10KV系统实验报告-完整表格数据--
- 格式:docx
- 大小:101.49 KB
- 文档页数:44

10kv实验项目耐压试验步骤报告英文回答:HV Insulation System Test Report.1. Introduction.This report describes the procedure for performing high voltage insulation system tests on electrical equipment.The purpose of the test is to verify the integrity of the insulation system and to ensure that the equipment will operate safely at the specified voltage level.2. Test Procedure.The test procedure shall be conducted in accordancewith the following steps:Visual Inspection: The insulation system shall be visually inspected for any signs of damage or deterioration.This includes checking for cracks, breaks, or other defects.Dielectric Strength Test: The dielectric strength ofthe insulation system shall be tested by applying a high voltage between the conductor and ground. The voltage shall be increased gradually until the insulation breaks down.The breakdown voltage shall be recorded.Insulation Resistance Test: The insulation resistanceof the insulation system shall be tested by measuring the resistance between the conductor and ground. The resistance shall be measured at a high voltage and a low voltage.Partial Discharge Test: The insulation system shall be tested for partial discharges by applying a high voltageand measuring the partial discharge activity. The partial discharge activity shall be measured at a variety of voltages and frequencies.3. Test Equipment.The following equipment shall be used to conduct thetest:High Voltage Power Supply: The high voltage power supply shall be capable of supplying the required voltage and current for the test.Dielectric Strength Tester: The dielectric strength tester shall be capable of measuring the breakdown voltage of the insulation system.Insulation Resistance Tester: The insulation