统计学第四版贾俊平人大_回归与时间序列stata
- 格式:doc
- 大小:1.36 MB
- 文档页数:38
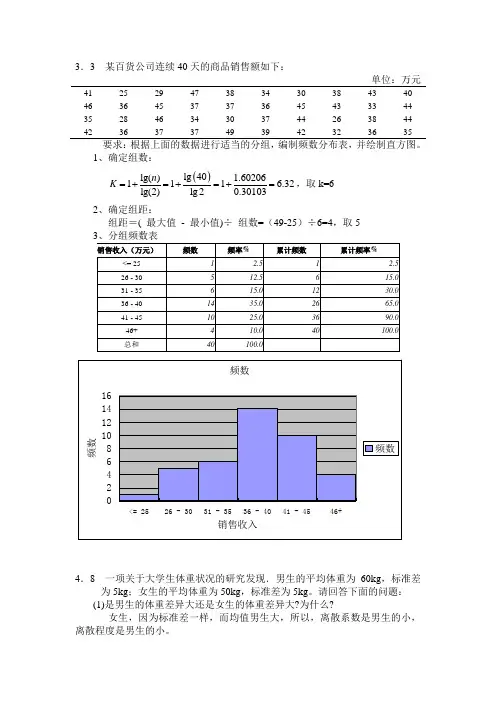
3.3 某百货公司连续40天的商品销售额如下:单位:万元41 25 29 47 38 34 30 38 43 40 46 36 45 37 37 36 45 43 33 44 35 28 46 34 30 37 44 26 38 44 42363737493942323635要求:根据上面的数据进行适当的分组,编制频数分布表,并绘制直方图。
1、确定组数: ()lg 40lg() 1.60206111 6.32lg(2)lg 20.30103n K =+=+=+=,取k=6 2、确定组距:组距=( 最大值 - 最小值)÷ 组数=(49-25)÷6=4,取54.8 一项关于大学生体重状况的研究发现.男生的平均体重为60kg ,标准差为5kg ;女生的平均体重为50kg ,标准差为5kg 。
请回答下面的问题: (1)是男生的体重差异大还是女生的体重差异大?为什么?女生,因为标准差一样,而均值男生大,所以,离散系数是男生的小,离散程度是男生的小。
(2)以磅为单位(1ks=2.2lb),求体重的平均数和标准差。
都是各乘以2.21,男生的平均体重为60kg×2.21=132.6磅,标准差为5kg ×2.21=11.05磅;女生的平均体重为50kg×2.21=110.5磅,标准差为5kg×2.21=11.05磅。
(3)粗略地估计一下,男生中有百分之几的人体重在55kg一65kg之间?计算标准分数:Z1=x xs-=55605-=-1;Z2=x xs-=65605-=1,根据经验规则,男生大约有68%的人体重在55kg一65kg之间。
(4)粗略地估计一下,女生中有百分之几的人体重在40kg~60kg之间?计算标准分数:Z1=x xs-=40505-=-2;Z2=x xs-=60505-=2,根据经验规则,女生大约有95%的人体重在40kg一60kg之间。

统计学第四版贾俊平人大-回归与时间序列stata回归分析与时间序列一、一元线性回归11.1 (1)编辑数据集,命名为linehuigui1.dat输入命令scatter cost product,xlabel(#10, grid) ylabel(#10, grid),得到如下散点图,可以看到,产量和生产费用是正线性相关的关系。
(2)输入命令reg cost product,得到如下图:可得线性函数(product为自变量,cost为因变量):y=0.4206832x+124.15,即β0=124.15,β1=0.4206832(3)对相关系数的显著性进行检验,可输入命令pwcorr cost product, sig star(.05) print(.05),得到下图:可见,在α=0.05的显著性水平下,P=0.0000<α=0.05,故拒绝原假设,即产量和生产费用之间存在显著的正相关性。
11.2 (1)编辑数据集,命名为linehuigui2.dat输入命令scatter fenshu time,xlabel(#4, grid) ylabel(#4, grid),得到如下散点图,可以看到,分数和复习时间是正线性相关的关系。
2)输入命令cor fenshu time计算相关系数,得下图:可见,r=0.8621,可见分数和复习时间之间存在高度的正相关性。
11.3 (1)(2)对于线性回归方程y=10-0.5x,其中β0=10,表示回归直线的截距为10;β1=-0.5,表示x变化一单位引起y的变化为-0.5。
(3)x=6时,E(y)=10-0.5*6=7。
11.4 (1)R2=SSRSST =SSRSSR+SSE=3636+4=0.9,判定系数R2测度了回归直线对观测数据的拟合程度,即在分数的变差中,有90%可以由分数与复习时间之间的线性关系解释,或者说,在分数取值的变动中,有90%由复习时间决定。

假设检验作业8.1 小样本、方差已知的均值校验已知:总体服从N(4.55,0.1082);n=9;x =4.484;α=0.05假设:H 0:μ=4.55;H 1:μ≠4.55。
利用stata 求Z 统计量:display z=(4.484-4.55)/(0.108/sqrt(9)) 又83.1=Z <96.12/±=αZ 故原假设能接受,即现在生产的铁水平均含碳量为4.55。
8.2 大样本的均值校验已知:总体服从N(700,602);n=36;x =680;α=0.05假设:H 0:μ≥700;H 1:μ<700。
利用stata 求Z 统计量:display (680-700)/(60/sqrt(36)) 又2=Z >αZ =1.64,故原假设不能接受,即这批元件不合格。
