UC头条文章采集
- 格式:docx
- 大小:3.47 MB
- 文档页数:32
对于站长以及新媒体运营人员来说,文章采集是必须要掌握的一项功能。
通过文章采集一个是能很清楚的掌握自身行业中哪些类型的文章受用户的喜爱,其实是合理的采集高质量的爆款文章,建立自己的资料库,从而生产出优质的文章。
目前来说,有很多自媒体平台都是可以采集文章的,比如今日头条、百家号、搜狗微信、新浪微博等等,这些平台基本都有搜索功能,你可以根据关键词去采集自己需要的文章。
下面具体为大家介绍八爪鱼文章采集软件的使用方法。
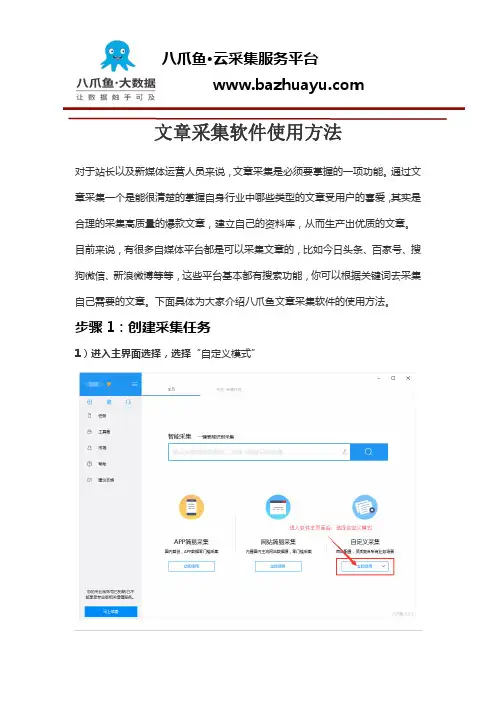
步骤1:创建采集任务1)进入主界面选择,选择“自定义模式”文章采集软件使用步骤12)将上面网址的网址复制粘贴到网站输入框中,点击“保存网址”文章采集软件使用步骤23)保存网址后,页面将在八爪鱼采集器中打开,红色方框中的信息是这次演示要采集的内容,即为今日头条最新发布的热点新闻。
文章采集软件使用步骤3步骤2:设置ajax页面加载时间●设置打开网页步骤的ajax滚动加载时间●找到翻页按钮,设置翻页循环●设置翻页步骤ajax下拉加载时间1)网页打开后,需要进行以下设置:打开流程图,点击“打开网页”步骤,在右侧的高级选项框中,勾选“页面加载完成向下滚动”,设置滚动次数,每次滚动间隔时间,一般设置2秒,这个页面的滚动方式,选择直接滚动到底部;最后点击确定文章采集软件使用步骤4注意:今日头条的网站属于瀑布流网站,没有翻页按钮,这里的滚动次数设置将影响采集的数据量。
文章采集软件使用步骤5步骤3:采集新闻内容创建数据提取列表1)如图,移动鼠标选中评论列表的方框,右键点击,方框底色会变成绿色 然后点击“选中子元素”文章采集软件使用步骤6注意:点击右上角的“流程”按钮,即可展现出可视化流程图。
2)然后点击“选中全部”,将页面中需要需要采集的信息添加到列表中文章采集软件使用步骤7注意:在提示框中的字段上会出现一个“X”标识,点击即可删除该字段。
文章采集软件使用步骤83)点击“采集以下数据”文章采集软件使用步骤9 4)修改采集字段名称,点击下方红色方框中的“保存并开始采集”文章采集软件使用步骤10步骤4:数据采集及导出1)根据采集的情况选择合适的采集方式,这里选择“启动本地采集”文章采集软件使用步骤11说明:本地采集占用当前电脑资源进行采集,如果存在采集时间要求或当前电脑无法长时间进行采集可以使用云采集功能,云采集在网络中进行采集,无需当前电脑支持,电脑可以关机,可以设置多个云节点分摊任务,10个节点相当于10台电脑分配任务帮你采集,速度降低为原来的十分之一;采集到的数据可以在云上保存三个月,可以随时进行导出操作。

网络文字抓取工具使用方法网页文字是网页中常见的一种内容,有些朋友在浏览网页的时候,可能会有批量采集网页内容的需求,比如你在浏览今日头条文章的时候,看到了某个栏目有很多高质量的文章,想批量采集下来,下面本文以采集今日头条为例,介绍网络文字抓取工具的使用方法。
采集网站:使用功能点:●Ajax滚动加载设置●列表内容提取步骤1:创建采集任务 1)进入主界面选择,选择“自定义模式”今日头条网络文字抓取工具使用步骤12)将上面网址的网址复制粘贴到网站输入框中,点击“保存网址”今日头条网络文字抓取工具使用步骤23)保存网址后,页面将在八爪鱼采集器中打开,红色方框中的信息是这次演示要采集的内容,即为今日头条最新发布的热点新闻。
今日头条网络文字抓取工具使用步骤3步骤2:设置ajax页面加载时间●设置打开网页步骤的ajax滚动加载时间●找到翻页按钮,设置翻页循环●设置翻页步骤ajax下拉加载时间1)网页打开后,需要进行以下设置:打开流程图,点击“打开网页”步骤,在右侧的高级选项框中,勾选“页面加载完成向下滚动”,设置滚动次数,每次滚动间隔时间,一般设置2秒,这个页面的滚动方式,选择直接滚动到底部;最后点击确定今日头条网络文字抓取工具使用步骤4注意:今日头条的网站属于瀑布流网站,没有翻页按钮,这里的滚动次数设置将影响采集的数据量。
今日头条网络文字抓取工具使用步骤5步骤3:采集新闻内容创建数据提取列表1)如图,移动鼠标选中评论列表的方框,右键点击,方框底色会变成绿色然后点击“选中子元素”今日头条网络文字抓取工具使用步骤6注意:点击右上角的“流程”按钮,即可展现出可视化流程图。
2)然后点击“选中全部”,将页面中需要需要采集的信息添加到列表中今日头条网络文字抓取工具使用步骤7注意:在提示框中的字段上会出现一个“X”标识,点击即可删除该字段。