resistance tester shall be capable of measuring the insulation resistance of the insulation system.Partial Discharge Detector: The partial discharge detector shall be capable of measuring the partial discharge activity of the insulation system.4. Safety Precautions.The following safety precautions shall be observed during the test:Personal Protective Equipment (PPE): The personnel performing the test shall wear appropriate PPE, including gloves, safety glasses, and a hard hat.Electrical Hazards: The test area shall be properly grounded and the equipment shall be properly insulated.Fire Hazards: The test area shall be kept clear of flammable materials.Emergency Procedures: Emergency procedures shall be established and communicated to the personnel performing the test.5. Test Data.The following data shall be recorded during the test:Visual Inspection: The results of the visual inspection shall be recorded, including any signs of damage or deterioration.Dielectric Strength Test: The breakdown voltage shall be recorded.Insulation Resistance Test: The insulation resistanceat the high voltage and the low voltage shall be recorded.Partial Discharge Test: The partial discharge activity at the various voltages and frequencies shall be recorded.6. Test Report.The test report shall include the following information:Test Date: The date the test was performed.Test Location: The location where the test was performed.Test Personnel: The names of the personnel who performed the test.Equipment Used: The equipment that was used to perform the test.Test Results: The results of the test, including the data recorded during the test.Conclusions: The conclusions of the test, including whether the insulation system passed or failed the test.Recommendations: Any recommendations for corrective action, if necessary.中文回答:10kV 试验项目耐压试验步骤报告。



