西文字符编码与汉字编码
- 格式:ppt
- 大小:166.50 KB
- 文档页数:2

高考信息技术一轮专题24:ASCⅡ码和汉字编码一、单选题1. ( 2分) 用WinHex软件观察字符内码如图所示,下列描述正确的是()A. 可推断“j”的内码为70HB. “陈旻”字内码为B3C2HC. “name”占用4b存储空间D. “My”内码和01001101 01111001B等值2. ( 2分) 字符“H”对应的ASCII码值为1001000,那么字符“K”对应的ASCII码值为( )A. 1001001B. 1001010C. 1001011D. 10001013. ( 2分) 下列有关汉字编码的叙述中,错误的是( )A. 智能拼音码属于音码,五笔字形码属于形码B. 采用BIG5编码,一个汉字在计算机中用两个字节表示C. 机内码是供计算机系统内部进行存储、加工和传输而统一使用的代码D. 字型码和音码、形码一样都属于输入码4. ( 2分) 计算机的汉字编码有输入码、机内码、输出码,以下不属于输入码的是()。
A. 智能ABCB. 搜狗拼音C. 微软拼音D. 国标码(GB)5. ( 2分) 汉字的编码多种多样,如输入码、输出码和机内码,其功能各异。
用于存储汉字的编码称为( )A. 机内码B. 字型码C. 拼音码D. 输出码6. ( 2分) 目前,国际上通用的字符编码是()A. ASCII码B. 拼音码C. 国标码D. 外码7. ( 2分) 下列关于汉字编码的叙述中,正确的是( )A. 搜狗拼音属于形码,五笔字形属于音码B. 采用BIG5编码,一个汉字在计算机中用一个字节表示C. 机内码是供计算机系统内部进行存储、加工和传输而统一使用的代码D. 字型码和音码、形码一样都属于输入码8. ( 2分) 下列选项中,不是计算机上使用的汉字编码方式的是( )A. 内码B. 条形码C. 外码D. 字型码9. ( 2分) 在ASCⅡ字符编码表中,字符“d”的ASCⅡ码是100,则字符“a”的ASCⅡ码是()A. 97B. 98C. 102D. 10310. ( 2分) 【加试题】下图是“中国诗词大会”的内码,可根据该图计算出“中”字在()A. 54区48位B. 36区30位C. 56区50位D. B6区B0位11. ( 2分) 在用Winhex软件观察字符的十六进制内码时,结果如下图所示,如果内码“69”位置上看到的是“70”,则该内码对应的字符为()A. IB. jC. pD. q12. ( 2分) 用十六进制查看字符内码,结果如下图所示该字符内码可能是()A. 2个GB2312字符B. 4个ASCII字符C. 2个ASCII字符1个GB2312字符D. 4个GB2312字符13. ( 2分) 下图可知I的内码是49H,那么字母j的内码会是()A. 4AHB. 50HC. 6AHD. 70H14. ( 2分) 使用UltraEdit软件观察“翻的-Ship”的内码,如图所示。

浅析汉字编码过程作者:黄小花来源:《电脑知识与技术》2015年第04期摘要:该文围绕了汉字的编码过程,详细介绍了输入码、区位码、国标码、机内码、字形码的编码方法。
输入码是为方便汉字输入而形成的汉字编码为,国标码是为表示汉字而统一的编码,计算机还不能将国标码作为汉字在计算机中的表现形式,因为会和ASCII码发生冲突,所以又产生了汉字的机内码,机内码是存储汉字的编码,最终汉字是通过字形码或输出码将汉字输出。
