回归模型可以较好地解释自变量与因变量之间的关系,并可进行预测和决策分析。
综上所述,本次实验通过Eviews软件对数据进行了分析和建模,得出了有关数据的一些重要结论,为后续数据分析和决策提供了基础和支持。




eviews实验报告总结eviews实验报告总结篇一:Evies实验报告实验报告一、实验数据:1994至201X年天津市城镇居民人均全年可支配收入数据 1994至201X年天津市城镇居民人均全年消费性支出数据 1994至201X年天津市居民消费价格总指数二、实验内容:对搜集的数据进行回归,研究天津市城镇居民人均消费和人均可支配收入的关系。
三、实验步骤:1、百度进入“中华人民共和国国家统计局”中的“统计数据”,找到相关数据并输入Exc el,统计结果如下表1:表11994年--201X年天津市城镇居民消费支出与人均可支配收入数据2、先定义不变价格(1994=1)的人均消费性支出(Yt)和人均可支配收入(Xt)令:Yt=cn sum/priceXt=ine/pri ce 得出Yt与Xt的散点图,如图1.很明显,Yt和X t服从线性相关。
图1 Yt和Xt散点图3、应用统计软件EVies完成线性回归解:根据经济理论和对实际情况的分析也都可以知道,城镇居民人均全年耐用消费品支出Yt依赖于人均全年可支配收入Xt的变化,因此设定回归模型为 Yt=β0+β?Xt﹢μt(1)打开E Vies软件,首先建立工作文件, Fil e rkfile ,然后通过bject建立 Y、X系列,并得到相应数据。
(2)在工作文件窗口输入命令:l s y c x,按E nter键,回归结果如表2 :表2 回归结果根据输出结果,得到如下回归方程:Y t=977.908+0.670Xt s=(172.3797) (0.0122) t=(5.673) (54.950) R2=0.995385 Adjust ed R2=0.995055 F-sta tistic=3019.551 残差平方和Sum sq uared resi d =1254108回归标准差S.E.f regressi n=299.2978(3)根据回归方程进行统计检验:拟合优度检验由上表2中的数分别为0.995385和0.995055,计算结果表明,估计的样本回归方程较好地拟合了样本观测值。

eviews图像及结果分析(同名23076)EViews图像及结果分析EViews软件提供了序列(Series)和序列组(Group)等对象的各种视图、统计分析方法和过程。
当序列对象中输入数据后,就可对序列对象中输入的数据进行统计分析,并且可以通过图、表等形式进行描述。
本章将介绍序列和序列组对象图形的生成和描述性统计量及其检验。
4.1 图形对象图形(Graph)对象可以形成序列和序列组等对象的各种视图,如线图(Line)、散点图(Scatter)以及饼图(Pie)等。
通过图形可以进一步观察和分析数据的变化趋势和规律。
下面介绍图形对象的基本操作。
4.1.1 图形(Graph)对象的生成图形对象也是工作文件中的基本对象之一。
要生成图形对象需首先打开序列对象窗口或序列组对象窗口,选择对象窗口工具栏中的“View”|“Graph”选项。
选择的对象类型不同,将弹出不同的窗口。
如果第4章图形和统计量分析• 43 •在序列对象窗口下选择“View”|“Graph”选项,将弹出如图4-1所示的界面。
图4-1 序列窗口下图形对象的生成此时“Graph”弹出的菜单中有6种图形可供选择。
“Line”表示生成的是折线图,如图4-2所示,其横轴表示时间或序列的顺序,纵轴表示序列对象观测值的大小。
“Area”表示生成面积图,其图形的形状与“Line”(折线图)相同,不同的是“Area”(面积图)曲线下方是被填满的,而“Line”(折线图)下方是空白。
• 44 •第4章图形和统计量分析图4-2 “Line”折线图“Bar”表示为条形图,用条状的高度表示观测值的大小。
“Spike”表示尖峰图,由竖线组成,每根竖线的高度代表观测值的大小。
“Seasonal Stacked Line”表示生成的是季节性堆叠图,“Seasonal Split Line”表示生成的是季节性分割线。
如果在序列组(群)对象窗口下选择“View”|“Graph”选项,将弹出如图4-3所示的界面。

Eviews回归分析输出结果指标解释Variable Coefficie Std。