今日头条网络文字抓取工具使用步骤8 3)点击“采集以下数据”今日头条网络文字抓取工具使用步骤94)修改采集字段名称,点击下方红色方框中的“保存并开始采集”今日头条网络文字抓取工具使用步骤10步骤4:数据采集及导出1)根据采集的情况选择合适的采集方式,这里选择“启动本地采集”今日头条网络文字抓取工具使用步骤11说明:本地采集占用当前电脑资源进行采集,如果存在采集时间要求或当前电脑无法长时间进行采集可以使用云采集功能,云采集在网络中进行采集,无需当前电脑支持,电脑可以关机,可以设置多个云节点分摊任务,10个节点相当于10台电脑分配任务帮你采集,速度降低为原来的十分之一;采集到的数据可以在云上保存三个月,可以随时进行导出操作。

网页数据爬取有什么用?如何爬取数据?网页数据爬虫相信很多朋友听过,一般是指从网站上提取指定内容,对于很多小白来说,不会编程让他们很难去实现网页数据爬取,但是爬虫工具出现后,他们很容易去从指定网站获取需要的内容。
下面为大家介绍网页爬取数据有什么用?如何爬虫数据?网页数据爬取有什么用1、电子商务,机票和酒店业的价格监控,利用网页数据爬取技术可以实时采集并更新这些产品的销售价格,从而实现价格监控。
2、挖掘客户的意见,通过对产品的评论数据爬取,然后进行相关的分词以及情感分析,就能清楚的知道客户对于自身产品或者竞品产品的意见。
3、构建机器学习算法的数据集,通过网络爬虫爬取相关的数据,然后用户训练机器学习。
其实网页数据爬取还有很多应用,上面只是简单介绍其中三种。
如何爬取网页数据以上介绍了网页数据爬取有如此多的应用,那么应该如何爬取网页数据呢,下面本文介绍一款爬虫工具,无需编写代码,只需要简单配置规则就能采集需要的网页数据,本次以采集示例网址为例,为大家演示这款爬虫工具采集方法。
示例网址:/guide/demo/tables2.html步骤1:打开八爪鱼采集器→点击自定义采集下立即使用按键→输入网址并保存说明:你可以根据自己掌握程度来选择自定义模式或向导模式进行采集。
步骤2:选择表格中两个以上要采集的单元格→等表格内要采集的内容变成绿色时点击选中全部→点击采集以下数据→打开流程图修改字段名并保存说明:操作提示中,选项后面的问号(?)表示备注信息,如果对采集选项有什么疑问可以先看一下备注信息,如果得不到解答可以联系客服。
操作提示中,如果页面当前显示的采集方式不能满足你的需求,请点击下面的更多按键,会出现所有可进行的操作。
步骤3:保存并启动→选择采集模式→采集完成→导出数据相关采集教程:今日头条采集/tutorial/hottutorial/xwmt/toutiao 企业信息采集/tutorial/hottutorial/qyxx58同城信息采集/tutorial/caiji58ershoucar美团商家数据采集/tutorial/meituansjpl阿里巴巴采集器/tutorial/1688qiyemlcj企查查企业邮箱采集/tutorial/qccqyemailcj微博图片采集/tutorial/wbpiccjuc头条文章采集/tutorial/ucnewscj。

自媒体免费爆文采集器如何使用创造出来一篇爆文对于众多做自媒体的朋友而言,无疑是件欢欣鼓舞的事。
感觉升职加薪,分分钟走上人生巅峰!然,即使自己暂时不能写出一篇爆文,那也不可阻拦自己去收集别人的。
他山之石,可以攻玉,更何况本来就是玉呢!而如何快速又免费收集到在自媒体爆文,这就有技巧了!要不然时间都花在文章收集上,还写啥文章!以下介绍使用八爪鱼7.0采集自媒体文章采集方法,以今日头条为例。
注:软件内还支持判断条件的设置,判断筛选出哪些是爆文,而这些都可以自定义设置。
采集网站:使用功能点:●Ajax滚动加载设置●列表内容提取步骤1:创建采集任务1)进入主界面选择,选择“自定义模式”自媒体文章采集步骤12)将上面网址的网址复制粘贴到网站输入框中,点击“保存网址”自媒体文章采集步骤23)保存网址后,页面将在八爪鱼采集器中打开,红色方框中的信息是这次演示要采集的内容,即为今日头条最新发布的热点新闻。
自媒体文章采集步骤3步骤2:设置ajax页面加载时间●设置打开网页步骤的ajax滚动加载时间●找到翻页按钮,设置翻页循环●设置翻页步骤ajax下拉加载时间1)网页打开后,需要进行以下设置:打开流程图,点击“打开网页”步骤,在右侧的高级选项框中,勾选“页面加载完成向下滚动”,设置滚动次数,每次滚动间隔时间,一般设置2秒,这个页面的滚动方式,选择直接滚动到底部;最后点击确定自媒体文章采集步骤4注意:今日头条的网站属于瀑布流网站,没有翻页按钮,这里的滚动次数设置将影响采集的数据量。
自媒体文章采集步骤5步骤3:采集新闻内容创建数据提取列表1)如图,移动鼠标选中评论列表的方框,右键点击,方框底色会变成绿色然后点击“选中子元素”自媒体文章采集步骤6注意:点击右上角的“流程”按钮,即可展现出可视化流程图。
2)然后点击“选中全部”,将页面中需要需要采集的信息添加到列表中自媒体文章采集步骤7注意:在提示框中的字段上会出现一个“X”标识,点击即可删除该字段。

