最大熵算法笔记
- 格式:doc
- 大小:17.00 KB
- 文档页数:5

最大熵原理和分析熵是信息论中一个非常重要的概念,它表示一个随机变量的不确定性。
对于一个离散随机变量X,其熵H(X)定义为:H(X) = -∑ P(x) log P(x)其中,P(x)表示X取一些值x的概率。
熵的值越大,表示随机变量的不确定性越高,反之,熵的值越小,表示随机变量的不确定性越低。
最大熵原理认为,当我们对一个问题缺乏先验知识,也就是无法对一些事件的概率分布进行确定时,我们应该选择一个与我们已知信息最为吻合,即最为均匀的分布。
最大熵原理的核心思想是在保持已知信息的基础上,尽可能避免引入不可验证的假设。
1.定义问题和确定已知信息:首先,我们需要清楚地定义问题,并确定我们已知的信息和限制条件。
这些已知信息可以是一些约束条件,也可以是一些期望值等。
2.确定特征函数:为了表示我们所关心的问题,我们需要选择一组合适的特征函数。
特征函数是一个从问题的状态空间映射到实数的函数,它可以度量一些状态的特征或属性。
3.确定约束条件:根据已知信息和特征函数,我们可以得到一组约束条件。
这些约束条件可以是一些状态的期望值等。
4.定义最大熵模型:最大熵模型是在满足已知信息和约束条件的条件下,找到最大熵分布的模型。
最大熵模型可以通过最优化方法来求解。
5.模型评估和应用:通过最大熵模型,我们可以得到概率分布或其他输出。
我们可以使用这些输出来进行模型评估、分类、预测等任务。
然而,最大熵原理也存在一些限制。
首先,在实际应用中,特征函数的选择往往具有一定的主观性。
其次,最大熵模型的计算复杂度较高,当特征函数和约束条件较多时,求解最大熵模型可能会变得困难。
另外,最大熵原理本身并没有提供一种判断模型的好坏的准则。
综上所述,最大熵原理是一种基于信息论的概率模型学习方法。
它通过最大化系统的熵,来求解最为均匀和不确定的概率分布。
最大熵原理在统计学、自然语言处理、机器学习等领域有广泛的应用,但同时也存在一些局限性。

最大熵模型知识点总结
最大熵模型(Maximum Entropy Model)是一种统计模型,用于处理分类和回归问题。
这种模型基于信息论中的熵的概念,通过最大化熵来选择最合适的模型。
以下是最大熵模型的一些重要知识点:
1. 熵的概念:熵是信息论中的一个重要概念,用于衡量信息的不确定性。
熵越高,表示信息越不确定;熵越低,表示信息越确定。
2. 最大熵原理:最大熵原理认为,在不缺乏任何先验知识的情况下,应选择熵最大的模型。
这是因为最大熵对未知的事物进行了最少的假设,使得模型具有更好的灵活性和泛化能力。
3. 特征函数:最大熵模型使用特征函数来定义特征。
特征函数是一个将实例映射到特征值(0或1)的函数,用于描述实例与某种事件的关系。
每个特征函数对应一个特征,通过定义一组特征函数,可以构建最大熵模型的特征集。
4. 约束条件:最大熵模型的训练过程是一个求解最优化问题。
为了获得最大熵模型,需要定义一组约束条件。
这些约束条件可以用于限制模型的潜在搜索空间,使其符合一些先验知识。
5. 最优化算法:求解最大熵模型问题的常用方法是使用迭代的最优化算法,例如改进的迭代尺度法(Improved Iterative Scaling,IIS)和梯度下降法(Gradient Descent)。
最大熵模型在自然语言处理、信息检索和机器学习等领域有广泛的应用。
它可以用于文本分类、命名实体识别、情感分析和机器翻译等任务。
最大熵模型的灵活性和泛化能力使其成为一种强大的统计模型。

最大熵模型算法今天我们来介绍一下最大熵模型系数求解的算法IIS算法。
有关于最大熵模型的原理可以看专栏里的这篇文章。
有关张乐博士的最大熵模型包的安装可以看这篇文章。
最大熵模型算法 1在满足特征约束的条件下,定义在条件概率分布P(Y|X)上的条件熵最大的模型就认为是最好的模型。
最大熵模型算法 23. IIS法求解系数wi先直接把算法粘贴出来,然后再用Python代码来解释。
这里也可以对照李航《统计学习方法》P90-91页算法6.1来看。
这个Python代码不知道是从哪儿下载到的了。
从算法的计算流程,我们明显看到,这就是一个迭代算法,首先给每个未知的系数wi赋一个初始值,然后计算对应每个系数wi的变化量delta_i,接着更新每个wi,迭代更新不断地进行下去,直到每个系数wi都不再变化为止。
下边我们一点点儿详细解释每个步骤。
