常见统计学错误共32页文档
- 格式:ppt
- 大小:3.16 MB
- 文档页数:32

第十五章医学科研中常见的统计学错误第一节科研设计中的常见错误一、抽样设计二、实验设计中的随机原则三、实验设计中的对照原则四、实验设计中的重复原则五、实验设计中的均衡原则第二节科研数据描述中的常见错误一、统计指标的选取二、统计图表第三节医学科研统计推断中的错误一、t检验二、方差分析三、卡方( 2)检验四、相关与回归分析五、结论表达不当第十五章医学科研中常见的统计学错误医学科研中,研究者关心的研究对象的特征往往具有变异性;如年龄、性别皆相同的人其身高不尽相同、体重、血型等也都存在类似的现象。
同时,由于研究对象往往很多,或者不知到底有多少,或者研究对象不宜全部拿来做研究;所以人们往往借助抽样研究,即从总体中抽取部分个体组成样本,依据对样本的研究结果推断总体的情况。
恰恰是这种变异的存在,以及如何用样本准确推断总体的需求,使得统计学有了用武之地和发展的机遇。
诚然,合理恰当地选用统计学方法,有助于人们发现变异背后隐藏的真面目,即一般规律。
但是,如果采用的统计学方法不当,不但找不到真正的规律,反而可能得出错误的结论,进而影响研究的科学性,甚至会使错误的结论蔓延,造成不良影响。
作为医学工作者,尤其是科研工作者,必须了解当前医学科研中常见的统计学错误,以便更好地开展科研和利用科研成果。
本章借助科研中统计学误用实例,介绍常见的错用情况,以帮助读者避免类似错误的发生。
第一节科研设计中的常见错误统计学是一门重要的方法学,是一门研究数据的收集、整理和分析,从而发现变幻莫测的表面现象之后隐含的一般规律的科学。
医学科研是研究医学现象中隐含规律的科学,包括基础医学研究、临床医学研究和预防医学研究等,不管哪类医学科研都离不开统计学的支持。
要想做好医学科研,必须掌握一定的统计学知识,如总体与样本、小概率原理、资料的类型和分布、科研设计类型、统计分析的主要工作、常用统计方法以及方法的种类和应用条件等,尤其要了解当前医学科研中常见的统计学错误。

医学论文中常用统计分析方法错误大全在医学研究领域,统计分析方法的正确应用对于得出科学、可靠的结论至关重要。
然而,在实际的医学论文中,我们常常能发现各种各样的统计分析方法错误,这些错误不仅影响了研究结果的准确性和可信度,还可能导致错误的临床决策。
下面,我们就来详细梳理一下医学论文中常见的统计分析方法错误。
一、样本量不足样本量的大小直接关系到研究结果的可靠性和普遍性。
如果样本量过小,可能无法准确反映总体的特征,导致统计效能不足,从而得出错误的结论。
例如,在比较两种治疗方法的疗效时,如果每组的样本量只有十几例,那么很可能因为偶然因素而得出错误的差异结论。
二、数据类型错误医学研究中数据类型多种多样,包括计量数据(如身高、体重、血压等)、计数数据(如治愈人数、死亡人数等)和等级数据(如病情的轻、中、重)。
如果对数据类型的判断错误,就会选择错误的统计分析方法。
例如,将本来应该是计数数据的治愈率当作计量数据进行 t 检验,这是不正确的。
三、忽视数据分布许多统计方法都有其适用的数据分布条件。
例如,t 检验和方差分析要求数据服从正态分布。
如果数据不服从正态分布而强行使用这些方法,就会得出错误的结果。
在这种情况下,应该先对数据进行正态性检验,如果不满足正态分布,可以考虑使用非参数检验方法,如秩和检验。
四、多重比较问题在医学研究中,常常需要进行多个组之间的比较。
如果不注意控制多重比较带来的误差,就会增加得出错误阳性结果的概率。
例如,在比较多个药物剂量组的疗效时,如果不进行适当的校正(如 Bonferroni 校正),就可能因为多次比较而错误地认为存在显著差异。
五、相关与回归分析的错误相关分析用于研究两个变量之间的线性关系,但不能得出因果关系。
在医学论文中,有时会错误地将相关关系解释为因果关系。
回归分析中,自变量的选择、模型的拟合度评估等方面也容易出现错误。
例如,没有考虑自变量之间的共线性问题,导致回归结果不准确。
六、生存分析的错误生存分析常用于研究疾病的发生、发展和预后。

常见统计学错误在人类社会发展的过程中,数据的重要性越来越被人们所重视。
统计学作为一门应用于数据处理、分析和解释的学科,被广泛运用于各个领域。
然而,由于统计学的复杂性和数据的多样性,常常会出现一些常见的统计学错误。
本文将会从统计学的角度对一些常见的错误进行分析。
错误一:关联误解许多人将相关性错误地解释为因果性,这是一个常见的误解。
例如,某个人认为他成功的原因是他经常使用的运动饮料,因为他发现当他使用该饮料时,他通常表现出更好的成绩。
然而,这种关联并不代表因果性。
在这种情况下,运动饮料与优秀的表现可能只是因为二者之间存在其他因素的原因。