网站文章标题采集当我们在网站优化,或分析词频权重,研究站点内哪些类型的文章标题是频繁出现时,快速的获取站点内全部的文章标题就必不可少了。
量少或许还能通过复制粘贴解决,但量若上来了,有成千甚至上万的文章标题需要获取。
那手动复制粘贴简直就是噩梦!此时必然要寻求更快的解决方案。
如通过爬虫工具快速批量获取文章标题。
以下用做网易号文章例演示,通过八爪鱼这个爬虫工具去获取数据,不单单获取文章标题,还能获取文章内容。
步骤1:创建网易号文章采集任务1)进入主界面,选择“自定义采集”2)将要采集的网址URL复制粘贴到网站输入框中,点击“保存网址”步骤2:创建循环点击加载更多1)打开网页之后,打开右上角的流程按钮,从左边的流程展示界面拖入一个循环的步骤,如下图2)然后拉到页面底部,看到加载更多按钮,因为想要查看更多内容就需要循环的点击加载更多,所以我们就需要设置一个点击“加载更多”的循环步骤。
注意:采集更多内容就需要加载更多的内容,本篇文章仅做演示,所以选择执行点击“加载更多”20次,根据自己实际需求加减即可。
步骤3:创建循环点击列表采集详情1)点击文章列表的第一个和第二个标题,然后选择“循环点击每个元素”按钮,这样就创建了一个循环点击列表命令,当前列表页的内容就都能在采集器中看到了。
2)然后就可以提取我们需要的文本数据了,下图提取了文本的标题、时间、正文等三个部分的文字内容,还需要其他的信息可以自由删减编辑。
然后就可以点 击保存,开始本地采集。
3)点击开始采集后,采集器就开始提取数据。
4)采集结束后导出即可。
相关采集教程:新浪新闻采集/tutorial/xlnewscjBBC英文文章采集/tutorial/englisharticlecj新浪博客文章采集/tutorial/sinablogcjuc头条文章采集/tutorial/ucnewscj百家号爆文采集/tutorial/bjharticlecj自媒体文章怎么采集/tutorial/zmtwzcj微信文章爬虫使用教程/tutorial/wxarticlecrawl 八爪鱼采集原理/tutorial/spcjyl八爪鱼采集器7.0简介/tutorial/70js八爪鱼——90万用户选择的网页数据采集器。

站文章自动采集自动采集文章标题:如何通过自动采集站点进行网站内容的快速获取在当今信息爆炸的时代,网站内容的获取和整理变得愈发重要。
而自动采集站点成为了一种快速获取网站内容的有效工具。
本文将介绍如何通过自动采集站点进行网站内容的快速获取。
一、了解自动采集站点的基本原理自动采集站点是一种能够自动抓取网站内容的工具,其基本原理是通过设定规则,自动识别网页上的信息,并将其抓取、整理、存储。
通过自动采集站点,用户可以快速获取大量网站内容,节省时间和人力成本。
二、选择适合自己需求的自动采集站点工具在选择自动采集站点工具时,需要根据自己的需求来进行选择。
一般来说,自动采集站点工具分为付费和免费两种类型。
付费工具通常功能更加强大,而免费工具则相对简单一些。
用户可以根据自己的需求和预算来选择适合自己的工具。
三、学习如何使用自动采集站点工具在使用自动采集站点工具之前,用户需要学习如何使用该工具。
一般来说,自动采集站点工具会提供详细的教程和帮助文档,用户可以根据这些文档来学习如何使用该工具。
此外,用户还可以通过观看视频教程或者参加培训课程来提升自己的技能。
四、合理设置自动采集规则在使用自动采集站点工具时,用户需要合理设置采集规则。
一般来说,用户可以根据需要设置网站的URL、关键词、抓取深度等参数。
通过合理设置采集规则,用户可以快速获取自己需要的网站内容。
五、定期更新和维护自动采集规则在使用自动采集站点工具时,用户需要定期更新和维护采集规则。
由于网站内容会不断更新和变化,用户需要及时调整采集规则,以确保能够持续获取到最新的网站内容。
六、注意合规和版权问题在使用自动采集站点工具时,用户需要注意合规和版权问题。
一般来说,用户需要遵守网站的使用条款和版权法律,不得未经授权擅自抓取网站内容。
用户可以通过与网站所有者协商或者购买授权的方式来解决版权问题。
总之,通过自动采集站点工具可以快速获取网站内容,节省时间和人力成本。
然而,在使用自动采集站点工具时,用户需要了解其基本原理,选择适合自己需求的工具,学习如何使用该工具,合理设置采集规则,定期更新和维护采集规则,以及注意合规和版权问题。

孤狼采集器是干什么的做自媒体相关工作或者站长的朋友可能会听过孤狼采集器,通过孤狼采集器采集微信文章,然后发布到自己的网站上或者微信工作号上。
不过孤狼采集器只能采集文章,并且目前好像只能采集微信平台的。
如果要采集其它网站数据,或者采集其它平台的文章,那么可以考虑使用八爪鱼采集器。
八爪鱼采集器的优点1、功能强大。