8.3 小样本、方差已知的均值校验已知:总体服从N(250,302);n=25;x =270;α=0.05假设:H 0:μ≥250;H 1:μ<250。
利用stata 求Z 统计量:display (270-250)/(30/sqrt(25)) 又Z =3.33>αZ =1.64,故原假设不能接受,即这种化肥使小麦增产不明显。
8.4 小样本、方差未知的均值校验已知:总体服从N(100,σ2);n=9;Xi(i=1,2,3,4,5,6,7,8,9);α=0.05假设:H 0:μ=100;H 1:μ≠100。
利用stata 新建weight.dta 输入数据:编写程序求t 统计量:clearuse weightlist weightegen wgt1=mean(weight)egen sd=sd(weight)display (wgt1-100)/(sqrt(sd)/sqrt(9))又Z=0.06<2/αZ=1.96,故原假设能接受,即该打包机工作正常。
8.5 大样本的比例校验假设:H0:π≤5%;H1:π>5%。

统计学(第四版)贾俊平复习资料名词解释概念课后思考题答案l.获得数据的概率抽样方法有哪些?(1)简单随机抽样简单随机抽样又称纯随机抽样,是指在特定总体的所有单位中直接抽取n个组成样本。
它最直观地体现了抽样的基本原理,是最基本的概率抽样。
<2)系统抽样系统抽样也称等距抽样或机械抽样,是按一定的间隔距离抽取样本的方法。
(3)分层抽样分层抽样也叫分类抽样,就是先将总体的所有单位依照一种或几种特征分为若干个子总体,每一个子总体即为一类,然后从每一类中按简单随机抽样或系统随机抽样的办法抽取一个子样本,称为分类样本,它们的集合即为总体样本。
(4)整群抽样整群抽样又称聚类抽样或集体抽样,是将总体按照某种标准划分为一些群体,每一个群体为一个抽样单位,再用随机的方法从这些群体中抽取若干群体,并将所抽出群体中的所有个体集合为总体的样本。
(5)多阶段抽样多阶段抽样又称多级抽样或分段抽样,就是把从总体中抽取样本的过程分成两个或多个阶段进行的抽样方法。
2.茎叶图与直方图相比有什么优点?它们的应用场合是什么?茎叶图与直方图相比,茎叶图既能给出数据的分布状况,又能给出每一个原始数值,即保留了原始数据的信息。
而直方图虽然能很好地显示数据的分布,但不能保留原始的数值。
在应用方面,直方图通常适用于大批量数据,茎叶图通常适用于小批量数据。
3鉴别图标优劣的准则1精心设计,有助于洞察问题的实质。
2使复杂的观点得到简明、确切、高效的阐述。
3能在最短的时间内以最少的笔墨给读者提供最大量的信息。
4是多维的。
5表述数据的真实情况。
4.一组数据的分布特征可以从哪几个方面进行测量?答:数据分布的特征可以从三个方面进行测度和描述:一是分布的集中趋势,反映各数据向其中心值靠拢或聚集的程度;二是分布的离散程度,反映各数据远离其中心值的趋势;三是分布的形状,反映数据分布的偏态和峰态。
这三个方面分别反映了数据分布特征的不同侧面。
5. 标准分数有哪些用途?标准分数给出了一组数据中各数值的相对位置。

stata时间序列回归步骤命令1.引言1.1 概述概述部分的内容:时间序列回归是一种经济学和统计学领域中常用的分析方法,用于研究随时间变化的因果关系。
它涉及使用时间上的观测数据来分析自变量和因变量之间的关系,并预测未来的值。
Stata是一种功能强大的统计软件,广泛用于数据分析和经济研究。
在Stata中,有一系列的命令可供使用,用于进行时间序列回归分析。
本文将介绍使用Stata进行时间序列回归分析的步骤和相应的命令。
通过学习这些命令,读者将能够熟练地使用Stata进行时间序列回归分析,并获得准确和可靠的结果。
本文主要包括以下章节内容:1. 引言部分介绍了时间序列回归的概述、文章结构和目的,旨在帮助读者全面了解本文内容。
2. 正文部分将详细介绍时间序列回归的概念和原理,并介绍Stata中的时间序列回归命令。
这些命令包括数据准备、建立模型、模型估计和统计推断等步骤。
3. 结论部分对本文进行总结,并展望时间序列回归在未来的应用前景。
同时,还会指出时间序列回归分析中可能存在的局限性,以及可能的改进方向。
通过本文的学习,读者将了解时间序列回归分析的基本概念和步骤,掌握对时间序列数据进行回归分析的方法和技巧,并能够运用Stata软件进行实际的分析工作。
1.2文章结构文章结构(Article Structure)本文将按照以下结构进行叙述。
第一部分为引言部分,目的是对时间序列回归步骤命令进行一个概述,并说明本文的目的。
接下来,第二部分将详细介绍时间序列回归的概念和一般步骤,并使用stata命令进行说明。
同时,本文还将重点介绍两个关键要点,这些要点对于正确进行时间序列回归分析非常重要。
