sss非参数检验K多个独立样本检验KruskalWallis检验案例解析
- 格式:doc
- 大小:183.00 KB
- 文档页数:5

spss-非参数检验-K多个独立样本检验
(Kruskal-Wallis检验)案例解析Kruskal-Wallis检验,也称为KW检验,是一种非参数检验方法,用于比较两个或多个独立样本的中位数是否相等。
它利用秩(等级)来进行统计分析,而不是直接使用原始数据。
假设有一个关于人们在不同饮料中的品尝体验的数据集。
数据集中包含了人们在红酒、白酒和啤酒中品尝的感受,包括甜度、酸度、苦度等。
现在想要比较这三种饮料在甜度方面的中位数是否有显著差异。
首先,对每种饮料的甜度进行排序,得到每个人的秩。
然后,将每个人的秩平均分到他们所对应的饮料中,得到每个饮料的平均秩。
接着,对这些平均秩进行比较。
如果红酒、白酒和啤酒的平均秩存在显著差异,则说明这三种饮料在甜度方面的中位数存在显著差异。
如果平均秩没有显著差异,则说明这三种饮料在甜度方面的中位数没有显著差异。
下面是一个具体的案例数据:
根据上述数据,我们可以计算出每种饮料的平均秩:
红酒: (2+1)/2 = 1.5
白酒: (4+3)/2 = 3.5
啤酒: (6+5)/2 = 5.5
然后对这些平均秩进行比较。
由于红酒的平均秩最小,白酒的平均秩次之,啤酒的平均秩最大,因此可以得出结论:这三种饮料在甜度方面的中位数存在显著差异,其中啤酒的甜度最高,白酒次之,红酒最低。
需要注意的是,KW检验的前提假设是各个样本是独立同分布的,且样本容量足够大。
如果样本不满足这些条件,可能会导致检验结果出现偏差。
此外,KW检验只能告诉我们是否存在显著差异,但不能告诉我们差异的具体原因。
如果想要了解更多信息,需要进行后续的统计分析。

Kruskal-Wallis检验的使用技巧在统计学中,Kruskal-Wallis检验是一种用于比较三个或更多组数据的非参数检验方法。
与方差分析(ANOVA)相比,Kruskal-Wallis检验不需要假设数据符合正态分布,因此适用于不满足正态分布假设的情况。
本文将介绍Kruskal-Wallis检验的使用技巧,包括数据准备、检验过程和结果解读。
数据准备在进行Kruskal-Wallis检验之前,首先需要准备要比较的数据。
假设我们有三个或更多个组别,每个组别包含的数据是独立同分布的。
数据可以是连续型、顺序型或等距型的,但不能是名义型的。
为了进行Kruskal-Wallis检验,需要将数据按组别进行整理,确保每个组别的样本量相近。
若样本量差异较大,可以考虑进行数据的重新抽样或者采用适当的变换方法使其满足检验的要求。
检验过程Kruskal-Wallis检验的原假设是各组数据的分布相同,备择假设是至少有一组数据的分布不同。
进行Kruskal-Wallis检验时,首先需要计算每个组别的秩和,然后计算整体的秩和。
接下来,将计算检验统计量H,其表达式为:其中n为总样本量,k为组别的个数,Ri为第i组的秩和,T为所有数据的总秩和。
检验统计量H服从自由度为k-1的卡方分布。
根据检验统计量H的值和自由度,可以查找卡方分布表或使用统计软件计算P值,进而判断是否拒绝原假设。
结果解读当得到Kruskal-Wallis检验的结果后,需要对结果进行解读。
如果P值小于显著性水平(通常取),则拒绝原假设,认为至少有一组数据的分布不同。
此时,可以进行事后检验,比较各组别之间的差异。
常用的事后检验方法包括Dunn-Bonferroni校正、Conover-Iman多重比较等。
若P值大于显著性水平,则接受原假设,认为各组别的数据分布相同。
在进行结果解读时,还需要注意Kruskal-Wallis检验的一些限制。
由于Kruskal-Wallis检验是一种秩和检验方法,对于大样本量或者数据分布差异较大的情况,可能会导致检验结果不准确。

Kruskal-Wallis检验是一种用于比较三个或更多独立样本中位数是否相等的非参数统计
检验方法。
在SAS中进行Kruskal-Wallis检验后,结果通常包括了检验统计量(通常为H 值)、p值以及可能的其他统计信息。
首先,要注意的是Kruskal-Wallis检验的原假设是所有样本的中位数相等,备择假设则是至少有一个样本的中位数不同。
因此,当p值小于设定的显著性水平(通常为0.05)时,我们可以拒绝原假设,认为至少有一个样本的中位数与其他样本不同。
在解读SAS结果时,首先关注检验统计量(H值)。
H值是一个衡量样本之间差异的统计量,数值越大表示样本之间的差异越大。
