SPSS两独立样本T检验结果解析.
- 格式:doc
- 大小:197.50 KB
- 文档页数:2

使用SPSS 进行两组独立样本的t检验、F检验、显著性差异、计算p值SPSS版本为SPSS 20.如有以下两组独立的数据,名称分别为“111”,“222”。
111组:4、5、6、6、4222组:1、2、3、7、7首先打开SPSS,输入数据,命名分组,体重和组名要对应,111组的就不要输入到222组了。
数据视图如下:变量视图如下,名称可以改成“分组嗷嗷嗷”“体重喵喵喵”等点击“分析”-“比较均值”-“独立样本T检验”来到这里,分组变量为“分组嗷嗷嗷”,检验变量为“体重喵喵喵”。
【关键的一步】点击分组嗷嗷嗷,进行“定义组”【关键的一步】输入对应的两组数据的组名:“ 111”和“222”点击确定,可见数据与组名对应上了。
点击“确定”,生成T检验的报告,即将大功告成!第一个表都知道什么回事就不缩了,excel都能实现的。
第二个表才是重点,不然用SPSS干嘛。
F检验:在两样本t检验中要用到F检验,F检验又叫方差齐性检验,用于判断两总体方差是否相等,即方差齐性。
如图:F旁边的 Sig的值为.007 即0.007, <0.01, 即两组数据的方差显著性差异!看到“假设方差相等”和“假设方差不相等”了么?此时由于F检验得出Sig <0.01,即认为假设方差不相等!因此只关注红框中的数据即可。
如图,红框内,Sig(双侧),为.490即0.490,也就是你们要求的P值啦,Sig ( 也就是P值 ) >0.05,所以两组数据无显著性差异。
PS:同理,如果F检验的Sig >.05(即>0.05),则认为两个样本的假设方差相等。
所以相应的t检验的结果就看上面那行。
by 20150120 深大医学院 FG。
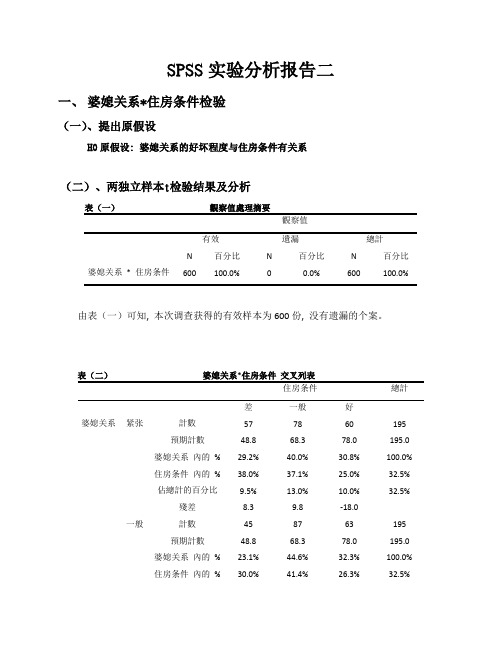
SPSS实验分析报告二一、婆媳关系*住房条件检验(一)、提出原假设H0原假设: 婆媳关系的好坏程度与住房条件有关系(二)、两独立样本t检验结果及分析表(一)觀察值處理摘要觀察值有效遺漏總計N百分比N百分比N百分比婆媳关系* 住房条件600100.0%00.0%600100.0%由表(一)可知, 本次调查获得的有效样本为600份, 没有遗漏的个案。
表(二)婆媳关系*住房条件交叉列表住房条件總計差一般好婆媳关系紧张計數577860195預期計數48.868.378.0195.0婆媳关系內的%29.2%40.0%30.8%100.0%住房条件內的%38.0%37.1%25.0%32.5%佔總計的百分比9.5%13.0%10.0%32.5%殘差8.39.8-18.0一般計數458763195預期計數48.868.378.0195.0婆媳关系內的%23.1%44.6%32.3%100.0%住房条件內的%30.0%41.4%26.3%32.5%佔總計的百分比7.5%14.5%10.5%32.5%殘差-3.818.8-15.0好計數4845117210預期計數52.573.584.0210.0婆媳关系內的%22.9%21.4%55.7%100.0%住房条件內的%32.0%21.4%48.8%35.0%佔總計的百分比8.0%7.5%19.5%35.0%殘差-4.5-28.533.0總計計數150210240600預期計數150.0210.0240.0600.0婆媳关系內的%25.0%35.0%40.0%100.0%住房条件內的%100.0%100.0%100.0%100.0%佔總計的百分比25.0%35.0%40.0%100.0%由表(二)可知, 一共调查了600人, 其中婆媳关系紧张的组有195人, 占总人数的32.5%;婆媳关系一般的组有195人, 占总人数的32.5%;婆媳关系好的组有210人, 占总人数的35.0%;数据分布均匀。

