计量经济学EVIEWS自相关检验与修正
- 格式:doc
- 大小:887.00 KB
- 文档页数:4


eviews时间序列一阶自相关检验命令在EViews中,我们可以使用AR(p)模型来进行时间序列的一阶自相关检验。
AR(p)模型表示自回归模型,其中p表示阶数。
一阶自相关检验是用来确定时间序列数据是否存在自相关性。
自相关是指序列中一个值与其在时间上前一时刻的值之间的相关性。
在时间序列分析中,我们希望序列的值是彼此相互独立的,因此自相关性可能会影响我们对序列的分析和预测。
在EViews中,可以通过以下步骤来进行一阶自相关检验:1.打开EViews软件并导入时间序列数据。
2.在EViews主菜单中选择“Quick/Estimate Equation”(快速估计方程)。
3.在“Equation Specification”(方程规范)对话框中,输入要估计的模型。
例如,如果要进行一阶自相关检验,则可以输入模型“y c ar(1)”。
- “y”表示被解释变量。
- “c”表示常数项。
- “ar(1)”表示自回归项,其中1表示阶数。
4.单击“OK”按钮以估计模型。
5.将结果显示为估计方程的系数,t统计量,R-squared(R平方值)等。
在估计方程后,EViews将为我们提供一阶自相关检验的结果。
重要的统计值包括Jarque-Bera(JB)统计量、ARCH LM检验、DW统计量等。
- Jarque-Bera(JB)统计量是用来检验数据是否服从正态分布。
如果JB统计量的p值小于0.05,则我们可以拒绝原假设,即数据不服从正态分布。
- ARCH LM检验旨在检验序列中是否存在异方差性。
如果ARCH LM 统计量的p值小于0.05,则我们可以拒绝原假设,即序列中存在异方差性。
- Durbin-Watson(DW)统计量是用来检验序列的自相关性。
DW统计量的值介于0和4之间,如果DW值接近于2,则表示序列不存在一阶自相关。
除了上述统计量之外,EViews还提供了其他有关模型估计的信息,包括系数的标准误差、置信区间、F统计量和R平方等。
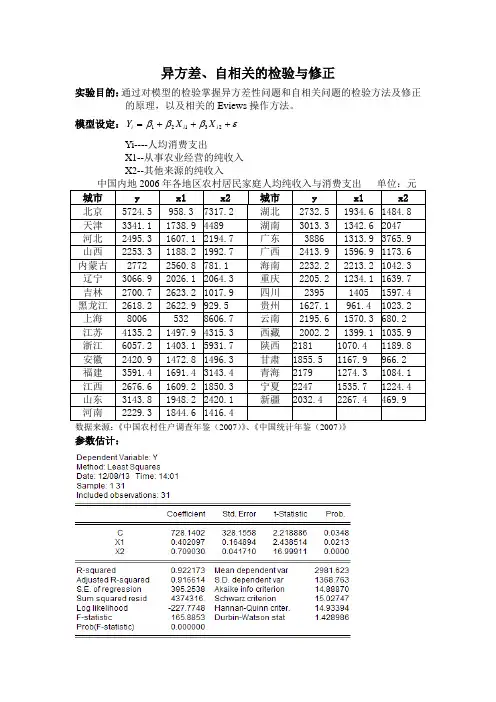
异方差、自相关的检验与修正实验目的:通过对模型的检验掌握异方差性问题和自相关问题的检验方法及修正的原理,以及相关的Eviews 操作方法。
模型设定:εβββ+++=23121i i i X X YYi----人均消费支出X1--从事农业经营的纯收入X2--其他来源的纯收入 中国内地2006年各地区农村居民家庭人均纯收入与消费支出 单位:元 城市 y x1 x2 城市 y x1 x2 北京 5724.5 958.3 7317.2 湖北 2732.5 1934.6 1484.8 天津 3341.1 1738.9 4489 湖南 3013.3 1342.6 2047 河北 2495.3 1607.1 2194.7 广东 3886 1313.9 3765.9 山西 2253.3 1188.2 1992.7 广西 2413.9 1596.9 1173.6 内蒙古 2772 2560.8 781.1 海南 2232.2 2213.2 1042.3 辽宁 3066.9 2026.1 2064.3 重庆 2205.2 1234.1 1639.7 吉林 2700.7 2623.2 1017.9 四川 2395 1405 1597.4 黑龙江 2618.2 2622.9 929.5 贵州 1627.1 961.4 1023.2 上海 8006 532 8606.7 云南 2195.6 1570.3 680.2 江苏 4135.2 1497.9 4315.3 西藏 2002.2 1399.1 1035.9 浙江 6057.2 1403.1 5931.7 陕西 2181 1070.4 1189.8 安徽 2420.9 1472.8 1496.3 甘肃 1855.5 1167.9 966.2 福建 3591.4 1691.4 3143.4 青海 2179 1274.3 1084.1 江西 2676.6 1609.2 1850.3 宁夏 2247 1535.7 1224.4 山东 3143.8 1948.2 2420.1 新疆 2032.4 2267.4 469.9 河南 2229.3 1844.6 1416.4 数据来源:《中国农村住户调查年鉴(2007)》、《中国统计年鉴(2007)》参数估计:估计结果如下:2709030.01402097.01402.728X X Y ++=Λ(2.218) (2.438) (16.999) 922173.02=R D.W.=1.4289 F=165.8853 SE=395.2538实验步骤:一、检查模型是否存在异方差1.图形分析检验(1)散点相关图分析分别做出X1和Y 、X2和Y 的散点相关图,观察相关图可以看出,随着X1、X2的增加,Y 也增加,但离散程度逐步扩大,尤其表现在X1和Y .这说明变量之间可能存在递增的异方差性。

实验四--自相关性的检验及修正
自相关性的检验是研究经济数据中自身序列的行为特征,它可用于识别趋势、判断虚
假反应、探究影响力以及衡量规律的发展变化,以及有助于指导未来政策的制定。
因此,自相关性检验是一项重要的经济学技术,它可以为序列分析获取相关信息,让研究者对特
定事件影响有更深刻的认识。
自相关性检验大概分为两个步骤:也就是统计学检验和模型修正。
统计学检验流程大
致包括参数估计、假设检验和结论。
其中,假设检验可以让研究者判断序列是否有自相关性,而参数估计则可以得到自相关性的大小和方向。