10kv电气设备高压试验报告变电站名称:煤炭总院
调试日期:2011年7月15日
宁夏天净隆鼎电力有限公司送变电工程分公司
接地电阻试验报告
名称:泰和翔达
测试日期:2011.6 测试地点11#杆处使用仪器4102
北
11#杆处接地电阻:
3.3Ω
结论:
合格
试验人员崔立兵张志强
审核复审
接地电阻试验报告
名称:泰和翔达
测试日期:2011.6 测试地点1#杆处使用仪器4102 北
1#杆处接地电阻:
3.1Ω
结论:
合格
试验人员崔立兵张志强
审核复审
接地电阻试验报告
结论: 名称:泰和翔达
测试日期:2011.6 测试地点 513简林线9#杆
处 使用仪器 4102
513简林线9#杆处接地
电阻:3.2Ω
北
合 格
试验人员
崔立兵 张志强 审 核 复 审
接地电阻试验报告
名称:泰和翔达
测试日期:2011.6 测试地点2#动力变处使用仪器4102 北
2#动力变处接地电
阻:3.5Ω
结论:
合格
试验人员崔立兵张志强
审核复审
接地电阻试验报告
名称:泰和翔达
测试日期:2011.6 测试地点1#杆动力变使用仪器4102 北
1#动力变处接地
电阻:3.3Ω
结论:
合格
试验人员崔立兵张志强
审核复审。

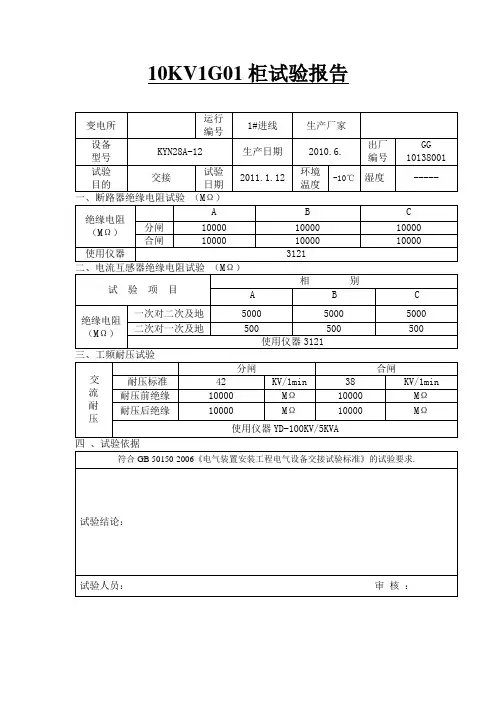
10kV高压开关柜试验报告[object Object]一、试验目的本次试验旨在对10kV高压开关柜进行全面的功能性试验,以验证其在正常运行情况下的性能和可靠性。
二、试验内容1.基本功能试验:包括开关柜的分、合、跳闸操作试验,分合闸时间试验,分合闸位置试验等。
2.电流互感器试验:检查电流互感器的接线是否正确,是否能正常工作。
3.电压互感器试验:检查电压互感器的接线是否正确,是否能正常工作。
4.遥控试验:使用遥控装置对开关柜进行遥控操作试验,检查遥控功能是否正常。
5.保护试验:对开关柜的各种保护装置进行试验,包括过电流保护、短路保护、接地保护等。
6.隔离开关试验:对开关柜的隔离开关进行试验,检查其分合闸是否正常。
7.漏电流试验:对开关柜的漏电流进行试验,检查其漏电流是否在规定范围内。
8.绝缘电阻试验:对开关柜的绝缘电阻进行试验,检查其绝缘性能是否满足要求。
三、试验结果及分析1.基本功能试验结果:开关柜的分、合、跳闸操作正常,分合闸时间符合要求,分合闸位置准确。
2.电流互感器试验结果:电流互感器的接线正确,能够准确地测量电流。
3.电压互感器试验结果:电压互感器的接线正确,能够准确地测量电压。
4.遥控试验结果:遥控装置能够正常对开关柜进行遥控操作。
5.保护试验结果:各种保护装置能够准确地工作,及时跳闸保护电气设备。
6.隔离开关试验结果:隔离开关的分合闸操作正常。
7.漏电流试验结果:开关柜的漏电流在规定范围内,符合要求。
8.绝缘电阻试验结果:开关柜的绝缘电阻满足要求,能够保障设备的安全运行。
四、结论经过全面的试验,本次对10kV高压开关柜的功能性试验结果良好,各项指标均符合要求,证明开关柜在正常运行情况下性能可靠,能够满足电气设备的运行要求。
建议将该开关柜投入使用,并定期进行维护和检修,以保障设备的长期稳定运行。
五、存在问题及改进措施在试验过程中,未发现开关柜存在明显的问题。
然而,为了进一步提高设备的可靠性和安全性,建议在投入使用后定期对开关柜进行维护和检修,及时排除潜在问题,确保设备长期稳定运行。

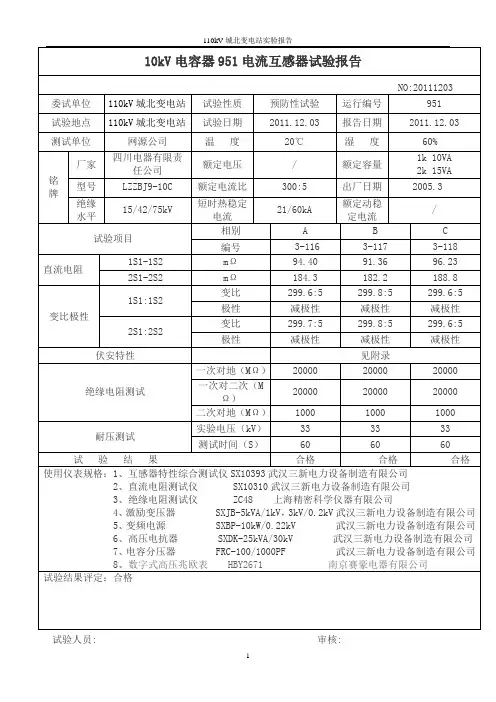
