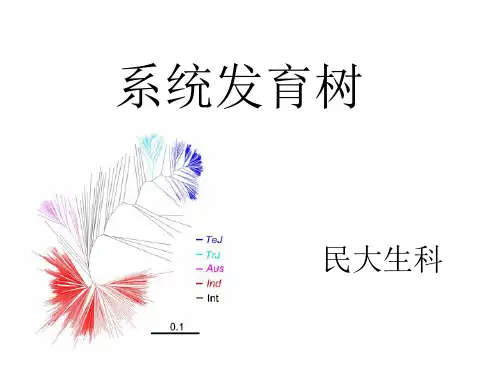
如何构建系统发育树
- 格式:doc
- 大小:27.50 KB
- 文档页数:2

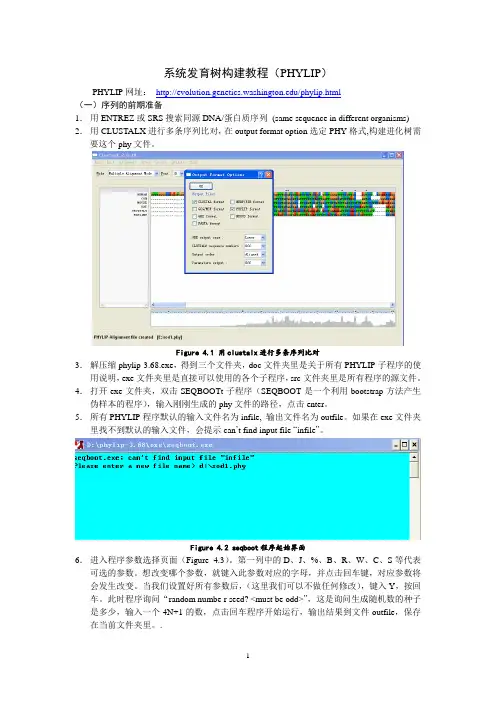
系统发育树构建教程(PHYLIP)PHYLIP网址:/phylip.html(一)序列的前期准备1.用ENTREZ或SRS搜索同源DNA/蛋白质序列(same sequence in different organisms) 2.用CLUSTALX进行多条序列比对,在output format option选定PHY格式,构建进化树需要这个phy文件。
Figure 4.1 用clustalx进行多条序列比对3.解压缩phylip-3.68.exe,得到三个文件夹,doc文件夹里是关于所有PHYLIP子程序的使用说明,exe文件夹里是直接可以使用的各个子程序,src文件夹里是所有程序的源文件。
4.打开exe文件夹,双击SEQBOOTt子程序(SEQBOOT是一个利用bootstrap方法产生伪样本的程序),输入刚刚生成的phy文件的路径,点击enter。
5.所有PHYLIP程序默认的输入文件名为infile, 输出文件名为outfile。
如果在exe文件夹里找不到默认的输入文件,会提示can’t find input file “infile”。
Figure 4.2 seqboot程序起始界面6.进入程序参数选择页面(Figure 4.3)。
第一列中的D、J、%、B、R、W、C、S等代表可选的参数。
想改变哪个参数,就键入此参数对应的字母,并点击回车键,对应参数将会发生改变。
当我们设置好所有参数后,(这里我们可以不做任何修改),键入Y,按回车。
此时程序询问“random numbe r seed? <must be odd>”,这是询问生成随机数的种子是多少,输入一个4N+1的数,点击回车程序开始运行,输出结果到文件outfile,保存在当前文件夹里。
.Figure 4.3 seqboot程序参数选择页面主要参数解释:D: 数据类型,有Molecular sequence、discrete morphology、restriction sites和gene frequencies4个选项。

一、概述系统发育树是生物学领域中常用的一种分类学方法,通过比较不同物种的遗传信息,构建它们之间的亲缘关系,从而揭示它们的进化历史和演化路径。
而最大似然法则是系统发育树构建的常用方法之一,它基于遗传信息的统计学原理,通过计算各种拓扑结构的概率来确定系统发育树的最优结构。
二、最大似然法的原理在构建系统发育树时,我们首先需要收集物种的遗传信息,比如DNA 序列,蛋白质序列等。
然后我们需要假设一个系统发育树的拓扑结构,即物种之间的亲缘关系,接着利用这些遗传信息来评估这个拓扑结构的合理性。
而最大似然法则就是基于遗传信息的统计学原理,来评估不同拓扑结构的合理性。
三、最大似然法的步骤最大似然法构建系统发育树的步骤通常可以分为以下几个步骤:1. 假设模型:我们需要选择一个适当的进化模型,用来描述物种进化的过程。
比较常用的模型包括Jukes-Cantor模型、Kimura模型、GTR模型等。
这些模型会考虑不同的进化因素,比如碱基替换率、碱基组成偏好等。
2. 构建系统发育树:在选择好模型后,我们需要利用这些遗传信息来构建系统发育树。
通常我们会有多个不同拓扑结构的备选方案,比如三叉结构、四叉结构等。
而最大似然法则会根据已有的遗传信息来评估这些备选方案的合理性。