从模型修正的角度来说,研究的目的
是建立一个能够自相关数据的特性并形式化处理的模型,这个模型必须注意记录自相关数
据的自身行为特征。
研究者也可以尝试采用其他方法进行模型修正,比如添加外生变量、增加时间序列滞后期、建立自回归模型和分析突变点等。
自相关性检验和模型修正在实践中都带有一定的挑战,例如原始数据的质量,可能存
在噪声;外生变量的准确性和凝聚力;记录的常数和参数的可靠性;动态变化趋势的准确
性等。
因此,研究者在进行自相关性检验和模型修正时要注意仔细进行检测和修正,以确
保研究结果的可靠性和有效性。
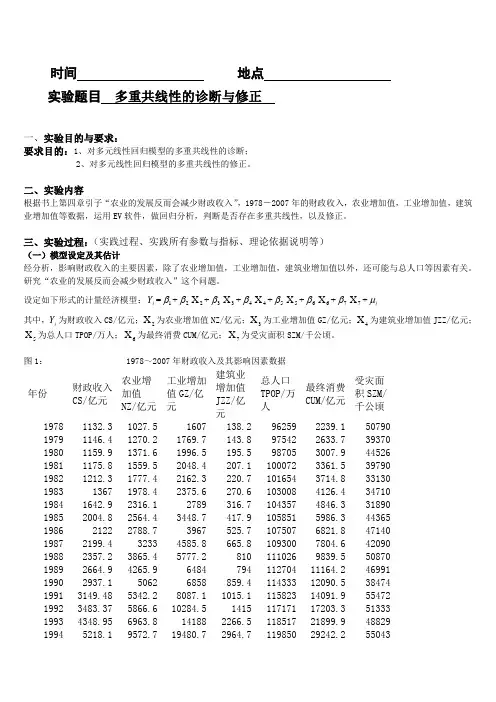
时间 地点 实验题目 多重共线性的诊断与修正一、实验目的与要求:要求目的:1、对多元线性回归模型的多重共线性的诊断;2、对多元线性回归模型的多重共线性的修正。
二、实验内容根据书上第四章引子“农业的发展反而会减少财政收入”,1978-2007年的财政收入,农业增加值,工业增加值,建筑业增加值等数据,运用EV 软件,做回归分析,判断是否存在多重共线性,以及修正。
三、实验过程:(实践过程、实践所有参数与指标、理论依据说明等)(一)模型设定及其估计经分析,影响财政收入的主要因素,除了农业增加值,工业增加值,建筑业增加值以外,还可能与总人口等因素有关。
研究“农业的发展反而会减少财政收入”这个问题。
设定如下形式的计量经济模型:i Y =1β+2β2X +3β3X +4β4X +5β5X +6β6X +7β7X +i μ其中,i Y 为财政收入CS/亿元;2X 为农业增加值NZ/亿元;3X 为工业增加值GZ/亿元;4X 为建筑业增加值JZZ/亿元;5X 为总人口TPOP/万人;6X 为最终消费CUM/亿元;7X 为受灾面积SZM/千公顷。
图1: 1978~2007年财政收入及其影响因素数据年份财政收入CS/亿元 农业增加值NZ/亿元 工业增加值GZ/亿元 建筑业增加值JZZ/亿元总人口TPOP/万人最终消费CUM/亿元受灾面积SZM/千公顷 1978 1132.3 1027.5 1607 138.2 96259 2239.1 50790 1979 1146.4 1270.2 1769.7 143.8 97542 2633.7 39370 1980 1159.9 1371.6 1996.5 195.5 98705 3007.9 44526 1981 1175.8 1559.5 2048.4 207.1 100072 3361.5 39790 1982 1212.3 1777.4 2162.3 220.7 101654 3714.8 33130 1983 1367 1978.4 2375.6 270.6 103008 4126.4 34710 1984 1642.9 2316.1 2789 316.7 104357 4846.3 31890 1985 2004.8 2564.4 3448.7 417.9 105851 5986.3 44365 1986 2122 2788.7 3967 525.7 107507 6821.8 47140 1987 2199.4 3233 4585.8 665.8 109300 7804.6 42090 1988 2357.2 3865.4 5777.2 810 111026 9839.5 50870 1989 2664.9 4265.9 6484 794 112704 11164.2 46991 1990 2937.1 5062 6858 859.4 114333 12090.5 38474 1991 3149.48 5342.2 8087.1 1015.1 115823 14091.9 55472 1992 3483.37 5866.6 10284.5 1415 117171 17203.3 51333 1993 4348.95 6963.8 14188 2266.5 118517 21899.9 48829 19945218.1 9572.7 19480.7 2964.7 11985029242.2550431995 6242.2 12135.8 24950.6 3728.8 121121 36748.2 45821 1996 7407.99 14015.4 29447.6 4387.4 122389 43919.5 46989 1997 8651.14 14441.9 32921.4 4621.6 123626 48140.6 53429 1998 9875.95 14817.6 34018.4 4985.8 124761 51588.2 50145 1999 11444.08 14770 35861.5 5172.1 125786 55636.9 49981 2000 13395.23 14944.7 40036 5522.3 126743 61516 54688 2001 16386.04 15781.3 43580.6 5931.7 127627 66878.3 52215 2002 18903.64 16537 47431.3 6465.5 128453 71691.2 47119 2003 21715.25 17381.7 54945.5 7490.8 129227 77449.5 54506 2004 26396.47 21412.7 65210 8694.3 129988 87032.9 37106 2005 31649.29 22420 76912.9 10133.8 130756 96918.1 38818 2006 38760.2 24040 91310.9 11851.1 131448 110595.3 41091 2007 51321.78 28095 107367.2 14014.1 132129 128444.6 48992利用EV 软件,生成i Y 、2X 、3X 、4X 、5X 、6X 、7X 等数据,采用这些数据对模型进行OLS 回归。

