01_尚硅谷大数据之HBase简介
- 格式:pdf
- 大小:292.77 KB
- 文档页数:3




hbase概述HBase是Apache Hadoop生态系统中的一个分布式非关系型数据库。
它是以Google的Bigtable为基础实现的,旨在为大规模分布式系统提供高可靠性、高性能的数据存储和处理能力。
HBase的设计目标是适用于海量数据环境下的随机实时读写,并能够容忍硬件故障。
HBase的特点和优势主要包括以下几个方面:1.分布式架构:HBase使用分布式架构来存储数据,数据可以水平扩展到数千台机器上。
它采用了Hadoop的HDFS(Hadoop Distributed File System)作为底层存储,可以自动在集群中多节点上复制数据,实现分布式存储和高可靠性。
2.高可扩展性:由于HBase采用分布式架构,可以通过简单地增加集群中的机器来扩展系统的容量和性能。
通过添加更多的Region Server节点,HBase能够支持PB级别的数据规模。
3.列式存储:HBase将数据以列式存储在磁盘上,相比传统的行式数据库,这种存储方式在某些场景下可以提供更好的查询性能。
此外,HBase还支持列族的概念,可以将相关的列进行组织,提高查询效率。
4.高性能读写:HBase支持高性能的读写操作,可以满足实时查询和更新的需求。
HBase的数据模型和存储方式使得它在随机读写方面表现出色,适合处理大量的随机访问操作。
5.强一致性:HBase提供强一致性的数据一致性模型,即读取操作总是可以看到最新的数据。
这种特性使得HBase适用于许多需要数据一致性的应用场景,如金融、电信等领域。
6.数据复制和容错:HBase采用副本机制来实现数据的复制和容错。
可以将数据副本存储在不同的Region Server上,以提高系统的容错能力和可靠性。
当某个副本节点发生故障时,可以自动切换到其他副本节点进行读写操作。
7.可伸缩的数据模型:HBase数据模型是非常灵活和可伸缩的,可以存储具有不同结构的数据。
HBase支持动态添加和删除列族,以及在行级别上进行事务处理。

HBase是一个分布式的、面向列的开源数据库存储系统,具有高可靠性、高性能和可伸缩性,它可以处理分布在数千台通用服务器上的PB级的海量数据。
以下是HBase的基本特点和概念:1.高可靠性:HBase使用Hadoop分布式文件系统(HDFS)作为其文件存储系统,具有高可靠性。
它利用Zookeeper作为协同服务,确保在系统出现故障时,数据不会丢失。
2.高性能:HBase具有高性能,可以在廉价的PC Server上搭建大规模结构化存储集群。
它使用Hadoop MapReduce来处理海量数据,确保数据能够快速地被访问和处理。
3.面向列:HBase是一个面向列的数据库,这意味着它以列族的形式存储数据,而不是以行的形式存储。
这使得HBase非常适合于处理大型数据集,因为它可以更快地访问和过滤数据。
4.可伸缩性:HBase可以轻松地扩展到数千台服务器,使其能够处理PB级别的数据。
这使得HBase成为处理大规模数据的理想选择。
5.适合非结构化数据存储:HBase不限制存储的数据的种类,允许动态的、灵活的数据模型。
它适合于存储非结构化数据,如文本、图像或音频等。
6.主从架构:HBase是主从架构,其中HMaster作为主节点,HRegionServer作为从节点。
HMaster负责协调和分配任务给各个HRegionServer,而HRegionServer则负责处理和存储数据。
7.多版本数据:HBase为null的记录不会被存储,同时它也支持多版本号数据。
这使得HBase可以方便地存储变动历史记录,比如用户的Address变更。
总的来说,HBase是一个非常强大和灵活的数据库系统,适用于处理大规模的非结构化数据。

hbase用法-回复如何使用HBaseHBase是一个分布式、面向列的NoSQL数据库,它专为存储大规模数据集而设计。
