实验一 数据报文分析 实验报告
- 格式:doc
- 大小:203.50 KB
- 文档页数:5
数据通信网络技术实验一一、实验目的:1.掌握网络设备的基本操作和日常维护;2.了解生成树协议spanning tree protocal的基本概念基本原理,掌握stp的基本配置步骤;3.了解vlan的基本概念和基本原理,掌握vlan的基本配置步骤。
二、实验要求:1.根据实验的任务要求,参考实验指导材料,完成实验,输入操作命令,观察输出结果,详细记录每个步骤的操作结果;2.在两台交换机的相应端口上开启STP,避免环路的出现,记录每个步骤的操作结果;3.两台交换机分别划分两个valn:vlan10、vlan20,要求同vlan能够跨越交换机互通,详细记录每个步骤的操作结果。
三、实验原理:1.STP协议的基本概念和基本原理基本定义:STP(Spanning-Tree Protocol),中文称生成树协议作用是能够发现并自动消除冗余网络拓扑中的环路。
它由规范IEEE 802.1D 规定,是指通过生成树的算法,暂时切断所有冗余的连接,使网络拓扑生成一个树的结构,消除网络循环,即保证从树的一点到其它任何一点只有一条路径。
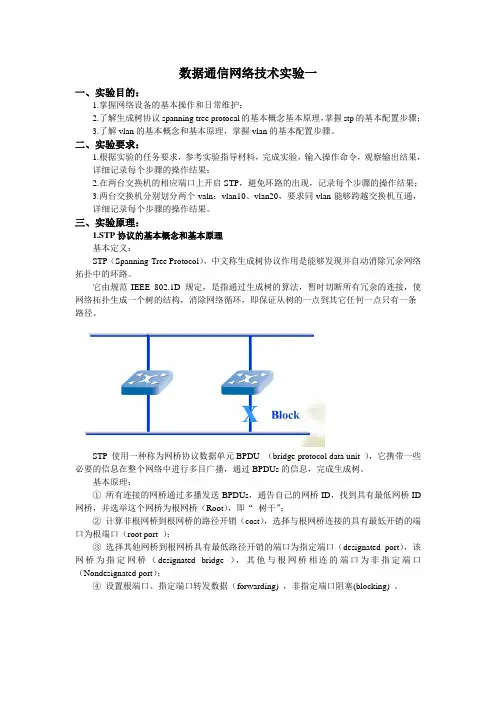
STP 使用一种称为网桥协议数据单元BPDU (bridge protocol data unit ),它携带一些必要的信息在整个网络中进行多目广播,通过BPDUs的信息,完成生成树。
基本原理:①所有连接的网桥通过多播发送BPDUs,通告自己的网桥ID,找到具有最低网桥ID 网桥,并选举这个网桥为根网桥(Root),即“树干”;②计算非根网桥到根网桥的路径开销(cost),选择与根网桥连接的具有最低开销的端口为根端口(root port );③选择其他网桥到根网桥具有最低路径开销的端口为指定端口(designated port),该网桥为指定网桥(designated bridge ),其他与根网桥相连的端口为非指定端口(Nondesignated port);④设置根端口、指定端口转发数据(forwarding) ,非指定端口阻塞(blocking) 。

一、实训目的本次数据报文交换实训旨在通过模拟实际网络环境,让学生深入了解数据报文交换的原理、过程和关键技术,掌握报文交换的基本操作,提高网络通信技能。
通过实训,学生能够:1. 理解数据报文交换的基本概念和原理;2. 掌握报文交换的关键技术,如报文路由、差错控制、流量控制等;3. 熟悉网络设备配置和报文交换实验环境搭建;4. 提高网络通信实践操作能力,为今后从事网络相关工作打下基础。
二、实训环境1. 硬件环境:实验室内配备有网络交换机、路由器、计算机等网络设备;2. 软件环境:使用网络模拟软件(如GNS3、Packet Tracer等)进行实验;3. 实验内容:数据报文交换的原理、过程、关键技术、实验环境搭建及操作。
三、实训原理数据报文交换是一种基于分组交换技术的通信方式,它将数据分割成若干个报文,每个报文独立进行传输。
在传输过程中,报文可能经过不同的路径,到达目的地的顺序可能不同,但最终会按照一定的顺序重新组装成完整的数据。
数据报文交换的主要原理包括:1. 分组交换:将数据分割成固定大小的报文,便于传输和处理;2. 路由选择:根据网络状况和路由协议,选择最佳路径进行报文传输;3. 差错控制:通过校验和、重传机制等手段,保证报文传输的可靠性;4. 流量控制:通过滑动窗口、拥塞控制等手段,防止网络拥塞。
四、实训过程1. 实验环境搭建:使用网络模拟软件搭建实验环境,包括网络拓扑结构、设备配置等;2. 报文交换原理演示:通过软件演示数据报文交换的原理,让学生了解报文交换的基本过程;3. 实验操作:分组交换实验、路由选择实验、差错控制实验、流量控制实验等;4. 实验结果分析:对实验结果进行分析,总结实验过程中的问题及解决方法。
五、实训结果1. 学生对数据报文交换的基本概念和原理有了深入理解;2. 掌握了报文交换的关键技术,如报文路由、差错控制、流量控制等;3. 熟悉了网络设备配置和报文交换实验环境搭建;4. 提高了网络通信实践操作能力。

UDP报文分析实验报告范文udp实验结果及分析实验报告实验名称UDP报文分析姓名学号实验日期2015.09.17实验报告要求:1.实验目的2.实验要求3.实验环境4.实验作业【实验目的】1.复习Wireshark抓包工具的使用及数据包分析方法;2.分析UDP报文3.校验和检验【实验要求】用Wireshark1.12.3截UDP包,分析数据包。
