基于Lucene的非结构化文档全文检索系统研究与实现
- 格式:doc
- 大小:31.50 KB
- 文档页数:8


基于Lucene全文检索系统的研究与实现[摘要] lucene是一个开放源代码的全文检索引擎工具包,利用它可以快速地开发一个全文检索系统。
利用lucene开发了一个全文检索系统,通过其特殊的索引结构,实现了传统数据库不擅长的全文索引机制,提供了对非结构化信息的检索能力。
[关键词] lucene 信息检索全文检索索引一、引言计算机技术及网络技术的迅速发展,使得internet成为人类有史以来资源最多、品种最全、规模最大的信息资源库。
如何在这海量的信息里面快速、全面、准确地查找所需要的资料信息已经成了人们关注的焦点,也成了研究领域内的一个热门课题。
这些信息基本上可以分做两类:结构化数据和非结构化数据(如文本文档、word 文档、pdf文档、html文档等)。
现有的数据库检索,是以结构化数据为检索的主要目标,实现相对简单。
但对于非结构化数据,即全文数据,由于复杂的数据事务操作以及低效的高层接口,导致检索效率低下。
随着人们对信息检索的要求也越来越高,而全文检索因为检索速度快、准确性高而日益受到广大用户的欢迎, lucene是一个用java写的全文检索引擎工具包,可以方便地嵌入到各种应用中实现针对应用的全文索引和检索功能。
这个开源项目的推出及发展,为任何应用提供了对非结构化信息的检索能力。
二、全文检索策略通常比较厚的书籍后面常常附关键词索引表(比如,北京:12,34页,上海:3,77页……),它能够帮助读者比较快地找到相关内容的页码。
而数据库索引能够大大提高查询的速度原理也是一样,由于数据库索引不是为全文索引设计的,因此,使用like “%keyword%”时,数据库索引是不起作用的,在使用like查询时,搜索过程又变成类似于一页页翻书的遍历过程了,所以对于含有模糊查询的数据库服务来说,like对性能的危害是极大的。
如果是需要对多个关键词进行模糊匹配:like“%keyword1%”and like “%keyword2%”……其效率也就可想而知了。







使用Apache Lucene进行全文检索和信息检索随着数据量的日益增长,信息的获取和管理也变得越来越困难。
在这样的背景下,全文检索技术备受关注。
全文检索是指通过对文本内容进行扫描和分析,快速地查找出包含指定关键字或短语的文本,以满足用户的需求。
Apache Lucene是一款强大的全文检索引擎,具有高效、可靠、易于扩展等特点,广泛被运用于信息检索、文本分类、数据挖掘等领域。
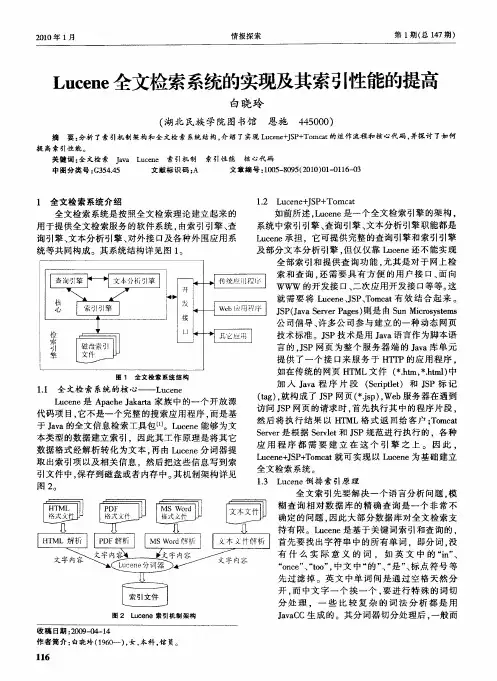
一、Lucene的基本原理Lucene是一款基于Java语言的全文检索引擎,能够快速地在海量数据中查找指定的文本。
Lucene的检索原理可以简单地描述为:将需要检索的文本输入Lucene,Lucene建立索引文件,用户查询文本时,Lucene在索引文件中查找匹配结果,返回用户所需的信息。
Lucene的基本原理如下:1. 建立索引建立索引是Lucene进行全文检索的第一步。
在索引过程中,Lucene会对文本进行解析、分词、词语过滤等处理,然后将这些处理后的词语和其所在的文档信息存储到索引文件中。
通过如此的操作,Lucene做到了在指定时间内,快速地查找指定文本。
2. 查询当用户输入需要检索的文本时,Lucene会对该文本进行同样的预处理,得到其中的每个单独词语,并在索引文件中查找与该词语相匹配的文档。
Lucene采用了先搜索后排名的检索策略,即先找到与关键词匹配的文档,然后再通过算法对得到的结果进行排序,得出匹配度最高的文档。
3. 返回结果Lucene的返回结果是一个文档对象,其中包含了原始文本、关键词匹配的位置和得分等信息。