本文将向您介绍HBase的用法,一步一步回答以下问题:1. HBase是什么及其特点?2. HBase的安装和设置。
3. HBase的数据模型。
4. HBase的数据访问和操作。
5. HBase的一致性和可用性。
6. HBase的性能调优。
7. HBase在实际应用中的使用。
1. HBase是什么?HBase是一个基于Hadoop的分布式面向列的数据库。
它是一个开源项目,采用了Google的Bigtable模型。
HBase具有以下特点:- 高度可扩展:HBase可以在数千台服务器上运行,处理海量数据。
- 面向列存储:数据以行和列的形式存储,每个列可以包含不同类型的数据。
- 高读写性能:HBase支持快速的随机读写操作,并具有高并发性能。
- 强一致性:HBase提供强一致性模型,支持事务处理。
- 自动故障转移:HBase具有自动故障转移功能,保证数据的可靠性和可用性。
2. HBase的安装和设置。
为了使用HBase,您需要按照以下步骤进行安装和设置:- 下载HBase二进制文件并解压缩到您的目标文件夹。
- 配置HBase环境变量(例如JAVA_HOME、HADOOP_HOME、HBASE_HOME)。
- 修改HBase配置文件hbase-site.xml,指定Hadoop集群的位置和运行模式(分布式或伪分布式)。
- 启动HBase集群:运行start-hbase.sh(Linux)或start-hbase.cmd (Windows)。
- 运行HBase Shell:输入hbase shell命令以进入交互式Shell界面。
3. HBase的数据模型。
HBase的数据模型是面向列的,类似于传统的二维表格。
数据存储在表中,每个表由行和列组成。
行由唯一的行键标识,列由列族和列限定符组成。

hbase的应用场景
HBase是一个分布式的非关系型数据库,其应用场景主要包括以下几个方面:
1. 大数据存储和处理:HBase可以存储PB级别的海量数据,并且支持快速的数据读写操作,可以作为大数据存储和处理平台的重要组成部分,例如企业级数据仓库、日志分析、搜索引擎等。
2. 实时数据处理:HBase可以实现实时的数据存储和查询,在实时数据处理场景下可以作为数据缓存和实时计算的基础组件,例如实时监控和分析系统、智能推荐系统等。
3. 协同过滤和推荐系统:HBase支持随机访问和列存储,可以快速查询和计算用户之间的相似度和兴趣偏好,可以作为协同过滤和推荐系统的底层存储和计算引擎。
4. 地理信息系统:HBase支持空间数据类型和空间索引,可以存储和查询大规模的地理空间数据,可以作为地理信息系统的底层存储和查询引擎。
5. 时序数据存储和分析:HBase支持时间戳的存储和查询,可以存储和查询大规模的时序数据,例如物联网数据、传感器数据、日志数据等。
总之,HBase适用于大规模数据存储和处理场景,具有高可靠性、高可扩展性和高性能的特点,是企业级大数据应用的重要组成部分。
- 1 -。

什么是HBase?HBase 介绍⼀、什么是HBase?1.HBase – Hadoop Database,是⼀个⾼可靠性、⾼性能、⾯向列、可伸缩、实时读写的分布式数据库2. HBASE是Google Bigtable的开源实现,但是也有很多不同之处。
⽐如:Google Bigtable使⽤GFS作为其⽂件存储系统,HBASE利⽤Hadoop HDFS作为其⽂件存储系统;Google运⾏MAPREDUCE来处理Bigtable中的海量数据,HBASE同样利⽤Hadoop MapReduce来处理HBASE中的海量数据;Google Bigtable利⽤Chubby作为协同服务,HBASE利⽤Zookeeper作为协同服务。
3.HBase是⼀个分布式存储、数据库引擎,可以⽀持千万的QPS、PB级别的存储,这些都已经在⽣产环境验证,并且在⼴⼤的公司已经验证。