Error t-Statistic Prob.X2。
0288730。
10155819。
977490。
0000回归结果的理解参数解释:1、回归系数(coefficient)注意回归系数的正负要符合理论和实际。
截距项的回归系数无论是否通过T检验都没有实际的经济意义。
2、回归系数的标准误差(Std。
Error)标准误差越大,回归系数的估计值越不可靠,这可以通过T值的计算公式可知3、T检验值(t-Statistic)T值检验回归系数是否等于某一特定值,在回归方程中这一特定值为0,因此T值=回归系数/回归系数的标准误差,因此T值的正负应该与回归系数的正负一致,回归系数的标准误差越大,T值越小,回归系数的估计值越不可靠,越接近于0。
另外,回归系数的绝对值越大,T值的绝对值越大。
4、P值(Prob)P值为理论T值超越样本T值的概率,应该联系显著性水平α相比,α表示原假设成立的前提下,理论T值超过样本T值的概率,当P值<α值,说明这种结果实际出现的概率的概率比在原假设成立的前提下这种结果出现的可能性还小但它偏偏出现了,因此拒绝接受原假设。
5、可决系数(R—squared)都知道可决系数表示解释变量对被解释变量的解释贡献,其实质就是看(y尖-y均)与(y=y均)的一致程度。
y尖为y的估计值,y均为y的总体均值。
6、调整后的可决系数(Adjusted R—squared)即经自由度修正后的可决系数,从计算公式可知调整后的可决系数小于可决系数,并且可决系数可能为负,此时说明模型极不可靠。
7、回归残差的标准误差(S。
E。
of regression)残差的经自由度修正后的标准差,OLS的实质其实就是使得均方差最小化,而均方差与此的区别就是没有经过自由度修正.8、残差平方和(Sum Squared Resid)见上79、对数似然估计函数值(Log likelihood)首先,理解极大似然估计法。

第二章案例分析一、研究的目的要求居民消费在社会经济的持续发展中有着重要的作用。
居民合理的消费模式和居民适度的消费规模有利于经济持续健康的增长,而且这也是人民生活水平的具体体现。
改革开放以来随着中国经济的快速发展,人民生活水平不断提高,居民的消费水平也不断增长。
但是在看到这个整体趋势的同时,还应看到全国各地区经济发展速度不同,居民消费水平也有明显差异。
例如,2002年全国城市居民家庭平均每人每年消费支出为6029.88元, 最低的黑龙江省仅为人均4462.08元,最高的上海市达人均10464元,上海是黑龙江的2.35倍。
为了研究全国居民消费水平及其变动的原因,需要作具体的分析。
影响各地区居民消费支出有明显差异的因素可能很多,例如,居民的收入水平、就业状况、零售物价指数、利率、居民财产、购物环境等等都可能对居民消费有影响。
为了分析什么是影响各地区居民消费支出有明显差异的最主要因素,并分析影响因素与消费水平的数量关系,可以建立相应的计量经济模型去研究。
二、模型设定我们研究的对象是各地区居民消费的差异。
居民消费可分为城市居民消费和农村居民消费,由于各地区的城市与农村人口比例及经济结构有较大差异,最具有直接对比可比性的是城市居民消费。
而且,由于各地区人口和经济总量不同,只能用“城市居民每人每年的平均消费支出”来比较,而这正是可从统计年鉴中获得数据的变量。
所以模型的被解释变量Y 选定为“城市居民每人每年的平均消费支出”。
因为研究的目的是各地区城市居民消费的差异,并不是城市居民消费在不同时间的变动,所以应选择同一时期各地区城市居民的消费支出来建立模型。
因此建立的是2002年截面数据模型。
影响各地区城市居民人均消费支出有明显差异的因素有多种,但从理论和经验分析,最主要的影响因素应是居民收入,其他因素虽然对居民消费也有影响,但有的不易取得数据,如“居民财产”和“购物环境”;有的与居民收入可能高度相关,如“就业状况”、“居民财产”;还有的因素在运用截面数据时在地区间的差异并不大,如“零售物价指数”、“利率”。
线性回归分析数据的预处理1.绘制统计图图形表明随时间变化存在上升趋势2.散点图由图看出各序列的相关系数均接近于1,所以各序列相关程度较高。
2.对原序列进行ADF平稳性检验Quick-series ststistics-unit root test ,在弹出的series name 对话框中输入需要检验的序列的名称,在test for unit root in 选择框中选择level,得到原数据序列的ADF 检验结果,其他保持默认设置。
