HITS算法概述
- 格式:pdf
- 大小:130.69 KB
- 文档页数:4

hits 原理Hits 原理解析1. Hits 模型简介•Hits(Hyperlink-Induced Topic Search)模型是一种经典的链接分析算法。
•它通过分析网页之间的链接结构,评估网页的重要性,并获取相关的主题信息。
•Hits 模型广泛应用于搜索引擎的排名算法中,如谷歌的PageRank 算法。
2. 基本原理•主题相关性:Hits 模型认为,一个网页的重要性与其所包含的关键词相关性有关。
•链接结构:通过分析网页之间的链接结构,Hits 模型可以判断网页的权威性和可信度。
3. Hits 模型的工作流程•首先,Hits 模型需要构建一个网页之间的链接图。
•然后,通过迭代计算的方式,不断更新每个网页的权重,直到收敛。
•最后,根据网页的权重,对搜索结果进行排序和排名。
4. 迭代计算过程1.初始化:为每个网页赋予一个初始的权重值。
2.计算 Authority 值:根据网页之间的链接关系,更新每个网页的 Authority 值。
3.计算 Hub 值:根据网页之间的链接关系,更新每个网页的 Hub值。
4.归一化:对 Authority 值和 Hub 值进行归一化处理,使其和为1。
5.收敛判断:检查计算得到的 Authority 和 Hub 值是否与上一次计算相差足够小,如果是,则停止计算,否则返回第2步。
5. 评估网页重要性的指标•Authority 值:代表一个网页的主题相关性,即网页作为一个权威来源提供的信息质量。
•Hub 值:代表一个网页的链接质量,即网页提供的链接是否指向其他权威来源。
6. Hits 模型的特点•基于链接分析:Hits 模型通过分析网页之间的链接结构来评估网页的重要性。
•主题相关性:Hits 模型将主题相关性作为评估网页重要性的关键指标。
•迭代计算:Hits 模型通过迭代计算的方式,不断更新网页的权重,直到收敛为止。
7. 总结•Hits 模型是一种经典的链接分析算法,用于评估网页的重要性和获取相关的主题信息。

HITS算法原理及应用概述HITS算法(即Hyperlink-Induced Topic Search Algorithm, 即超链接诱导主题搜索算法),是H. Garcia-Molina等在1998年提出的一种网页排名算法。
此算法通过分析网页与网页之间的链接关系,给出一个基于主题的网页排序结果。
HITS算法应用广泛,包括搜索引擎、网络广告、电子商务等领域。
本文将详细介绍HITS算法的原理和应用。
HITS算法原理HITS算法的原理是基于共同性和引用性。
即,如果一个网页被其他很多网页引用,那么它应该是具有权威性和有价值的。
而如果一个网页指向其他很多网页,那么它应该是一个重要的主题或分类的代表。
HITS算法的核心是两个概念:hub和authority。
一个hub是指指向其他页面的关键页面。
一个authority是指所链接的相关页面。
通过这两个概念,HITS算法可以将网页划分为hub和authority两个等级。
在实际应用中,HITS算法通过计算网页间的链接关系,为每个网页赋予hub和authority权重。
算法的过程大致可以分为两个步骤:1. 构建网页链接图HITS算法的第一步是构建网页间的链接图,即用图形表示每个页面以及它们之间的链接关系。
这个图将网页表示为节点,将链接关系表示为有向边。
2. 计算hub和authority权重HITS算法的第二步是计算每个页面的hub和authority权重。
算法使用迭代的方式计算每个页面的hub和authority值,直到收敛为止。
