统计学第四版贾俊平人大-回归与时间序列stata
- 格式:docx
- 大小:1.38 MB
- 文档页数:38

与时间序列相关的S T A T A命令及其统计量的解析Document serial number【NL89WT-NY98YT-NC8CB-NNUUT-NUT108】与时间序列相关的S T A T A命令及其统计量的解析残差U 序列相关:①DW 统计量——针对一阶自相关的(高阶无效)STATA 命令:1.先回归2.直接输入dwstat统计量如何看:查表②Q 统计量——针对高阶自相关correlogram-Q-statisticsSTATA 命令:1.先回归reg2.取出残差predict u,residual(不要忘记逗号)3. wntestq u Q统计量如何看:p 值越小(越接近0)Q 值越大——表示存在自相关具体自相关的阶数可以看自相关系数图和偏相关系数图:STATA 命令:自相关系数图:ac u( 残差) 或者窗口操作在 Graphics ——Time-series graphs ——correlogram(ac)偏相关系数图:pac u 或者窗口操作在Graphics——Time-series graphs—— (pac)自相关与偏相关系数以及Q 统计量同时表示出来的方法:corrgram u或者是窗口操作在Statistics——Time-series——Graphs—— Autocorrelations&Partial autocorrelations③LM 统计量——针对高阶自相关STATA 命令:1.先回归reg2.直接输入命令estate bgodfrey,lags(n) 或者窗口操作在 Statistics——Postestimation(倒数第二个)——Reports andStatistics(倒数第二个) ——在里面选择 Breush-Godfrey LM(当然你在里面还可以找到方差膨胀因子还有DW 统计量等常规统计量)LM 统计量如何看:P 值越小(越接近 0)表示越显着(显着拒绝原假设),存在序列相关具体是几阶序列相关,你可以把滞后期写为几,当然默认是 1,(通常的方法是先看图,上面说的自相关和偏相关图以及Q 值,然后再利用LM 肯定)。
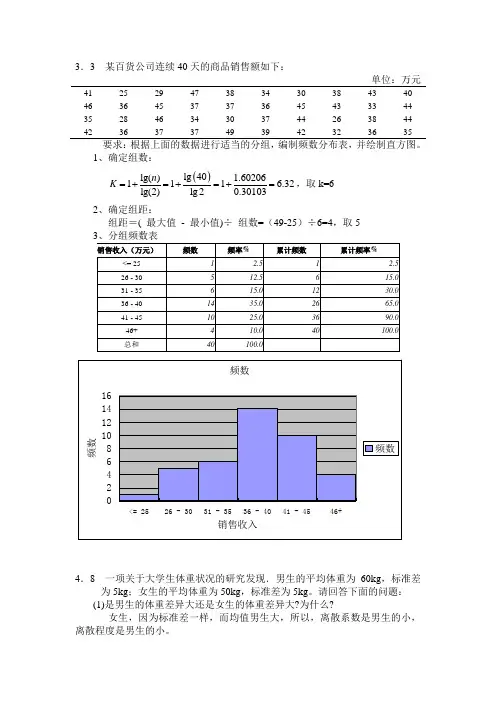
3.3 某百货公司连续40天的商品销售额如下:单位:万元41 25 29 47 38 34 30 38 43 40 46 36 45 37 37 36 45 43 33 44 35 28 46 34 30 37 44 26 38 44 42363737493942323635要求:根据上面的数据进行适当的分组,编制频数分布表,并绘制直方图。
1、确定组数: ()lg 40lg() 1.60206111 6.32lg(2)lg 20.30103n K =+=+=+=,取k=6 2、确定组距:组距=( 最大值 - 最小值)÷ 组数=(49-25)÷6=4,取54.8 一项关于大学生体重状况的研究发现.男生的平均体重为60kg ,标准差为5kg ;女生的平均体重为50kg ,标准差为5kg 。
请回答下面的问题: (1)是男生的体重差异大还是女生的体重差异大?为什么?女生,因为标准差一样,而均值男生大,所以,离散系数是男生的小,离散程度是男生的小。
(2)以磅为单位(1ks=2.2lb),求体重的平均数和标准差。
都是各乘以2.21,男生的平均体重为60kg×2.21=132.6磅,标准差为5kg ×2.21=11.05磅;女生的平均体重为50kg×2.21=110.5磅,标准差为5kg×2.21=11.05磅。
(3)粗略地估计一下,男生中有百分之几的人体重在55kg一65kg之间?计算标准分数:Z1=x xs-=55605-=-1;Z2=x xs-=65605-=1,根据经验规则,男生大约有68%的人体重在55kg一65kg之间。
