少量数据的统计处理
- 格式:docx
- 大小:7.38 MB
- 文档页数:4

一、单选题(共30小题)1. 下列不属于系统误差性质的是( ) A. 重复性B. 数据很小C. 单向性D. 误差大小基本不变2. 下列不属于系统误差产生原因的是( ) A. 方法不完善B. 试剂纯度不够C. 仪器未经校正D. 操作失误3. 下列分析过程中不会产生系统误差的是( ) A. 沉淀重量法中使用定性滤纸,使最后灰分加大 B. 使用分析天平时,天平零点稍有变动 C. 试剂中含有少量的被测组分D. 以含量为99%的邻苯二甲酸氢钾作基准物标定碱溶液 4. 下列哪种情况所产生的误差属于系统误差( ) A. 指示剂的变色点与化学剂量点不一致 B. 滴定管读数最后一位估计不准 C. 称样时,砝码数值记错D. 称量过程中,天平零点稍有变动5. 下列哪种措施可用于消除分析方法中系统误差( ) A. 增大试样称量质量 B. 操作时细心、认真 C. 增加测定次数 D. 进行仪器校准6. 下列关于随机误差的论述中不正确的是( ) A. 分析过程中不可避免 B. 正、负误差出现的概率相等 C. 具有单向性D. 由一些不确定的偶然因素造成7. 下述关于随机误差的正态分布曲线的论述中错误的是( ) A. 横坐标x 值等于总体平均值μ时,曲线出现极大值B. 曲线与横坐标之间所夹面积的总和代表所有测量值出现的概率,其值为1C. 标准偏差σ越小,测量值越分散,曲线越平坦D .分布曲线以x=μ点做纵坐标为其对称轴呈镜面对称,说明正负误差出现概率相等 8. 在下列表述中,最能说明偶然误差小的是( ) A. 高精密度 B. 与已知含量的试样多次分析结果的平均值一致 C. 标准偏差大D. 仔细校正所用的天平、容量仪器等9. 下列可用于减小定量分析中偶然误差的方法是( ) A. 校正测定结果B. 进行对照实验C. 增加平行测定次数D. 进行空白实验10. 从精密度就可以断定分析结果可靠的前提是( ) A. 随机误差小B. 系统误差小C. 平均误差小D. 增加平行实验的次数11. n 次测定结果平均值的标准偏差x s 和单次测量结果的标准偏差s x 之间关系的正确表达式是( ) A. n /s s x x =B. n /s s x x =C. n /s s x x =D. x x s s >12. 下列关于置信区间定义,正确的是( )A. 以真值为中心的某一区间包括测定结果的平均值的几率B. 在一定置信度下,以测量值的平均值为中心的包括总体平均值的范围C. 真值落在某一可靠区间的几率D. 在一定置信度下,以真值为中心的可靠范围13. 有两组分析数据,要比较它们的测量精密度有无显著性差异,应采用( ) A. F 检验B. t 检验C. Q 检验D. 格鲁布斯法14. 有一组平行测定的分析数据,要判断其中是否有异常值,可采用( ) A. F 检验B. t 检验C. 方差分析D. 格鲁布斯法15. 对同一试样用两种不同的测量方法进行分析,得到两组数据,若想判断两组数据之间是否存在显著性差异应采用( ) A. u 检验B. t 检验C. F+t 检验D. F 检验16. 用25 mL 移液管移出的溶液体积应记为( ) A. 25 mLB. 25.0 mLC. 25.00 mLD. 25.000 mL17.四位学生用重量法同时对分析纯BaCl 2⋅2H 2O 试剂中Ba 的质量分数各测三次,所得结果及标准偏差如下,其中结果最好的是( )已知:3.244M O H 2BaCl 22=⋅;()3.137Ba Ar = A. 42.55x =;%5.1s = B. 18.56x =;%1.2s = C. 22.56x =;%21.0s =D. 10.55x =;%20.0s =18. 滴定分析中通常要求称量误差≤±0.1%,若分析天平精度为0.1 mg ,则至少应称取多少样品( ) A. 0.1 gB. 0.2 gC.0.05 gD. 1.0 g19. 下列是95%置信度下某试样测量结果的报告,请问哪份报告更为合理( ) A. ()%2.036.25±B. ()%24.036.25±C. ()%243.036.25±D. ()%2432.036.25±20. 