计量经济学论文(eviews分析)我国限额以上餐饮企业营业额的影响因素分析摘要:本文收集了1999年至2009年共11年的相关数据,选取餐饮企业数量、城镇居民人均年消费性支出、全国城镇人口数以及公路里程数作为解释变量构建模型,对我国限额以上餐饮企业营业额的影响因素进行分析。
利用Eviews软件对模型进行参数估计和检验,并加以修正,最后根据模型的最终结果进行经济意义分析,提出自己的看法。
关键词:餐饮企业营业额、影响因素、计量分析一、研究背景近十年来,投资者进入餐饮企业的数量不断增加。
在他们进入一个行业之前,势必要对该行业的营业额、营业利润等进行估计,当这些因素的估计值能够达到他们的预期时,他们才会对其进行投资。
由于餐饮企业的营业额是影响投资者是否进入餐饮业的一个重要因素,对于我国餐饮企业的营业额问题的深入研究就显得尤为必要,这有助于投资者作出合理的决策。
因此,本文进行了对我国限额以上餐饮企业营业额的计量模型研究。
二、变量的选取影响餐饮企业营业额的因素有很多,包括餐饮企业的数量、营业面积、从业人员、城镇居民人均年消费性支出、全国城镇人口数、餐饮企业的平均价格水平及公路里程数(表示交通状况)。
但综合考虑后,本文选取了其中的一部分变量(企业数、城镇居民人均年消费性支出、全国城镇人口数、公路里程数)进行研究,并对各个变量对餐饮企业营业额的影响进行预测。
1.企业数本文认为餐饮企业营业额与餐饮企业的数量有关,并预测两者之间呈正相关。
2.城镇居民人均年消费性支出本文认为餐饮企业营业额与城镇居民人均年消费性支出有关,并预测两者之间呈正相关。
3.全国城镇人口数本文认为餐饮企业营业额与全国城镇人口数有关,并预测两者之间呈正相关。
4.公路里程数本文认为餐饮企业营业额与公路里程数有关,并预测两者之间呈正相关。
三、相关数据本文收集了1999年至2009年共11年的相关数据,包括营业额(单位:亿元)、企业数(单位:个)、人均年消费性支出(单位:元)、全国城镇人口数(单位:万人)以及公路里程数(单位:万公里)。

计量经济学Eview分析教程第一章预备知识一、什么是Eviews(全称Econometric Views)Eviews 软件是QMS(Quantitative Micro Software)公司开发的基于Windows平台下的应用软件,其前身是DOS操作系统下的TSP软件,最新版本是Eviews6.0。
该软件是由经济学家开发,要紧应用在经济学领域,可用于回来分析与推测(regression and forecasting)、时刻序列(Time series)以及横截面数据(cross-sectional data )分析。
与其他统计软件(如EXCEL、SAS、SPSS)相比,Eviews功能优势是回来分析与推测。
二、Eviews工作特点初学者需牢记以下两点。
一、Eviews软件对对象(objects)的具体操作是在Workfile 中进行,也确实是说,假如想用Eviews进行具体的操作,必须先新建一个或打开一个差不多存在在硬盘(或软盘)上的Workfile,在此Workfile中进行输入数据、建筑模型等操作;二、Eviews处理的对象及运行结果都称之为objects,如序列(sereis)方程(equations)、模型(models)、系数(coefficients)等objects。
objects能够不同形式扫瞄(views),比如表格(spreadsheet)、图(graph)、描述统计(descriptive statistics)等,但这些扫瞄(views)不是独立的objects,他们随原变量序列(views)的改变而改变。
假如想将某个扫瞄(views)转换成一个独立的objects,可使用freeze 按钮将该views“冻结”,从而形成一个独立的objects,然后可对其进行编辑或储备。
三、一个作示例在那个地点,我们通过一个简单的回来分析例子来显示一个Eviews过程,不对Eviews 的功能展开讨论,目的是使读者先对Eviews有个概括了解。
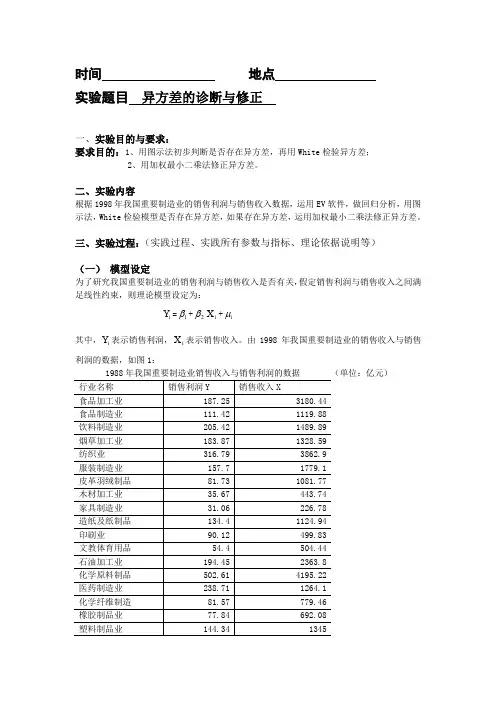
时间 地点 实验题目 异方差的诊断与修正一、实验目的与要求:要求目的:1、用图示法初步判断是否存在异方差,再用White 检验异方差;2、用加权最小二乘法修正异方差。
二、实验内容根据1998年我国重要制造业的销售利润与销售收入数据,运用EV 软件,做回归分析,用图示法,White 检验模型是否存在异方差,如果存在异方差,运用加权最小二乘法修正异方差。
三、实验过程:(实践过程、实践所有参数与指标、理论依据说明等)(一) 模型设定为了研究我国重要制造业的销售利润与销售收入是否有关,假定销售利润与销售收入之间满足线性约束,则理论模型设定为:i Y =1β+2βi X +i μ其中,i Y 表示销售利润,i X 表示销售收入。
由1998年我国重要制造业的销售收入与销售利润的数据,如图1:1988年我国重要制造业销售收入与销售利润的数据 (单位:亿元)(二) 参数估计1、双击“Eviews ”,进入主页。