具体地,HITS算法使用以下公式计算每个页面的hub值和authority值:$\operatorname{auth}(p) = \sum \limits_{q \in \text{in}(p)}\operatorname{hub}(q)$$\operatorname{hub}(p) = \sum \limits_{q \in \text{out}(p)}\operatorname{auth}(q)$其中,$p$为当前页面,$\text{in}(p)$和$\text{out}(p)$分别为指向$p$的页面和$p$指向的页面。

基于HITS算法的搜索引擎概述摘要:本文简要介绍了目前搜索引擎中应用较为广泛的一种算法——HITS算法。
HITS算法是Web结构挖掘中最具有权威性和使用最广泛的算法。
其基本思想是利用页面之间的引用链来挖掘隐含在其中的有用信息(如权威性),具有计算简单且效率高的特点。
HITS算法通过两个评价权值——内容权威度(Authority)和链接权威度(Hub)来对网页质量进行评估。
HITS算法认为对每一个网页应该将其内容权威度和链接权威度分开来考虑,在对网页内容权威度做出评价的基础上再对页面的链接权威度进行评价,然后给出该页面的综合评价。
它专注于改善泛指主题检索的结果,通过一定的计算(迭代计算)方法以得到针对某个检索提问的最具价值的网页,即排名最高的authority。
关键词:搜索引擎;HITS算法;权威度;网页排名引言:随着因特网的迅猛发展,搜索引擎的应用已经非常普及。
然而,人们对搜索引擎的核心技术———算法设计知之并不多。
了解搜索引擎的算法设计思想及原理,有助于提高我们的信息检索能力,评价搜索引擎。
更为重要的是,我国在信息技术领域内的发展情况与发达国家相比还有相当的差距,只有真正掌握了搜索引擎的核心技术,才可能开发出属于我们自己功能强大的搜索引擎,以使我们在当今的信息社会中立于不败之地。
国内目前对搜索引擎排序算法的介绍较少,从已有的文献来看,多集中于对更具影响力的PageRank算法的介绍和分析研究,而对全球已有较大影响的HITS算法和SALSA算法介绍较少。
本文中所重点说明的HITS算法是由康奈尔大学(Cornell University)的JonKleinberg博士于1998年首先提出的,HITS的英文全称为Hy pertext-Induced Topic Search。
目前,它为IBM公司阿尔马登研究中心(IBM Almaden Research Center)的名为“CLEVER”的研究项目中的一部分。

搜索引擎算法介绍之HITS算法。
HITS算法是Web结构挖掘中最具有权威性和使用最广泛的算法。
Hits算法由乔恩·克莱因伯格(Jon Kleinberg)于1998年设计提出,该算法的研究工作启发了PageRank算法的诞生。
HITS算法的主要思想是:网页的重要程度是与所查询的主题相关的。
我们可以这样理解:HITS算法是基于主题来衡量网页的重要程度,相对不同主题,同一网页的重要程度也是不同的。
例如,百度对于主题“搜索引擎”和主题“湖南SEO”的重要程度是不同的。
HITS算法使用了两个重要的概念:权威网页(authority)和中心网页(hub)。
例如:Google、Baidu、Yahoo!、bing、sogou、soso等这些搜索引擎相对于主题“搜索引擎”来说就是权威网页(authority),因为这些网页会被大量的超链接指向。
://.html这个页面链接了这些权威网页(authority),则这个页面可以称为主题“搜索引擎”的中心网页(hub)。
HITS算法发现,在很多情况下,同一主题下的权威网页(authority)之间并不存在相互的链接。
所以,权威网页(authority)通常都是通过中心网页(hub)发生关联的。
HITS算法描述了权威网页(authority)和中心网页(hub)之间的一种依赖关系:一个好的中心网页(hub)应该指向很多好的权威性网页(authority),而一个好的权威性网页(authority)应该被很多好的中心性网页(hub)所指向。