下列数值中,有效数字为四位的是( ) A. π=3.141B. pH=10.50C. CaO%=25.30D. 222.3021. 下列数据不是四位有效数字的是( ) A. pH=11.26 B. [H +]=0.1020 C. Cu%=10.26D. [Pb 2+]=12.28×10-4 22. 测得某种新合成的有机酸pKa 为12.35,其Ka 值应表示为( )A. 4.467⨯10-13B. 4.47⨯10-13C. 4.5⨯10-13D. 4⨯10-1323. 已知某溶液的pH 为11.02,其氢离子活度的正确表示为( ) A. 9.550⨯10-12mol ⋅L -1B. 9.55⨯10-12mol ⋅L -1C. 9.5⨯10-12mol ⋅L -1D. 1⨯10-11mol ⋅L -124. 误差的有效数字位数通常为( ) A. 1~2位B. 2~3位C. 四位有效数字D.算出多少就多少 25. 定量分析中,对测定结果误差的要求是( ) A. 越大越好B. 越小越好C. 等于零D. 在允许范围内即可26. 甲乙丙丁四人同时分析一矿物中的含硫量,取样均为3.5 g ,下列哪份报告合理( ) A. 甲:0.04%B. 乙:0.042%C. 丙:0.0421%D. 丁:0.04211%27. 欲测定石英(SiO 2)中的Fe 、Al 、Ca 、Mg 的含量,应采用下列哪组试剂分解试样( ) A. HF+H 2SO 4B. H 2SO 4+HNO 3C. H 2SO 4+H 3PO 4D. HClO 4+HNO 328. 欲进行硅酸盐的全分析,宜采用下列哪种熔剂分解试样( ) A. K 2S 2O 7B. KHSO 4C. Na 2CO 3D. NaHCO 329. 欲测定钢铁中的磷含量,选择下列哪组试剂分解试样最合适( ) A. HClB. HNO 3+H 2SO 4C. H 2SO 4D. H 2SO 4+HCl30. 某组分的质量分数按下式计算而得:s m /M v c w ⋅⋅= ,若c =0.1020±0.0001 mol ⋅L -1,V = 30.02±0.02 mL ,M =50.00±0.01 g ⋅mol -1,m =0.2020±0.0001 g ,则对w 的误差而言( ) A. V 项引入的最大B. c 项引入的最大C. M 项引入的最大D. m 项引入的最大二、填空题(共15小题,30个空)1. 决定正态分布曲线形状的两个参数为:________和________;它们分别反应了测量值的______________________________和______________________________。

统计数据的采集整理与处理方法统计数据的采集、整理与处理方法在各个领域中扮演着重要的角色,它们为研究人员、决策者以及企业提供了有力的支持。
本文将介绍几种常见的统计数据的采集、整理与处理方法,并探讨它们的优缺点以及适用场景。
一、问卷调查法问卷调查是一种常见的统计数据采集方法,通过向被调查者提出特定问题,收集他们的意见和观点。
问卷调查既可以是纸质问卷,也可以是在线调查。
在实施问卷调查时,应注意设计合理的问题,并确保样本的代表性。
问卷调查的优点是能够快速收集大量的数据,但缺点是容易受到被调查者主观因素的影响,结果可能不够客观。
二、抽样调查法抽样调查法是一种通过对部分样本进行研究,推断总体特征的方法。
抽样调查需要根据目标总体的特点来选择合适的抽样方法,常见的抽样方法包括简单随机抽样、分层抽样和整群抽样等。
抽样调查的优点是能够通过有限的样本获得总体特征,并减少成本和时间,但也存在样本偏差的风险。
三、观察法观察法是通过观察和记录来收集统计数据的方法。
观察法分为实验观察和非实验观察两种形式。
实验观察是在控制条件下对被观察对象进行观察,非实验观察是在自然条件下进行观察。
观察法的优点是能够直接观察对象的行为和现象,但也受到观察者主观因素和环境变量的影响。
四、文献资料法文献资料法是通过收集、整理和分析已有的文献材料来获取统计数据的方法。
文献资料可以是书籍、论文、报告、统计年鉴等,通过对文献资料的综合分析和归纳总结,可以得出有关统计数据的结论。
文献资料法的优点是可以利用已有的资源进行分析,但也面临数据更新不及时和数据可信度的问题。
