Stata_之面板数据处理—长面板
- 格式:ppt
- 大小:188.50 KB
- 文档页数:12


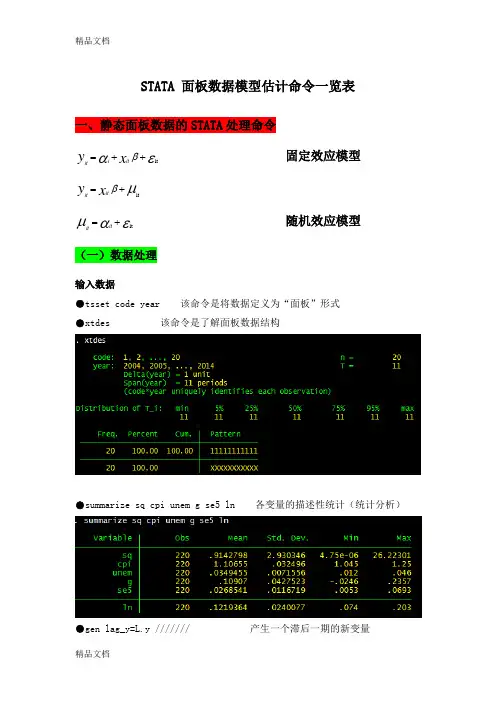
STATA 面板数据模型估计命令一览表 一、静态面板数据的STATA 处理命令εαβit ++=x y it i it 固定效应模型μβit +=x y it itεαμit +=it it 随机效应模型(一)数据处理输入数据●tsset code year 该命令是将数据定义为“面板”形式●xtdes 该命令是了解面板数据结构●summarize sq cpi unem g se5 ln 各变量的描述性统计(统计分析)●gen lag_y=L.y /////// 产生一个滞后一期的新变量gen F_y=F.y /////// 产生一个超前项的新变量gen D_y=D.y /////// 产生一个一阶差分的新变量gen D2_y=D2.y /////// 产生一个二阶差分的新变量(二)模型的筛选和检验●1、检验个体效应(混合效应还是固定效应)(原假设:使用OLS混合模型)●xtreg sq cpi unem g se5 ln,fe对于固定效应模型而言,回归结果中最后一行汇报的F统计量便在于检验所有的个体效应整体上显著。
在我们这个例子中发现F统计量的概率为0.0000,检验结果表明固定效应模型优于混合OLS模型。
●2、检验时间效应(混合效应还是随机效应)(检验方法:LM统计量)(原假设:使用OLS混合模型)●qui xtreg sq cpi unem g se5 ln,re (加上“qui”之后第一幅图将不会呈现) xttest0可以看出,LM检验得到的P值为0.0000,表明随机效应非常显著。
可见,随机效应模型也优于混合OLS模型。
●3、检验固定效应模型or随机效应模型(检验方法:Hausman检验)原假设:使用随机效应模型(个体效应与解释变量无关)通过上面分析,可以发现当模型加入了个体效应的时候,将显著优于截距项为常数假设条件下的混合OLS模型。
但是无法明确区分FE or RE的优劣,这需要进行接下来的检验,如下:Step1:估计固定效应模型,存储估计结果Step2:估计随机效应模型,存储估计结果Step3:进行Hausman检验●qui xtreg sq cpi unem g se5 ln,feest store fequi xtreg sq cpi unem g se5 ln,reest store rehausman fe (或者更优的是hausman fe,sigmamore/ sigmaless)可以看出,hausman检验的P值为0.0000,拒绝了原假设,认为随机效应模型的基本假设得不到满足。

Chp8 Panel Data一直想把看Panel模型时的感悟整理成笔记,但终因懒惰而未能成行。
今天终于下决心开了个头,可遗憾的是,这个开头却是从本章的结尾写起,因为这一部分最容易写。
不过,凡事有了好的开头基本上也算成功一半了,所以后面的整理工作还要有劳各位的督促。
文中的不足还望不吝指出。
8.1简介8.2一般模型8.2.1固定效应模型(Fixed Effect Model)8.2.2随机效应模型(Random Effect Model)8.3自相关性8.4动态Panel Data8.5门槛Panel Data8.6非稳定Panel Data及协整8.7Panel V AR8.8Stata8.0实现在介绍了Panel Data的基本理论后,下面我们介绍如何使用STATA8.0软件包来实现模型的估计。
前面我们已经提到,Panel Data具有如下数据存储格式:company year invest mvalue11951755.94833.011952891.24924.9119531304.46241.7119541486.75593.621951588.22289.521952645.52159.421953641.02031.321954459.32115.531951135.21819.431952157.32079.731953179.52371.631954189.62759.9其中,变量company和year分别为截面变量和时间变量。