【实验环境】用以太网交换机连接起来的windows8.1操作系统的计算机,通过iNode客户端接入Internet。
【实验作业】1.截包在Filter处输UDP截到的没有UDP,选udpencap后截到UDP报文。
UDP是封装在IP里的。
2.报文字段分析=1\*GB3①源端口源端口号是8000。
关于端口号有一些规定,服务器端通常用知名端口号,通常在0-1023之间。
而客户端用随机的端口号,其范围在49152到65535之间。
=2\*GB3②目的端口=3\*GB3③报文长度=4\*GB3④校验和=5\*GB3⑤数据3.校验和计算(与IP首部校验和计算方法相同)=1\*GB3①UDP的校验和所需信息:UDP伪首部:源IP+目的IP+Byte0+Byte17+UDP长度,其目的是让UDP两次检查数据是否已经正确到达目的地,只是单纯为了做校验用的。
UDP首部:该长度不是报文的总长度,而只是UDP(包括UDP头和数据部分)的总长度UDP的数据部分。
=2\*GB3②计算步骤把伪首部添加到UDP上;计算初始时将校验和字段添零的;把所有位划分为16位(2字节)的字;把所有16位的字相加,如果遇到进位,则将高于16字节的进位部分的值加到最低位上。
将所有字相加得到的结果应该为一个16位的数,将该数按位取反则可以得到校验和。
=3\*GB3③计算由上图可知源IP:111.161.88.16、目的IP:10.104.113.47、UDP 长度:47和数据。
计算后得校验和正确。
成绩优良中及格不及格教师签名:日期:。

洛阳理工学院实验报告
减少不必要的数据。
按照下面的步骤完成实验内容。
(一)建立连接
三次握手
1)源主机向目的主机发送连接请求
报头:
源端口号:1865
目的端口号:http(80)
序列号:0(源主机选择0作为起始序号)
报头长度:28字节
标志位:仅SYN设为1,请求建立连接,ACK:notset 窗口大小:64240字节
选项字段:8字节
2)目的主机返回确认信号
报头:
源端口号:http(80)
目的端口号:1865
序列号:0(目的主机选择0作为起始序号)
报头长度:28字节
标志位:SYN设为1,ACK设为1,确认允许建立连接
窗口大小:16384字节
选项字段:8字节
3)源主机再次返回确认信息,并可以携带数据
报头:
源端口号:1865
目的端口号:http(80)
序列号:1(发送的报文段编号)
报头长度:20字节
标志位:SYN=1,ACK=1
窗口大小:64240字节
(二)关闭连接
四次握手
1)源主机向目的主机发送关闭连接请求,FIN=1 2)目的主机返回确认信号,ACK=1
3)目的主机允许关闭连接,FIN=1
4)源主机返回确认信号,ACK=1
实验总结:在这次试验中我学会了抓包,虽然现在还不是特别理解这里面好些东西的含义,但是我相信随着后来学习的加深,最终会了解的更多,抓包后可以查看网络的状态以及路由器之间的访问顺序,途径等等,可以更好的了解网络的工作状态。

网络报文分析实验报告实验目的本次实验旨在通过对网络报文的分析,深入了解网络通信过程中数据的传输和交互。
实验背景随着互联网的快速发展,网络通信已经成为了人们日常生活中一个不可或缺的组成部分。
网络通信的基本单位是报文,它是在网络中传输的数据单元。
通过对网络报文的分析,可以帮助我们更好地理解、掌握网络通信的工作原理。
实验材料- Wireshark软件:用于捕获和分析网络报文。
实验步骤1. 下载并安装Wireshark软件。
2. 打开Wireshark软件并选择要监测的网络接口。
3. 开始捕获网络报文。
4. 执行特定操作,如访问一个网页、发送邮件等,以产生网络通信。
5. 停止网络报文捕获。
6. 分析捕获到的网络报文。
实验结果通过对网络报文的捕获和分析,我们可以了解到以下几个方面的信息:1. 源IP地址和目标IP地址:可以确定报文是从哪个主机发送到哪个主机。
2. 源端口号和目标端口号:可以确定报文是通过哪个应用程序发送和接收的。
3. 报文的数据内容:可以查看报文中的数据部分,并进行进一步的分析,如解码加密的数据、查找特定信息等。
4. 报文的协议类型:可以确定报文使用的是哪个协议,如TCP、UDP、HTTP 等。
5. 报文的长度和时间戳:可以了解报文的大小和传输时间。
实验分析通过分析捕获到的网络报文,我们可以获得以下几个方面的信息:1. 网络通信的双方:通过源IP地址和目标IP地址,我们可以知道网络通信是由哪两台主机之间进行的。