最后,第三部分为结论,将总结本文的主要内容,并展望一下未来可能的研究方向。
在正文部分,我们将首先概述时间序列回归的基本概念,并提供了一个对该方法的整体认识。
然后,我们将详细介绍stata时间序列回归步骤命令的使用方法,包括数据导入、变量设定、模型拟合和结果解释等。

统计学完整(贾俊平)人大课件ppt课件•引言•数据收集与整理•描述性统计分析目录•概率论基础•推断性统计分析•方差分析与回归分析•时间序列分析与预测•统计决策与风险管理目录•总结与展望01引言统计学是一门研究如何收集、整理、分析和解释数据的科学。
统计学的定义统计学的历史统计学的分支统计学的发展经历了古典统计学、近代统计学和现代统计学三个阶段。
统计学可以分为描述统计学和推断统计学两大分支。
030201统计学概述社会科学医学与健康工程与技术商业与经济统计学应用领域01020304在社会科学领域,统计学被广泛应用于调查研究、民意测验、市场分析等方面。
在医学和健康领域,统计学被用于临床试验、流行病学研究、健康风险评估等方面。
在工程和技术领域,统计学被用于质量控制、可靠性分析、信号处理等方面。
在商业和经济领域,统计学被用于市场分析、财务分析、经济预测等方面。
通过学习,学生应掌握统计学的基本概念和方法,包括数据收集、整理、描述和分析等方面的内容。
掌握统计学基本概念和方法具备数据处理和分析能力了解统计学的应用领域培养批判性思维学生应具备独立处理和分析数据的能力,能够运用适当的统计方法进行数据分析和解释。
学生应了解统计学的应用领域,能够运用所学知识解决实际问题。
学生应培养批判性思维,能够对统计结果进行合理的解释和评估。
学习目标与要求02数据收集与整理数据来源及类型数据来源包括原始数据和二手数据,原始数据是通过直接调查、实验或观察获得的数据;二手数据则是已经经过他人收集、整理和处理过的数据。
数据类型包括定性数据和定量数据,定性数据是描述性的、非数值的,如文字、图像等;定量数据则是可以用数值表示的,如年龄、收入等。
此外,还可以根据数据的测量尺度将其分为名义型数据、顺序型数据、间隔型数据和比率型数据。
调查法实验法观察法大数据收集数据收集方法通过问卷、访谈、电话调查等方式收集数据,可以获取大量的、详细的信息。
直接观察研究对象的行为、状态等,记录相关数据,适用于无法控制或干预的情况。

课件•引言•统计数据的收集与整理•统计描述目•概率论基础•统计推断录•统计指数与因素分析•相关与回归分析•统计决策目•统计学的应用与发展录引言统计学概述统计学的定义统计学的发展历史统计学的分支领域1 2 3统计学在决策中的应用统计学在科学研究中的应用统计学在社会生活中的应用统计学的重要性统计学的研究对象01020304数据的收集数据的整理数据的分析数据的解释统计数据的收集与整理原始数据二手数据定性数据定量数据时序数据030201数据的收集方法观察法调查法实验法数据的整理与显示数据整理数据显示通过图表、图像等方式将数据呈现出来,以便于直观理解和分析。
常见的数据显示方式包括表格、条形图、折线图、饼图等。
统计描述集中趋势的描述算术平均数适用于数值型数据,反映数据的平均水平。
中位数适用于顺序数据,反映数据的中等水平。
众数适用于分类数据,反映数据的多数水平。
离散程度的描述四分位数间距极差上四分位数与下四分位数之差,反映中间50%数据的离散程度。
方差与标准差分布形态的描述偏态峰态统计图表的应用适用于分类数据,表示各类别的频数或频率。
适用于时间序列数据,表示事物随时间的变化趋势。
适用于分类数据,表示各类别在总体中的占比。
适用于两个数值型变量,表示它们之间的相关关系。
条形图折线图饼图散点图概率论基础随机事件与概率随机试验与样本空间随机试验是具有某些基本特点的试验,其所有可能结果构成的集合称为样本空间。
随机事件随机试验的某个(些)样本点构成的集合称为随机事件。
概率的定义概率是描述随机事件发生的可能性大小的数值,常用P(A)表示。
概率的性质与运算法则概率的性质01概率的加法公式02概率的乘法公式03事件的独立性如果事件A 与事件B 相互独立,则P(A∩B)=P(A)P(B)。
条件概率在事件B 发生的条件下,事件A 发生的概率称为条件概率,记作P(A|B)。
多个事件的独立性如果事件A1,A2,...,An 相互独立,则对于任意k 个事件Ai1,Ai2,...,Aik(1≤i1<i2<...<ik≤n),都有P(Ai1∩Ai2∩...∩Aik)=P(Ai1)P(Ai2)...P(Aik)。


统计学课件贾俊平人大课件•课件背景与目标•统计学基本概念•数据收集与整理目•统计描述分析•概率论基础与抽样分布录•参数估计与假设检验•非参数统计方法•统计决策与预测目•统计软件应用与实践录课件背景与目标贾俊平,中国人民大学统计学系教授,具有丰富的统计学教学和科研经验。