关键词:汉字的编码;国标码;机内码;字形码中图分类号:G642 文献标识码:A 文章编号:1009-3044(2015)04-0181-02Abstract: This paper around the coding process Chinese characters, detailed introduces the coding method for input code, area code, GB code, machine code, shape code. The input code is formed Chinese characters code for the convenience of Chinese characters input, GB code is unified for the said Chinese characters coding, computer can be GB code as a form Chinese characters in the computer, because ASCII codes and conflict, so they produced a Chinese characters within the machine code, machine code is only, font code is Chinese characters coding form to display and print output Chinese characters.Key words: Chinese characters coding; GB code; machine code; font code计算机是二进制世界,只能识别由0和1组成的二进制度,所有外部信息都要编码成二进制。


即:中文内码之一,代表中文,在广泛使用,影响所及,使用量渐见普及。
“国家标准信息交换用汉字编码”(GB2312-80标准),简称国标码。
国标码是指1980年中国制定的用于不同的具有处理功能的计算机系统间交换汉字信息时使用的编码。
国际码是二字节码, 用两个七位二进制数编码表示一个汉字。
目前国标码收入6763个汉字, 其中一级汉字(最常用)3755个, 二级汉字3008个, 另外还包括682个西文字符、图符。
例如“巧”字的代码是39H 41H, 在机内形式如下: 0 1 1 1 0 0 1 1 第一0 0 0 0 0 1第二字节在计算机内部,汉字编码和西文编码是共存的,如何区分它们是个很重要的问题,因为对不同的信息有不同的处理方式。
方法之一是对于二字节的国标码,将二个字节的最高位都置成“1”, 而码所用字节最高位保持“0”,然后由软件(或硬件)根据字节最高位来作出判断。
字符代码化是指用户从键盘上输入代表某个汉字的编码。
我们把采用不同的编码系统以代表汉字进行输入的方案(如数字码、拼音码和),称为汉字的输入法,、五笔字型码、拼音码、、拼音输入法等都是其中的具体代表。
汉字通过编码输入计算机后,在其后的处理过程中,不同阶段使用不同的代码,首先通过键盘管理程序将接收到的输入编码转换为0和1构成的机内码,实现计算机的存储、加工和传输处理。
同样,存储在计算机内部的机内码也必须经转换后才能恢复汉字的“本来面目”。
这种转换通常是由计算机的输入/输出设备来实现的, 有时还需要软件来参与这种转换过程。
这个阶段的汉字代码称为字形码,用以显示和打印输出。
区位码:1980年,为了使每一个汉字有一个全国统一的代码,我国颁布了第一个汉字编码的国家标准:GB2312-80《信息交换用汉字编码字符集》基本集,这个字符集是我国中文信息处理技术的发展基础,也是目前国内所有汉字系统的统一标准。
国标码是一个四位十六进制数,区位码是一个四位的十进制数,每个国标码或区位码都对应着一个唯一的汉字或符号,但因为十六进制数我们很少用到,所以大家常用的是区位码,它的前两位叫做区码,后两位叫做位码。
字符编码一、西文字符编码:ASCII码ASCII码全称为美国标准信息交换码(American Standard Code for Information Interchange)。
它用8位二进制数来编码,第1位全部是0,因此ASCII码最多可以表示2^7=128个字符,包括字母、数字、标点符号、控制符号等西文字符。
ASCII码已经被ISO认定为国际标准。
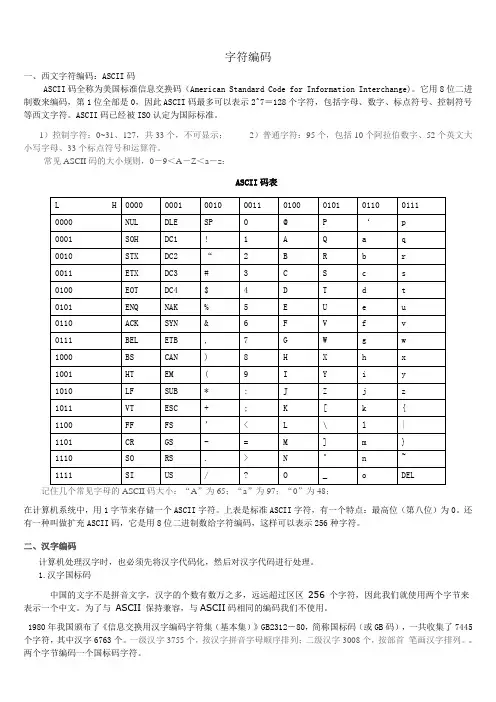