操作方法
01
首先需要输入数据,t检验数据的输入格式为区别为一列,数值为一列。
02
接下是做正态性检验。
首先需要拆分文件,对两组数据分别做检验。
即数据——拆分文件
03
然后点一下比较组,把组别调入分组方式这里,再点击确定。
这样就拆分完毕了。
04
继续点分析——非参数检验——旧对话框——1-样本K-S
05
这样就弹出了正态性检验的对话框,将需要分析的数值调入右边的框框,然后勾选上下方检验分布的第一个,正态(也写为常规,一般默认已经勾上),然后点击确定(数值调入右边后,确定键变为可用)
06
查看结果,第一组的正态性检验P=0.798,第二组为P=0.835,可认为近似正态分布。
07
接着取消拆分。
数据——拆分文件,在跳出来的框框中点一下第一个(分组所有组),然后点确定
08
然后点分析——比较均值——独立样本t检验
09
将组别调入分组变量,数值调入检验变量
10
接着点一下分组变量下方的定义组,在弹出来的框框中输入组别1、2,再点继续——确定
11
结果出来了。
第一个表格是两组数据的例数、均值、标准差和均数的标准误。
第二个表格前部是方差齐性检验,可看到P=0.141>0.05,具有方差齐性,
然后t检验的P值为0.007,可认为差异有统计学意义。

t检验过程,是对两样本均数(mean)差别的显著性进行检验。
惟t检验须知道两个总体的方差(Variances)是否相等;t检验值的计算会因方差是否相等而有所不同。
也就是说,t检验须视乎方差齐性(Equality of Variances)结果。
所以,SPSS在进行t-test for Equality of Means的同时,也要做Levene's Test for Equality of Variances 。
1.在Levene's Test for Equality of Variances一栏中F值为2.36, Sig.为.128,表示方差齐性检验「没有显著差异」,即两方差齐(Equal Variances),故下面t检验的结果表中要看第一排的数据,亦即方差齐的情况下的t检验的结果。
2.在t-test for Equality of Means中,第一排(Variances=Equal)的情况:t=8.892, df=84, 2-Tail Sig=.000, Mean Difference=22.99 既然Sig=.000,亦即,两样本均数差别有显著性意义!3.到底看哪个Levene's Test for Equality of Variances一栏中sig,还是看t-test for Equality of Means中那个Sig. (2-tailed)啊?答案是:两个都要看。
先看Levene's Test for Equality of Variances,如果方差齐性检验「没有显著差异」,即两方差齐(Equal Variances),故接著的t检验的结果表中要看第一排的数据,亦即方差齐的情况下的t检验的结果。
反之,如果方差齐性检验「有显著差异」,即两方差不齐(Unequal Variances),故接著的t检验的结果表中要看第二排的数据,亦即方差不齐的情况下的t检验的结果。

