一元线性回归方程
- 格式:doc
- 大小:41.41 KB
- 文档页数:7

12.9 一元线性回归以前我们所研究的函数关系是完全确定的,但在实际问题中,常常会遇到两个变量之间具有密切关系却又不能用一个确定的数学式子表达,这种非确定性的关系称为相关关系。
通过大量的试验和观察,用统计的方法找到试验结果的统计规律,这种方法称为回归分析。
一元回归分析是研究两个变量之间的相关关系的方法。
如果两个变量之间的关系是线性的,这就是一元线性回归问题。
一元线性回归问题主要分以下三个方面:(1)通过对大量试验数据的分析、处理,得到两个变量之间的经验公式即一元线性回归方程。
(2)对经验公式的可信程度进行检验,判断经验公式是否可信。
(3)利用已建立的经验公式,进行预测和控制。
12.9.1 一元线性回归方程 1.散点图与回归直线在一元线性回归分析里,主要是考察随机变量y 与普通变量x 之间的关系。
通过试验,可得到x 、y 的若干对实测数据,将这些数据在坐标系中描绘出来,所得到的图叫做散点图。
例1 在硝酸钠(NaNO 3)的溶解度试验中,测得在不同温度x (℃)下,溶解于100解 将每对观察值(x i ,y i )在直角坐标系中描出,得散点图如图12.11所示。
从图12.11可看出,这些点虽不在一条直线上,但都在一条直线附近。
于是,很自然会想到用一条直线来近似地表示x 与y 之间的关系,这条直线的方程就叫做y 对x 的一元线性回归方程。
设这条直线的方程为yˆ=a+bx 其中a 、b 叫做回归系数(y ˆ表示直线上y 的值与实际值y i 不同)。
图12.11下面是怎样确定a 和b ,使直线总的看来最靠近这几个点。
2.最小二乘法与回归方程在一次试验中,取得n 对数据(x i ,y i ),其中y i 是随机变量y 对应于x i 的观察值。
我们所要求的直线应该是使所有︱y i -yˆ︱之和最小的一条直线,其中i y ˆ=a+bx i 。
由于绝对值在处理上比较麻烦,所以用平方和来代替,即要求a 、b 的值使Q=21)ˆ(i ni iyy-∑=最小。

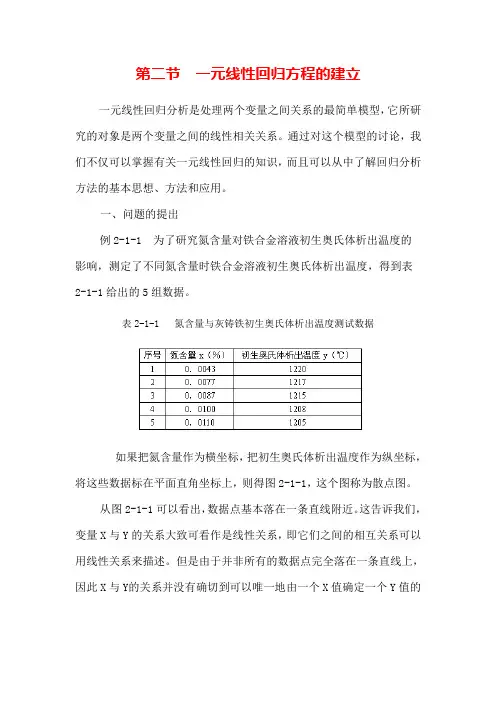
第二节一元线性回归方程的建立一元线性回归分析是处理两个变量之间关系的最简单模型,它所研究的对象是两个变量之间的线性相关关系。
通过对这个模型的讨论,我们不仅可以掌握有关一元线性回归的知识,而且可以从中了解回归分析方法的基本思想、方法和应用。
一、问题的提出例2-1-1 为了研究氮含量对铁合金溶液初生奥氏体析出温度的影响,测定了不同氮含量时铁合金溶液初生奥氏体析出温度,得到表2-1-1给出的5组数据。
表2-1-1 氮含量与灰铸铁初生奥氏体析出温度测试数据如果把氮含量作为横坐标,把初生奥氏体析出温度作为纵坐标,将这些数据标在平面直角坐标上,则得图2-1-1,这个图称为散点图。
从图2-1-1可以看出,数据点基本落在一条直线附近。
这告诉我们,变量X与Y的关系大致可看作是线性关系,即它们之间的相互关系可以用线性关系来描述。
但是由于并非所有的数据点完全落在一条直线上,因此X与Y的关系并没有确切到可以唯一地由一个X值确定一个Y值的程度。
其它因素,诸如其它微量元素的含量以及测试误差等都会影响Y 的测试结果。
如果我们要研究X与Y的关系,可以作线性拟合(2-1-1)二、最小二乘法原理如果把用回归方程计算得到的i值(i=1,2,…n)称为回归值,那么实际测量值y i与回归值i之间存在着偏差,我们把这(i=1,2,3,…,n)。
这样,我们就可以用残差平种偏差称为残差,记为e i方和来度量测量值与回归直线的接近或偏差程度。
