谭营---机器学习研究及最新进展
- 格式:ppt
- 大小:682.50 KB
- 文档页数:90

生成式对抗网络:从生成数据到创造智能王坤峰;左旺孟;谭营;秦涛;李力;王飞跃【期刊名称】《自动化学报》【年(卷),期】2018(044)005【总页数】6页(P769-774)【作者】王坤峰;左旺孟;谭营;秦涛;李力;王飞跃【作者单位】中国科学院自动化研究所复杂系统管理与控制国家重点实验室北京100190;青岛智能产业技术研究院青岛266000;哈尔滨工业大学计算机科学与技术学院哈尔滨150001;北京大学信息科学技术学院北京100871;微软亚洲研究院北京100080;清华大学自动化系北京100084;中国科学院自动化研究所复杂系统管理与控制国家重点实验室北京100190;国防科技大学军事计算实验与平行系统技术研究中心长沙410073【正文语种】中文技术创新是社会经济发展的核心驱动力.继以物联网、云计算、大数据和移动互联网为代表的信息技术之后,以深度学习为代表的人工智能技术蓬勃发展,被公认是社会经济发展的新动能和新引擎,有望在农业生产、工业制造、经济金融、社会管理等众多领域产生颠覆性变革.生成式对抗网络(Generative adversarial networks,GAN)作为一种新的生成式模型,已成为深度学习与人工智能技术的新热点,在图像与视觉计算、语音语言处理、信息安全等领域中展现出巨大的应用和发展前景.1 GAN的原理与现状生成式对抗网络GAN是由Goodfellow等[1]在2014年提出的一种生成式模型.其核心思想来源于博弈论中的二人零和博弈.基本的GAN模型在结构上由一个生成器(Generator)和一个判别器(Discriminator)组成,如图1所示.从某个概率分布pz(例如高斯分布)中采样随机变量z,作为生成器G的输入,经过G的非线性映射,输出信号G(z).取决于G的结构和计算复杂性,从z到G(z)一般经过高度复杂的非线性变换,使得随机变量G(z)具备拟合高度复杂分布的能力.不失一般性,将G(z)称为生成数据(或伪数据),相应地将来自物理世界的数据x称为真实数据.判别器D以G(z)或x为输入,通过计算其属于真实数据的概率,判断输入数据是来自于真实数据还是生成数据.由于G和D一般采用高度非线性并且可微的深度神经网络结构,因而均可以采用端对端学习策略进行训练.具体而言,在训练G和D 时,采用对抗学习策略,使二者的训练目标相反.D的目标是最大化对数似然函数以判断G(z)和x的来源,将G(z)判断为生成数据,将x判断为真实数据.与之相对的是,G的目标是最小化对数似然函数,使G(z)的分布pg逼近真实数据x的分布pdata.不断迭代此对抗训练过程,交替更新判别器D和生成器G的参数,使D和G的性能不断提高;当达到平衡状态时,则认为G(z)学习到了真实数据x的分布空间,此时G(z)和x在分布上不具有差异性,判别器D无法对数据来源做出正确的判断.Goodfellow等[1]从理论上证明了当GAN模型收敛时,生成数据具有和真实数据相同的分布.但是在实践中,GAN的收敛性和生成数据的多样性通常难以保证[2].主要存在两个问题:生成器梯度消失和模式坍塌(Mode collapse).梯度消失是指由于生成器G和判别器D的训练不平衡,判别器D的性能很好,对生成数据G(z)和真实数据x能够做出完美的分类,那么D 对应的误差损失将很小,进而反向传播到G的梯度值很小,使得生成器G不能得到有效的训练.模式坍塌是指对于任意随机变量z,生成器G仅能拟合真实数据分布pdata的部分模式,虽然G(z)与真实数据x在判别器D难以区分,但是生成器G无法生成丰富多样的数据.为了解决GAN模型存在的问题,国内外学者提出了许多衍生模型[3].例如,Arjovsky 等[4]提出了Wasserstein GAN,用Earth-mover距离代替Jensen-Shannon散度,来度量生成数据分布与真实数据分布之间的差异,在很大程度上缓解了梯度消失和模式坍塌问题.图2显示了arXiv上GAN 论文数量 (以 Generative adversarial networks、Generative adversarial nets和Adversarial learning为关键词检索得到)的变化趋势,反映了GAN的研究热度变化.可以看出,Goodfellow等提出GAN后的两年内,相关论文的数量并不多,但是从2016年下半年开始,论文数量快速增长.图1 GAN的基本结构和计算流程Fig.1 Basic structure and computation procedure of GAN图2 arXiv上GAN论文数量的变化趋势Fig.2 Trend of the number of GAN papers published on arXiv另外,有许多衍生模型是从应用的角度提出的.例如,图像到图像转换具有广泛的应用,Zhu等[5]提出了CycleGAN,它包括两个生成器和两个判别器,在对抗损失的基础上增加了循环一致性损失,用于训练非配对的图像到图像转换模型.目前,GAN已经被广泛应用于计算机视觉、语音语言处理、信息安全等领域.图3显示了arXiv 上GAN论文所属的学科领域.可以看出,论文最多的学科领域是计算机视觉(cs.CV),说明GAN目前主要用于图像处理与计算机视觉;其次是机器学习(cs.LG和stat.ML)、计算与语言(cs.CL)、人工智能(cs.AI)、语音(cs.SD)、语音处理(eess.AS)、机器人(cs.RO)、密码与安全(cs.CR)、多媒体(cs.MM)等.2 GAN:从生成数据到创造智能GAN的初始目的是基于大量的无标记数据无监督地学习生成器G,具备生成各种形态(图像、语音、语言等)数据的能力.随着研究的深入与发展,以生成图像为例,GAN能够生成百万级分辨率的高清图像[6].实际上,GAN生成数据并不是无标记真实数据的单纯复现,而是具备一定的数据内插和外插作用,可以作为一种数据增广方式,结合其他数据更好地训练各种学习模型.进而,通过在生成器的输入同时包括随机变量z和隐码c并最大化生成图像与隐码c的互信息,InfoGAN能够揭示复杂数据中隐含的分布规律,实现数据的解释化表达[7].因而,GAN不仅可以用于探索复杂数据的潜在规律,还能够生成高质量的生成样本以作为真实数据的有效补充,为学习智能模型提供了新的视角和数据基础.图3 arXiv上GAN论文所属的TOP 10学科领域Fig.3 Top 10 subject categories of the GAN papers published on arXiv对于条件GAN模型,生成网络的输入往往被定义为样本的类别甚至其他形式(模态)的数据.到目前为止,已经研究了根据文本描述生成图像[8],进行交互式图像编辑[9],从低分辨率图像生成高分辨率图像[10],预测视频的未来帧[11],将仿真图像转换为真实风格的图像[12],实现通用的图像到图像转换[5],对真实图像的光照和天气条件进行变换[13],从二维图像生成物体的三维模型等[14].数据形式(模态)的转换可以进一步带来不同模态之间数据的可复用、模型和知识的迁移,创造更高水平的智能.例如,SimGAN能够将仿真图像转换为更具真实感的图像,同时保持仿真图像的标注信息不变,利用转换后的图像数据来训练视线估计和手势估计模型,使模型精度得到大幅提升[12].更进一步,由于GAN引入了对抗学习机制,在训练生成器产生更高质量数据的过程中,本身就会创造新的智能.例如,将语义分割卷积神经网络作为GAN的生成器,用判别器来判断分割图是来自分割网络还是来自真实标注,可以引入更高阶的一致性约束,提高语义分割的精度[15];在本专刊中,郑文博等撰写的“基于贝叶斯生成对抗网络的背景消减算法”利用GAN的对抗学习机制来训练背景消减神经网络,将一批输入图像直接转换成一批前景/背景分割结果,在公共测试集上取得了良好的性能;Mal-GAN能够主动生成具有对抗性的病毒代码样本,攻击黑盒病毒检测模型,有利于提高反病毒软件的性能[16].总之,GAN在对抗样本、数据增广、迁移学习和创造智能等方面都展现出巨大的潜力,已成为当前的深度学习与人工智能研究中关注的热点.3 GAN与平行智能GAN作为一种有效的生成数据和创造智能的模型,与平行智能密切相关[17].平行智能强调虚实互动,其载体是基于ACP(Arti ficial systems,computational experiments,and parallel execution)的平行系统[18].利用人工系统来建模和表示实际系统,通过计算实验来分析和评估各种计算模型,借助平行执行来引导实际系统向着理想的目标状态逼近.平行智能包括平行视觉、平行学习等分支.平行视觉[19−20]是ACP理论在视觉计算领域的推广.平行视觉利用人工场景来模拟和表示复杂挑战的实际场景,使采集和标注大规模多样性的图像数据集成为可能,通过计算实验进行视觉算法的设计与评估,最后借助平行执行来在线优化视觉系统,实现对复杂环境的感知与理解.利用GAN的半监督/无监督学习能力,能够生成大规模、多样性的图像数据[12−13],有利于对视觉模型进行充分的训练与评估,提高视觉模型在复杂场景下的运行可靠性.平行学习[21]是一个新型的机器学习理论框架.首先从原始数据中选取特定的“小数据”,输入到软件定义的人工系统中,并由人工系统产生大量新的数据;然后这些人工数据和特定的原始小数据一起构成解决复杂问题所需要学习的“大数据”集合,通过计算实验和平行执行来设计优化机器学习模型,得到应用于某些具体场景或任务的“精准知识”.GAN能够生成大量新的数据,作为训练数据的一部分,提高机器学习模型的性能.简言之,可以把GAN看作真与假的平行,把平行智能看作虚与实的平行.GAN必将促进平行智能理论的发展!4 专刊论文概览为促进我国生成式对抗网络(GAN)相关理论、方法、技术与应用研究的开展,及时反映我国学者在相关领域的最新研究进展,我们特组织本专刊,针对GAN的基础理论与方法、结构优化和训练稳定性、对抗机制以及在各领域的应用等重要问题,面向国内研究者征文.本专刊共收到38篇稿件.经过同行评议,我们录用了其中的13篇稿件,研究内容涉及GAN的新结构、因果关系抽取、多视图学习与重构、低秩图像生成等基础研究;GAN在图像识别、人脸表情识别、背景消减等计算机视觉领域的应用基础研究;以及在语言模型数据增强、自能源混合建模与参数辨识、原油总氢物性预测等其他领域的应用基础研究.首先,林懿伦等撰写的综述文章“人工智能研究的新前线:生成式对抗网络”概括了GAN的基本思想,对近年来相关的理论与应用研究进行了梳理,总结了常见的GAN 网络结构与训练方法、博弈形式和集成方法,并对一些应用场景进行了介绍.在此基础上,对GAN发展的内在逻辑进行了归纳总结.针对GAN的生成模型学习效率低、判别模型易出现梯度消失等问题,王功明等撰写的“一种能量函数意义下的生成式对抗网络”提出一种能量函数意义下基于重构误差的生成式对抗网络(Energy reconstruction error GAN,E-REGAN).将自适应深度信念网络作为生成模型,来加快学习速度;将自适应深度自编码器作为判别模型,用重构误差作为能量函数来表征判别模型的性能,能量越小表示GAN学习过程越趋近于纳什均衡的平衡点.在MNIST和CIFAR-10数据集上的实验结果表明,与同类模型相比,E-REGAN在学习速度和数据生成能力两方面都有较大提高.GAN的学习目标是完整拟合真实样本的分布,然而在实践中,真实样本分布的复杂程度难以预计,容易发生模式坍塌.为了提高无监督条件下的GAN生成能力,减少模式坍塌,张龙等撰写的“协作式生成对抗网络”强调不同模式之间既有差异又有联系,提出一种新的协作式生成网络结构.通过构建多个生成模型,在它们之间引入协作机制,使得生成模型在训练过程中能够相互学习,提高模型对真实数据的拟合能力.实验表明,该模型在二维图像生成方面有显著的效果,协作机制可以加快模型收敛速度,提高训练效率,还能消除损失函数噪声,在三维模型生成方面也产生了一定的效果.通过调整模型参数,能够有效抑制模式坍塌.因果关系是一种重要的关系类型,在事件预测、情景生成、问答、文本蕴涵等许多任务中具有重要的应用价值.现有的因果关系抽取方法大多需要繁琐的特征选择,并且严重依赖知识库.为此,冯冲等撰写的“融合对抗学习的因果关系抽取”利用GAN 的对抗学习特性,将带注意力机制的双向门控循环单元神经网络与对抗学习相融合,在因果关系增强模型中引入因果关系解释语句.