同时产生的两个问题是:HITS算法将链接与内容分开来考虑,仅考虑网页之间的链接结构来分析页面的权威性一个页面与另一页面的引用有多种情况,如为了导航或为了付费广告。
第一个问题提出的解决方法是:利用超链文字及其周围文字与关键字相匹配而计算超链权值,并引入系数对周围文字和超链文字进行权值的相对控制。
第二个问题的解决方法是:HITS算法引入了时间参数,即利用对一链接引用的时问长短来评价是否为正常引用。

一、实验目的◆ 理解搜索引擎的链接结构子系统的基本功能; ◆ 了解万维网链接的结构图及特性; ◆ 理解HITS 算法的基本思想和原理。
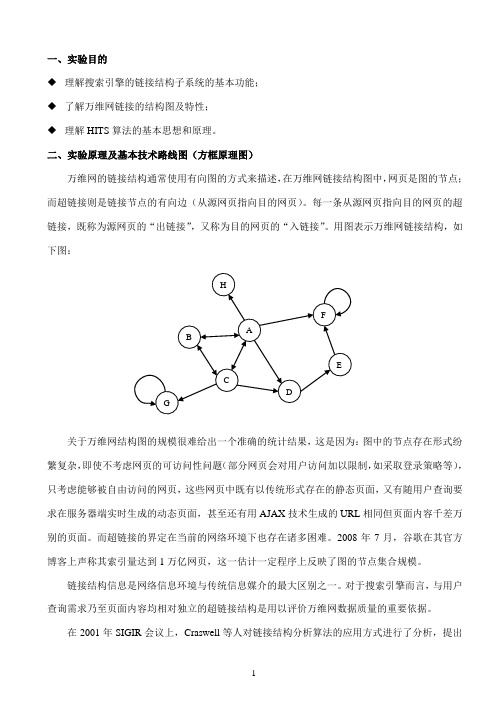
二、实验原理及基本技术路线图(方框原理图)万维网的链接结构通常使用有向图的方式来描述,在万维网链接结构图中,网页是图的节点;而超链接则是链接节点的有向边(从源网页指向目的网页)。
每一条从源网页指向目的网页的超链接,既称为源网页的“出链接”,又称为目的网页的“入链接”。
用图表示万维网链接结构,如下图:关于万维网结构图的规模很难给出一个准确的统计结果,这是因为:图中的节点存在形式纷繁复杂,即使不考虑网页的可访问性问题(部分网页会对用户访问加以限制,如采取登录策略等),只考虑能够被自由访问的网页,这些网页中既有以传统形式存在的静态页面,又有随用户查询要求在服务器端实时生成的动态页面,甚至还有用AJAX 技术生成的URL 相同但页面内容千差万别的页面。
而超链接的界定在当前的网络环境下也存在诸多困难。
2008年7月,谷歌在其官方博客上声称其索引量达到1万亿网页,这一估计一定程序上反映了图的节点集合规模。
链接结构信息是网络信息环境与传统信息媒介的最大区别之一。
对于搜索引擎而言,与用户查询需求乃至页面内容均相对独立的超链接结构是用以评价万维网数据质量的重要依据。
在2001年SIGIR 会议上,Craswell 等人对链接结构分析算法的应用方式进行了分析,提出HBAFDECG万维网超链接应具有的两个特性:如果存在超链接L从页面P source指向页面P destiny,则P source与P destiny满足:特性1:(内容推荐特性)页面P source的作者推荐页面P destiny的内容,且利用L的链接文本内容对P destiny进行描述。
特性2:(主题相关特性)被超链接连接的两个页面P source与P destiny的页面内容涉及类似的主题。
然而这两个特性对于万维网数据爆炸性增长的背景下被认为过于理想主义。
社会网络数据分析基础HITS算法应用-V1社交网络数据分析基础HITS算法应用社交网络已成为人们日常生活中重要的交流和互动平台。
对于这些网络数据的分析对于了解人们的行为和态度,判断网络广告效果等方面有着至关重要的作用。
HITS算法就是一种用于社交网络数据分析的重要算法。
一、HITS算法HITS(Hyperlink-Induced Topic Search)算法也称为网页极少搜索,最初是由著名的信息检索学家Kleinberg提出的。
该算法是一种基于链接分析的算法。
其计算原理是通过对网页中的链接关系进行分析得出网页的权重值,从而进一步分析网页之间的相关度,最终用于社交网络数据的分析。
在HITS算法中,将网页分为两类,即“主题节点”和“枢纽节点”。
主题节点是指在网页内容中包含某种主题信息的节点,例如包含关于汽车行业的文章的网页。
枢纽节点则是网页间的链接关系起到联系作用的节点,例如在汽车行业网页中,枢纽节点可以是一些汽车行业的知名网站,如汽车之家等。
算法首先根据网页相关性的度量进行初始化,然后通过迭代计算更新节点的分值,最后得出每个节点的得分值。
二、HITS算法的应用1. 社交网络广告投放使用HITS算法可以对社交网络中的广告进行定向投放。
通过计算用户相关度和结点权重,将广告投放到最适合的用户或节点上,从而提高广告的转化率和效果。
2. 社交网络用户推荐HITS算法可以用于推荐系统中的用户推荐。