3. 计算概率:最大似然法则通过计算每个拓扑结构出现的概率来评估其合理性。
这里的概率通常是指给定遗传信息的情况下,某拓扑结构出现的可能性。
而这个概率通常是利用进化模型和统计学原理计算得来的。
4. 确定最优结构:通过比较不同拓扑结构的概率,我们可以确定系统发育树的最优结构。
通常我们会选择概率最大的那个拓扑结构作为最终的系统发育树。
四、总结通过最大似然法则构建系统发育树的步骤,我们可以在遗传信息的基础上,找到最优的物种亲缘关系,从而揭示它们的进化历史和演化路径。
最大似然法则基于遗传信息的统计学原理,通过计算不同拓扑结构的概率来评估其合理性,从而确定系统发育树的最优结构。


叙述系统发育树的构建过程嘿,咱今儿就来讲讲系统发育树的构建过程,这可有意思啦!你看啊,系统发育树就像是一棵大树,它的枝桠代表着各种生物之间的关系。
那怎么把这棵大树给“种”出来呢?首先得有一堆生物的数据呀,就像盖房子得有砖头一样。
这些数据可以是各种各样的,比如基因序列啦、形态特征啦等等。
然后呢,就开始比对这些数据,这就好比把不同的砖头摆在一起,看看哪些相似,哪些不同。
接着,就根据这些比对的结果来确定它们之间的亲缘关系。
这就好像在给砖头们找它们的“家族”一样,哪些是近亲,哪些是远亲。
这可不是一件容易的事儿啊,得非常仔细地去分析。
然后呢,把这些亲缘关系用一种特别的方式表示出来,就像把砖头们按照一定的规律摆好,形成一个结构。
这个结构慢慢就变成了系统发育树的雏形。
这时候,就像是在给大树修剪枝叶一样,要对这个雏形进行调整和优化。
要确保每个部分都放对了位置,不能有差错。
最后,一棵完整的系统发育树就出来啦!哇塞,你想想看,通过这么多复杂的步骤,终于把生物之间的关系给清楚地呈现出来了,这难道不神奇吗?你说,这系统发育树构建的过程,像不像一个艺术家在精心雕琢一件作品?每一个细节都要处理好,才能呈现出完美的结果。
而且啊,这可不是一次性就能完成的事儿,得反复地去研究、去调整。
你再想想,要是没有系统发育树,我们怎么能知道各种生物之间有着这样那样的联系呢?我们怎么能更好地理解生命的奥秘呢?所以啊,这个构建过程虽然复杂,但真的超级重要呢!咱平时生活中也有类似的情况呀,比如说搭积木,不也是一块一块地搭起来,最后形成一个完整的造型嘛。
这和构建系统发育树不是有点像嘛!总之呢,系统发育树的构建过程就是这么神奇又有趣,它让我们对生物的世界有了更深的了解和认识。
这可真是一项伟大的工作啊!你难道不这么觉得吗?。
MEGA软件——系统发育树构建方法(图
文讲解)
一、序列文本的准备
构树之前先将目标基因序列都分别保存为txt文本文件中(或者把所有序列保存在同一个txt文本中,可以用“>基因名称”作为第一行,然后重起一行编辑基因序列),序列只包含序列字母(ATCG或氨基酸简写字母)。
文件名名称可以已经您
的想法随意编辑。
二、序列导入到Mega 5软件
(1)打开Mega 5软件,界面如下
(2)导入需要构建系统发育树的目的序列
OK
选择分析序列类型(如果是DNA序列,点击DNA,如果是蛋白序列,点击Prot
ein)
出现新的对话框,创建新的数据文件
选择序列类型
导入序列
导入序列成功。
(3)序列比对分析
点击工具栏中“W”工具,进行比对分析,比对结束后删除两端不能够完全对齐
碱基
(4)系统发育分析
关闭窗口,选择保存文件路径,自定义文件名称
三、系统发育树构建
根据不同分析目的,选择相应的分析算法,本例子以N—J算法为例
Bootstrap 选择1000,点击Compute,开始计算
计算完毕后,生成系统发育树。
.