获得特征函数输入的特征函数f1,f2,...,fn,也可以把它们理解为特征模板,用词性标注来说,假设有下边的特征模板x1=前词, x2=当前词, x3=后词 y=当前词的标记。
然后,用这个特征模板在训练语料上扫,显然就会出现很多个特征函数了。
比如下边的这句话,我/r 是/v 中国/ns 人/n用上边的模板扫过,就会出现下边的4个特征函数(start,我,是,r)(我,是,中国,v)(是,中国,人,ns)(中国,人,end,n)当然,在很大的训练语料上用特征模板扫过,一定会得到相同的特征函数,要去重只保留一种即可。
可以用Python代码得到特征函数def generate_events(self, line, train_flag=False):"""输入一个以空格为分隔符的已分词文本,返回生成的事件序列:param line: 以空格为分隔符的已分词文本:param train_flag: 真时为训练集生成事件序列;假时为测试集生成事件:return: 事件序列"""event_li = []# 分词word_li = line.split()# 为词语序列添加头元素和尾元素,便于后续抽取事件 if train_flag:word_li = [tuple(w.split(u'/')) for w inword_li if len(w.split(u'/')) == 2]else:word_li = [(w, u'x_pos') for w in word_li]word_li = [(u'pre1', u'pre1_pos')] + word_li + [(u'pro1', u'pro1_pos')]# 每个中心词抽取1个event,每个event由1个词性标记和多个特征项构成for i in range(1, len(word_li) - 1):# 特征函数a 中心词fea_1 = word_li[i][0]# 特征函数b 前一个词fea_2 = word_li[i - 1][0]# 特征函数d 下一个词fea_4 = word_li[i + 1][0]# 构建一个事件fields = [word_li[i][1], fea_1, fea_2, fea_4] # 将事件添加到事件序列event_li.append(fields)# 返回事件序列return event_li步进值 \delta_{i} 的求解显然delta_i由3个值构成,我们一点点儿说。

们对事物了解的不确定性的消除或减少。
他把不确定的程度称为信息熵。
假设每种可能的状态都有概率,我们⽤关于被占据状态的未知信息来量化不确定性,这个信息熵即为:
其中是以
扩展到连续情形。
假设连续变量的概率密度函数是,与离散随机变量的熵的定义类似,
上式就是我们定义的随机变量的微分熵。
当被解释为⼀个随机连续向量时,就是的联合概率密度函数。
4.2. ⼩概率事件发⽣时携带的信息量⽐⼤概率事件发⽣时携带的信息量多
证明略,可以简要说明⼀下,也挺直观的。
如果事件发⽣的概率为,在这种情况下,事件了,并且不传达任何
;反之,如果事件发⽣的概率很⼩,这就有更⼤的
对所有随机变量的概率密度函数,满⾜以下约束条件:
其中,是的⼀个函数。
约束
量的矩,它随函数的表达式不同⽽发⽣变化,它综合了随机变量的所有可⽤的先验知其中,是拉格朗⽇乘⼦。
对被积函数求的微分,并令其为。

最大熵强化学习算法SACSAC:Soft Actor-Critic,Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor。
模型结构模型同时学习action value Q、state value V和policy π。
1.V中引入Target V,供Q学习时使用;Target Network使学习有章可循、效率更高。
2.Q有两个单独的网络,选取最小值供V和π学习时使用,希望减弱Q的过高估计。
3.π学习的是分布的参数:均值和标准差;这与DDPG不同,DDPG的π是Deterministic的,输出直接就是action,而SAC学习的是个分布,学习时action需要从分布中采样,是Stochastic的。
SoftSoft,Smoothing,Stable。
原始的强化学习最大熵目标函数(maximum entropy objective)如下,比最初的累计奖赏,增加了policy π的信息熵。
A3C目标函数里的熵正则项和形式一样,只是作为正则项,系数很小。
