把语音合成mp3文件怎么弄
- 格式:docx
- 大小:178.06 KB
- 文档页数:8

微信语音打包教程
微信语音打包是指将多个语音文件打包成一个文件,方便传输和保存。
以下是微信语音打包的步骤和方法。
第一步,准备语音文件。
打包前需要将需要的语音文件准备好,确保文件格式为支持的语音格式,如mp3、wav等。
第二步,打开文件压缩软件。
可以使用常用的压缩软件,如WinRAR或7-Zip等。
第三步,创建一个新的压缩文件。
在文件压缩软件中,点击“新建”或“创建”按钮,选择压缩文件的保存路径和文件名。
第四步,将语音文件添加到压缩文件中。
在压缩软件中,选择“添加文件”或“添加到压缩文件”选项,浏览并选择需要打包的
语音文件,点击“确定”或“添加”按钮。
第五步,调整压缩文件设置(可选)。
可以设置压缩文件的密码保护,压缩方法和压缩级别等。
根据需要进行设置,并点击“确定”或“应用”按钮。
第六步,等待打包完成。
根据语音文件的大小和电脑的性能,等待压缩软件完成打包过程。
处理速度可能会有所不同。
第七步,查看打包完成的压缩文件。
在保存路径中找到打包好的压缩文件,确认语音文件已经被成功打包。
通过以上步骤,语音文件被成功打包成一个压缩文件。
通过这个文件,可以方便地进行传输、分享和保存。
总结一下,微信语音打包是将多个语音文件打包成一个文件的过程。
只需准备好语音文件,通过文件压缩软件创建一个新的压缩文件,将语音文件添加到压缩文件中,并进行一些可选的设置,等待打包完成即可。
这样可以方便地进行传输和保存。

语音合成软件的音频格式转换和导出技巧语音合成软件是一种能够将文字转换成语音的工具,它在现代生活中有着广泛的应用,比如语音助手、有声图书、语音导航等等。
在使用语音合成软件的过程中,我们经常会遇到需要将合成的音频文件转换成不同格式或者导出到不同设备的情况。
本文将针对这些问题,介绍一些语音合成软件的音频格式转换和导出技巧。
首先,让我们来介绍一些常见的语音合成软件。
目前市面上有很多优秀的语音合成软件,比如百度语音合成、讯飞语音合成、Google Text-to-Speech等等。
这些软件都具有将文字转换成语音的功能,并且支持多种音频格式的导出。
不同的语音合成软件可能支持的音频格式有所不同,因此在选择软件的时候,需要根据自己的需求来进行选择。
其次,对于音频格式转换的技巧,我们可以利用一些专业的音频编辑软件来进行操作。
比如Audacity、Adobe Audition等等,这些软件都具有强大的音频格式转换功能,能够将不同格式的音频文件进行转换。
在使用这些软件的时候,我们需要先将合成的音频文件导入到软件中,然后选择需要转换的格式,进行相应的设置,最后导出即可。
此外,一些在线音频格式转换工具也是不错的选择。
比如在线转换网站、云转换等等,这些工具能够帮助我们快速地将音频文件转换成需要的格式。
在使用这些工具的时候,我们只需要上传需要转换的音频文件,选择目标格式,然后进行转换即可。
这些工具通常简单易用,适合对音频格式转换没有过多要求的用户。
最后,关于音频文件的导出技巧,我们需要根据具体的需求来选择合适的导出方式。
如果我们需要将音频文件导出到移动设备上进行播放,可以选择将文件通过数据线传输到设备中;如果我们需要将音频文件上传到网络进行分享,可以选择将文件导出到电脑中,然后通过网络传输工具进行上传。