通过重新定义生成模型和判别模型,基本的因果关系抽取网络能够与判别网络形成对抗,进而从因果关系解释信息中获得高区分度的特征.实验结果验证了该方法的有效性和优越性.综合多个甚至所有的角度往往有助于对事物的全面和深入理解,然而在实际应用中,完整视图数据会导致巨大的获取成本.为了从已有视图构建事物的完整视图,孙亮等撰写的“基于生成对抗网络的多视图学习与重构算法”提出一种基于GAN的多视图学习与重构算法,利用已知单一视图,通过生成模型构建其他视图.提出新型表征学习算法,将同一实例的任意视图都能映射到相同的表征向量,并保证其包含实例的完整重构信息.为构建给定事物的多种视图,提出基于GAN的重构算法,在生成模型中加入表征信息,保证了生成视图数据与源视图相匹配.实验表明该算法取得了很好的视图重构性能.低秩纹理模型是图像处理领域中的一个重要纹理模型,借助于纹理的低秩性可以对受到各种变换干扰的图像进行校正.针对低秩图像校正问题,赵树阳等撰写的“基于生成对抗网络的低秩图像生成方法”提出了一种由原始图像直接生成低秩图像的生成式对抗网络(Low-rank generative adversarial network,LR-GAN).该方法将传统的无监督学习的低秩纹理映射算法(Transform invariant low-rank textures,TILT)作为引导加入到网络中来辅助判别器,使网络整体达到无监督学习的效果,并且使低秩对抗对在生成器和判别器上都能够学习到低秩表示.为了保证生成的图像既有较高的质量又有相对较低的秩,同时考虑到低秩约束条件下优化问题的不易解决,在经过一定阶段的TILT引导后,设计并加入了低秩梯度滤波层来逼近网络的低秩最优解.实验表明,LR-GAN取得了很好的低秩图像生成效果.在漫画绘制的过程中,按草稿绘制出线条干净的线稿是一个很重要的环节.现有的草图简化方法具有一定的线条简化能力,但是由于草图绘制方式的多样性以及画面复杂凌乱程度的不同,这些方法的适用范围和效果有限.为此,卢倩雯等撰写的“基于生成对抗网络的漫画草稿图简化”提出一种基于GAN的草图简化方法,将条件随机场和最小二乘生成对抗网络相结合,搭建草图简化的深度卷积神经网络模型,通过生成器和判别器之间的零和博弈与条件约束,得到更加接近于真实线稿的简化图.深度卷积生成对抗网络在传统GAN的基础上引入卷积神经网络作为模型骨架结构,条件生成对抗网络在GAN的基础上扩展为条件模型.唐贤伦等撰写的“基于条件深度卷积生成对抗网络的图像识别方法”结合深度卷积生成对抗网络和条件生成对抗网络的优点,建立了条件深度卷积生成对抗网络模型.利用卷积神经网络强大的特征提取和表达能力,加以条件辅助生成样本,将此结构优化改进后,应用于MNIST、CIFAR-10等图像识别任务中,有效提高了识别准确率.让机器能够识别人的表情,是人机交互的关键.在自然交流中,人的情绪表达往往伴随着丰富的头部姿态和肢体动作,使得提取有效的表情特征非常困难.现有的表情识别方法大多基于通用的人脸特征表示和识别算法,很少考虑表情识别和身份识别的差异,使得算法不够鲁棒.为此,姚乃明等撰写的“基于生成式对抗网络的鲁棒人脸表情识别”提出一种对人脸局部遮挡图像进行用户无关表情识别的方法.该方法包括一个基于Wasserstein GAN的人脸图像生成网络,能够为图像中的遮挡区域生成上下文一致的补全图像;还包括一个表情识别网络,在表情识别和身份识别任务之间建立对抗关系,提取用户无关的表情特征并推断表情类型.该方法在公共数据集上取得了较高的表情识别准确率.背景消减是计算机视觉领域的一个重要研究方向.实际环境中存在的光照变化、阴影、背景运动等因素对背景消减提出了严重挑战.为此,郑文博等撰写的“基于贝叶斯生成对抗网络的背景消减算法”提出一种基于GAN的背景消减算法.首先利用中值滤波算法进行背景数据的获取,然后基于贝叶斯GAN建立背景消减模型,采用深度卷积神经网络构建贝叶斯GAN的生成器和判别器,利用GAN的对抗学习机制来进行模型训练.训练后的生成器能够将每个像素分类为前景或背景,有效解决了光照变化、非静止背景、鬼影(Ghost)等问题.基于最大似然估计(Maximum likelihood estimation,MLE)的语言模型数据增强方法存在暴露偏差问题,无法生成具有长时语义信息的采样数据.为此,张一珂等撰写的“基于对抗训练策略的语言模型数据增强技术”提出一种基于对抗训练策略的语言模型数据增强方法,通过一个卷积神经网络判别模型判断生成数据的真伪,引导递归神经网络生成模型学习真实数据的分布.语言模型的数据增强问题实质上是离散序列的生成问题.为了将判别模型的误差通过反向传播算法回传到生成模型,该方法将离散序列生成问题表示为强化学习问题,利用判别模型的输出作为奖励对生成模型进行优化,采用蒙特卡洛搜索算法对生成序列的中间状态进行评价.实验表明,在有限文本数据条件下,随着训练数据量的增加,该方法可以降低识别字错误率,优于基于MLE的数据增强方法.自能源是能源互联网的子单元,旨在实现能量间的双向传输及灵活转换.由于自能源在不同工况下的运行特性存在很大差异,现有方法不能对其进行精确的参数辨识.为此,孙秋野等撰写的“基于GAN技术的自能源混合建模与参数辨识方法”提出了一种基于GAN的数据和机理混合驱动方法,对自能源模型进行参数辨识.将GAN 模型中训练数据与专家经验结合,进行模糊分类,解决了自能源在不同工况下的模型切换问题.通过应用含策略梯度反馈的GAN技术对模型进行训练,解决了自能源中输出序列离散的问题.仿真实验结果表明,提出的模型具有较高的辨识精度和更好的推广性,能够有效地拟合系统在不同工况下的状态变化.针对原油物性的回归预测问题,郑念祖等撰写的“基于Regression GAN的原油总氢物性预测方法”提出一种回归生成对抗网络(Regression GAN,RGAN)结构,该结构在传统GAN的生成模型和判别模型的基础上增加了一个回归模型.通过判别模型与生成模型之间的对抗学习,使得判别模型提取了原油物性核磁共振氢谱谱图的一系列潜在特征.回归模型和判别模型共享首层潜在特征,即样本空间的浅层表达,有利于提高回归模型的预测精度及稳定性.通过在生成模型增加互信息约束,并采用回归模型的均方误差损失函数来估计互信息下界,使得生成模型产生更加接近于真实的样本.实验结果表明,RGAN有效提高了原油总氢物性的预测精度及稳定性.本专刊的顺利完成,离不开作者、审稿专家和《自动化学报》编辑们的大力支持与协助.我们在此表示诚挚的感谢,并希望本专刊对我国生成式对抗网络与人工智能领域的研究起到积极的促进作用.References1 Goodfellow I J,Pouget-Abadie J,Mirza M,Xu B,Warde-Farley D,Ozair S,et al.Generative adversarial nets.In:Proceedings of the 27th International Conference on Neural Information ProcessingSystems.Montreal,Canada:Curran Associates,Inc.,2014.2672−26802 Creswell A,White T,Dumoulin V,Arulkumaran K,Sengupta B,Bharath AA.Generative adversarial networks:an overview.IEEE Signal Processing Magazine,2018,35(1):53−653 Wang Kun-Feng,Gou Chao,Duan Yan-Jie,Lin Yi-Lun,Zheng Xin-Hu,Wang Fei-Yue.Generative adversarial networks:the state of the art and beyond.Acta Automatica Sinica,2017,43(3):321−332(王坤峰,苟超,段艳杰,林懿伦,郑心湖,王飞跃.生成式对抗网络GAN的研究进展与展望.自动化学报,2017,43(3):321−332)4 Arjovsky M,Chintala S,Bottou L.Wasserstein GAN.arXiv preprintarXiv:1701.07875,2017.5 Zhu J Y,Park T,Isola P,Efros A A.Unpaired imageto-image translation using cycle-consistent adversarial networks.In:Proceedings of the 2017 IEEE International Conference on ComputerVision(ICCV).Venice,Italy:IEEE,2017.2242−22516 Karras T,Aila T,Laine S,Lehtinen J.Progressive growing of GANs for improved quality,stability,and variation.arXiv preprintarXiv:1710.10196,2017.7 Chen X,Duan Y,Houthooft R,Schulman J,Sutskever I,AbbeelGAN:interpretable representation learning by information maximizing generative adversarial nets.In:Proceedings of the 30th Conference on Neural Information ProcessingSystems.Barcelona,Spain:Curran Associates,Inc.,2016.8 Zhang H,Xu T,Li H S,Zhang S T,Huang X L,Wang X G,et al.StackGAN:text to photo-realistic image synthesis with stacked generative adversarial networks.arXiv preprint arXiv:1612.03242,2016.9 Zhu J Y,Krähenbühl P,Shechtman E,Efros A A.Generative visual manipulation on the natural image manifold.arXiv preprintarXiv:1609.03552,2016.10 Ledig C,Theis L,Huszar F,Caballero J,Cunningham A,Acosta A,etal.Photo-realistic single image superresolution using a generative adversarial network.arXiv preprint arXiv:1609.04802,2016.11 Santana E,Hotz G.Learning a driving simulator.arXiv preprintarXiv:1608.01230,2016.12 Shrivastava A,P flster T,Tuzel O,Susskind J,Wang W D,Webb R.Learning from simulated and unsupervised images through adversarial training.In:Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Honolulu,HI,USA:IEEE,2017.2242−225113 Liu M Y,Breuel T,Kautz J.Unsupervised image-to-image translation networks.In:Advances in Neural Information Processing Systems30.Barcelona,Spain:Curran Associates,Inc.,2017.14 Wu J J,Zhang C K,Xue T F,Freeman B,Tenenbaum J.Learning a probabilistic latent space of object shapes via 3D generative-adversarial modeling.In:Advances in Neural Information Processing Systems29.Barcelona,Spain:Curran Associates,Inc.,2016.15 Luc P,Couprie C,Chintala S,Verbeek J.Semantic segmentation using adversarial networks.arXiv preprint arXiv:1611.08408,2016.16 Hu W W,Tan Y.Generating adversarial malware examples for black-box attacks based on GAN.arXiv preprint arXiv:1702.05983,2017.17 Wang F Y,Wang X,Li L X,Li L.Steps toward parallel intelligence.IEEE/CAA Journal of Automatica Sinica,2016,3(4):345−34818 Wang Fei-Yue.Parallel system methods for management and control of complex sys tems.Control and Decision,2004,19(5):485−489,514(王飞跃.