残差平方和定义为: (2-1-2) 所谓最小二乘法,就是选择a和b使Q(a,b)最小,即用最小二乘法得到的回归直线是在所有直线中与测量值残差平方和Q最小的一条。
由(2-1-2)式可知Q是关于a,b的二次函数,所以它的最小值总是存在的。
下面讨论的a和b的求法。



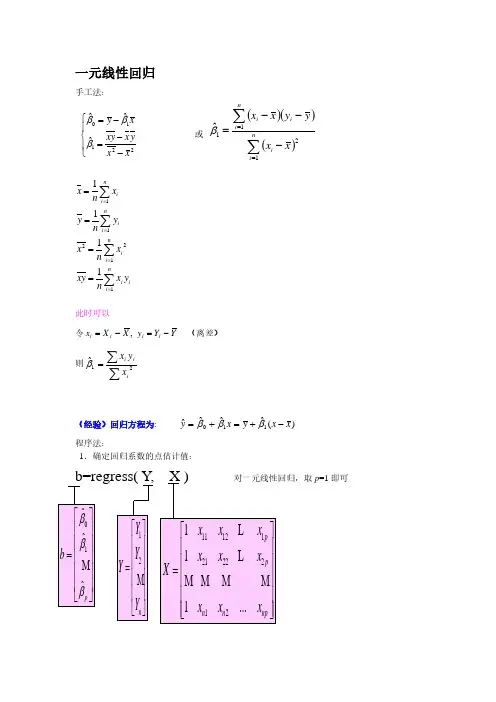
一元线性回归手工法:⎪⎩⎪⎨⎧−−=−=22110ˆˆˆx x y x xy x y βββ 或 ()()()∑∑==−−−=ni ini i ix xy y x x1211ˆβini i n i ini ini iy x n xy x n x y n y x n x ∑∑∑∑========1122111111 此时可以令Y Y y X X x i i i i −=−= , (离差)则∑∑=21ˆiii xy x β(经验)回归方程为: )(ˆˆˆˆ110x x y x y −+=+=βββ 程序法:1.确定回归系数的点估计值:b=regress( Y , X ) 对一元线性回归,取p =1即可01ˆˆˆp b βββ⎡⎤⎢⎥⎢⎥=⎢⎥⎢⎥⎢⎥⎣⎦M 12n Y Y Y Y ⎡⎤⎢⎥⎢⎥=⎢⎥⎢⎥⎣⎦M 111212122212111...p p n n np x x x x x x X x x x ⎡⎤⎢⎥⎢⎥=⎢⎥⎢⎥⎢⎥⎣⎦L L M M M M程序数据的输入可以参考如下:x=[143 145 146 147 149 150 153 154 155 156 157 158 159 160 162 164]'; X=[ones(16,1) x];Y=[88 85 88 91 92 93 93 95 96 98 97 96 98 99 100 102]';2.回归分析及检验:[b,bint,r,rint,stats]=regress(Y ,X)b,bint,stats得结果:b = bint =-16.0730 -33.7071 1.5612 0.7194 0.6047 0.8340 stats =0.9282 180.9531 0.0000即7194.0ˆ,073.16ˆ10=−=ββ;0ˆβ的置信区间为[-33.7017,1.5612], 1ˆβ的置信区间为[0.6047,0.834]; r 2=0.9282, F =180.9531, p =0.0000 p <0.05, 可知回归模型 y =-16.073+0.7194x 成立.这个程序可以进行,第一步的拟合优度与相关系数检验, 第三步的方程的整体性检验(F 检验) ,因此第一步的拟合优度 r 平方已算出就根据 r 2 =1意味着完全拟合,r 2 =0意味着被解释变量与解释变量之间没有线性关系,0< r 2 <1时,r 2越接近于1拟合效果越好。




从统计学看线性回归(1)——⼀元线性回归⽬录1. ⼀元线性回归模型的数学形式2. 回归参数β0 , β1的估计3. 最⼩⼆乘估计的性质 线性性 ⽆偏性 最⼩⽅差性⼀、⼀元线性回归模型的数学形式 ⼀元线性回归是描述两个变量之间相关关系的最简单的回归模型。
⾃变量与因变量间的线性关系的数学结构通常⽤式(1)的形式:y = β0 + β1x + ε (1)其中两个变量y与x之间的关系⽤两部分描述。
⼀部分是由于x的变化引起y线性变化的部分,即β0+ β1x,另⼀部分是由其他⼀切随机因素引起的,记为ε。
该式确切的表达了变量x与y之间密切关系,但密切的程度⼜没有到x唯⼀确定y的这种特殊关系。
式(1)称为变量y对x的⼀元线性回归理论模型。
⼀般称y为被解释变量(因变量),x为解释变量(⾃变量),β0和β1是未知参数,成β0为回归常数,β1为回归系数。
ε表⽰其他随机因素的影响。