2. 通信所使用的协议:通过报文的协议类型,我们可以确定报文是使用TCP、UDP、HTTP还是其他协议进行传输。
3. 通信的具体内容:通过分析报文的数据部分,我们可以了解到通信中传输的具体内容,如网页的HTML代码、文件的二进制数据等。
4. 通信的时间和速率:通过报文的时间戳和长度,我们可以了解到通信过程所花费的时间和传输速率。
实验总结通过本次实验,我们对网络报文的分析有了更深入的了解。


《计算机网络》实验报告信息安全1201吴淑珍2012080601222015年4月1日1.实验报告内容包括:实验目的、实验内容、实验程序和程序流程图、实验步骤、记录中间结果和最终结果。
实验一应用协议与数据包分析实验(使用Wireshark)一、实验目的通过本实验,熟练掌握Wireshark的操作和使用,学习对HTTP协议进行分析。
二、实验内容学习HTTP 协议,了解HTTP 的工作原理和HTTP 报文格式。
运行Wireshark,截获在浏览器访问web界面的报文,并根据截获的报文分析其格式与内容,进一步学习 HTTP 协议工作过程。
三、实验步骤步骤1:在PC 机上运行Wireshark,开始截获报文;步骤2:从浏览器上访问Web 界面,如。
打开网页,待浏览器的状态栏出现“完毕”信息后关闭网页。
步骤3:停止截获报文,将截获的报文命名为http-学号保存。
步骤4:分析截获的报文。
四、实验结果分析截获的报文,回答以下几个问题:1)综合分析截获的报文,查看有几种HTTP 报文?答:两种,一种是请求报文,请求行方法为GET(有一个截去顶端的GET);另一种是响应报文。
2)在截获的HTTP 报文中,任选一个HTTP 请求报文和对应的 HTTP 应答报文,仔细分析它们的格式,填写表1.1 和表1.2。
表1.1 HTTP 请求报文格式*GET方法首部行后面没有实体主体。
*实体主体部分为服务器发送给客户的对象。
***查找的资料Content-Length用于描述HTTP消息实体的传输长度。
在HTTP协议中,消息实体长度和消息实体的传输长度是有区别,比如说gzip压缩下,消息实体长度是压缩前的长度,消息实体的传输长度是gzip压缩后的长度。
在具体的HTTP交互中,客户端是如何获取消息长度的呢,主要基于以下几个规则:响应为1xx,204,304相应或者head请求,则直接忽视掉消息实体内容。
如果有Transfer-Encoding,则优先采用Transfer-Encoding里面的方法来找到对应的长度。

一、实验目的1. 理解网络报文的基本概念和结构;2. 掌握网络报文的发送和接收过程;3. 熟悉网络报文的调试和优化方法;4. 提高网络编程能力。
二、实验环境1. 操作系统:Windows 102. 编程语言:C++3. 网络设备:局域网(以太网)4. 实验工具:Wireshark三、实验内容1. 网络报文结构分析2. 网络报文发送与接收3. 网络报文调试与优化四、实验步骤1. 网络报文结构分析(1)使用Wireshark抓取网络报文,观察报文结构;(2)分析报文头部信息,包括源IP地址、目的IP地址、端口号等;(3)分析报文负载部分,了解数据传输内容。
2. 网络报文发送与接收(1)编写C++程序,实现网络报文的发送和接收功能;(2)设置发送和接收端口号,确保程序正常运行;(3)编写测试用例,验证程序功能。
3. 网络报文调试与优化(1)使用Wireshark抓取网络报文,分析报文发送和接收过程;(2)检查报文头部信息,确保正确无误;(3)针对发送和接收速度进行优化,提高程序性能。
五、实验结果与分析1. 网络报文结构分析通过Wireshark抓取网络报文,我们可以观察到以下结构:(1)头部信息:包括源IP地址、目的IP地址、端口号、协议类型等;(2)负载信息:数据传输内容。
2. 网络报文发送与接收编写C++程序,实现网络报文的发送和接收功能。
程序运行结果如下:(1)发送端:成功发送网络报文,报文头部信息正确;(2)接收端:成功接收网络报文,报文头部信息正确。
3. 网络报文调试与优化通过Wireshark抓取网络报文,分析报文发送和接收过程。
针对发送和接收速度进行优化,提高程序性能。
优化后,发送和接收速度得到明显提升。
六、实验总结本次实验使我们对网络报文有了更深入的了解,掌握了网络报文的发送和接收过程,并学会了网络报文的调试和优化方法。