试验人员: 审核:试验人员: 审核:试验人员: 审核:试验人员: 审核:试验人员: 审核:试验人员: 审核:试验人员: 审核:试验人员: 审核:试验人员: 审核:试验人员: 审核试验人员: 审核:试验人员: 审核:试验人员: 审核:试验人员: 审核:试验人员: 审核:试验人员: 审核:试验人员: 审核:试验人员: 审核:试验人员: 审核:试验人员: 审核:试验人员: 审核:试验人员: 审核:试验人员: 审核:试验人员: 审核试验人员: 审核:试验人员: 审核:试验人员: 审核:试验人员: 审核:试验人员: 审核:试验人员: 审核:试验人员: 审核:试验人员: 审核:目录10kV电容器951电流互感器试验报告 (1)10kV电容器951断路器试验报告 (2)10kV电容器951开关柜避雷器试验报告 (3)10kV电容器951零序电流互感器试验报告 (4)10kV电容器952电流互感器试验报告 (5)10kV电容器952断路器试验报告 (6)10kV电容器952开关柜避雷器试验报告 (7)10kV电容器952零序电流互感器试验报告 (8)10kV城厂线953电流互感器试验报告 (9)10kV城厂线953断路器试验报告 (10)10kV城厂线953开关柜避雷器试验报告 (11)10kV城厂线953零序电流互感器试验报告 (12)10kV城花线954电流互感器试验报告 (13)10kV城花线954断路器试验报告 (14)10kV城花线954开关柜避雷器试验报告 (15)10kV城花线954零序电流互感器试验报告 (16)10kV城峡线955电流互感器试验报告 (17)10kV城峡线955断路器试验报告 (18)10kV城峡线955开关柜避雷器试验报告 (19)10kV城峡线955零序电流互感器试验报告 (20)10kV城愉线956电流互感器试验报告 (21)10kV城愉线956断路器试验报告 (22)10kV城愉线956开关柜避雷器试验报告 (23)10kV城愉线956零序电流互感器试验报告 (24)10kV城石线957电流互感器试验报告 (25)10kV城石线957断路器试验报告 (26)10kV城石线957开关柜避雷器试验报告 (27)10kV城石线957零序电流互感器试验报告 (28)10kV城水线958电流互感器试验报告 (29)10kV城水线958断路器试验报告 (30)10kV城水线958开关柜避雷器试验报告 (31)10kV城水线958零序电流互感器试验报告 (32)10kV 1MPT试验报告 (33)10kV 1MPT开关柜避雷器试验报告 (34)。

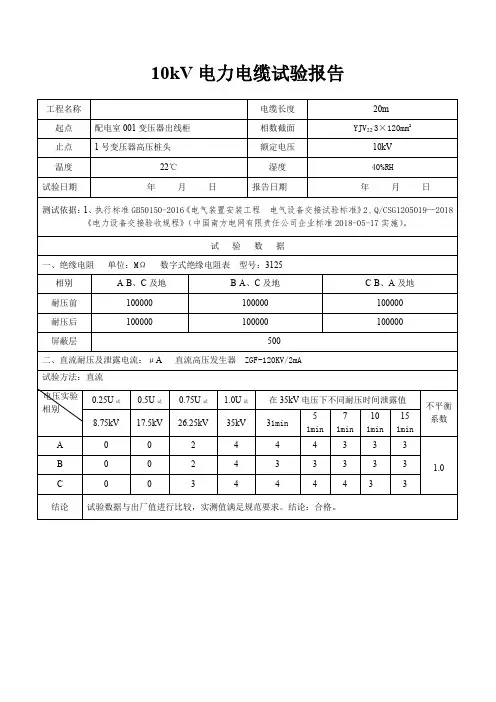
配电设备交接试验报告书用电单位:XXXXXX改造工程用电容量:400kVA试验单位:有限公司年月日报告目录#1母线PT柜 (3)10kV电压互感器试验报告 (3)10kV避雷器试验报告 (4)电压并列装置试验报告 (5)1#变出线柜 (9)10kV真空断路器试验报告 (9)10kV电流互感器试验报告 (10)10kV零序电流互感器试验报告 (11)10kV高压电缆试验报告 (12)继电保护试验报告 (13)文化#1线柜 (14)10kV真空断路器试验报告 (14)10kV电流互感器试验报告 (15)10kV电压互感器试验报告 (16)10kV高压电缆试验报告 (17)继电保护试验报告 (18)分段柜 (19)10kV真空断路器试验报告 (19)10kV电流互感器试验报告 (20)10kV高压电缆试验报告 (21)继电保护试验报告 (22)备自投试验报告 (23)金马新区#2线柜 (26)10kV真空断路器试验报告 (26)10kV电流互感器试验报告 (27)10kV电压互感器试验报告 (28)继电保护试验报告 (29)#2母线PT柜 (30)10kV电压互感器试验报告 (30)10kV避雷器试验报告 (31)工频耐压试验报告 (32)地网接地电阻交接试验 (33)安全工器具试验报告 (34)变压器试验报告 (35)#1母线PT柜10kV电压互感器试验报告使用单位:XXXXXX改造工程装设位置:10kV #1母线PT柜测试天气:晴温度:31°C 湿度:65%试验结果:依据GB50150-2016 电气装置安装工程电气设备交接试验标准判定合格。
五、试验人员:六、审核人员:七、试验日期:年月日10kV避雷器试验报告使用单位:XXXXXX改造工程装设位置:10kV #1母线PT柜测试天气:晴温度:31°C 湿度:65%试验结果:依据GB50150-2016 电气装置安装工程电气设备交接试验标准判定合格。
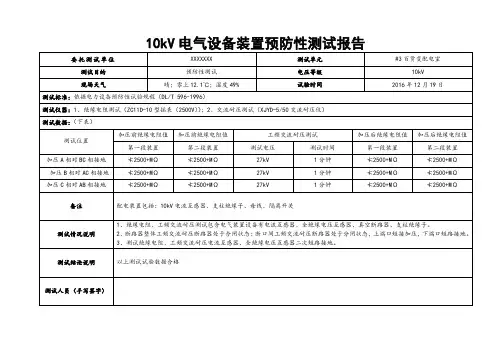