在大多数情况下,返回的文档对象并不是用户真正想要的结果,需要进行二次过滤和排序,才能得出目标结果。
二、Lucene的基本使用Lucene的使用可以简单地分为以下几个步骤:1. 创建索引创建索引是Lucene进行全文检索的第一步,也是最重要的一步。
在创建索引前,需要准备好需要检索的文本文件。
Lucene支持的文本格式包括txt、doc、pdf等。
基于双层PDF和Lucene技术的全文检索研究与实现作者:向禹吴世明来源:《现代情报》2014年第06期〔摘要〕通过建设双层PDF全文数据库、创建索引和全文检索等实现过程来阐述相关技术的研究和运用。
以建设全文数据库为基础,研究结构化信息与非结构化数据的合并管理,对目录数据和全文数据的同步索引,基于Lucene技术,实现档案管理系统的一站式智能化档案全文检索,提升档案查全率。
〔关键词〕双层PDF;全文检索;档案管理;Lucene〔中图分类号〕TP391〔文献标识码〕B〔文章编号〕1008-0821(2014)06-0075-04由于档案的凭证性、惟一性和不可替代性,导致用户和档案行业更注重查全率。
传统的档案管理手段,由于对标引和著录标准的理解、执行和操作、人员责任心等方面的差异,导致著录信息和检索效果不尽人意。
基于Lucene技术,依托双层PDF文档,对结构化和非结构化信息合并管理,在档案管理系统中实现一站式全文检索,具有很重要的现实意义。
1档案检索研究现状传统档案检索,主要是对档案信息著录和标引进行研究,编制检索目录和目录检索系统,常见的检索工具有主题、分类、字序、文号等多种方式,检索系统有简单检索、复合逻辑组配表达式检索等。
著录和标引质量提高,检索工具完备均能提高查全率,但存在缺陷,且效率较低。
要实现高查全率,必须研究在档案文档中实现内容检索。
Lucene是一个非常优秀的全文本型检索框架[1],在文本型的全文检索方面得到广泛的支持和运用;然而,对纸质档案进行数字化扫描加工,最好的存储方式仍为图片格式的非文本型文档,要实现全文检索并非易事;基于图像的检索技术的研究也还不成熟,效果并不理想。
2全文检索思想与技术档案资源数据有多种类型:一是结构化数据,有固定格式和长度,如数据库或者元数据,数据表格等;二是非结构化数据,特点是不定长和无固定格式,如Word、PDF、JPG等文档;三是半结构化数据,如XML、HTML等,这类数据比较灵活,可根据需要按结构化处理,也可按非结构化处理,在使用Web Service方式的系统集成对接时,协议中采用的数据传输格式大多为XML。
全⽂搜索技术—Lucene前⾔:⽣活中的数据总体分为两种:结构化数据和⾮结构化数据。
(1)结构化数据: 有固定长度或者类型的数据,例如:数据库中的数据, 元数据(就是操作系统中的数据,有⼤⼩有名称有类型);查询⽅式:1、顺序扫描法: 拿着需要搜索的关键字,然后逐⾏匹配内容,直到找到和关键字匹配的内容. 例如:windows中搜索⽂件的算法;sql语句中使⽤like;优点: 只要内容中包含要搜索的关键字,就⼀定能找到需要的内容缺点: 效率⾮常缓慢。
2、数值检索,可以建⽴⼀张排序好的索引表,以⼆分法实现查找,速度很快。
(2)⾮结构化数据: 没有固定长度和类型的数据, 例如: 邮件,word⽂档等磁盘上的⽂件。