根据不同目的,导出分析结果,进行简单的修饰,保存
精选范本。


构建系统发育树的方法
构建系统发育树的方法
一、定义
系统发育树(Phylogenetic Tree)又称为系统种群学树,是一
种描述物种演化的树型结构,从根节点开始描述物种主要进化分支结构,树上的每条边则表示两个物种在进化的历史中距离彼此更近或来自同一进化祖先的关系。
二、建立系统发育树的方法
1.收集数据:系统发育树的建立首先要收集数据,作为建立树的基础,这些数据一般是利用各种实验技术来收集,比如遗传学实验和物种形态的实验。
2.选取特征:从收集的大量数据中,应选取尽可能多的可靠特征,作为建立树的材料,这些特征要有规律性,有可靠性,可以容易发现物种之间的内在关系,有利于在研究中可靠地比较各物种之间的相似程度。
3.分类比较:将所有待比较的物种或实体按照类似的特征进行分类,根据同一物种种的特征之间的差异,可以比较出物种之间的相似度,确定出有利于建立树的特征。
4.描绘树枝:根据比较的结果,可以依次将物种分类编码,从根节点开始,逐级分细枝条,最后得出系统发育树的图形结构。
5.校正树枝:检查系统发育树的构建结果,如果发现有一些物种不太符合物种演化过程的规律,可以根据其他数据和结果来校正树枝,
从而得出最终的发育树结构。

系统发育树构建的三种方法
系统发育树(Systems 发育 Tree,简称Stree)是一种用于描述生物系统进化的图形化工具,通常用于模拟生物系统行为的演化过程。
以下是三种构建系统发育树的方法:
1. 基于规则的方法:这种方法使用预定义的规则和偏好来构建
系统发育树。
例如,可以使用遗传算法或人工神经网络等机器学习方法,来预测一个物种的遗传特征或行为演化轨迹。
这种方法需要大量
的人工工作,但可以生成较为准确的演化树。
2. 基于统计方法的方法:这种方法使用统计学方法来推断物种
之间的演化关系。
例如,可以使用最大似然估计或贝叶斯推断等方法,来预测一个物种的遗传特征或行为演化轨迹。
这种方法不需要人工工作,但需要更多的计算资源和时间,才能得到比较准确的演化树。
3. 基于模型的方法:这种方法使用已经建立的模型和数据来构
建系统发育树。
例如,可以使用层次结构模型(如生物进化树、社会网络模型等)来预测一个物种的遗传特征或行为演化轨迹。
这种方法可
以快速构建系统发育树,但需要更多的人工工作来验证模型的准确性。

构建系统发育树方法
构建系统发育树的方法主要有以下几种:
1. 最大简约法:该方法通过比较各个分类单位之间的特征相似性,选择具有最少进化步骤的系统树作为最佳解。
最大简约法常用的算法有邻接法和分枝定界法。
2. 距离法:该方法通过测量各个分类单位之间的距离,构建进化距离矩阵,再通过层次聚类等方法构建系统树。
常用的距离法有UPGMA(最大平均连接法)和Neighbor-Joining(邻居联接法)等。
3. 最大似然法:该方法通过建立进化模型,利用统计模型估计各个分类单位之间的进化距离和树的拓扑结构,选择最大似然值最高的系统树作为最佳解。
4. 贝叶斯推理法:该方法通过建立贝叶斯统计模型,利用贝叶斯推理计算出各个分类单位之间的进化关系和树的拓扑结构概率分布,选择概率最高的系统树作为最佳解。