1)控制字符:0~31、127,共33个,不可显示;2)普通字符:95个,包括10个阿拉伯数字、52个英文大小写字母、33个标点符号和运算符。
常见ASCII码的大小规则,0-9<A-Z<a-z:ASCII码表记住几个常见字母的ASCII码大小:“A”为65;“a”为97;“0”为48;在计算机系统中,用1字节来存储一个ASCII字符。
上表是标准ASCII字符,有一个特点:最高位(第八位)为0。
还有一种叫做扩充ASCII码,它是用8位二进制数给字符编码,这样可以表示256种字符。
二、汉字编码计算机处理汉字时,也必须先将汉字代码化,然后对汉字代码进行处理。
1.汉字国标码中国的文字不是拼音文字,汉字的个数有数万之多,远远超过区区256 个字符,因此我们就使用两个字节来表示一个中文。
为了与ASCII 保持兼容,与ASCII码相同的编码我们不使用。
1980年我国颁布了《信息交换用汉字编码字符集(基本集)》GB2312-80,简称国标码(或GB码),一共收集了7445个字符,其中汉字6763个。
一级汉字3755个,按汉字拼音字母顺序排列;二级汉字3008个,按部首笔画汉字排列。
两个字节编码一个国标码字符。
2.汉字的机内表示:机内码:计算机在信息处理时表示汉字的编码,称作机内码。
现在我国都用国标码(GB2312)作为机内码。
中国的台湾省也在使用中文,但是由于历史的原因,那里没有使用大陆的简体中文,还在使用着繁体的中文,并且他们自己也制定了一套表示繁体中文的字符编码,称为BIG5,不幸的是,虽然他们的也使用两个字节来表示一个汉字,但他们没有象我们兼容ASCII 一样兼容大陆的简体中文,他们使用了大致相同的编码范围来表示繁体的汉字。





输入码、区位码、国标码与机内码我们知道,键盘是当前微机的主要输入设备,输入码就是使用英文键盘输入汉字时的编码。
目前,我国已推出的输入码有数百种,但用户使用较多的约为十几种,按输入码编码的主要依据,大体可分为顺序码、音码、形码、音形码四类,如“保”字,用全拼,输入码为码为“BAO”,用区位码,输入码为“1703”,用五笔字型则输入码为“WKS”。
计算机只识别由0、1组成的代码,ASCII码是英文信息处理的标准编码,汉字信息处理也必须有一个统一的标准编码。
我国国家标准局于1981年5月颁布了《信息交换用汉字编码字符集──基本集》,代号为GB2312-80,共对6763个汉字和682个图形字符进行了编码,其编码原则为:汉字用两个字节表示,每个字节用七位码(高位为0),国家标准将汉字和图形符号排列在一个94行94列的二维代码表中,每两个字节分别用两位十进制编码,前字节的编码称为区码,后字节的编码称为位码,此即区位码,如在二维代码表中处于17区第3位,区位码即为“1703 ”。
(教材附页可找到)国标码并不等于区位码,它是由区位码稍作转换得到,其转换方法为:先将十进制区码和位码转换为十六进制的区码和位码,这样就得了一个与国标码有一个相对位置差的代码,再将这个代码的第一个字节和第二个字节分别加上20H,就得到国标码,相当于如果不转换的话,在两个字节上分别加上32即可。
如:“保”字的国标码为3123H,它是经过下面的转换得到的:1703D->1103H->+20H->3123H。
国标码是汉字信息交换的标准编码,但因其前后字节的最高位为0,与ASCII码发生冲突,如“保”字,国标码为31H和23H,而西文字符“1”和“#”的SCII也为31H和23H,现假如内存中有两个字节为31H和23H,这到底是一个汉字,还是两个西文字符“1”和“#”?于是就出现了二义性,显然,国标码是不可能在计算机内部直接采用的,于是,汉字的机内码采用变形国标码,其变换方法为:将国标码的每个字节都加上128,即将两个字节的最高位由0改1,其余7位不变,也就是如果国标码是16进制的,直接加上8080H即可。

国标码即GB国标码:中文内码之一,代表中文简化字,在中国大陆广泛使用,影响所及,使用量渐见普及。