平行系统方法与复杂系统的管理和控制.控制与决策,2004,19(5):485−489,514)19 Wang Kun-Feng,Gou Chao,Wang Fei-Yue.Parallel vision:an ACP-based approach to intelligent vision computing.Acta AutomaticaSinica,2016,42(10):1490−1500(王坤峰,苟超,王飞跃.平行视觉:基于ACP的智能视觉计算方法.自动化学报,2016,42(10):1490−1500)20 Wang K F,Gou C,Zheng N N,Rehg J M,Wang F Y.Parallel vision for perception and understanding of complex scenes:methods,framework,and perspectives.Arti ficial Intelligence Review,2017,48(3):299−32921 Li Li,Lin Yi-Lun,Cao Dong-Pu,Zheng Nan-Ning,Wang Fei-Yue.Parallel learning—a new framework for machine learning.Acta Automatica Sinica,2017,43(1):1−8(李力,林懿伦,曹东璞,郑南宁,王飞跃.平行学习—机器学习的一个新型理论框架.自动化学报,2017,43(1):1−8)。


谭营教授目前,以互联网和移动通信为纽带,实现了人类群体、大数据、物联网的广泛和深度互联,这样的模式,让群体智能发挥了极大的科技优势,并由此改变了人工智能领域。
1.群体智能的“真相”著名科学家钱学森先生在20世纪90年代曾提出综合集成研讨厅体系,强调专家群体以人机结合的方式进行协同研讨,共同对复杂巨系统的挑战性问题进行研究。
而现在,群体智能作为人工智能最重要的研究领域之一,正吸引着大量国际知名学者进行深入和广泛研究。
尤其是在国务院颁布的《新一代人工智能发展规划》中,群体智能作为我国四个战略性重要研究方向之一,具有极其重要的意义。
群体智能源于对以蚂蚁、鸟群等为代表的社会性昆虫群体行为的研究。
最早被用在细胞机器人系统的描述中。
群体智能的特点在于分布式并行控制,不存在控制扰源的影响。
对此,团队提出了一种群体协作策略,相对于机器人独立搜索而言,能够降低假目标的访问次数,较好地完成了任务需求。
群体机器人自适应部署可作为群体机器人多目标搜索问题的一个子任务,通过自适应调节势场函数的参数,于是,团队提出了一种自适应部署机制,能够较快地让整个机器人群体部署到未知搜索空间。
此外,他们还就基于机器学习的多智能体学习任务展开了相关研究,提出了基于进化算法的群体机器人策略演化与基于深度强化学习的多智能体协同算法。
学习机制可方便地用于群体机器人算法的建模与学习,并应用到了一些基于多智能体协同的游戏中来。
提到群体智能,就不能不提近些年备受关注的烟花算法,作为一种新的群体智能优化算法,它与粒子群优化、蚁群优化和遗传算法等SI算法相比,具有不同的协作框架和搜索方式。
在烟花算法中,多个烟花在自身周围分布新个体(称为火花),来进行局部邻域的搜索;各烟花根据自身的搜索状态,相互交换信息,调整自身爆炸范围和火花分配,从而实现整体搜索的协调。
相比其它群体智能算法与进化算法框架,烟花算法在基准目标函数和现实问题上都有着更好的表现。
随着研究的深入,谭营和其研究团队又提出了许多效果更好的烟花算法变体,并且达到了群体智能算法的先进水平。

《人工智能极简说:人人都能读懂的AI入门书》读书记录目录一、书籍概览 (2)1.1 作者介绍及写作目的 (2)1.2 书籍内容概述 (3)1.3 读者群体定位 (4)二、人工智能基础概念篇 (5)2.1 内容描述 (6)2.2 人工智能定义与起源 (7)2.3 人工智能发展阶段 (8)2.4 人工智能技术应用领域 (9)三、关键技术解析篇 (11)3.1 机器学习原理及应用 (12)3.2 深度学习及其技术特点 (13)3.3 自然语言处理技术 (14)3.4 计算机视觉技术 (16)四、人工智能在各领域的应用实践篇 (17)4.1 金融行业应用案例分析 (18)4.2 医疗健康行业应用案例分析 (19)4.3 教育行业应用案例分析 (20)4.4 其他领域应用展望 (22)五、人工智能的伦理与社会影响篇 (23)5.1 人工智能带来的伦理问题与挑战 (24)5.2 人工智能对社会就业的影响分析 (25)5.3 人工智能对人类生活方式的改变 (26)六、未来发展趋势与展望篇 (28)6.1 人工智能未来技术创新方向预测 (29)6.2 人工智能与其他产业融合发展趋势分析 (30)一、书籍概览《人工智能极简说:人人都能读懂的AI入门书》是一本全面介绍人工智能基础知识的科普读物,旨在帮助读者快速了解并掌握人工智能的基本概念、原理和应用。
本书通过通俗易懂的语言和生动的案例,让读者在轻松愉快的阅读中领略人工智能的魅力。
本书的作者是一位资深的人工智能专家,拥有丰富的研究和实践经验。
他她通过深入浅出的讲解,将复杂的理论知识转化为易于理解的概念,使读者能够轻松掌握人工智能的核心要点。
人工智能概述:介绍人工智能的定义、发展历程、应用领域以及未来趋势;人工智能实践:通过实际案例展示人工智能技术的实际应用,培养读者的实践能力。
为了更好地理解和掌握本书的内容,建议读者先了解人工智能基础知识,然后按照章节顺序逐步阅读。


参考文献(人工智能)曹晖目的:对参考文献整理(包括摘要、读书笔记等),方便以后的使用。
分类:粗分为论文(paper)、教程(tutorial)和文摘(digest)。
0介绍 (1)1系统与综述 (1)2神经网络 (2)3机器学习 (2)3.1联合训练的有效性和可用性分析 (2)3.2文本学习工作的引导 (2)3.3★采用机器学习技术来构造受限领域搜索引擎 (3)3.4联合训练来合并标识数据与未标识数据 (5)3.5在超文本学习中应用统计和关系方法 (5)3.6在关系领域发现测试集合规律性 (6)3.7网页挖掘的一阶学习 (6)3.8从多语种文本数据库中学习单语种语言模型 (6)3.9从因特网中学习以构造知识库 (7)3.10未标识数据在有指导学习中的角色 (8)3.11使用增强学习来有效爬行网页 (8)3.12★文本学习和相关智能A GENTS:综述 (9)3.13★新事件检测和跟踪的学习方法 (15)3.14★信息检索中的机器学习——神经网络,符号学习和遗传算法 (15)3.15用NLP来对用户特征进行机器学习 (15)4模式识别 (16)4.1JA VA中的模式处理 (16)0介绍1系统与综述2神经网络3机器学习3.1 联合训练的有效性和可用性分析标题:Analyzing the Effectiveness and Applicability of Co-training链接:Papers 论文集\AI 人工智能\Machine Learning 机器学习\Analyzing the Effectiveness and Applicability of Co-training.ps作者:Kamal Nigam, Rayid Ghani备注:Kamal Nigam (School of Computer Science, Carnegie Mellon University, Pittsburgh, PA 15213, knigam@)Rayid Ghani (School of Computer Science, Carnegie Mellon University, Pittsburgh, PA 15213 rayid@)摘要:Recently there has been significant interest in supervised learning algorithms that combine labeled and unlabeled data for text learning tasks. The co-training setting [1] applies todatasets that have a natural separation of their features into two disjoint sets. We demonstrate that when learning from labeled and unlabeled data, algorithms explicitly leveraging a natural independent split of the features outperform algorithms that do not. When a natural split does not exist, co-training algorithms that manufacture a feature split may out-perform algorithms not using a split. These results help explain why co-training algorithms are both discriminativein nature and robust to the assumptions of their embedded classifiers.3.2 文本学习工作的引导标题:Bootstrapping for Text Learning Tasks链接:Papers 论文集\AI 人工智能\Machine Learning 机器学习\Bootstrap for Text Learning Tasks.ps作者:Rosie Jones, Andrew McCallum, Kamal Nigam, Ellen Riloff备注:Rosie Jones (rosie@, 1 School of Computer Science, Carnegie Mellon University, Pittsburgh, PA 15213)Andrew McCallum (mccallum@, 2 Just Research, 4616 Henry Street, Pittsburgh, PA 15213)Kamal Nigam (knigam@)Ellen Riloff (riloff@, Department of Computer Science, University of Utah, Salt Lake City, UT 84112)摘要:When applying