输入数据:点击主菜单中的File/Open /EV Workfile —Excel —异方差数据2.xls ;2、在EV 主页界面的窗口,输入“ls y c x ”,按“Enter ”。
出现OLS 回归结果,如图2:估计样本回归函数Dependent Variable: Y Method: Least Squares Date: 10/19/05 Time: 15:27 Sample: 1 28Included observations: 28Variable Coefficient Std. Error t-Statistic Prob.C 12.03564 19.51779 0.616650 0.5428 X0.1043930.008441 12.366700.0000R-squared0.854696 Mean dependent var 213.4650 Adjusted R-squared 0.849107 S.D. dependent var 146.4895 S.E. of regression 56.90368 Akaike info criterion 10.98935 Sum squared resid 84188.74 Schwarz criterion 11.08450 Log likelihood -151.8508 F-statistic 152.9353 Durbin-Watson stat1.212795 Prob(F-statistic)0.000000估计结果为: iY ˆ = 12.03564 + 0.104393i X (19.51779) (0.008441) t=(0.616650) (12.36670)2R =0.854696 2R =0.849107 S.E.=56.89947 DW=1.212859 F=152.9353这说明在其他因素不变的情况下,销售收入每增长1元,销售利润平均增长0.104393元。

计量经济学实验报告实验目的:掌握自相关问题的检验以及相关的Eviews的操作方法。
实验内容:消费总量的多少主要有GDP决定。
为了考察GDP对消费总额的影响,可使用如下模型:Yi =1ββ+iX;其中,X表示GDP,Y表示消费总量。
下表列出了中国1990-2000的GDP的X与消费总额Y的统计数据。
年份GDP(X)消费总额(Y)年份GDP(X)消费总额(Y)199018319.5 11365.2 199879003.3 46405.9199121280.4 13145.9 199982673.2 49722.8199225863.7 15952.1 200089112.5 54617.2199334500.7 20182.1 2001 98592.9 58927.4199446690.7 26796 2002 107897.6 62798.5199558510.5 33635 2003 121730.3 67493.5199668330.4 40003.9 2004 142394.2 75439.7199774894.243579.4一、估计回归方程OLS法的估计结果如下:Y=2329.401+0.546950X(1.954322)(36.71110)R2=0.990446,R2=0.989711,SE=2091.475,D.W.=0.478071。
二、进行序列相关性检验(1)图示检验法(2)回归检验法一阶回归检验二阶回归检验e=1.144406e1-t-0.343796e2-t+εtt3)拉格朗日乘数(LM)检验法Breusch-Godfrey Serial Correlation LM Test:F-statistic 29.41781 Probability 0.000038Obs*R-squared 12.63731 Probability 0.001802Test Equation:Dependent Variable: RESIDMethod: Least SquaresC 37.31393 644.3315 0.057911 0.9549X -0.002008 0.009377 -0.214144 0.8344RESID(-1) 1.744086 0.234326 7.442998 0.0000R-squared 0.842487 Mean dependent var 4.37E-12Adjusted R-squared 0.799529 S.D. dependent var 2015.396S.E. of regression 902.3726 Akaike info criterion 16.67111Sum squared resid 8957040. Schwarz criterion 16.85992Log likelihood -121.0333 F-statistic 19.61188Durbin-Watson stat 2.360720 Prob(F-statistic) 0.000101C=37.31393 x=-0.002008 RESID(-1)=1.744086 RESID(-2)= -1.088243 三、序列相关的补救Dependent Variable: DYMethod: Least SquaresDate: 12/17/12 Time: 22:07Sample(adjusted): 1991 2004Included observations: 14 after adjusting endpointsC 2369.885 789.9844 