八爪鱼采集器是一款通用爬虫,可应对各种网页的复杂结构(瀑布流等)和防采集措施(登录、验证码、封IP),实现百分之九十九的网页数据抓取。
2、操作简单。
模拟人浏览网页的操作,通过输入文字、点击元素、选择操作项等一些简单操作,即可完成规则配置,无需编写代码,对没有技术背景的用户极为友好。
3、流程可视化。
真正意义上实现了操作流程可视化,用户可打开“流程”按钮,直接可见操作流程,并对每一步骤,进行高级选项的设置(ajax/修改xpath 等)。
4、云采集。
数量庞大的企业云,24x7不间断运行,可定时采集、关机也可采集,同时支持任务拆分,可提高数据采集速度。
5、7.0版本推出的简易网页采集,内置主流网站大量数据源和已经写好的采集规则。
用户只需输入关键词,即可采集到大量所需数据。
八爪鱼采集器能采集平台文章数据目前绝大部分自媒体平台,八爪鱼采集器都是可以进行采集的,比如微信公众号,今日头条,新浪博客,UC头条,下面介绍具体的采集方法,大家可以根据自身需求查看相应的教程。
1、今日头条数据采集采集内容:标题、来源、评论、发布时间采集教程地址:/tutorialdetail-1/jrtt-7.html2、网易号文章采集采集内容:网易号文章标题,网易号文章发布时间,网易号文章正文。
采集教程地址:/tutorialdetail-1/wyhcj.html3、uc头条文章采集采集内容:标题、发布者、发布时间、文章内容、页面网址、图片URL 采集教程地址:/tutorialdetail-1/ucnewscj.html4、百家号爆文采集采集内容:文章标题,文章作者,发布时间,阅读数,文章正文采集教程地址:/tutorialdetail-1/bjharticlecj.html5、微信公众号热门文章采集(文本+图片)采集内容:文章标题、时间、来源和正文+图片URL采集教程地址:/tutorialdetail-1/wxcjimg.html6、新浪博客文章采集采集内容:博客文章正文,博客文章标题,文章标签,文章分类,文章发布日期。

网络赚钱利器:文章采集神器分享哈喽,各位亲爱的伙伴们,大家好,今天给大家分享一个超级腻害、实用的神器:文章采集器。
为什么要给大家分享这款神器呢?因为我们现在做互联网,在互联网赚钱,写文章是家常便饭,比如你自己本身就是做自媒体、微信公众号、网站编辑,站长类等工作,你每天都需要大量的文章去维持更新。
还有你像你的客户介绍产品,大多数也需要写软文文案等等这款神器就是分享给那些需要写文章的人的,你可以用这款神器根据关键词采集文章,然后可以借鉴这些文章的思想,完成文章的撰写,对于做网站推广和优化的朋友来说更是一款不可多得的使用工具;可以大大提高你的工作效率;解决没文章没素材的烦恼,助你网络赚钱一臂之力!接下来正式分享这款采集器:水淼万能文章采集器是一款简单有效功能强大的文章采集软件。
你只需要可输入关键词,即可采集各大搜索引擎网页和新闻,也可以采集指定网站文章,非常方便快捷;本次小编为大家带来的是水淼万能文章采集器绿色免费破解版,双击即可打开使用,软件已经完美破解无需注册码激活即可免费使用,喜欢的小伙伴们欢迎下载。
文章采集来源主要来自以下搜索引擎:百度网页、百度新闻、搜狗网页、搜狗新闻、微信、360网页、360新闻、今日头条、一点资讯、必应网页、必应新闻、雅虎、谷歌网页、谷歌新闻功能特点一、依托于万能正文识别智能算法,可实现任何网页正文自动提取准确率95%以上。
二、只需输入关键词,就能采集到百度新闻和网页、搜狗新闻和网页、360新闻和网页、谷歌新闻和网页、必应新闻和网页、雅虎;可批量关键词全自动采集。
三、可定向采集指定网站栏目列表下的所有文章,智能化匹配,无需编写复杂规则。
四、文章转译功能,可对采集好的文章,将其翻译到英文再翻译回中文,实现翻译伪原创,支持谷歌和有道翻译。
五、史上最简单最智能文章采集器,支持全功能试用,效果如何一试就知!使用说明1、下载并解压好文件,双击“水淼·万能文章采集器Crack.exe”打开,你会发现软件还是免费破解的哦。


其他微信公众号的文章排版都美美哒,自己只能眼巴巴的看着,想用却无从下手?需要转载一篇文章,好不容易复制完,结果一粘贴,发现格式全乱了?今天我就教大家一个小技能——文章采集,不管是排版样式,还是文章内容,只需一键即可导入编辑器中,快来学习一下吧。
01采集演示整个操作过程不到5秒钟,是不是超级简单?超级快捷好用?02使用教程接下来,我们就一起来看一下采集功能如何使用。
⑴选定目标文章,复制文章链接。
电脑端用户可直接全选复制浏览器地址栏中的文章链接。
▲ PC端保存文章链接手机端用户可点击右上角菜单按钮,选择复制链接,将该链接发送到电脑上。
▲移动端保存文章链接⑵点击采集按钮。
编辑器中的文章采集功能入口有两个:① 编辑菜单右上角的【采集文章】按钮;▲采集按钮② 右侧功能按钮底部的【采集文章】按钮。