错误二:回归分析回归分析是一种非常有用的分析方法,可以用来探索变量之间的关系。
但是,如果分析方法不正确,就可能会导致错误的结论。
例如,如果回归模型中使用了错误的自变量或母体数据,甚至丢失了一些因素,那么得到的结果就可能是不准确的。
错误三:样本选择偏差样本选择偏差是指样本失去代表性,不符合总体规律的现象。
这种情况可能会导致结果的不准确,因为样本无法代表总体。
例如,在研究城市居民身体健康的研究中,如果仅仅选择某一小部分正常体型、有规律的情况,而忽略了任何超出这个范围的人,那么这个研究的结果将忽略其他身体健康状况的可能性。
错误四:误差概率统计分析必须包括在结果中发现的误差概率。
虽然有时误差会被忽略,但没考虑误差的影响会导致结果的不确定性和不准确性的增加。
例如,考虑一个零件生产厂家使用的质量控制方法。
如果该厂家仅仅进行一次样本检查,而没有考虑样本选取的偶然性,那么可能无法获得正确的结果。
错误五:推断推断通常用于从一个样本中推广一个总体结论。
但是,如果样本不够大或者不够代表性,那么结果就不能代表总体。
例如,在某一工厂中,如果只从少数员工中调查了病假的问题,那么结果可能并不具有代表性,不能推广到整个员工群体。
总之,正确的统计分析至关重要,结果的准确性直接影响到实际应用的结果。
因此,在进行统计分析时,务必要注意常见的统计学错误,避免这些错误并提高数据分析和结论推断的准确性。

医学论文中常用统计分析方法错误大全在医学研究领域,准确合理地运用统计分析方法对于得出可靠的研究结论至关重要。
然而,在实际的医学论文中,却存在着各种各样的统计分析方法错误,这些错误可能会导致研究结果的偏差,甚至得出错误的结论。
下面,我们就来详细探讨一下医学论文中常见的统计分析方法错误。
一、数据类型判断错误数据类型的正确判断是选择合适统计分析方法的基础。
医学研究中常见的数据类型包括计量资料、计数资料和等级资料。
然而,很多研究者在数据类型判断上出现失误。
例如,将原本应该是计数资料的数据(如疾病的治愈、好转、无效等)当成计量资料进行分析,错误地使用了均值和标准差等统计指标,而应该使用频率和百分比等指标,并采用卡方检验等方法。
二、样本量计算不合理样本量的大小直接影响到研究结果的可靠性和准确性。
一些医学论文在研究设计阶段没有充分考虑样本量的计算,导致样本量过小或过大。
样本量过小,可能会使研究结果缺乏统计学意义,无法检测出真实存在的差异;样本量过大,则会造成资源的浪费,同时增加研究的难度和成本。
正确的样本量计算应该综合考虑研究的设计类型、预期效应大小、检验水准和检验效能等因素。
三、选择错误的统计方法这是医学论文中常见的错误之一。
例如,对于两组独立样本的均数比较,应该使用 t 检验,但如果两组数据的方差不齐,就需要使用校正的 t 检验或者非参数检验方法(如 Wilcoxon 秩和检验)。
然而,很多研究者在这种情况下仍然使用了普通的 t 检验,导致结果不准确。
再比如,对于多组均数的比较,如果方差分析结果有统计学意义,还需要进一步进行多重比较。
但有些研究在这一步没有进行恰当的多重比较方法选择,导致结论不够准确。
四、忽视数据的正态性检验在进行某些统计分析(如 t 检验、方差分析等)时,要求数据服从正态分布。
然而,很多研究者在使用这些方法之前,没有对数据进行正态性检验。
如果数据不服从正态分布,却仍然使用基于正态分布假设的统计方法,就会得出错误的结论。






统计工作中常见错误及其解决方法统计工作是在各个领域中都非常重要的一项工作。
为了能够准确地发现数据中隐藏的规律和信息,统计工作需要严谨的思维和高水平的技能。
然而,统计工作中常见的错误也让许多人头疼。
在2023年,我们希望通过本文来总结和解决统计工作中常见的错误,以便数据分析人员能够更好地处理数据和做出更准确的决策。
一、数据收集错误数据收集是所有其它统计工作的基础。
如果数据存在错误,那么所有后续的统计工作都可能受到影响。
以下是可能会出现的数据收集错误及其解决方法:1.1 数据来源不清晰如果数据来源不清楚,那么无法确定数据的可靠性和有效性。
在确定数据来源时,必须确保来源合法和可靠。
如果数据来源存在问题,那么可能会导致数据的严重偏差。
解决方法:在数据收集时,必须清楚数据来源并对其进行验证。
1.2 数据重复在数据收集过程中,如果数据重复,那么可能会导致数据分析的结果不准确。
同时,如果数据重复严重,那么数据的采样率也会降低。
因此,在数据收集过程中需要尽量避免数据重复。
解决方法:在数据收集过程中,需要有有效的数据去重方法。
例如,可以使用数字指纹等技术来确保数据的唯一性。
1.3 数据缺失在数据收集过程中,可能会出现数据缺失的情况。
如果数据缺失太多,那么可能会导致数据分析的结果不准确,甚至可能导致分析失败。