⼀般假定ε是不可观测的随机误差,它是⼀个随机变量,通常假定ε满⾜:(2)对式(1)两边求期望,得E(y) = β0 + β1x, (3)称式(3)为回归⽅程。
E(ε) = 0 可以理解为ε对 y 的总体影响期望为 0,也就是说在给定 x 下,由x确定的线性部分β0 + β1x 已经确定,现在只有ε对 y 产⽣影响,在 x = x0,ε = 0即除x以外其他⼀切因素对 y 的影响为0时,设 y = y0,经过多次采样,y 的值在 y0 上下波动(因为采样中ε不恒等于0),若 E(ε) = 0 则说明综合多次采样的结果,ε对 y 的综合影响为0,则可以很好的分析 x 对 y 的影响(因为其他⼀切因素的综合影响为0,但要保证样本量不能太少);若 E(ε) = c ≠ 0,即ε对 y 的综合影响是⼀个不为0的常数,则E(y) = β0 + β1x + E(ε),那么 E(ε) 这个常数可以直接被β0 捕获,从⽽变为公式(3);若 E(ε) = 变量,则说明ε在不同的 x 下对 y 的影响不同,那么说明存在其他变量也对 y 有显著作⽤。
一元线性回归方程式为:y=a+b x
b=n∑xy−∑x∑y n∑x2−(∑x)2
a=y̅−bx̅
其中a、b都是待定参数,可以用最小二乘法求得。
(最小平方法)b表示直线的斜率,又称为回归系数。
n表示所有数据的项数。
∑x表示所有x的求和
∑y表示所有y的求和
∑xy表示所有xy的求和
∑x2表示所有x2的求和
(∑x)2表示∑x的平方,即所有x的求和再求平方。
x̅表示所有x的平均数
y̅表示所有y的平均数
答题解法如下:
解:(答:)相关数据如下表:
根据公式b=n∑xy−∑x∑y
n∑x2−(∑x)2
得:
b=6∗1481−21∗426
6∗79−212=8886−8946
474−441
=−60
33
=-1.82
根据公式a=y̅−bx̅得:
a=71−(−1.82)∗3.5=71-(-6.37)=71+6.37=77.37
代入方程式y=a+b x得:
y=77.37+(-1.82)x=77.37-1.82 x
已知7月份产量为7000件,则x=7(千件),代入得:
y=77.37-1.82 x=77.37-1.82*7=77.37-12.74=64.63(元)
根据一元回归方程(最小乘法或最小平方法),当7月份产量为7000件时,其单位成本为64.63元。
一元线性回归方程公式
一元线性回归方程公式:
y = ax + b
元线性回归方程反映一个因变量与一个自变量之间的线性关系,当直线方程Y'=a+bx的a和b确定时,即为一元回归线性方程。
经过相关分析后,在直角坐标系中将大量数据绘制成散点图,这些点不在一条直线上,但可以从中找到一条合适的直线,使各散点到这条直线的纵向距离之和最小,这条直线就是回归直线,这条直线的方程叫作直线回归方程。
注意:一元线性回归方程与函数的直线方程有区别,一元线性回归方程中的自变量X对应的是因变量Y的一个取值范围。
1。
第十三讲简单线性相关(一元线性回归分析)对于两个或更多变量之间的关系,相关分析考虑的只是变量之间是否相关、相关的程度,而回归分析关心的问题是:变量之间的因果关系如何。
回归分析是处理一个或多个自变量与因变量间线性因果关系的统计方法。
如婚姻状况与子女生育数量,相关分析可以求出两者的相关强度以及是否具有统计学意义,但不对谁决定谁作出预设,即可以相互解释,回归分析则必须预先假定谁是因谁是果,谁明确谁为因与谁为果的前提下展开进一步的分析。
一、一元线性回归模型及其对变量的要求(一)一元线性回归模型1、一元线性回归模型示例两个变量之间的真实关系一般可以用以下方程来表示:Y=A+BX+方程中的 A 、B 是待定的常数,称为模型系数,是残差,是以X预测Y 产生的误差。