text learning algorithms to complex tasks, it is tedious and expensive to hand-label the large amounts of training data necessary for good performance. This paper presents bootstrapping as an alternative approach to learning from large sets of labeled data. Instead of a large quantity of labeled data, this paper advocates using a small amount of seed information and alarge collection of easily-obtained unlabeled data. Bootstrapping initializes a learner with the seed information; it then iterates, applying the learner to calculate labels for the unlabeled data, and incorporating some of these labels into the training input for the learner. Two case studies of this approach are presented. Bootstrapping for information extraction provides 76% precision for a 250-word dictionary for extracting locations from web pages, when starting with just a few seed locations. Bootstrapping a text classifier from a few keywords per class and a class hierarchy provides accuracy of 66%, a level close to human agreement, when placing computer science research papers into a topic hierarchy. The success of these two examples argues for the strength of the general bootstrapping approach for text learning tasks.3.3 ★采用机器学习技术来构造受限领域搜索引擎标题:Building Domain-specific Search Engines with Machine Learning Techniques链接:Papers 论文集\AI 人工智能\Machine Learning 机器学习\Building Domain-Specific Search Engines with Machine Learning Techniques.ps作者:Andrew McCallum, Kamal Nigam, Jason Rennie, Kristie Seymore备注:Andrew McCallum (mccallum@ , Just Research, 4616 Henry Street Pittsburgh, PA 15213)Kamal Nigam (knigam@ , School of Computer Science, Carnegie Mellon University Pittsburgh, PA 15213)Jason Rennie (jr6b@)Kristie Seymore (kseymore@)摘要:Domain-specific search engines are growing in popularity because they offer increased accuracy and extra functionality not possible with the general, Web-wide search engines. For example, allows complex queries by age-group, size, location and cost over summer camps. Unfortunately these domain-specific search engines are difficult and time-consuming to maintain. This paper proposes the use of machine learning techniques to greatly automate the creation and maintenance of domain-specific search engines. We describe new research in reinforcement learning, information extraction and text classification that enables efficient spidering, identifying informative text segments, and populating topic hierarchies. Using these techniques, we have built a demonstration system: a search engine forcomputer science research papers. It already contains over 50,000 papers and is publicly available at ....采用多项Naive Bayes 文本分类模型。

融合论坛INTEGRATION FORUM26软件和集成电路SOFTWARE AND INTEGRATED CIRCUITAI和大数据赋能金融由于深度学习推进,人工智能技术已经进展到一个热火朝天的状态,人工智能技术的发展在各个产业里面都引起了很大的变革,当然金融行业也在内。
我接下来主要讲的就是人工智能在金融方面的一些应用。
人工智能带来产业的全面升级,不仅可以提高我们生产的工作效率,而且可以在金融行业领域大大提高智能分析和决策水平。
金融行业每天都面临着大量的各种金融数据、政策消息,如何能够全面掌握金融行业的发展趋势?我们知道任何一个人在获取知识和对知识分析的过程中,个人的能力是有边界的,是有限的。
但是现今数据、消息铺天盖地呈指数级增长,人工智能借助于强大的计算背景和学习能力,辅助人类开展各项智能活动,金融行业引入人工智能是必然的趋势。
到目前为止,人工智能在金融行业的很多领域都得到了广泛的应用,如智能支付、人脸支付、指纹支付、生物特征支付、智能客服等。
自然语言处理技术的飞速发展,可以使得公司客服服务24小时不间断,这背后是强大的人工智能技术的支撑。
再有就是关于智能理财方面,人民生活宽裕,有一定的资金,就希望通过一些渠道增值,发挥更大的效能。
借助于人工智能技术,我们增长了对投资信息的判断能力,增加投资的回报率,这是我们大家都很期待的事。
对于智能的信用评级系统,实际上现在很多的保险公司、银行已经在大量使用了。
A I本身是从简单到复杂的发展过程,从1956年定义—北京大学教授、计算智能实验室主任、烟花算法发明人谭营“AI赋能”是金融行业的大势所趋,我们以深度学习为核心技术,以大数据分析为支撑,结合AI算法创建智能投资模型,进行精准量化投资,降低投资风险。
主题演讲人工智能这个词,到现在已经有60多年的历史。
人工智能的发展是一个曲折的过程,经历过寒冬,也得到过大家的追捧。
现今人工智能处于一个爆发期,是第三次人工智能浪潮的爆发期。

视觉与听觉信息处理国家重点实验室视觉与听觉信息处理国家重点实验室、智能科学系(信息科学中心)主任:查红彬副主任:吴玺宏谢昆青刘宏视觉与听觉信息处理国家重点实验室学术委员会视觉研究室视觉信息处理研究室在充分发挥学科交叉的综合优势基础上,特别注意从视觉信息处理中提出新的数学问题,进一步发展用于信息处理的数学方法,主要研究方法包括图像压缩与编码、图像处理和模式识别、计算机视觉等。
多年来我们承担了国家科技攻关、863高科技、攀登计划、自然科学基金、博士点基金等大量课题,同时取得了一批有独创性的重大成果。
本研究室具体包含如下4个研究领域:1、图像处理、图像理解和计算机视觉2、生物特征识别3、图像的压缩、复现、传输及其信息安全4、三维视觉计算与机器人(New!!!)联系人:张超电话: 62757000视觉信息处理研究室科研方向:[1]图像处理、图像理解和计算机视觉[2]生物特征识别[3]图像的压缩、复现、传输及其信息安全[4]三维视觉计算与机器人视觉信息处理研究室科研项目:用于患者行为实时跟踪的护理机器人主动视觉研究,国家自然科学基金项目,2002-2004建筑物与复杂场景三维数字化技术的基础研究,教育部科学技术研究重点项目,2003-2005数字博物馆关键技术研究,北京大学15-211项目,2003-2005Document Image Retrieval,与日本Ricoh Co.的合作项目,2003-20043D Model Retrieval,与日本Fujitsu研发中心的合作项目,2003-2004数字几何处理的理论框架与关键技术研究,国家自然科学基金重点项目,2004-2007计算机视觉研究,自然科学基金重大项目子项小波分析理论及其在图像处理中的应用,自然科学基金跨学部重点项目数学机械化与自动推理平台"课题"信息安全、传输与可靠性研究,国家重点基础研究发展规划项目微阵列基因表达数据分析和可视化研究,自然科学基金项目全国优秀博士学位论文奖励基金, 2001-2005JPEG2000图象压缩集成电路核心技术研究,国家863高科技研究项目基于小波的视频压缩与通讯系统研究,国家973重大基础项目的子专题符合JPEG2000的图象压缩集成电路研究,教育部骨干教师项目多进制小波理论及其在基于内容的图像压缩中的应用,国家自然科学基金项目, 2004.1-2006.12 视觉研究室主要人员:听觉研究室言语听觉信息处理研究室成立于1988年,多年来一直以人工神经网络、智能机器学习等为理论基石,以听觉信息处理、语音信号处理和语言信息处理为研究背景进行了深入的理论探索和实践研究。
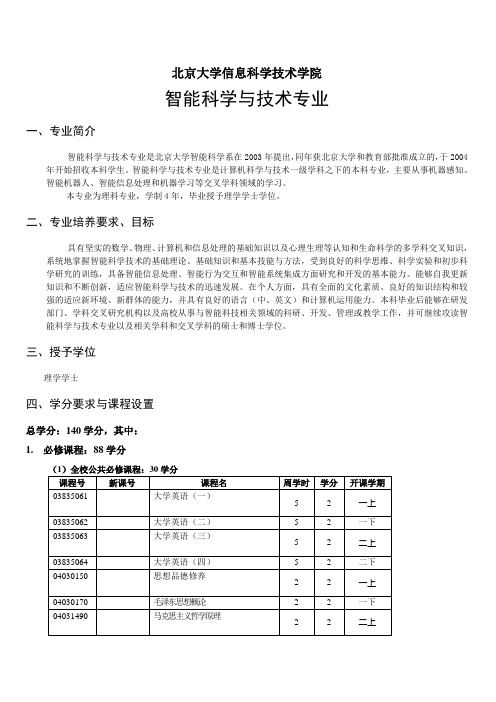
北京大学信息科学技术学院智能科学与技术专业一、专业简介智能科学与技术专业是北京大学智能科学系在2003年提出,同年获北京大学和教育部批准成立的,于2004年开始招收本科学生。
智能科学与技术专业是计算机科学与技术一级学科之下的本科专业,主要从事机器感知、智能机器人、智能信息处理和机器学习等交叉学科领域的学习。
本专业为理科专业,学制4年,毕业授予理学学士学位。
二、专业培养要求、目标具有坚实的数学、物理、计算机和信息处理的基础知识以及心理生理等认知和生命科学的多学科交叉知识,系统地掌握智能科学技术的基础理论、基础知识和基本技能与方法,受到良好的科学思维、科学实验和初步科学研究的训练,具备智能信息处理、智能行为交互和智能系统集成方面研究和开发的基本能力。
能够自我更新知识和不断创新,适应智能科学与技术的迅速发展。
在个人方面,具有全面的文化素质、良好的知识结构和较强的适应新环境、新群体的能力,并具有良好的语言(中、英文)和计算机运用能力。
本科毕业后能够在研发部门、学科交叉研究机构以及高校从事与智能科技相关领域的科研、开发、管理或教学工作,并可继续攻读智能科学与技术专业以及相关学科和交叉学科的硕士和博士学位。
三、授予学位理学学士四、学分要求与课程设置总学分:140学分,其中:1.必修课程:88学分(2)全院必修课程:25 学分2.(1)专业方向核心课程:18学分说明:要求在下列一组智能科学与技术专业方向核心课程中至少选择18学分课程。