总的来说,我们在导出音频文件的时候,需要考虑到目标设备和网络环境等因素,选择合适的导出方式。
综上所述,语音合成软件的音频格式转换和导出技巧是我们在使用语音合成软件时需要了解的重要内容。

我们走在大街上经常听到各种清仓大甩卖的叫卖声音,不知道你的店铺有没有这种需求,怎么用手机去做这种语音合成呢。
操作选用工具:在应用市场下载【文字转语音助手】
操作步骤:
第一步:首先我们在浏览器或者手机应用市场里面搜索:【文字转语音助手】然后进行下载并安装。
第二步:打开工具后会出现一个文件库的页面,在页面的下面一共有三个选择,分别是:文件库、一个【+】号和个人中心,我们在这里点击【+】号。
第三步:然后会出现一个【导入文件】和【新建文本】的页面,【导入文件】是把之前存储的文件导进来识别,【新建文本】是现在输入文字进行识别,可以根据自己的需求进行选择,小编这里以【新建文本】来做演示。
第四步:这时会出现一个【新建文本】的页面,在这里输入或者粘贴需要转换的文字,完成后点击预览。
第五步:点击预览之后,软件会对文字进行识别,耐心等待,识别完成之后,下面会有一个试听的按钮。
第六步:试听完成之后,还可以进行声音的设置,可以调整语速、音量以及音调,以及发音人。
第七步:试听完成之后,如果你下次还想听,可以点击右上角的勾号,默认认会勾选文本和转换音频一起保存,编辑好文件名称,点击右边保存按钮就行了。
以上就是语音合成的操作步骤了,更多好用、有趣的玩法,等你来探索哦。
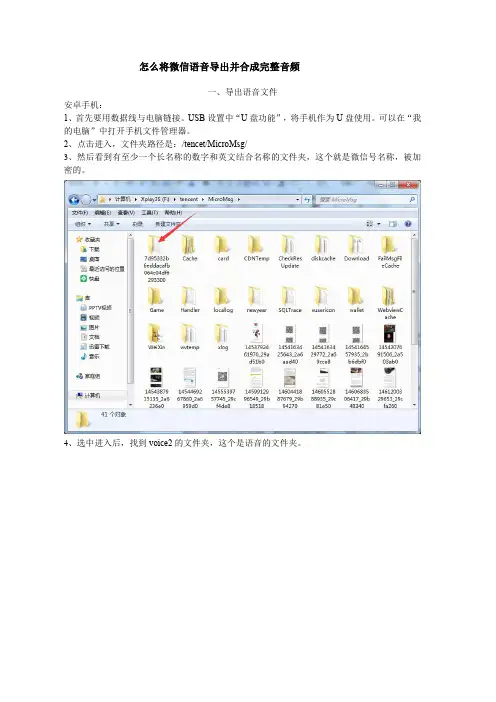
怎么将微信语音导出并合成完整音频一、导出语音文件安卓手机:1、首先要用数据线与电脑链接。
USB设置中“U盘功能”,将手机作为U盘使用。
可以在“我的电脑”中打开手机文件管理器。
2、点击进入,文件夹路径是:/tencet/MicroMsg/3、然后看到有至少一个长名称的数字和英文结合名称的文件夹,这个就是微信号名称,被加密的。
4、选中进入后,找到voice2的文件夹,这个是语音的文件夹。
5、打开后,看到的就是语音的文件夹,不过微信语音放的路径很乱,即使你连讲了三四个语音,它都会放到各个文件夹中,所以根本无法看到自己要找的语音放在什么地方。
怎么办呢?办法总比问题多的。
打开搜索功能,win7或win8 在右上角。
搜索栏中输入.amr。
6、搜索出来后,在“修改时间”里按倒序排列。
就直接找你需要的时间范围的语音就可以。
复制到电脑的就行了。
需要整理的语音较多的话,建议将语音文件按日期整理到不同文件夹二、转换语音文件的格式但是这个语音的格式显示是.amr 。
酷狗等播放器也播放不了。
但其实也不是AMR的格式, 是SKYPE的SILK, 然后还在最前面加了一个字节扰乱正常的SILK解码工具。
普通转换工具及音频解码器均无法正常解码。
当然还是有办法。
打开“微信语音AMR转MP3”在线版/amr/(建议用chrome浏览器或qq浏览器,感谢知友提供:怎么把微信语音信息的.amr文件转为.mp3文件? - 回答作者: 匿名用户/question/31286525/answer/75999860)上传需转换的语音文件。
点击文件名进行下载,并将这些文件按顺序整理好。
三、将多段语音合成将多段语音合成。
强烈推荐“mp3剪切合并大师”,一键合成。
下载地址:/detail/43/424910.shtml打开MP3语音剪切合并大师,选择“mp3合并”。