然后,看p值。
p值是在原假设为真的情况下,观察到检验统计量或更极端情况的概率。
如果p值小于显著性水平,那么我们就有足够的证据来拒绝原假设,接受备择假设,认为至少有一个样本的中位数与其他样本不同。
另外,一些SAS软件还可能提供组间比较的结果,包括每一对组之间的比较统计量和p值。
这些比较通常会使用多重比较校正方法(如Bonferroni校正)来控制实验整体的错误率。
这些组间比较结果可以帮助进一步理解不同组别之间的差异性。
综合考虑检验统计量、p值以及组间比较的结果,可以得出对样本之间中位数差异的合理解释。
如果p值小于显著性水平,通常会认为存在显著差异,但具体的结论应该结合研究背景、实际情况以及可能的假设前提进行综合考虑。
总之,对于Kruskal-Wallis检验的SAS结果,关注检验统计量、p值以及组间比较结果,并综合考虑各方面信息,有助于进行合理的统计推断和科学解释。
spss- 非参数检验 -K 多个独立样本检验(Kruskal-Wallis检验)案例解析2011-09-19 15:09最近经常失眠,好痛苦啊!大家有什么好的解决失眠的方法吗?希望知道的能够告诉我,谢谢啦,今天和大家一起探讨和分下一下SPSS非-参数检验 --K 个独立样本检验(Kruskal-Wallis检验)。
还是以 SPSS教程为例:假设: HO:不同地区的儿童,身高分布是相同的H1:不同地区的儿童,身高分布是不同的不同地区儿童身高样本数据如下所示:提示:此样本数为 4 个(北京,上海,成都,广州)每个样本的样本量(观察数)都为 5 个即:K=4>3 n=5,此时如果样本逐渐增大,呈现出自由度为K-1 的平方的分布,(即指:卡方检验)点击“分析”——非参数检验——旧对话框—— K 个独立样本检验,进入如下界面:将“周岁儿童身高”变量拖入右侧“检验变量列表”内,将“城市( CS)变量”拖入“分组变量”内,点击“定义范围” 输入“最小值”和“最大值”(这里的变量类型必须为“数字型”)如果不是数字型,必须要先定义或者重新编码。
在“检验类型”下面选择“秩和检验”(Kruskal-Wallis检验)点击确定运行结果如下所示:对结果进行分析如下:1:从“检验统计量a,b ”表中可以看出:秩和统计量为:13.900自由度为: 3=k-1=4-1下面来看看“秩和统计量”的计算过程,如下所示:假设“秩和统计量”为kw那么:其中: n+1/2为全体样本的“秩平均”Ri./ni为第i个样本的秩平均Ri. 代表第 i 个样本的秩和, ni 代表第 i 个样本的观察数)最后得到的公式为:北京地区的“秩和”为:秩平均 * 观察数( N) = 14.4*5=72上海地区的“秩和”为:8.2*5=41成都地区的“秩和”为:15.8*5=79广州地区的“秩和”为: 3.6*5=18接近 13.90 (由于中间的计算,我采用四舍五入,丢弃了部分数值,所以,会有部分误差)2:“检验统计量 a,b ”表中可以看出:“渐进显著性为0.003 ,由于0.003<0.01所以得出结论:H1:不同地区的儿童,身高分布是不同的。

Kruskal-Wallis检验的使用技巧Kruskal-Wallis检验是一种用于比较三个或三个以上独立样本的非参数检验方法。
与方差分析(ANOVA)相比,Kruskal-Wallis检验不需要满足正态分布和等方差的假设,因此在数据分布不符合正态分布或方差不齐的情况下更为适用。
下面将介绍Kruskal-Wallis检验的使用技巧,包括检验的假设条件、计算方法以及结果的解释。
检验假设条件Kruskal-Wallis检验的假设条件包括独立性、随机性和等方差性。
独立性要求样本之间相互独立,即一个样本的观测值不受其他样本的影响;随机性要求样本是随机抽取的,具有代表性;等方差性要求不同总体的方差相等。
在进行实际检验时,需要对样本数据进行方差齐性检验,例如Levene检验,以确认是否满足等方差性的假设。
计算方法Kruskal-Wallis检验的计算方法较为复杂,需要将样本数据进行秩次转换,并计算秩和。
首先,将所有样本数据(包括各组数据)合并成一个总体,并按照大小顺序排列,然后对每个数据赋予相应的秩次。
接下来,计算各组数据的秩和,并根据秩和的差异来进行假设检验。
通常,这些计算可以通过统计软件(如SPSS、R 等)进行实现,减少了手工计算的复杂度。
结果解释Kruskal-Wallis检验的结果通常包括检验统计量(H值)和P值。
H值代表样本数据的差异程度,而P值则表示在原假设成立的情况下,观察到当前H值或更极端情况的概率。