显然,通过这两个变量我们可以非常清楚地确定panel data的数据存储格式。
因此,在使用STATA8.0估计模型之前,我们必须告诉它截面变量和时间变量分别是什么,所用的命令为tsset1,命令格式如下:tsset panelvar timevar这里需要指出的是,由于Panel Data本身兼具截面数据和时间序列二者的特性,所以对时间序列进行操作的运算同样可以应用到Panel Data身上。
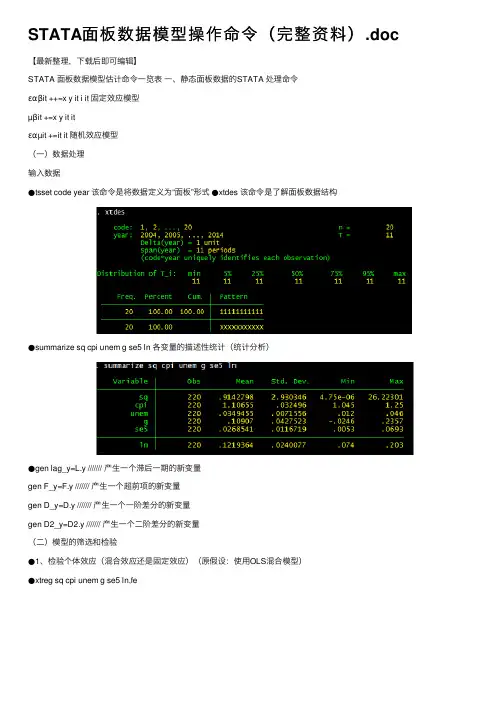
STATA⾯板数据模型操作命令(完整资料).doc 【最新整理,下载后即可编辑】STATA ⾯板数据模型估计命令⼀览表⼀、静态⾯板数据的STATA 处理命令εαβit ++=x y it i it 固定效应模型µβit +=x y it itεαµit +=it it 随机效应模型(⼀)数据处理输⼊数据●tsset code year 该命令是将数据定义为“⾯板”形式●xtdes 该命令是了解⾯板数据结构●summarize sq cpi unem g se5 ln 各变量的描述性统计(统计分析)●gen lag_y=L.y /////// 产⽣⼀个滞后⼀期的新变量gen F_y=F.y /////// 产⽣⼀个超前项的新变量gen D_y=D.y /////// 产⽣⼀个⼀阶差分的新变量gen D2_y=D2.y /////// 产⽣⼀个⼆阶差分的新变量(⼆)模型的筛选和检验●1、检验个体效应(混合效应还是固定效应)(原假设:使⽤OLS混合模型)●xtreg sq cpi unem g se5 ln,fe对于固定效应模型⽽⾔,回归结果中最后⼀⾏汇报的F统计量便在于检验所有的个体效应整体上显著。
在我们这个例⼦中发现F 统计量的概率为0.0000,检验结果表明固定效应模型优于混合OLS模型。
●2、检验时间效应(混合效应还是随机效应)(检验⽅法:LM 统计量)(原假设:使⽤OLS混合模型)●qui xtreg sq cpi unem g se5 ln,re (加上“qui”之后第⼀幅图将不会呈现)xttest0可以看出,LM检验得到的P值为0.0000,表明随机效应⾮常显著。
可见,随机效应模型也优于混合OLS模型。
●3、检验固定效应模型or随机效应模型(检验⽅法:Hausman 检验)原假设:使⽤随机效应模型(个体效应与解释变量⽆关)通过上⾯分析,可以发现当模型加⼊了个体效应的时候,将显著优于截距项为常数假设条件下的混合OLS模型。

STATA⾯板数据模型操作命令讲解STATA ⾯板数据模型估计命令⼀览表⼀、静态⾯板数据的STATA 处理命令εαβit ++=xy itiit固定效应模型µβit +=xy ititεαµit+=itit随机效应模型(⼀)数据处理输⼊数据●tsset code year 该命令是将数据定义为“⾯板”形式●xtdes 该命令是了解⾯板数据结构●summarize sq cpi unem g se5 ln 各变量的描述性统计(统计分析)●gen lag_y=L.y /////// 产⽣⼀个滞后⼀期的新变量gen F_y=F.y /////// 产⽣⼀个超前项的新变量gen D_y=D.y /////// 产⽣⼀个⼀阶差分的新变量gen D2_y=D2.y /////// 产⽣⼀个⼆阶差分的新变量(⼆)模型的筛选和检验●1、检验个体效应(混合效应还是固定效应)(原假设:使⽤OLS混合模型)●xtreg sq cpi unem g se5 ln,fe对于固定效应模型⽽⾔,回归结果中最后⼀⾏汇报的F统计量便在于检验所有的个体效应整体上显著。
在我们这个例⼦中发现F统计量的概率为0.0000,检验结果表明固定效应模型优于混合OLS模型。