▲采集按钮⑶粘贴文章链接并采集。
▲粘贴链接采集编辑器支持采集微信公众号、QQ公众号、今日头条号、百度百家号、一点号、网易号、搜狐公众号、新浪博客、腾讯新闻、新浪新闻、天天快报、网易新闻、知乎专栏等【众多自媒体平台】文章。
03文章应用将文章采集到编辑区域之后,我们就可以进行后续的修改和排版了。
⑴使用原文的排版。
如果只使用原文的排版,将文章采集过来之后,仅【替换文字和图片】即可。
文字替换:将需要使用的文字写入编辑区域,或者用无格式粘贴(Ctrl+Shift+V),将文字粘贴至编辑区域,随后用【格式刷】工具,将原文的格式应用到新输入的文中上。
▲格式刷图片替换:点击编辑区域需要替换的图片,再点击右侧图片区域的图片,即可完成替换。
⑵使用原文的内容。
如果不需要原文的排版,只需要使用文章的内容,将文章采集到编辑区域之后,可以使用快捷键(Ctrl+A )全选,然后用【清除格式】按钮,清除原文格式,随后对文章内容进行排版即可。
▲清除格式① 可以使用【秒刷】功能,直接套用编辑器中的素材样式:选中要秒刷的内容,点击喜欢的样式,样式即可使用成功。

如何使用八爪鱼批量下载网页八爪鱼作为一款通用的网页数据采集器,其并不针对于某一网站某一行业的数据进行采集,而是网页上所能看到或网页源码中有的文本信息几乎都能采集,有些朋友有批量下载网页的需求,其实可以使用八爪鱼采集器去实现。
下面以UC头条网页为大家详细介绍如何使用八爪鱼批量下载网页。
采集网站:https:///使用功能点:Xpathxpath入门教程1/tutorialdetail-1/xpathrm1.htmlxpath入门2/tutorialdetail-1/xpathrm1.html相对XPATH教程-7.0版/tutorialdetail-1/xdxpath-7.htmlAJAX滚动教程/tutorial/ajgd_7.aspx?t=1步骤1:创建UC头条文章采集任务1)进入主界面,选择“自定义模式”2)将要采集的网址URL复制粘贴到网站输入框中,点击“保存网址”3)在页面右上角,打开“流程”,以展现出“流程设计器”和“定制当前操作”两个板块。
网页打开后,默认显示“推荐”文章。
观察发现,此网页没有翻页按钮,而是通过下拉加载,不断加载出新的内容因而,我们选中“打开网页”步骤,在高级选项中,勾选“页面加载完成后向下滚动”,滚动次数根据自身需求进行设置,间隔时间根据网页加载情况进行设置,滚动方式为“向下滚动一屏”,然后点击“确定”(注意:间隔时间需要针对网站情况进行设置,并不是绝对的。
一般情况下,间隔时间>网站加载时间即可。
有时候网速较慢,网页加载很慢,还需根据具体情况进行调整。
具体请看:八爪鱼7.0教程——AJAX滚动教程步骤2:创建翻页循环及提取数据1)移动鼠标,选中页面里第一条文章链接。
系统会自动识别相似链接,在操作提示框中,选择“选中全部”2)选择“循环点击每个链接”3)系统会自动进入文章详情页。
点击需要采集的字段(这里先点击了文章标题),在操作提示框中,选择“采集该元素的文本”文章发布时间、文章作者、文章发布时间、文章正文内容采集方法同上。
采集文章的技巧
以下是采集文章的技巧:
1. 确定采集目标:在采集文章之前,要明确采集的目标,确定文章的类型、主题和风格。
2. 收集信息:通过搜索引擎、社交网络、论坛、新闻等途径收集相关信息,可以收集到不同的观点和角度,提高文章的质量。
3. 审核来源:在收集信息的过程中,要注意审核来源的可靠性和权威性,避免引用虚假、不实或未经证实的信息。
4. 整理内容:在收集到相关文章后,要整理内容,剔除无关和重复的信息,提炼出核心观点和信息。
5. 引用的技巧:引用他人的观点和信息时,要注明来源,避免侵犯知识产权和抄袭行为。
此外,在引用的同时,可以适度加入自己的观点和见解,提高文章的独特性和质量。
6. 对比和参考:在完成文章后,可以进行对比和参考,将自己的文章和相关文章进行比较和分析,了解文章的优劣之处,提高自己的写作水平。
如何快速提取网页文字我们在浏览网页时,有时候需要将网页上的一些文字内容复制下来,保存到本地电脑或者数据库中,手工复制粘贴费时费力,效率又低,这时我们可以借助网页文字采集器来轻松提取网页上可见的文字内容,甚至是那些被大面积的广告覆盖看不到的文字内容,网页文字采集器都可以帮你把想要的网页文字内容给提取出来,简单方便,又大大的提升了效率。
下面就为大家介绍一款免费好用的网页文字采集器来提取网页文字。
本文以使用八爪鱼采集器采集新浪博客文章为例子,为大家详细讲解如何快速提取网页文字。
采集网站:/s/articlelist_1406314195_0_1.html 采集的内容包括:博客文章正文,标题,标签,分类,日期。