在Soft Policy Iteration中,近似soft Q-value的迭代更新规则如下:其中V(s)为soft state value function:根据信息熵的定义:soft state value function和maximum entropy objective在形式上还是一致的,系数α能通过调节Q-value消掉,可忽略。
TD3的soft state value function V形式与Soft Policy Iteration 中类似,但是SAC的action是通过对policy π采样确定地得到,每条数据数据的信息熵就是其不确定性-logπ(a|s);但考虑整个批量batch数据,其整体还是π的信息熵,与maximum entropy方向一致。

总结各种熵什么是熵熵是信息论中一个重要的概念,用于度量信息的不确定性。
在信息论中,熵通常表示为H,可以理解为一个随机变量的平均信息量。
熵越高,信息的不确定性就越大。
香农熵香农熵是信息论中最常见的熵的定义方式。
它衡量了一个随机变量的平均信息量,即表示对这个变量进行编码时所需要的平均比特数。
香农熵的计算公式如下:H(X) = - Σ (p(xi) * log2(p(xi)))其中,X表示一个随机变量,p(xi)表示变量取值为xi的概率。
香农熵的取值范围为0到正无穷大。
当熵为0时,表示随机变量是确定性的,即不会产生任何信息量;当熵为正无穷大时,表示随机变量的可能取值有无穷多个,每个取值的概率相等。
条件熵条件熵是给定某一随机变量的条件下,另一个随机变量的平均不确定性。
条件熵的计算公式如下:H(Y|X) = Σ (p(xi) * H(Y|X=xi))其中,X和Y分别表示两个随机变量,p(xi)表示X取值为xi的概率,H(Y|X=xi)表示在X=xi的条件下,Y的熵。
条件熵表示了在已知一个随机变量的情况下,对另一个随机变量的不确定程度。
互信息互信息用于度量两个随机变量之间的相互依赖程度。
它描述了当我们知道一个随机变量的取值时,对另一个随机变量的平均提供的额外信息量。
互信息的计算公式如下:I(X;Y) = Σ (p(xi,yj) * log2(p(xi,yj)/(p(xi)*p(yj))))其中,X和Y分别表示两个随机变量,p(xi,yj)表示X取值为xi,Y取值为yj的联合概率,p(xi)和p(yj)分别表示X和Y的边缘概率。
互信息的取值范围为0到正无穷大。
当互信息为0时,表示两个随机变量是独立的;当互信息为正值时,表示两个随机变量之间存在依赖关系。
相对熵(KL散度)相对熵,也称为KL散度(Kullback-Leibler divergence),用于度量两个概率分布之间的差异。
在机器学习中,相对熵常常用于表示两个概率分布之间的距离。

一、熵物理学概念宏观上:热力学定律——体系的熵变等于可逆过程吸收或耗散的热量除以它的绝对温度(克劳修斯,1865)微观上:熵是大量微观粒子的位置和速度的分布概率的函数,是描述系统中大量微观粒子的无序性的宏观参数(波尔兹曼,1872)结论:熵是描述事物无序性的参数,熵越大则无序。
二、熵在自然界的变化规律——熵增原理一个孤立系统的熵,自发性地趋于极大,随着熵的增加,有序状态逐步变为混沌状态,不可能自发地产生新的有序结构。
当熵处于最小值, 即能量集中程度最高、有效能量处于最大值时, 那么整个系统也处于最有序的状态,相反为最无序状态。
熵增原理预示着自然界越变越无序三、信息熵(1)和熵的联系——熵是描述客观事物无序性的参数。
香农认为信息是人们对事物了解的不确定性的消除或减少,他把不确定的程度称为信息熵(香农,1948 )。
随机事件的信息熵:设随机变量ξ,它有A1,A2,A3,A4,……,An共n种可能的结局,每个结局出现的概率分别为p1,p2,p3,p4,……,pn,则其不确定程度,即信息熵为(2)信息熵是数学方法和语言文字学的结合。
一个系统的熵就是它的无组织程度的度量。
熵越大,事件越不确定。
熵等于0,事件是确定的。
举例:抛硬币,p(head)=0.5,p(tail)=0.5H(p)=-0.5log2(0.5)+(-0.5l og2(0.5))=1说明:熵值最大,正反面的概率相等,事件最不确定。
四、最大熵理论在无外力作用下,事物总是朝着最混乱的方向发展。
事物是约束和自由的统一体。
事物总是在约束下争取最大的自由权,这其实也是自然界的根本原则。
在已知条件下,熵最大的事物,最可能接近它的真实状态。