这些方法在具体操作中还可以结合不同的分子标记(如DNA序列、蛋白质序列等)和分析工具(如软件程序)来构建系统发育树。
同时,不同方法的结果可能存在差异,因此在实际应用中需要综合考虑多个方法的结果来得出最终的系统发育关系。
三种方法构建系统发育树学习笔记所用数据为一个属内不同种不同群体的叶绿体基因组序列,数量为80条。
发现用全长序列建树的时候,不适合选用太多外类群,否则ML法中会导致属内分枝的枝长特别短。
原因应该是基因间隔区和内含子区域序列位点的差异较大。
枝长含义NJ:表示遗传距离;MP:性状状态变换的替换数;ML/BI:该分枝上的相对进化数量(遗传变异量);每个位点上的替换数(一般以每位点多少次核苷酸替换或氨基酸取代来表示)。
遗传距离大多数情况以序列来说遗传距离就是两个OTU(个体、群体、物种或基因家族)之间序列的差异值。
序列比对多序列比对用mafft得到的结果较为准确,muscle比对的速度较快。
多序列比对的绝大多数算法都是基于渐进比对的概念。
简单来说就是先从两个序列的比对开始,逐渐添加新序列,直到所有的序列都加入为止。
但是不同的添加顺序会产生不同的比对结果。
所以由最相似的两个序列开始比对,由近到远逐步完成最为可靠。
mafft --thread 15 --auto 80-AcoeOut.fasta > 80-AcoeOut_aln.fasta##比对时如果不清楚什么参数合适,加个参数--auto,软件可以自动帮你处理挑选保守位点进行下一步建树序列比对完后,用于建树的序列位点必须保证具有良好的同源性。
所以需要删除序列分歧很大的区域和gap区域。
我用的软件为Gblocks,主要目的是把有gap的位点全部去除,参数为-b5=n,其余的选项有-b5=h,h表示half 指去除在大于50%的序列中出现gap的位点。
Gblocks 80-AcoeOut_aln.fasta -t=d -b5=n最大简约法(软件PAUP)最大简约法的树长指所有性状在一棵树上的进化改变总数。
计算得到的结果可能会有许多树长相等的简约树,此时需要计算它们的一致树。
分为strict consensus和semistrict consensus等,strict表示100%,在所有简约树中都出现的分枝,才会出现在一致树中,否则为梳子。
系统发育树的构建方法
嘿,朋友们!今天咱来聊聊系统发育树的构建方法,这可有意思啦!
你想想啊,系统发育树就像是一棵大树,上面挂满了各种生物,它们之间有着千丝万缕的联系。
那怎么把这棵大树给建起来呢?
首先得有数据呀!就像盖房子得有砖头一样。
这些数据可以是各种生物的特征啦、基因序列啦等等。
这可不能马虎,得仔细收集。
然后呢,就是选择合适的方法啦。
这就好比做菜,得选对调料和烹饪方法才能做出美味的菜肴。
不同的方法有不同的特点,得根据实际情况来选。
接下来,就是分析数据啦!这就像是侦探在破案,要从一堆线索中找出真相。
得仔细琢磨每个数据的意义和关系。
在这个过程中,可不能瞎搞哦!得有耐心,就像绣花一样,一针一线都要精细。
要是马马虎虎,那建出来的树可就歪七扭八啦。
还有哦,要不断地调整和优化。
就像雕刻一件艺术品,得不断地打磨才能让它更完美。
建系统发育树可不是一件容易的事儿,但当你看到那棵清晰地展示出生物之间关系的大树时,那种成就感,哇,简直没法形容!