点击添加,一次选择中所有你要合并的语音。
点击“设置”,音频质量选择”64kbps“,这样合成的文件比较小。

语音打包的操作方法
语音打包是指将多个语音文件打包成一个统一的文件。
以下为常见的语音打包操作方法:
1. 使用压缩软件进行打包:可以使用压缩软件(如WinRAR、7-Zip)将多个语音文件压缩成一个打包文件。
选择要打包的语音文件,右键点击,选择“添加到压缩文件”或类似选项,设置打包文件的存储路径和格式,点击确定即可完成打包。
2. 使用命令行进行打包:可以使用命令行工具(如tar、zip)进行语音文件的打包。
在命令行中输入相应的打包命令,指定要打包的语音文件路径和打包文件的路径,运行命令即可完成打包。
3. 使用编程语言进行打包:如果需要进行批量的语音打包操作,可以使用编程语言来编写脚本实现打包功能。
例如,使用Python的zipfile库可以方便地进行文件打包操作,通过编写脚本来对语音文件进行批量的打包。
无论使用哪种方法进行语音打包,都要注意选择合适的打包格式(如zip、rar、tar.gz等),以便于后续的传输、存储和解压缩。

tts语音合成原理和流程
TTS(Text-to-Speech)语音合成技术是通过将文本转化为人工语音的过程。
其主要原理是通过语音合成引擎将输入的文字转化为声音。
下面是TTS语音合成的一般流程:
1. 文本预处理:对输入的文本进行预处理,包括拆分句子、词性标注、语法分析等。
2. 音素转换:将文本中的每个单词转化为对应的音素,音素是语音的最小单位,是构成语音的基本元素。
3. 音素拼接:将转换后的音素按照一定规则进行拼接,形成连续的音频流。
4. 声音合成:使用声音合成引擎,根据音素序列生成相应的语音波形。
5. 合成后处理:对合成出的语音进行后期处理,包括音量调整、语速控制、音色优化等。
6. 输出语音:将合成后的语音输出为音频文件或者直接播放出来。
整个流程的目标是通过模拟人类发声的过程,将输入的文本转化为自然流畅的人工语音,以便进行听觉交流。
TTS技术在语音助手、语音导航、语音学习等领域有着广泛的应用。
cooleditcooledit著名的多轨音频编辑软件,也就是专业录音室通常使用的软件1.实时的非破坏编辑。
2.为每一轨提供了实时效果器链。
3.实时均衡处理器。
4.多轨调音台。
5.多轨模式下对midi文件的支持。
6.可以实现数字式CD抓轨,同时提供批处理式的音乐格式转换或者压缩。
这个功能很强大,也非常方便。
7.对Loop的支持。
8.抽取并编辑视频文件中的音频。
9.X作界面更加灵活化。
10.新增加了几个效果器。
11.相位分析器。
在Analysis菜单下选择"Show Phase Analysis",即可打开相位分析器。
可以对立体声音频文件的相位进行细致的分析。
12.支持更多轨数。
从1.2版的最多64轨翻了一倍,现在可以支持最多128轨了。
13.更多的包络编辑功能。
在1.2版的音量包络和声相包络的基础上,2.0版新增加了3种包络编辑功能:Wet/Dry Envelopes对某一轨上加载的效果器量(干/湿)进行调节。
FX Parameter Envelopes对某一轨上加载的动态效果(如Dynamic EQ,Dynamic Delay)的量进行调节。
Tempo Envelopes对midi轨的速度进行调节。