五、统计软件和工具随着计算机技术的发展,统计软件和工具成为统计数据采集、整理与处理的重要工具。
常见的统计软件包括SPSS、Excel、R等,它们提供了丰富的统计分析方法和数据处理函数,可以有效地处理大规模数据和进行复杂的统计计算。
使用统计软件和工具的优点是提高了工作效率和准确性,但也需要熟悉相应的软件操作和统计方法。

统计学中缺失数据的处理方法在统计学中,数据的完整性对于研究结果的准确性至关重要。
然而,在实际数据收集和处理过程中,经常会遇到数据缺失的情况。
数据缺失可能是由于调查对象未提供相关信息、记录错误、设备故障等原因造成的。
如何有效地处理缺失数据,成为统计学研究中一个重要的问题。
本文将介绍统计学中常用的几种处理缺失数据的方法。
一、删除法删除法是最简单直接的缺失数据处理方法之一。
当数据中存在缺失值时,可以选择直接删除缺失值所在的行或列。
这样做的好处是简单快捷,不会对原始数据进行修改,但缺点是可能会造成数据量的减少,丢失了一部分信息,从而影响统计结果的准确性。
二、均值、中位数、众数插补法均值、中位数、众数插补法是一种常用的缺失数据处理方法。
对于数值型数据,可以用整个变量的均值、中位数或众数来替代缺失值;对于分类变量,可以用出现频率最高的类别来替代缺失值。
这种方法的优点是简单易行,不会改变原始数据的分布特征,但缺点是可能会引入一定的偏差。
三、最近邻插补法最近邻插补法是一种基于样本相似性的缺失数据处理方法。
该方法的思想是找到与缺失样本最相似的样本,然后用这些样本的观测值来插补缺失值。
这种方法的优点是能够更好地保留原始数据的特征,缺点是对样本相似性的定义和计算比较主观,可能会引入较大的误差。
四、回归插补法回归插补法是一种基于回归分析的缺失数据处理方法。
该方法的思想是利用其他变量的信息来预测缺失变量的取值。
通过建立回归模型,利用已有数据对缺失值进行估计。
这种方法的优点是能够利用其他变量之间的相关性来填补缺失值,缺点是对模型的选择和拟合要求较高。
五、多重插补法多重插补法是一种结合模型建立和随机抽样的缺失数据处理方法。
该方法的思想是通过多次模拟,生成多个完整数据集,然后对这些数据集进行分析,最后将结果进行汇总。
多重插补法能够更好地反映数据的不确定性,提高了数据处理的准确性。
六、EM算法EM算法是一种迭代优化算法,常用于缺失数据的处理。



第3章分析化学中的误差与数据处理一、选择题1.下列叙述错误的是()A.误差是以真值为标准的,偏差是以平均值为标准的,实际工作中获得的所谓“误差”,实质上仍是偏差B.对某项测定来说,它的系统误差大小是不可测量的C.对偶然误差来说,大小相近的正误差和负误差出现的机会是均等的D.标准偏差是用数理统计方法处理测定的数据而获得的2.四位学生进行水泥熟料中SiO2 , CaO, MgO, Fe2O3 ,Al2O3的测定。
下列结果(均为百分含量)表示合理的是()A.21.84 , 65.5 , 0.91 , 5.35 , 5.48 B.21.84 , 65.50 , 0.910 , 5.35 , 5.48C.21.84 , 65.50 , 0.9100, 5.350 , 5.480 D.21.84 , 65.50 , 0.91 , 5.35, 5.483.准确度和精密度的正确关系是()A.准确度不高,精密度一定不会高B.准确度高,要求精密度也高C.精密度高,准确度一定高D.两者没有关系4.下列说法正确的是()A.精密度高,准确度也一定高B.准确度高,系统误差一定小C.增加测定次数,不一定能提高精密度D.偶然误差大,精密度不一定差5.以下是有关系统误差叙述,错误的是()A.误差可以估计其大小B.误差是可以测定的C.在同一条件下重复测定中,正负误差出现的机会相等D.它对分析结果影响比较恒定6.滴定终点与化学计量点不一致,会产生()A.系统误差B.试剂误差C.仪器误差D.偶然误差7.下列误差中,属于偶然误差的是()A.砝码未经校正B.容量瓶和移液管不配套C.读取滴定管读数时,最后一位数字估计不准D.重量分析中,沉淀的溶解损失8.可用于减少测定过程中的偶然误差的方法是()A.进行对照试验B.进行空白试验C.进行仪器校准D.增加平行试验的次数9.下列有效数字位数错误的是()A.[H+]=6.3×10-12mol/L (二位) B.pH=11.20(四位)C.CHCl=0.02502mol/L (四位) D.2.1 (二位)10.由计算器算得9.250.213341.200100⨯⨯的结果为0.0164449。