五、基于最大熵的统计建模:建模理论以最大熵理论为基础的统计建模。
为什么可以基于最大熵建模?Jaynes证明:对随机事件的所有相容的预测中,熵最大的预测出现的概率占绝对优势。
Tribus证明,正态分布、伽马分布、指数分布等,都是最大熵原理的特殊情况。


简述最大熵定理内容最大熵原理是一种选择随机变量统计特性最符合客观情况的准则,也称为最大信息原理。
随机量的概率分布是很难测定的,一般只能测得其各种均值(如数学期望、方差等)或已知某些限定条件下的值(如峰值、取值个数等),符合测得这些值的分布可有多种、以至无穷多种,通常,其中有一种分布的熵最大。
选用这种具有最大熵的分布作为该随机变量的分布,是一种有效的处理方法和准则。
这种方法虽有一定的主观性,但可以认为是最符合客观情况的一种选择。
在投资时常常讲不要把所有的鸡蛋放在一个篮子里,这样可以降低风险。
在信息处理中,这个原理同样适用。
在数学上,这个原理称为最大熵原理。
历史背景最大熵原理是在1957年由E.T.Jaynes提出的,其主要思想是,在只掌握关于未知分布的部分知识时,应该选取符合这些知识但熵值最大的概率分布。
因为在这种情况下,符合已知知识的概率分布可能不止一个。
我们知道,熵定义的实际上是一个随机变量的不确定性,熵最大的时候,说明随机变量最不确定,换句话说,也就是随机变量最随机,对其行为做准确预测最困难。
从这个意义上讲,那么最大熵原理的实质就是,在已知部分知识的前提下,关于未知分布最合理的推断就是符合已知知识最不确定或最随机的推断,这是我们可以作出的不偏不倚的选择,任何其它的选择都意味着我们增加了其它的约束和假设,这些约束和假设根据我们掌握的信息无法作出。
可查看《浅谈最大熵原理和统计物理学》——曾致远(RichardChih-YuanTseng)研究领域主要为古典信息论,量子信息论及理论统计热物理学,临界现象及非平衡热力学等物理现象理论研究古典信息论在统计物理学中之意义及应用[1]。
发展过程早期的信息论其中心任务就是从理论上认识一个通信的设备(手段)的通信能力应当如何去计量以及分析该通信能力的规律性。
但是信息论研究很快就发现利用信息熵最大再附加上一些约束,就可以得到例如著名的统计学中的高斯分布(即正态分布)。

最⼤熵1. 最⼤熵原理最⼤熵原理是概率模型学习的⼀个准则,其认为学习概率模型时,在所有可能的概率模型中,熵最⼤的模型是最好的模型。
通常⽤约束条件来确定概率模型的集合,然后在集合中选择熵最⼤的模型。
直观地,最⼤熵原理认为要选择的概率模型⾸先必须满⾜已有的事实,即约束条件。
在没有更多信息的情况下,那些不确定的部分都是等可能的。
最⼤熵原理通过熵的最⼤化来表⽰等可能性,因为当X服从均匀分布时熵最⼤。
2. 最⼤熵模型最⼤熵原理应⽤到分类得到最⼤熵模型。
给定训练集T=(x1,y1),(x2,y2),...,(x N,y N),联合分布P(X,Y)以及边缘分布P(X)的经验分布都可以由训练数据得到:˜P(X=x,Y=y)=count(X=x,Y=y)N˜P(X=x)=count(X=x)N⽤特征函数f(x,y)描述输⼊x和输出y之间的某⼀个事实,特征函数是⼀个⼆值函数,当x与y满⾜某⼀事实时取1,否则取0。
例如,可以令特征x与标签y在训练集出现过时取1,否则取0。
特征函数f(x,y)关于经验分布˜P(X=x,Y=y)的期望值为:E˜P(f)=∑x,y˜P(x,y)f(x,y)特征函数f(x,y)关于模型P(Y|X)与经验分布˜P(x)的期望值为:E P(f)=∑x,y˜P(x)P(y|x)f(x,y)如果模型能够获取训练数据中的信息,那么就可以假设这两个期望值相等,即:∑x,y ˜P(x,y)f(x,y)=∑x,y˜P(x)P(y|x)f(x,y)将上式作为模型学习的约束条件,条件数量对应特征函数个数,设所有满⾜约束条件的模型集合为:C={P|∑x,y˜P(x,y)fi(x,y)=∑x,y˜P(x)P(y|x)fi(x,y),i=1,2,...,n}其中n为特征函数个数。
定义在条件概率分布P(Y|X)上的条件概率熵为:H(P)=−∑x,y˜P(x)P(y|x)ln P(y|x)模型集合C中条件熵H(P)最⼤的模型称为最⼤熵模型。
第五节最大熵模型最大熵模型(Entropy Model)也是随机概率模型之一。
典型的最大熵模型有Wilson模型和佐佐木(Sasaki)模型,以下分别讲述。