SPSS学习笔记参数检验—两独⽴样本t检验⽬的:利⽤来⾃两个总体的独⽴样本,推断两个总体的均值是否存在差异。
适⽤条件:(1)样本来⾃的总体应服从或近似服从正态分布;(2)两样本相互独⽴,两样本的样本量可以不等;案例分析:案例描述:评价两位⽼师的教学质量,试⽐较其分别任教的甲、⼄两班(设甲、⼄两班原成绩相近,不存在差别)考试后的成绩是否存在差异?(数据来源:《统计分析基础教程》张⽂彤第⼗⼀章)题⽬分析:该问题涉及是两个独⽴样本(教学质量和班级)总体,进⾏总体均值检验,同时总体近似服从正态分布,因此⽤两独⽴样本t检验。
案例步骤:提出原假设:甲、⼄两班考试后的成绩不存在差异,两个⽼师的教学质量⼀样。
界⾯操作步骤:输⼊数据—分析—⽐较均值—独⽴样本t检验—变量设置—输出结果关键步骤截图:分清检验变量和分组变量(分组变量起识别作⽤)点击定义组,填⼊组别各⾃的名称当有些分组变量是数值型的时候,定义组会出现”割点“(烟龄和胆固醇的关系,25可以将烟龄分为>=25和<25两组,具体例⼦见于:《统计分析与SPSS的应⽤》薛薇第五章)结果分析:组统计量班级N均值标准差均值的标准误成绩甲2083.30 6.906 1.544⼄2075.459.179 2.053标准误:;独⽴样本检验⽅差⽅程的 Levene 检验均值⽅程的 t 检验F Sig.t df Sig.(双侧)均值差值标准误差值差分的 95% 置信区间下限上限成绩假设⽅差相等.733.397 3.05638.0047.850 2.569 2.65013.050假设⽅差不相等3.05635.290.0047.850 2.569 2.63713.063分析:F:Levene F检验⽅法,判断两总体的⽅差是否相等?注:假设⽅差相等?假设⽅差不相等?如何决定t检验的t、df、Sig、均值差值……的数值?利⽤F检验⽅法,判断两总体的⽅差是否相等,⽐较F检验⽅法中的p和ɑ(⼀般取0.05);若p>ɑ,则接受原假设(两总体的⽅法⽆显著差异),此时,选择”假设⽅差相等“那⾏的t检验的数据,若p<ɑ,则相反。

在SPSS中利用均数和标准差做两独立样本t检验一、引言在统计学中,两个独立样本t检验被广泛应用于比较两个独立样本的均值是否存在显著差异。
它可以用于各个领域,比如医学、心理学、社会科学等等。
本文将介绍如何使用SPSS软件进行两独立样本t检验,以及如何使用均数和标准差来解读结果。
二、数据准备首先,我们需要准备好两组独立的样本数据。
例如,我们对男性和女性的身高进行比较。
我们需要收集到足够的样本数据,分别记录男性身高和女性身高。
这里我们假设每组数据的样本量相等,并且服从正态分布。
数据准备完毕后,我们可以开始进行两独立样本t检验。
三、SPSS分析步骤1. 打开SPSS软件,新建数据文件,并将收集到的数据录入到不同的变量列中。
确保每列代表一个变量,每行代表一个样本。
2. 点击“分析”选项卡,选择“比较手段”下的“独立样本t检验”。
3. 在弹出的对话框中,将两组独立样本的变量分别拖拽到左右两栏中。
点击“确定”。
4. SPSS会进行假设检验,计算两组样本的均值和标准差,并给出两组样本均值是否有显著差异的判断结果。
同时,SPSS 还会给出相关的统计指标和可视化图表帮助解读结果。
四、结果解释1. 假设检验结果SPSS会给出一个包括假设检验结果的统计表,其中包括两组样本的均值、标准差、t值、自由度、显著性水平等信息。
通过观察显著性水平是否小于设定的显著性水平(通常为0.05),我们可以判断两组样本的均值是否存在显著差异。
如果显著性水平小于设定的显著性水平,我们可以得出结论:两组样本的均值存在显著差异,即可以认为两组样本在某个变量上有不同的表现。
反之,如果显著性水平大于设定的显著性水平,我们则无法准确地判断两组样本的均值是否存在显著差异。
2. 相关统计指标除了假设检验结果,SPSS还会给出两组样本的均值和标准差,以及t值和自由度。
均值表示两组样本的平均水平,标准差代表样本值的差异程度。
t值则表示两组样本均值之差的标准误差,自由度代表样本数据参与构建t统计量的程度。