2.999914 0.0111DX 0.465880 0.029328 15.88520 0.0000R-squared 0.954604 Mean dependent var 13875.68Adjusted R-squared 0.950821 S.D. dependent var 5320.847S.E. of regression 1179.971 Akaike info criterion 17.11593Sum squared resid 16707973 Schwarz criterion 17.20722Log likelihood -117.8115 F-statistic 252.3397Durbin-Watson stat 0.521473 Prob(F-statistic) 0.000000(2)科克伦-奥科特法估计模型Dependent Variable: YMethod: Least SquaresDate: 12/17/12 Time: 22:09Sample(adjusted): 1991 2004Included observations: 14 after adjusting endpointsC 55169.41 54542.80 1.011488 0.3335X 0.345292 0.057754 5.978675 0.0001R-squared 0.998047 Mean dependent var 43478.53 Adjusted R-squared 0.997691 S.D. dependent var 19591.16 S.E. of regression 941.3171 Akaike info criterion 16.71985 Sum squared resid 9746856. Schwarz criterion 16.85679 Log likelihood -114.0389 F-statistic 2810.040。
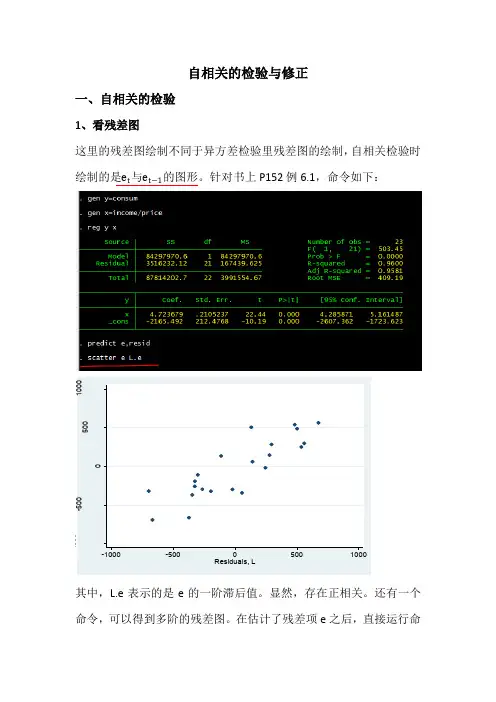
自相关的检验与修正一、自相关的检验1、看残差图这里的残差图绘制不同于异方差检验里残差图的绘制,自相关检验时绘制的是e t 与e t −1的图形。
针对书上P152例6.1,命令如下:其中,L.e 表示的是e 的一阶滞后值。
显然,存在正相关。
还有一个命令,可以得到多阶的残差图。
在估计了残差项e之后,直接运行命R e s i d u a l s令ac e 就可得到下图(ac 为autocorrelation 的缩写):横轴表示的是滞后阶数,阴影部分表示的是相应的置信区间,在上图中,显然一阶滞后是自相关的。
补充:滞后算子L 。
L.x 表示x 的一阶滞后值,L2.x 表示二阶滞后值。
差分算子D 。
D.x 表示x 的一阶差分,D2.x 表示二阶差分。
LD.x 表示一阶差分的一阶滞后值。
需要注意的是,在使用之后算子和差分算子时,一定要事先设定时间变量。
2、DW 检验该方法出现较早,现在已经过时,主要是因为该方法只能检验一阶自相关。
命令:estat dwatson 。
经验上DW 值在1.8---2.2之间接受原假设,不存在一阶自相关。
DW 值接近于0或者接近于4,拒绝原假设,存在一阶自相关。
3、LM检验(BG检验)命令:estat bgodfrey 一阶滞后自相关检验estat bgodfrey,lags(p) P阶滞后自相关检验滞后阶数P的选取最简单的方法就是看自相关图,阴影部分以外的自相关阶数为显著。
二、自相关的处理—广义最小二乘法FGLS命令:prais y x1 x2 x3 该命令对应的是书上P147的(6.33)方法prais y x1 x2 x3,corc 该命令对应的是书上P147的(6.32)方法在自相关检验及处理上,还有比较常用的稳健标准差命令newey以及Q-Test命令,感兴趣的同学可以去查阅相关书籍。

eviews时间序列一阶自相关检验命令摘要:一、引言二、eviews 时间序列一阶自相关检验命令介绍1.语法结构2.参数说明三、eviews 时间序列一阶自相关检验命令实例1.数据准备2.命令执行3.结果解读四、结论正文:一、引言在时间序列分析中,自相关系数检验是评估时间序列数据之间关系的重要方法。
eviews 作为一款强大的时间序列分析软件,提供了丰富的自相关系数检验命令。
本文将详细介绍eviews 时间序列一阶自相关检验命令及其应用。
二、eviews 时间序列一阶自相关检验命令介绍1.语法结构eviews 时间序列一阶自相关检验命令为:ACF(depvar, type, lags, options)其中:- depvar:因变量(时间序列数据)- type:自相关系数类型,包括"ACF"(自相关系数)和"CCF"(偏自相关系数)- lags:滞后阶数- options:可选参数,如"plot"(绘制自相关系数图)2.参数说明在上述语法结构中,depvar 表示需要进行自相关检验的时间序列数据,type 表示需要计算的自相关系数类型,lags 表示需要计算的滞后阶数。
options 为可选参数,用于指定是否绘制自相关系数图等。
三、eviews 时间序列一阶自相关检验命令实例1.数据准备假设我们已经得到了一个时间序列数据集,包含以下变量:- 时间(time)- 因变量(y)2.命令执行我们可以通过以下命令计算时间序列一阶自相关系数:ACF(y, ACF, 1)该命令表示计算y 变量的一阶自相关系数(ACF),滞后阶数为1。