●2、检验时间效应(混合效应还是随机效应)(检验⽅法:LM统计量)(原假设:使⽤OLS混合模型)●qui xtreg sq cpi unem g se5 ln,re (加上“qui”之后第⼀幅图将不会呈现) xttest0可以看出,LM检验得到的P值为0.0000,表明随机效应⾮常显著。
可见,随机效应模型也优于混合OLS模型。
●3、检验固定效应模型or随机效应模型(检验⽅法:Hausman检验)原假设:使⽤随机效应模型(个体效应与解释变量⽆关)通过上⾯分析,可以发现当模型加⼊了个体效应的时候,将显著优于截距项为常数假设条件下的混合OLS模型。
但是⽆法明确区分FE or RE的优劣,这需要进⾏接下来的检验,如下:Step1:估计固定效应模型,存储估计结果Step2:估计随机效应模型,存储估计结果Step3:进⾏Hausman检验●qui xtreg sq cpi unem g se5 ln,feest store fequi xtreg sq cpi unem g se5 ln,reest store rehausman fe (或者更优的是hausman fe,sigmamore/ sigmaless)可以看出,hausman检验的P值为0.0000,拒绝了原假设,认为随机效应模型的基本假设得不到满⾜。
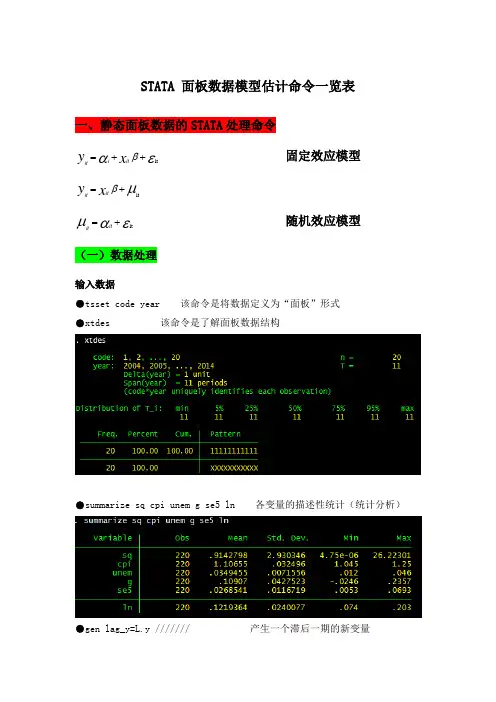
STATA 面板数据模型估计命令一览表 一、静态面板数据的STATA 处理命令εαβit ++=x y it i it 固定效应模型μβit +=x y it itεαμit +=it it 随机效应模型(一)数据处理输入数据●tsset code year 该命令是将数据定义为“面板”形式●xtdes 该命令是了解面板数据结构●summarize sq cpi unem g se5 ln 各变量的描述性统计(统计分析)●gen lag_y=L.y /////// 产生一个滞后一期的新变量gen F_y=F.y /////// 产生一个超前项的新变量gen D_y=D.y /////// 产生一个一阶差分的新变量gen D2_y=D2.y /////// 产生一个二阶差分的新变量(二)模型的筛选和检验●1、检验个体效应(混合效应还是固定效应)(原假设:使用OLS混合模型)●xtreg sq cpi unem g se5 ln,fe对于固定效应模型而言,回归结果中最后一行汇报的F统计量便在于检验所有的个体效应整体上显著。
在我们这个例子中发现F统计量的概率为0.0000,检验结果表明固定效应模型优于混合OLS模型。
●2、检验时间效应(混合效应还是随机效应)(检验方法:LM统计量)(原假设:使用OLS混合模型)●qui xtreg sq cpi unem g se5 ln,re (加上“qui”之后第一幅图将不会呈现) xttest0可以看出,LM检验得到的P值为0.0000,表明随机效应非常显著。
可见,随机效应模型也优于混合OLS模型。
●3、检验固定效应模型or随机效应模型(检验方法:Hausman检验)原假设:使用随机效应模型(个体效应与解释变量无关)通过上面分析,可以发现当模型加入了个体效应的时候,将显著优于截距项为常数假设条件下的混合OLS模型。
但是无法明确区分FE or RE的优劣,这需要进行接下来的检验,如下:Step1:估计固定效应模型,存储估计结果Step2:估计随机效应模型,存储估计结果Step3:进行Hausman检验●qui xtreg sq cpi unem g se5 ln,feest store fequi xtreg sq cpi unem g se5 ln,reest store rehausman fe (或者更优的是hausman fe,sigmamore/ sigmaless)可以看出,hausman检验的P值为0.0000,拒绝了原假设,认为随机效应模型的基本假设得不到满足。