特别是阿⾥(淘宝、天猫、蚂蚁⾦服)、⼩⽶⽶聊、⼩⽶云、⼩⽶推送服务)、京东、滴滴内部都有数千、上万台的HBase集群。
Hbase PMC。
阿⾥1个。
Hbase Committer。
阿⾥4个,⼩⽶4个。
2016年双11,HBase承载访问量达到了上百GB/秒(写⼊)与上百GB/秒(读取),相当于全国⼈民⼀秒收发⼀条短信,在业务记录、安全风控、实时计算、⽇志监控、消息聊天等多个场景发挥重要价值。
⼆、哪些是HBase的特点?1.存储数据量⼤:⼀个表可以有上亿⾏,上百万列。
2.⾯向列:⾯向列表(簇)的存储和权限控制,列(簇)独⽴检索。
3.稀疏:对于为空(NULL)的列,并不占⽤存储空间,因此,表可以设计的⾮常稀疏。
4.⽆模式:每⼀⾏都有⼀个可以排序的主键和任意多的列,列可以根据需要动态增加,同⼀张表中不同的⾏可以有截然不同的列。
5.数据多版本:每个单元中的数据可以有多个版本,默认情况下,版本号⾃动分配,版本号就是单元格插⼊时的时间戳。
6.数据类型单⼀:HBase中的数据都是字符串,没有类型。

hbase知识点总结HBase的特点:1. 高可靠性:HBase采用了分布式架构,数据被分布存储在多个节点上,因此可以提高系统的可靠性,即使某些节点发生故障,也能保证系统的正常运行。
2. 高性能:HBase支持并发访问、扩展性好,可以处理大规模数据,并提供快速的读写性能。
3. 灵活的数据模型:HBase采用列存储的模式,数据存储在表中的列族中,可以动态地增加列族和列,适合存储半结构化、非结构化的数据。
4. 水平扩展:HBase可以通过增加或减少节点的方式进行扩展,可以适应数据规模的增长。
HBase的原理:1. 数据模型:HBase的数据模型是面向列族的,数据存储在表中的行和列族中,每个列族包含多个列,每个列有一个时间戳,可以存储多个版本的数据。
这种数据模型适合存储稀疏数据,可以动态地增加列族、列。
2. 分布式存储:HBase采用了分布式存储的方式,数据被分割成多个区域,并存储在不同的RegionServer节点上,每个RegionServer管理多个Region,Region则包含多个Store,每个Store包含一个或多个列族。
3. 架构组件:HBase包含Master节点和RegionServer节点,Master节点负责管理集群的元数据信息、负载均衡、安全性等,RegionServer节点则负责存储和处理数据。
HBase还包含ZooKeeper节点用于协调集群中各个节点的状态和配置信息。
4. 读写操作:HBase的读操作是通过Row Key来获取数据,可以在列族、列和时间戳上进行过滤,支持多版本数据的读取。
写操作则是先将数据写入MemStore,当MemStore的数据达到一定大小时,将数据刷写到磁盘中的HFile文件。
HBase的使用方法:1. 数据模型设计:在使用HBase之前,需要对数据进行合理的数据模型设计,包括表的结构、列族的设计、Row Key的选择等。
要根据实际的业务需求来进行设计,保证数据的高效访问和存储。

第 1 页 共 4 页 hbase基础操作 【原创实用版】 目录 1.HBase 简介 2.HBase 基本操作 a.创建表 b.删除表 c.添加数据 d.查询数据 e.更新数据 f.删除数据 正文 HBase 是一个分布式、可扩展、高性能的列式存储系统,它基于 Google 的 Bigtable 设计,适用于存储大型表格数据。HBase 提供了对数据的高效存储和快速查询,非常适合用于数据仓库和数据分析等场景。
在 HBase 中,表是由行和列组成的,表可以看作是一个键值对集合,其中行键是唯一的,列族和列是无限的。接下来,我们将介绍 HBase 的基本操作。
1.创建表 在 HBase 中,创建表需要指定表名、列族和列。可以使用如下命令创建表:
``` CREATE TABLE table_name ( 第 2 页 共 4 页