3.结果解读命令执行后,eviews 会显示计算得到的自相关系数结果。
对于一阶自相关系数,我们主要关注其p 值。
如果p 值小于显著性水平(通常为0.05),则说明因变量与自身存在显著的正相关或负相关关系;反之,则无法拒绝原假设,认为因变量与自身不存在显著的相关关系。
一、数据来源
数据:国家统计局(1981~2010年国内生产总值与固定资产投资)软件版本:EVIEWS7.2
二、回归结果
1、一元线性回归:
三、模型诊断与修正
DW检验:相关系数δ=0.8546,查表得,
1.35
1.49
L
U
d
d
=
=
经检验,DW<1.35,自变量呈一阶正自
相关
四、广义差分法修正后的结果
对E 进行滞后一期的自回归,可得回归方程:E=0.9337E(-1)
对原模型进行广义差分,输出结果为:
**ˆˆ6981.723 1.002749t t y x =+
由于使用广义差分数据,样本容量减少了1个,为29个。
查5%的显著性水平的DW
统计表可知, 1.341.48
L U d d ==,模型中的4-DU>DW>DU ,所以广义差分模型已无序列相关。
根据()1ˆˆ16981.723βρ-=,可得1
ˆ=105305.023β。
因此,原回归模型应为 105305.023 1.002749t t y x =+
采用普莱斯-文斯滕变换后第一个观测值变为211y δ-为1750.7019和211x δ-为344.1377,变换后普通最小二乘结果为**ˆˆ7555.503 1.0611t t y
x =+,根据()1ˆˆ17555.503βρ-=,得1
ˆ=113959.321β,由此,最终模型是 ˆ113959.321 1.0611t t y
x =+。
计量经济学经典eviews 定义和诊断检验 本章描述的每一检验过程包括假设检验的原假设定义。
检验指令输出包括一个或多个检验统计量样本值和它们的联合概率值(p 值)。
p 值说明在原假设为真的情况下,样本统计量绝对值的检验统计量大于或等于临界值的概率。
这样,低的p 值就拒绝原假设。
对每一检验都有不同假设和分布结果。
方程对象菜单的View 中给出三种检验类型选择来检验方程定义。
包括系数检验、残差检验和稳定性检验。
其他检验,如单位根检验(13章)、Granger 因果检验(8章)和Johansen 协整检验(19章)。
§15.1 系数检验一、Wald 检验——系数约束条件检验Wald 检验没有把原假设定义的系数限制加入回归,通过估计这一无限制回归来计算检验统计量。
Wald 统计量计算无约束估计量如何满足原假设下的约束。
如果约束为真,无约束估计量应接近于满足约束条件。
考虑一个线性回归模型:εβ+=X y 和一个线性约束:0:0=-r R H β,R 是一个已知的k q ⨯阶矩阵,r 是q 维向量。
Wald 统计量在0H 下服从渐近分布)(2q χ,可简写为:)())(()(112r Rb R X X R s r Rb W -'''-=--进一步假设误差ε独立同时服从正态分布,我们就有一确定的、有限的样本F-统计量q W k T u u q u u u u F /)/(/)~~(=-''-'= u~是约束回归的残差向量。
F 统计量比较有约束和没有约束计算出的残差平方和。
如果约束有效,这两个残差平方和差异很小,F 统计量值也应很小。
EViews 显示2χ和F 统计量以及相应的p 值。
假设Cobb-Douglas 生产函数估计形式如下:εβα+++=K L A Q log log log (1)Q 为产出增加量,K 为资本投入,L 为劳动力投入。
系数假设检验时,加入约束1=+βα。
eviews异方差、自相关检验与解决办法一、异方差检验:1.相关图检验法LS Y C X 对模型进行参数估计GENR E=RESID 求出残差序列GENR E2=E^2 求出残差的平方序列SORT X 对解释变量X排序SCAT X E2 画出残差平方与解释变量X的相关图2.戈德菲尔德——匡特检验已知样本容量n=26,去掉中间6个样本点(即约n/4),形成两个样本容量均为10的子样本。
SORT X 将样本数据关于X排序SMPL 1 10 确定子样本1LS Y C X 求出子样本1的回归平方和RSS1SMPL 17 26 确定子样本2LS Y C X 求出子样本2的回归平方和RSS2计算F统计量并做出判断。
解决办法3.加权最小二乘法LS Y C X 最小二乘法估计,得到残差序列GRNR E1=ABS(RESID) 生成残差绝对值序列LS(W=1/E1) Y C X 以E1为权数进行加权最小二成估计二、自相关1.图示法检验LS Y C X 最小二乘法估计,得到残差序列GENR E=RESID 生成残差序列SCAT E(-1) E et—et-1的散点图PLOT E 还可绘制et的趋势图2.广义差分法LS Y C X AR(1) AR(2)首先,你要对广义差分法熟悉,不是了解,如果你是外行,我奉劝你还是用eviews来做就行了,其实我想老师要你用spss无非是想看你是否掌握广义差分,好了,废话不多说了。
接着,使用spss16来解决自相关。
第一步,输入变量,做线性回归,注意在Liner Regression 中的Statistics中勾上DW,在save中勾Standardized,查看结果,显然肯定是有自相关的(看dw值)。
第二步,做滞后一期的残差,直接COPY数据(别告诉我不会啊),然后将残差和滞后一期的残差做回归,记下它们之间的B指(就是斜率)。
第三步,再做滞后一期的X1和Y1,即自变量和因变量的滞后一期的值,也是直接COPY。