作者背景课件来源适用对象该课件是贾俊平教授在人大授课时所使用的教学材料,经过整理和优化后形成。
适用于统计学专业的学生、教师以及对统计学感兴趣的人士。
030201背景介绍掌握统计学的基本概念、原理和方法,能够运用统计学知识解决实际问题。
知识与技能通过案例分析、实践操作等方式,培养学生的统计思维和实践能力。
过程与方法培养学生对统计学的兴趣和热爱,认识到统计学在各个领域的重要性和应用价值。
情感态度与价值观教学目标与要求教材《统计学》(贾俊平等编著),该教材系统介绍了统计学的基本理论和方法,是该课件的主要参考教材。
参考资料包括相关统计学著作、学术论文、案例分析等,为学生提供更广泛的学习资源和参考。
网络资源推荐一些优质的统计学学习网站、在线课程等,方便学生进行自主学习和拓展。
教材与参考资料统计学基本概念统计学是一门研究数据收集、整理、分析和解释的科学。
统计学具有广泛的应用性,可以应用于各个领域的数据分析。
统计学是一门方法论科学,提供了一套系统的数据处理和分析方法。
统计学的定义与性质02030401统计学的研究对象及方法统计学的研究对象是数据,包括数值数据和分类数据。
统计学的研究方法包括描述统计和推断统计。
描述统计是对数据进行整理、概括和描述的方法。
推断统计是通过样本数据推断总体特征的方法。
总体和样本变量和指标概率和随机性统计量和抽样分布统计学中的基本概念01020304总体是研究对象的全体,样本是从总体中抽取的一部分。
变量是描述现象特征的属性,指标是反映现象数量特征的概念和数值。
概率是某一事件发生的可能性,随机性是指事件发生的不确定性。
统计量是样本的函数,抽样分布是统计量的概率分布。
第1章统计和统计数据1.1 指出下面的变量类型。
(1)年龄。
(2)性别。
(3)汽车产量。
(4)员工对企业某项改革措施的态度(赞成、中立、反对)。
(5)购买商品时的支付方式(现金、信用卡、支票)。
详细答案:(1)数值变量。
(2)分类变量。
(3)数值变量。
(4)顺序变量。
(5)分类变量。
1.2 一家研究机构从IT从业者中随机抽取1000人作为样本进行调查,其中60%回答他们的月收入在5000元以上,50%的人回答他们的消费支付方式是用信用卡。
(1)这一研究的总体是什么?样本是什么?样本量是多少?(2)“月收入”是分类变量、顺序变量还是数值变量?(3)“消费支付方式”是分类变量、顺序变量还是数值变量?详细答案:(1)总体是“所有IT从业者”,样本是“所抽取的1000名IT从业者”,样本量是1000。
(2)数值变量。
(3)分类变量。
1.3 一项调查表明,消费者每月在网上购物的平均花费是200元,他们选择在网上购物的主要原因是“价格便宜”。
(1)这一研究的总体是什么?(2)“消费者在网上购物的原因”是分类变量、顺序变量还是数值变量?详细答案:(1)总体是“所有的网上购物者”。
(2)分类变量。
1.4 某大学的商学院为了解毕业生的就业倾向,分别在会计专业抽取50人、市场营销专业抽取30、企业管理20人进行调查。
(1)这种抽样方式是分层抽样、系统抽样还是整群抽样?(2)样本量是多少?详细答案:(1)分层抽样。
(2)100。
第3章用统计量描述数据为7.2分钟,标准差为1.97分钟,第二种排队方式的等待时间(单位:分钟)如下:5.56.6 6.7 6.87.1 7.3 7.4 7.8 7.8(1)计算第二种排队时间的平均数和标准差。
(2)比两种排队方式等待时间的离散程度。
(3)如果让你选择一种排队方式,你会选择哪一种?试说明理由。
详细答案:(1)(岁);(岁)。
(2);。
第一中排队方式的离散程度大。
(3)选方法二,因为平均等待时间短,且离散程度小。
统计学课件(贾俊平)人大课件contents •统计学概述•统计数据的收集与整理•统计描述分析•统计推断分析•统计决策分析•统计软件应用与实践目录统计学概述统计学的定义与特点定义统计学是一门研究数据收集、整理、分析和解释的方法论科学,旨在探索数据内在的数量规律性。
特点统计学具有广泛的应用性、严密的数学性和明确的目的性。
它通过收集和分析数据来揭示总体特征,为决策提供依据。
03现代统计学时期计算机技术的广泛应用,使得大规模数据处理和复杂模型分析成为可能,推动了统计学的快速发展。
01古典统计学时期主要关注国家管理和人口统计,如古希腊、罗马和中国的古代统计实践。
02近代统计学时期概率论和数理统计学的形成与发展,为现代统计学奠定了基础。
统计学的发展历史统计学的研究对象与分类研究对象统计学的研究对象是数据,包括各种类型、来源和形式的数据。
分类根据研究目的和方法的不同,统计学可分为描述统计学和推断统计学两大类。
描述统计学主要关注数据的整理、描述和可视化;推断统计学则通过样本数据推断总体特征。