你说,这是不是很神奇?通过这样的方法,我们就能更好地了解生物的演化历程,就像穿越时空看到了它们的过去一样。
这不就像是我们在探索一个神秘的世界吗?每一个数据都是一个线索,每一次分析都是一次冒险。
所以啊,朋友们,别小看了系统发育树的构建方法,它可是打开生物奥秘大门的一把钥匙呢!让我们一起努力,去构建出更漂亮、更准确的系统发育树吧!
原创不易,请尊重原创,谢谢!。
细菌系统发育树的分析与构建
细菌系统发育树分析和构建是重要的微生物进化工作。
它不仅有助于我们研究细菌的系统发育史,而且可以提供宝贵的信息,以便我们更好地了解细菌的关联性以及改善微生物分类法。
分析与构建细菌系统发育树的过程通常包括以下步骤:(1)从候选的细菌中收集
数据,然后从中提取最有信息值的标识符,如16S rRNA序列;(2)确定候选细菌之间
的分子进化关系,通常这是通过算法,如联立方突变分析;(3)使用算法,将候选细菌
排序,建立一个系统发育树;(4)测试系统发育树是否可信,例如使用Bayesian定性统计检验;(5)将细菌分类到物种和自然属级别,以便更好地说明系统发育树的特征。
为了建立准确的细菌系统发育树,数据的质量与种数对最终树的准确性有很大影响,因此选择和收集有关候选细菌的质量数据是整个分析与构建过程中非常重要的一步。
最常用的细菌质量数据是核糖核酸序列(如16S rRNA),它可以有效地跨越主要的系统发育树枝。
此外,建立的系统发育树应经常检查和修正,以确保树的正确性。
此外,还需要定期更新
数据集,以确保系统发育树具有最新的分子进化信息。
最后,通过建立细菌系统发育树,我们可以更好地理解细菌的相关性,从而改善现存的微
生物分类方法,同时在不同细菌物种间建立良好的关联。
此外,这些细菌系统发育树也帮
助了在细菌抗性领域中的研究,并为抗性细菌的了解与治疗提供宝贵的信息。
因此,细菌
系统发育树的分析与构建是重要的一步,从而可以提供重要的信息以改善我们对细菌起源、进化和系统发育机理的理解。
标题:单拷贝直系同源基因系统发育树的构建摘要:随着基因测序技术的不断发展,越来越多的基因序列得到了公开发布,为研究者提供了丰富的遗传信息。
在众多研究中,通过构建系统发育树来揭示不同物种的亲缘关系和进化历史是一项重要的工作。
而单拷贝直系同源基因系统发育树的构建,对于了解不同物种之间的关系和进行进化分析具有重要意义。
本文将介绍单拷贝直系同源基因系统发育树的构建方法及相关应用。
正文:1. 单拷贝直系同源基因系统概述单拷贝直系同源基因即同一基因家族中的每个成员都只有一个拷贝,且这些拷贝是由同一个祖先基因直接演化而来,因此它们在不同物种之间具有较高的同源性和拓展性。
而单拷贝直系同源基因系统则是指由这些单拷贝直系同源基因所构成的系统。
这些基因在不同物种之间的保守程度较高,因此常被用于物种之间亲缘关系的研究和系统发育树的构建。
2. 单拷贝直系同源基因系统发育树构建的重要性单拷贝直系同源基因系统发育树的构建对于揭示不同物种之间的亲缘关系具有重要意义。
通过比较单拷贝直系同源基因在不同物种中的序列差异和演化速率,可以推断这些物种之间的亲缘关系和进化历史。
单拷贝直系同源基因系统发育树的构建还可以为物种的分类和系统发育关系提供重要参考。
3. 单拷贝直系同源基因系统发育树构建的方法a. 基因家族的筛选与挑选需要从目标物种的基因组序列中筛选出单拷贝直系同源基因家族。
可以利用基因同源性分析工具如BLAST、HMMER等进行筛选和挑选,确保所选择的基因家族符合单拷贝直系同源基因的特征。
b. 序列比对与进化树构建选定合适的单拷贝直系同源基因后,需要对这些基因序列进行比对。
可以利用一些专业的序列比对软件如ClustalW、MAFFT等进行多序列比对,得到基因序列的保守区域和变异区域。
利用分子进化树构建软件如PHYLIP、MEGA等构建系统发育树,并进行进化分析。
4. 单拷贝直系同源基因系统发育树构建的应用单拷贝直系同源基因系统发育树的构建在生物学领域有着广泛的应用。