SPSS两独立样本T检验结果解析SPSS(Statistical Package for the Social Sciences)是一款广泛使用的统计分析软件,可以进行各种复杂的数据分析。
其中,两独立样本T检验是SPSS中的常用统计方法之一、下面将对SPSS进行两独立样本T检验结果进行详细解析。
首先要明确两独立样本T检验的目的是比较两个独立样本之间的平均值是否存在显著差异。
在SPSS中,进行两独立样本T检验的步骤如下:1. 打开数据文件(Data Editor)并导入数据。
3. 在下拉菜单中选择“Independent-Samples T Test”(独立样本T检验)。
4. 将需要进行比较的两个变量移动到“Test Variable List”(测试变量列表)中。
5.点击“OK”进行分析。
对于两独立样本T检验的结果解析,主要关注以下几个方面的内容:1. 描述统计(Descriptive Statistics):此部分显示了两个样本的基本统计信息,包括平均值(Mean)、标准差(Standard Deviation)等。
通过比较两个样本的均值可以初步判断是否存在差异。
2. 独立样本T检验(Independent Samples Test):此部分给出了两独立样本T检验的结果。
主要包括t值(t),自由度(df),显著性水平(Sig.)和均值差(Mean Difference)等。
其中,t值用于判断两个样本均值之间的差异是否显著,自由度表示模型中自由变量的约束条件的数量。
显著性水平表示差异的统计显著程度,一般选择显著性水平为0.05,即p值小于0.05时,差异是显著的。
均值差可以用来衡量两个样本之间的差异的大小。
3. Levene's Test for Equality of Variances(Levene方差齐性检验):此部分用于判断两个样本的方差是否相等。
若显著性水平小于0.05,则认为两个样本的方差不相等,这将影响到独立样本T检验的结果。

两独立样本T检验SPSS操作详解以下是步骤详解:1.打开SPSS软件,并导入数据文件。
在“文件”菜单中选择“打开”选项,浏览并选择你的数据文件,并点击“打开”。
数据文件需要包含两组要比较的两个变量。
2.选择菜单中的“分析”选项,然后选择“比较均值”子选项,再选择“独立样本T检验”。
3.在弹出的独立样本T检验对话框中,将你要比较的两个变量移动到变量框中。
其中一个变量移动到“依赖变量”框中,另一个变量移动到“提取组变量”框中。
4.点击“定义组”按钮,在出现的对话框中输入两个组的编号,并点击“添加”按钮。
然后关闭“定义组”对话框。
5.在独立样本T检验对话框中,确定其他参数,如显著性水平(默认为0.05)和描述统计量选项。
6.点击“确定”按钮运行分析。
SPSS将计算出两组的均值、标准差、样本大小等统计量,并给出T值、自由度和显著性水平。
7.分析结果将显示在输出窗口的“独立样本T检验”表中。
主要关注的结果包括均值差异、T值、自由度和显著性水平。
8.可以根据需要导出分析结果。
在输出窗口中选择你感兴趣的表格或图表,然后在菜单中选择“文件”选项,再选择“另存为”选项,将分析结果保存为你想要的格式。
需要注意的是,在进行两独立样本T检验之前,要确保数据满足T检验的假设:两组样本是独立的、来自正态分布总体和方差齐性。
如不满足这些假设,可以考虑使用非参数检验或进行数据转换。
此外,对于SPSS软件的具体操作细节可能会因软件版本而有些差异,但基本的步骤和参数设置是相同的。
以上就是两独立样本T检验SPSS操作的详解。
通过SPSS软件进行数据分析可以更方便地得到结果,并为研究者提供科学依据。

spss中有关独立样本T检验的详细介绍包含操作过程和结果分析分析>比较平均值3.独立样本T检验独立样本T检验类似于单样本T检验,不过独立样本T检验的内容比单样本T检验要复杂的多,特别是对其结果的分析,而独立样本T检验被使用的情况也比单样本T检验更广泛(因此也可以看到网络上关于独立样本T检验的文章远比关于单样本T检验的文章多)对比:二者都是将数据的平均值进行比较,不同之处在于单样本T检验是将一个样本与某一特定值进行对比,而独立样本T检验是对多个样本之间的平均值进行对比。
独立样本是指进行对比的多个样本之间是相互独立、互不干扰的,通过独立样本T检验我们可以判断多个样本之间的平均值是否可以认为是相等的。
没有什么比举个例子更容易理解独立样本T检验的用途了:假如我们有两个样本,分别是来自农村和城市两个不同地方的人们的身高数据,我们的目的是探讨农村和城市的差异会不会给当地的人们带来身高上的影。
这时我们算出城市的人群的平均身高为168.38cm,而农村的人们的平均身高为164.58cm,二者差了3.8cm,那我们是否就可以认为这3.8cm就可以很好的说明农村和城市的人们身高有差异呢?那如果是差了3cm呢?如果是差了1cm呢?这种时候就不可以单靠感觉来评判了,而是应该使用独立样本T检验来帮助我们判断得出结论检验变量——需要进行平均值比较的数据分组变量——用于区分不同样本的变量选项——选择置信区间百分比以及缺失值的处理方法对于分组变量我们操作时需要注意一下,在我们选入了分组变量后,我们必须要对其进行定义组操作,因为SPSS无法自行判断如何通过分组变量对数据进行分组点击定义组我们有两种分类的方法,分别是使用指定的值与分割点,指定值就是将所有分类变量等于该输入的数值的样本划分为一组,分割点就是以该输入的数值为分割点划分出大于和小于该值的两组进行比较,这些都是很简单的,不多废话了~~接下来就是重头戏了——对结果的分析简洁解释:得到结果后,首先将独立样本检验表格中莱文方差等同性检验的显著性数值与0.05进行比较大于0.05,两组假定等方差,看第一行数据的显著性(双尾)数值,如果大于0.05,两组差异不显著;如果小于0.05,两组差异显著;小于0.05,两组不假定等方差,看第二行数据的显著性(双尾)数值,如果大于0.05,两组差异不显著;如果小于0.05,两组差异显著。