社会经济领域生物医药领域工程技术领域环境科学领域统计学的应用领域人口普查、经济分析、市场调研等。
质量控制、可靠性分析、优化设计等。
临床试验、基因测序、流行病学调查等。
环境监测、生态评估、气候变化研究等。
统计数据的收集与整理数据的来源与类型数据来源包括直接来源(如调查、实验)和间接来源(如文献资料、网络数据)。
数据类型包括定性数据和定量数据,其中定量数据又可分为离散型和连续型。
数据收集的方法与步骤方法包括问卷调查、访谈、观察、实验等。
步骤明确调查问题、确定调查对象、选择调查方法、设计调查问卷或实验方案、实施调查或实验、收集并整理数据。
数据整理的原则与方法原则确保数据的准确性、完整性、及时性和一致性。
方法包括数据清洗(如去除重复、异常值处理)、数据转换(如标准化、归一化)、数据分组与编码等。
数据质量的评估与控制评估指标包括准确性、完整性、及时性、一致性、可比性和可解释性等。
统计课后思考题答案第一章思考题1.1什么是统计学统计学是关于数据的一门学科,它收集,处理,分析,解释来自各个领域的数据并从中得出结论。
1.2解释描述统计和推断统计描述统计;它研究的是数据收集,处理,汇总,图表描述,概括与分析等统计方法。
推断统计;它是研究如何利用样本数据来推断总体特征的统计方法。
1.3统计学的类型和不同类型的特点统计数据;按所采用的计量尺度不同分;(定性数据)分类数据:只能归于某一类别的非数字型数据,它是对事物进行分类的结果,数据表现为类别,用文字来表述;(定性数据)顺序数据:只能归于某一有序类别的非数字型数据。
它也是有类别的,但这些类别是有序的。
(定量数据)数值型数据:按数字尺度测量的观察值,其结果表现为具体的数值。
统计数据;按统计数据都收集方法分;观测数据:是通过调查或观测而收集到的数据,这类数据是在没有对事物人为控制的条件下得到的。
实验数据:在实验中控制实验对象而收集到的数据。
统计数据;按被描述的现象与实践的关系分;截面数据:在相同或相似的时间点收集到的数据,也叫静态数据。
时间序列数据:按时间顺序收集到的,用于描述现象随时间变化的情况,也叫动态数据。
1.4解释分类数据,顺序数据和数值型数据答案同1.31.5举例说明总体,样本,参数,统计量,变量这几个概念对一千灯泡进行寿命测试,那么这千个灯泡就是总体,从中抽取一百个进行检测,这一百个灯泡的集合就是样本,这一千个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是参数,这一百个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是统计量,变量就是说明现象某种特征的概念,比如说灯泡的寿命。
1.6变量的分类变量可以分为分类变量,顺序变量,数值型变量。
变量也可以分为随机变量和非随机变量。
经验变量和理论变量。
1.7举例说明离散型变量和连续性变量离散型变量,只能取有限个值,取值以整数位断开,比如“企业数”连续型变量,取之连续不断,不能一一列举,比如“温度”。
假设查验作业小样本、方差已知的均值校验已知:整体服从N,;n=9;x =;α=假设:H 0:μ=;H 1:μ≠。
利用stata 求Z 统计量:display z=又83.1=Z <96.12/±=αZ 故原假设能同意,即此刻生产的铁水平均含碳量为。
大样本的均值校验已知:整体服从N(700,602);n=36;x =680;α= 假设:H 0:μ≥700;H 1:μ<700。
利用stata 求Z 统计量:display (680-700)/(60/sqrt(36))又2=Z >αZ =,故原假设不能同意,即这批元件不合格。
小样本、方差已知的均值校验已知:整体服从N(250,302);n=25;x =270;α=假设:H 0:μ≥250;H 1:μ<250。
利用stata 求Z 统计量:display (270-250)/(30/sqrt(25))又Z =>αZ =,故原假设不能同意,即这种化肥使小麦增产不明显。
小样本、方差未知的均值校验已知:整体服从N(100,σ2);n=9;Xi(i=1,2,3,4,5,6,7,8,9);α= 假设:H0:μ=100;H1:μ≠100。
利用stata新建输入数据:编写程序求t统计量:clearuse weightlist weightegen wgt1=mean(weight)egen sd=sd(weight)display (wgt1-100)/(sqrt(sd)/sqrt(9))又Z=<2/αZ=,故原假设能同意,即该打包机工作正常。
大样本的比例校验假设:H0:π≤5%;H1:π>5%。
P=6/50=编写程序求Z统计量:cleardisplay 又Z=>αZ=,故原假设不能同意,即该批产品不能出厂。