作业1我们有1978-2007年我国财政收入,国内生产总值,财政支出和商品零售价格指数的年度数据。
请用Eview 进展回归分析。
(1) 根据回归结果分析模型的经济意义〔包含模型的显著性,拟合优度,系数的显著性,系数的经济意义〕建立模型,做OLS 估计,得结果图一,列表如下:43283175.57898859.0003271.0558.6399X X X Y ++--=∧)0636.20)(065848.0)(012559.0)(836.2132(SE )882456.2)(65061.13)(260476.0-)(000492.3-(t =997046.02=R 996705.02=R 845.2924=F模型整体显著性较高〔F 检验十分显著〕,可决系数2R 和调整的可决系数较大,即样本回归方程对样本观测值拟合较好。
t 检验显示2X 的系数不显著〔p 值>0.05,不能拒绝β=0的原假设〕,3X 和4X 的系数显著〔p 值<0.05,拒绝β=0的原假设〕。
从模型的经济意义来看,财政支出、商品零售价格指数与财政收入成正相关,国内生产总值与财政收入成负相关,不符合客观经济规律,可能与模型变量的选取有关。
考虑对模型进展对数变换,结果为图二。
432ln 128427.1ln 631090.0ln 448496.0946444.6ln X X X Y +++-=∧)610249.0)(160929.0)(141418.0)(853146.2(SE)849127.1)(921549.3)(171412.3)(434662.2(t -=987673.02=R 986251.02=R 3969.694=F对数变换后模型整体显著性较高〔F 检验十分显著,p 值=0.00<<0.05〕,可决系数2R 和调整的可决系数略有下降,模型可解释98.63%的因变量变化。
t 检验显示4ln X 的系数不显著〔p 值=0.0758>0.05,不能拒绝β=0的原假设〕,2ln X 和3ln X 的系数显著〔p 值<0.05,拒绝β=0的原假设〕。
计量经济学实验报告实验目的:掌握自相关问题的检验以及相关的Eviews的操作方法。
实验内容:消费总量的多少主要有GDP决定。
为了考察GDP对消费总额的影响,可使用如下模型:Yi =1ββ+iX;其中,X表示GDP,Y表示消费总量。
下表列出了中国1990-2000的GDP的X与消费总额Y的统计数据。
年份GDP(X)消费总额(Y)年份GDP(X)消费总额(Y)199018319.5 11365.2 199879003.3 46405.9199121280.4 13145.9 199982673.2 49722.8199225863.7 15952.1 200089112.5 54617.2199334500.7 20182.1 2001 98592.9 58927.4199446690.7 26796 2002 107897.6 62798.5199558510.5 33635 2003 121730.3 67493.5199668330.4 40003.9 2004 142394.2 75439.7199774894.243579.4一、估计回归方程OLS法的估计结果如下:Y=2329.401+0.546950X(1.954322)(36.71110)R2=0.990446,R2=0.989711,SE=2091.475,D.W.=0.478071。
二、进行序列相关性检验(1)图示检验法(2)回归检验法一阶回归检验二阶回归检验e=1.144406e1-t-0.343796e2-t+εtt3)拉格朗日乘数(LM)检验法Breusch-Godfrey Serial Correlation LM Test:F-statistic 29.41781 Probability 0.000038Obs*R-squared 12.63731 Probability 0.001802Test Equation:Dependent Variable: RESIDMethod: Least SquaresC 37.31393 644.3315 0.057911 0.9549X -0.002008 0.009377 -0.214144 0.8344RESID(-1) 1.744086 0.234326 7.442998 0.0000R-squared 0.842487 Mean dependent var 4.37E-12Adjusted R-squared 0.799529 S.D. dependent var 2015.396S.E. of regression 902.3726 Akaike info criterion 16.67111Sum squared resid 8957040. Schwarz criterion 16.85992Log likelihood -121.0333 F-statistic 19.61188Durbin-Watson stat 2.360720 Prob(F-statistic) 0.000101C=37.31393 x=-0.002008 RESID(-1)=1.744086 RESID(-2)= -1.088243 三、序列相关的补救Dependent Variable: DYMethod: Least SquaresDate: 12/17/12 Time: 22:07Sample(adjusted): 1991 2004Included