得到序列的ADF 平稳性检验结果,检测值-1.17大于所有临界值,则表明序列不平稳以此方法,对各时间序列以此进行ADF检验,将检验值与临界值比较,发现所有序列的检验值均大于临界值,表明各序列都是非平稳的。
(3)时间序列数据的一阶差分的ADF检验Quick-series statistics-unit root test,在series name 对话框中输入需要检验的序列名称QMG ,在test for unit root in 选择框中选择1 nd difference ,对其一阶差分进行稳定性检验,其他保持默认设置。
得到序列的ADF平稳性检验结果,检测值-3.323并非远小于所有临界值,表明序列一阶差分不平稳。
3.Granger因果检验(1)quick-group statistics-granger causality test ,出现如下对话框,点击OK,得到输入序列之间的单项或双向因果关系。
(2)滞后阶数采用Eviews推荐的滞后阶数(3)得到与序列相关的Granger因果检验结果。
MOB的P值是0.0296<0.05,所以拒绝原假设,即MOB是GNP的Granger原因,而GNP的P值为0.6483>0.05,所以接受MOB是GNP的Granger的原解释,也就是MOB是GNP的Granger 的原解释。
分析:MOB对GNP的促进作用比较明显,而GNP对MOB的促进作用很不明显。
一、研究课题:通过对1984——2003年某国GDP和出口的分析,研究GDP和出口量的相关关系并对参数估计值进行检验。
二、模型及数据来源:GDP为因变量,出口量为自变量。
选择模型是一元线性回归模型y=c0+c1x+u(y代表GDP,x代表出口量,u表示残差项)数据来自《计量经济学软件——eviews的使用》135页表12.1。
提取其进口和国内生产总值两列数据:annual export gdp1984 580.5 71711985 808.9 8964.41986 1082.1 10202.21987 1470 11962.51988 1766.7 14928.31989 1956 16909.21990 2985.8 18547.91991 3827.1 21617.81992 4676.3 26638.11993 5284.8 34634.41994 10421.8 46759.41995 12451.8 58478.11996 12576.4 67884.61997 15160.7 74462.61998 15233.6 78345.21999 16159.8 82067.52000 20634.4 89468.12001 22024.4 97314.82002 26947.4 105172.32003 36287.9 117251.9三、作业1、根据表格得到曲线图、散点图、X-Y曲线图:1200001000008000060000400002000084868890929496980002曲线图05000010000015000010000200003000040000EXPORTG D P散点图20000400006000080000100000120000100002000030000EXPORTG D PX-Y 曲线图2、数据描述统计分析024681001234563、简单的回归估计Dependent Variable: GDP Method: Least Squares Date: 06/14/09 Time: 16:38 Sample: 1984 2003 Variable Coefficient Std. Error t-Statistic Prob. C 11772.77 2862.419 4.112873 0.0007 R-squared0.946953 Mean dependent var 49439.02 Adjusted R-squared 0.944006 S.D. dependent var 36735.19 S.E. of regression 8692.656 Akaike info criterion 21.07298 Sum squared resid1.36E+09 Schwarz criterion21.17256Log likelihood -208.7298 F-statistic 321.3229Durbin-Watson stat 0.604971 Prob(F-statistic) 0.000000y t=-11772.77+3.547790x t R2=0.946953 df=18检验回归系数显著性的原假设和备择假设是(给定α = 0.05)H0:c1= 0;H1:c1≠ 0。