因此,必须尽量避免数据缺失。
解决方法:在数据收集过程中,必须对缺失的数据进行补充。
例如,可以使用差值法或者统计方法等来处理缺失数据。
二、样本分析错误在统计分析的过程中,经常会使用随机抽样技术来取得样本。
然而,在样本分析过程中,也会有一些错误出现。
以下是可能会出现的样本分析错误及其解决方法:2.1 样本偏差在进行样本分析的过程中,可能会出现样本偏差的情况。
如果样本偏差很大,那么可能会导致分析结果的错误。
解决方法:在进行样本抽取的过程中,需要采用恰当的抽样技术,并确保样本的有效性和充分性。
2.2 样本误差在进行样本分析的过程中,也可能会出现样本误差的情况。
医学论文中常见统计学错误案例分析一、概述在医学研究领域,统计学方法的应用至关重要,它有助于科研人员对复杂数据进行深入的分析与解读,从而得出科学的结论。
由于统计学知识的复杂性和多样性,医学论文中常常会出现各种统计学错误。
这些错误不仅可能影响研究结果的准确性和可靠性,还可能误导读者对研究的理解和评价。
本文旨在通过分析医学论文中常见的统计学错误案例,揭示其产生原因和可能带来的后果,以提高医学科研人员和论文作者在统计学应用方面的准确性和规范性。
常见的医学论文统计学错误包括但不限于样本量计算不当、数据分布误判、统计方法选择错误、假设检验理解偏差、多重共线性问题以及P值解读不当等。
这些错误往往源于对统计学基本概念和方法理解不深入,或是忽视了对数据特征和实际研究问题的综合考量。
通过案例分析,我们可以更直观地了解这些错误在实际研究中的表现形式和潜在影响。
每个案例都将详细剖析错误发生的具体原因,并指出正确的处理方法或避免策略。
这将有助于医学科研人员和论文作者在今后的研究中更加谨慎地应用统计学方法,提高研究质量和学术水平。
本文还将强调加强统计学知识和技能的培训在医学科研中的重要性。
只有具备扎实的统计学基础,才能更好地理解和运用各种统计方法,避免或减少统计学错误的发生。
医学科研人员和论文作者应不断学习和更新统计学知识,提高自己在统计学应用方面的能力和素养。
1. 医学论文中统计学的重要性在医学研究中,统计学扮演着至关重要的角色。
它是确保研究设计合理性、数据收集和分析准确性以及结论可靠性的基石。
通过运用统计学方法,医学研究人员能够系统地评估治疗方法的疗效、疾病的发病机制和预后因素,从而为临床实践和政策制定提供科学依据。
统计学在医学论文中有助于确保研究的内部和外部有效性。
通过运用适当的统计学方法,研究人员可以控制潜在的混杂变量和偏倚,从而提高研究的准确性和可靠性。
这有助于避免由于研究设计不当或数据分析错误而导致的误导性结论。
Chapter2What Can Go Wrong?■ Don’t label a variable as categorical or quantitative without thinkingabout the question you want it to answer. The same variable cansometimes take on different roles.■ Just because your variable’s values are numbers, don’t assume that it’s quantitative. Categories are often given numerical labels. Don’t let that fool you into thinking they have quantitative meaning. Look at thecontext.■ Always be skeptical. One reason to analyze data is to discover the truth.Even when you are told a context for the data, it may turn out that thetruth is a bit (or even a lot) different. The context colors our interpretationof the data, so those who want to influence what you think may slant thecontext. A survey that seems to be about all students mayin fact reportjust the opinions of those who visited a fan website. The question that respondentsanswered may have been posed in a way that influenced their responses.Chapter3Displaying and Summarizing Quantitative DataWhat Can Go Wrong?