1.Wilson模型Wilson模型是由A.G.Wilson提出的方法,它以英国为中心,在区域科学方面的应用例较多,其模型如下式所示。
(4-5-1)式中,T:对象地区的生成交通量。
即,OD交通量的组合数由求E的最大得到。
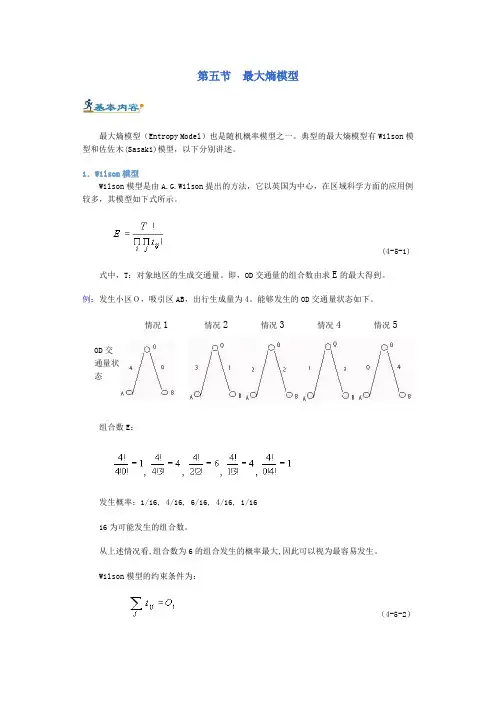
例:发生小区O,吸引区AB,出行生成量为4。
能够发生的OD交通量状态如下。
OD交通量状态情况1 情况2 情况3 情况4情况5组合数E:,,,,发生概率:1/16, 4/16, 6/16, 4/16, 1/1616为可能发生的组合数。
从上述情况看,组合数为6的组合发生的概率最大,因此可以视为最容易发生。
Wilson模型的约束条件为:(4-5-2)(4-5-3)(4-5-4)式中,的交通费用;总交通费用。
最大熵模型一般用以下对数拉格朗日方法求解。
(4-5-5)式中,,,为拉格朗日系数。
应用Stirling公式近似,得,(4-5-6) 代入(4-5-5)式,并对求导数,得,令,得,(4-5-7)∵∴(4-5-8)同样,(4-5-9)这里,令,则(4-5-7)为:(4-5-10)可以看出,式(4-5-10)为重力模型。
Wilson模型的特点:(1)能表现出行者的微观行动;(2)总交通费用是出行行为选择的结果,对其进行约束脱离现实;(3)各微观状态的概率相等,即各目的地的选择概率相等的假设没有考虑距离和行驶时间等因素。
计算步骤:第1步给出第2步给出,求出第3步用求出的,求出第4步如果,非收敛,则返第2步;反之执行第5步。
第5步将,,代入式(4-5-7)求出,这时,如果总用条件( 4-5-4)满足,则结束计算,反之,更新值返回第1步。
2.佐佐木(Sasaki)模型分别设定i区的发生概率和j区的吸引(选择)概率。
, ()--发生守恒条件(4-5-11), ()--吸引守恒条件(4-5-12), () (4-5-13)式中,为i区的发生交通量被j区有吸引的概率。
最大熵原则1. 介绍最大熵原则的概念及背景最大熵原则是一种基于信息论的原则,它认为在不缺乏任何已知信息的情况下,概率模型应该保持最大的不确定性。
这意味着在估计模型参数时,应该选择使得模型熵最大的参数。
最大熵原则的提出源于对信息不完全的处理,它能够在给定有限信息的情况下,更好地描述模型的不确定性。
2. 最大熵原则在自然语言处理中的应用自然语言处理是研究计算机与人类自然语言交互的领域,最大熵原则在其中扮演着重要的角色。
例如,在文本分类任务中,最大熵模型可以根据给定的文本特征和标签信息,学习出一个概率模型,用于判断新文本的类别。
最大熵原则能够充分利用已知的特征信息,同时保持模型的不确定性,使得模型的分类能力更加准确。
3. 最大熵原则在机器学习中的应用机器学习是一种通过从数据中学习模式和规律,从而进行预测和决策的方法。
最大熵原则在机器学习中也有着广泛的应用。
例如,在监督学习中,最大熵模型可以通过最大化训练数据的对数似然函数,学习出一个概率模型,用于预测新样本的标签。
最大熵原则能够充分利用训练数据的信息,同时保持模型的不确定性,使得模型的泛化能力更加强大。
4. 最大熵原则在信息检索中的应用信息检索是指通过检索系统查找与用户信息需求相匹配的文档或资源的过程。
最大熵原则在信息检索中也有着重要的应用。
例如,在文档排序任务中,最大熵模型可以根据用户的查询和文档的特征信息,学习出一个概率模型,用于对文档进行排序。
最大熵原则能够充分利用查询和文档的信息,同时保持模型的不确定性,使得排序结果更加符合用户的需求。
5. 最大熵原则的意义及局限性最大熵原则在概率模型估计中具有重要意义,它能够充分利用已知的信息,同时保持模型的不确定性。
然而,最大熵原则也有其局限性,例如在数据稀疏的情况下,最大熵模型的估计可能存在问题。
此外,最大熵原则也不适用于所有的问题,对于一些特定的场景和任务,其他的原则和方法可能更加合适。
总结起来,最大熵原则是一种在概率模型中进行参数估计的方法,它在自然语言处理、机器学习和信息检索等领域中有着广泛的应用。
贝叶斯最大熵
贝叶斯最大熵(BayesianMaximumEntropy)是信息论中著名的理论之一,它利用熵的概念来表示和分析随机变量的不确定性和不可预测性。
由信息论家Jaynes在1957年提出,它在解决概率推断问题和机器学习问题中有着广泛的应用。
贝叶斯最大熵原理的核心思想是假设按照一定的概率分布来描述随机变量,以最大程度地提高概率模型的不确定性。