作业:2.自己设计一个一元线性回归模型,并查阅2012年统计年鉴,用1985-2011年数据完成下列要求:(1) 作散点图; (2) 拟合样本回归函数;(3) 对所建立的模型进行经济意义检验;(4) 对所建立的模型进行统计检验,并详细解释检验结果; (5) 作历史模拟图,并计算平均绝对百分比误差:%100ˆ11⨯-=∑=ni iii Y Y Y nMAPE(6) 用2011年数据对模型作外推检验;(7) 预测2012年、2013年被解释变量的值,并给出总体均值的95%预测区间。
(注:用Eviews 完成)解:由经济理论分析可知,经济发展水平与居民消费水平有密切关系。
因此,我们设定居民消费水平i Y (绝对数(元))与国内生产总值i X (亿元)的关系为:011,1,2,...,27i i Y X i ββμ=++=数据来源:中国统计年鉴2012 (1) 散点图:在Eviews 中,通过Quick →Gragh →Scatter Diagram ,得到如下散点图:(2)拟合样本回归函数:通过Quick estimation equation,在如下窗口中输入:得到:由此可得样本回归函数:^=665.6063+0.02534i iY X ,(7.398) (50.495)2R=0.9903(3) 其中^1β=0.02534是回归方程的斜率,它表示1985-2011年期间,GDP 每增加1亿元,居民消费水平平均增加0.02534元;^0β=665.6065是回归方程的截距,她表示不受GDP 影响的居民消费水平的起始值。
^1β,^β的符号大小均符合经济理论及实际情况。
(4) 统计检验。
2R =0.9903,说明总离差平方和的99.03%被样本回归直线所解释,只有0.97%未被解释,因此样本回归对样本点的拟合优度很高。
给出显著性水平,α=0.05,查自由度n-2=25的t 分布表,得临界值0.05(25) 2.060t =,^0tβ=7.398 > 0.05(25) 2.060t =,^1tβ=50.495 > 0.05(25) 2.060t =,拒绝回归系数为零的原假设,说明X 变量显著地影响Y 变量。
第4章图形和统计量分析EViews软件提供了序列(Series)和序列组(Group)等对象的各种视图、统计分析方法和过程。
当序列对象中输入数据后,就可对序列对象中输入的数据进行统计分析,并且可以通过图、表等形式进行描述。
本章将介绍序列和序列组对象图形的生成和描述性统计量及其检验。
图形对象图形(Graph)对象可以形成序列和序列组等对象的各种视图,如线图(Line)、散点图(Scatter)以及饼图(Pie)等。
通过图形可以进一步观察和分析数据的变化趋势和规律。
下面介绍图形对象的基本操作。
图形(Graph)对象的生成图形对象也是工作文件中的基本对象之一。
要生成图形对象需首先打开序列对象窗口或序列组对象窗口,选择对象窗口工具栏中的“View”|“Graph”选项。
选择的对象类型不同,将弹出不同的窗口。
如果在序列对象窗口下选择“View”|“Graph”选项,将弹出如图4-1所示的界面。
图4-1 序列窗口下图形对象的生成此时“Graph”弹出的菜单中有6种图形可供选择。
“Line”表示生成的是折线图,如图4-2所示,其横轴表示时间或序列的顺序,纵轴表示序列对象观测值的大小。
“Area”表示生成面积图,其图形的形状与“Line”(折线图)相同,不同的是“Area”(面积图)曲线下方是被填满的,而“Line”(折线图)下方是空白。
图4-2 “Line”折线图“Bar”表示为条形图,用条状的高度表示观测值的大小。
“Spike”表示尖峰图,由竖线组成,每根竖线的高度代表观测值的大小。
“Seasonal Stacked Line”表示生成的是季节性堆叠图,“Seasonal Split Line”表示生成的是季节性分割线。
如果在序列组(群)对象窗口下选择“View”|“Graph”选项,将弹出如图4-3所示的界面。