【最新整理,下载后即可编辑】STATA 面板数据模型估计命令一览表 一、静态面板数据的STATA 处理命令εαβit ++=x y it i it 固定效应模型μβit +=x y it itεαμit +=it it 随机效应模型(一)数据处理输入数据●tsset code year 该命令是将数据定义为“面板”形式 ●xtdes 该命令是了解面板数据结构●summarize sq cpi unem g se5 ln 各变量的描述性统计(统计分析)●gen lag_y=L.y /////// 产生一个滞后一期的新变量gen F_y=F.y /////// 产生一个超前项的新变量gen D_y=D.y /////// 产生一个一阶差分的新变量gen D2_y=D2.y /////// 产生一个二阶差分的新变量(二)模型的筛选和检验●1、检验个体效应(混合效应还是固定效应)(原假设:使用OLS混合模型)●xtreg sq cpi unem g se5 ln,fe对于固定效应模型而言,回归结果中最后一行汇报的F统计量便在于检验所有的个体效应整体上显著。
在我们这个例子中发现F统计量的概率为0.0000,检验结果表明固定效应模型优于混合OLS模型。
●2、检验时间效应(混合效应还是随机效应)(检验方法:LM 统计量)(原假设:使用OLS混合模型)●qui xtreg sq cpi unem g se5 ln,re (加上“qui”之后第一幅图将不会呈现)xttest0可以看出,LM检验得到的P值为0.0000,表明随机效应非常显著。
可见,随机效应模型也优于混合OLS模型。
●3、检验固定效应模型or随机效应模型(检验方法:Hausman 检验)原假设:使用随机效应模型(个体效应与解释变量无关)通过上面分析,可以发现当模型加入了个体效应的时候,将显著优于截距项为常数假设条件下的混合OLS模型。
但是无法明确区分FE or RE的优劣,这需要进行接下来的检验,如下:Step1:估计固定效应模型,存储估计结果Step2:估计随机效应模型,存储估计结果Step3:进行Hausman检验●qui xtreg sq cpi unem g se5 ln,feest store fequi xtreg sq cpi unem g se5 ln,reest store rehausman fe (或者更优的是hausman fe,sigmamore/sigmaless)可以看出,hausman检验的P值为0.0000,拒绝了原假设,认为随机效应模型的基本假设得不到满足。

STATA面板数据模型操作命令stata面板数据模型估计命令一览表一、静态面板数据的stata处理命令(一)数据处理输入数据●tssetcodeyear该命令就是将数据定义为“面板”形式●xtdes该命令就是介绍面板数据结构●summarizesqcpiunemgse5ln各变量的描述性统计(统计分析)●genlag_y=l.y///////产生一个滞后一期的新变量genf_y=f.y///////产生一个超前项的新变量gend_y=d.y///////产生一个一阶差分的新变量gend2_y=d2.y///////产生一个二阶差分的新变量(二)模型的甄选和检验●1、检验个体效应(混合效应还是固定效应)(原假设:使用ols混合模型)●xtregsqcpiunemgse5ln,fe对于紧固效应模型而言,重回结果中最后一行汇报的f统计数据量便是检验所有的个体效应整体上明显。
在我们这个例子中辨认出f统计数据量的概率为0.0000,检验结果表明紧固效应模型强于混合ols模型。
●2、检验时间效应(混合效应还是随机效应)(检验方法:lm统计量)(原假设:使用ols混合模型)●quixtregsqcpiunemgse5ln,re(加之“qui”之后第一幅图将不能呈现出)xttest0可以看出,lm检验得到的p值为0.0000,表明随机效应非常显著。
可见,随机效应模型也优于混合ols模型。
●3、检验紧固效应模型or随机效应模型(检验方法:hausman检验)原假设:采用随机效应模型(个体效应与表述变量毫无关系)通过上面分析,可以发现当模型加入了个体效应的时候,将显著优于截距项为常数假设条件下的混合ols模型。