以下为实验心得体会:1. 网络编程需要熟悉网络报文结构,了解报文头部信息;2. 网络编程过程中,调试和优化是提高程序性能的关键;3. Wireshark是一款强大的网络抓包工具,可以帮助我们分析网络报文。

数据与分析实验报告1. 引言数据分析是一种通过分析和解释数据来确定模式、关系以及其他有价值信息的过程。
在现代社会中,数据分析已经成为各个领域中不可或缺的工具。
本实验旨在通过对一个特定数据集的分析,展示数据分析的过程以及结果的解读和应用。
本实验选择了一组关于学业表现的数据进行分析,并探讨了学生的各项指标与其学习成绩之间的关系。
2. 数据集描述本次实验所使用的数据集是一个包含了1000名学生的学术成绩和相关指标的数据集。
数据集中包含了每位学生的性别、年龄、是否拥有本科学历、成绩等信息。
数据集以CSV格式提供。
3. 数据清洗与预处理在进行数据分析之前,首先需要进行数据清洗和预处理的工作,以保证后续分析的准确性和可靠性。
本实验中的数据集在经过初步检查后,发现存在一些缺失值和错误值。
为了保证数据的完整性,我们采取了以下措施进行数据清洗:- 删除缺失值:对于存在缺失值的数据,我们选择了删除含有缺失值的行。
- 纠正错误值:通过对每个指标的合理范围进行了限定,排除了存在明显错误值的数据。
此外,还进行了数据的标准化处理,以确保各项指标具有可比性。
4. 数据探索与分析4.1 性别与学习成绩的关系为了探究性别与学习成绩之间的关系,我们进行了如下分析:- 绘制了性别与学习成绩的散点图,并使用不同的颜色进行了标记。
通过观察散点图,我们可以初步得出性别与学习成绩之间存在一定的关系。
但由于性别只是一个二分类变量,为了更加准确地探究性别与学习成绩之间的关系,我们使用了ANOVA分析进行了验证。
4.2 年龄与学习成绩的关系为了探究年龄与学习成绩之间的关系,我们进行了如下分析:- 将学生按年龄分组,计算每个年龄组的平均成绩,并绘制了年龄与学习成绩的折线图。
通过观察折线图,我们可以发现年龄与学习成绩之间存在一定的曲线关系。
年龄在一定范围内的增长会对学习成绩产生积极影响,但随着年龄的增长,学习成绩会逐渐下降。
4.3 学历与学习成绩的关系为了探究学历与学习成绩之间的关系,我们进行了如下分析:- 计算了不同学历组的平均学习成绩,并绘制了学历与学习成绩的柱状图。

分析数据实训报告1. 引言本报告是针对分析数据实训项目的报告。
项目是基于提供的数据集进行分析工作,旨在探索数据的特征和关联性,并通过数据可视化的方式呈现分析结果。
本报告将介绍项目的背景、数据集的概述、分析方法和结果。
2. 背景数据分析在现代社会中扮演着重要的角色,帮助人们更好地理解和利用数据。
分析数据实训项目旨在让学员通过实践项目,掌握数据分析的基本工具和技巧。
此项目要求学员能够运用数据分析工具和统计方法,从给定的数据集中提取有用的信息和洞察力。
3. 数据集概述本项目使用的数据集是一个包含多个变量的表格。
数据集的每一行代表一个样本,每一列代表一个变量。
数据集中的变量包括但不限于年龄、性别、收入、教育程度等。
数据集还包含了一些其他指标,如消费习惯、购物行为等。
数据集的规模为1000行 × 20列。
4. 分析方法为了更好地理解数据集并发现其中的模式和关联性,我们采用了以下分析方法:4.1 数据清洗在进行分析之前,我们首先对数据进行了清洗。
清洗的过程包括处理缺失值、删除异常值、处理重复数据等。
通过数据清洗,我们确保了分析的准确性和可靠性。
4.2 描述性统计分析描述性统计是一种描述和总结数据的方法。
我们对数据集中的各个变量进行了描述性统计分析,包括计算均值、中位数、标准差、最小值、最大值等。
通过描述性统计,我们得到了各个变量的基本统计特征,从而更好地了解了数据的分布和范围。
4.3 相关性分析为了研究数据集中变量之间的关联性,我们进行了相关性分析。
我们计算了各个变量之间的相关系数,并通过热图的形式进行了可视化展示。
通过相关性分析,我们发现了一些变量之间具有较强的相关性,这为后续的分析工作提供了指导。
4.4 数据可视化数据可视化是一种将数据以图形的形式展现出来的方法。
为了更好地理解数据集,并能够直观地展示分析结果,我们使用了数据可视化技术。
我们绘制了柱状图、折线图、散点图等不同类型的图表,以展示数据的不同特征和关系。

第1篇一、实验背景随着互联网技术的飞速发展,数据已经成为现代社会的重要资源。
大数据分析作为一种新兴的技术手段,通过对海量数据的挖掘和分析,为企业、政府和研究机构提供了决策支持。
本实验旨在通过实际操作,掌握大数据分析的基本流程和方法,提高对大数据技术的理解和应用能力。