(4)粗略地估计一下,女生中有百分之几的人体重在40kg~60kg之间?计算标准分数:Z1=x xs-=40505-=-2;Z2=x xs-=60505-=2,根据经验规则,女生大约有95%的人体重在40kg一60kg之间。


回归分析与时间序列一、一元线性回归11。
1 (1)编辑数据集,命名为linehuigui1.dat输入命令scatter cost product,xlabel(#10,grid) ylabel(#10,grid),得到如下散点图,可以看到,产量和生产费用是正线性相关的关系。
(2)输入命令regcost product,得到如下图:可得线性函数(product为自变量,cost为因变量):y=0。
4206832x+124。
15,即β0=124。
15,β1=0。
4206832(3)对相关系数的显著性进行检验,可输入命令pwcorr cost product,sig star (.05) print(。
05),得到下图:可见,在α=0。
05的显著性水平下,P=0。
0000<α=0。
05,故拒绝原假设,即产量和生产费用之间存在显著的正相关性。
11。
2 (1)编辑数据集,命名为linehuigui2。
dat输入命令scatterfenshu time,xlabel(#4, grid) ylabel(#4,grid),得到如下散点图,可以看到,分数和复习时间是正线性相关的关系。
2)输入命令cor fenshu time计算相关系数,得下图:可见,r=0.8621,可见分数和复习时间之间存在高度的正相关性。
11.3 (1)(2)对于线性回归方程y=10-0。
5x,其中β0=10,表示回归直线的截距为10;β1=—0.5,表示x变化一单位引起y的变化为—0.5。
(3)x=6时,E(y)=10-0.5*6=7.11.4(1)R2=SSRSST =SSRSSR+SSE=3636+4=0.9,判定系数R2测度了回归直线对观测数据的拟合程度,即在分数的变差中,有90%可以由分数与复习时间之间的线性关系解释,或者说,在分数取值的变动中,有90%由复习时间决定。
可见,两者之间有很强的线性关系.(2)估计标准误差S e=√SSEn−2=√418−2=0.25分,即根据复习时间来估计分数时,平均的估计误差为0.25分.11.5 (1)编辑数据集,命名为linehuigui3。


stata时间序列回归步骤命令1.引言1.1 概述概述部分的内容:时间序列回归是一种经济学和统计学领域中常用的分析方法,用于研究随时间变化的因果关系。
它涉及使用时间上的观测数据来分析自变量和因变量之间的关系,并预测未来的值。
Stata是一种功能强大的统计软件,广泛用于数据分析和经济研究。
在Stata中,有一系列的命令可供使用,用于进行时间序列回归分析。
本文将介绍使用Stata进行时间序列回归分析的步骤和相应的命令。
通过学习这些命令,读者将能够熟练地使用Stata进行时间序列回归分析,并获得准确和可靠的结果。
本文主要包括以下章节内容:1. 引言部分介绍了时间序列回归的概述、文章结构和目的,旨在帮助读者全面了解本文内容。
2. 正文部分将详细介绍时间序列回归的概念和原理,并介绍Stata中的时间序列回归命令。
这些命令包括数据准备、建立模型、模型估计和统计推断等步骤。
3. 结论部分对本文进行总结,并展望时间序列回归在未来的应用前景。
同时,还会指出时间序列回归分析中可能存在的局限性,以及可能的改进方向。
通过本文的学习,读者将了解时间序列回归分析的基本概念和步骤,掌握对时间序列数据进行回归分析的方法和技巧,并能够运用Stata软件进行实际的分析工作。
1.2文章结构文章结构(Article Structure)本文将按照以下结构进行叙述。
第一部分为引言部分,目的是对时间序列回归步骤命令进行一个概述,并说明本文的目的。