当P值小于显著性水平(通常取)时,可以拒绝原假设,认为样本之间存在显著性差异;反之,则无法拒绝原假设,认为样本之间不存在显著性差异。
实际应用Kruskal-Wallis检验在实际应用中具有广泛的使用场景。
例如,在医学研究中,可以用于比较不同药物治疗组的疗效差异;在市场调研中,可以用于比较不同产品在消费者满意度上的差异;在教育评估中,可以用于比较不同学校学生的成绩差异等。
通过Kruskal-Wallis检验,可以客观地评估不同总体之间的差异情况,为决策提供科学依据。

kruskal-wallis test h值案例描述Kruskal-Wallis test(克鲁斯卡尔-沃利斯检验)是一种非参数统计方法,用于比较两个或多个独立样本的中位数是否相等。
该方法适用于有序数据,即数据按照一定顺序排列的情况。
下面将通过一个案例描述,来说明Kruskal-Wallis test的使用方法和注意事项。
假设我们要研究三种不同治疗方法对治疗某种疾病的有效性是否有差异。
我们随机选取了三组患者,每组患者分别接受了三种不同的治疗方法。
我们记录了每位患者的治疗结果,以及他们的年龄和性别作为控制变量。
我们的原假设是三种治疗方法对疗效没有影响,即三组患者的中位数相等。
备择假设是至少有一组患者的中位数与其他组不相等。
首先,我们需要将每组患者的治疗结果按照一定顺序排列。
然后,我们计算每组的秩和,作为该组的代表值。
接下来,我们将使用Kruskal-Wallis test来判断三组患者的中位数是否相等。
以下是一些统计学参考内容:1. Kruskal-Wallis test的原假设和备择假设:- 原假设(H0):众数在所有组中相等。
- 备择假设(H1):至少有一组与其他组的众数不相等。
2. 计算秩和:- 将每组的数值按照顺序排列,并用秩替代原始数据。
秩是指在排序后的位置所对应的数字。
- 计算每组的秩和,作为该组的代表值。
- 计算总的秩和(将所有组的秩和相加)。
3. 计算检验统计量和p值:- 检验统计量(H值)是通过计算每组的秩和来得到的。
- 检验统计量服从自由度为k-1的chi-square分布,其中k是组的数量。
- 根据Kruskal-Wallis分布表,可以查找相应的临界值。
- p值是根据H值和自由度,进行双尾或单尾检验得到的。
4. 检验结果的解释:- 如果p值小于显著性水平(通常为0.05),则拒绝原假设,即认为有差异。
- 如果p值大于显著性水平,则接受原假设,即认为无差异。
需要注意的是,Kruskal-Wallis test是一种非参数统计方法,不对样本分布进行任何假设。

kruskal-wallis检验方法Kruskal-Wallis检验方法。
Kruskal-Wallis检验方法是一种非参数检验方法,用于比较两个或多个独立样本的中位数是否相等。
它是对方差分析的一种推广,适用于数据不满足正态分布的情况。
在实际应用中,Kruskal-Wallis检验方法常常用于医学、社会科学等领域的数据分析。
Kruskal-Wallis检验的原假设是各组样本来自同一总体,备择假设是各组样本来自不同总体。
在进行Kruskal-Wallis检验时,首先需要对数据进行秩次转换,然后计算秩和值,最后根据计算出的检验统计量进行显著性检验。
Kruskal-Wallis检验方法的步骤如下:1. 将所有数据合并,并按照大小顺序排列;2. 对排列后的数据进行秩次转换,即用1, 2, 3, ... , n表示数据的大小顺序;3. 计算各组的秩和值,即将每组的秩次相加;4. 根据计算出的检验统计量进行显著性检验。
在进行Kruskal-Wallis检验时,需要注意以下几点:1. 样本独立性,各组样本应该是相互独立的;2. 数据类型,Kruskal-Wallis检验适用于等距数据或等比数据;3. 样本量,各组样本量应该相等或接近相等;4. 数据分布,Kruskal-Wallis检验对数据的分布没有要求,可以是正态分布、偏态分布或者其他分布。
Kruskal-Wallis检验方法的结果解释通常包括检验统计量、自由度和显著性水平。
如果显著性水平小于设定的显著性水平(通常为0.05),则拒绝原假设,认为各组样本来自不同总体;反之,则接受原假设,认为各组样本来自同一总体。
在实际数据分析中,Kruskal-Wallis检验方法常常与其他统计方法结合使用,例如配对t检验、Wilcoxon秩和检验等,以全面地分析数据的差异性和相关性。
总之,Kruskal-Wallis检验方法是一种非参数检验方法,适用于比较两个或多个独立样本的中位数是否相等。