数据统计处理的基本步骤
数据统计处理的基本步骤如下:
1. 确定问题和目标:确定需要解决的问题和所希望达到的目标,明确需要统计的数据。
2. 收集数据:收集相关的原始数据,可以通过观察、实验、调查等方式获取数据。
3. 数据清理和整理:对收集到的数据进行清理和整理,包括去除错误和缺失值、处理异常值等。
4. 数据描述和总结:对数据进行描述性统计分析,包括计算数据的中心趋势、离散程度、分布等,可以使用均值、中位数、标准差、频数分布等指标进行描述。
5. 数据可视化:通过可视化手段绘制图表,直观地展示数据的特征和分布,如柱状图、折线图、饼图等。
6. 数据分析和解释:对数据进行进一步的分析和解释,根据问题和目标使用适当的统计方法进行推断统计和假设检验,例如相关分析、回归分析、ANOVA等。
7. 结果报告和解读:根据分析结果撰写报告,对结果进行解读和解释,并给出相应的结论和建议。
8. 结果验证和反馈:对统计结果进行验证,评估统计方法的有
效性和可靠性,并及时反馈结果给相关人员,以便后续决策和调整。

数据的统计处理和解释正态样本离群值的判断和处理数据的统计处理和解释可以使用各种方法,包括描述统计、概率分布拟合和假设检验等。
下面是一些常见的方法和技术。
1. 描述统计:描述统计是一种简单但有效的数据统计处理方法。
它包括计算样本的均值、中位数、标准差和百分位数等指标,以了解数据的集中趋势和分散程度。
2. 概率分布拟合:通过拟合常见的概率分布,如正态分布、指数分布或伽玛分布,可以评估数据是否服从某个特定的分布。
如果数据的分布明显偏离所拟合的分布,可能存在离群值。
3. 箱线图:箱线图是一种可视化工具,用于显示数据的分布情况和离群值。
它通过绘制数据的最小值、最大值、中位数和四分位数等统计量,可以显示出数据的异常值。
4. Grubbs' test:格拉布斯(Grubbs)检验是一种常用的离群值检测方法。
它基于假设,即在正态样本中,离群值的概率较低。
通过计算样本中个别值与样本均值的差异,可以识别离群值。
5. 非参数统计方法:非参数统计方法不依赖于数据的具体分布。
例如,孤立森林(Isolation Forest)算法和DBSCAN(Density-Based Spatial Clustering of Applications with Noise)算法可以用于离群值的检测。
当发现离群值之后,可以考虑以下处理方法:1. 删除离群值:简单粗暴地删除离群值,可能导致数据的信息损失,因此需要慎重考虑。
删除离群值可能会影响样本的分布和模型的表现。
2. 替换离群值:可以将离群值替换为合理的值,例如使用极值替代、中位数或均值替代。
根据数据的背景和特点,选择合适的替代方法。
3. 离群值分析:对离群值进行详细的分析和研究,确定它们是否是数据收集或处理中的错误。
如果不是错误,离群值可能包含有价值的信息,可以进一步进行研究。
需要注意的是,离群值的处理取决于具体的数据和分析目的。
在处理离群值之前,应该对数据的背景和特点进行充分的了解,并结合领域知识和实际需求进行判断和处理。

如何进行科学合理的数据处理和统计分析在进行科学合理的数据处理和统计分析时,需要遵循一系列步骤和方法,以确保数据的准确性和可靠性。
以下将介绍如何进行科学合理的数据处理和统计分析。
一、数据处理步骤1. 数据收集:收集与研究主题相关的原始数据。
可以通过实地观察、实验设计、问卷调查等方式获取数据。
2. 数据清洗:对收集到的数据进行整理和筛选,过滤掉异常数据、缺失数据或错误的数据。
确保数据的完整性和一致性。
3. 数据转换:将原始数据转换成可用于分析的格式,包括数值化、标准化、编码等操作。
确保数据的可比性和一致性。
4. 数据归类:根据研究目的和变量特征,将数据进行分类和分组,便于后续的统计分析。
5. 数据存储:将清洗和转换后的数据保存在适当的媒介中,如电子表格、数据库等,方便后续的统计分析。
二、统计分析方法1. 描述性统计分析:通过计算数据的中心趋势(如平均值、中位数、众数)、离散程度(如方差、标准差)和分布形态等,对数据进行描述和总结。