但是无法明确区分feorre的优劣,这需要进行接下来的检验,如下:step1:估算紧固效应模型,存储估算结果step2:估算随机效应模型,存储估算结果step3:展开hausman检验●quixtregsqcpiunemgse5ln,fe eststorefequixtregsqcpiunemgse5ln,reeststorerehausmanfe(或者更优的是hausmanfe,sigmamore/sigmaless)可以看出,hausman检验的p值为0.0000,拒绝了原假设,认为随机效应模型的基本假设得不到满足。

STATA 面板数据模型估计命令一览表一、静态面板数据的STATA 处理命令εαβit ++=xy itiit固定效应模型μβit +=xy ititεαμit+=itit随机效应模型(一)数据处理输入数据●tsset code year 该命令是将数据定义为“面板”形式 ●xtdes 该命令是了解面板数据结构●summarize sq cpi unem g se5 ln 各变量的描述性统计(统计分析)●gen lag_y=L.y /////// 产生一个滞后一期的新变量 gen F_y=F.y /////// 产生一个超前项的新变量gen D_y=D.y /////// 产生一个一阶差分的新变量gen D2_y=D2.y /////// 产生一个二阶差分的新变量(二)模型的筛选和检验●1、检验个体效应(混合效应还是固定效应)(原假设:使用OLS混合模型)●xtreg sq cpi unem g se5 ln,fe对于固定效应模型而言,回归结果中最后一行汇报的F统计量便在于检验所有的个体效应整体上显著。
在我们这个例子中发现F统计量的概率为0。
0000,检验结果表明固定效应模型优于混合OLS模型.●2、检验时间效应(混合效应还是随机效应)(检验方法:LM统计量)(原假设:使用OLS混合模型)●qui xtreg sq cpi unem g se5 ln,re (加上“qui"之后第一幅图将不会呈现)xttest0可以看出,LM检验得到的P值为0.0000,表明随机效应非常显著。
可见,随机效应模型也优于混合OLS模型.●3、检验固定效应模型or随机效应模型(检验方法:Hausman检验)原假设:使用随机效应模型(个体效应与解释变量无关)通过上面分析,可以发现当模型加入了个体效应的时候,将显著优于截距项为常数假设条件下的混合OLS模型。
但是无法明确区分FE or RE的优劣,这需要进行接下来的检验,如下:Step1:估计固定效应模型,存储估计结果Step2:估计随机效应模型,存储估计结果Step3:进行Hausman检验●qui xtreg sq cpi unem g se5 ln,feest store fequi xtreg sq cpi unem g se5 ln,reest store rehausman fe (或者更优的是hausman fe,sigmamore/ sigmaless)可以看出,hausman检验的P值为0.0000,拒绝了原假设,认为随机效应模型的基本假设得不到满足。

stata长格式-回复Stata(统计分析软件)长格式数据处理与分析在进行统计分析时,我们常常需要处理大量的数据。
对于处理长格式数据,Stata提供了一系列功能强大的命令和工具,能够帮助我们轻松地进行数据整理和分析。
本文将一步一步回答与Stata长格式数据处理有关的问题,并详细介绍如何利用Stata进行数据整理和分析。
一、什么是Stata长格式数据?Stata长格式数据(long format data)是指将每个观测对象的多个测量结果排列成一列的数据结构。
在长格式数据中,每行代表一个观测对象的一个测量结果,而每个变量则对应着不同的测量结果。
通过使用长格式数据,我们可以更加方便地进行数据整理和分析。
二、如何将数据转换成长格式?在Stata中,我们可以使用reshape命令将数据从宽格式(wide format)转换成长格式。
