统计学基础 第7章简单统计推断(二)假设检验
- 格式:pptx
- 大小:503.29 KB
- 文档页数:31

旗开得胜1第七章 假设检验与方差分析 习题答案一、名词解释用规范性的语言解释统计学中的名词。
1. 假设检验:对总体分布或参数做出某种假设,然后再依据抽取的样本信息,对假设是否正确做出统计判断,即是否拒绝这种假设。
2. 原假设:又叫零假设或无效假设,是待检验的假设,表示为 H 0,总是含有等号。
3. 备择假设:是零假设的对立,表示为 H 1,总是含有不等号。
4. 单侧检验:备择假设符号为大于或小于时的假设检验。
5. 显著性水平:原假设为真时,拒绝原假设的概率。
6. 方差分析:是检验多个总体均值是否相等的一种统计分析方法。
二、填空题根据下面提示的内容,将适宜的名词、词组或短语填入相应的空格之中。
1. u ,nx σμ0-,标准正态; ),(),(2/2/+∞--∞nz nz σσααY2. 参数检验,非参数检验3. 弃真,存伪4. 方差旗开得胜25. 卡方, F6. 方差分析7. t ,u8. nsx 0μ-,不拒绝9. 单侧,双侧10.新产品的废品率为5% ,0.01 11.相关,总变异,组间变异,组内变异12.总变差平方和=组间变差平方和+组内变差平方和 13.连续,离散 14.总体均值 15.因子,水平 16.组间,组内 17.r-1,n-r18. 正态,独立,方差齐三、单项选择从各题给出的四个备选答案中,选择一个最佳答案,填入相应的括号中。
1.B 2.B 3. B 4.A 5.C 6.B 7.C 8.A 9.D 10.A 11.D 12.C四、多项选择从各题给出的四个备选答案中,选择一个或多个正确的答案,填入相应的括号中。
1.AC 2.A 3.B 4.BD 5. AD五、判断改错对下列命题进行判断,在正确命题的括号内打“√”;在错误命题的括号内打“×”,并在错误的地方下划一横线,将改正后的内容写入题下空白处。
1. 在任何情况下,假设检验中的两类错误都不可能同时降低。
( ×)样本量一定时2. 对于两样本的均值检验问题,若方差均未知,则方差分析和t检验均可使用,且两者检验结果一致。



统计学中的假设检验(Hypothesis Testing in Statistics)统计学中的假设检验是一种统计推断方法,用于验证对总体参数或某个结论提出的假设是否是合理的。
它可以用来评估样本数据是否可以支持或反驳特定的假设,从而对研究问题进行分析和决策。
在假设检验中,我们通常提出一个零假设(null hypothesis)和一个备择假设(alternative hypothesis)。
零假设是一种无效假设,即我们认为没有关联或没有差异存在。
备择假设是一种我们希望证明的假设,即存在某种关联或差异。
在进行假设检验时,我们首先收集样本数据。
然后,我们基于这些数据计算一个统计量,该统计量可以用于判断是否可以拒绝零假设。
统计学家们使用最常见的统计量是p值(P-value)。
p值是在给定零假设成立的条件下,观察到结果或更极端结果的概率。
如果p值小于预先设定的显著性水平α(通常为0.05),我们可以拒绝零假设,并接受备择假设。
举例来说,假设我们想要研究某药物对某种疾病的治疗效果。
零假设可以是该药物对治疗效果没有明显影响,备择假设可以是该药物对治疗效果有显著影响。
我们收集了一组患有该疾病的患者,并将其随机分为两组,对其中一组使用药物进行治疗,另一组使用安慰剂进行治疗。
然后,我们比较两组的治疗效果。
通过对比两组的数据,我们可以计算出一个p值。
如果p值小于我们设定的显著性水平α,我们可以拒绝零假设,即药物对治疗效果具有显著影响。
反之,如果p值大于α,我们无法拒绝零假设,即药物对治疗效果没有明显影响。
在假设检验中,还有两种错误可能性:第一类错误和第二类错误。
第一类错误是当真实情况下零假设正确时,我们错误地拒绝了它。
第二类错误是当真实情况下备择假设正确时,我们错误地接受了零假设。