2. 探索性数据分析(EDA):通过数据可视化(如散点图、箱线图、直方图)等方法,发现数据之间的关系和趋势,并提出初步的假设和推断。
3. 推断统计分析:通过对样本数据进行假设检验、置信区间估计和相关性分析等方法,对总体或群体的特征进行推断和判断。
4. 预测分析:使用回归分析、时间序列分析等方法,对未来的数据趋势进行预测和预估。
5. 实证研究:通过实验设计和调查分析等方法,验证研究假设并得出科学结论。
三、注意事项1. 数据的采样和样本选择要具有代表性,避免选择偏倚导致的扭曲结果。
2. 合理选择统计方法和模型,避免过度拟合或欠拟合的情况发生。
3. 在进行假设检验时,要明确研究的假设、显著性水平和统计指标的选择,以充分判断研究结果的可靠性。
4. 需要注意数据的聚集效应等问题,避免在分析中出现不科学的关联性。
5. 在报告或论文中,应清晰地描述数据处理和统计方法的步骤和过程,以及分析的结果和结论。

统计数据处理的基本方法统计数据处理是指对收集到的数据进行整理、分析和解释的过程。
在各个领域中,统计数据处理都是非常重要的,它能够为我们提供有关事物的详细信息和洞察力。
本文将介绍统计数据处理的基本方法,以帮助读者更好地理解和应用这些方法。
1. 数据收集统计数据处理的第一步是收集数据。
数据可以通过各种方式收集,包括调查问卷、实验记录、观察数据等。
在收集数据时,我们应该确保数据的准确性和完整性,以便后续的处理和分析。
2. 数据整理一旦数据收集完毕,接下来的步骤是对数据进行整理。
数据整理包括数据录入、删除重复数据、处理缺失数据等。
在这个阶段,我们还可以进行数据的规范化处理,以确保数据的一致性和可比性。
3. 描述性统计描述性统计是对数据进行总结和描述的方法。
通过描述性统计,我们可以计算数据的中心趋势(例如平均值、中位数、众数)、数据的离散程度(例如标准差、方差)以及数据的分布情况(例如直方图、箱线图)。
描述性统计能够帮助我们对数据进行初步的分析和理解。
4. 探索性数据分析探索性数据分析是一种通过图表和可视化方法来发现数据之间关系和模式的方法。
通过绘制散点图、折线图、柱状图等图形,我们可以更好地理解数据之间的相关性和趋势。
探索性数据分析有助于发现隐藏在数据背后的信息和规律。
5. 参数估计与假设检验参数估计和假设检验是统计推断的重要方法。
参数估计是通过样本数据来推断总体参数的值,比如使用样本均值来估计总体均值。
而假设检验则是通过样本数据来评估一个关于总体参数的假设是否成立。
参数估计和假设检验能够帮助我们从样本数据中得出对总体的推断。
6. 数据分析软件的应用在现代统计数据处理中,常常使用专业的数据分析软件来处理和分析数据。
常见的数据分析软件包括SPSS、R、Python等。
这些软件提供了丰富的统计函数和图形功能,能够更高效地进行数据处理和分析。
熟练掌握数据分析软件的使用对于统计数据处理至关重要。
总结:统计数据处理是对收集到的数据进行整理、分析和解释的过程。
临床试验中的数据清理与统计分析技巧临床试验是评估新药物或治疗方法的可行性和有效性的重要步骤。
数据的准确性和可靠性对于试验结果的解释至关重要。
数据清理和统计分析是临床试验中不可或缺的环节,本文将介绍一些数据清理和统计分析的技巧。
一、数据清理技巧1. 缺失值处理:在临床试验中,由于各种原因,可能存在一些缺失值。
处理缺失值的方法包括删除有缺失值的观测值、对缺失值进行插补、使用合适的统计方法处理。
需要根据实际情况进行选择,保证数据的完整性和准确性。
2. 异常值检测与处理:临床试验中,可能会出现一些异常值,这些异常值可能会对试验结果产生不良影响。
因此,需要对数据进行异常值的检测与处理。
可以使用统计方法,如箱线图、Z-score等,对数据进行筛选和排除。
3. 数据格式转换:临床试验中收集的数据可能存在不同的格式,如日期、文本、数字等。
在进行统计分析之前,需要对数据进行格式转换,确保数据的一致性和可比性。
4. 数据标准化:为了方便比较和分析,可能需要对不同量纲的数据进行标准化处理。
常见的标准化方法包括Z-score标准化、最小-最大值标准化等。