假设我们有以下的宽格式数据:id var1 var2 var31 10 20 302 15 25 35我们可以使用如下的命令将其转换成长格式数据:reshape long var, i(id) j(variable)这里,var是指定要转换成长格式的变量列表,i(id)表示标识变量,j(variable)则表示新生成的变量名称。
三、如何对长格式数据进行数据整理?在进行数据整理时,我们可能需要进行数据的排序、重命名、生成新的变量等操作。
Stata提供了一系列的命令和函数,可以方便地进行这些操作。
1. 对数据进行排序:可以使用sort命令对长格式数据进行排序。
例如,如果我们要按照id从小到大的顺序对数据进行排序,可以使用如下命令:sort id2. 重命名变量:可以使用rename命令对变量进行重命名。
例如,如果我们要将变量var1改名为newvar1,可以使用如下命令:rename var1 newvar13. 生成新的变量:可以使用generate命令生成新的变量。
例如,如果我们要生成变量var1的平方变量,可以使用如下命令:generate var1_sq = var1^2四、如何对长格式数据进行分析?在对长格式数据进行分析时,我们可以利用Stata提供的各种统计命令进行统计分析。
面板数据的常见处理面板数据是一种特殊的数据结构,通常用于描述在不同时间和不同实体(例如公司、个人等)上的观察结果。
在处理面板数据时,需要采取一些特殊的方法和技术。
本文将介绍面板数据的常见处理方法,帮助读者更好地理解和分析这种数据结构。
一、面板数据的概述1.1 面板数据的定义:面板数据是一种包含多个实体和多个时间点观察结果的数据结构,通常以二维表格的形式呈现。
1.2 面板数据的特点:面板数据具有时间序列和截面数据的特点,能够捕捉实体间的变化和时间上的趋势。
1.3 面板数据的应用:面板数据在经济学、金融学、社会学等领域广泛应用,用于分析实体间的关系和趋势。
二、面板数据的清洗和准备2.1 缺失值处理:面板数据中常常存在缺失值,需要采取合适的方法填充或删除缺失值。
2.2 异常值处理:对于异常值,需要进行识别和处理,以保证数据的准确性和可靠性。
2.3 数据格式转换:将面板数据转换成适合分析的格式,例如长格式或宽格式,以便进行后续的数据分析和建模。
三、面板数据的描述性统计分析3.1 平均值和标准差:计算面板数据的平均值和标准差,了解数据的中心趋势和离散程度。
3.2 相关系数和协方差:计算面板数据的相关系数和协方差,分析不同实体间的关系和趋势。
3.3 可视化分析:利用图表和图形展示面板数据的分布和趋势,帮助更直观地理解数据的特征和规律。
四、面板数据的面板回归分析4.1 固定效应模型:利用固定效应模型分析面板数据中实体间的固定效应,探讨不同实体对因变量的影响。
4.2 随机效应模型:利用随机效应模型分析面板数据中实体间的随机效应,探讨不同实体对因变量的随机影响。
4.3 混合效应模型:结合固定效应和随机效应模型,分析面板数据中实体间的混合效应,更全面地理解实体间的影响。
五、面板数据的时间序列分析5.1 时间序列趋势分析:分析面板数据中时间序列的趋势和周期性,了解时间上的变化和规律。
5.2 季节性分析:分析面板数据中季节性的影响,探讨不同季节对因变量的影响。
stata长格式-回复Stata长格式: 数据整理与分析引言:在数据分析的过程中,数据的整理和清洗是非常重要的一步。
Stata作为一款强大的统计软件,提供了一系列操作和函数来帮助我们对数据进行整理和分析。
其中,Stata长格式是一种常见的数据格式,它可以更好地适应数据整理的需求。
本文将以Stata长格式为主题,详细介绍如何利用Stata进行数据的整理与分析。
第一部分:Stata长格式的概念及优势(300字)Stata长格式是指将数据按照个体或观察单元的不同组合形式排列的一种数据格式。
在Stata中,长格式的数据通常被分为三个部分:个体特征变量、时间变量和观测值变量。
个体特征变量通常包括个体的ID或编号;时间变量反映出每个观测值的时间点;观测值变量包含了具体的观测指标。