使用贝叶斯最大熵模型来进行概率推理,有两种方法:1. maximal entropy distributionMED)法;2. Lagrange multipliers(L-M)方法。
MED 法可以用来构建出一个服从最大熵分布的随机变量,而L-M方法则可以用来求解相关的参数空间。
贝叶斯最大熵模型在条件概率推断中的应用主要是:当需要用概率模型描述的unknow distribution的不确定性很大的时候,而同时又有一些初始的“知识”,这时候可以采用贝叶斯最大熵模型(MED 法)来构建一个参数分布,以反映可能的unknow distribution,并做出相关的预测。
此外,贝叶斯最大熵模型还被广泛应用于机器学习中,在求解复杂的概率模型时,贝叶斯最大熵也可以提供一种求解方案,其结果更加稳定、准确。
具体而言,贝叶斯最大熵模型可以用于分类问题,例如文本分类;也可以用于回归问题,如统计学习中的高斯岭回归;还可以用于优化中的参数估计等问题。
总之,贝叶斯最大熵是一个重要的信息论概念,它可以帮助我们
更好地理解和描述随机变量的不确定性,并且在概率推断和机器学习中有着广泛的应用。
因此,贝叶斯最大熵是未来机器学习和概率推断的重要理论基础。
广义最大熵方程1. 引言广义最大熵方程(Generalized Maximum Entropy Equation)是一种用于推断概率分布的数学模型。
它基于信息论中的最大熵原理,通过最大化系统的不确定性来得到一个满足给定约束条件的概率分布。
广义最大熵方程在机器学习、自然语言处理、统计物理等领域都有广泛应用。
2. 最大熵原理最大熵原理是信息论中的一个重要概念,它认为在缺乏先验知识的情况下,应选择使得概率分布具有最大不确定性的模型。
也就是说,在没有其他约束条件下,我们应选择最均匀的概率分布。
3. 广义最大熵方程推导假设我们有一组约束条件,形如:E(f_i) = ∑ p(x)f_i(x) = F_i其中f_i是特征函数,p(x)是待求解的概率分布,E(f_i)是特征函数在该分布下的期望值,F_i是给定的约束条件。
我们希望找到一个满足这些约束条件且不确定性最大(即熵最大)的概率分布p(x)。
根据最大熵原理,我们可以将该问题转化为一个优化问题,即最大化熵的同时满足约束条件。
定义概率分布p(x)的熵为:H(p) = -∑ p(x)log(p(x))则广义最大熵方程可以表示为以下优化问题:max H(p)s.t. E(f_i) = F_i∑ p(x) = 1p(x) ≥ 04. 广义最大熵模型广义最大熵方程是一个非凸优化问题,很难直接求解。
因此,我们通常使用拉格朗日乘子法来转化为对偶问题,并通过迭代算法进行求解。
在引入拉格朗日乘子后,广义最大熵方程可以重写为如下形式:max L(p,λ,μ)s.t. ∑ p(x)f_i(x) - F_i = 0∑ p(x) - 1 = 0p(x) ≥ 0其中L(p,λ,μ)是拉格朗日函数,λ和μ是拉格朗日乘子。
通过对拉格朗日函数求导,并令导数等于零,可以得到关于概率分布p(x)的更新公式。
一般来说,我们使用迭代算法(如改进的迭代尺度法)来逐步优化概率分布,直到收敛到最优解。
5. 应用举例广义最大熵方程在自然语言处理中有广泛应用。
最大熵模型原理嘿,朋友们!今天咱来聊聊这个特别有意思的最大熵模型原理。
你说啥是最大熵模型呀?这就好比你去参加一场比赛,规则就是要在各种可能性中找到最公平、最不偏袒任何一方的那个选择。
就像咱平时分东西,得让每个人都觉得公平合理,不能厚此薄彼,这就是最大熵模型在努力做到的事儿。
咱想象一下哈,世界这么大,事情那么多,要怎么去判断哪种情况最有可能发生呢?最大熵模型就像是个聪明的裁判,它不随便猜测,而是根据已知的信息,尽可能地让结果最广泛、最不确定,也就是让可能性最多。
这多有意思呀!比如说天气预报,咱都知道天气变化多端,那怎么预测明天是晴天还是下雨呢?最大熵模型就会综合各种因素,像温度啦、湿度啦、气压啦等等,然后给出一个最有可能的结果,但它可不会随便就说肯定是晴天或者肯定是下雨,它会考虑到各种可能情况呢。
再打个比方,就像你去抽奖,你不知道会抽到啥,但最大熵模型会告诉你,在所有可能的奖品中,每个都有一定的可能性被抽到,不会偏向任何一个。
是不是很神奇?你想想看,要是没有这个最大熵模型,那我们的很多预测和判断不就变得很不靠谱啦?它就像是我们生活中的一个小助手,默默地帮我们理清各种可能性。