14.用鼠标拖拽波形的长短。
15.内置的节拍器。
16.支持更多的音频文件格式。
常用的包括wav, mp3, mp3pro, raw, cel, cda, voc, vox,录音是所有后期制作加工的基础,这个环节出问题,是无法靠后期加工来补救的,所以,如果是原始的录音有较大问题,就重新录吧。
cooledit1.打开CE进入多音轨界面右击音轨1空白处,插入你所要录制歌曲的mp3伴奏文件,wav 也可(图1)。
cooledit2.选择将你的人声录在音轨2,按下“R”按钮。
(图2)cooledit3.按下左下方的红色录音键,跟随伴奏音乐开始演唱和录制。
(图3)cooledit4.录音完毕后,可点左下方播音键进行试听,看有无严重的出错,是否要重新录制(图4)cooledit5.双击音轨2进入波形編辑界面(图5),将你录制的原始人声文件保存为mp3pro格式(图6 图7),以前的介绍中是让大家存为wav格式,其实mp3也是绝对可以的,并且可以节省大量空间。

程序实现拼接mp3的原理在日常生活中,我们可能会遇到需要将多个MP3音频文件拼接成一个文件的情况。
比如,我们想将多个歌曲合并成一首歌,或者将多个录音拼接成一个文件。
这个时候,我们就需要用到拼接MP3的技术。
拼接MP3的原理其实很简单,就是将多个MP3文件的音频数据流合并成一个文件。
这个过程涉及到两个主要的步骤:解码和编码。
解码在MP3文件中,音频数据被压缩存储,需要进行解码才能得到原始音频数据流。
在解码过程中,我们需要使用解码器来将MP3文件解码成原始音频数据流。
解码器会读取MP3文件的头部信息,包括采样率、码率、声道数等参数,然后将音频数据解码成原始音频数据流。
编码在将多个MP3文件合并成一个文件时,我们需要将每个文件的音频数据流合并成一个文件,然后再进行编码。
编码过程中,我们需要使用编码器将原始音频数据流编码成MP3格式的音频数据流。
编码器会根据采样率、码率、声道数等参数将原始音频数据流压缩并编码成MP3格式的音频数据流。
拼接在MP3文件解码和编码完成后,我们就可以将多个MP3文件的音频数据流合并成一个文件。
这个过程中,我们需要将每个文件的音频数据流按顺序合并成一个文件,然后再进行编码。
合并和编码过程中,我们需要注意每个文件的音频数据流的格式和参数,保证每个文件的音频数据流能够无缝地拼接在一起。
总结拼接MP3的原理就是将多个MP3文件的音频数据流合并成一个文件。
这个过程中,我们需要进行解码和编码,保证每个文件的音频数据流能够无缝地拼接在一起。
在实际操作中,我们可以使用专业的音频处理工具,如Audacity、Adobe Audition等,来进行MP3文件的拼接和处理。
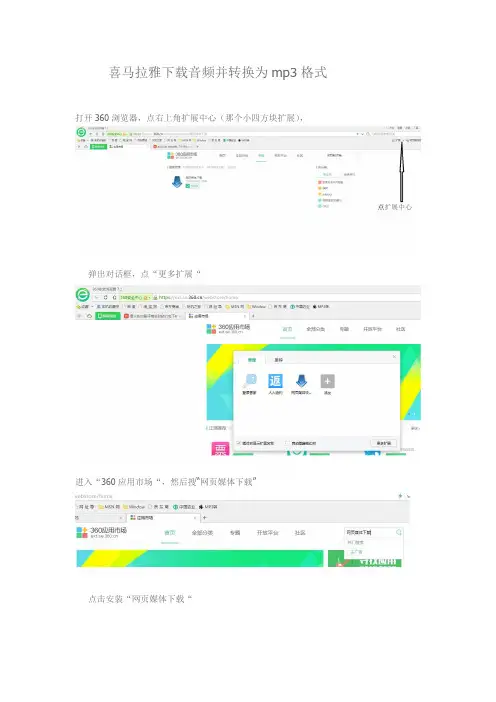
喜马拉雅下载音频并转换为mp3格式打开360浏览器,点右上角扩展中心(那个小四方块扩展),
弹出对话框,点“更多扩展“
进入“360应用市场“,然后搜“网页媒体下载”
点击安装“网页媒体下载“
然后打开你要下载的音频页面,点击播放音频,打开右上角“箭头网页媒体“,就会显示已经提取出音频了,下载。
喜马拉雅上直接下载的格式不是mp3格式,将扩展名改成.mp3就可以了。
批量改扩展名:开始--运行CMD—进入DOS模式—cd命令进入存放要修改扩展名的目录。