步骤1:创建新浪博客文章采集任务1)进入主界面,选择“自定义采集”2)将要采集的网址URL复制粘贴到网站输入框中,点击“保存网址”步骤2:创建翻页循环1)打开网页之后,打开右上角的流程按钮,使制作的流程可见状态。
点击页面下方的“下一页”,如图,选择“循环点击单个链接”,翻页循环创建完成。
(可在左上角流程中手动点击“循环翻页”和“点击翻页”几次,测试是否正常翻页。
)2)由于进入详情页时网页加载很慢,网址一直在转圈状态,无法立即执行下一个步骤,因此在“循环翻页”的高级选项里设置“ajax 加载数据”,超时时间设置为5秒,点击“确定”。
步骤3:创建列表循环1)鼠标点击列表目录中第一个博文,选择操作提示框中的“选中全部”。
2)鼠标点击“循环点击每个链接”,列表循环就创建完成,并进入到第一个循环项的详情页面。
由于进入详情页时网页加载很慢,网址一直在转圈状态,无法立即执行下一个步骤,因此在“点击元素”的高级选项里设置“ajax加载数据”,AJAX超时设置为3秒,点击“确定”。
3)数据提取,接下来采集具体字段,分别选中页面标题、标签、分类、时间,点击“采集该元素的文本”,并在上方流程中修改字段名称。
鼠标点击正文所在的地方,点击提示框中的右下角图标,扩大选项范围,直至包括全部正文内容。
自媒体爆文采集工具使用方法自媒体是随着移动互联网发展起来的,日常生活的信息很大一部分是来自于自媒体,自媒体不是简简单单的写写文章,而是要有丰富的知识体系和生活感悟,才能写出有深度略带鸡汤的干货,这样才能成为自媒体爆文。
如果要从事自媒体工作应该如何才能写出有影响力的爆文呢,最好方法是参考。
本文介绍一种自媒体爆文采集工具的使用方法,让你在海量的爆文中找到套路。
本文采集的字段是标题、发文者、时间、阅读数和正文。
大家在实际操作过程中,可根据自身需求更改字段内容。
此网站需要注意的是网页应用了ajax技术、系统自动生成的流程图会出现重复数据,需手动调整。
采集网站:https:///使用功能点:●分页列表信息采集/tutorialdetail-1/fylb-70.html●AJAX点击和翻页/tutorialdetail-1/ajaxdjfy_7.html步骤1:创建百家号文章采集任务1)进入主界面,选择“自定义模式”2)将要采集的网址URL复制粘贴到网站输入框中,点击“保存网址”步骤2:创建翻页循环1)在页面右上角,打开“流程”,以展现出“流程设计器”和“定制当前操作”两个板块。
网页打开后,默认显示“热门”文章。
下拉页面,找到并点击“查看更多”按钮,在操作提示框中,选择“循环点击单个元素”,以创建一个翻页循环由于此网页涉及Ajax技术,我们需要进行一些高级选项的设置。
选中“点击元素”步骤,打开“高级选项”,勾选“Ajax加载数据”,设置时间为“2秒”注:AJAX即延时加载、异步更新的一种脚本技术,通过在后台与服务器进行少量数据交换,可以在不重新加载整个网页的情况下,对网页的某部分进行更新。
表现特征:a、点击网页中某个选项时,大部分网站的网址不会改变;b、网页不是完全加载,只是局部进行了数据加载,有所变化。
验证方式:点击操作后,在浏览器中,网址输入栏不会出现加载中的状态或者转圈状态。
2)观察网页,我们发现,通过点击“查看更多”按钮,页面可以无限加载。
自媒体文章采集器使用方法在这个自媒体时代,人人都是撰稿人。
而要写的一手好文章,除非天资聪颖,各种妙语信手拈来,否则前期的资料积累是必不可少的。
参考其他人的文章,去其糟粕留其精华归吾所用。
可谓提升自己文章之捷径。
而又应如何快速大量的获取到他人文章呢?这时网页采集器就必不可少了!让我们能快速搜集各个平台上的自媒体文章。
以下是一个使用八爪鱼采集网站文章的完整示例,示例中采集的是在搜狗微信这个网站上,搜索关键词“八爪鱼大数据”后出现的结果文章的标题、文章关键词、文章部分内容展示、所属公众号、发布时间、文章URL等字段数据。
采集网站:/步骤1:创建采集任务1)进入主界面,选择“自定义模式”自媒体文章采集器使用步骤图12)将要采集的网址URL复制粘贴到网站输入框中,点击“保存网址”自媒体文章采集器使用步骤图2步骤2:创建翻页循环1)在页面右上角,打开“流程”,以展现出“流程设计器”和“定制当前操作”两个板块。
点击页面中的文章搜索框,在右侧的操作提示框中,选择“输入文字”自媒体文章采集器使用步骤图32)输入要搜索的文章信息,这里以搜索“八爪鱼大数据”为例,输入完成后,点击“确定”按钮自媒体文章采集器使用步骤图43)“八爪鱼大数据”会自动填充到搜索框,点击“搜文章”按钮,在操作提示框中,选择“点击该按钮”自媒体文章采集器使用步骤图54)页面中出现了“八爪鱼大数据”的文章搜索结果。
将结果页面下拉到底部,点击“下一页”按钮,在右侧的操作提示框中,选择“循环点击下一页”自媒体文章采集器使用步骤图6步骤3:创建列表循环并提取数据1)移动鼠标,选中页面里第一篇文章的区块。