两个变量之间拟合的直线是:y a bxy 是y的拟合值或预测值,它是在X 条件下 Y 条件均值的估计a 、b 是回归直线的系数,是总体真实直线距,当自变量的值为0 时,因变量的值。
A、B 的估计值, a 即 constant 是截b 称为回归系数,指在其他所有的因素不变时,每一单位自变量的变化引起的因变量的变化。
可以对回归方程进行标准化,得到标准回归方程:y x为标准回归系数,表示其他变量不变时,自变量变化一个标准差单位( Z XjXj),因变量 Y 的标准差的平均变化。
S j由于标准化消除了原来自变量不同的测量单位,标准回归系数之间是可以比较的,绝对值的大小代表了对因变量作用的大小,反映自变量对Y 的重要性。
(二)对变量的要求:回归分析的假定条件回归分析对变量的要求是:自变量可以是随机变量,也可以是非随机变量。
自变量 X 值的测量可以认为是没有误差的,或者说误差可以忽略不计。
回归分析对于因变量有较多的要求,这些要求与其它的因素一起,构成了回归分析的基本条件:独立、线性、正态、等方差。
(三)数据要求模型中要求一个因变量,一个或多个自变量(一元时为 1 个自变量)。
一元线性回归模型1.一元线性回归模型有一元线性回归模型(统计模型)如下,y t = 0 + 1 x t + u t上式表示变量y t 和x t之间的真实关系。
其中y t 称被解释变量(因变量),x t称解释变量(自变量),u t称随机误差项, 0称常数项, 1称回归系数(通常未知)。
上模型可以分为两部分。
(1)回归函数部分,E(y t) = 0 + 1 x t,(2)随机部分,u t。
图2.1 真实的回归直线这种模型可以赋予各种实际意义,收入与支出的关系;如脉搏与血压的关系;商品价格与供给量的关系;文件容量与保存时间的关系;林区木材采伐量与木材剩余物的关系;身高与体重的关系等。
以收入与支出的关系为例。
假设固定对一个家庭进行观察,随着收入水平的不同,与支出呈线性函数关系。
但实际上数据来自各个家庭,来自各个不同收入水平,使其他条件不变成为不可能,所以由数据得到的散点图不在一条直线上(不呈函数关系),而是散在直线周围,服从统计关系。
随机误差项u t中可能包括家庭人口数不同,消费习惯不同,不同地域的消费指数不同,不同家庭的外来收入不同等因素。
所以在经济问题上“控制其他因素不变”是不可能的。
回归模型的随机误差项中一般包括如下几项内容,(1)非重要解释变量的省略,(2)人的随机行为,(3)数学模型形式欠妥,(4)归并误差(粮食的归并)(5)测量误差等。
回归模型存在两个特点。
(1)建立在某些假定条件不变前提下抽象出来的回归函数不能百分之百地再现所研究的经济过程。
(2)也正是由于这些假定与抽象,才使我们能够透过复杂的经济现象,深刻认识到该经济过程的本质。
通常线性回归函数E(y t) = 0 + 1 x t是观察不到的,利用样本得到的只是对E(y t) = 0 + 1 x t 的估计,即对 0和 1的估计。
在对回归函数进行估计之前应该对随机误差项u t做出如下假定。
(1) u t 是一个随机变量,u t 的取值服从概率分布。
附件二:实验报告格式(首页)
山东轻工业学院实验报告成绩
课程名称计量经济学基础指导教师实验日期 2013-4-20 院(系)商学院专业班级实验地点 :二机房
学生姓名学号同组人无
实验项目名称一元线性回归方程
一、实验目的和要求
1、熟悉Eviews的窗口与界面
2、掌握Eviews的命令与菜单的操作
3、掌握用Eviews估计与检验一元线性回归模
4、影响消费的因素可能很多,比如国内生产总值,经济增长,物价指数,居民收入等等。
主要
讨论是否在收入水平提高时,消费也会随之提高。