小样本、方差未知的均值查验假设:H0:μ=25000;H1:μ≠25000。
已知:整体服从N(25000,σ2);n=15;x=27000;s=5000;α=编写程序求t统计量:display (27000-25000)/(5000/sqrt(15))又Z=<2/αZ=,故原假设能同意,即该厂家的广告真实。
第三章节:数据的图表展示…………………………………………………1 第四章节:数据的概括性度量………………………………………………15 第六章节:统计量及其抽样分布……………………………………………26 第七章节:参数估计…………………………………………………………28 第八章节:假设检验…………………………………………………………38 第九章节:列联分析…………………………………………………………41 第十章节:方差分析…………………………………………………………43 3.1 为评价家电行业售后服务的质量,随机抽取了由100个家庭构成的一个样本。
服务质量的等级分别表示为:A .好;B .较好;C 一般;D .较差;E.差。
调查结果如下: B E C C A D C B A E D A C B C D E C E E A D B C C A E D C B B A C D E A B D D C C B C E D B C C B C D A C B C D E C E B B E C C A D C B A E B A C E E A B D D C A D B C C A E D C B C B C E D B C C B C 要求:(1)指出上面的数据属于什么类型。
顺序数据(2)用Excel 制作一张频数分布表。
用数据分析——直方图制作:(3)绘制一张条形图,反映评价等级的分布。
用数据分析——直方图制作: (4)绘制评价等级的帕累托图。
逆序排序后,制作累计频数分布表:接收 频数 频率(%) 累计频率(%) C 32 32 32 B 21 21 53 D 17 17 70 E 16 16 86 A 14 14 1003.2 某行业管理局所属40个企业2002年的产品销售收入数据如下: 152 124 129 116 100 103 92 95 127 104 105 119 114 115 87 103 118 142 135 125 117 108 105 110 107 137 120 136 117 108 97 88 123 115 119 138 112 146 113 126 要求:接收 频率 E 16D 17C 32 B 21 A 14(1)根据上面的数据进行适当的分组,编制频数分布表,并计算出累积频数和累积频率。
回归分析与时间序列一、一元线性回归11.1 (1)编辑数据集,命名为linehuigui1.dat输入命令scatter cost product,xlabel(#10, grid) ylabel(#10, grid),得到如下散点图,可以看到,产量和生产费用是正线性相关的关系。
(2)输入命令reg cost product,得到如下图:可得线性函数(product为自变量,cost为因变量):y=0.4206832x+124.15,即β0=124.15,β1=0.4206832(3)对相关系数的显著性进行检验,可输入命令pwcorr cost product, sig star(.05) print(.05),得到下图:可见,在α=0.05的显著性水平下,P=0.0000<α=0.05,故拒绝原假设,即产量和生产费用之间存在显著的正相关性。
11.2 (1)编辑数据集,命名为linehuigui2.dat输入命令scatter fenshu time,xlabel(#4, grid) ylabel(#4, grid),得到如下散点图,可以看到,分数和复习时间是正线性相关的关系。
2)输入命令cor fenshu time计算相关系数,得下图:可见,r=0.8621,可见分数和复习时间之间存在高度的正相关性。
11.3 (1)(2)对于线性回归方程y=10-0.5x,其中β0=10,表示回归直线的截距为10;β1=-0.5,表示x变化一单位引起y的变化为-0.5。
(3)x=6时,E(y)=10-0.5*6=7。
11.4 (1) ,判定系数 测度了回归直线对观测数据的拟合程度,即在分数的变差中,有90%可以由分数与复习时间之间的线性关系解释,或者说,在分数取值的变动中,有90%由复习时间决定。
可见,两者之间有很强的线性关系。
(2)估计标准误差 分,即根据复习时间来估计分数时,平均的估计误差为0.25分。
11.5 (1)编辑数据集,命名为linehuigui3.dat输入命令scatter time juli,xlabel(#5, grid) ylabel(#5, grid),得到如下散点图,可以看到,时间和距离是正线性相关的关系。
