薛薇第四版SPSS第五章
- 格式:ppt
- 大小:1.62 MB
- 文档页数:22
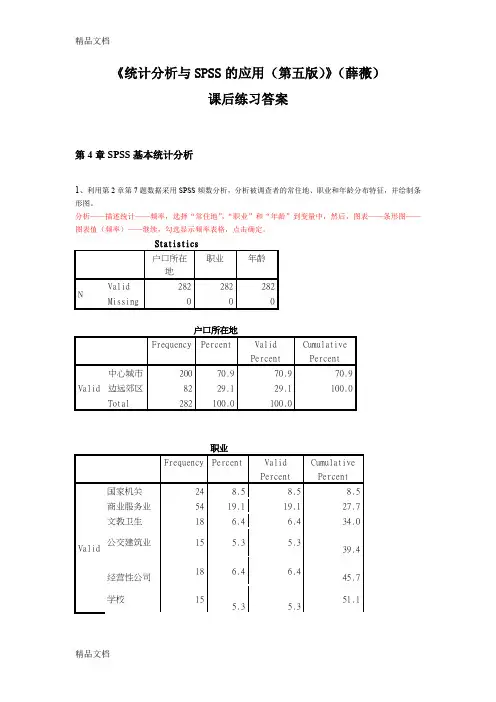
《统计分析与SPSS的应用(第五版)》(薛薇)课后练习答案第4章SPSS基本统计分析1、利用第2章第7题数据采用SPSS频数分析,分析被调查者的常住地、职业和年龄分布特征,并绘制条形图。
分析——描述统计——频率,选择“常住地”,“职业”和“年龄”到变量中,然后,图表——条形图——图表值(频率)——继续,勾选显示频率表格,点击确定。
Statistics户口所在地职业年龄N Valid 282 282 282Missing 0 0 0户口所在地Frequency Percent ValidPercentCumulativePercentValid 中心城市200 70.9 70.9 70.9 边远郊区82 29.1 29.1 100.0 Total 282 100.0 100.0职业Frequency Percent ValidPercentCumulativePercentValid 国家机关24 8.5 8.5 8.5 商业服务业54 19.1 19.1 27.7 文教卫生18 6.4 6.4 34.0公交建筑业15 5.3 5.339.4 经营性公司18 6.4 6.445.7学校155.3 5.351.1一般农户3512.4 12.4 63.5 种粮棉专业户4 1.4 1.4 64.9 种果菜专业户10 3.5 3.5 68.4 工商运专业户34 12.1 12.1 80.5 退役人员17 6.0 6.0 86.5 金融机构35 12.4 12.4 98.9现役军人 3 1.11.1 100.0Total 282 100.0 100.0年龄Frequency Percent ValidPercent Cumulative PercentValid 20岁以下 4 1.4 1.4 1.4 20~35岁146 51.8 51.8 53.2 35~50岁91 32.3 32.3 85.5 50岁以上41 14.5 14.5 100.0 Total 282 100.0 100.0分析:本次调查的有效样本为282份。

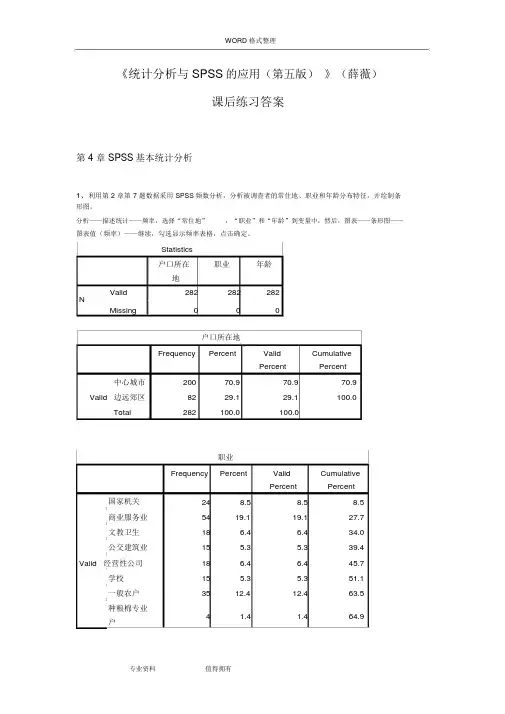
WORD 格式整理《统计分析与SPSS的应用(第五版)》(薛薇)课后练习答案第 4 章 SPSS基本统计分析1、利用第2章第7题数据采用SPSS频数分析,分析被调查者的常住地、职业和年龄分布特征,并绘制条形图。
分析——描述统计——频率,选择“常住地”,“职业”和“年龄”到变量中,然后,图表——条形图——图表值(频率)——继续,勾选显示频率表格,点击确定。
Statistics户口所在职业年龄地Valid282282282NMissing000户口所在地Frequency Percent Valid CumulativePercent Percent中心城市20070.970.970.9 Valid 边远郊区8229.129.1100.0Total282100.0100.0职业Frequency Percent Valid CumulativePercent Percent 国家机关248.58.58.5商业服务业5419.119.127.7文教卫生18 6.4 6.434.0公交建筑业15 5.3 5.339.4Valid 经营性公司18 6.4 6.445.7学校15 5.3 5.351.1一般农户3512.412.463.5种粮棉专业4 1.4 1.464.9户WORD 格式整理种果菜专业10 3.5 3.568.4户工商运专业3412.112.180.5户退役人员17 6.0 6.086.5金融机构3512.412.498.9现役军人3 1.1 1.1100.0Total282100.0100.0年龄Frequency Percent Valid CumulativePercent Percent20 岁以下4 1.4 1.4 1.420~35 岁14651.851.853.2 Valid 35~50 岁9132.332.385.550 岁以上4114.514.5100.0Total282100.0100.0分析:本次调查的有效样本为282 份。