通常,我们在设计假设检验时将第一类错误的概率控制在一个较小的水平上(如0.05),而第二类错误的概率则可能较大。
在实际应用中,假设检验是一种重要的工具,被广泛用于各种领域和学科,如医学研究、社会科学、工程等。

统计推断的基本解法统计推断是统计学的重要分支,用于从样本中推断总体特征。
在统计分析中,我们通常使用一些基础的解法来进行统计推断。
本文将介绍一些常用的基本解法。
点估计点估计是一种基本的统计推断方法,用于估计总体参数的值。
在点估计中,我们通过样本数据得到一个点估计量,作为总体参数的估计值。
例如,常见的点估计方法包括样本均值、样本方差和样本比例等。
区间估计区间估计是一种更精确的统计推断方法,用于估计总体参数的范围。
在区间估计中,我们通过样本数据得到一个区间估计量,包含了总体参数真值的可能范围。
例如,常见的区间估计方法包括置信区间和可信区间等。
假设检验假设检验是一种常用的统计推断方法,用于验证关于总体参数的假设。
在假设检验中,我们首先提出一个原假设和一个备择假设,然后使用样本数据来判断哪个假设更为合理。
例如,常见的假设检验方法包括单样本检验、双样本检验和方差分析等。
相关分析相关分析是一种用于研究变量之间关系的统计推断方法。
在相关分析中,我们通过计算相关系数来衡量变量之间的相关程度。
例如,常见的相关分析方法包括皮尔逊相关系数和斯皮尔曼相关系数等。
回归分析回归分析是一种用于预测和探索变量之间关系的统计推断方法。
在回归分析中,我们使用回归方程来建立变量之间的函数关系,并通过回归系数来解释这种关系。
例如,常见的回归分析方法包括线性回归和逻辑回归等。
综上所述,统计推断的基本解法包括点估计、区间估计、假设检验、相关分析和回归分析等。
这些方法在统计学领域中被广泛应用,帮助我们从样本中推断总体的特征和关系。


统计学重点笔记第一章导论一、比较描述统计和推断统计:数据分析是通过统计方法研究数据,其所用的方法可分为描述统计和推断统计。
(1)描述性统计:研究一组数据的组织、整理和描述的统计学分支,是社会科学实证研究中最常用的方法,也是统计分析中必不可少的一步。
内容包括取得研究所需要的数据、用图表形式对数据进行加工处理和显示,进而通过综合、概括与分析,得出反映所研究现象的一般性特征。
(2)推断统计学:是研究如何利用样本数据对总体的数量特征进行推断的统计学分支。
研究者所关心的是总体的某些特征,但许多总体太大,无法对每个个体进行测量,有时我们得到的数据往往需要破坏性试验,这就需要抽取部分个体即样本进行测量,然后根据样本数据对所研究的总体特征进行推断,这就是推断统计所要解决的问题。
其内容包括抽样分布理论,参数估计,假设检验,方差分析,回归分析,时间序列分析等等。
(3)两者的关系:描述统计是基础,推断统计是主体二、比较分类数据、顺序数据和数值型数据:根据所采用的计量尺度不同,可以将统计数据分为分类数据、顺序数据和数值型数据。
(1)分类数据是只能归于某一类别的非数字型数据。
它是对事物进行分类的结果,数据表现为类别,是用文字来表达的,它是由分类尺度计量形成的。
(2)顺序数量是只能归于某一有序类别的非数字型数据。
也是对事物进行分类的结果,但这些类别是有顺序的,它是由顺序尺度计量形成的。
(3)数值型数据是按数字尺度测量的观察值。
其结果表现为具体的数值,现实中我们所处理的大多数都是数值型数据。
总之,分类数据和顺序数据说明的是事物的本质特征,通常是用文字来表达的,其结果均表现为类别,因而也统称为定型数据或品质数据;数值型数据说明的是现象的数量特征,通常是用数值来表现的,因此可称为定量数据或数量数据。
三、比较总体、样本、参数、统计量和变量:(1)总体是包含所研究的全部个体的集合。
通常是我们所关心的一些个体组成,如由多个企业所构成的集合,多个居民户所构成的集合。



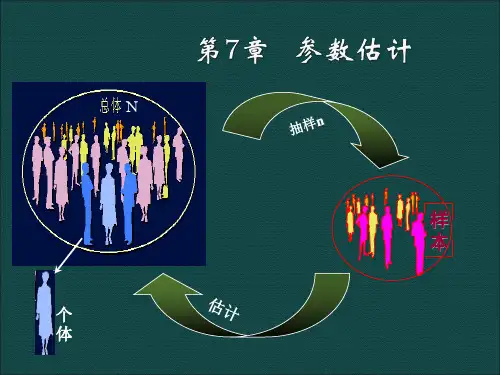