SPSS中,进⾏两独⽴样本T检验•两独⽴样本T检验的⽬的是利⽤来⾃两个正态总体的独⽴样本,推断两个总体的均值是否存在显著差异。
区别于配对样本T检验,独⽴样本T检验是来⾃两个独⽴样本,或者被同⼀样本数据的⼆分类变量分配的两个样本;配对样本是同⼀样本数据,不同环境。
⼀、验证两独⽴样本数据是否符合正态分布(分析-描述统计-探索),若不符合对数据进⾏处理,若符合进⾏第⼆步;关注正态分布结果:(1)单样本的K-S检验是⽤来检验⼀个数据的观测经验分布是否是已知的理论分布。
当两者间的差距很⼩时,推断该样本取⾃已知的理论分布。
作为零假设的理论分布⼀般是⼀维连续分布 F(如正态分布、均匀分布、指数分布等),有时也⽤于离散分布(如Poisson分布)。
即H0:总体X 服从某种⼀维连续分布 F。
检验统计量为:(2)Shapiro—Wilk检验法是S.S.Shapiro与M.B.Wilk提出⽤顺序统计量W来检验分布的正态性。
统计量:H0:总体服从正态分布(3)两种检验的选择:•样本量⼩于2000时看shapiro-wilk的检验结果,精度⾼。
•kolmogorov-smimov适合⼤样本,⼀般⼤于2000。
•对于此两种检验,如果P值⼤于0.05,没有理由说样本数据不服从正态分布。
•由下表得出结论:三国样本数据中,⽂官和武将两类数据均服从正态分布,可以进⾏两独⽴样本T检验⼆、分析-⽐较均值-两独⽴样本T检验;选项-置信⽔平;定义组-输⼊分类数据;三、输出结果;第⼀步:下表可以看出,⽂官和武将之间武⼒的样本平均值很⼤的差距。
通过假设检验应推断这种差异是抽样误差造成的还是系统性的。
第⼆步:First,两总体⽅差是否相等的F检验。
这⾥,该检验的F统计量的观测值为42.595,对应的概率P-值为0.000。
在0.05显著性⽔平下,由于概率P-值⼩于0.05,可以认为两总体的⽅差有显著差异,即两总体⽅差是不相等的。
原假设:⽅差相等。

SPSS两独立样本T检验结果解析SPSS中的两独立样本T检验是一种用于比较两个独立样本均值是否存在显著差异的统计方法。
在进行T检验时,SPSS会提供多个结果和统计指标,以下将对这些结果进行详细解析。
1.描述统计:首先,SPSS提供了每个样本的基本统计描述,包括样本均值(Mean)、标准差(Standard Deviation)、样本大小(N)等。
这些统计指标可以帮助我们了解样本的基本情况,并对比两个样本的差异。
2.正态性检验:T检验的前提是两个样本都满足正态分布。
SPSS会进行正态性检验,提供Shapiro-Wilk和Kolmogorov-Smirnov两种方法。
若p值大于显著性水平(通常是0.05),则我们可以认为数据满足正态分布假设;若p值小于显著性水平,则我们需谨慎解释数据结果,并可以采用非参数检验方法。
3.方差齐性检验:T检验还要求两个样本的方差齐性。
SPSS提供Levene's Test和Brown-Forsythe两种方差齐性检验方法。
若p值大于显著性水平,我们可以认为两个样本具有方差齐性;若p值小于显著性水平,则需要调整我们对于T检验结果的解释,例如使用修正的T检验方法。
4.独立样本T检验结果:SPSS提供了多个独立样本T检验的结果,包括T值、自由度、双侧p 值、置信区间等。
其中T值表示两个样本均值之间的差异是否显著,自由度用于计算T分布的临界值,p值则用于判断差异是否具有统计学意义,置信区间则给出了均值差异的范围估计。
通常,p值小于显著性水平(例如0.05)可以认为两个样本的均值存在显著差异。
5.效应量指标:除了上述的结果,SPSS还提供了一些效应量指标,可以帮助评估均值差异的大小。
其中,Cohen's d是一种常用的效应量指标,表示两个样本均值差异的标准化大小。
Cohen's d的值越大,表示两个样本的均值差异越大。
6.异常值和离群值:最后,SPSS还可以通过箱线图和散点图等方法帮助我们检查两个样本中是否存在异常值或离群值。