而且啊,这个最大熵模型在很多领域都大显身手呢!在自然语言处理里,它能帮助我们理解和生成更准确的语言;在图像识别中,也能让我们更精确地识别各种物体。
它就像一个万能钥匙,能打开很多难题的大门。
那为啥最大熵模型这么厉害呢?这是因为它遵循了一个很重要的原则,就是不做过多的假设,只根据已有的信息来推断。
这就好比我们做人,不能随便猜测别人,要根据实际情况来判断。
所以啊,朋友们,可别小看了这个最大熵模型原理,它虽然听起来有点深奥,但其实就在我们身边,影响着我们的生活呢!它让我们的世界变得更加有序,让我们的预测和判断更加可靠。
你说,它是不是超级棒呢?反正我是觉得它厉害得很呢!。
高斯分布最大熵
高斯分布,又称正态分布,是概率论与统计学中常用的一种连续概率分布。
它具有钟形曲线的特征,以均值μ和方差σ^2作为参数来描述。
最大熵,是一种信息理论中的概念,指的是在已知一些约束条件的情况下,选择一个概率分布使得其信息熵最大。
最大熵原理是指在无其他信息的情况下,应选择信息熵最大的概率分布作为模型的默认分布。
高斯分布具有最大熵的性质,即在已知均值和方差的约束条件下,高斯分布的熵达到最大。
这是由于在所有具有相同均值和方差的连续分布中,高斯分布的信息熵是最大的,意味着它是对未知情况的最不确定性假设。
最大熵原理还可以用于解决其他的概率模型选择问题,如自然语言处理、图像处理等。
通过最大熵原理,可以构建出更合理且更具泛化能力的模型,提高预测与估计的准确性。
高斯分布和最大熵的研究被广泛应用于各个领域,如信号处理、机器学习、统计推断等。
在实际应用中,我们可以利用高斯分布的最大熵性质来对数据进行建模和分析,进而推断出未知的概率分布和参数估计。
总而言之,高斯分布与最大熵是统计学中重要且相关的概念,它们在数据分析和模型构建中扮演着重要的角色,促进了对随机现象的深入理解与预测能力的提升。
最大熵算法笔记
最大熵,就是要保留全部的不确定性,将风险降到最小,从信息论的角度讲,就是保留了最大的不确定性。
最大熵原理指出,当我们需要对一个随机事件的概率分布进行预测时,我们的预测应当满足全部已知的条件,而对未知的情况不要做任何主观假设。
在这种情况下,概率分布最均匀,预测的风险最小。
因为这时概率分布的信息熵最大,所以人们称这种模型叫"最大熵模型"。
匈牙利著名数学家、信息论最高奖香农奖得主希萨(Csiszar)证明,对任何一组不自相矛盾的信息,这个最大熵模型不仅存在,而且是唯一的。
而且它们都有同一个非常简单的形式-- 指数函数。
我们已经知道所有的最大熵模型都是指数函数的形式,现在只需要确定指数函数的参数就可以了,这个过程称为模型的训练。
最原始的最大熵模型的训练方法是一种称为通用迭代算法GIS (generalized iterative scaling) 的迭代算法。
GIS 的原理并不复杂,大致可以概括为以下几个步骤:
1. 假定第零次迭代的初始模型为等概率的均匀分布。
2. 用第N 次迭代的模型来估算每种信息特征在训练数据中的分布,如果超过了实际的,就把相应的模型参数变小;否则,将它们便大。
3. 重复步骤2 直到收敛。
GIS 最早是由Darroch 和Ratcliff 在七十年代提出的。
但是,这两人没有能对这种算法的物理含义进行很好地解释。
后来是由数学家希萨(Csiszar) 解释清楚的,因此,人们在谈到这个算法时,总是同时引用Darroch 和Ratcliff 以及希萨的两篇论文。
GIS 算法每
次迭代的时间都很长,需要迭代很多次才能收敛,而且不太稳定,即使在64 位计算机上都会出现溢出。
因此,在实际应用中很少有人真正使用GIS。
大家只是通过它来了解最大熵模型的算法。
八十年代,很有天才的孪生兄弟的达拉皮垂(Della Pietra) 在IBM 对GIS 算法进行了两方面的改进,提出了改进迭代算法IIS (improved iterative scaling)。
这使得最大熵模型的训练时间缩短了一到两个数量级。
这样最大熵模型才有可能变得实用。
即使如此,在当时也只有IBM 有条件是用最大熵模型。
由于最大熵模型在数学上十分完美,对科学家们有很大的诱惑力,因此不少研究者试图把自己的问题用一个类似最大熵的近似模型去套。
谁知这一近似,最大熵模型就变得不完美了,结果可想而知,比打补丁的凑合的方法也好不了多少。
于是,不少热心人又放弃了这种方法。
第一个在实际信息处理应用中验证了最大熵模型的优势的,是宾夕法尼亚大学马库斯的另一个高徒原IBM 现微软的研究员拉纳帕提(Adwait Ratnaparkhi)。