cd abc回车(例如目录名为“abc”,dir命令查看目录中有什么文件,ren改文件名或扩展名。
) ren *.m4a *.mp3
下图为DOS下执行REN命令:
完成改扩展名。
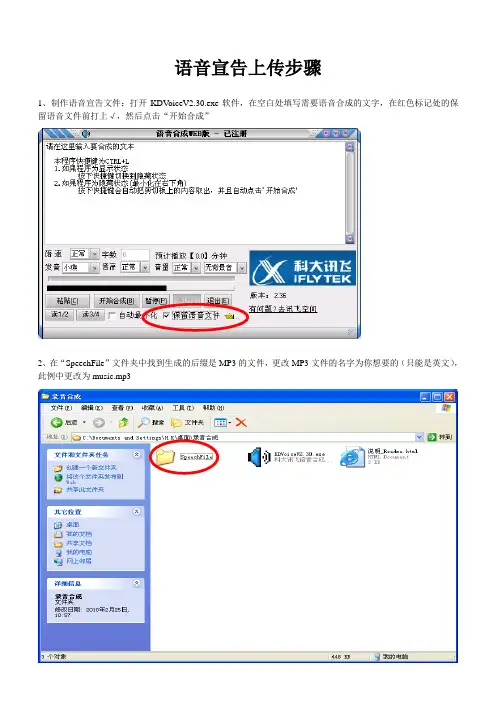
语音宣告上传步骤1、制作语音宣告文件:打开KDV oiceV2.30.exe软件,在空白处填写需要语音合成的文字,在红色标记处的保留语音文件前打上√,然后点击“开始合成”2、在“SpeechFile”文件夹中找到生成的后缀是MP3的文件,更改MP3文件的名字为你想要的(只能是英文),music.mp3此例中更改为3、打开音乐编辑软件GoldWave,点击打开按钮4、选择music.mp3文件打开5、打开后出现如下窗口6、选择要编辑的音乐段落进行编辑7、编辑完成后点击“文件”菜单,选择“另存为”8、选择“保存类型”为“Wave (*.wav)”9、选择“音质”为“A-Law,8000 Hz,64 kbps,单声”,然后保存文件10、进入Avaya Site Administration软件,输入命令enable filexfer后回车打开语音宣告板卡的FTP上传开关,,如图:CM:110.46 TN2501:110.5211、设置FTP的用户名Login和密码Password,此例Login为huapu,Password为huapu01,设置Secure为n,Board address设置为1a0412、按F3确认,成功后显示如红色标记处显示13、在电脑上打开“命令提示符”14、进到存放音频文件music.mp3的文件夹下,输入命令回车15、输入ftp用户名16、输入ftp的密码,密码不会显示出来17、进入后输入pro18、输入19、把文件传到交换机上(用于更换或添加新的语音宣告文件)20、把交换机上文件下载到电脑(用于备份或需要编辑交换机上的音频文件)21、完成后使用quit命令退出22、使用add announcement xxxx增加语音宣告号码(xxxx是语音宣告号码)Annc Name必须与上传到交换机的语音文件名字完全相同Annc Type 选择integrated类型Group/Board 选择1a04其他的保持不变,按F3确认23、输入命令disable filexfer board 1a04关闭语音宣告板的FTP上传开关。

把语⾳合成mp3⽂件怎么弄
⼴告促销、地摊叫卖配⾳需求量⼤,真⼈录⾳成本太⾼,⽽且不及时。
低成本、⾼效性、便捷性的录⾳⼯具能受到⼈们的喜爱,现在就教⼤家如何语⾳合成⼴告配⾳。
操作选⽤⼯具:在应⽤市场下载【⽂字转语⾳助⼿】
操作步骤:
第⼀步:⾸先我们在浏览器或者⼿机应⽤市场⾥⾯搜索:【⽂字转语⾳助⼿】然后进⾏下载并安装。
第⼆步:打开⼯具后会出现⼀个⽂件库的页⾯,我们在这⾥点击中间的蓝⾊【+】号。
演⽰。
上⾓的全部⽂件按路径查找⽂本。
第五步:导⼊之后,点击预览,软件会对⽂字进⾏识别,耐⼼等待,识别完成之后,下⾯会有⼀个试听的按钮。
第六步:试听完成之后,可以进⾏声⾳的设置,调整语速、⾳量、⾳调以及发⾳⼈的声⾳。
第七步:试听满意之后可以点击右上⾓的勾号,在弹出的界⾯勾选⽂本和语⾳,编辑好⽂件名称,点击保存就⾏了。
以上就是语⾳合成的操作步骤了,如果你有需求,可以去下载⽤⽤看哦。
如何提取微信语音制成MP3格式