“国家标准信息交换用汉字编码”(GB2312-80标准),简称国标码。
国标码是指1980年中国制定的用于不同的具有汉字处理功能的计算机系统间交换汉字信息时使用的编码。
国际码是二字节码, 用两个七位二进制数编码表示一个汉字。
目前国标码收入6763个汉字, 其中一级汉字(最常用)3755个, 二级汉字3008个, 另外还包括682个西文字符、图符。
例如“巧”字的代码是39H 41H, 在机内形式如下: 0 1 1 1 0 0 1 1 第一字节0 0 0 0 0 1第二字节在计算机内部,汉字编码和西文编码是共存的,如何区分它们是个很重要的问题,因为对不同的信息有不同的处理方式。
方法之一是对于二字节的国标码,将二个字节的最高位都置成“1”, 而ASCII码所用字节最高位保持“0”,然后由软件(或硬件)根据字节最高位来作出判断。
字符代码化是指用户从键盘上输入代表某个汉字的编码。
我们把采用不同的编码系统以代表汉字进行输入的方案(如数字码、拼音码和字形码),称为汉字的输入法,区位码、五笔字型码、拼音码、智能ABC、微软拼音输入法等都是其中的具体代表。
汉字通过编码输入计算机后,在其后的处理过程中,不同阶段使用不同的代码,首先通过键盘管理程序将接收到的输入编码转换为0和1构成的机内码,实现计算机的存储、加工和传输处理。
同样,存储在计算机内部的机内码也必须经转换后才能恢复汉字的“本来面目”。
这种转换通常是由计算机的输入/输出设备来实现的, 有时还需要软件来参与这种转换过程。
这个阶段的汉字代码称为字形码,用以显示和打印输出。
区位码:1980年,为了使每一个汉字有一个全国统一的代码,我国颁布了第一个汉字编码的国家标准:GB2312-80《信息交换用汉字编码字符集》基本集,这个字符集是我国中文信息处理技术的发展基础,也是目前国内所有汉字系统的统一标准。
全国计算机应用基础知识:汉字、字符编码全国计算机应用基础知识:汉字、字符编码(1)计算机中的信息单位计算机中对信息表示的单位有位、字、字长及字节等,它们是用来表示信息量的大小的基本概念。
① 位:计算机中数据存储的最小单位是一个二进制位,简称位,英文为bit,音译为比特,可用小写字母b表示。
② 字节:八位二进制位称为一个字节,英文为Byte,可用大写字母B表示,是计算机存储的基本单位。
一个字节的八位二进制数,其位编号自左至右为b7、b6、b5、b4、b3、b2、b1、b0。
在计算机中,往往用字节数来表示存储容量,容量可以以KB、MB、GB、TB为单位,它们相互之间的转换关系如下: 1KB=210B=1024B1MB=210KB=1024KB1GB=210MB=1024MB1TB=210GB=1024GB③ 字:计算机在存储、传送或操作时,作为一个整体单位进行操作的一组二进制,称为一个计算机字,简称字。
④ 字长:每个字所包含的位数称为字长。
由于字长是计算机一次可处理的二进制数的位数,因此它与计算机处理数据的速率有关,是衡量计算机性能的一个重要因素。
(2)字符的编码。
① ASCII码。
计算机只能识别二进制数,因此计算机中的数字、字母、符号也必须用二进制进行编码。
编码方法有多种,微型机中普遍采用的是ASCII码(美国标准信息交换码),ASCII码现已被国际标准化组织(ISO)接收为国际标准,称为ISO-646。
ASCII码有7位版本和8位版本两种,国际上通用的ASCII码是7位版本。
7位版本的ASCII码包含10个阿拉伯数字、52个英文大小写字母、32个标点符号和运算符及34个控制码,共128个字符,所以可用7位二进制数表示。
7位ASCII码字符如下图所示:要确定一个数字、字母、符号或控制字符的ASCII码,可在表中先找出它的位置,然后确定它所对应的十进制值或二进制值。
例如小写字母“a”的ASCII码其十进制值是97,二进制值是B(B表示二进制数),若转换成十六进制,其值是61H(H表示十六进制数)。