并集(2)专业选修课:至少12学分也可从计算机科学技术、电子和微电子类中选择(详见“信息科学技术学院课程”附录)。
对本科生来说,除选修课一览表所列课程外,还可以选修学校其他专业相关课程。
但是,如果选择课程在本专业课程中有相似的课程,其课程难易程度必须高于本专业同类课程,方可选择。
3.毕业论文:6学分智能科学系教师基本情况北京大学智能科学与技术专业本科生课程年度安排(2005,4,27)1/21/22/2 高等数学4/5 3/33/3 高数注:(1)毕业总学分140学分(含毕业论文6学分),必修课8846学分(包括专业方向核心课18学分,素质教育通选课16学分,专业选修12学分)。


HU M, PENG Y, HUANG Z, et al. Open-domain tar-geted sentiment analysis via span-based extraction and classification[C] // Proceedings of the 57th Conference of the Association for Computational Linguistics.Florence,Italy, 2019 : 537 –546.[27]作者简介:肖宇晗,硕士研究生,主要研究方向为深度学习、数据挖掘和自然语言处理。
林慧苹,副教授,博士,主要研究方向为大数据分析、企业信息服务,主持和参与国家863计划、国家自然科学基金项目、国家重点研发计划项目等多项。
发表学术论文20余篇。
谭营,教授,博士生导师,主要研究方向为智能科学、计算智能与群体智能、机器学习、人工神经网络、群体机器人、大数据挖掘。
烟花算法发明人。
吴文俊人工智能科学技术成就奖创新三等奖获得者。
发表学术论文330 余篇,出版学术专著 12 部。
陈小平主编《人工智能伦理导引》出版人工智能是21世纪最引人注目的重大科技进展,被普遍认为是第四次工业革命的引导力量。
人工智能与大数据、网络、信息、自动化、物联网和云计算等新技术相结合,正渗透到工业、农业、服务业、交通运输、能源、金融、安全和国防等各个领域,成为这些产业部门转型升级的核心驱动力。
在这种新形势下,人工智能及大数据等相关技术将对各行各业、各种岗位的从业人员产生广泛、深刻、长期的影响。
由此出现一种普遍的现象:所有社会成员都需要更多、更深入地了解人工智能,全面、客观、准确地认识人工智能带给我们的正面效应和负面效应。
社会的上述巨大变化必然反映到教育实践中,引出本科生和研究生教育的一种全新的重大需求—人工智能及其应用的快速发展,要求对现有学校教育内容进行及时的扩展,将人工智能和人工智能伦理纳入各个学科的教育体系,开设相关的课程和培训,使学生得到必要的培养和训练。

机器学习在军事领域有哪些创新应用在当今的科技时代,机器学习作为一项前沿技术,正逐渐在军事领域展现出其巨大的潜力和创新应用。
它不仅改变了军事作战的方式,还为军事战略、战术以及军事装备的发展带来了全新的思路和突破。
首先,机器学习在情报分析方面发挥着关键作用。
现代战争中,情报的准确性和及时性至关重要。
通过机器学习算法,可以对大量的情报数据进行快速处理和分析。
例如,从卫星图像、雷达监测、通信截获等多种渠道获取的海量信息,利用机器学习能够自动识别和提取有价值的情报线索。
比如,能够快速识别敌方军事设施的位置、类型和活动模式,预测敌方的军事行动意图。
这种能力大大提高了情报分析的效率和准确性,为军事决策提供了有力支持。
在军事装备的维护和故障预测方面,机器学习也有着出色的表现。
军事装备的复杂程度日益增加,传统的维护方式往往依赖于定期检查和经验判断,效率低下且容易出现漏检。
而机器学习可以通过对装备运行数据的实时监测和分析,提前预测可能出现的故障。
例如,对于飞机发动机的运行参数进行分析,提前发现潜在的故障隐患,及时进行维修和更换部件,从而大大提高了装备的可靠性和可用性,减少了因装备故障导致的战斗力损失。
在军事指挥和决策领域,机器学习同样带来了创新变革。
通过对历史战争数据和模拟作战数据的学习,机器学习模型可以为指挥官提供决策建议和方案评估。
比如,在制定作战计划时,能够根据敌方的兵力部署、地形条件、气候因素等多方面的信息,快速生成多种作战方案,并评估每种方案的可行性和可能的结果。
这有助于指挥官在复杂的战场环境中做出更加明智和快速的决策,提高作战的成功率。
机器学习还在军事目标识别和追踪方面取得了显著进展。
在战场上,准确快速地识别和追踪敌方目标是至关重要的。
利用深度学习技术,如卷积神经网络,可以对图像和视频中的目标进行精准识别和跟踪。
无论是飞机、坦克、舰艇等大型军事目标,还是敌方士兵等小型目标,都能够实现实时、准确的识别和追踪。

第47卷第3期燕山大学学报Vol.47No.32023年5月Journal of Yanshan UniversityMay 2023㊀㊀文章编号:1007-791X (2023)03-0262-11一种多策略混合型烟花算法黄华娟1,邹鹏程2,韦修喜1,∗,徐㊀晨2(1.广西民族大学人工智能学院广西南宁530006;2.广西民族大学电子信息学院广西南宁530006)㊀㊀收稿日期:2022-07-06㊀㊀㊀责任编辑:唐学庆基金项目:国家自然科学基金资助项目(62266007);广西自然科学基金资助项目(2021GXNSFAA220068,2018GXNSFAA294068)㊀㊀作者简介:黄华娟(1984-),女,广西崇左人,博士,副教授,主要研究方向为机器学习和数据挖掘;∗通信作者:韦修喜(1980-),男,广西百色人,副教授,硕士生导师,主要研究方向为机器学习和智能优化,Email:weixiuxi@㊂摘㊀要:针对传统烟花算法存在寻优精度低,多样性差,爆炸更新具有盲目性的不足,提出一种融合算术优化算法的混合型烟花算法㊂首先,该算法利用算术中乘除运算和加减运算实现烟花的爆炸操作,从而提高算法的收敛能力和寻优精度㊂其次,采用 精英 选择策略取代 轮盘赌 选择策略,降低算法复杂度㊂最后,通过对8个基准函数优化测试以及联合谱聚类算法对2个UCI 基本数据集进行分类实验来评估该算法的有效性㊂实验结果表明,该算法对于函数优化能够较好的寻优求解在4个测试函数上精度误差从10-100附近降低至10-300,在谱聚类算法的应用中适应度值平均值至少优于原算法3.3%,总体性能优秀㊂关键词:烟花算法;算术优化算法;函数优化;谱聚类中图分类号:TP18㊀㊀文献标识码:A㊀㊀DOI :10.3969/j.issn.1007-791X.2023.03.0100 引言烟花算法(Fireworks algorithm,FWA)[1]是由北京大学谭营教授于2010年提出的模拟烟花爆炸并结合进化计算的随机搜索的群智能算法㊂烟花算法不同于其他群智能算法,它的多种不同算子分布工作,实现信息交互共享,能够处理复杂的优化问题㊂爆炸㊁变异㊁选择等算子的存在使得算法具备广阔的研究前景㊂算术优化算法(Arithmetic optimizationalgorithm,AOA)[2]是Abualigah 等于2021年提出的一种根据算术操作符的分布特性实现全局寻优的元启发式优化算法㊂该算法通过乘除运算进行全局勘探并通过加减运算进行局部开采,具有可移植性强㊁参数少及执行效率高等特点㊂谱聚类(Spectral clustering,SC)是基于图论的现代聚类算法,根据样本之间的相似度构建无向图,再使用某种切图算法把无向图分割为若干个不相连接的子图,从而实现对样本的划分,将聚类问题转化为图的切割问题[3]㊂传统的聚类算法在非凸数据上的表现较差,而SC 算法却没有这个限制,对于不同分布的数据都有很好的划分效果㊂具有解决多路谱聚类能力的NJW(Neue juristischewochenschrift)算法是谱聚类的代表性算法,然而其聚类效果很大程度依赖于对初始类中心敏感的K -means 算法㊂K -means 算法是一种无监督学习的聚类方法,在聚类过程中,受初始聚类中心的影响,算法易存在聚类精度低㊁聚类效果不稳定等问题[4]㊂烟花算法对空间解的搜索具有一定的优势,因此,在NJW 算法的特征空间内对新样本划分时,若采用烟花算法替代K -means 算法,这将融合NJW 和FWA 两种算法的优势㊂近年来学界对烟花算法的研究不断深入并针对算法的不足提出一系列改进算法㊂Zheng 等[5]针对爆炸算子存在的不足提出了引入最小爆炸半径阈值的增强烟花算法(Enhanced fireworks algorithm,EFWA)㊂仅依据烟花适应度差值计算得到的爆炸半径较难达到较小值,所以FWA 和EFWA 局部搜索能力较差㊂针对局部寻优能力不足,Zheng 等[6]提出了引入爆炸半径放大缩小机制第3期黄华娟等㊀一种多策略混合型烟花算法263㊀的动态搜索烟花算法(Dynamic search in fireworks algorithm,dynFWA),当烟花种群搜索到一个适应度值不再变好的位置时,dynFWA将减小核心烟花的爆炸半径,反之则增大㊂虽然dynFWA去除了变异算子加快了寻优速度,但适应度值不再变好时减小半径易使得算法陷入局部最优㊂自适应烟花算法(Adaptive fireworks algorithm,AFWA)是Li 等[7]提出的另一种与粒子群算法全局搜索类似的调整搜索半径的方法㊂当前个体的爆炸半径为当前个体与当前最优个体的距离,以便算法跳出局部最优㊂虽然AFWA能对搜索步长进行自适应调整,表现出了很好的性能改善,但是仅有步长的自适应调整,而没有爆炸火花数的自适应变化,难以平衡算法的开采与勘探能力㊂只对单一算法改进难以快速找到最优解,为此,一些混合算法相继被提出㊂Gao等[8]提出融合文化算法的文化烟花算法(Cultural fireworks algorithm,CA-FWA),并将文化烟花算法应用到滤波器的设计上,并取得了较好的性能㊂Zheng等[9]提出融合差分进化算法的混合型烟花算法(Hybrid fireworks optimization method with differential evolution operators,FWA-DE)㊂文化烟花算法和差分进化算法都有其特定的优势,用于结合烟花算法的混合算法能兼顾两种算法的优势,但同时也会产生冲突,如何解决两种算法的冲突往往是解决问题的关键㊂AOA算法原理简单,易于实现,参数少,为此将AOA算法与FWA算法结合,冲突少,易于得到可观的结果㊂以上文献对基本烟花算法都有一定程度的改进,但仍有不足㊂首先,对于爆炸半径的设置,非线性递减的步长具有一定盲目性㊂其次,对粒子随机维度进行爆炸半径内位置更新操作,并非更新步长为爆炸半径,而是0到爆炸半径,既无法保证所选维度的有效性,又可能导致多代粒子更新步长相似,爆炸半径起到极其微小的作用㊂最后,对于变异策略,大多数采用的高斯变异使得粒子变异过程中倾向于0,造成算法对于最优解在原点附近寻优精度高的假象㊂为此,本文提出了融合AOA算法的混合型烟花算法(Hybrid fireworks algorithm based on AOA,AOAFWA)㊂受半径放大缩小机制及AOA算法加减乘除机制的启发,结合烟花爆炸的随机性,本文算法引入加减乘除机制代替烟花算法爆炸更新机制,由于加减乘除机制是在当前最优粒子上实施的,本文采用精英选择策略,既没有了轮盘赌[10]选择策略的高复杂度,又更好地迎合加减乘除机制㊂最后,选取柯西变异[11]策略以增加种群多样性,帮助算法跳出局部最优㊂本文选取了8个基本测试函数进行测试并在谱聚类问题上进行测试,验证了AOAFWA算法在收敛能力和搜索能力上的有效性和优越性㊂1㊀烟花算法1.1㊀烟花算法实现步骤步骤1:种群初始化㊂随机生成N个烟花,根据优化的目标函数计算每个烟花的适应度值,从而确定烟花质量的好坏㊂步骤2:计算烟花的爆炸半径A i和爆炸火花数S i:S i=M㊃y max-f(x i)+εðN i=1(y max-f(x i))+ε,(1)A i=A^㊃f(x i)-y min+εðN i=1(f(x i)-y min)+ε,(2)其中:A^和M为常数,用于调整爆炸半径和爆炸产生火花数;f(x i)为烟花i的适应度值;y min和y max 分别是最好与最差烟花个体的适应度值;ε为机器最小量,避免除零操作㊂为防止产生爆炸火花数向优质或劣质烟花压倒性倾斜,文献[1]对于爆炸火花数进行了限制:S i=round(a㊃M)㊀S