——蔡菜老师的分享我们有很多老师的分享,有用文字,有用语音,文字的适合实际操作内容,语音适合方向思维的课程。
语音只能收藏在微信收藏夹,很不方便,我都是提取出来,传上云盘随时可以听,随时洗脑。
有的语音很精华,我们记不住的,我就要把这些提取出来,很多人不知道这个干货,我没事就琢磨的~
首先我分享苹果手机的。
第一步:下载3个软件,一个苹果自带的itunes,一个itools,一个视频编辑软件。
(微商创业赢)
第二步:手机连接电脑,打开itools这个软件,有个微信管理,点击。
第三步:点击后进入以下界面。
找到需要导出语音的微信群,看以下箭头,点击导出。
点击导出后进入以下界面,只能一段段保存,记得妥善命名不要乱,如1、2、3……,否则后面合成的会乱。
第四步:合成成为一个文件。
打开视频编辑器,选择视频合并,后点击添加,选择语音
添加完成后点击下一步,选择保存格式,一般为mp3或m4a,点击下一步文件就开始合成,就可以成为一个文件了。
文字转语音:讯飞软件
下次分享:如何同步手机界面到电脑显示屏中。
如何使用Premiere Pro进行音频合成处理Adobe Premiere Pro 是一款被广泛用于视频编辑的专业软件。
除了视频编辑功能外,它还具备强大的音频处理功能,能够帮助用户实现高质量的音频合成处理。
本文将教你如何在 Premiere Pro 中进行音频合成处理。
1. 导入音频素材首先,打开 Premiere Pro 软件。
点击“文件”菜单,选择“导入”,然后在弹出的对话框中选择你希望合成处理的音频素材文件。
将素材文件拖动至项目面板中,即可完成导入。
2. 创建新的音轨在项目面板中,右键单击空白区域,选择“新建条目” -> “音频轨道”。
在弹出的对话框中,选择音轨的数量和格式,点击“确定”按钮创建新的音轨。
3. 添加音频素材到音轨在时间轴面板中,将需要合成处理的音频素材拖动到相应的音轨上。
你可以使用鼠标拖动来调整素材在音轨上的位置,以达到合适的效果。
4. 调整音频素材的音量选中音频素材,点击右侧的“音量”面板,可以调整音频的音量大小。
你可以直接在面板上拖动滑块,或者手动输入具体数值来调整音量。
5. 淡入淡出效果在音频素材的开头和结尾处,可以添加淡入淡出效果,使音频的开始和结束更加平滑。
选中音频素材,点击右侧的“音量”面板,在“音频调整”选项中,勾选“淡入淡出”复选框。
根据需要,调整淡入淡出效果的持续时间和曲线形状。
6. 使用音频效果器Premiere Pro 提供了丰富的音频效果器,可以帮助你对音频进行各种处理。
选中音频素材,点击右侧的“音频效果器”面板,在列表中选择你希望使用的效果器。
例如,你可以使用均衡器来调整音频的频率平衡,使用降噪效果器来消除背景噪音等。
7. 调整音频的音高和速度如果你希望调整音频素材的音高或速度,可以使用 Premiere Pro 提供的音频效果器来实现。
选中音频素材,点击右侧的“音频效果器”面板,在“变速倒放”选项中,选择你希望应用的效果器,并调整对应的参数。
语音合成的流程
1. 文本分析:
- 将需要合成的文本内容进行预处理,包括标点符号、缩略词、数字等的规范化处理。
- 进行文本分词,划分出句子、词语的边界。
- 进行语音学分析,确定每个词的发音、重音位置等信息。
2. 语音单元选取:
- 根据预先录制的语音单元库(包括单音、音节、单词等),为每个词选取合适的语音单元。