二、实验原理
Eviews具有现代Windows软件可视化操作的优良性。
可以使用鼠标对标准的Windows菜单和对话框进行操作。
操作结果出现在窗口中并能采用标准的Windows技术对操作结果进行处理。
此外,Eviews还拥有强大的命令功能和批处理语言功能。
在Eviews的命令行中输入、编辑和执行命令。
在程序文件中建立和存储命令,以便在后续的研究项目中使用这些程序。
三、主要仪器设备、试剂或材料
Eviews软件、课本、电脑、对问题的经济理论的分析、所涉及的经济变量、变量的设定,熟悉EVIEWS操作。
四、实验方法与步骤
(1)单击任务栏上的“开始”→“所有程序”→“Eviews5”程序组→“Eviews5”图标。
(2)新建文件:File→New→Workfile,出现对话框“工作文件范围”,选取或填上数据类型、起止时间 1980-1998。
OK后,得到一个无名字的工作文件,其中有:时间范围、当前工作文件样本范围、filter 、默认方程、系数向量C、序列RESID。
(3)命令方式新建文件
在EViews软件的命令窗口中直接键入CREATE命令,也可以建立工作文件。
命令格式为: CREATE 时间频率类型起始期终止期
则以上菜单方式过程可写为:CREATE A 1980 1998
(4) 工作文件创立后,需将工作文件保存到磁盘.单击菜单兰中File→Save或Save as→输入文件名、路径→保存。
(5)输入数据
进入数据编辑窗口
DATA命令方式
在EViews软件的命令窗口键入DATA命令,命令格式为:
DATA <序列名1> <序列名2>…<序列名n>
本例中可在命令窗口键入如下命令,将显示一个数组窗口,此时可以按全屏幕编辑方式输入每个变量的数据。
DATA Y X
数据输入完毕,单击工作文件窗口工具条的Save或单击菜单兰的File→Save将数据存入磁盘。
(6)命令方式
在主菜单命令行键入
LS Y C X 回车
FORECAST--OK(
(7)单击Equation 窗口中的View → Actual, Fitted, Resid → Table按钮,可以得到拟合直线和残差的有关结果.
五、实验数据记录、处理及结果分析
β1 =0.691754 是样本回归方程的斜率,它表示该市城镇居民的边际消费倾向,说明年可支配收入每增加1元,将0.691754元用于消费性支出;βo=135.3063是样本回归方程的截距,它表示不受可支配收入影响的自发消费行为。
βo和β1的符号和大小均符合经济理论及目前该市的实际情况。
六、讨论、心得
初步投身于计量经济学,通过利用Eviews软件将所学到的计量知识进行实践,让我加深了对理论的理解和掌握,直观而充分地体会到老师课堂讲授内容的精华之所在。
在实验过程中我们提高了手动操作软件、数量化分析与解决问题的能力,还可以培养我在处理实验经济问题的严谨的科学的态度,并且避免了课堂知识与实际应用的脱节。
虽然在实验过程中出现了很多错误,但这些经验却锤炼了我们发现问题的眼光,丰富了我们分析问题的思路。
通过这次实验让我受益匪浅。
这次操作后,对Eviews软件有了更深层的了解,学会了对软件进行简单的操作,对实际的经济问题进行分析与检验。
使原本枯燥、繁琐、难懂的课本知识变得简洁化,跨越理论和实践的鸿沟,同时使我对计量经济学产生兴趣。
通过这次的实验,我对课上所学的最小二乘法有了进一步的理解,在掌握理论知识的同时,将其与实际的经济问题联系起来。
通过本次上机实验,我认识到我们一定要掌握Eviews,并且通过这次学习,我逐渐了解了关于Eviews的相关知识。
相信Eviews将会给我们的学习和生活带来诸多便利。
附件三:实验报告附页
山东轻工业学院实验报告(附页)。