系统会识别此区块中的子元素,在操作提示框中,选择“选中子元素”自媒体文章采集器使用步骤图72)继续选中页面中第二篇文章的区块,系统会自动选中第二篇文章中的子元素,并识别出页面中的其他10组同类元素,在操作提示框中,选择“选中全部”自媒体文章采集器使用步骤图83)我们可以看到,页面中文章区块里的所有元素均被选中,变为绿色。
采集文章内容
采集文章内容需要使用爬虫技术,通过编写程序来抓取网页上的文章,并从中提取所需的信息。
以下是一些采集文章内容的基本步骤:
1. 选择目标网站:确定要采集文章内容的网站,可以是一个新闻网站、博客、论坛等。
2. 分析网页结构:使用开发者工具(如Chrome的开发者工具)来查看网
页的源代码,了解网页的结构和文章内容所在的HTML标签。
3. 编写爬虫程序:根据网页结构编写爬虫程序,使用Python等编程语言来发送HTTP请求、解析网页内容、提取文章信息等。
4. 提取文章内容:使用正则表达式、BeautifulSoup等工具来解析网页内容,提取出所需文章的信息,如标题、正文、作者、发布时间等。
5. 存储和处理数据:将提取出的文章内容存储到数据库或文件中,并可以使用自然语言处理技术对文章进行进一步的处理和分析。
需要注意的是,采集文章内容需要遵守法律法规和网站的使用协议,尊重原创版权,不要侵犯他人的权益。
同时,采集过程中也要遵守robots协议,
不要频繁访问目标网站,以免对网站的正常运行造成影响。
自媒体文章采集
自媒体文章采集是通过搜集和整理各种信息素材,撰写原创文章的一个过程。
这一方法已经成为许多自媒体从业者广泛采用的方式之一。
采集文章时,需要注意不得出现任何网址、超链接和电话等直接的联系方式。
采集文章的目的在于为读者提供有价值的信息和观点。
在撰写过程中,我们应该注重信息的准确性和可靠性。
不仅要从多个渠道获取素材,还要进行筛选和整理,确保所使用的素材来源可靠,并且确保所呈现的信息是客观和全面的。
在撰写文章时,可以引用一些专家观点和研究数据,以增加文章的权威性和可信度。
但是,要注意不得直接引用他人的文字,而应该给出引用来源,并以自己的语言进行表达和解读。
此外,在采集文章的过程中,还需要注意保护知识产权。
不得滥用他人的创作成果,不得侵犯他人的版权和相关权益。
尊重原创作者的权益,是维护自媒体行业良好秩序的基本原则之一。
总之,自媒体文章的采集需要遵循准确、客观、全面的原则,同时尊重知识产权和作者权益。
只有这样,我们才能提供高质量、有价值的自媒体内容,满足读者的需求。
UC头条文章采集-文本+图片
UC 头条是UC浏览器团队潜力打造的新闻资讯推荐平台,拥有大量的新闻资讯内容,并通过阿里大数据推荐和机器学习算法,为广大用户提供优质贴心的文章。
很多用户可能有采集UC头条文章采集的需求,这里采集了文章的文本和图片。
文本可直接采集,图片需先将图片URL采集下来,然后将图片URL批量转换为图片。
本文将采集UC头条的文章,采集的字段为:标题、发布者、发布时间、文章内容、页面网址、图片URL、图片存储地址。
采集网站:https:///
使用功能点:
Xpath
xpath入门教程1
/tutorialdetail-1/xpathrm1.html
xpath入门2
/tutorialdetail-1/xpathrm1.html 相对XPATH教程-7.0版
/tutorialdetail-1/xdxpath-7.html
AJAX滚动教程
/tutorial/ajgd_7.aspx?t=1
步骤1:创建UC头条文章采集任务
1)进入主界面,选择“自定义模式”
2)将要采集的网址URL复制粘贴到网站输入框中,点击“保存网址”
3)在页面右上角,打开“流程”,以展现出“流程设计器”和“定制当前操作”两个板块。
网页打开后,默认显示“推荐”文章。
观察发现,此网页没有翻页按钮,而是通过下拉加载,不断加载出新的内容
因而,我们选中“打开网页”步骤,在高级选项中,勾选“页面加载完成后向下滚动”,滚动次数根据自身需求进行设置,间隔时间根据网页加载情况进行设置,滚动方式为“向下滚动一屏”,然后点击“确定”
(注意:间隔时间需要针对网站情况进行设置,并不是绝对的。
一般情况下,间隔时间>网站加载时间即可。
有时候网速较慢,网页加载很慢,还需根据具体情况进行调整。
具体请看:八爪鱼7.0教程——AJAX滚动教程
步骤2:创建翻页循环及提取数据
1)移动鼠标,选中页面里第一条文章链接。
系统会自动识别相似链接,在操作提示框中,选择“选中全部”
2)选择“循环点击每个链接”
3)系统会自动进入文章详情页。
点击需要采集的字段(这里先点击了文章标题),在操作提示框中,选择“采集该元素的文本”
文章发布时间、文章作者、文章发布时间、文章正文内容采集方法同上。
以下采集的是文章正文