这里有9种图形可供选择。
其前4种与上面讲述的相同。
图4-3 序列组(群)窗口下图对象的生成其中,“Scatter”表示生成散点图。
在“Scatter”弹出的菜单中有5个选项,分别是“Simple Scatter”(简单散点图)、“Scatter with Regression”(带有回归线的散点图)、“Scatter with Nearest Neighbor Fit”(近邻匹配散点图)、“Scatter with Kernel Fit”(核心匹配散点图)、“XY Pairs”(XY成对散点图)。
当序列组中包含两个序列对象时,第一个序列对象的观测值构成散点图的横坐标,第二个序列对象的观测值构成散点图的纵坐标,如图4-4所示。
当序列组中有三个以上的序列对象时,第一个序列对象构成散点图的横坐标,其余序列对象构成散点图的纵坐标。
图4-4 简单散点图(“Simple Scatter”)“XY line”表示X与Y的折线图,横纵坐标分别表示两个序列对象的观测值。
“Error Bar”表示误差长条图,“High-Low”表示高低图,“Pie”表示饼图。
另外,在序列组(群)对象窗口下还可通过选择“View”|“Multiple Graphs”选项来生成图形。
此时图形显示在不同的坐标系中,即每个序列对象各形成一个图形,并显示在同一个窗口中。
除上面介绍的在序列对象窗口中生成图对象外,还可以通过选择EViews主菜单中的“Quick”|“Graph”选项来生成。
在“Graph”的菜单中选择图的类型,将弹出图4-5所示的文本框。
在文本框内输入序列或序列组的名称,例如“fdi”,然后单击“OK”按钮,即可打开相应的图。
此时所生成的图对象未被命名,单击图对象窗口中的“Name”按钮即可命名。
图4-5 生成图对象的文本框图形的冻结在上面所介绍的两种图对象生成方法中,通过“Quick”|“Graph”选项生成图形对象,单击图对象窗口工具栏中的“Name”选项,在弹出的对话框中输入该对象的名称,单击“OK”按钮后该对象即可被保存,并在工作文件窗口中显示图对象的图标。
但直接在序列对象窗口中形成的图形未被保存,当序列对象中的观测值发生改变时,或当前工作文件的样本范围发生变化时,图形也将随之改变。
如果要保留所建立的图形,使之不随样本及观测值的改变而发生变化,则可以通过序列对象窗口中的“Freeze”键来冻结图形。
EViews软件将被冻结的图形以一个图(Graph)对象的形式保存在工作文件中。
当选择序列对象窗口中的“Freeze”键时,会弹出图对象窗口。
其中有几个键值得关注,一个是“AddText”功能键,通过它可以将文字显示在图形中,并且可以选择显示的位置。
一个是“Line/Shade”功能键,通过它可以改变图形的背景颜色,横纵坐标轴的线条类型和颜色等。
还有一个是“Remove”功能键,可以用来删除图形中的一些附加要素。
例如,将在图形中所建立的文字删除,应首先用鼠标单击所需删除的内容,使其被选中,然后单击“Remove”键,则文字即被删除。
用同样的方法也可以删除为图形所设置的颜色等。
图形的复制如果需要将图形保存到其他文件中,例如放在Word文档中,则选择图对象窗口中的“Proc”|“Copy”选项,然后在弹出的对话框中单击“OK”按钮。
或者将鼠标移动到图形上,右击,在弹出的快捷菜单中选择“Copy”命令。
再打开需要粘贴的文件,进行粘贴即可。
描述性统计量EViews软件中包含一些基本的描述性统计量,有直方图、均值、方差、协方差、自相关等。
本节主要介绍序列和序列组对象窗口下的描述性统计量及其检验。
描述性统计量概述序列窗口下的描述性统计量和序列组窗口下的描述性统计量有所不同。
在序列窗口下有4种描述性统计量,分别是“Histogram and Stats”(直方图和统计量)、“Stats Table”(统计表)、“Stats by Classification”(分类统计量)和“Boxplots by Classification”(箱线图/箱尾图分类)。
序列组窗口下有3种描述性统计量,分别是“Common Sample”(普通样本)、“Individual Samples ”(个体样本)和“Boxplots ”(箱线图/箱尾图)。
下面分别进行详细介绍。
(1) 序列窗口下的描述性统计量在序列(Series)对象窗口下选择工具栏中的“View ”|“Descriptive Statistics ”(描述性统计量)选项,将出现4个选项。