通过计算用户之间的关联度,并选出枢纽节点,推荐系统可以为用户提供更加个性化的推荐,从而提高推荐的准确性和用户体验。
3. 社交网络营销策略制定社交网络数据分析可以帮助企业制定更精准的营销策略。
利用HITS算法分析网络中的节点和用户之间的联系,确定关键节点,结合用户的属性信息,进一步制定营销策略,提高营销效果。
三、结语HITS算法作为社交网络数据分析中的重要算法,具有广泛的应用前景。
在实际应用中,需要根据具体情况进行调整和优化,以提高算法的准确度和效率。
hits算法
HITS(Hyperlink-Induced Topic Search)算法是一种网络分析算法,用于评估网页的重要性。
它通过分析网页之间的链接关系来计算每个网页的权威值(Authority)和枢纽值(Hub)。
权威值是指一个网页被其他网页引用的次数,而枢纽值是指一个网页指向其他网页的链接数。
HITS算法认为,一个网页的权威值越高,说明它越重要,因为它被很多其他网页所引用;同样地,一个网页的枢纽值越高,也说明它越重要,因为它指向很多其他网页。
在实际应用中,HITS算法可以通过根集合和基本集合的概念来找到与查询主题相关的网页。
根集合是指与查询主题直接相关的网页集合,而基本集合则是指根集合中所有网页的邻居集合。
然后,HITS算法会计算每个网页的权威值和枢纽值,从而确定每个网页的重要性。
HITS算法的优点是简单易用,可以快速找到与查询主题相关的网页。
但是,它也有一些局限性,例如可能会受到网络中的噪声和垃圾链接的影响,导致结果不够准确。
因此,在实际应用中,需要结合其他算法和评价指标来综合评估网页的重要性。
基于HITS算法的搜索引擎概述摘要:本文简要介绍了目前搜索引擎中应用较为广泛的一种算法——HITS算法。
HITS算法是Web结构挖掘中最具有权威性和使用最广泛的算法。
其基本思想是利用页面之间的引用链来挖掘隐含在其中的有用信息(如权威性),具有计算简单且效率高的特点。
HITS算法通过两个评价权值——内容权威度(Authority)和链接权威度(Hub)来对网页质量进行评估。
HITS算法认为对每一个网页应该将其内容权威度和链接权威度分开来考虑,在对网页内容权威度做出评价的基础上再对页面的链接权威度进行评价,然后给出该页面的综合评价。
它专注于改善泛指主题检索的结果,通过一定的计算(迭代计算)方法以得到针对某个检索提问的最具价值的网页,即排名最高的authority。
关键词:搜索引擎;HITS算法;权威度;网页排名引言:随着因特网的迅猛发展,搜索引擎的应用已经非常普及。
然而,人们对搜索引擎的核心技术———算法设计知之并不多。
了解搜索引擎的算法设计思想及原理,有助于提高我们的信息检索能力,评价搜索引擎。
更为重要的是,我国在信息技术领域内的发展情况与发达国家相比还有相当的差距,只有真正掌握了搜索引擎的核心技术,才可能开发出属于我们自己功能强大的搜索引擎,以使我们在当今的信息社会中立于不败之地。
国内目前对搜索引擎排序算法的介绍较少,从已有的文献来看,多集中于对更具影响力的PageRank算法的介绍和分析研究,而对全球已有较大影响的HITS算法和SALSA算法介绍较少。
本文中所重点说明的HITS算法是由康奈尔大学(Cornell University)的JonKleinberg博士于1998年首先提出的,HITS的英文全称为Hy pertext-Induced Topic Search。
目前,它为IBM公司阿尔马登研究中心(IBM Almaden Research Center)的名为“CLEVER”的研究项目中的一部分。
一、搜索引擎搜索引擎为用户提供信息检索服务,作为辅助人们检索信息的工具,是在Web上发现信息的关键技术,是用户访问万维网的最佳入口。
它借助于自动搜索网页的软件,在网络上通过各种链接获得大页面文档的信息,并按照一定算法与规则进行归类整理,形成文档索引数据库,以备用户查询。