相比较于宽格式,Stata长格式的优势主要体现在以下几个方面:1. 数据整理更加方便:长格式的数据更容易进行增加、删除或调整观测指标的操作,特别适用于处理大规模的数据集。
2. 更加利于分析:长格式的数据更适合进行面板数据分析,可以更好地捕捉个体和时间维度的变异。
3. 适用于多种统计模型:长格式的数据易于配对和对比,可以更好地适用于多重回归模型和纵向数据模型的分析。
第二部分:将数据转化为Stata长格式的方法(500字)在Stata中,将数据转化为长格式通常可以通过reshape命令来实现。
下面我们将具体介绍一下reshape命令的用法和步骤。
首先,我们需要明确将数据转化为长格式的思路和规则。
假设我们有一个宽格式的数据集,其中包含个体编号、时间和观测值。
我们将观测值变量命名为var1、var2等。
第一步:使用reshape long命令将数据集转化为长格式。
reshape long var, i(ID) j(time)在命令中,var是要转化的观测值变量;i(ID)指定个体编号变量;j(time)指定时间变量。
执行该命令后,原始数据将被转化为长格式,新生成的数据将被命名为var。
stata长格式-回复[stata长格式]Stata是一款广泛应用于统计分析的软件,它支持各种数据格式的导入与导出,包括长格式数据。
长格式数据是一种常见的数据结构,特别适用于面板数据和多水平模型的分析。
在这篇文章中,我们将逐步讨论Stata中的长格式数据,从数据导入和整理到数据分析和展示。
第一步:数据导入在Stata中,可以使用多种方法将数据导入为长格式。
一种常用的方法是使用命令`import delimited`。
该命令允许您从CSV或其他文本文件中导入数据,并将其保存为长格式。
例如,您可以使用以下命令导入一个包含个体ID、时间和变量值的CSV文件:import delimited "data.csv", varnames(1) case(2) clear这个命令将根据数据在CSV文件中的列位置自动命名变量,并根据数据在CSV文件中的行形成个体(或时间)标识。
当然,您也可以使用其他选项来自定义导入过程。
第二步:数据整理在导入数据后,您可能需要对数据进行一些整理,以便更好地使用长格式进行分析。
一种常见的数据整理方法是使用命令`reshape`。
该命令允许您从宽格式转换为长格式,或从长格式转换为宽格式。
对于长格式数据,您可以使用以下命令从宽格式转换为长格式:reshape long var, i(ID) j(time)在这个命令中,`var`是宽格式中的变量名称,`ID`是个体标识变量的名称,`time`是时间标识变量的名称。
通过这个命令,Stata会重新组织数据,使每个观测值成为一个单独的观测,并使用个体ID和时间标识变量来区分观测。
第三步:数据分析一旦您将数据整理为长格式,您就可以开始进行各种数据分析。
长格式数据结构非常适合面板数据分析,例如面板回归模型。
在Stata中,您可以使用命令`xtreg`或`xtmixed`来拟合面板回归模型。
这些命令可以针对个体和时间的随机效应进行建模,并报告相应的系数估计和统计显著性。
STATA面板数据模型操作命令讲解STATA 面板数据模型估计命令一览表一、静态面板数据的STATA处理命令y it i xit it 固定效应模型yit x it itit it it 随机效应模型(一)数据处理输入数据●tsset code year该命令是将数据定义为“面板”形式●xtdes该命令是了解面板数据结构● summarize sq cpi unem g se5 ln 各变量的描述性统计(统计分析)● gen lag_y=L.y /////// 产生一个滞后一期的新变量gen F_y=F.y /////// 产生一个超前项的新变量gen D_y=D.y /////// 产生一个一阶差分的新变量gen D2_y=D2.y /////// 产生一个二阶差分的新变量(二)模型的筛选和检验●1、检验个体效应(混合效应还是固定效应)(原假设:使用OLS 混合模型)●xtreg sq cpi unem g se5 ln,fe对于固定效应模型而言,回归结果中最后一行汇报的F 统计量便在于检验所有的个体效应整体上显著。