observations: 14 after adjusting endpointsC 2369.885 789.9844 2.999914 0.0111DX 0.465880 0.029328 15.88520 0.0000R-squared 0.954604 Mean dependent var 13875.68Adjusted R-squared 0.950821 S.D. dependent var 5320.847S.E. of regression 1179.971 Akaike info criterion 17.11593Sum squared resid 16707973 Schwarz criterion 17.20722Log likelihood -117.8115 F-statistic 252.3397Durbin-Watson stat 0.521473 Prob(F-statistic) 0.000000(2)科克伦-奥科特法估计模型Dependent Variable: YMethod: Least SquaresDate: 12/17/12 Time: 22:09Sample(adjusted): 1991 2004Included observations: 14 after adjusting endpointsC 55169.41 54542.80 1.011488 0.3335X 0.345292 0.057754 5.978675 0.0001R-squared 0.998047 Mean dependent var 43478.53 Adjusted R-squared 0.997691 S.D. dependent var 19591.16 S.E. of regression 941.3171 Akaike info criterion 16.71985 Sum squared resid 9746856. Schwarz criterion 16.85679 Log likelihood -114.0389 F-statistic 2810.040。
实验五自相关性【实验目的】掌握自相关性的检验与处理方法。
【实验内容】利用表5-1资料,试建立我国城乡居民储蓄存款模型,并检验模型的自相关性。
【实验步骤】一、回归模型的筛选⒈相关图分析SCAT X Y相关图表明,GDP指数与居民储蓄存款二者的曲线相关关系较为明显。
现将函数初步设定为线性、双对数、对数、指数、二次多项式等不同形式,进而加以比较分析。
⒉估计模型,利用LS命令分别建立以下模型⑴线性模型:LS Y C Xt (-6.706) (13.862)=2R=0.9100 F=192.145 S.E=5030.809⑵双对数模型:GENR LNY=LOG(Y)GENR LNX=LOG(X)LS LNY C LNXt (-31.604) (64.189)=2R=0.9954 F=4120.223 S.E=0.1221⑶对数模型:LS Y C LNX=t (-6.501) (7.200)2R =0.7318 F =51.8455 S.E =8685.043 ⑷指数模型:LS LNY C X=t (23.716) (14.939)2R =0.9215 F =223.166 S.E =0.5049 ⑸二次多项式模型:GENR X2=X^2 LS Y C X X2=t (3.747) (-8.235) (25.886)2R =0.9976 F =3814.274 S.E =835.979 ⒊选择模型比较以上模型,可见各模型回归系数的符号及数值较为合理。
各解释变量及常数项都通过了t 检验,模型都较为显著。
除了对数模型的拟合优度较低外,其余模型都具有高拟合优度,因此可以首先剔除对数模型。
比较各模型的残差分布表。
线性模型的残差在较长时期内呈连续递减趋势而后又转为连续递增趋势,指数模型则大体相反,残差先呈连续递增趋势而后又转为连续递减趋势,因此,可以初步判断这两种函数形式设置是不当的。
而且,这两个模型的拟合优度也较双对数模型和二次多项式模型低,所以又可舍弃线性模型和指数模型。
一、数据来源
数据:国家统计局(1981~2010年国内生产总值与固定资产投资)软件版本:EVIEWS7.2
二、回归结果
1、一元线性回归:
三、模型诊断与修正
DW检验:相关系数δ=0.8546,查表得,
1.35
1.49
L
U
d
d
=
=
经检验,DW<1.35,自变量呈一阶正自
相关
四、广义差分法修正后的结果
对E 进行滞后一期的自回归,可得回归方程:E=0.9337E(-1)
对原模型进行广义差分,输出结果为:
**ˆˆ6981.723 1.002749t t y x =+
由于使用广义差分数据,样本容量减少了1个,为29个。
查5%的显著性水平的DW
统计表可知, 1.341.48
L U d d ==,模型中的4-DU>DW>DU ,所以广义差分模型已无序列相关。
根据()1ˆˆ16981.723βρ-=,可得1
ˆ=105305.023β。
因此,原回归模型应为 105305.023 1.002749t t y x =+
采用普莱斯-文斯滕变换后第一个观测值变为211y δ-为1750.7019和211x δ-为344.1377,变换后普通最小二乘结果为**ˆˆ7555.503 1.0611t t y
x =+,根据()1ˆˆ17555.503βρ-=,得1
ˆ=113959.321β,由此,最终模型是 ˆ113959.321 1.0611t t y
x =+。