Kruskal-Wallis检验是一种用于比较三个以上独立样本的非参数检验方法。
它通常用于检验多组数据的总体中位数是否相等。
与方差分析和t检验不同,Kruskal-Wallis检验不要求数据满足正态分布和方差齐性的假设,因此在数据不满足这些假设的情况下,Kruskal-Wallis检验是一个非常有用的统计方法。
首先,我们来看一下Kruskal-Wallis检验的基本原理。
该检验的原假设是各组样本来自同一总体分布,备择假设是各组样本来自不同的总体分布。
在进行检验之前,需要计算每组样本的秩和,然后根据秩和来计算检验统计量H。
H的计算方法较为复杂,通常需要使用统计软件进行计算。
在进行Kruskal-Wallis检验时,需要注意以下几点使用技巧。
首先,要注意选择合适的样本量。
Kruskal-Wallis检验对样本量的要求相对较高,较小的样本量可能导致检验结果不够可靠。
通常来说,每组样本的数量应该不少于5才能保证检验结果的准确性。
其次,要注意选择合适的统计软件进行计算。
由于Kruskal-Wallis检验需要进行秩和的计算,手动计算比较繁琐,容易出错。
因此建议使用专业的统计软件如SPSS、R或者Python进行计算,以确保结果的准确性和可靠性。
另外,Kruskal-Wallis检验的结果需要进行解释时,需要注意检验统计量H 的概念。
H的值越大,意味着样本之间的差异越大,备择假设的支持程度越高。
通常来说,当H的值显著大于临界值时,可以拒绝原假设,认为各组样本来自不同的总体分布。
此外,Kruskal-Wallis检验的结果也可以进行后续的多重比较分析。
当检验的结果显著时,可以使用多重比较方法如Dunn检验或者Conover-Iman检验来进一步比较各组样本之间的差异。
这有助于更加深入地理解各组样本之间的差异性。
最后,要注意Kruskal-Wallis检验的局限性。
虽然Kruskal-Wallis检验在数据不满足正态分布和方差齐性假设时仍然能够进行有效的比较,但是它对于样本量的要求较高,而且在样本量较小的情况下可能会导致结果的不稳定。

2多独立样本Kr u s k a l-Wa llis检验的原理及其实证分析摘要:阐述了多独立样本Kruskal-Wallis检验的基本思想和如何构造K-W统计量,运用多独立样本Kruskal- Wallis检验方法进行了实例分析,并进行H检验的事后比较,给出应用Mathematica和SPSS 做出的相关图形。
关键词:Kruskal-Wallis检验;K-W统计量;Mathematica中图分类号:O212.7非参数检验在总体分布未知时有很大的优越性。
这时如果利用传统的假定分布已知的检验,就会产生错误甚至灾难。
非参数检验总是比传统检验安全。
但是在总体分布形式已知时,非参数检验就不如传统方法效率高。
这是因为非参数方法利用的信息要少些。
往往在传统方法可以拒绝零假设的情况,非参数检验无法拒绝。
但非参数统计在总体未知时效率要比传统方法高,有时要高很多。
是否用非参数统计方法,要根据对总体分布的了解程度来确定[1]。
笔者就K r uskal-Wal lis检验方法及其在经济研究中的应用进行分析,以期对经济分析领域的实证研究提供借鉴。
1多独立样本Kruskal-Wallis检验的基本思想多独立样本K r uskal-Wal lis检验(又称H检验)的实质上是两独立样本时的M ann-Whi tney U检验在多个独立样本下的推广,用于检验多个总体的分布是否存在显著差异。
其原假设是:多个独立样本来自的多个总体的分布无显著差异。
多独立样本K r uskal-Wal lis检验的基本思想是:首先,将多组样本数混合并按升序排序,求出各变量值的秩;然后,考察各组秩的均值是否存在显著差异。
如果各组秩的均值不存在显著差异,则认为多组数据充分混合,数值相差不大,可以认为多个总体的分布无显著差异;反之,如果各组秩的均值存在显著差异,则是多组数据无法混合,有些组的数值普遍偏大,有些组的数值普遍偏小,可认为多个总体的分布存在显著差异,至少有一个样本不同于其他样本。

spss-非参数检验-K多个独立样本检验(-Kruskal-Wallis检验)案例解析spss-非参数检验-K多个独立样本检验( Kruskal-Wallis检验)案例解析2011-09-19 15:09最近经常失眠,好痛苦啊!大家有什么好的解决失眠的方法吗?希望知道的能够告诉我,谢谢啦,今天和大家一起探讨和分下一下SPSS-非参数检验--K 个独立样本检验( Kruskal-Wallis检验)。