(2)输入命令cor time juli计算相关系数,得下图:可见,r=0.9489,可见时间和距离之间存在高度的正相关性。
(3)输入命令reg time juli得到下图:可得线性函数(juli为自变量,time为因变量):y=0.0035851x+0.1181291,即β0=0.1181291,表示回归直线的截距为0.1181291;β1=0.0035851,表示距离(x)变化1km引起时间(y)的变化为0.0035851天。
11.6 (1)编辑数据集,命名为linehuigui4.dat输入命令scatter cspt GDP,xlabel(#3, grid) ylabel(#3, grid),得到如下散点图,可以看到,时间和距离是正线性相关的关系。
(2)输入命令cor cspt GDP计算相关系数,得下图:可见,r=0.9981,可见人均消费水平和人均GDP之间存在高度的正相关性。
(3)输入命令reg cspt GDP得到下图:可得线性函数(GDP为自变量,cspt为因变量):y=0.3086827x+734.6928,即β0=734.6928,表示回归直线的截距为734.6928;β1=0.3086827,表示人均GDP(x)变化1元引起人均消费水平(y)的变化为0.3086827元。
(4)由(3)得到的结果可得 =0.9963,判定系数 测度了回归直线对观测数据的拟合程度,即在人均消费水平的变差中,有99.63%可以由人均消费水平与人均GDP之间的线性关系解释,或者说,在人均消费水平取值的变动中,有99.63%由人均GDP决定。
可见,两者之间有很强的线性关系。
(5)由(3)得到的结果可得回归方程线性关系的F检验值1331.69对应的检验P值为0.0000<α=0.05,故拒绝原假设,即人均消费水平和人均GDP之间存在显著的正相关性。
(6)x=5000时,E(y)=0.3086827*5000+734.6928=2278.1063。
(7)x=5000时,输入命令predictnl PT=predict(xb),ci(lb ub) l(95),得到各人均GDP 水平下的置信区间,如下图:输入如下命令,得到置信区间和预测区间示意图:predict yhatpredict stdp, stdppredict stdf, stdfgenerate zl = yhat - invttail(5,0.025)*stdpgenerate zu= yhat + invttail(5,0.025)*stdpgenerate yl = yhat - invttail(5,0.025)*stdfgenerate yu = yhat + invttail(5,0.025)*stdftwoway (lfitci cspt GDP, level(95)) (scatter cspt GDP) (line zl zu yl yu GDP, pstyle(p2 p2 p3 p3) sort)取cspt=y,GDP=x,y0为x0=5000的预测值,x1为GDP平均值,x2=(x0-x1)^2,x3= sum((x-x1)^2),,y0=0.3086827*5000+734.6928=2278.1063,egen x1=mean(x),得到x1=12248.429,gen x2=(5000-12248.429)^2,得到x2=52539722.968,egen x3= sum((x-x1)^2),得到x3=854750849.7143display y0+2.7764*247.3*sqrt(1/7+x2/x3),得zu=2588.4671display y0-2.7764*247.3*sqrt(1/7+x2/x3),得zl=1967.7455display y0+2.7764*247.3*sqrt(1+1/7+x2/x3),得yu=3031.5972display y0+2.7764*247.3*sqrt(1+1/7+x2/x3),得yl= 1524.6154即人均GDP为5000元时,人均消费水平95%的置信区间为[1967.7455,2588.4671],预测区间为[1524.6154, 3031.5972]。
11.7 (1)编辑数据集,命名为linehuigui5.dat输入命令scatter cmplts percent,xlabel(#5, grid) ylabel(#5, grid),得到如下散点图,可以看到,时间和距离是负线性相关的关系。
(2)输入命令reg cmplts percent得到下图:可得线性函数(percent为自变量,cmplts为因变量):y=-4.700623x+430.1892,即β0=430.1892,表示回归直线的截距为430.1892;β1=-4.700623,表示航班正点率percent 提高1%使投诉次数cmplts的减少-4.700623次。