- 考虑语音单元之间的连接平滑性,选取最佳拼接序列。
3. 语音修改:
- 根据语境和语音环境,对选取的语音单元进行修改,包括时长、音高、能量等参数调整。
- 使用算法模型(如PSOLA、TD-PSOLA等)对语音单元进行时长修改,实现自然的节奏和语速。
4. 语音合成:
- 将修改后的语音单元按顺序连接,生成完整的语音波形。
- 处理连接处的不连续,使语音过渡更加自然流畅。
5. 信号处理:
- 对合成的语音波形进行信号处理,如增加自然的震动、混响等效果,
提高语音真实感。
- 进行编码、压缩等处理,以减小文件大小,方便存储和传输。
6. 输出:
- 将最终合成的语音输出为音频文件(如WAV、MP3等格式)。
- 也可以直接通过音频设备实时播放合成的语音。
语音合成的核心是基于语音单元库和算法模型,将文本转换为可听的人工语音信号。
通过上述流程,可以实现自然、流畅的语音合成效果。
剪映转mp3的方法
剪映是一款视频编辑软件,通常用于剪辑和编辑视频,而不是用于音频提取。
然而,如果你想从剪映中提取音频并将其转换为MP3格式,你可以使用以下方法:
1. 使用剪映软件自身,在剪映中,你可以导出视频并选择只保留音频部分。
然后你可以将这个音频文件导入到其他音频编辑软件中,比如Audacity或Adobe Audition,然后再将它导出为MP3格式。
2. 使用在线转换工具,有许多在线工具可以将视频文件转换为音频文件,比如Zamzar、OnlineVideoConverter等。
你可以上传你的剪映导出的视频文件,然后选择MP3作为输出格式进行转换。
3. 使用专业的视频转音频软件,有一些专门用于提取音频的软件,比如WonderShare UniConverter、Freemake Video Converter 等。
你可以使用这些软件来导入剪映导出的视频文件,然后将其转换为MP3格式。
需要注意的是,无论使用哪种方法,你都应该确保你有权利使
用视频中的音频内容,遵守相关的版权法律和规定。
另外,转换后
的MP3文件也应该符合你的使用目的,比如个人使用、教育用途等。
希望这些方法能够帮助你成功将剪映中的音频转换为MP3格式。
苹果仍然是大众非常喜爱的手机品牌,但他们独特ios系统,跟安卓的不一样,下一些App Store里边没有的软件还得越狱,今天,小编就教大家一个小技巧,怎么在苹果手机上做语音合成,这个软件在App Store里边就可以找到。
操作选用工具:在应用市场下载【文字转语音助手】
操作步骤:
第一步:首先我们在浏览器或者手机应用市场里面搜索:【文字转语音助手】然后进行下载并安装。
第二步:打开工具后会出现一个文件库的页面,在页面的下面一共有三个选择,分别是:文件库、一个【+】号和个人中心,我们在这里点击【+】号。
第三步:然后会出现一个【导入文件】和【新建文本】的页面,【导入文件】是把之前存储的文件导进来识别,【新建文本】是现在输入文字进行识别,可以根据自己的需求进行选择,小编这里以【新建文本】来做演示。
第四步:这时会出现一个【新建文本】的页面,在这里输入或者粘贴需要转换的文字,完成后点击预览。
第五步:点击预览之后,软件会对文字进行识别,耐心等待,识别完成之后,下面会有一个试听的按钮。
第六步:试听完成之后,还可以进行声音的设置,可以调整语速、音量以及音调,以及发音人。