column_family_1 column_name_1, column_family_2 column_name_2, ... ) ``` 例如,创建一个名为“students”的表,包含“name”和“age”两个列:
``` CREATE TABLE students ( name String, age Int ) ``` 2.删除表 在 HBase 中,删除表非常简单,只需使用如下命令: ``` DROP TABLE table_name ``` 例如,删除刚才创建的“students”表: ``` DROP TABLE students ``` 第 3 页 共 4 页
3.添加数据 在 HBase 中,向表中添加数据使用 put 命令,格式如下: ``` PUT table_name row_key column_family:column_name value ``` 例如,向“students”表中添加一条数据,学生姓名为“张三",年龄为 20:
Hbase数据库简介Hbase概念:常⽤的oracle、mySQL数据库都是⾯向⾏储存的,⽽hbase是⾯向列储存的数据库,储存本⾝具有⽔平延展性。
hbase有两个主要概念:Row key和Column FamliyColumn Famliy⼜称为“列族”,每⼀个Column Family都可以根据“限定符”有多个column。
例如:有⼀个User表,传统的数据库中,表的列是固定的,name,age,sex等属性,User的属性不能动态增加。
但采⽤列储存系统,⽐如Hbase,那么我们可以定义User表,然后定义info 列族,User的数据可以分为:info:name = zhangsan,info:age=30,info:sex=male等,如果后来你⼜想增加另外的属性,这样很⽅便只需要info:newProperty就可以了。
⼜⽐如储存⽤户信息,信息并不⼀定完整,⽽null的单元会造成空间浪费,在Hbase⾥,如果每⼀个column 单元没有值,那么是不占⽤空间的。
采⽤Hbase的这种⽅式,还有⼀个⾮常重要的好处就是会⾃动切分,当表中的数据超过某⼀个阀值以后,Hbase会⾃动为我们切分数据,这样的话,查询就具有了伸缩性,⽽再加上Hbase的弱事务性的特性,对Hbase的写⼊操作也将变得⾮常快。
另⼀个主要概念:Row key,其实可以理解row key 是某⼀⾏的主键,但是因为Hbase不⽀持条件查询以及Order by等查询,因此Row key的设计就要根据你系统的查询需求来设计了。
例如我们查询某⼈信息,因此我们的Row key可以有以下三个部分构成<userId><timestamp><feedId>,这样以来当我们要查询某个⼈的最进的Feed就可以指定Start Rowkey为<userId><0><0>,End Rowkey为<userId><Long.MAX_VALUE><Long.MAX_VALUE>来查询了,同时因为Hbase中的记录是按照rowkey来排序的,这样就使得查询变得⾮常快。
HBase名词解释1. 什么是HBase?HBase是一个基于Hadoop的分布式、面向列的非关系型数据库。
它是Apache软件基金会的一个开源项目,被设计用于处理大规模数据集。
HBase提供了高可靠性、高性能和高可扩展性,并且具有强大的数据模型。
2. HBase的特点2.1 列存储HBase以列族(Column Family)的形式存储数据,而不是以行的形式。
每个列族包含多个列限定符(Column Qualifier),这些列限定符可以动态地定义。
这种列存储的方式使得HBase能够高效地存储稀疏数据。
2.2 分布式HBase基于Hadoop的分布式文件系统(HDFS)进行数据存储,数据被分散存储在多个节点上,可以实现水平扩展,处理大规模数据集。
2.3 高可靠性HBase通过数据的冗余复制提供了高可靠性。
数据被复制到多个节点上,当某个节点出现故障时,可以从其他节点恢复数据。