发育树的构建方法发育树,又称分配树,简称FT,是一种复杂的分析方法,用来表示生物的进化过程,或表示两个生物的系统进化关系。
它是一种重要的分析工具,被广泛应用于生物学、分子生物学、信息学和其它领域。
发育树可以帮助研究者了解生物或者物种之间的关系,从而可以更好地解释物种的变化和生物的进化。
发育树的构建有多种方法,其具体选择则取决于研究者的具体目的和应用领域。
一般来说,发育树构建可分为两大类:观察性方法、推断性方法。
观察性方法是根据观察到的实际生物的特征和形态,结合已有的知识和经验,以某种标准建立的发育树。
一般而言,观察性构建方法更加简单明确,也更加容易掌握。
常用的观察性构建方法有:拟物系统构建法、分支系统构建法、定量分析构建法、具体性观察构建法等。
推断性方法是利用分子生物学的技术,从序列数据中推断出生物的发育关系,构建出发育树。
一般而言,推断性方法构建出的发育树更加准确,适用范围更广。
常用的推断性方法有:进化距离构建法、进化最近邻构建法、最大似然比构建法、最大简约构建法等。
在建立发育树时,还要考虑到发育树的体系结构,及其定义结构元素。
常用的树结构元素包括:分支节点、基本分歧、分歧路径、根节点和叶节点等。
考虑到不同的生物,可以采用不同的树结构,最常用的是网状结构和森林结构。
发育树的构建还可以通过计算机程序和软件来完成,包括但不限于PAUP*、MacClade、TreeFig、TreeView等软件。
除此之外,聚类分析也是构建发育树的一种重要方法,包括:层次聚类、K均值聚类、二分聚类等。
总之,发育树的构建方法有很多,研究者可以根据目的和应用领域,选择合适的构建方法,从而实现更准确、更有效的发育树构建。
如何构建系统发育树Bioinformatics2009-11-03 10:45 阅读159 评论0字号:大中小(2009-06-11 22:44:13)标签:系统发育树构建系统发育树分子生物学发育分析it转自丁香园构建系统发育树需要注意的几个问题1 相似与同源的区别:只有当序列是从一个祖先进化分歧而来时,它们才是同源的。
2 序列和片段可能会彼此相似,但是有些相似却不是因为进化关系或者生物学功能相近的缘故,序列组成特异或者含有片段重复也许是最明显的例子;再就是非特异性序列相似。
3 系统发育树法:物种间的相似性和差异性可以被用来推断进化关系。
4 自然界中的分类系统是武断的,也就是说,没有一个标准的差异衡量方法来定义种、属、科或者目。
5 枝长可以用来表示类间的真实进化距离。
6 重要的是理解系统发育分析中的计算能力的限制。
任何构树的实验目的基本上就是从许多不正确的树中挑选正确的树。
7 没有一种方法能够保证一棵系统发育树一定代表了真实进化途径。
然而,有些方法可以检测系统发育树检测的可靠性。
第一,如果用不同方法构建树能得到同样的结果,这可以很好的证明该树是可信的;第二,数据可以被重新取样,来检测他们统计上的重要性。
分子进化研究的基本方法对于进化研究,主要通过构建系统发育过程有助于通过物种间隐含的种系关系揭示进化动力的实质。
表型的(phenetic)和遗传的(cladistic)数据有着明显差异。
Sneath和Sokal(1973)将表型性关系定义为根据物体一组表型性状所获得的相似性,而遗传性关系含有祖先的信息,因而可用于研究进化的途径。
这两种关系可用于系统进化树(phylogenetictree)或树状图(dendrogram)来表示。
表型分枝图(phenogram)和进化分枝图(cladogram)两个术语已用于表示分别根据表型性的和遗传性的关系所建立的关系树。
进化分枝图可以显示事件或类群间的进化时间,而表型分枝图则不需要时间概念。
如何构建系统发育树
Bioinformatics2009-11-03 10:45 阅读159 评论0
字号:大中小小
(2009-06-11 22:44:13)
标签:系统发育树构建系统发育树分子生物学发育分析it
转自丁香园
构建系统发育树需要注意的几个问题
1 相似与同源的区别:只有当序列是从一个祖先进化分歧而来时,它们才是同源的。