■ Don’t violate the area principle. This is probably the most common mistake in a graphical display. It is often made in the cause of artistic presentation.Here, for example, are two displays of the pie chart of the Titanicpassengers by clas、A’\‘GN;’{s:Crew Third ClassFirst Class Second Class First Class325Second Class285Third ClassCrew 70688550.0%31.5%26.7%UseMarijuanaUseAlcoholHeavyDrinkingThe one on the left looks pretty, doesn’t it? But showing the pie on a slantviolates the area principle and makes it much more difficult to comparefractions of the whole made up of each class—the principal feature that apie chart ought to show.■ Keep it honest. Here’s a pie chart that displays data on the percentage ofhigh school students who engage in specified dangerous behaviors as reportedby the Centers for Disease Control and Prevention. What’s wrongwith this plot?Try adding up the percentages. Or look at the 50% slice. Does it look right?Then think: What are these percentages of? Is there a “whole” that hasbeen sliced up? In a pie chart, the proportions shown by each slice of thepie must add up to 100% and each individual must fall into only one category.Of course, showing the pie on a slant makes it even harder to detectthe error.A data display should tell a story about the data. To do that, it must speak ina clear language, making plain what variable is displayed, what any axisshows, and what the values of the data are. And it must be consistent in thosedecisions.A display of quantitative data can go wrong in many ways. The most commonfailures arise from only a few basic errors:■ Don’t make a histogram of a categorical variable. Just because thevariable contains numbers doesn’t mean that it’s quantitative. Here’sa histogram of the insurance policy numbers of some workers.It’s not very informative because the policy numbers are just labels.A histogram or stem-and-leaf display of a categoricalvariable makesno sense. A bar chart or pie chart would be more appropriate.