还是以SPSS教程为例:假设:HO: 不同地区的儿童,身高分布是相同的H1:不同地区的儿童,身高分布是不同的不同地区儿童身高样本数据如下所示:提示:此样本数为4个(北京,上海,成都,广州)每个样本的样本量(观察数)都为5个即:K=4>3 n=5, 此时如果样本逐渐增大,呈现出自由度为K-1的平方的分布,(即指:卡方检验)点击“分析”——非参数检验——旧对话框——K个独立样本检验,进入如下界面:将“周岁儿童身高”变量拖入右侧“检验变量列表”内,将“城市(CS)变量” 拖入“分组变量”内,点击“定义范围” 输入“最小值”和“最大值”(这里的变量类型必须为“数字型”)如果不是数字型,必须要先定义或者重新编码。
在“检验类型”下面选择“秩和检验”( Kruskal-Wallis检验)点击确定运行结果如下所示:对结果进行分析如下:1:从“检验统计量a,b”表中可以看出:秩和统计量为:13.900自由度为:3=k-1=4-1下面来看看“秩和统计量”的计算过程,如下所示:假设“秩和统计量”为 kw 那么:其中:n+1/2 为全体样本的“秩平均” Ri./ni 为第i个样本的秩平均 Ri.代表第i个样本的秩和, ni代表第i个样本的观察数)最后得到的公式为:北京地区的“秩和”为:秩平均*观察数(N) = 14.4*5=72上海地区的“秩和”为:8.2*5=41成都地区的“秩和”为:15.8*5=79广州地区的“秩和”为:3.6*5=18接近13.90 (由于中间的计算,我采用四舍五入,丢弃了部分数值,所以,会有部分误差)2:“检验统计量a,b”表中可以看出:“渐进显著性为0.003,由于0.003<0.01 所以得出结论:H1:不同地区的儿童,身高分布是不同的。

Kruskal-Wallis检验的使用技巧统计学中,Kruskal-Wallis检验是一种用于比较三个或更多组之间差异的非参数检验方法。
与方差分析相比,Kruskal-Wallis检验不需要满足数据正态分布的假设,因此在样本数据不满足正态分布的情况下,Kruskal-Wallis检验是一种很好的选择。
本文将介绍Kruskal-Wallis检验的使用技巧,帮助读者更好地理解和应用这一方法。
1. 概述Kruskal-Wallis检验Kruskal-Wallis检验是基于秩和的非参数检验方法,用于比较三个或更多组的中位数差异。
它的零假设是所有总体的中位数相等,备择假设是至少有一组的中位数不同。
在进行Kruskal-Wallis检验时,首先需要对每组的数据进行合并,然后计算秩次和,最后根据秩次和的大小来判断组间的差异是否显著。
2. 数据的准备在进行Kruskal-Wallis检验之前,需要准备好各组的数据。
确保数据的测量尺度是至少顺序尺度,且是独立互不相关的。
另外,样本量不宜过小,以确保检验的可靠性。
如果样本量较小,建议采用其他非参数检验方法,如Mann-Whitney U检验。
3. 检验的假设在进行Kruskal-Wallis检验之前,需要明确检验的假设。
零假设是各组的总体中位数相等,备择假设是至少有一组的总体中位数不同。
根据备择假设的不同,可以进行单侧或双侧的检验。
4. 统计分析软件的选择进行Kruskal-Wallis检验时,需要选择适当的统计分析软件进行计算。
常见的统计软件如SPSS、R、Python等均能进行Kruskal-Wallis检验,读者可以根据自己的偏好和需要选择合适的软件进行分析。
5. 结果的解释进行Kruskal-Wallis检验后,需要对结果进行解释。
通常会得到秩次和、自由度和显著性水平等统计量。
根据显著性水平的大小,来判断组间的差异是否显著。
如果显著性水平小于设定的显著性水平(通常为),则拒绝零假设,认为组间存在显著差异。
SPSS非参数检验—两独立样本检验_案例解析非参数检验是一种不基于总体分布特征的统计方法,适用于数据分布未知、非正态分布或无法满足参数检验假设的情况。
其中一种非参数检验是两独立样本检验,用于比较两组独立样本之间的统计差异。
本篇文章将结合案例解析,详细介绍SPSS软件中如何进行非参数检验的两独立样本检验。
案例背景:工厂生产两种不同形状的零件,为了比较两种零件的尺寸是否存在差异,随机选取了30个零件进行测量。
现在需要使用两独立样本检验来研究这两种零件的尺寸是否存在显著差异。
步骤一:数据导入首先,将收集到的数据导入SPSS软件中。
数据包括两个变量:零件类型(Group)和尺寸(Size)。
将数据按照Excel或CSV格式保存,然后在SPSS中选择"文件"->"导入"->"数据",选择导入文件,并进行数据格式定义。