二、实验目的1. 熟悉大数据分析的基本流程。
2. 掌握常用的数据预处理方法。
3. 熟悉大数据分析工具的使用。
4. 能够对实际数据进行有效的分析和解读。
三、实验环境1. 操作系统:Windows 102. 数据库:MySQL 5.73. 编程语言:Python 3.74. 大数据分析工具:Pandas、NumPy、Matplotlib、Scikit-learn5. 云计算平台:阿里云四、实验内容(一)数据采集本实验选取某电商平台的用户购买数据作为分析对象,数据包含用户ID、购买时间、商品ID、商品类别、购买金额等字段。
(二)数据预处理1. 数据清洗:去除重复数据、处理缺失值、修正错误数据。
2. 数据转换:将时间戳转换为日期格式,对金额进行归一化处理。
3. 特征工程:提取用户购买行为特征,如购买频率、购买金额等。
(三)数据分析1. 用户画像:分析用户购买偏好、购买频率等特征。
2. 商品分析:分析商品销量、商品类别分布等特征。
3. 购买行为分析:分析用户购买时间分布、购买金额分布等特征。
(四)实验结果与分析1. 用户画像分析根据用户购买数据,我们可以得出以下结论:(1)年轻用户购买频率较高,偏好时尚、电子产品等商品。
(2)中年用户购买金额较高,偏好家居、家电等商品。
(3)老年用户购买频率较低,偏好健康、养生等商品。
2. 商品分析根据商品购买数据,我们可以得出以下结论:(1)电子产品销量最高,其次是家居、家电等商品。
(2)商品类别分布较为均匀,但电子产品、家居、家电等类别占比相对较高。
3. 购买行为分析根据购买时间、购买金额等数据,我们可以得出以下结论:(1)用户购买时间主要集中在上午10点到下午6点。
一、实验目的1. 理解数据报文的基本概念和结构。
2. 掌握数据报文的传输过程。
3. 熟悉数据报文的处理方法。
4. 培养实际操作能力和问题解决能力。
二、实验环境1. 操作系统:Windows 102. 网络设备:路由器、交换机、计算机3. 实验工具:Wireshark网络抓包工具三、实验内容1. 数据报文的基本概念2. 数据报文的传输过程3. 数据报文的处理方法4. 数据报文实验四、实验步骤1. 数据报文的基本概念(1)定义:数据报文(Data Packet)是指在网络中传输的数据单元,它包含了源地址、目的地址、数据内容等信息。
(2)结构:数据报文通常由头部和负载两部分组成。
头部包含了源地址、目的地址、协议类型、数据长度等控制信息;负载包含了实际传输的数据。
2. 数据报文的传输过程(1)源主机发送数据报文:源主机将待传输的数据封装成数据报文,并添加头部信息,然后将数据报文发送到网络。
(2)数据报文在网络中的传输:数据报文在网络中通过路由器、交换机等设备进行转发,直至到达目的主机。
(3)目的主机接收数据报文:目的主机接收数据报文,解析头部信息,提取数据内容,完成数据传输。
3. 数据报文的处理方法(1)校验和:数据报文在传输过程中可能会受到干扰,为了检测数据是否完整,数据报文通常会添加校验和。
(2)分片:当数据报文长度超过最大传输单元(MTU)时,需要进行分片处理。
分片后的数据报文在网络中独立传输,到达目的主机后再进行重组。
(3)路由选择:数据报文在网络中的传输需要选择合适的路由,路由器根据目的地址进行路由选择。
4. 数据报文实验(1)实验环境搭建:将计算机、路由器、交换机连接成网络,并配置IP地址。
(2)使用Wireshark抓包:在计算机上运行Wireshark,设置抓包过滤器为“IP”,观察数据报文在网络中的传输过程。
(3)分析数据报文:观察数据报文的头部信息,如源地址、目的地址、协议类型等,分析数据报文的传输过程。
实验一:TCP数据包捕获及分析实验学时:4实验类型:设计实验要求:选做一、实验目的理解网络数据包的捕获原理及一般分析方法。
二、实验内容根据参考程序编写一段基于Winpcap的TCP数据包捕获并分析的程序。
要求能正确解析TCP报头的相关内容。
三、实验原理、方法和手段以太网(Ethernet)具有共享介质的特征,信息是以明文的形式在网络上传输,当网络适配器设置为监听模式(混杂模式,Promiscuous)时,由于采用以太网广播信道争用的方式,使得监听系统与正常通信的网络能够并联连接,并可以捕获任何一个在同一冲突域上传输的数据包。
IEEE802.3 标准的以太网采用的是持续CSMA 的方式,正是由于以太网采用这种广播信道争用的方式,使得各个站点可以获得其他站点发送的数据。