在我们这个例子中发现F 统计量的概率为 0.0000 ,检验结果表明固定效应模型优于混合 OLS模型。
● 2、检验时间效应(混合效应还是随机效应)(检验方法:LM 统计量)(原假设:使用OLS混合模型)●qui xtreg sq cpi unem g se5( 加上“ qui ”之后第一幅图将不会呈现) ln,re xttest0可以看出, LM检验得到的 P 值为 0.0000 ,表明随机效应非常显著。
可见,随机效应模型也优于混合 OLS模型。
● 3、检验固定效应模型or 随机效应模型(检验方法:Hausman 检验)原假设:使用随机效应模型(个体效应与解释变量无关)通过上面分析,可以发现当模型加入了个体效应的时候,将显著优于截距项为常数假设条件下的混合 OLS模型。
但是无法明确区分 FE or RE 的优劣,这需要进行接下来的检验,如下:Step1 :估计固定效应模型,存储估计结果Step2 :估计随机效应模型,存储估计结果Step3 :进行 Hausman检验●qui xtreg sq cpi unem g se5ln,fe est store fequi xtreg sq cpi unem g se5 ln,reest store rehausman fe ( 或者更优的是hausman fe,sigmamore/ sigmaless)可以看出, hausman检验的 P 值为 0.0000 ,拒绝了原假设,认为随机效应模型的基本假设得不到满足。
STATA面板数据模型估计命令一览表一、静态面板数据的STATA处理命令y it=αi+x itβ+εit固定效应模型y it=x itβ+μitμit=αit+εit随机效应模型(一)数据处理输入数据●tsset code year该命令是将数据定义为“面板”形式●xtdes该命令是了解面板数据结构●summarize sq cpi unem g se5ln各变量的描述性统计(统计分析)●gen lag_y=L.y///////产生一个滞后一期的新变量gen F_y=F.y///////产生一个超前项的新变量gen D_y=D.y///////产生一个一阶差分的新变量gen D2_y=D2.y///////产生一个二阶差分的新变量(二)模型的筛选和检验●1、检验个体效应(混合效应还是固定效应)(原假设:使用OLS混合模型)●xtreg sq cpi unem g se5ln,fe对于固定效应模型而言,回归结果中最后一行汇报的F统计量便在于检验所有的个体效应整体上显著。
在我们这个例子中发现F统计量的概率为0.0000,检验结果表明固定效应模型优于混合OLS模型。
●2、检验时间效应(混合效应还是随机效应)(检验方法:LM统计量)(原假设:使用OLS混合模型)●qui xtreg sq cpi unem g se5ln,re(加上“qui”之后第一幅图将不会呈现) xttest0可以看出,LM检验得到的P值为0.0000,表明随机效应非常显著。
可见,随机效应模型也优于混合OLS模型。
●3、检验固定效应模型or随机效应模型(检验方法:Hausman检验)原假设:使用随机效应模型(个体效应与解释变量无关)通过上面分析,可以发现当模型加入了个体效应的时候,将显著优于截距项为常数假设条件下的混合OLS模型。
但是无法明确区分FE or RE的优劣,这需要进行接下来的检验,如下:Step1:估计固定效应模型,存储估计结果Step2:估计随机效应模型,存储估计结果Step3:进行Hausman检验●qui xtreg sq cpi unem g se5ln,feest store fequi xtreg sq cpi unem g se5ln,reest store rehausman fe(或者更优的是hausman fe,sigmamore/sigmaless)可以看出,hausman检验的P值为0.0000,拒绝了原假设,认为随机效应模型的基本假设得不到满足。