二、统计分析技巧1. 描述性统计分析:通过计算均值、中位数、标准差、百分位数等指标,可以对试验数据进行描述性统计分析,了解数据的分布和变异情况。
2. 推断统计分析:通过假设检验、置信区间、回归分析等方法,可以对试验数据进行推断性统计分析,判断变量之间的关系和进行统计推断。
3. 生存分析:对于临床试验中的生存数据,可以使用生存分析方法,如Kaplan-Meier曲线、Cox比例风险模型等,评估生存数据的生存率和相关因素。
4. 多变量分析:在临床试验中,常存在多个相关变量,为了探索变量之间的关系和确定影响结果的因素,可以进行多变量分析,如多元回归分析、方差分析等。
5. 敏感性分析:临床试验的结果可能受到多种因素的影响,为了评估结果的稳健性和一致性,可以进行敏感性分析,对关键参数进行变化和测试。
统计数据的收集整理与处理方法统计数据在各个领域中起着重要的作用,可以帮助人们了解问题的本质、发现问题的规律,并做出科学的决策。
然而,要准确地收集、整理和处理统计数据并不是一项容易的任务。
下面将介绍几种常用的统计数据的收集、整理和处理方法。
一、统计数据的收集方法1.问卷调查问卷调查是一种常见的统计数据收集方法,可以通过编制问卷并发放给目标受众来获取数据。
问卷调查可以通过面对面的访谈、电话调查或在线调查等方式进行。
在设计问卷时,需要确保问题的准确性、完整性和可理解性,以便受访者可以清楚地理解并提供准确的回答。
2.观察法观察法是通过观察目标群体的行为或现象来收集统计数据的方法。
观察可以是直接观察,也可以是利用摄像机、监测设备等进行间接观察。
在进行观察时,需要明确观察的目的和要收集的数据类型,并制定观察规则和记录方法,以确保数据的准确性和可比性。
3.实验法实验法是通过对不同试验组进行操作或处理,并观察结果的变化来收集统计数据的方法。
在进行实验时,需要明确实验的目的和设定实验组和对照组,并控制其他变量的影响,以便获得可靠的实验结果。
二、统计数据的整理方法1.分类整理分类整理是将收集到的统计数据按照不同的特征或属性进行分类,并将其编码或标记,使数据更易于分析和处理。
分类的方式可以是按照时间、地区、性别、年龄等进行划分,根据需求选择最合适的分类方式。
2.数据清洗数据清洗是指对收集到的统计数据进行去噪、去重、修正等处理,以保证数据的准确性和一致性。
在进行数据清洗时,需要对异常值进行识别和处理,并对缺失值进行填充或删除,以确保数据的完整性和可靠性。
3.数据转换数据转换是将原始数据按照需要的形式进行格式转换和计算,以方便后续的分析和应用。
数据转换可以包括数值的计算、数据的加工和指标的计算等操作。
在进行数据转换时,需要根据需求选择合适的计算方法和转换规则,确保数据的准确性和可靠性。
三、统计数据的处理方法1.描述统计分析描述统计分析是对统计数据进行基本的统计量计算和分析,以了解数据的基本特征和分布规律。
数据的统计分析与处理方法数据统计分析与处理是现代社会中大量数据处理的基础。
这些数据涉及到各个领域,例如商业、医疗、科学等。
统计分析与处理的过程是将数据以统计学的方法进行分析和处理,以获得有用的信息。
本文将介绍数据统计分析与处理的基本概念和各种数据处理技术。
1. 基本概念统计学是一种研究自然和社会现象的科学。
数据处理则是统计学中的一个重要领域。
数据处理的目标是使用数学模型和统计方法对数据进行分析和处理,以获取所需的信息。
数据处理的流程包括数据收集、数据预处理、数据分析和数据可视化等。
数据收集是数据处理中的第一步。
数据可能是通过观察、实验、调查、模拟、日志等方式获得的。
在数据收集过程中,需要确保数据的准确性和完整性。
数据预处理是数据处理的重要步骤。
预处理的目的是清理并处理数据中的错误、异常数据和缺失数据。
数据预处理通常涉及数据清洗、数据抽样、数据变换、数据规范化等。
数据分析是数据处理的核心环节。
数据分析使用统计学和其他方法来解释和汇总数据以获得有用的信息。
常见的数据分析包括描述性统计分析、推论性统计分析、因子分析、回归分析、分类和聚类分析等。
数据可视化是数据处理的最后一步。
数据可视化是将分析后的数据可视化展示,以便于人们理解。
常见的数据可视化工具包括柱状图、折线图、散点图、箱形图、热力图等。
2. 数据处理技术数据处理技术是统计分析与处理的重要工具。
下面列举几种常见的数据处理技术。