2 序列和片段可能会彼此相似,但是有些相似却不是因为进化关系或者生物学功能相近的缘故,序列组成特异或者含有片段重复也许是最明显的例子;再就是非特异性序列相似。
3 系统发育树法:物种间的相似性和差异性可以被用来推断进化关系。
4 自然界中的分类系统是武断的,也就是说,没有一个标准的差异衡量方法来定义种、属、科或者目。
5 枝长可以用来表示类间的真实进化距离。
6 重要的是理解系统发育分析中的计算能力的限制。
任何构树的实验目的基本上就是从许多不正确的树中挑选正确的树。
7 没有一种方法能够保证一棵系统发育树一定代表了真实进化途径。
然而,有些方法可以检测系统发育树检测的可靠性。
第一,如果用不同方法构建树能得到同样的结果,这可以很好的证明该树是可信的;第二,数据可以被重新取样,来检测他们统计上的重要性。
分子进化研究的基本方法
对于进化研究,主要通过构建系统发育过程有助于通过物种间隐含的种系关系揭示进化动力的实质。
表型的(phenetic)和遗传的(cladistic)数据有着明显差异。
Sneath和Sokal(1973)将表型性关系定义为根据物体一组表型性状所获得的相似性,而遗传性关系含有祖先的信息,因而可用于研究进化的途径。
这两种关系可用于系统进化树(phylogenetictree)或树状图(dendrogram)来表示。
表型分枝图(phenogram)和进化分枝图(cladogram)两个术语已用于表示分别根据表型性的和遗传性的关系所建立的关系树。
进化分枝图可以显示事件或类群间的进化时间,而表型分枝图则不需要时间概念。
文献中,更多地是使用“系统进化树”一词来表示进化的途径,另外还有系统发育树、物种树(speciestree)、基因树等等一些相同或含义略有差异的名称.
系统进化树分有根(rooted)和无根(unrooted)树。
有根树反映了树上物种或基因的时间顺序,而无根树只反映分类单元之间的距离而不涉及谁是谁的祖先问题。
用于构建系统进化树的数据有二种类型:一种是特征数据(characterdata),它提供了基因、个体、群体或物种的信息;二是距离数据(distancedata)或相似性数据(similaritydata),它涉及的则是成对基因、个体、群体或物种的信息。
距离数据可由特征数据计算获得,但反过来则不行。
这些数据可以矩阵的形式表达。
距离矩阵(distancematrix)是在计算得到的距离数据基础上获得的,距离的计算总体上是要依据一定的遗传模型,并能够表示出两个分类单位间的变化量。
系统进化树的构建质量依赖于距离估算的准确性。
一1) 打开clustal X,载入上述序列,“load sequences”→“output format options”:
“CLASTAL FORMA T”;CLASTAL SEQUENCES NUMBERS:ON;
ALIGNMENT PARAMETERS:
“RESET NEW GAPS BEFOR ALIGNMENT”
“MULTIPLE ALIGNMENT PARAMETERS”→设置相关参数
2) “DO COMPLETE ALIGNMENT”→FILE→SA VE AS,掐头去尾。
3) 打开MEGA4,FILE→CONVERT TO MEGA FORMA TE→SA VE→FILE→OPEN DA TA→CONTAINING PROTAIN SEQUENCES? NO →PHYLOGENY→BOOTSTRAP TEST OF PHYLOGENY→N J →
设置相关参数。
最后看到系统发育树
二这里要介绍的是Bioedit-Mega建树法,简单实用,极易上手。
1 将所测得的序列在NCBI上进行比对,这个就不多讲了。
2 选取序列保存为text格式。
3 运行Bioedit,使用其中的CLUSTAL W进行比对。
4 运用MEGA 4 建树,首先将前面的文件转化格式为mega格式,然后进行激活,最后进行N-J建树。
此法简单实用,树形美观。