步骤二:描述性统计分析在进行假设检验之前,首先进行描述性统计分析,以了解样本数据的基本特点。
在SPSS中,选择"分析"->"描述性统计"->"描述性统计",将"Size"变量拖入"变量"框中,然后点击"统计"按钮,选择要统计的统计量(如均值、标准差等),最后点击"确定"按钮进行计算。
步骤三:正态性检验在进行非参数检验之前,需要进行正态性检验,以确定数据是否满足参数检验的假设。
在SPSS中,选择"分析"->"非参数检验"->"单样本分布检验",将"Size"变量拖入"变量"框中,然后点击"选项"按钮,选择要进行的正态性检验方法,如Kolmogorov-Smirnov检验或Shapiro-Wilk检验等。
Kruskal-Wallis H检验(多个独立样本)【详】-SPSS教程一、问题与数据某研究者认为工作年限多的人能更好地应对职场的压力。
为了验证这一假设,某研究招募了31名研究对象,调查了他们的工作年限,并测量了他们应对职场压力的能力。
根据工作年限,研究对象被分为4组:0-5年、6-10年、11-15年、>16年(变量名为working_time)。
利用Likert量表调查的总得分(CWWS得分)来评估应对职场压力的能力,分数越高,表明应对职场压力的能力越强(变量名为stress_score)。
部分数据如图1。
图1 部分数据二、对问题分析研究者想知道不同工作年限之间CWWS得分是否不同。
由于CWWS得分不服从正态分布(仅为模拟数据,实际使用时需要专业判断或结合正态性检验结果),因此可以使用Kruskal-Wallis H检验。
Kruskal-Wallis H检验(有时也叫做对秩次的单因素方差分析)是基于秩次的非参数检验方法,用于检验多组间(也可以是两组)连续或有序分类变量是否存在差异。
使用Kruskal-Wallis H test检验时,需要考虑以下3个假设。
假设1:有一个因变量,且因变量为连续变量或有序分类变量。
假设2:存在多个分组(≥2个)。
假设3:具有相互独立的观测值。
三、SPSS操作3.1 Kruskal-Wallis H检验在主界面点击Analyze→Nonparametric Tests→Independent Samples,出现Nonparametric Tests: Two or More Independent Samples对话框,默认选择Automatically compare distributions across groups。
如图2。
图2 Nonparametric Tests: Two or More Independent Samples点击Fields,在Fields下方选择Use custom field assignments,将变量stress_score放入Test Fields框中,将变量working_time放入Groups框中。
kruskal-wallis检验方法Kruskal-Wallis检验方法。
Kruskal-Wallis检验是一种非参数检验方法,用于比较三个以上独立样本的中位数是否存在显著差异。
它是对方差分析的一种推广,适用于数据不满足正态分布的情况。
在实际应用中,Kruskal-Wallis检验常常用于医学、生物学、社会科学等领域的数据分析中。
首先,我们来了解一下Kruskal-Wallis检验的基本原理。
假设我们有k个独立样本,每个样本的大小分别为n1,n2,…,nk。
我们的原假设是所有样本的总体中位数相等,备择假设是至少有一个样本的总体中位数不相等。
Kruskal-Wallis检验的统计量H计算方法如下:H = (12 / (N(N+1))) Σ(Rj^2 / nj) 3(N+1)。
其中,Rj为第j个样本的秩和,nj为第j个样本的大小,N为总样本大小。
在原假设成立的情况下,H近似服从自由度为k-1的卡方分布。
我们可以通过查找卡方分布表或使用统计软件来计算出对应的p值,从而进行假设检验。
接下来,我们将介绍Kruskal-Wallis检验的具体步骤。
首先,我们需要对所有样本的数据进行合并,并对合并后的数据进行排序。
然后,我们为每个数据点标记秩,即从1到N。
在存在重复数值的情况下,我们取其平均秩。
接着,我们计算每个样本的秩和,并代入到H的计算公式中。
最后,我们根据计算得到的H值和自由度进行假设检验,判断样本中位数是否存在显著差异。
在实际应用中,Kruskal-Wallis检验常常与多重比较方法结合使用,以确定具体哪些样本的中位数存在显著差异。
常见的多重比较方法包括Dunn法、Conover-Iman法等。