第七步:试听完成之后,如果你下次还想听,可以点击右上角的勾号,默认认会勾选文本和转换音频一起保存,编辑好文件名称,点击右边保存按钮就行了。
文字转语音助手转换起文件来也是很方便实用的,如果你需要语音合成的话,不妨试试哦。
教师助手使用说明文档教师助手使用说明V2.1.0 英语人机对话同步训练(牛津版)南京听说科技有限公司4000-186-178教师助手使用说明文档目录一、教师助手介绍 (3)二、阅读试卷 (6)三、试卷编辑 (10)1. 编辑听力材料以及编辑听力试卷 (10)2. 文本转mp3 (17)四课堂听写 (20)1.编辑听写材料 (20)2.导入自制试卷 (28)五课文领读与讲解 (31)六单元知识点讲解 (37)七资源共享 (41)1.图片资源共享 (41)2.音频资源共享 (43)八课堂用语 (46)九、典型案例 (51)1.自制听力试卷进行课堂测验 (51)2. 自制对话类听力材料MP3文件 (56)教师助手使用说明文档一、教师助手介绍教师助手是南京听说科技有限公司软件产品中的一个特色功能模块,是依托听说科技的海量内容,基于听说科技强大的多媒体技术、计算机技术和语音评测与合成技术开发而成,通常会嵌在听说科技软件产品的教师版中,主要是辅助教师进行一些特殊的教学活动,如试卷讲评、试卷发布、听力音频材料制作等。
教师助手工具有下面几方面的功能:1. 阅读试卷:针对学生版产品导出的模拟考场试卷答卷包进行阅卷,可以查看学生分数和具体作答情况,便于老师了解学生的具体掌握情况进行有针对性的试卷点评。
2.试卷编辑:本部分主要是包括三块:●编辑听力材料:此功能主要是针对教师手中的听力材料,用此功能生成听力音频,供教师播放使用。
●编辑听力试卷:此功能主要是为老师编辑一份完整试卷提供帮助,用此功能可以生成听力试卷以及配套的听力音频。
●文本转MP3:此功能可以将一段中文或英文文章转换成音频文件,供教师播放使用。
●打开试卷:此功能可以打开一份以前保存的未编辑完成的试卷,继续进行编辑。
3. 词汇听写:主要用于帮助教师课堂听写单词、词组或者文中句子。
对于需要听写的单词、词组以及句子提供英文发音和中文释义发音两种。
4.课文领读与讲解:主要是针对课文中的朗读短文部分提供朗读、领读以及跟读的功能,方便教师教学。
广告促销、地摊叫卖配音需求量大,真人录音成本太高,而且不及时。
低成本、高效性、便捷性的录音工具能受到人们的喜爱,现在就教大家如何语音合成广告配音。
操作选用工具:在应用市场下载【文字转语音助手】
操作步骤:
第一步:首先我们在浏览器或者手机应用市场里面搜索:【文字转语音助手】然后进行下载并安装。
第二步:打开工具后会出现一个文件库的页面,我们在这里点击中间的蓝色【+】号。
第三步:然后会跳转到【导入文件】和【新建文本】的界面,在此可以根据自己的需求进行选择,小编这里拿【导入文件】做演示。
第四步:这时会进入一个导入文件的界面,里面是手机已经保存好的文本,在这里选择需要转换的文本,没有的话可以点击右上角的全部文件按路径查找文本。
第五步:导入之后,点击预览,软件会对文字进行识别,耐心等待,识别完成之后,下面会有一个试听的按钮。
第六步:试听完成之后,可以进行声音的设置,调整语速、音量、音调以及发音人的声音。
第七步:试听满意之后可以点击右上角的勾号,在弹出的界面勾选文本和语音,编辑好文件名称,点击保存就行了。
以上就是语音合成的操作步骤了,如果你有需求,可以去下载用用看哦。