spss两独立样本t检验结果解析SPSS是一款非常常用的统计分析软件,它适用于不同领域的全部用户。
SPSS统计软件不仅可以完成数据录入、数据清洗等简单操作,还可以完成数据分析、数据挖掘等复杂的操作。
在进行SPSS两独立样本t检验之前,我们需要了解两个样本的数据情况以及两组数据是否满足t检验的前提条件。
两独立样本t检验的前提条件为:1. 两样本各自服从正态分布。
2. 两样本方差相等(方差齐性)。
下面我们来看一下SPSS两独立样本t检验的结果解析。
首先,我们要在SPSS中输入两组数据,造成数据如下:组别得分组1 85、90、88、75、92、80组2 85、95、75、70、88、82第一步打开SPSS软件后,点击运行拦,然后选择“t检验单样本均数的文件”,进入t检验对话框。
第二步在t检验对话框中选择两独立样本t检验选项。
在窗口中,输入变量对,也就是需要比较的两组数据的变量名。
在本例中,变量对为“得分”和“组别”。
第三步在t检验对话框的“选项”标签页中,选择检验方向和置信区间。
选择一个置信度,通常选择95%或99%。
第四步点击“确定”按钮运行SPSS两独立样本t检验。
运行完成后,我们将获得以下输出:【IMG】输出的表格中包含了两个主要的部分:汇总信息(Summary Information)和检验结果(Test Results)。
检验结果中包括统计量(t值)、自由度(df)和p值。
这些统计量可以用来决定是否拒绝零假设,即两个样本的均值相等。
在本例中,t=1.025,df=10,p=0.325。
根据p值大于0.05,我们不能拒绝零假设,即两组样本的均值可能是相等的。
因为本数据的p值大于0.05,在这个置信度下,我们不能否定零假设,即不能得出两组数据的平均值不同。
因此,可以根据结果推断,“得分”在两个组别之间没有显著差异。
综上述,我们已经学会了如何进行SPSS两独立样本t检验,以及如何解析结果。
在SPSS中使用两独立样本t检验可以让我们更快、更方便地了解两个样本的差异,这对于许多研究者来说非常相关。


在SPSS中利用均数和标准差做两独立样本t检验在SPSS中利用均数和标准差做两独立样本t检验统计学中的t检验是一种经典的假设检验方法,广泛应用于研究中两个独立样本的均值是否存在显著差异。
而SPSS (Statistical Package for the Social Sciences)是一款能够进行统计数据分析的专业软件,它提供了方便快捷进行t检验的功能。
本文将详细介绍在SPSS中如何通过均数和标准差进行两独立样本t检验。
首先,我们需要准备两组独立的样本数据。
假设我们正在研究两种不同疗法对患者疼痛程度的影响,我们随机选择了100名患者,将他们分为两组,分别接受疗法A和疗法B,然后记录他们的疼痛程度数据。
接下来,我们打开SPSS软件,并导入我们准备好的数据。
在菜单栏中选择“文件(File)”,然后选择“导入(Import)”,再选择“数据(Data)”。
然后我们选择我们的数据文件,并点击“打开(Open)”按钮,我们的数据将会被导入到SPSS中。
在导入数据后,我们需要检查数据的质量和健康程度。
我们可以使用SPSS的描述性统计功能,来获取样本的均值和标准差。
首先,选择菜单栏中的“分析(Analyse)”,然后选择“描述统计(Descriptive Statistics)”,再选择“统计(Statistics)”。
在弹出的对话框中勾选“平均值(Mean)”和“标准差(Standard Deviation)”,然后点击“确定(OK)”按钮。
SPSS将会生成两组样本的均值和标准差信息。
在获得两组样本的均值和标准差之后,我们可以进行两独立样本t检验来检验两组样本均值是否存在显著差异。
可以使用SPSS的独立样本t检验功能来进行分析。
选择菜单栏中的“分析(Analyse)”,然后选择“比较手段(Compare Means)”,再选择“独立样本t检验(Independent-Samples T Test)”。
在弹出的对话框中,选择我们的两组样本数据,点击“变量(Variables)”按钮,将我们的自变量和因变量添加到列表中。