接下来,第二部分将详细介绍时间序列回归的概念和一般步骤,并使用stata命令进行说明。
同时,本文还将重点介绍两个关键要点,这些要点对于正确进行时间序列回归分析非常重要。
最后,第三部分为结论,将总结本文的主要内容,并展望一下未来可能的研究方向。
在正文部分,我们将首先概述时间序列回归的基本概念,并提供了一个对该方法的整体认识。
然后,我们将详细介绍stata时间序列回归步骤命令的使用方法,包括数据导入、变量设定、模型拟合和结果解释等。
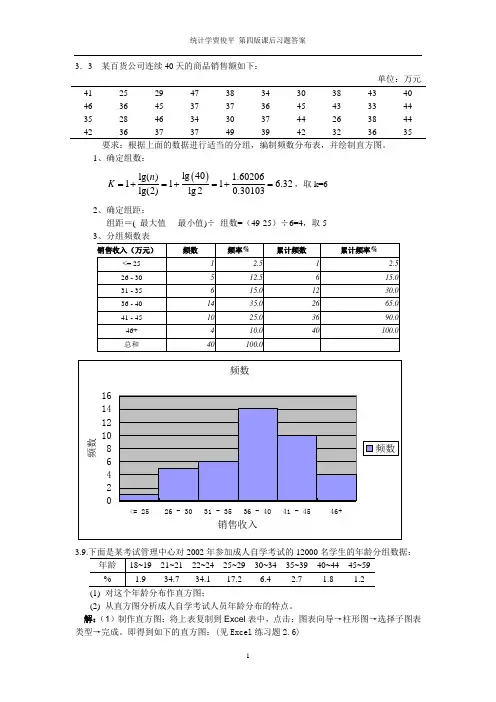
3.3 某百货公司连续40天的商品销售额如下:单位:万元41 25 29 47 38 34 30 38 43 40 46 36 45 37 37 36 45 43 33 44 35 28 46 34 30 37 44 26 38 44 42363737493942323635要求:根据上面的数据进行适当的分组,编制频数分布表,并绘制直方图。
1、确定组数: ()l g 40l g () 1.60206111 6.32l g (2)l g 20.30103n K =+=+=+=,取k=62、确定组距:组距=( 最大值 - 最小值)÷ 组数=(49-25)÷6=4,取5(1) 对这个年龄分布作直方图;(2) 从直方图分析成人自学考试人员年龄分布的特点。
解:(1)制作直方图:将上表复制到Excel 表中,点击:图表向导→柱形图→选择子图表类型→完成。
即得到如下的直方图:(见Excel 练习题2.6)(2)年龄分布的特点:自学考试人员年龄的分布为右偏。
解:(1)根据上面的数据,画出两个班考试成绩的对比条形图和环形图。
3.14 已知1995—2004年我国的国内生产总值数据如下(按当年价格计算):要求:(2)绘制第一、二、三产业国内生产总值的线图。
4.1 一家汽车零售店的10名销售人员5月份销售的汽车数量(单位:台)排序后如下:2 4 7 10 10 10 12 12 14 15要求:(1)计算汽车销售量的众数、中位数和平均数。
(2)根据定义公式计算四分位数。
(3)计算销售量的标准差。
(4)说明汽车销售量分布的特征。
解:Statistics汽车销售数量N Valid 10Missing 0Mean 9.60Median 10.00Mode 10Std. Deviation 4.169Percentiles 25 6.2550 10.0075 12.50种是所有颐客都进入一个等待队列:另—种是顾客在三千业务窗口处列队3排等待。

统计课后思考题答案第一章思考题1。
1什么是统计学统计学是关于数据的一门学科,它收集,处理,分析,解释来自各个领域的数据并从中得出结论。
1。
2解释描述统计和推断统计描述统计;它研究的是数据收集,处理,汇总,图表描述,概括与分析等统计方法。
推断统计;它是研究如何利用样本数据来推断总体特征的统计方法。
1。
3统计学的类型和不同类型的特点统计数据;按所采用的计量尺度不同分;(定性数据)分类数据:只能归于某一类别的非数字型数据,它是对事物进行分类的结果,数据表现为类别,用文字来表述;(定性数据)顺序数据:只能归于某一有序类别的非数字型数据.它也是有类别的,但这些类别是有序的.(定量数据)数值型数据:按数字尺度测量的观察值,其结果表现为具体的数值. 统计数据;按统计数据都收集方法分;观测数据:是通过调查或观测而收集到的数据,这类数据是在没有对事物人为控制的条件下得到的.实验数据:在实验中控制实验对象而收集到的数据。
统计数据;按被描述的现象与实践的关系分;截面数据:在相同或相似的时间点收集到的数据,也叫静态数据.时间序列数据:按时间顺序收集到的,用于描述现象随时间变化的情况,也叫动态数据。
1。
4解释分类数据,顺序数据和数值型数据答案同1.31。