i<a㊃Mround(b㊃M)㊀S i⩾b㊃Mround(S i)其他ìîíïïïï,(3)其中:a,b是常数;round(㊀)是取整函数㊂步骤3:根据式(4)生成爆炸火花,并对其进行越界检测,根据式(5)将超出爆炸空间的爆炸火花映射到可行域空间内:N k i=N k i+A iˑU(-1,1),(4) N k i=N k LB+mod(N k i,(N k UB-N k LB)),(5)其中:N k i代表烟花i的第k维度的位置;U(-1,1)代表[-1,1]的随机分布;N k LB和N k UB分别为在维度k上解空间的下㊁上边界㊂步骤4:根据式(6)生成少量的高斯变异火花264㊀燕山大学学报2023并根据式(5)进行越界处理,增加了群体多样性:N k i=N k i㊃e,(6)其中,e~N(0,1)㊂步骤5:选择策略㊂根据式(7)从烟花㊁爆火花和高斯变异火花组成的候选者集合中选择N-1个烟花和当代适应度值最优的火花作为下一代烟花:p i=ðK j=1d(N i-N j)ðK j=1N j,(7)其中d(N i-Νj)表示候选集中个体i与除i以外所有个体之间的距离㊂步骤6:判断是否满足终止条件㊂满足则终止搜索,否则转至步骤2㊂2㊀算术优化算法2.1㊀算术优化算法实现步骤步骤1:初始化算法相关参数和种群㊂步骤2:计算适应度值,并记录最优位置㊂生成0到1之间的随机数r1,r2,r3㊂步骤3:根据式(8)计算数学优化器加速函数(Math Optimizer Acceleration function,MOA),记为FMOA,判断是否小于r1,小于则转步骤4进行全局搜索,否则转步骤5进行局部搜索:FMOA(iter)=M min+iter㊃M max-M minMaxIter,(8)其中:M min和M max分别是加速函数的最小值和最大值,为0.2和1;iter和MaxIter分别为当前迭代次数和最大迭代次数㊂步骤4:根据式(9)和式(10)(数学优化器概率(Math optimizer probability,MOP),记为FMOP)进行乘除运算更新粒子位置㊂其中:μ是调整搜索过程的控制参数,值为0.499;ε为极小值;X b(iter)为iter代最优位置;UB和LB分别为寻优空间上下界;α是敏感参数,取值为5㊂转步骤6㊂步骤5:根据式(11)进行加减运算更新位置:X(iter+1)=X b(iter)/(FMOP(iter)+ε)㊃((UB-LB)㊃μ+LB)㊀r2<0.5X b(iter)㊃FMOP(iter)㊃((UB-LB)㊃μ+LB)r2ȡ0.5{,(9) FMOP(iter+1)=1-iter1/α/MaxIter1/α,(10)X(iter+1)=X b(iter)-FMOP(iter)㊃((UB-LB)㊃μ+LB)㊀r3<0.5X b(iter)+FMOP(iter)㊃((UB-LB)㊃μ+LB)r3ȡ0.5{㊂(11)㊀㊀步骤6:计算适应度值,并记录最优位置㊂步骤7:判断是否满足结束条件,如果满足则输出最优解,否则跳转至步骤3㊂3㊀混合型烟花算法3.1㊀基于加减乘除机制的爆炸策略烟花算法的核心就是烟花爆炸环节,爆炸策略的好坏直接影响寻优能力㊂传统烟花算法以及大多数改进算法均存在爆炸半径盲目设定的问题,无法实现爆炸半径与寻优进度相适应,同时,在不同半径内爆炸的粒子覆盖率较高(极少部分粒子以爆炸半径为步长进行位置更新),进而导致算法早熟或者过早陷入局部最优㊂此外,对爆炸粒子随机维度进行位置更新,无法保证所选维度为寻优所需要的维度,即使该维度为寻优所需关键维度,仅对其实施一次0到A i之间随机幅度位移操作,难以保证寻优效果,应给予其更大的爆炸幅度及更多的位移次数㊂鸟群算法中通过学习因子调节认知经验和社会经验㊂在搜索前期较大的认知系数和较小的社会系数可以增大认知经验的比重,使得鸟群全局搜索能力增强,搜索后期较小的认知系数和较大的社会系数可以增大社会经验的比重,增强局部搜索能力㊂针对上述存在的问题,参考复杂适应理论中的自适应性和个体与种群的协同进化作用[12],采取随机均匀分布的加速度函数的AOA算法与FWA算法结合将更好地平衡算法在迭代初期和后期的全局及局部搜索能力㊂具体通过将AOA 算法位置更新方式取代烟花算法爆炸位置更新方式,利用乘除运算实现全局搜索,利用加减运算实现局部开发㊂第3期黄华娟等㊀一种多策略混合型烟花算法265㊀3.2㊀柯西变异策略传统烟花算法对随机选择的烟花的随机维度进行高斯变异操作,主要存在以下问题:第一,随机选择的烟花,其位置具有很大随机性,难以保证其位置优越性,再对其部分维度进行变异操作,难保证选到需要变异的维度,假设选到该维度,变异方向与大小又会对结果产生影响,总之,其整体位置变优的概率很小,大多数变异粒子适应度值差于当代最优适应度值而被淘汰,浪费了计算资源㊂第二,高斯分布特征决定了算法只在当前解领域范围内进行搜索,难以跳出局部最优㊂针对以上不足,本文根据式N k i=N k i㊃(1+c)(12)对变异算子进行柯西变异,其中c~C(0,1)㊂柯西变异算子的全局搜索能力更强,增大了变异范围,增加了种群多样性㊂3.3㊀精英选择策略传统烟花算法采用基于欧氏距离的轮盘赌选择策略有以下两个主要缺点:第一,计算复杂,限制收敛速度;第二,密度高或适应度值好的粒子周围存在较多粒子,其被选择到下一代的概率较小㊂为了加快收敛速度㊁提高收敛精度以及更好地迎合加减乘除机制,本文选用精英选择策略㊂3.4㊀算法伪代码及复杂度分析算法1㊀AOAFWA算法1输入:群体规范N,最大爆炸火花数M,变异火花数Mu2输出:最优解和最佳适应度值3搜索空间内随机初始化N个烟花;4计算烟花的适应度值;5㊀㊀FOR㊀iter=1TO MaxIter DO6㊀㊀㊀FOR㊀i=1TO N DO7㊀㊀㊀㊀根据式(1)㊁(3)得到爆炸子数S i;8㊀㊀㊀㊀根据式(8)㊁(9)㊁(10)㊁(11)生成爆炸火花,并根据式(5)进行越界处理;9㊀㊀㊀㊀根据式(12)生成变异火花,并根据式(5)进行越界处理;10㊀㊀㊀根据精英选择策略,选出N个烟花作为下一代烟花; 11㊀㊀㊀END FOR12㊀㊀END FOR13输出最佳解和最佳适应度;㊀㊀时间复杂度是指算法执行完成所需的时间,主要取决于问题被重复执行的次数㊂标准烟花算法的时间复杂度主要取决于种群大小n㊁迭代次数t和问题维度d㊂由标准烟花算法的算法步骤可知,它的时间复杂度为O(nˑtˑd)㊂AOAFWA算法是通过改进FWA算法而来,由算法伪代码可知,将原算法爆炸更新机制替换为AOA算法位置更新机制增加了O(t)的工作量,柯西变异策略及精英选择策略均未增加工作量㊂综上,AOAFWA算法的时间复杂度仍是O(nˑtˑd)㊂空间复杂度是算法在执行完成所需的存储空间,而标准烟花算法的空间复杂度主要取决于种群大小n和问题维度d,所以标准烟花算法的空间复杂度为O(nˑd)㊂改进算法AOAFWA中采用几个常量标记MOA和MOP的值,同时减少了常量A i的值,它所消耗的存储空间可以忽略不计,故AOAFWA的空间复杂度也是O(nˑd)㊂4㊀实验仿真与分析为了验证AOAFWA算法的有效性,进行了两组实验㊂第一组是通过8个标准测试函数(详细信息见表1,F1㊁F2㊁F3和F4为单峰函数,F5㊁F6㊁F7和F8中为多峰函数,维度均为30,最优值均为0)及FWA㊁AOA㊁GFWA[13]㊁LoTFWA[14]㊁GWO[15]和BOA[16]6个对比算法进行测试分析㊂第二组是应用于谱聚类问题㊂所有算法初始种群大小统一设置为30,最大迭代次数设为1000次㊂为了降低算法随机性对实验性能的影响,以30次独立实验的平均值作为评估算法寻优性能和收敛性能的最终结果㊂所有算法的实验在同一平台上运行,实验平台为Windows10(64bit)操作系统下的MATLAB R2018b,硬件条件为Intel Core i5-4210CPU 2.90GHz㊁8GB内存㊂参与测试的各算法的具体参数见表2㊂4.1㊀基准函数实验测试与分析表3列出了7种算法在不同测试函数下目标函数最优值㊁最差值㊁平均值㊁运行时间以及标准差的详细数据,其中粗体标注为最佳搜索结果㊂为了更直观地比较,表中将搜索质量进行量化,通过平均值㊁方差进行排序,排名越靠前,等级值越小,最后一列给出了排列次序㊂从表中数据可看266㊀燕山大学学报2023出:在8个测试函数中,AOAFWA 算法均排名第一,并且寻找到最优解㊂在单峰函数F 1㊁F 2㊁F 3和F 4中,AOAFWA 相较于标准FWA,其收敛精度误差从10-100附近降低至10-300,相较于其他对比算法所提升的数量级更多㊂在多峰函数F 5㊁F 6㊁F 7和F 8中,AOAFWA 与标准FWA 均能收敛到最优值,且收敛精度远超其他对比算法㊂这表明,标准FWA 自身已具备出色的寻优能力,改进后的AOAFWA 进一步增加了原算法的收敛精度㊂从运行时间看,AOAFWA 算法运行时间远小于FWA 算法及其改进算法,虽然略高于GWO㊁BOA 和AOA算法,但运行时间的略微增加换取了更高的寻优精度还是可以接受的㊂为补充说明,图1~图8分别描绘了8个测试函数寻优迭代对比曲线图㊂观察可知,改进后的AOAFWA 充分吸收了AOA 和FWA 的优点,既具备了AOA 快速寻优的特点(200代以内就搜寻到最优解),又具备了FWA 收敛精度高的特点(均快速收敛到最优解,远超其他对比算法)㊂通过实验数据和收敛图的展示,进一步说明了AOAFWA 算法相比其他FWA 变体算法以及其他智能优化算法在标准函数测试中的表现更优越㊂表1㊀标准测试函数Tab.1㊀Standard test function函数范围F 1=ðni =1x 2i [-100,100]F 2=ðn i =1|x i |+ᵑni =1|x i |[-10,10]F 3=ðn i =1ðnj =1x j ()2[-100,100]F 4=106x 21+ðni =2x 2i [-100,100]F 5=ðni =1[x 2i -10cos(2πx i )+10][-5.12,5.12]F 6=-20exp -0.21nðni =1x 2i()-exp1nðni =1cos(2πx i )()+20+e [-32,32]F 7=14000ðni =1x 2i-ᵑni =1cos x i i()+1[-600,600]F 8=0.5+sin 2(x 21+x 22+0.5)(1.0+0.0001(x 21+x 22))2[-100,100]表2㊀具体参数Tab.2㊀Specific parameters算法参数FWAN =30,M =20,Mu =10,a =0.04,b =0.8,A ^=0.8DGFWAN =30,M =20,σ=0.2,α=0,A c (1)=0.8D ,ρ+=1.2,ρ-=0.9LoTFWA N =30,M =20,σ=0.2,A c (1)=0.8D ,ρ+=1.2,ρ-=0.9BOAN =30,p =0.8,c =0.01,a =0.3GWO N =30AOA N =30,μ=0.449,α=5,Min =0.2,Max =1AOAFWA N =30,M =20,Mu =10,a =0.04,b =0.8,Min =0.2,Max =1,μ=0.499,α=5第3期黄华娟等㊀一种多策略混合型烟花算法267㊀表3㊀标准函数测试结果Tab.3㊀Test results of standard function函数算法平均值方差最优值最差值时间/s排名F1AOAFWA0.00ˑ1000.00ˑ1000.00ˑ1000.00ˑ1000.661 FWA 4.58ˑ10-87 4.40ˑ10-83 6.02ˑ10-115 2.00ˑ10-82 2.812 AOA 1.19ˑ10-69 3.56ˑ10-69 2.54ˑ10-289 1.19ˑ10-680.183 GFWA 3.78ˑ10-12 1.92ˑ10-11 1.51ˑ10-138.76ˑ10-11 3.147 LoTFWA 1.44ˑ10-19 2.74ˑ10-19 2.86ˑ10-219.51ˑ10-19 4.016 GWO9.04ˑ10-59 1.46ˑ10-59 1.16ˑ10-61 6.44ˑ10-590.234 BOA7.73ˑ10-23 2.34ˑ10-23 4.73ˑ10-23 1.54ˑ10-220.325F2AOAFWA0.00ˑ1000.00ˑ1000.00ˑ1000.00ˑ1000.661 FWA 1.17ˑ10-48 