(3)由(2)得到的结果可得回归系数检验的t值-4.96对应的P值为0.001<α=0.05,故拒绝原假设,即航班正点率percent是投诉次数cmplts的一个显著因素(或者输入test percent=0)。
(4)x=80时,E(y)=-4.700623*80+430.1892=54.13936次。
(5)x=80时,输入命令predictnl PT=predict(xb),ci(lb ub) l(95),得到各航班正点率水平下的置信区间,如下图:输入如下命令,得到置信区间和预测区间示意图:predict yhatpredict stdp, stdppredict stdf, stdfgenerate zl = yhat - invttail(8,0.025)*stdpgenerate zu= yhat + invttail(8,0.025)*stdpgenerate yl = yhat - invttail(8,0.025)*stdfgenerate yu = yhat + invttail(8,0.025)*stdftwoway (lfitci cmplts percent, level(95)) (scatter cmplts percent) (line zl zu yl yu percent, pstyle(p2 p2 p3 p3) sort)取cmplts=y,percent=x,y0为x0=80的预测值,x1为percent平均值,x2=(x0-x1)^2,x3= sum((x-x1)^2),,y0=-4.700623*80+430.1892=54.13936,egen x1=mean(x),得到x1=12248.429,gen x2=(80-75.86)^2,得到x2= 17.1396,egen x3= sum((x-x1)^2),得到x3=397.024display y0+2.3060*18.887*sqrt(1/10+x2/x3),得zu=70.619033display y0-2.3060*18.887*sqrt(1/10+x2/x3),得zl=37.659687display y0+2.3060*18.887*sqrt(1+1/10+x2/x3),得yu=100.7063display y0-2.3060*18.887*sqrt(1+1/10+x2/x3),得yl= 7.5724171即航班正点率为80%时,投诉次数的95%的置信区间为[37.659687,70.619033],预测区间为[7.5724171, 100.7063]。
11.8 (1)打开一张EXCEL表格,输入数据如下:(2)数据|分析|数据分析|回归,弹出回归对话框并设置如下:(3)单击“确定”得如下输出结果:SUMMARY OUTPUT回归统计Multiple R 0.79508 R Square 0.632151 Adjusted RSquare0.611715 标准误差 2.685819 观测值20 方差分析df SS MS F SignificanceF回归分析 1 223.1403 223.1403 30.93318 2.79889E-05 残差18 129.8452 7.213622总计19 352.9855Coefficients 标准误差t Stat P-value Lower 95% Upper95%下限95.0%上限95.0%Intercept 49.31768 3.805016 12.96123 1.45E-10 41.32363505 57.31172 41.323635 57.31172 X Variable 1 0.249223 0.04481 5.561761 2.8E-05 0.155080305 0.343365 0.1550803 0.343365 Excel输出的回归结果包括以下几个部分:第一部分是“回归统计”,这部分给出了回归分析中的一些常用统计量,包括表中复相关系数Multiple R=0.79508,它是度量复相关程度的指标,取值[0,1]之间,取值越大,表明要素或变量之间的线性相关程度越密切;判定系数R Square=0.632151,表示有63.2151%的出租率可以由每平方米月租金之间的线性关系来解释;调整的决定系数Adjusted R Square=0.611715,表示调整后的判定系数使用了自由度为一个权重因子,即使解释变量增加,如果它与被解释变量无关,则调整后的判定系数不会增加会减少;标准误差,表示各测量值误差的平方的平均值的平方根,故又称为均方误差的平方根,在这里取2.685819(已验证,该值即为 );观测值个数19。