第一个选项是“Histogram and Stats ”(直方图和统计量),能显示序列对象的直方图和描述性统计量的值。
下面以建立好的序列对象“fdi ”为例来进行说明。
如图4-6所示,图的左侧显示的是该序列对象的直方图,为观测值的频率分布。
右侧分三个部分,最上面显示的是序列对象的名称、样本的范围和样本数量。
中间部分显示的是各统计量的值。
其中,“Mean ”表示均值,即序列对象观测值的平均值;“Median ”表示中位数,即从小到大排列的序列对象观测值的中间值,是对序列分布中心的一个大致估计;“Maximum ”和“Minimum ”表示的是该序列观测值中的最大值和最小值;“”表示标准差,用来衡量序列观测值的离散程度。
其计算公式为 ∑=--=N i x x N i 1)(112σ (4-1)式中,σ为标准差,N 为样本观测值个数,x i 是样本观测值,x 为样本均值。
图4-6 序列对象“fdi ”的直方图分布形状和相关统计量的描述“Skewness ”表示偏度,用来衡量观测值分布偏离均值的状况。
其计算公式为 31ˆ1∑=⎪⎭⎫ ⎝⎛-=N i x x N S i σ (4-2)式中,σˆ是变量方差的有偏估计。
当S =0时,序列的分布是对称的,如正态分布;当S >0时,序列分布为右偏;当S <0时,序列分布为左偏。
例如图4-6中的偏度为 500>0,所以我国的外商直接投资(fdi)的分布是不对称的,为右偏分布形态。
“Kurtosis ”表示峰度,用来衡量序列分布的凸起状况。
其计算公式为 41ˆ1∑=⎪⎭⎫ ⎝⎛-=N i x x N K i σ (4-3) 正态分布的K 值为3,当K >3时,序列对象的分布凸起程度大于正态分布的凸起程度;当K <3时,序列对象的分布凸起程度要比正态分布小。
例如,图4-6中的峰度为 917 >3,外商直接投资(fdi)的分布呈尖峰状态。
最下方是JB(Jarque-Bera)统计量及其相应的概率(Probability)。
JB 统计量用来检验序列观测值是否服从正态分布,该检验的零假设为样本服从正态分布。
在零假设下,JB 统计量服从χ2(2)分布。
根据第1章所介绍的假设检验,P(Probability)值为拒绝原假设所犯第Ⅰ类错误的概率。
在本例中P 值接近于0,因而可在1%的显著性水平下拒绝零假设,即序列不服从正态分布。
第二个选项是“Stats Table ”(统计表),它将描述性统计量值通过电子表格的形式显示在对象窗口中。
第三个选项是“Stats by Classification ”(分类统计量),它将样本分为若干组后再对各组观测值分别进行描述统计。
选择此项后将弹出如图4-7所示的对话框,其中包括三部分内容。
在左边“Statistics ”选项中勾选需要显示的统计量,其中“# of NAs ”为无观测个数,“Observations ”为观测值个数。
在“Series/Group for classify ”中输入需分类的序列或序列组对象名称,右侧“Output Layout ”为输出结果的显示形式。
选择好后单击“OK ”按钮即可。
图4-7 “Stats by Classification”(分类统计量)对话框第四个选项是“Boxplots by Classification”(分类箱线图/箱尾图),将序列分布按照箱线图/箱尾图进行分类。
箱线图(Boxplot)也称为箱尾图,是利用数据统计量来描述数据的一种方法,它可以粗略地看出数据是否具有对称性,分布的分散程度等。
图4-8所示为fdi序列的分类箱线图。
图4-8 fdi序列对象的分类箱线图(“Boxplots by Classification”)(2) 序列组窗口下的描述性统计量在序列组(Group)对象窗口下选择工具栏中的“View”| “Descriptive Statistics”(描述性统计量)选项,将弹出3个选项。
第一个选项是“Common Sample”(普通样本),选择该项将得到含有均值、中位数、最大/小值等统计量的一张电子表格。
“Common Sample”要求各序列对象的样本范围相同,不能含有NA符(空值)。
第二个选项是“Individual Samples”(个体样本),选择该项后弹出的界面也是含有均值、中位数、最大/小值等统计量的一张电子表格。