运用这一原理使信息捕获系统能够拦截的我们所要的信息,这是捕获数据包的物理基础。
Winpcap是针对Win32平台上的抓包和网络分析的一个架构。
它包括一个核心态的包过滤器,一个底层的动态链接库(packet.dll)和一个高层的不依赖于系统的库(wpcap.dll)。
抓包是NPF最重要的操作。
在抓包的时候,驱动使用一个网络接口监视着数据包,并将这些数据包完整无缺地投递给用户级应用程序。
四、实验组织运行要求1.安装Winpcap驱动及开发库。
2.在VC++6.0环境下进行程序编写五、实验条件PC机VC++6.0,winpcap驱动及开发库六、实验步骤1、安装winpcap驱动2、解压WpdPack_4_0_2.zip到磁盘,例如D盘,并将文件夹名改为WpdPack,即开发库放在D:\WpdPack 目录下。
3、设置编程环境要想例如Winpcap的开发库进行编程,就必须在VC++6.0配置与Winpcap相关的头文件和库文件的位置。
其次,为了在Microsoft VC++项目中添加一个新库连接,须要从菜单Project中选择Settings,再在tab控件中选择Link,然后在Objcet/library modules编辑框中加入要加入的新连接库名字(wpcap.lib ws2_32.lib)。
实验一 数据报文分析一、实验目的1、深入理解以太网原理;2、理解ARP 协议、ICMP 协议、IP 协议和TCP 协议的原理;3、掌握wireshark 软件的使用方法。
二、实验原理1、以太网的工作原理(1) 在以太网中是基于广播方式传输数据的,即所有的物理信号都要经过同一网段的所有设备。
(2) 网卡可设置成混杂模式,在这种模式下网卡能接收到一切通过它的数据,能不管实际上的数据的目的地址是不是它。
计算机直接传输的数据是大量的二进制数据,因此一个网络监听程序还必须使用特定的网络协议来分解嗅探到的数据,嗅探器通过解析数据包头部的各字段含义,能够识别出这个数据片段对应于哪个协议,实现正确得解码。
应用层物理层链路层网络层运输层图 TCP/IP 协议族中不同层次的协议2、协议标识由于TCP 、UDP 、ICMP 和IGMP 都向IP 传输数据,因此IP 头部必须加入标识字段,以表明数据属于哪种协议,在IP 的头部信息中有8bit 长度的字段,称作协议域,其中1表示为ICMP ,2表示为IGMP ,6表示为TCP ,17表示为UDP 协议。
三、实验所用设备本实验中不需要动手连线,机房中所有主机均通过交换机相连,组成局域网。
相邻的2名同学组成一个小组,完成本次实验。
四、实验步骤1、网络命令学习(1)点击“开始”→“运行”,输入cmd回车,打开的是dos的命令窗口,在命令行中输入ipconfig命令,查看计算机当前的IP地址、子网掩码和默认网关。
添加上参数,输入ipconfig /all 记录本地连接中IP地址,MAC地址(Physical Address),网关(Default Gateway)等信息。
如:MAC:00-98-99-00-EA-32IP:222.28.78.X网关:222.28.78.1(2)在命令行下输入route print命令,查看本机上路由表信息。
(3)输入arp –a 命令,查看本地高速缓存中IP地址和MAC地址的信息,并记录下来。
网络管理实验————SNMP报文解析2010-6-14.trap操作:Sniffer软件截获到的trap报文如下图所示:30 2e SNMP报文是ASN.1的SEQUENCE 类型,报文长度是46个八位组。
02 01 00:版本号为integer类型,取值为0,表示snmpv1。
04 06 70 75 62 6c 69 63:团体名为octet string类型,值为“public”a4 21: 表示pdu类型为trap,长度为33个八位组。
06 0c 2b 06 01 04 01 82 37 01 01 03 01 02:制造商标识,类型为object identifier。
值为1.3.6.1.4.1.311.1.1.3.1.2。
40 04 c0 a8 01 3b:代理的IP地址,类型OCTECT STRING,值为192.168.1.59;02 01 04:一般陷阱,类型为INTEGER,值为4,代表这是由“authentication Failure(身份验证失败)”引发的TRAP;02 01 00:特殊陷阱,类型为INTEGER,值为0(当一般陷阱取值不是6时);43 03 06 63 29:时间戳,类型为TIME TICKS,值为418601 (百分之一秒),即系统在运行到大约第70分钟时,代理发出了此TRAP;30 00变量绑定表为空。