10KV现场试验报告630电气设备试验调试报告 (交接)报告类型: 100kVA变压器试验报告日期: 201 年月日客户名称:项目名称:审核:批准:编制:10KV变压器现场试验记录型号: S-M-100/10 额定容量:100KV A 额定电压:10/0.4 日期:2014年8月出厂序号:R14087 联接组标号:Y,yno生产厂家:上海浦变徐州变压器有限公司短路阻抗:4%一:绕组联同套管的直流电阻线圈分接位置AB BC AC 电阻不平衡率%10KV (Ω) 1 19.050 19.024 19.014 0.192 18.067 18.042 18.036 0.183 17.062 17.037 17.032 0.16 450.4kv侧(MΩ)ao bo co 电阻不平衡率% 12.265 12.328 12.125 1.6二:联接组别检查:变压器三相接线组别正确。
三:变压比检查:分接位置分接位置(V)额定变比电压比偏差(%)AB/ab BC/bc ACac1 10500 26.25 -0.01 -0.02 -0.042 10000 25.00 -0.02 -0.01 -0.013 9500 23.75 -0.01 -0.00 -0.0045四:绕组连同套管的绝缘电阻(MΩ)测试绕组接地绕组实验后R15S R60S 吸收比高压低压150****0001.3低压高压150****0001.3五:绕组连同套管的交流耐压:测试绕组试验电压时间(min)结论高压 28 1 通过六:绝缘油耐压(kV)击穿电压38实验结论:所做试验项目结果符合GB1094.1.2 GB1094.3.5-2006规程有关规定使用仪器:ZTHY-2000V数字式高压绝缘电阻测试仪ZT-20A变压器直流电阻测试仪ZTBC-Ⅱ全自动变比测试仪TC-YDQ-10kVA/50kV高压试验变压器试验负责人:编制:试验人员:天气:晴试验温度:10℃试验日期:10KV氧化锌避雷器现场试验记录型号HY5WZ-17/50 生产厂家西安西电电瓷器厂试验项目/相别 A B C 绝缘底座(MΩ)∞∞∞直流1mA电压(KA)26.5 27.2 26.5 绝缘电阻(MΩ)∞∞∞0.75UmA下泄漏电流μA 2.3 1.7 2.3 结论合格使用仪器:ZTHY-2000V数字式高压绝缘电阻测试仪直流高压发生器 ZGF-120/2试验负责人:编制:试验人员:天气:晴试验温度:10℃试验日期:接地网现场测试记录测试地点主接地接地电阻值 2.99测试地点80KVA变压器主接地接地电阻值 3.11使用仪器:ZTDW-R接地电阻测试仪试验负责人:编制:试验人员:天气:晴试验温度:10℃试验日期:10KV户外真空断路器现场试验记录型号:ZW32-12/M 出厂日期:2013年10月生产厂家:浙江博力电气有限公司出厂编号:2863试验项目/相别实验电流试验数据A B C回路电阻(μΩ)100A 43 47 45绝缘电阻测试(G Ω) 测试相接地相试验前试验后结果R15S R60S 吸收比R15S R60S 吸收比整体及地80000 100000 1.25 80000 100000 1..25 通过交流耐压(KV )测试相接地相试验电压结果一次绕组二次绕组及地42kV1min 通过隔离开关对地38kV1min 通过PT耐压试验一次绕组二次绕组及地30kV1min 通过动作过流定值速断100A 时限0s 过流8A 时限0.3s通过试验过流电流(A)7.9A 动作时间(s)0.3sPT直流电阻及绝缘电阻试验二次绕组项目名称A相B相C相1a-1n 直流电阻(Ω)0.239 0.239 0.2412a-2n 直流电阻(Ω)0.288 0.291 0.293da-dn 直流电阻(Ω)0.219 0.222 0.224 一次绕组直流电阻(Ω)1641 1653 1668 极性减减减绝缘电阻(MΩ)一次对二次及地3000 3000通过二次间及地1000 1000备注真空开关互感器变比为600/1结论符合出厂技术数据,符合GB50150-2006规程有关规定使用仪器:MODEL-3125数字式高压绝缘电阻测试仪TC-YDQ-10kVA/50kV高压试验变压器试验负责人:编制:试验人员:天气:晴试验温度:10℃试验日期:电气设备试验调试报告 (交接)报告类型: 