此外,Kruskal-Wallis检验也可以用于分析有序分类数据,如评分、排名等。
需要注意的是,Kruskal-Wallis检验对样本的独立性要求较高,如果存在样本间的相关性,可能会导致检验结果的不准确性。
因此,在进行Kruskal-Wallis检验前,我们需要对数据的独立性进行充分的检查。
多个独立样本比较的秩和检验(Kruskal-WallisH)Kruskal-Walis H检验,用于推断计量资料或等级资料的多个独立样本所来自的多个总体分布是否有差别。
在理论上检验假设H0为总体分布位置相同。
例题比较小白鼠接种三种不同菌型伤寒杆菌9D、11C、和DSC1后存活日数,结果见下表。
问小白鼠接种三种不同菌型伤寒杆菌的存活日数有无差别?9D 11C DSC125325526636646647748751097121071111SPSS操作组别:9D=1,11C=2,DSC1=3。
1建立数据库2SPPS操作分析——非参数检验——K个独立样本3结果解释H=9.94,P=0.007,按照α=0.05的检验标准,拒绝H0,接受H1,可以认为小白鼠接种不同菌型伤寒杆菌的存活日数有差别。
两两比较经过Kruskal-Wallis H检验可知三组的总体分布位置不同,若要进一步推断是哪两两总体分布位置不同时,可用Nemenyi法检验。
Nemenyi法在SPSS中没有直接的窗口操作,需要利用SPSS编程实现。
1编辑程序文件——新建——语法2程序代码HC表示总体检验的H值,r1,r2,r3分别表示三组的平均秩次,N,n1,n2,n3分别表示总例数和三组例数。
data list free/Hc r1 r2 r3 N n1 n2 n3 .begin data9.94 8.4 18.78 19.27 30 10 9 11end data.computeH=(12*((r1*n1)**2/n1+(r2*n2)**2/n2+(r3*n3)**2/n3))/(N*(N+1)) -3*(N+1).compute c=H/Hc.compute x12=(r1-r2)**2/((N*(N+1)/12)*(1/n1+1/n2)*c).compute x13=(r1-r3)**2/((N*(N+1)/12)*(1/n1+1/n3)*c).compute x23=(r2-r3)**2/((N*(N+1)/12)*(1/n2+1/n3)*c).compute p12=1-cdf.chisq(x12,2).compute p13=1-cdf.chisq(x13,2).compute p23=1-cdf.chisq(x23,2).execute.3结果解释运行——全部卡方P两两比较9D和6.70 0.0411C8.13 0.029D和DSC111C和0.02 0.69DSC19D和11C、DCSI组伤寒杆菌存活天数有统计学差异,11C组和DSC1组没有统计学差异。
matlab两组独立样本等级资料kruskal-wallis h假设检验方法文章标题:深度解析MATLAB中的两组独立样本等级资料Kruskal-Wallis H假设检验方法在统计学中,Kruskal-Wallis H检验是一种用于比较两个或多个独立组的等级资料的非参数假设检验方法。
在MATLAB中,我们可以利用这种方法来进行统计分析,并得出对应的假设检验结果。
本文将从简到繁地介绍Kruskal-Wallis H检验的基本原理,然后结合MATLAB 的实际操作,以帮助读者更加全面、深入地理解这一统计分析方法。
1. Kruskal-Wallis H检验的基本原理Kruskal-Wallis H检验是一种用于比较两个或多个独立组的等级资料的非参数假设检验方法。
当我们需要比较多个组的数据时,无法满足方差分析等条件的情况下,可以使用Kruskal-Wallis H检验来判断这些组是否具有差异。
其原假设为各组样本来自同一总体,备择假设为不是来自同一总体。
2. MATLAB中的Kruskal-Wallis H检验函数在MATLAB中,我们可以使用“kruskalwallis”函数来进行Kruskal-Wallis H检验。
该函数的语法为:[p, tbl, stats] = kruskalwallis(x,group),其中x为一个包含所有数据的向量,group为一个指示每个数据所属组别的向量。
该函数将返回假设检验的p值以及其他相关统计信息。
3. 实际操作及结果解释接下来,我们将给出一个具体的例子来演示如何使用MATLAB中的Kruskal-Wallis H检验函数。