(1)假设检验假设检验是通过样本检验推断整体的统计方法,可用于检验样本均值、比例及方差等统计量。
假设检验中包括零假设和备择假设两种假设,如果零假设是错误的,则接受备择假设。
(2)方差分析方差分析是用于比较两个或多个样本均值是否有显著性差异的一种方法。
方差分析可用于直接比较两个组的均值,也可用于比较多个组的均值之间的差异。
(3)回归分析回归分析是一种用于研究两个或多个变量之间关系的统计方法。
回归分析可用于预测或控制一个变量时,对另一个或多个变量的影响。
数据处理中的数据抽样方法引言在大数据时代,海量的数据成为了我们生活中无法避免的一部分。
然而,处理这些海量数据也变得愈加困难和耗时。
为了解决这个问题,数据抽样成为了一种常见的数据处理方法。
本文将探讨数据抽样的定义、原理以及常见的数据抽样方法。
一、数据抽样的定义数据抽样是指从大量的数据中选取一部分数据进行统计、分析和处理的过程。
简单来说,就是通过少量的样本来推断整体数据的特征。
数据抽样在各个领域都有着广泛的应用,如市场调研、医学实验、社会调查等。
通过合理的数据抽样方法,我们可以减少数据处理的时间和成本,同时又能保证所选样本的代表性。
二、数据抽样的原理数据抽样是基于概率论和统计学的原理进行的,主要有以下两个基本假设:1. 总体假设:假设数据样本是从一个大总体中随机抽取的。
这意味着我们假设样本能够代表整体数据的特征,并且每个样本都是相互独立的。
2. 随机性假设:假设每个样本点都是通过随机抽取的方式选取的,从而确保每个样本点都有被选中的机会,避免主观偏好的影响。
三、常见的数据抽样方法1. 简单随机抽样简单随机抽样是最常见也是最简单的抽样方法之一。
它的原理是,每个样本点都有相等的机会被选中。
在实际操作中,可以使用随机数生成器来进行样本点的选取,以确保每个样本点都有同等机会被选中。
2. 系统抽样系统抽样是按一定规则从总体中选择样本的方法。
例如,我们可以按照固定的间隔选取样本,其中第一个样本点是随机选取的。
这种方法既能保证样本的随机性,又能够减少抽样过程的时间和成本。
3. 分层抽样分层抽样将总体划分为几个层次,在每个层次中随机选取样本。
这样做可以确保每个层次都有代表性的样本,从而更准确地反映整体数据的特征。
分层抽样常用于样本中包含多个亚群的情况,比如对不同年龄、性别、地区进行调查。
4. 整群抽样整群抽样是将总体划分为若干群体,然后随机选择其中的几个群体作为样本。
这种方法适用于总体中的群体有明显特点,并且群体内部的差异相对较小。
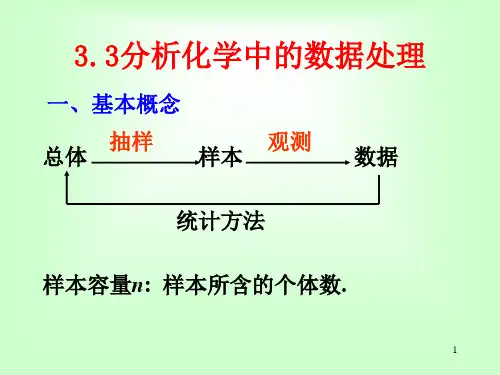
少量数据的统计处理 Revised by Jack on December 14,2020
少量数据的统计处理
t 分布曲线
正态分布是无限次测量数据的分布规律。
当测量数据不多时,其分布服从t 分布规律。
对于有限次测量,用s 代替,用t 代替u ,t 的定义是:
t 分布图如右。
由图可知,t 分布曲线与正态分布曲线相似,纵坐标仍为概率密度,但横
坐标为统计量t 。
t 分布曲线随自由度改变f 而改变,当f 趋近∞时,t 分布趋近正态分布。
置信度(P )表示测定值在x tS μ±范围内的概率,当f ,t 即为u 。
显着性水平()=1-P :表示测定值在x tS μ±范围之外的概率。
t 值与置信度及自由度有关,一般表示为,f t α。
例如:,10 表示置信度为 95%,自由度为 10 时的 t 值。
平均值的置信区间
实际工作中,往往是由样本平均值来估计总体平均值可能存在的区间,根据t 分布可知,
x t
n μ=±
此式表示在一定的置信度下,以平均值x 为中心,包括总体平均值的范围。
此范围称为平均值的置信区间。
选定置信度P ,根据P (或)与f 即可查出t ,f 值,从样本的平均值和标准偏差,即可求出相应的置信区间。
例2:分析某尾矿中铁含量得如下结果:x =%,s=%,n=4,求(1)置信度为95%时平均值的置信区间;(2)置信度为99%时平均值的置信区间。
解:置信度为95%,查表得,3=,那么
15.78 3.1815.780.05%
4
x t
n
μ=±=±⨯
=±
置信度为99%,查表得,3=,那么15.78 5.8415.780.09%