5.SNMPv2 GetBulk操作:Sniffer软件截获到的getbulkrequest报文如下图所示:对该报文的分析如下 :30 27 SNMP 报文是ASN.1的SEQUENCE 类型,报文长度为46个八位组;02 01 01 版本号为INTEGER类型,取值为1,表示SNMPv2;04 06 70 75 62 6c 69 63 团体名为OCTET STRING类型,值为“public”。
a5 1a 表示PDU类型为GetBulkRequest,PDU长度为26个八位组;02 03 00 c2 2d 请求标识,INTEGER类型,值为49709;02 01 00 非重复数,INTEGER类型,值为0;02 01 0a 最大后继数,INTEGER类型,值为10;非重复数为0,最大后继数为10,表示要求返回所有请求对象按照字典顺序的后继承法10个对象实例。
实验一:网络数据包分析实验班级:班学号:姓名:一、实验目的通过对实际的网络数据包进行捕捉,分析数据包的结构,加深对网络协议分层概念的理解,并实际的了解数据链路层,网络层,传输层以及应用层的相关协议和服务。
、实验内容1. IGMP包解析1.1数据链路层El代XEL洱丁;亡日:亡5 MB)」osr: IP- 4m<as z_<i J;QJ L15 (21 -E-D.5eJO.E-D■>4 t-is :hi-At I _n * tP f Ld L^iJ 1 Sei 00:00:1^^saur-ctt El1imro_&ai«SiUType;IP CgMOsw)源数据:数据链路层头部:01 00 5e 00 00 16 00 21 97 0a e5 16 08 00 数据链路层尾部:00 00 00 00 00 00分析如下:数据头部的前6个字节是接收者的mac地址:01 00 5e 00 00 16 数据头部的中间6个字节是发送者的mac地址:00 21 97 0a e5 16 数据头部的最后2个字节代表网络协议,即:08 00协议类型。
1.2网络层Header* 1 cngth: 24 byresn axed services "乜Id:0x00 (.DSCP 0X00: D&fau11: 0x003Tqtil rength:斗DTdsrrtificar I cn: QklclJ 也^7460)H Flmqs: Q>00Fra^Tienr offset;:QTime VQ live; 1Fr DTCCDl : IGMP go?)¥ HPAder fhecksijn:CxJ85c [correct]5DU RUM;172,10.103.?0 <L72<10.163・2O)Castinari ant 224.0.0.22 (224.3.0.22^±j opt 1 oris: (4 Lyn源数据:46 00 00 28 1d 38 00 00 01 02 d8 5c ac 10 a3 14 e0 00 00 16 94 04 00 00数据分析:第一个字节(46)的前4位表示的是IP协议的版本,即IPv4;它的后4位表示首部长度为6,最大十进制数值时为15第二个字节(00)是区分服务,一直缺省,所以为0第三、四字节(00 28)是指首部和数据之和的长度40个字节第五、六字节(1d 38)是一个数据报被分片后的标识,便于正确地重装原来的数据报第七、八字节(00 00)分前3位为标志位和后13位为片偏移,其中标识位只有两位有意义,表明这已经是若干用户数据报片最后一个(MF=0,并且DF=0)不需要再分片了。
第1篇一、实验背景随着互联网的快速发展,网络通信数据量呈爆炸式增长,报文抓取技术在网络安全、网络监控、数据分析和数据挖掘等领域具有广泛的应用。
报文抓取技术可以从网络中捕获和解析数据包,提取出有用的信息。
本实验旨在通过报文抓取技术,实现网络数据包的捕获、解析和展示。
二、实验目的1. 熟悉报文抓取的基本原理和流程。
2. 掌握使用Wireshark等工具进行报文抓取的方法。
3. 能够对抓取到的报文进行解析和分析。
4. 提高网络监控、数据分析和数据挖掘等方面的能力。
三、实验环境1. 操作系统:Windows 102. 抓包工具:Wireshark3. 网络设备:路由器、交换机、计算机4. 网络连接:有线网络或无线网络四、实验步骤1. 安装Wireshark(1)从Wireshark官方网站下载最新版本的Wireshark安装包。