4.89ˑ10-45 2.17ˑ10-60 2.25ˑ10-44 2.273 AOA0.00ˑ1000.00ˑ1000.00ˑ1000.00ˑ1000.181 GFWA 5.11ˑ10-2 3.00ˑ10-27.42ˑ10-7 1.90ˑ10-1 3.147 LoTFWA 1.94ˑ10-109.49ˑ10-11 4.65ˑ10-11 3.42ˑ10-10 4.096 GWO 1.17ˑ10-34 6.63ˑ10-35 2.02ˑ10-35 2.79ˑ10-340.234 BOA 3.06ˑ10-20 4.00ˑ10-21 2.10ˑ10-20 3.51ˑ10-200.325F3AOAFWA0.00ˑ1000.00ˑ1000.00ˑ1000.00ˑ1000.761 FWA 3.14ˑ10-58 1.29ˑ10-57 2.72ˑ10-93 5.91ˑ10-57 2.372 AOA 6.61ˑ10-5 1.98ˑ10-4 2.84ˑ10-195 6.61ˑ10-40.205 GFWA 1.95ˑ10-37.47ˑ10-4 1.29ˑ10-5 2.58ˑ10-3 3.796 LoTFWA 3.91ˑ10-2 2.36ˑ10-2 5.65ˑ10-39.36ˑ10-2 4.867 GWO 1.59ˑ10-14 3.34ˑ10-13 1.69ˑ10-19 1.51ˑ10-120.264 BOA8.56ˑ10-23 1.62ˑ10-23 5.50ˑ10-23 1.12ˑ10-220.393F4AOAFWA0.00ˑ1000.00ˑ1000.00ˑ1000.00ˑ100 1.051 FWA7.54ˑ10-84 2.05ˑ10-858.82ˑ10-1188.00ˑ10-85 2.933 AOA 6.02ˑ10-99 1.38ˑ10-98 6.74ˑ10-266 4.56ˑ10-980.312 GFWA 4.92ˑ103 3.40ˑ104 1.19ˑ100 1.50ˑ105 5.846 LoTFWA8.73ˑ106 3.52ˑ106 3.57ˑ106 1.63ˑ1077.157 GWO 2.12ˑ10-55 5.15ˑ10-55 3.53ˑ10-58 2.06ˑ10-540.374 BOA 1.52ˑ10-21 1.80ˑ10-18 1.39ˑ10-228.25ˑ10-190.595F5AOAFWA0.00ˑ1000.00ˑ1000.00ˑ1000.00ˑ1000.661 FWA0.00ˑ1000.00ˑ1000.00ˑ1000.00ˑ100 2.951 AOA0.00ˑ1000.00ˑ1000.00ˑ1000.00ˑ1000.191 GFWA 3.90ˑ101 3.26ˑ1018.95ˑ100 1.20ˑ102 3.496 LoTFWA8.75ˑ101 1.52ˑ101 5.57ˑ101 1.11ˑ102 4.577 GWO 5.92ˑ10-1 2.07ˑ1000.00ˑ100 6.02ˑ1000.235 BOA 3.35ˑ10-13 1.26ˑ10-13 1.14ˑ10-13 6.25ˑ10-130.344268㊀燕山大学学报2023续表函数算法平均值方差最优值最差值时间/s排名F6AOAFWA0.00ˑ1000.00ˑ1000.00ˑ1000.00ˑ1000.661 FWA0.00ˑ1000.00ˑ1000.00ˑ1000.00ˑ100 3.561 AOA0.00ˑ1000.00ˑ1000.00ˑ1000.00ˑ1000.191 GFWA 1.16ˑ10-1 4.89ˑ10-1 5.75ˑ10-8 2.22ˑ100 3.507 LoTFWA 1.35ˑ10-107.01ˑ10-11 2.04ˑ10-11 3.41ˑ10-10 4.746 GWO 1.31ˑ10-14 3.57ˑ10-15 1.07ˑ10-14 2.84ˑ10-140.234 BOA 4.05ˑ10-14 2.09ˑ10-15 3.20ˑ10-14 4.26ˑ10-140.325F7AOAFWA0.00ˑ1000.00ˑ1000.00ˑ1000.00ˑ100 6.781 FWA0.00ˑ1000.00ˑ1000.00ˑ1000.00ˑ100 2.981 AOA0.00ˑ1000.00ˑ1000.00ˑ1000.00ˑ1000.191 GFWA 5.67ˑ10-38.31ˑ10-3 3.17ˑ10-13 2.96ˑ10-2 3.597 LoTFWA 1.67ˑ10-16 1.11ˑ10-160.00ˑ100 3.33ˑ10-16 4.745 GWO0.00ˑ1000.00ˑ1000.00ˑ1000.00ˑ1000.241 BOA 4.33ˑ10-168.93ˑ10-17 3.33ˑ10-16 5.55ˑ10-160.336F8AOAFWA0.00ˑ1000.00ˑ1000.00ˑ1000.00ˑ1000.651 FWA0.00ˑ1000.00ˑ1000.00ˑ1000.00ˑ100 3.621 AOA 6.81ˑ10-2 3.40ˑ10-20.00ˑ1008.51ˑ10-20.185 GFWA 1.01ˑ10-2 5.61ˑ10-28.51ˑ10-2 2.42ˑ10-1 3.214 LoTFWA 4.81ˑ10-1 4.97ˑ10-3 4.85ˑ10-1 5.00ˑ10-1 4.377 GWO 1.32ˑ10-17.19ˑ10-28.51ˑ10-2 2.42ˑ10-10.236 BOA 4.39ˑ10-16 5.30ˑ10-17 2.78ˑ10-16 5.00ˑ10-160.313图1㊀F1的收敛曲线Fig.1㊀The convergence curve of F 1图2㊀F2的收敛曲线Fig.2㊀The convergence curve of F2第3期黄华娟等㊀一种多策略混合型烟花算法269㊀图3㊀F3的收敛曲线Fig.3㊀The convergence curve of F 3图4㊀F4的收敛曲线Fig.4㊀The convergence curve of F 4图5㊀F5的收敛曲线Fig.5㊀The convergence curve of F 5图6㊀F6的收敛曲线Fig.6㊀The convergence curve of F 6图7㊀F7的收敛曲线Fig.7㊀The convergence curve of F 7图8㊀F8收敛曲线Fig.8㊀The convergence curve of F8270㊀燕山大学学报20234.2㊀Wilcoxon 统计校验仅以算法的平均值㊁标准差㊁最优值和最差值作为算法性能的评价指标是不够严谨的㊂因此对所提出的算法进行统计校验是必不可少的㊂为了比较文中7种算法的性能,采用了Wilcoxon 秩和校验㊂表4中记录了7种算法在8个测试函数上秩和校验后得到的p 值㊂当p 值小于0.05时,说明两种对比算法之间存在较大的差异,否则表明对比算法存在一定的相似性㊂p 值为 NA 表示此校验不适用㊂表4㊀Wilcoxon 秩和校验的p 值Tab.4㊀p-value of Wilcoxon rank-sum test函数AOAFWA /FWA AOAFWA /AOA AOAFWA /GFWA AOAFWA /LoTFWAAOAFWA /GWO AOAFWA /BOA F 18.01ˑ10-9 6.39ˑ10-58.01ˑ10-98.01ˑ10-98.01ˑ10-98.01ˑ10-9F 28.01ˑ10-9NA8.01ˑ10-98.01ˑ10-98.01ˑ10-98.01ˑ10-9F 38.01ˑ10-9 6.39ˑ10-58.01ˑ10-98.01ˑ10-98.01ˑ10-98.01ˑ10-9F 48.01ˑ10-96.39ˑ10-58.01ˑ10-98.01ˑ10-98.01ˑ10-98.01ˑ10-9F 5NA NA 8.01ˑ10-98.01ˑ10-9 3.77ˑ10-47.45ˑ10-9F 6NA NA 8.01ˑ10-98.01ˑ10-9 2.66ˑ10-9 3.73ˑ10-9F 7NA NA 8.01ˑ10-98.00ˑ10-7NA6.85ˑ10-9F 8NA5.97ˑ10-37.56ˑ10-97.30ˑ10-98.01ˑ10-95.88ˑ10-9㊀㊀由表4可知,在所有测试函数中,AOAFWA 与其他对比算法有很大的不同,这说明了AOAFWA 具有较好的寻优性能㊂4.3㊀NJW 谱聚类问题测试与分析NJW 谱聚类可以理解为将高维空间的数据映射到低维,然后在低维空间用其他聚类算法(如K -means)进行聚类㊂本文通过AOAFWA 算法代替K -means 算法寻找最优初始中心簇,评价指标选取为所有点到相应重心的距离的平方和F (D K ,ξ),F (D K ,ξ)=ðKk =1ðnki =1Dist (d (k )i,ξk ),(13)其中:数据集D K 为原始数据划分为K 类得到新的数据集,聚类中心ξ=ξ1,ξ2, ,ξK {},d (k )i为第k 类别中第i 个数据,Dist 为欧氏距离的平方㊂通过2个UCI 数据集Iris 和Wine 及不同尺度参数σ进行分类实验,由于尺度参数对聚类结果有较大影响,所以进行大量实验以验证算法寻优能力,篇幅有限,表5只列出了部分AOAFWA 算法与FWA 算法以及K -means 算法在30次独立运行后的寻优结果,算法具体参数设置见表2㊂与FWA 相比,无论从平均值㊁标准差㊁最优值或者最差值来看,AOAFWA 算法均获得较佳的数据,平均值至少优于原算法3.3%,体现其出色的稳定性与寻优精度;与K -means 相比,AOAFWA 算法平均值依然最低,虽然最优值差于K -means 算法(最多为1.7%),但最差值却优于K -means 算法(最少为3.1%)㊂从标准差可看出:改进后的AOAFWA 算法标准差远远低于改进前的FWA 算法,鉴于K -means 算法具有较大的随机性,所以出现个别标准差低于AOAFWA 算法的情况也可接受㊂综上AOAFWA 收敛速度㊁收敛精度㊁稳定性都优于FWA,表现出对FWA 改进后的AOAFWA 出色效果㊂5㊀结论针对FWA 算法的缺点,本文在传统烟花算法的基础上进行改进,融合了AOA 算法收敛速度快的优点㊂对于AOA 算法而言,FWA 算法烟花爆炸机制的存在增加了AOA 算法的并行寻优能力,进一步提高了AOA 算法寻优速度与寻优精度;对于FWA 算法而言,AOA 算法的加减乘除机制为已经处于瓶颈期的爆炸策略提供了新的思路,进一步平衡了FWA 算法勘探与开采能力㊂通过测试,该算法对于函数优化能够较好的寻优求解,在4个测试函数上精度误差从10-100附近降低至10-300(同时从收敛曲线图能够看出该算法均在300代以内就收敛到全局最优解),在谱聚类算法的应用中适应度值平均值至少优于原算法3.3%,证明本文AOAFWA 算法相比于其他算法在求解精度方第3期黄华娟等㊀一种多策略混合型烟花算法271㊀面具有更强的竞争优势,但运行效率稍低于GWO㊁AOA和BOA算法,这也是FWA算子众多所带来的弊端㊂这篇文章限于篇幅,并未对FWA算子进行简化再融合AOA,未来将考虑删除变异算子并将改进后的AOA融入到FWA中,进一步减少算法运行时间,提高收敛精度,并用于解决更多实际问题㊂表5㊀不同算法在谱聚类问题测试结果比较Tab.5㊀Comparison of test results of different algorithms in Spectral clustering problem数据集尺度参数测试算法最优值最差值平均值标准差WineAOAFWA 1.7495 1.9428 1.78250.0637 0.3FWA 1.7731 2.1561 1.90040.0882K-means 1.7491 2.2975 1.90220.0972AOAFWA 1.5794 1.6889 1.64460.0457 1.0FWA 1.5964 2.0589 1.74440.1255K-means 1.5790 2.1350 1.75840.0983AOAFWA 1.5086 1.6312 1.57390.0316 1.7FWA 1.5340 1.9446 1.72650.1027K-means 1.5083 2.0737 1.65350.0993IrisAOAFWA 1.8401 1.9011 1.86290.0164 0.3FWA 1.8660 1.9618 1.90530.0266K-means 1.8388 1.9681 1.86740.0008AOAFWA 1.7738 1.9229 1.79970.0307 1.0FWA 1.8164 1.9417 1.86040.0318K-means 1.7724 1.8976 1.81180.0015AOAFWA 1.7981 1.8921 1.82480.0225 1.7FWA 1.8143 1.9724 1.88500.0423K-means 1.7964 1.9545 1.83600.0014参考文献1TAN Y ZHU Y.Fireworks algorithm for optimization C// Proceedings of International Conference in Swarm Intelligence Berlin Germany 2010 355-364.2ABUALIGAH L DIABAT A MIRJALILI S et al.The arithmetic optimization algorithm J .Computer Methods in Applied Mechanics and Engineering 2021 376 113609.3俞家珊.