拉纳帕提的聪明之处在于他没有对最大熵模型进行近似,而是找到了几个最适合用最大熵模型、而计算量相对不太大的自然语言处理问题,比如词性标注和句法分析。
拉纳帕提成功地将上下文信息、词性(名词、动词和形容词等)、句子成分(主谓宾)通过最大熵模型结合起来,做出了当时世界上最好的词性标识系统和句法分析器。
拉纳帕提的论文发表后让人们耳目一新。
拉纳帕提的词性标注系统,至今仍然是使用单一方法最好的系统。
科学家们从拉纳帕提的成就中,又看到了用最大熵模型解决复杂的文字信息处理的希望。
但是,最大熵模型的计算量仍然是个拦路虎。
我在学校时花了很长时间考虑如何简化最大熵模型的计算量。
终于有一天,我对我的导师说,我发现一种数学变换,可以将大部分最大熵模型的训练时间在IIS 的基础上减少两个数量级。
我在黑板上推导了一个多小时,他没有找出我的推导中的任何破绽,接着他又回去想了两天,然后告诉我我的算法是对的。
从此,我们就建造了一些很大的最大熵模型。
这些模型比修修补补的凑合的方法好不少。
即使在我找到了快速训练算法以后,为了训练一个包含上下文信息,主题信息和语法信息的文法模型(language model),我并行使用了20 台当时最快的SUN 工作站,仍然计算了三个月。
由此可见最大熵模型的复杂的一面。
最大熵模型快速算法的实现很复杂,到今天为止,世界上能有效实现这些算法的人也不到一百人。
有兴趣实现一个最大熵模型的读者可以阅读我的论文。
最大熵模型,可以说是集简与繁于一体,形式简单,实现复杂。
值得一提的是,在Google的很多产品中,比如机器翻译,都直接或间接地用到了最大熵模型。
讲到这里,读者也许会问,当年最早改进最大熵模型算法的达拉皮垂兄弟这些年难道没有做任何事吗?他们在九十年代初贾里尼克离开IBM 后,也退出了学术界,而到在金融界大显身手。
他们两人和很多IBM 语音识别的同事一同到了一家当时还不大,但现在是世界上最成功对冲基金(hedge fund)公司----文艺复兴技术公司(Renaissance Technologies)。
我们知道,决定股票涨落的因素可能有几十甚至上百种,而最大熵方法恰恰能找到一个同时满足成千上万种
不同条件的模型。
达拉皮垂兄弟等科学家在那里,用于最大熵模型和其他一些先进的数学工具对股票预测,获得了巨大的成功。
从该基金1988 年创立至今,它的净回报率高达平均每年34%。
也就是说,如果1988 年你在该基金投入一块钱,今天你能得到200 块钱。
这个业绩,远远超过股神巴菲特的旗舰公司伯克夏哈撒韦(Berkshire Hathaway)。
同期,伯克夏哈撒韦的总回报是16 倍。
最大熵训练算法的比较
最大熵模型做为一个数学模型有一些特殊的或者通用的训练算法,比较常见的有GIS,SCGIS,IIS,LBFGS等,这里我根据自己的经验对他们做一番比较,仅供参考。
收敛速度:
既然是最优化算法,那么收敛速度是重要的性能衡量标准之一。
GIS算法在这方面的表现不敢令人恭维,在大的数据模型上大家可能只能用最大迭代次数来限制训练时间了。
SCGIS是在GIS算法的基础上做了优化,使减速因子变小,从而收敛速度能提高几十倍左右。
LBFGS算法是一种通用的最优化方法,其基于牛顿算法的思想,收敛速度自也不慢,比SCGIS稍快一些。
单次迭代速度:
单次迭代速度也是影响训练算法性能的重要因素之一,否则一次迭代
就耗上半日,任你收敛再快,也是无用
GIS算法单次迭代是最快的,时间复杂度和特征数量成线性关系,但其实就时间复杂度来说三种算法都差不多
SCGIS算法单次迭代速度比GIS慢,在我们的系统中大概是3倍左右,主要由于SCGIS算法中数学运算比较多,所以其实现起来要特别注意针对数学运算的优化,不过终究是比GIS要慢的
LBFGS算法单次迭代速度比GIS算法稍慢,因为在算法内部除了和GIS算法类似的求模型期望外还多了一些线扫描之类的东西,但通常情况下这些操作都是很快的
稳定性:
这个纯粹是我们根据对特定数据上结果的观测总结出来的经验结果,无任何理论根据
GIS算法由于训练过慢故在实验中放弃掉了
SCGIS算法在用不同的参数进行训练的时候表现诡异,罕有规律可循LBFGS算法在进行各种实验的时候表现相对稳定,在一定的误差下有一些规律
IIS算法在我们的系统中没有实现,故不可妄加评论,只在一些论文中看到过其一些表现,大致为收敛较快,单次迭代慢,故总体类同于GIS算法,也属iterative scaling流派。