(2)按照安装向导完成Wireshark的安装。
2. 配置网络环境(1)将计算机连接到网络设备,确保网络连接正常。
(2)在Wireshark中,选择合适的网络接口进行抓包。
3. 抓取报文(1)在Wireshark界面中,点击“Capture”菜单,选择“Options”。
(2)在“Capture Filters”选项卡中,设置合适的过滤条件,如协议类型、端口号等。
(3)点击“Start”按钮开始抓包,观察网络数据包的传输情况。
4. 解析报文(1)在Wireshark界面中,找到需要分析的报文。
(2)展开报文结构,查看报文头部和负载部的信息。
(3)分析报文的协议类型、源地址、目的地址、端口号等关键信息。
5. 分析报文(1)根据实验需求,对抓取到的报文进行分析,如流量分析、协议分析、安全分析等。
(2)记录分析结果,为后续实验提供参考。
五、实验结果与分析1. 抓取到的报文包括HTTP、FTP、TCP、UDP等协议类型的数据包。
2. 通过分析HTTP协议的报文,发现大部分数据包为网页访问请求,目的地址为网页服务器。
实验一数据报文分析
物联10 查天翼41050051
一、实验目的
1.掌握网络分析原理
2.学习Wireshark协议分析软件的使用
3.加深对基本协议的理解
二、实验环境
机器代号:K053
IP地址:222.28.78.53
MAC地址:00-88-98-80-95-C2
三、实验结果
数据链路层(以太网)数据帧分析
3c e5 a6 b3 af c1 00 88 98 80 95 c2 08 00
3c e5 a6 b3 af c1:表示目的MAC(Hangzhou_b3:af:c1)地址
00 88 98 80 95 c2:表示本机MAC地址
08 00:表示数据类型,里面封装的是IP数据包
IP数据包分析
45 00 00 28 63 cd 40 00 80 06 19 1f de 1c 4e 35 77 4b da 46
45:高四位是4,表示此数据报是IPv4版本;低四位是5,表示首部长度,由于首部长度以4字节为单位,所以IP数据包的首部长度为20字节。
00:表示服务类型
00 28:表示数据包的总长度是40
63 cd:表示表示字段0x63cd(25549)
40 00:“40”高4位表示标志字段,低4位和第8个字节“00”组成片偏移字段。
80:表示生存时间
06:表示数据包的数据部分属于哪个协议,此值代表的协议是TCP协议。
19 1f:表示首部校验和
de 1c 4e 35:表示源IP地址222.28.78.53
77 4b da 46:表示目的IP地址119.75.218.70
07 a1 00 50 d7 c3 fb a4 5d 84 9a 2e 50 10 ff ff 5e e4 00 00
07 a1:表示源端口号1953
00 50:表示目的端口号80
d7 c3 fb a4:表示序号字段值430
5d 84 9a 2e:表示确认序号值3196
50:“50”的高4为位表示数据偏移字段值,该TCP报文数据偏移字段值是5,该字段表示报文首部的长度,以4字节为单位,所以该TCP报文的首部长度是20字节。
10:表示ACK=1,SYN=0
ff ff:表示窗口字段值是65535,即告诉发送端在没有收到确认之前所能发送最多的报文段的个数。
5e e4:表示校验和字段0x5ee4
00 00:表示紧急指针字段值
04 49:表示源端口是1097
1e 7b:表示目的端口是7803
00 18:表示报文长度是24
a2 2e:表示校验和字段0xa22e
思考题:
1.TCP的顺序号和确认号有什么规律?
TCP的序列号加上数据大小也就是下一个数据包中服务器发送给客户端的数据包中的确认号。
2.TCP数据中为什么没有总长度?
因为TCP数据中有一个标明是否是结尾报文的标志位,只有最后的那个报文会置为0。
所以可以通过收到的报文推算出TCP数据的总长度。
3.UDP校验和根据什么计算?
在发送数据时进行计算:首先把IP数据包的校验和字段置为0,然后把首部看成以16
位为单位的数字组成,依次进行二进制反码求和。
最后把得到的结果存入校验和字段中。
在接收数据时进行计算:先把首部看成以16位为单位的数字组成,依次进行二进制反码求和,包括校验和字段。
再检查计算出的校验和的结果是否等于零(反码应为16个1)。
如果等于零,说明被整除,校验是和正确。
否则,校验和就是错误的,协议栈要抛弃这个数据包。