假设我们有三个组的等级资料数据,分别为组A、组B和组C。
我们首先将这些数据输入到MATLAB中,并使用“kruskalwallis”函数进行假设检验。
假设检验的结果显示p值为0.032,小于显著性水平0.05,因此我们拒绝原假设,可以认为这三组数据具有显著差异。
Kruskal-Wallis检验的使用技巧Kruskal-Wallis检验是一种非参数检验方法,用于比较三个以上独立样本的中位数是否相同。
在实际应用中,Kruskal-Wallis检验常常被用于比较不同组别的样本的总体中位数是否有显著差异。
本文将介绍Kruskal-Wallis检验的使用技巧,包括数据准备、假设检验和结果解释等方面。
数据准备在进行Kruskal-Wallis检验之前,首先需要进行数据的准备工作。
具体而言,需要收集三个以上独立样本的数据,并对数据进行整理和清理。
在整理数据的过程中,需要注意检查数据是否符合Kruskal-Wallis检验的前提条件,即数据应当是来自对称分布的总体。
如果数据不符合这一前提条件,可能需要进行数据变换或者选择其他适合的统计方法。
假设检验进行Kruskal-Wallis检验时,需要先建立相应的假设。
在Kruskal-Wallis检验中,零假设是各组总体的中位数相等,备择假设是各组总体的中位数不全相等。
接着,进行检验统计量的计算,并根据该统计量的分布情况,计算P值以得出检验结果。
通常情况下,P值小于显著性水平(通常为)时,可以拒绝零假设,认为各组总体的中位数有显著差异。
结果解释在得出Kruskal-Wallis检验的结果之后,需要进行相应的结果解释。
如果P 值小于显著性水平,可以拒绝零假设,认为各组总体的中位数有显著差异。
此时,可以进一步进行事后比较分析,以确定具体哪些组别之间存在差异。
如果P值大于显著性水平,则不能拒绝零假设,即无法得出各组总体中位数有显著差异的结论。
应用技巧在进行Kruskal-Wallis检验时,需要注意一些应用技巧。
首先,应当注意样本量的大小。
当样本量较小的时候,Kruskal-Wallis检验可能会失去一些效应,因此在这种情况下可能需要考虑其他检验方法。
其次,需要注意分组的合理性。
在进行Kruskal-Wallis检验之前,需要对分组变量进行合理的划分,以确保各组之间存在一定的差异性。
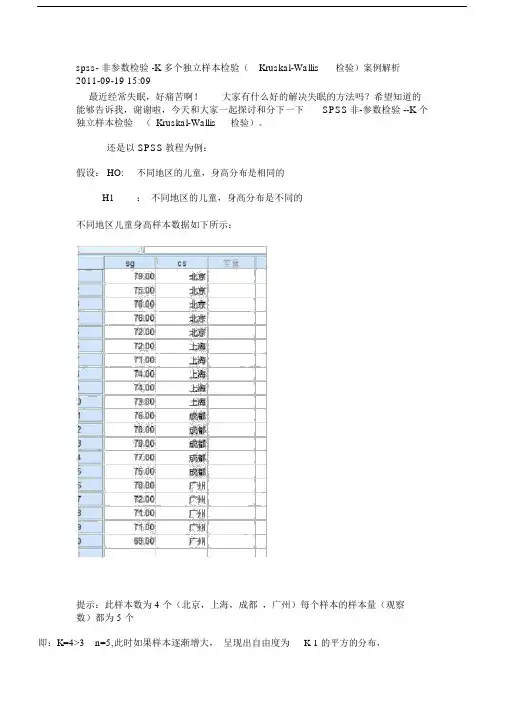
spss-非参数检验-K多个独立样本检验( Kruskal-Wallis检验)案例解析2011-09-19 15:09
最近经常失眠,好痛苦啊!大家有什么好的解决失眠的方法吗?希望知道的能够告诉我,谢谢啦,今天和大家一起探讨和分下一下SPSS-非参数检验--K个独立样本检验( Kruskal-Wallis检验)。
还是以SPSS教程为例:
假设:HO: 不同地区的儿童,身高分布是相同的
H1:不同地区的儿童,身高分布是不同的
不同地区儿童身高样本数据如下所示:
提示:此样本数为4个(北京,上海,成都,广州)每个样本的样本量(观察数)都为5个
即:K=4>3 n=5, 此时如果样本逐渐增大,呈现出自由度为K-1的平方的分布,(即指:卡方检验)
点击“分析”——非参数检验——旧对话框——K个独立样本检验,进入如下界面:
将“周岁儿童身高”变量拖入右侧“检验变量列表”内,将“城市(CS)变量” 拖入“分组变量”内,点击“定义范围” 输入“最小值”和“最大值”(这里的变量类型必须为“数字型”)如果不是数字型,必须要先定义或者重新编码。
在“检验类型”下面选择“秩和检验”( Kruskal-Wallis检验)点击确定
运行结果如下所示:
对结果进行分析如下:
1:从“检验统计量a,b”表中可以看出:秩和统计量为:13.900
自由度为:3=k-1=4-1
下面来看看“秩和统计量”的计算过程,如下所示:
假设“秩和统计量”为 kw 那么:
其中:n+1/2 为全体样本的“秩平均” Ri./ni 为第i个样本的秩平均 Ri.代表第i个样本的秩和, ni代表第i个样本的观察数)
最后得到的公式为:
北京地区的“秩和”为:秩平均*观察数(N) = 14.4*5=72
上海地区的“秩和”为:8.2*5=41
成都地区的“秩和”为:15.8*5=79
广州地区的“秩和”为:3.6*5=18
接近13.90 (由于中间的计算,我采用四舍五入,丢弃了部分数值,所以,会有部分误差)
2:“检验统计量a,b”表中可以看出:“渐进显著性为0.003,由于
0.003<0.01 所以得出结论:
H1:不同地区的儿童,身高分布是不同的。