5举例说明总体,样本,参数,统计量,变量这几个概念对一千灯泡进行寿命测试,那么这千个灯泡就是总体,从中抽取一百个进行检测,这一百个灯泡的集合就是样本,这一千个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是参数,这一百个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是统计量,变量就是说明现象某种特征的概念,比如说灯泡的寿命。
1.6变量的分类变量可以分为分类变量,顺序变量,数值型变量。
变量也可以分为随机变量和非随机变量。
经验变量和理论变量。
1。
7举例说明离散型变量和连续性变量离散型变量,只能取有限个值,取值以整数位断开,比如“企业数”连续型变量,取之连续不断,不能一一列举,比如“温度”。

stata 时间序列回归模型使用 Stata 进行时间序列回归建模时间序列分析是统计学的一个分支,用于对按时间顺序排列的数据进行建模和预测。
Stata 是一个用于统计分析的强大软件包,它提供了广泛的功能来处理时间序列数据。
本文将指导您使用Stata 进行时间序列回归建模,重点介绍基本概念、过程和最佳实践。
基本概念时间序列回归模型是一种统计模型,用于预测未来值,同时考虑过去值的影响。
这些模型假设观测值之间存在时间相关性,并利用这种相关性来提高预测精度。
最常见的时间序列回归模型类型包括:自回归(AR)模型:当前值由过去的值线性加权。
移动平均(MA)模型:当前值由过去误差项的线性加权。
自回归移动平均(ARMA)模型:结合 AR 和 MA 模型。
自回归综合移动平均(ARIMA)模型:用于处理非平稳时间序列的 ARMA 扩展。
Stata 中的时间序列回归在 Stata 中,使用 `arima` 命令执行时间序列回归。
该命令需要指定模型类型、滞后阶数和估计选项。
基本的语法如下:```stataarima depvar [indepvars] (p d q) [options]```其中:`depvar` 是您要预测的因变量。
`indepvars` 是任何要包含在模型中的自变量。
`p`、`d` 和 `q` 是 AR、差分和 MA 滞后阶数。
`options` 指定估计选项,例如最大似然法或贝叶斯估计。
例如,要估计具有 1 个 AR 滞后和 2 个 MA 滞后的 ARMA(1,2) 模型,您可以使用以下命令:```stataarima y (1 0 2)```模型选择和诊断选择合适的模型对于时间序列回归至关重要。
Stata 提供了信息准则(例如 AIC 和 BIC)来帮助评估模型的拟合度。
您还可以使用图形诊断,例如残差图和自相关图,来检查模型的假设是否得到满足。
预测和预测区间一旦您选择了一个模型,就可以使用它来预测未来值。

课件•引言•统计数据的收集与整理•统计描述目•概率论基础•统计推断录•统计指数与因素分析•相关与回归分析•统计决策目•统计学的应用与发展录引言统计学概述统计学的定义统计学的发展历史统计学的分支领域1 2 3统计学在决策中的应用统计学在科学研究中的应用统计学在社会生活中的应用统计学的重要性统计学的研究对象01020304数据的收集数据的整理数据的分析数据的解释统计数据的收集与整理原始数据二手数据定性数据定量数据时序数据030201数据的收集方法观察法调查法实验法数据的整理与显示数据整理数据显示通过图表、图像等方式将数据呈现出来,以便于直观理解和分析。
常见的数据显示方式包括表格、条形图、折线图、饼图等。
统计描述集中趋势的描述算术平均数适用于数值型数据,反映数据的平均水平。
中位数适用于顺序数据,反映数据的中等水平。
众数适用于分类数据,反映数据的多数水平。
离散程度的描述四分位数间距极差上四分位数与下四分位数之差,反映中间50%数据的离散程度。
方差与标准差分布形态的描述偏态峰态统计图表的应用适用于分类数据,表示各类别的频数或频率。
适用于时间序列数据,表示事物随时间的变化趋势。
适用于分类数据,表示各类别在总体中的占比。