基于改进的谱聚类算法和TTLSSA-LSSVM的短期电力负荷预测 D .无锡江南大学2021.YU J S.Short-term load forecasting based on improved spectral clustering algorithm and TTLSSA-LSSVM D .Wuxi Jiangnan University 2021.4王盛慧夏永丰.基于搜寻者优化算法的K-means聚类算法 J .燕山大学学报2018 42 5 422-426.WANG S H XIA Y F.K-means clustering algorithm based on seeker optimization algorithm J .Journal of Yanshan University 2018 42 5 422-426.5ZHENG S Q JANECEK A TAN Y.Enhanced fireworksalgorithm C//IEEE Congress on Evolutionary Computation Cancun Mexico 2013 2069-2077.6ZHENG S Q JANECEK A LI J et al.Dynamic search in fireworks algorithm C//IEEE Congress on Evolutionary Computation Beijing China 2014 3222-3229.7LI J ZHENG S Q TAN Y.Adaptive fireworks algorithm C// IEEE Congress on Evolutionary Computation Beijing China 2014 3214-3221.8GAO H Y DIAO M.Cultural fireworks algorithm and its application for digital filters design J .International Journal of Modelling Identification and Control 2011 14 4 324-331. 9ZHENG Y J XU X L LING H F et al.A hybrid fireworks optimization method with differential evolution operators J . Neurocomputing 2015 148 75-80.10向万里马寿峰.基于轮盘赌反向选择机制的蜂群优化算法 J .计算机应用研究2013 30 1 86-89.XIANG W L MA S F.Artificial bee colony based on reserve selection of roulette J .Application Research of Computers 2013 30 1 86-89.11曾敏赵志刚李智梅.带柯西变异的自学习改进烟花算法272㊀燕山大学学报2023J .小型微型计算机系统2020 41 2 264-270. ZENG M ZHAO Z G LI Z M.Self-learning improved fireworks algorithm with Cauchy mutation J .Journal of Chinese Computer Systems 2020 41 2 264-270.12聂瀚杨文荣马晓燕等.基于改进鸟群算法的离网微电网优化调度 J .燕山大学学报2019 43 3 228-237.NIE H YANG W R MA X Y et al.Optimal scheduling of islanded microgrid based on improved bird swarm optimization algorithm J .Journal of Yanshan University 2019 433 228-237.13LI J ZHENG S Q TAN Y.The effect of information utilization Introducing a novel guiding spark in the fireworks algorithm J .IEEE Transactions on Evolutionary Computation 2017 141 153-166.14LI J TAN Y.Loser-out tournament-based fireworks algorithm for multimodal function optimization J .IEEE Transactions on Evolutionary Computation 2018 22 5 679-691.15VAPNIK V N LERNER A Y.Pattern recognition using generalized portrait method J .Automation and Remote Control 1963 24 774-780.16ARORA S SINGH S.Butterfly optimization algorithm a novel approach for global optimization J .Soft Computing 2019 233 715-734.A multi-strategy hybrid fireworks algorithmHUANG Huajuan1ZOU Pengcheng2WEI Xiuxi1XU Chen21.College of Artificial Intelligence Guangxi Minzu University Nanning Guangxi530006 China2.College of Electronic Information Guangxi Minzu University Nanning Guangxi530006 ChinaAbstract Aiming at the shortcomings of traditional fireworks algorithm such as low searching accuracy poor diversity and blindness of explosion updating a hybrid fireworks algorithm was proposed by integrating arithmetic optimization algorithm.Firstly the algorithm uses arithmetic multiplication division addition and subtraction to realize the fireworks explosion operation so as to improve the convergence ability and optimization accuracy of the algorithm.Secondly the"elite"selection strategy is used to replace the"roulette"selection strategy to reduce the algorithm complexity.Finally the effectiveness of this algorithm was evaluated by eight benchmark function optimization tests and two UCI basic data sets were classified by the joint spectral clustering algorithm.The experimental results show that the algorithm can better optimize the function optimization.The accuracy error of the four test functions is reduced from10-100to10-300.In the application of spectral clustering algorithm the average fitness value is at least3.3%better than the original algorithm and the overall performance is excellent.Keywords fireworks algorithm arithmetic optimization algorithm benchmark function optimization spectral clusteringCopyright©博看网. All Rights Reserved.。



Cloudless-Training:基于serverless的高效跨地域分布式ML训练框架谭文婷;吕存驰;史骁;赵晓芳【期刊名称】《高技术通讯》【年(卷),期】2024(34)3【摘要】跨地域分布式机器学习(ML)训练能够联合多区域的云资源协作训练,可满足许多新兴ML场景(比如大型模型训练、联邦学习)的训练需求。
但其训练效率仍受2方面挑战的制约。
首先,多区域云资源缺乏有效的弹性调度,这会影响训练的资源利用率和性能;其次,模型跨地域同步需要在广域网(WAN)上高频通信,受WAN的低带宽和高波动的影响,会产生巨大通信开销。
本文提出Cloudless-Training,从3个方面实现高效的跨地域分布式ML训练。
首先,它基于serverless计算模式实现,使用控制层和训练执行层的2层架构,支持多云区域的弹性调度和通信。
其次,它提供一种弹性调度策略,根据可用云资源的异构性和训练数据集的分布自适应地部署训练工作流。
最后,它提供了2种高效的跨云同步策略,包括基于梯度累积的异步随机梯度下降(ASGD-GA)和跨云参数服务器(PS)间的模型平均(MA)。
Cloudless-Training是基于OpenFaaS实现的,并被部署在腾讯云上评估,实验结果表明Cloudless-Training可显著地提高跨地域分布式ML训练的资源利用率(训练成本降低了9.2%~24.0%)和同步效率(训练速度最多比基线快1.7倍),并能保证模型的收敛精度。
【总页数】14页(P219-232)【作者】谭文婷;吕存驰;史骁;赵晓芳【作者单位】中国科学院计算技术研究所;中国科学院大学;中科南京信息高铁研究院;中科苏州智能计算技术研究院【正文语种】中文【中图分类】TP3【相关文献】1.基于跨地域分布式架构的无限加盟电子商务新模式2.基于Spark的分布式机器人强化学习训练框架3.跨地域环境下的电磁数据分布式存储架构4.面向联邦学习的高效分布式训练框架因版权原因,仅展示原文概要,查看原文内容请购买。