1)搜索引擎的工作原理搜索引擎有两个重要组成部分,即离线部分和在线部分。
离线部分由搜索引擎定期执行,包括下载网站的页面集合,并经处理把这些页面转换成可搜索的索引。
在线部分在用户查询时被执行,根据与用户需求的相关性,利用索引去选择候选文档并排序显示。
搜索引擎原理-三段式工作流程2)搜索引擎算法获得网站网页资料,建立数据库并提供查询的系统,我们都可以把它叫做搜索引擎。
搜索引擎的数据库是依靠一个叫“网络机器人(Spider)”或叫“网络蜘蛛(crawlers)”的软件,通过网络上的各种链接自动获取大量网页信息内容,并按一定的规则分析整理形成的。
Google、百度都是比较典型的搜索引擎系统。
为了更好的服务网络搜索,搜索引擎的分析整理规则---既搜索引擎算法是变化的。
3)搜索引擎排名算法分类在各种搜索引擎上进行同样搜索时会产生不同的结果。
究其原因,首先,检索依赖于网络蜘蛛能找到的信息。
其次,并非搜索引擎都使用相同的排名算法。
排名算法趋势:以Yahoo为代表的第一代文本搜索算法;雅虎的人工分类方式,网站目录搜索第二代以PageRank和HITS为代表的基于链接分析的搜索算法;第二代半基于网站的访问量。
第三代应该具有智能化、个性化和社区化等特征。
二、HITS算法HITS(Hyperlink-Induced Topic Search)是由Kleinberg在90年代末提出的基于链接分析的网页排名算法。
描述两种类型的网页:“权威型(Authority)网页”:对于一个特定的检索,该网页提供最好的相关信息;“目录型(Hub)网页”:该网页提供很多指向其它高质量权威型网页的超链。
由此,我们可以在每个网页上定义“目录型权值”和“权威型权值”两个参数。
1)Hits算法的基本思想1.好的Hub型网页指向好的Authority网页2.好的Authority网页是由好的Hub型网页所指向的网页。
2)Hits算法HITS(Hyperlink-Induced Topic Search)算法是利用HubPAuthority的搜索方法,具体算法如下:将查询q提交给基于关键字查询的检索系统,从返回结果页面的集合总取前n个网页(如n=200),作为根集合(root set),记为S,则S满足:1.S中的网页数量较少2.S中的网页是与查询q相关的网页3.S中的网页包含较多的权威(Authority)网页通过向S中加入被S引用的网页和引用S的网页,将S扩展成一个更大的集合T.以T中的Hub网页为顶点集V1,以权威网页为顶点集V2。
V1中的网页到V2中的网页的超链接为边集E,形成一个二分有向图.对V1中的任一个顶点v,用h(v)表示网页v的Hub值,且h(v)收敛;对V2中的顶点u,用a(u)表示网页的Authority值。
开始时h(v)=a(u)=1,对u执行I操作,修改它的a(u),对v执行O 操作,修改它的h(v),然后规范化a(u)P h(v),如此不断的重复计算下面的I 操作和O操作,直到a(u)。
其中I操作:a(u)=Σh(v);O操作:h(v)=Σa(u)。
每次迭代对a(u)、h(v)进行规范化处理:a(u)=a(u)PΣ[a(q)]2;h(v)= h(v)PΣ[h(q)]2。
HITS算法可以获得比较好的查全率,输出一组具有较大Hub值的网页和具有较大权威值的网页.但在实际应用中,HITS算法有以下几个问题:由S生成T的时间开销是很昂贵的,由T生成有向图也很耗时,需要分别计算网页的A P H值,计算量大;网页中广告等无关链接影响A、H值的计算,降低HITS算法的精度;HITS算法只计算主特征向量,处理不好主题漂移问题;进行窄主题查询时,可能产生主题泛化问题。
相关分析算法大体可以分为4类:基于随机漫游模型的算法,比如PageRank,Repution算法;基于Hub和Authority相互加强模型的算法,如HITS 及其变种;基于概率模型的算法,如SALSA,PHITS;基于贝叶斯模型的算法,如贝叶斯算法.所有的算法在实际应用中都结合传统的内容分析技术进行优化。