4
x t
n
μ=±=±⨯
=±
对此例可知,置信度越高,置信区间越大。
例3:下列有关置信区间的定义中,正确的是:
a.以真值为中心的某一区间包括测定结果的平均值的几率;
b.在一定置信度时,以测量值的平均值为中心的包括总体平均值的范围;
c.真值落在某一可靠区间的几率;
d.在一定置信度时,以真值为中心的可靠范围。
解:答案为b 。
因为真值是客观存在的,是用有限次的测量的平均值来估计它所在的范围,不能说它落在某一区间的概率为多少,
显着性检验
判断两组分析结果是否存在系统误差,换句话来说,是否存在显着性差异,可用t 检验和F 检验法。
检验
(1)平均值与标准值的比较:为了检验分析方法或者分析人员的分析数据是否存在系统误差,可对标准试样进行若干次分析,然后用t 检验法判断是否存在显着性差异。
具体的做法是:首先按下式计算t 值,
t 然后查出统计值t ,f ;若
t > t 表,则有显着差异,否则无。
(2)两组平均值的比较:为了检验两组数据间是否存在显着性差异,也可使用t 检验法。
设两组数据的平均值分别为12x x 与,标准偏差分别为s 1与s 2, 先用F 检验法检验两组数据的度是否有显着性差异,若无差异,则按下式计算。
然后在一定置信度时,查表得到t 表,t 表中的自由度f =n 1+n 2-2,若t > t 表,则两组数据的平均值有显着差异,否则无。
2.F 检验
F 检验是通过比较两组数据的方差s 2,以确定它们的精密度是否存在显着性差异的方法。
统计量F 的定义为两组数据的方差的比值,大方差为分子,小方
差为分母,即22
s F s =
大小。
若F 计算>F 表,有显着差异,否则无。
例4.用两种不同的方法测得合金中铝的含量,其结果如下:方法1:
11142.340.105x s n ===,,;方法2:22242.440.124x s n ===,,,试判断两种方法是否
存在显着性差异。
解:先用F 检验s 1与s 2有无显着差异:
()()
2
222
0.12 1.44
0.10s F s =
==大计算小
查表得F 表=,因F 计算< F 表,因此 s 1与s 2无显着差异。
再用t 检验法检验两种方法的平均值12x x 与是否存在显着性差异: 查表,当f =5+4-2=7,P=95%,得:t 表=,则 t < t 表,因此,无显着差异。
异常值的取舍
一组分析测量数据中的异常值的取舍,可按统计学方法进行处理。
1.d 4法
依据:随机误差超过3的测量值出现的概率小于%,故这些测量值通常可以舍去。
又因为=,34,即偏差超过4的个别测定值可以舍去。
对于少量实验数据,用s 代替σ。
用d 代替,所以可以粗略地认为,偏差大于d 4的个别测量值可以舍去。
方法特点:简便,不需查表,但不够准确,当此法与其他检验方法结论有悖时,应以其他方法为准。
步骤:(1)剔除异常可疑值后,计算其余数据的平均值x 与平均偏差d ;(2)考察异常可疑值与x 的差是否大于d 4,若d
x x 4>-,则测定值x 应该
舍去,否则保留。
2.格鲁布斯(Grubbs )法
步骤:(1)将数据由小到大排列, x 1,x 2……x n-1,x n 。
求出平均值x 与标准偏差s ;(2)按下式计算统计量T ,
s x x T 1-=
(x 1为可疑值)或s x
x T n
-= (xn
为可疑值);(3)将T 与表值T ,n 比较,若T >T a ,n ,则可疑值舍去,否则保留。
方法特点:可靠性高,计算略为麻烦。
3.Q 检验法
步骤:(1)数据由小到大排列。
x 1,x 2……x n-1,x n ,设x n 或x 1为可疑值;(2)
计算统计量
11Q x x x x n n n --=
-(x n 为可疑值时)或
11
2Q x x x
x n --=(x n 为可疑值时);(3)比较Q 和Q 表的大小,若Q >Q 表,则对应的疑值舍去,否则保留。
例5. 某药物中钴的分析结果为:,, ,μg/g,用d 4法和Grubbs 法判断,在显着性水准为时,数据是否应保留
解:按d 4法判断,先除去,计算平均值和平均偏差得: = 5>4, 所以此数据应舍去。
按Grubbs 法,先求全组数据的平均值和标准偏差:
T <T,n ,所以不应舍去。