查询⽅式:1、顺序扫描法:拿着需要搜索的关键字,然后逐⾏匹配内容,直到找到和关键字匹配的内容.2、全⽂检索算法(倒排索引算法): ⾸先将搜索的内容中的词抽取出来,组成索引(字典中的⽬录), 搜索时根据关键字先去查询索引,然后通过索引来查找⽂档(字典中的内容).优点: 查询效率⾼,速度快缺点: 全⽂检索算法是⽤空间来换取时间, 因为通过内容创建索引,索引是个单独的⽂件,所以⼜额外占⽤了磁盘空间, 但是这种算法查询效率⾼,节省时间⼀、简介:Lucene是apache下的全⽂检索引擎⼯具包,⼯具包就是⼀堆jar包,不能独⽴运⾏,但是可以⽤它jar包中的API,创建像百度,⾕歌这样的搜索引擎系统.lucene和全⽂检索引擎系统区别:lucene:是⼀个⼯具包,就是⼀堆jar包, 不能独⽴运⾏,但是可以使⽤它来创建搜索引擎系统全⽂检索引擎系统:也叫做搜索引擎系统, 它可以独⽴放到tomcat下运⾏, 它对外提供搜索服务,⽐如百度,⾕歌.⼆、应⽤领域:. 1:互联⽹全⽂检索引擎:例如百度, ⾕歌, 必应;. 2:站内全⽂检索:⽐如: 京东还有淘宝的搜索功能;. 3:数据库搜索使⽤模糊查询会使⽤关键字like, ⽽like内部使⽤的算法是顺序扫描法,效率⾮常低,所以⼀般对于⼤量的⽂本数据会使⽤lucene来优化查询。
基于Lucene的非结构化文档全文检索系统研究与实现摘要:如何在海量的非结构文档内容中准确、快捷找到自己所需要的信息,是信息检索技术的研究重点。
全文检索是现代信息检索技术一个非常重要的分支,是解决非结构化数据检索需求的重要技术手段。
以已发布的各类通信业务管理规范的全文检索需求为切入点,设计并实现了适用于国家级气象信息化业务管理的非结构化文档全文检索系统。
该系统基于Java技术,并采用Lucene技术框架,对业务规范信息进行了分析和重新数据组织,确保良好的检索时效与准确率。
系统应用后能快速应对业务变化,在已有的大量的规定、规范、标准和公文函件中迅速、准确、全面地查找有关资料信息,帮助用户准确把握气象信息化发展脉络。
关键词:非结构化文档;全文检索;Lucene;索引文件0引言大数据时代的到来使得可利用的数据和信息量越来越多。
面对超负荷的海量数据,信息检索技术帮助人们在海量数据中准确、快捷地定位和找到所需要的信息。
如何为不同领域的用户提供专业的、量身定做的信息服务成为目前信息检索领域普遍关注的一个热点。
近10年来,我国的气象信息化建设取得了长足的发展。
气象信息系统已经成为现代气象业务体系的重要基础支撑,是现代气象业务的中枢和纽带,是国家信息基础设施的重要组成部分。
气象信息系统整体能力不断提高,目前已经进入了“十二五”发展的快车道。
推动气象信息化建设,在管理工作中快速应对业务系统的发展,亟需在已经颁布和归档的大量的业务规定、规范、标准和公文函件中迅速、准确、全面地查找资料信息,为气象信息化发展与决策提供信息支撑。
为进一步提升气象信息管理软实力,促进气象信息管理向标准化、数字化方向转变,本文设计并实现了国家级气象信息化业务管理检索系统。
该系统将分散的原始规定、规范、标准和公文函件进行有序整编,按照信息覆盖的内容进行分类和合理组织,为国家级和省级气象信息化管理部门提供快捷、有效的业务文档管理与检索服务。
由于该系统应用了目前较为先进的信息检索与管理技术,具有良好的扩展性,能够实现部门内各类办公文档的集中检索与管理,从而对未来提升整个部门的文档管理和使用效率具有重大意义。
1系统分析与设计1.1需求分析建设国家级气象信息化业务管理检索系统是为了提高对各类气象信息化业务规定、规范、标准和公文函件内容的全文检索时效性、便捷性和美观性,并使用户具有良好的用户体验,其基本原理便是非结构化数据全文检索。
主要需求归纳如下:(1)对近10年的我国气象信息化规定、规范、标准和公文函件等文档进行重新组织和管理,合理分组,从逻辑上对文档内容进行分类。
(2)检索反馈迅速,满足时效要求;检索结果准确、全面,没有重复,尽量避免遗漏。
重点是实现非结构化数据全文检索,能够准确定位Word、Excel、PDF等常用格式的文档信息。
(3)快速响应业务现状的变化,数据库和检索结果即时更新。
(4)系统具备良好的可扩展性和易用性。
1.2系统设计国家级气象信息化业务管理检索系统采用分层设计的思想,划分为4个层次的架构:(1)数据访问层。