定量分析之两独立样本T检验(2007-04-01 22:26:38)由输出结果可以看出:样本中区域编号为1(即苏南地区)的城市有5个。
其地区生产总值的平均值为1928.3540亿元,标准差为1059.98148,均值标准误差为474.03813。
人均GDP的平均值为40953.40元,标准差为13391.301,均值标准误差为5988.772。
样本中区域编号为2(即苏中地区)的城市有3个。
其地区生产总值的平均值为906.4633亿元,标准差为279.86759,均值标准误差为161.58163。
人均GDP的平均值为15726.33元,标准差为1673.922,均值标准误差为966.440。
由输出结果可以看到:对于地区生产总值来说,F值为2.574,相伴概率为0.160,大于显著性水平0.05,不能拒绝方差相等的假设,可以认为苏南和苏中的地区生产总值方差无显著差异;然后看方差相等时T检验的结果,T统计量的相伴概率为0.167,大于显著性水平0.05,不能拒绝T检验的零假设,也就是说,苏南和苏中两个地区城市生产总值平均值不存在显著差异。
另外从样本的均值差的95%置信区间看,区间跨0,这也说明两个地区生城市生产总值的平均值无显著差异。
对于人均GDP来说,F值为24.266,相伴概率为0.003,小于显著性水平0.05,拒绝方差相等的假设,可以认为苏南和苏中地区城市人均GDP方差存在显著差异;然后看方差不相等时T检验的结果,T统计量的相伴概率为0.013小于显著性水平0.05,拒绝T检验的零假设,也就是说,苏南和苏中两个地区城市人均GDP平均值存在显著差异。
另外从样本的均值差的95%置信区间看,区间没有跨0,这也说明两个地区城市人均GDP平均值存在显著差异。


SPSS知识3t检验(两个总体均数比较)t检验前言:一、t检验有3种:单样本t检验、配对样本t检验、两组独立样本t检验。
二、t检验条件:数据资料服从正态或近似正态分布。
两组独立样本t检验还要求两组方差齐(不齐则要进行校正)。
正文:一、单样本t检验理论:单样本t检验是检验样本均数X和总体均数μ【已知的理论值(如脉搏72)、标准值或公认值】的比较。
T=(样本均数-总体均数)/样本均数的标准误Spss操作:前提:建立数据库(一列变量)第一步:正态性检验Analyze→Npar tests→1-sample K-S→数据调入右框(test variable list),选中Test Distribution中的normal→OK。
第二步:看output,判断数据资料正态性与否。
看统计量Z 和P值。
P>0.05,资料正态分布。
第三步:t检验。
正态性,则进行样本均数与总体均数的比较,即单样本t检验。
Analyze→compare means→one-sample T test→将数据调入右框(test variable),在右框下的Test Value右边框中输入总体均数μ→OK第四步:看output中的P值,判断差异是否有统计学意义。
P>0.05,差异无统计学意义。
二、配对样本t检验理论:配对设计有3种情况:1、同一样本分为2份,用2种不同的方法测定;2、自身比较,同一样本处理前后的比较(处理前后的过程中,应保持其他非处理因素的齐同性,并且处理周期不宜太长;3、将某些因素相同的样本组成配伍组,随即分为两组。
T=每一配对的测量值之差的均数/每一配对的测量值之差的均数的标准误。
(各自公式见理论)Spss操作:前提:建立数据库(两列:如before和after)第一步:两组数据做正态性检验Analyze→Npar tests→1-sample K-S→两组数据皆调入右框(test variable list),选中Test Distribution中的normal →OK。