]统计学复习笔记第七章一、思考题1.解释估计量和估计值在参数估计中,用来估计总体参数的统计量称为估计量。
估计量也是随机变量。
如样本均值,样本比例、样本方差等。
根据一个具体的样本计算出来的估计量的数值称为估计值。
2.简述评价估计量好坏的标准"(1)无偏性:是指估计量抽样分布的期望值等于被估计的总体参数。
(2)有效性:是指估计量的方差尽可能小。
对同一总体参数的两个无偏估计量,有更小方差的估计量更有效。
(3)一致性:是指随着样本量的增大,点估计量的值越来越接近被估总体的参数。
3.怎样理解置信区间在区间估计中,由样本统计量所构造的总体参数的估计区间称为置信区间。
置信区间的论述是由区间和置信度两部分组成。
有些新闻媒体报道一些调查结果只给出百分比和误差(即置信区间),并不说明置信度,也不给出被调查的人数,这是不负责的表现。
因为降低置信度可以使置信区间变窄(显得“精确”),有误导读者之嫌。
在公布调查结果时给出被调查人数是负责任的表现。
这样则可以由此推算出置信度(由后面给出的公式),反之亦然。
4.解释95%的置信区间的含义是什么置信区间95%仅仅描述用来构造该区间上下界的统计量(是随机的)覆盖总体参数的概率。
也就是说,无穷次重复抽样所得到的所有区间中有95%(的区间)包含参数。
不要认为由某一样本数据得到总体参数的某一个95%置信区间,就以为该区间以的概率覆盖总体参数。
5.|6.简述样本量与置信水平、总体方差、估计误差的关系。
1.估计总体均值时样本量n为2. 样本量n 与置信水平1-α、总体方差、估计误差E 之间的关系为与置信水平成正比,在其他条件不变的情况下,置信水平越大,所需要的样本量越大;与总体方差成正比,总体的差异越大,所要求的样本量也越大; 与与总体方差成正比,样本量与估计误差的平方成反比,即可以接受的估计误差的平方越大,所需的样本量越小。
)二、 练习题1. 从一个标准差为5的总体中采用重复抽样方法抽出一个样本量为40的样本,样本均值为25。
第七章假设检验第一节二项分布二项分布的数学形式·二项分布的性质第二节统计检验的基本步骤建立假设·求抽样分布·选择显著性水平和否定域·计算检验统计量·判定第三节正态分布正态分布的数学形式·标准正态分布·正态分布下的面积·二项分布的正态近似法第四节中心极限定理抽样分布·总体参数与统计量·样本均值的抽样分布·中心极限定理第五节总体均值和成数的单样本检验σ已知,对总体均值的检验·学生t分布(小样本总体均值的检验)·关于总体成数的检验一、填空1.不论总体是否服从正态分布,只要样本容量n足够大,样本平均数的抽样分布就趋于(正态)分布。
2.统计检验时,被我们事先选定的可以犯第一类错误的概率,叫做检验的( 显著性水平),它决定了否定域的大小。
3.假设检验中若其他条件不变,显著性水平的取值越小,接受原假设的可能性越(大),原假设为真而被拒绝的概率越(小)。
4.二项分布的正态近似法,即以将B(x;n,p)视为N( np ,npq) 查表进行计算。
二、单项选择1.关于学生t分布,下面哪种说法不正确( B )。
A要求随机样本 B 适用于任何形式的总体分布C 可用于小样本D 可用样本标准差S代替总体标准差2.二项分布的数学期望为( C )。
A n(1-n)pB np(1- p)C npD n(1- p)。
3.处于正态分布概率密度函数与横轴之间、并且大于均值部分的面积为( D )。
A大于0.5 B -0.5 C 1 D 0.5。
4.假设检验的基本思想可用( C )来解释。
A中心极限定理 B 置信区间C 小概率事件D 正态分布的性质5.成数与成数方差的关系是(D)。
A成数的数值越接近0,成数的方差越大B 成数的数值越接近0.3,成数的方差越大C 成数的数值越接近1,成数的方差越大D 成数的数值越接近0.5,成数的方差越大6.在统计检验中,那些不大可能的结果称为( D )。