2.4 高性能HBase通过将数据存储在内存中,并使用B树索引来提供高性能的数据访问。
此外,HBase还支持在列族级别进行数据压缩,减少了存储空间的占用。
2.5 强一致性HBase提供了强一致性的读写操作。
当数据被写入或读取时,HBase会确保数据的一致性,避免出现数据不一致的情况。
2.6 支持在线扩容HBase支持在线扩容,可以动态地添加或删除节点,以适应数据量的增长或减少。
这种扩容方式不会影响正在进行的读写操作。
2.7 支持复杂的查询HBase支持针对单行或范围的查询操作,可以根据行键(Row Key)或列限定符进行查询。
此外,HBase还支持过滤器(Filter)的使用,可以进行更复杂的查询。
3. HBase的数据模型HBase的数据模型是基于行的,每一行由一个唯一的行键标识。
行键是按照字典顺序进行排序的,可以使用任意的字节序列作为行键。
HBase的数据是以列族的形式进行组织的。
每个列族可以包含多个列限定符,列限定符是列族内的列的唯一标识。
HBase简介什么是HBase?HBase,是Hadoop Database,是⼀个⾼可靠性、⾼性能、⾯向列、可伸缩的分布式存储系统。
使⽤HBase技术可以在廉价的PC服务器上搭建起⼤规模结构化的存储集群。
它底层的⽂件系统使⽤HDFS,使⽤Zookeeper来管理集群的HMaster和各Region server 之间的通信,监控各Region server的状态,存储各Region的⼊⼝地址等。
何时⽤HBase?⾸先想想传统的关系型数据库都有哪些特点,⼤概的特点有:⽀持事务,ACID(原⼦性、⼀致性、隔离性和持久性)特性;⾏式存储;SQL语句使⽤起来⽐较⽅便;⽀持索引、视图等;接下来我们考虑⼀个场景:我们想要构建⼀个社交⽹站,我们可能会选择易于操作的LAMP(Linux、Apache、Mysql、PHP)模型来快速的搭建⼀个原型。
随着⽤户数的不断增加,每天有越来越多的⼈开始访问,这时候,共享的数据库服务器压⼒会越来越⼤,可以选择增加应⽤服务器,但因为这些应⽤服务器共享中央数据库,所以,随着数据库的CPU 和I/O负载升⾼,这种⽅案势必不可长久。
这时候,我们可能会增加从服务器,以便并⾏读取,将读写分离。
这样做是因为考虑到⽤户访问产⽣的读次数⽐写⼊次数更多,但是如果⽤户数⽬增加很快,产⽣的内容越来越多,导致读写数⽬相差没那么⼤,这种⽅案也就不能长久。
接下来的常见做法就是增加缓存,⽐如使⽤Memcached。
这样,读操作存⼊到内存中的数据库系统中,但⼜没办法保证数据⼀致性,因为⽤户更新数据到数据库,⽽数据库不会主动更新缓存中的数据,⽽且,这种⽅案只能解决读请求的压⼒,对于写请求,还是没有解决。
所以需要更多的服务器,更快的磁盘,会导致硬件成本快速升⾼。
⽽且,随着⽤户的增多,⽹站功能势必增加,业务功能都会使⽤sql语句进⾏查询,⽽表数据过多会导致join操作变慢,所以会不得不采⽤⼀些逆范式的⽅式来设计数据库,这样导致⽆法使⽤存储过程。
HBase分布式数据库基础第⼀章 HBase 简介1.1 HBase 定义在⼤数据场景中,除了直接以⽂件形式保存的数据外,还有⼤量结构化和半结构化的数据,这些数据通常需要⽀持更新操作,⽐如随机插⼊和删除,这使得分布式⽂件系统HDFS很难满⾜要求。
为了⽅便⽤户存取海量结构化和半结构化数据,HBase应运⽽⽣。
HBase是构建在分布式⽂件系统HDFS之上的、⽀持随机插⼊和删除的列簇式存储系统,它可被简单理解为⼀个具有持久化能⼒的分布式多维有序映射表。
HBase特点极好的扩展性弱化ACID需求良好的容错性1.2 HBase 数据模型逻辑上,HBase 的数据模型同关系型数据库很类似,数据存储在⼀张表中,有⾏有列。
但从 HBase 的底层物理存储结构(K-V)来看,HBase 更像是⼀个multi-dimensional map。