SPSS-比较均值-独立样本T检验案例解析2011-08-26 14:55在使用SPSS进行单样本T检验时,很多人都会问,如果数据不符合正太分布,那还能够进行T检验吗?而大样本,我们一般会认为它是符合正太分布的,在鈡型图看来,正太分布,基本左右是对称的,一般具备两个参数,数学期望和标准方差,即:N(p, Q)如果你的样本数非常少,一般需要进行正太分布检验,检验的方法网上很多,我就不说了下面以“雄性老鼠和雌性老鼠分别注射了某种毒素,经过观察分析,进行随机取样,查看最终老鼠是否活着。
问题:很多人认为,雄性老鼠和雌性老鼠分别注射毒液后,雌性老鼠存活下来的数量会比雄性老鼠多?我们将通过进行统计分析来认证这个假设是否成立。
下面进行参数设置:a 代表:雄性老鼠b代表:雌性老鼠tim 代表:生存时间,即指经过多长时间后,去查看结果0 代表:结果死亡1 代表:结果活着随机抽取的样本,如下所示:打开SPSS- 分析---检验均值---独立样本T检验,如下图所示:将你要分析的变量,移入右边的框内,再将你要进行分组的变量移入“分组变量”框内,“组别group()里面的两个参数,不能够随意设置,必须要跟样本里面的数字一致点击确定后,分析结果,如下所示:从组统计量可以看出,雄性老鼠的存活下来的均值为0.73,但是雌性老鼠存活下来的均值为1.00,很明显,雌性老是存活下来的个数明显比雄性老鼠多,但是一般我们不看这个结果,为什么?因为样本不够大,如果将样本升至10000个?也许这个均值将会发生变化,不具备统计学意义,我们一般只看独立样本检验的结果。
独立样本检验,提供了两种方法:levene检验和均值T检验两种方法Levene检验主要用来检验原假设条件是否成立,(即:假设方差相等和方差不相等两种情况)如果SIG>0.05,证明假设成立,不能够拒绝原假设,如果SIG<0.05,证明假设不成立,拒绝原假设。
进行levene检验结果判断是第一步,从上图,可以看出 sig<0.05 方差相等的假设不成立,所以看第二行,方差不相等的情况sig=0.082>0.05 即说明 P 值大于显著性水平,不应该拒绝原假设:即指:雌性老鼠和雄性老鼠在注射毒液后,存活下来的个数没有显著的差异本次分析的结果,不支持,很多人认为的:雄性老鼠和雌性老鼠分别注射毒液后,雌性老鼠存活下来的数量会比雄性老鼠多的结论。
定量分析之两独立样本T检验
(2007-04-01 22:26:38)
由输出结果可以看出:
样本中区域编号为1(即苏南地区)的城市有5个。
其地区生产总值的平均值为1928.3540亿元,标准差为1059.98148,均值标准误差为474.03813。
人均GDP的平均值为40953.40元,标准差为13391.301,均值标准误差为5988.772。
样本中区域编号为2(即苏中地区)的城市有3个。
其地区生产总值的平均值为906.4633
亿元,标准差为279.86759,均值标准误差为161.58163。
人均GDP的平均值为15726.33元,标准差为1673.922,均值标准误差为966.440。
由输出结果可以看到:
对于地区生产总值来说,F值为2.574,相伴概率为0.160,大于显著性水平0.05,不能拒绝方差相等的假设,可以认为苏南和苏中的地区生产总值方差无显著差异;然后看方差相等
时T检验的结果,T统计量的相伴概率为0.167,大于显著性水平0.05,不能拒绝T检验的零假设,也就是说,苏南和苏中两个地区城市生产总值平均值不存在显著差异。
另外从样本的均值差的95%置信区间看,区间跨0,这也说明两个地区生城市生产总值的平均值无显著差异。
对于人均GDP来说,F值为24.266,相伴概率为0.003,小于显著性水平0.05,拒绝方差相等的假设,可以认为苏南和苏中地区城市人均GDP方差存在显著差异;然后看方差不相等时T检验的结果,T统计量的相伴概率为0.013小于显著性水平0.05,拒绝T检验的零假设,也就是说,苏南和苏中两个地区城市人均GDP平均值存在显著差异。
另外从样本的均值差的95%置信区间看,区间没有跨0,这也说明两个地区城市人均GDP平均值存在显著差异。