统计学的研究方法——统计推断常常存在这种情况,我们所掌握的数据只是部分单位的数据或有限单位的数据,而我们所关心的却是整个总体甚至是无限总体的数量特征。
例如民意测验谁会当选主席,体育锻炼读增强心脏功能是否有益,某种新药是否提高疗效,全国因而性别比例如何,等等。
这是只靠部分数据的描述是无法获得总体特征的知识。
我们利用统计推断的方法来解决。
所谓统计推断就是以一定的置信标准要求,根据样本数据来判断总体数量特征的归纳推理的方法。
统计推断是逻辑归纳法在统计推的应用。
所以称为归纳推理的方法。
统计推断可以用于总体数量特征的估计,也可以用于对总体某些假设的检验,所以又有不同的推断方法。
(1)参数估计法。
当总体的界限已经划定,总体某一数量特征的数值就是唯一确定的,所以把总体的数量特征称为总体参数。
但是总体参数通常不知道,这就需要通过样本数据计算样本统计量,并以此作为总体参数的估计量来估计总体参数的取值或取值区间,这种方法称为参数估计法。
例如,实割实测若干样本点的粮食产量来推测全区的粮食产量,对若干种选的样本居民户的家庭收支进行经常性的登记,以估计全市居民家庭生活的收支水平等,由于统计分析中经常需要对总体的各项综合指标作出客观的评价,因此参数估计方法在实际工作被广泛地采用。
(2)假设检验法假设检验的特点是,由于对总体的变化情况不了解,不妨相对总体的状况作出某种假设,然后根据样本实际观察的资料对所做假设进行检验,来判断这种假设的真伪,以决定行动的取舍。
例如,工厂生产某种产品,经过工艺改革,不知道产品质量是否有所提高,我们不妨假设工艺改革没有效果,产品质量和以往正常生产的产品质量没有显著性的差异,所有差异仅仅由随机性的原因引起的。
我们从假设为真的前提出发,比较样本指标的实际值和假设的总体参数之间的差异是否超过给定的显著性标准。
如果超过这标准,我们就有理由否定原来的假设,而采纳其对立的假设,即工艺改革是有效的,提高了产品质量,如果差异没有超过显著性标准,则接受原来的假设,即认为公益改革是无效的,产品质量没有显著性提高,假设检验的方法是统计推断常用的方法。
基本统计方法第一章 概论1. 总体(Population):根据研究目的确定的同质对象的全体(集合);样本(Sample):从总体中随机抽取的部分具有代表性的研究对象。
2。
参数(Parameter):反映总体特征的统计指标,如总体均数、标准差等,用希腊字母表示,是固定的常数;统计量(Statistic ):反映样本特征的统计指标,如样本均数、标准差等,采用拉丁字字母表示,是在参数附近波动的随机变量。
3. 统计资料分类:定量(计量)资料、定性(计数)资料、等级资料。
第二章 计量资料统计描述1. 集中趋势:均数(算术、几何)、中位数、众数2。
离散趋势:极差、四分位间距(QR =P 75—P 25)、标准差(或方差)、变异系数(CV )3。
正态分布特征:①X 轴上方关于X =μ对称的钟形曲线;②X =μ时,f (X )取得最大值;③有两个参数,位置参数μ和形态参数σ;④曲线下面积为1,区间μ±σ的面积为68。
27%,区间μ±1.96σ的面积为95.00%,区间μ±2.58σ的面积为99.00%。
4。
医学参考值范围的制定方法:正态近似法:/2X u S α±;百分位数法:P 2。
5-P 97.5.第三章 总体均数估计和假设检验1. 抽样误差(Sampling Error ):由个体变异产生、随机抽样造成的样本统计量与总体参数的差异。
抽样误差不可避免,产生的根本原因是生物个体的变异性.2. 均数的标准误(Standard error of Mean , SEM ):样本均数的标准差,计算公式:/X σσ=3。
降低抽样误差的途径有:①通过增加样本含量n ;②通过设计减少S 。
4。
t 分布特征:①单峰分布,以0为中心,左右对称;②形态取决于自由度ν,ν越小,t 值越分散,t 分布的峰部越矮而尾部翘得越高; ③当ν逼近∞,X S 逼近X σ, t 分布逼近u 分布,故标准正态分布是t 分布的特例。