步骤3:提取UC头条文章图片地址
1)接下来开始采集图片地址。
先点击文章中第一张图片,再点击页面中第二张图片,在弹出的操作提示框中,选择“采集以下图片地址”
2)修改字段名称,再点击“确定”
3)现在我们已经采集到了图片URL,接下来为批量导出图片做准备。
批量导出图片的时候,我们想要同一篇文章中的图片放进同一个文件中,文件夹以文章标题命名。
首先,我们选中标题,在操作提示框中,选择“采集该元素的文本”
选中标题字段,点击如图所示按钮
选择“格式化数据”
点击添加步骤
选择“添加前缀”
在如图位置,输入前缀:“D:\UC头条图片采集\”,然后点击“确定”
以同样的方式添加后缀“\”,然后点击“确定”
4)修改字段名为“图片存储地址”,最后展示出的“D:\UC头条图片采集\文章标题”即为图片保存文件夹名,其中“D:\UC头条图片采集\”是固定的,文章标题是变化的
步骤4:修改Xpath
1)选中整个“循环”步骤,打开“高级选项”,可以看到,八爪鱼默认生成的是固定元素列表,定位的是前13篇文章的链接
2)在火狐浏览器中打开要采集的网页并观察源码。
我们发现,通过此条Xpath://DIV[@class='news-list']/UL[1]/LI/DIV[1]/DIV[1]/A,页面中所需的所有文章均被定位了
3)将修改后的Xpath,复制粘贴到八爪鱼中所示位置,然后点击“确定”
步骤5:文章数据采集及导出
1)点击左上角的“保存”,然后点击“开始采集”,选择“启动本地采集”
注:本地采集占用当前电脑资源进行采集,如果存在采集时间要求或当前电脑无法长时间进行采集可以使用云采集功能,云采集在网络中进行采集,无需当前电脑支持,电脑可以关机,可以设置多个云节点分摊任务,10个节点相当于10台电脑分配任务帮你采集,速度降低为原来的十分之一;采集到的数据可以在云上保存三个月,可以随时进行导出操作。
2)采集完成后,会跳出提示,选择“导出数据”,选择“合适的导出方式”,将采集好的数据导出
3)这里我们选择excel作为导出为格式,数据导出后如下图
步骤6:将图片URL批量转换为图片
经过如上操作,我们已经得到了要采集的图片的URL。
接下来,再通过八爪鱼专用的图片批量下载工具,将采集到的图片URL中的图片,下载并保存到本地电脑中。
图片批量下载工具:https:///s/1c2n60NI
1)下载八爪鱼图片批量下载工具,双击文件中的MyDownloader.app.exe文件,打开软件
2)打开File菜单,选择从EXCEL导入(目前只支持EXCEL格式文件)
3)进行相关设置,设置完成后,点击OK即可导入文件
选择EXCEL文件:导入你需要下载图片地址的EXCEL文件
EXCEL表名:对应数据表的名称
文件URL列名:表内对应URL的列名称,在这里为“图片URL”
保存文件夹名:EXCEL中需要单独一个列,列出图片想要保存到文件夹的路径,可以设置不同图片存放至不同文件夹,在这里为“图片存储地址”
可以设置不同图片存放至不同文件夹,在这里我们已经于前期准备好了,同一篇文章中的图片会放进同一个文件中,文件夹以文章标题命名
4)点击OK后,界面如图所示,再点击“开始下载”
5)页面下方会显示图片下载状态
6)全部下载完成后,找到自己设定的图片保存文件夹,可以看到,图片URL 已经批量转换为图片了,且同一篇文章中的图片会放进同一个文件中,文件夹以文章标题命名
本文来自:/tutorialdetail-1/ucnewscj.html
相关采集教程:
新浪博客文章采集:
/tutorialdetail-1/sinablogcj.html
微信公众号热门文章采集(文本+图片):
/tutorialdetail-1/wxcjimg.html
文章采集:
/blog/224-2.html
自媒体文章采集:
/tutorialdetail-1/wyhcj.html
公众号文章采集:
/tutorialdetail-1/wxcjimg.html
今日头条采集:
/tutorialdetail-1/jrtt-7.html
八爪鱼——90万用户选择的网页数据采集器。
1、操作简单,任何人都可以用:无需技术背景,会上网就能采集。
完全可视化流程,点击鼠标完成操作,2分钟即可快速入门。
2、功能强大,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布流、Ajax脚本异步加载数据的网页,均可经过简单设置进行采集。
3、云采集,关机也可以。
配置好采集任务后可关机,任务可在云端执行。
庞大云采集集群24*7不间断运行,不用担心IP被封,网络中断。
4、功能免费+增值服务,可按需选择。
免费版具备所有功能,能够满足用户的基本采集需求。
同时设置了一些增值服务(如私有云),满足高端付费企业用户的需要。