Allan Borodin也指出没有一种算法是完美的,在某些查询下,结果可能很好,在另外的查询下,结果可能很差.将S扩展为基本集合(base set)T,T包含由S指出或指向S 的网页。
可以设定一个上限如1000—5000个网页。
开始权重传播。
在集合T中计算每个网页的目录型权值和权威型权值。
Clever 的做法是采用目录型网页和权威型网页相互评价的办法进行递归计算。
对于一个网页p,用xp来表示网页p的权威型权值,用yp来表示它的目录型权值,并且用如下公式进行计算:1.计算各节点的Hub和Authority:2.赋予每个节点的hub值和authority值都为1。
3.运行Authority更新规则。
4.运行Hub更新规则。
5.Normalize数值,即每个节点的Hub值除所有Hub值之和,每个Authority值除所有Authority值之和。
6.必要时从第二步开始重复。
三、HITS与PageRank的区别PageRank和HITS的迭代算法都利用了特征向量作为理论基础和收敛性依据。
这也是超链接环境下此类算法的一个共同特征。
但两种算法也有着明显的不同点,下面着重阐述两种算法的不同点。
从两者的权值传播类型来看,PageRank算法基于随机冲浪(Random Surfer)模型,将网页权值直接从authority网页传递到authority网页;而HITS算法则是将authority网页的权值经过hub网页的传递进行传播。
从算法思想上看,虽然均同为链接分析算法,但二者之间还是有一定的区别。
HITs的原理如前所述,其authority值只是相对于某个检索主题的权重,因此HITS 算法也常被称为query—dependent算法。
而PageRank算法独立于检索主题,因此也常被称为query—independent算法。
PageRank的发明者(Page Brin)把引文分析思想借鉴到网络文档重要性的计算中来,利用网络自身的超链接结构给所有的网页确定一个重要性的等级数。
当然PageRank并不是引文分析的完全翻版,根据因特网自身的性质等,它不仅考虑网页引用数量,还特别考虑了网页本身的重要性。
从处理的数据量及用户端等待时间来分析。
表面上看,HITS算法对需排序的网页数量需求较小,所计算的网页数量一般为1000至5000个,但由于需要从基于内容分析的搜索引擎中提取根集并扩充基本集,这个过程需要耗费相当的时间,而PageRank算法表面上看,处理的数据数量上远远超过了HITS算法。
从两者的处理对象来看,都是针对整个万维网上的网页的一个子集进行排序、筛选,没有一个搜索引擎能够将万维网上的网页全部搜索下来。
但是,PageRank 算法的处理对象是一个搜索引擎上当前搜索下来的所有网页,一般在几千万个页面以上;而HITS的处理对象是搜索引擎针对具体查询主题所返回的结果,从几百个页面扩展到几千几万个页面。
从两者的具体应用来看,PageRank算法应用于搜索引擎服务端,可以直接用于标题查询并获得较好的结果,若要用于全文本查询,需要与其它相似度判定标准(向量模型等)进行复合,以针对具体查询形成最终排名,搜索机器人(Crawler)可以将PageRank作为搜索优先次序的标准,算法中E的取值可以用来定制个人搜索引擎;HITS算法一般用于全文本搜索引擎的客户端l1,对于宽主题的搜索相当有效,可以用于自动编撰万维网分类目录,通过找到指向某网页的Hub网页并以此为根集R,查找该网页的相关网页,也可以用于元搜索引擎的网页排序。
参考文献:西北大学可视化研究所常庆、周明全、耿国华《基于PageRank和HITS的Web搜索》苏州大学范聪贤、徐汀荣、范强贤《Web结构挖掘中HITS算法改进的研究》第三军医大学图书馆何晓阳、吴强、吴治蓉《HITS算法与PageRank算法比较分析》。