在数据访问层的构建上,系统设计采用统一的数据访问接口来实现各类文档数据的统一访问功能,例如数据库的连接管理,数据查询以及数据库事务管理等功能。
(2)数据实体层。
考虑到气象信息业务的复杂性,系统设计以元数据驱动为开发模型,在元数据的基础上进行统一的设计。
数据实体层对文档数据和相应的元数据进行统一存储与管理,并能提供高效的组合查询与检索。
(3)业务逻辑层。
业务逻辑层在整个体系架构中最为关键,具有承上启下的作用,系统设计根据用户的请求生成数据库操作语句,并把结果返回给前段界面显示。
(4)数据表现层。
数据表现层的设计功能主要是对实体数据进行展示,并实现美观易用的展示查询、元数据录入等用户界面。
数据表现层是与用户的交互接口,直接影响到系统的用户体验。
1.3工作流程对于非结构化文档(Word等格式),系统将自动从文档中提取信息,经用户修改、确认后,自动生成该文档的元数据。
对于纸质文档、扫描件等无法自动提取信息的文档,用户需录入相关信息,手动生成该文档的元数据,然后系统将通过统一接口来处理元数据,将元数据和原始文档一并保存到数据组织与管理系统。
同时根据中文词典库和相关分词算法,对元数据内容进行分词,为数据组织与管理系统建立索引。
检索系统将通过用户输入的包含标题、颁布时间、关键字、内容等任一或多种信息组合进行查询,并显示查询结果。
2关键技术2.1基于Lucene 框架设计国家级气象信息化业务管理检索系统的实现是在Lucene<sup>[1,2]</sup>全文本搜索技术框架基础上进行的二次开发。
Lucene是一套使用Java语言编写的开源引擎工具包,提供了可自由扩展的查询引擎、文本分析引擎和索引引擎,近年来逐渐被广泛应用<sup>[38]</sup>。
Lucene的设计目的是提供一个简单易用的全文搜索工具包,以方便在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。
其内部预先定义了索引文件的格式,并提供了面向对象技术程序访问接口。
Lucene的接口主要包括7个模块,以Java包形式提供,每个包完成特定的功能:(1)analysis语言分析器模块。
主要用于语法分析切词,提供对各种文本的切词和过滤功能,将文本解析成词条(Term)的序列。
其对英文支持较好,中文切词能力一般,可以扩展此类。
查询模块(search)利用语言分析器分析查询串,而索引模块(index)则在创建索引时用它分析索引的文档。
(2)document文档管理模块。
用于索引存储时的文档结构管理,对索引的数据描述接口。
(3)index索引管理模块。
包括索引建立、删除等。
索引管理模块负责对索引的读写和解析,是系统的核心部分。
在Lucene中,任何文本资源先经过文档管理模块document变成一个文档,文档是域的组合,再由文本分析模块将索引域的文本分解成一个个的词条,形成包含位置信息的词表,再经过索引管理模块index生成倒排索引(Invested Index),最后由数据存贮模块store写入到全文索引库中。
(4)queryParser查询分析器模块。
实现关键词分析及检索功能,可以对查询关键词间进行运算,如与、或、非及组合操作等。
(5)search检索管理模块。
包括查询结果的管理,根据查询条件,检索得到结果。
查询模块负责在全文索引中搜索,它利用索引模块读取和解析全文索引。
它将用户的查询语句由分析模块分解成一个词表,由查询模块对词表进行解析,解释为许多关键词查询的逻辑组合(与、或等),再由查询模块在索引中匹配基本查询的关键字,得到关键词匹配文档集,然后对关键词匹配文档集结果进行评分并逻辑组合,形成最终的检索结果。