■ Don’t look for shape, center, and spread of a bar chart.A bar chart showingthe sizes of the piles displays the distribution of a categorical variable,but the bars could be arranged in any order left to right. Concepts likesymmetry, center, and spread make sense only for quantitative variables.■ Don’t use bars in every display—save them for histograms and barcharts. In a bar chart, the bars indicate how many cases of a categoricalvariable are piled in each category. Bars in a histogram indicate thenumber of cases piled in each interval of a quantitative variable. In bothbar charts and histograms, the bars represent counts of data values. Somepeople create other displays that use bars to representindividual data values.Beware: Such graphs are neither bar charts nor histograms. For example,a student was asked to make a histogram from data showing thenumber of juvenile bald eagles seen during each of the 13 weeks in thewinter of 2003–2004 at a site in Rock Island, IL. Instead, he made this plot:1 2 3 4 5 6 7的方差等于21 2 3 4 5 6的方差等于2.92。
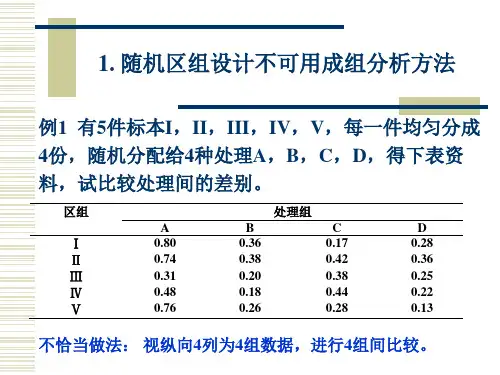
4定量资料统计分析方面存在的统计学错误4.1忽视t检验和方差分析的前提条件4.1.1忽视t检验的前提条件例16原文题目:重症急性胰腺炎并发肝功能不全的临床研究。
实验数据见表5[4]。
原文作者用t检验分析此资料。
请问:这样做正确吗?表5两组患者血清淀粉酶、肌酐和乳酸脱氢酶水平的比较(略)*P<0.05,与重症急性胰腺炎肝功能不全组比较。
对差错的辨析与释疑对表5数据进行方差齐性检验,可发现2组患者的血清淀粉酶和肌酐指标不能满足方差齐性的要求,故不能采用t检验进行分析,须采用相应的非参数检验方法。
4.1.2忽视方差分析的前提条件例17原文题目:川芎嗪对心室快速起搏心力衰竭实验犬心房颤动及心房纤维化的影响。
原作者将健康杂种犬21只,随机分为3组:正常对照组、充血性心力衰竭模型组和川芎嗪治疗组,每组7只[1 3]。
请问:用配对设计定量资料的t检验处理此定量资料合适吗?对差错的辨析与释疑原作者用配对t检验处理此设计下的定量资料是错误的。
此实验分3组,应为单因素三水平设计定量资料,应在检查是否符合方差分析的3个前提条件“独立性”、“正态性”和“方差齐性”后,根据情况选用合适的分析方法。
根据原文陈述,原作者在进行统计分析时,将充血性心力衰竭模型组和川芎嗪治疗组在模型建立之前所测得的血液标本指标,均归入正常对照组进行统计学分析,意在增大正常对照组的样本含量,严格地说,这样做违反了方差分析的“独立”条件。
4.2误用t检验处理均数间的多重比较例18原文题目:姜黄素抑制晶状体上皮细胞增殖的信号转导机制。
原作者实验共分3组:空白对照组、模型组、姜黄素组,实验数据见表6[5]。
统计分析时计量资料均数用x±s表示,组间比较采用t检验。
请问:统计分析方法选用得正确吗?表6姜黄素对重组人表皮生长因子诱导的小牛晶状体上皮细胞增殖细胞内C a2+、c AMP和cGMP浓度的影响(略)**P<0.01,与空白对照组比较;△△P<0.01,与模型组比较。