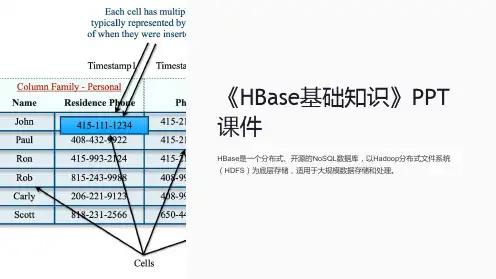
1.2.1 HBase 逻辑结构HBase表由⾏和列组成,每个⾏由⾏键(row key)来标识,列划分为若⼲列族,⼀个列族中可以包含任意多个列,同⼀个列族⾥⾯的数据存储在⼀个⽂件中(不同的列族⾥的数据存储在不同的⽂件中)。
当这个⽂件达到⼀定⼤⼩后,会进⾏分裂形成多个region。
当⼀个⾏键在不同的列族中都有相应的列值的话,不同列族中的⽂件都会存储这个⾏键的值。
也就是说,⼀⾏可能包含多个列族,⼀个列族有多个列,对某⼀⾏⽽⾔,某列族⽂件中只存储了这⼀⾏键在列族中有值的那些列(列族可能有上百个列),没有不会存储(不存null,不占空间)。
1.2.2 HBase 物理存储结构逻辑结构转成物理结构当在t4时间put(插⼊)row_key1的phone数据时,原来t3的并不会马上被覆盖。
当查询row_key1的phone时会返回时间戳最⼤的t4那⼀个数据(最新的)。
从保存格式上可以看出,每⾏数据中不同版本的cell value会重复保存rowkey,colum family和colum qualifier,因此,为了节省存储空间,这⼏个字段值在保证业务易理解的前提下,应尽可能短。
第1章HBase简介
1.1 什么是HBase
HBASE是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBASE 技术可在廉价PC Server上搭建起大规模结构化存储集群。
HBASE的目标是存储并处理大型的数据,更具体来说是仅需使用普通的硬件配置,就能够处理由成千上万的行和列所组成的大型数据。
HBASE是Google Bigtable的开源实现,但是也有很多不同之处。
比如:Google Bigtable 利用GFS作为其文件存储系统,HBASE利用Hadoop HDFS作为其文件存储系统;Google 运行MAPREDUCE来处理Bigtable中的海量数据,HBASE同样利用Hadoop MapReduce来处理HBASE中的海量数据;Google Bigtable利用Chubby作为协同服务,HBASE利用Zookeeper作为对应。
1.2 HBase中的角色
1.2.1 HMaster
功能:
1) 监控RegionServer
2) 处理RegionServer故障转移
3) 处理元数据的变更
4) 处理region的分配或移除
5) 在空闲时间进行数据的负载均衡
6) 通过Zookeeper发布自己的位置给客户端
1.2.2 RegionServer
功能:
1) 负责存储HBase的实际数据
2) 处理分配给它的Region
3) 刷新缓存到HDFS
4) 维护HLog
5) 执行压缩
6) 负责处理Region分片
1.2.3 其他组件:
1) Write-Ahead logs
HBase的修改记录,当对HBase读写数据的时候,数据不是直接写进磁盘,它会在内存中保留一段时间(时间以及数据量阈值可以设定)。
但把数据保存在内存中可能有更高的概率引起数据丢失,为了解决这个问题,数据会先写在一个叫做Write-Ahead logfile的文件中,然后再写入内存中。
所以在系统出现故障的时候,数据可以通过这个日志文件重建。
2) HFile
这是在磁盘上保存原始数据的实际的物理文件,是实际的存储文件。
3) Store
HFile存储在Store中,一个Store对应HBase表中的一个列族。
4) MemStore
顾名思义,就是内存存储,位于内存中,用来保存当前的数据操作,所以当数据保存在WAL 中之后,RegsionServer会在内存中存储键值对。
5) Region
Hbase表的分片,HBase表会根据RowKey值被切分成不同的region存储在RegionServer中,在一个RegionServer中可以有多个不同的region。
1.3 HBase架构
HBase架构图。