适用于两个数值型变量,表示它们之间的相关关系。
条形图折线图饼图散点图概率论基础随机事件与概率随机试验与样本空间随机试验是具有某些基本特点的试验,其所有可能结果构成的集合称为样本空间。
随机事件随机试验的某个(些)样本点构成的集合称为随机事件。
概率的定义概率是描述随机事件发生的可能性大小的数值,常用P(A)表示。
概率的性质与运算法则概率的性质01概率的加法公式02概率的乘法公式03事件的独立性如果事件A 与事件B 相互独立,则P(A∩B)=P(A)P(B)。
条件概率在事件B 发生的条件下,事件A 发生的概率称为条件概率,记作P(A|B)。
多个事件的独立性如果事件A1,A2,...,An 相互独立,则对于任意k 个事件Ai1,Ai2,...,Aik(1≤i1<i2<...<ik≤n),都有P(Ai1∩Ai2∩...∩Aik)=P(Ai1)P(Ai2)...P(Aik)。
第三章节:数据的图表展示 (1)第四章节:数据的概括性度量 (15)第六章节:统计量及其抽样分布 (26)第七章节:参数估计 (28)第八章节:假设检验 (38)第九章节:列联分析 (41)第十章节:方差分析 (43)3.1 为评价家电行业售后服务的质量,随机抽取了由100个家庭构成的一个样本。
服务质量的等级分别表示为:A.好;B.较好;C一般;D.较差;E.差。
调查结果如下:B EC C AD C B AE D A C B C D E C E EA DBC C A ED C BB ACDE A B D D CC B C ED B C C B CD A C B C DE C E B B E C C A D C B A E B A C E E A B D D C A D B C C A E D C BC B C ED B C C B C要求:(1)指出上面的数据属于什么类型。
顺序数据(2)用Excel制作一张频数分布表。
用数据分析——直方图制作:接收频率E 16D 17C 32B 21A 14(3)绘制一张条形图,反映评价等级的分布。
用数据分析——直方图制作:(4)绘制评价等级的帕累托图。
逆序排序后,制作累计频数分布表:接收 频数 频率(%) 累计频率(%) C 32 32 32 B 21 21 53 D 17 17 70 E 16 16 86 A 14 14 1005101520253035CDBAE204060801001203.2 某行业管理局所属40个企业2002年的产品销售收入数据如下: 152 124 129 116 100 103 92 95 127 104 105 119 114 115 87 103 118 142 135 125 117 108 105 110 107 137 120 136 117 108 97 88 123 115 119 138 112 146 113 126 要求:(1)根据上面的数据进行适当的分组,编制频数分布表,并计算出累积频数和累积频率。
统计学课后习题答案-(第四版)-贾俊平《统计学》第四版 第四章练习题答案4.1 (1)众数:M 0=10; 中位数:中位数位置=n+1/2=5.5,M e =10;平均数:6.91096===∑n x x i(2)Q L 位置=n/4=2.5, Q L =4+7/2=5.5;Q U 位置=3n/4=7.5,Q U =12(3)2.494.1561)(2==-=∑-n i s x x(4)由于平均数小于中位数和众数,所以汽车销售量为左偏分布。
4.2 (1)从表中数据可以看出,年龄出现频数最多的是19和23,故有个众数,即M 0=19和M 0=23。