125kVA变压器试验报告日期: 201 年月日客户名称:项目名称:审核:批准:编制:10KV变压器现场试验记录型号: S-M-125/10 额定容量:125KV A 额定电压:10/0.4 日期:2014 年8月出厂序号:W14092R 联接组标号:Y,yno生产厂家:上海浦变徐州变压器有限公司短路阻抗:4%一:绕组联同套管的直流电阻线圈分接位置AB BC AC 电阻不平衡率%10KV (Ω) 1 11.63 11.65 11.60 0.42 10.89 10.94 11.89 0.33 10.25 10.23 10.22 0.3 450.4kv侧(MΩ) ao bo co 电阻不平衡率% 5.21 5.27 5.42 2.6二:联接组别检查:变压器三相接线组别正确。
10kv配电线路实习报告10kv配电线路实习报告篇1为适应我局的改革发展、提高供电可靠性、节约投资建社,更好的搞好我局对用户的服务质量,局及工区领导于6月首批派我们3个人到省电力工业学校进行了配电线路带电作业培训。
带电作业指在不停电的高压电气设备上进行检修、测试的一种作业方法。
电气设备在长期运行中需要经常测试、检查和维修。
带电作业是避免检修停电,保证正常供电的有效措施。
从今年后的发展来看,带电作业也是保障可靠供电的一个重要的技术措施。
带电作业根据人体与带电体之间的关系可分为三类:地电位作业、中间电位作业和等电位作业。
地电位作业时,人体处于接地的杆塔或构架上,通过绝缘工具带电作业,因而又称绝缘工具法。
在不同电压等级电气设备上带电作业时,必须保持空气间隙的最小距离及绝缘工具的最小长度。
在确定安全距离及绝缘长度时,应考虑系统操作过电压及远方落雷时的雷电过电压。
中间电位作业系通过绝缘车等工具进入高压电场中某一区域,但还未直接接触高压带电体,是地电位与等电位作业的中间状况。
因此,地电位与等电位作业时的基本安全要求,在中间电位作业时均须考虑。
等电位作业时,人体直接接触高压带电部分。
处在高压电场中的人体,会有危险电流流过,危及人身安全,因而所有进入高电场的工作人员,都应穿全套合格的屏蔽服,包括衣裤、鞋袜、帽子和手套等。
全套屏蔽服的各部件之间,须保证电气连接良好,最远端之间的电阻不能大于20,使人体外表形成等电位体。
三种作业法人体与带电体的关系如下:在带电作业培中心这段时间,我们对地电位、中间电位、等电位作业法有了明确的了解,着重对地电位和中间电位作业法进行了理论学习及实操技能培训。
随着设备的更新和新工具的发明,大多数情况下,配电带电作业采用的是中间电位作业法,而这种作业法要求对绝缘斗臂车进行熟练的操作,这样才能保障作业人员在工作时的安全距离。
(目前,主要绝缘斗臂车有三兴、阿尔泰克和杭州爱知。
相比较下,爱知比较灵活。
10KV系统实验报告-完整表格数据--
叉叉水电站
电力设备交接试验报告
10KV系统
中国水利水电第叉叉工程局有限公司
机电安装分局调试所
叉叉年叉叉月
ZSD10-JS-05113
中国水利水电第叉叉工程局有限公司机电安装
分局调试所
干式变压器交接试验报告
1.干式变压器—XXX
电站名称叉叉电站
设备用途TA3厂用变压器
安装位置10KV
1.设备参数
型号SCB11-800/
10
额定容量
(kVA)
800
额定电压(kV)10
额定电流
(A)
73.3
接线组别Dyn11 冷却方式AN
短路阻抗(%)/ 空载电流
(%)
/
额定频率50 出厂日期/
ZSD10-JS-05136
中国水利水电叉叉工程局有限公司机电安装分
局调试所
电力电缆线路交接试验报告
2.电力电缆—10KV
ZSD10-JS-05136
中国水利水电叉叉工程局有限公司机电安装分
局调试所
电力电缆线路交接试验报告
3.电力电缆—10KV
ZSD10-JS-05124
中国水利水电叉叉工程局有限公司机电安装分
局调试所
干式电流互感器交接试验报告
4.干式电流互感器—10KV
ZSD10-JS-05120
中国水利水电叉叉工程局有限公司机电安装分
局调试所
干式电压互感器交接试验报告
5.干式电压互感器—10KV
ZSD10-JS-05127
中国水利水电叉叉工程局有限公司机电安装分
局调试所
真空断路器交接试验报告
6.真空断路器—XXX。