用户输入的查询串先由分析模块分解成一个词表,由查询模块对词表进行解析,形成一组关键词和关键词之间进行组台的查询逻辑(与、或等),再由查询模块在倒排索引中匹配关键词,得到关键词匹配文档集,最后关键词匹配文档集和查询逻辑处理,得到最终的结果文档集。
(6)store数据存贮管理模块。
包括一些底层的文件级操作,提供了对磁盘文件或内存的各种数据结构的读写功能,主要由索引模块使用,向索引模块屏蔽了存贮的底层物理细节。
(7)此外还有util公用工具类。
2.2全文检索流程实现本系统在对Lucene全文检索引擎工具包进行深入剖析的基础上,进行扩展以及二次开发:(1)采用新的中文语言分析器进行中文分词,实现对中英文文档的全文索引。
(2)针对非结构化文档多样性的特点,建立统一的文件非结构化文档处理接口,把各种途径得到的数据源进行处理,转化成统一的、索引器能够理解的通用文档结构。
(3)语言分析器对统一格式的通用文档结构进行分词处理,生成词条序列,供索引模块进行索引。
索引模块读入语言分析器解析文档生成的词表,然后对词表中每个词条进行索引,并将索引结果保存到索引数据库中。
(4)检索模块读入用户的查询,在索引数据库中进行检索,并在把检索到的匹配结果经过排序后返回给用户。
检索模块同时引入同义词和业务词汇词典,提高检索正确率。
2.3数据有效组织形式(1)简单有效的文档目录组织结构。
针对需求,提前开展了文档整编分析,将原始资料以日期、收发类型、文件类型分层目录形式组织,便于文档快速定位和存取。
(2)非结构化文档处理统一接口。
本文系统基于Lucene进行二次开发,对WORD、PDF、HTML、TEXT文件建立针对不同格式的文件解析器,统一转化成索引器能够理解的通用文档结构。
这样做既可以屏蔽文档的不同格式,又可以随时增加新格式的文档。
在程序设计上,只需设计每种格式对应的解析器便可以对各种文件进行索引。
(3)合理有效地组织元数据。
除自身文档内容外,非结构化文档的使用往往还需要其它信息,如数据来源、收发类型、废止时间、有关人员等。
为方便用户快速掌握上述信息,系统内部对每个非结构化文档都配置了一个元数据,用于承载相关信息。
当然,部分非结构化文档自身会具有一定的元数据功能,但是考虑系统的规范性和统一性,本系统统一配置了元数据信息。
3结语本文论述了运用Lucene框架涉及的相关技术,探索了如何运用这些技术帮助用户在非结构化的文档中获取信息的方法,并提供了一套非结构化数据全文检索解决方案。
国家级气象信息化业务管理检索系统作为中国气象局重点推广的新技术项目,已投入测试运行。
系统简洁美观的界面风格、快速的检索响应效率,验证了方案的可行性。
后续工作中,还将继续设计和完善符合气象业务需求的中文分词器和更符合专业要求的评分系统机制。
参考文献:[1]Apache Lucene web site[EB/OL].http:///[2]GOSPODNETIC O,HATCHER E. Lucene IN ACTION [M].中文版.北京:电子工业出版社,2007.[3]邱哲,符滔滔.开发自己的搜索引擎—Lucene 2.0+Heritrix[M].北京:人民邮电出版社,2007.[4]谢峰,刘洪星.基于Lucene的Web站内搜索引擎的研究[J].电脑知识与技术,2008(2):691694.[5]郎小伟,王申康.基于Lucene的全文检索系统研究与开发[J].计算机工程,2006(4):9496.[6]周登朋,谢康林.Lucene搜索引擎[J].计算机工程,2007(18):9596.[7]管建和,甘剑峰.基于Lucene全文检索引擎的应用研究与实现[J].计算机工程与设计,2007(2):489491.[8]葛振国,李建,何林糠,等.基于Lucene的Oracle数据库全文检索[J].信息技术,2010(3):156158.。