将原始数据排序后,计算中位数的位置为:中位数位置= n+1/2=13,第13个位置上的数值为23,所以中位数为M e =23(2)Q L 位置=n/4=6.25, Q L ==19;Q U 位置=3n/4=18.75,Q U =26.5(3)平均数==∑nx x i600/25=24,标准差65.612510621)(2=-=-=∑-n i s x x(4)偏态系数SK=1.08,峰态系数K=0.77 (5)分析:从众数、中位数和平均数来看,网民年龄在23-24岁的人数占多数。
由于标准差较大,说明网民年龄之间有较大差异。
从偏态系数来看,年龄分布为右偏,由于偏态系数大于1,所以,偏斜程度很大。
由于峰态系数为正值,所以为尖峰分布。
4.3 (1)茎叶图如下:(2)==∑n x x i63/9=7,714.0808.41)(2==-=∑-n i s x x(3)由于两种排队方式的平均数不同,所以用离散系数进行比较。
第一种排队方式:v 1=1.97/7.2=0.274;v 21>v 2,表明第一种排队方式的离散程度大于第二种排队方式。
(4)选方法二,因为第二种排队方式的平均等待时间较短,且离散程度小于第一种排队方式。
4.4 (1)==∑n x x i8223/30=274.1中位数位置=n+1/2=15.5,M e =272+273/2=272.5 (2)Q L 位置=n/4=7.5, Q L ==(258+261)/2=259.5;Q U 位置=3n/4=22.5,Q U =(284+291)/2=287.5 (3)17.211307.130021)(2=-=-=∑-n i s x x4.5 (1)甲企业的平均成本=总成本/总产量=41.193406600301500203000152100150030002100==++++乙企业的平均成本=总成本/总产量=29.183426255301500201500153255150015003255==++++原因:尽管两个企业的单位成本相同,但单位成本较低的产品在乙企业的产量中所占比重较大,因此拉低了总平均成本。
与时间序列相关的S T A T A命令及其统计量的解析Modified by JEEP on December 26th, 2020.与时间序列相关的S T A T A命令及其统计量的解析残差U 序列相关:①DW 统计量——针对一阶自相关的(高阶无效)STATA 命令:1.先回归2.直接输入dwstat统计量如何看:查表②Q 统计量——针对高阶自相关correlogram-Q-statisticsSTATA 命令:1.先回归reg2.取出残差predict u,residual(不要忘记逗号)3. wntestq u Q统计量如何看:p 值越小(越接近0)Q 值越大——表示存在自相关具体自相关的阶数可以看自相关系数图和偏相关系数图:STATA 命令:自相关系数图:ac u( 残差) 或者窗口操作在 Graphics ——Time-series graphs —— correlogram(ac)偏相关系数图:pac u 或者窗口操作在Graphics——Time-series graphs—— (pac)自相关与偏相关系数以及Q 统计量同时表示出来的方法:corrgram u或者是窗口操作在Statistics——Time-series——Graphs—— Autocorrelations&Partial autocorrelations③LM 统计量——针对高阶自相关STATA 命令:1.先回归reg2.直接输入命令estate bgodfrey,lags(n) 或者窗口操作在 Statistics——Postestimation(倒数第二个)——Reports and Statistics(倒数第二个) ——在里面选择 Breush-Godfrey LM(当然你在里面还可以找到方差膨胀因子还有DW 统计量等常规统计量)LM 统计量如何看:P 值越小(越接近 0)表示越显着(显着拒绝原假设),存在序列相关具体是几阶序列相关,你可以把滞后期写为几,当然默认是 1,(通常的方法是先看图,上面说的自相关和偏相关图以及Q 值,然后再利用LM 肯定)。