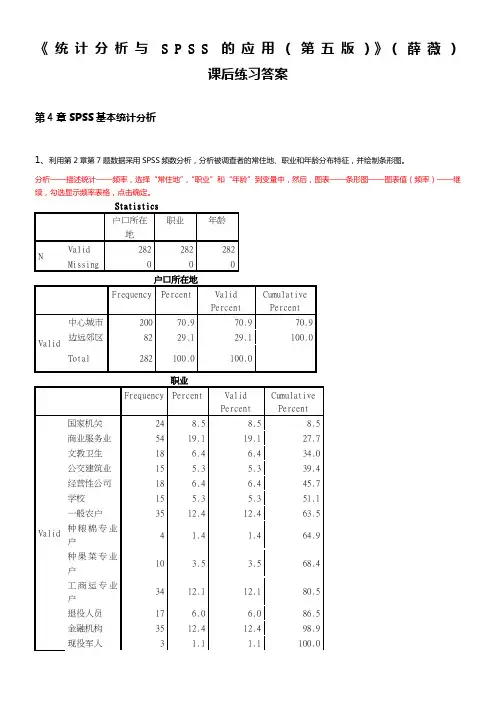
《统计分析与S P S S的应用(第五版)》(薛薇)课后练习答案第4章SPSS基本统计分析1、利用第2章第7题数据采用SPSS频数分析,分析被调查者的常住地、职业和年龄分布特征,并绘制条形图。
分析——描述统计——频率,选择“常住地”,“职业”和“年龄”到变量中,然后,图表——条形图——图表值(频率)——继续,勾选显示频率表格,点击确定。
Statistics户口所在地职业年龄N Valid 282 282 282Missing 0 0 0户口所在地Frequency Percent ValidPercentCumulativePercentValid 中心城市200 70.9 70.9 70.9 边远郊区82 29.1 29.1 100.0Total 282 100.0 100.0职业Frequency Percent ValidPercentCumulativePercentValid 国家机关24 8.5 8.5 8.5 商业服务业54 19.1 19.1 27.7 文教卫生18 6.4 6.4 34.0 公交建筑业15 5.3 5.3 39.4 经营性公司18 6.4 6.4 45.7 学校15 5.3 5.3 51.1 一般农户35 12.4 12.4 63.5 种粮棉专业户4 1.4 1.4 64.9 种果菜专业户10 3.5 3.5 68.4 工商运专业户34 12.1 12.1 80.5 退役人员17 6.0 6.0 86.5 金融机构35 12.4 12.4 98.9 现役军人 3 1.1 1.1 100.0Total 282 100.0 100.0年龄Frequency PercentValid PercentCumulative PercentValid20岁以下 4 1.4 1.4 1.4 20~35岁146 51.8 51.8 53.2 35~50岁 91 32.3 32.3 85.5 50岁以上 41 14.5 14.5 100.0Total282100.0100.0分析:本次调查的有效样本为282份。

《统计分析与SPSS的应用(第五版)》(薛薇)课后练习答案第5章SPSS的参数检验1、某公司经理宣称他的雇员英语水平很高,如果按照英语六级考试的话,一般平均得分为75分。
现从雇员中随机选出11人参加考试,得分如下: 80, 81, 72, 60, 78, 65, 56, 79, 77,87, 76 请问该经理的宣称是否可信。
原假设:样本均值等于总体均值即u=u0=75步骤:生成spss数据→分析→比较均值→单样本t检验→相关设置→输出结果(Analyze->compare means->one-samples T test;)采用单样本T检验(原假设H0:u=u0=75,总体均值与检验值之间不存在显著差异);分析:指定检验值:在test后的框中输入检验值(填75),最后ok!分析:N=11人的平均值(mean)为73.7,标准差(std.deviation)为9.55,均值标准误差(std error mean)为2.87.t统计量观测值为-4.22,t统计量观测值的双尾概率p-值(sig.(2-tailed))为0.668,六七列是总体均值与原假设值差的95%的置信区间,为(-7.68,5.14),由此采用双尾检验比较a和p。
T统计量观测值的双尾概率p-值(sig.(2-tailed))为0.668>a=0.05所以不能拒绝原假设;且总体均值的95%的置信区间为(67.31,80.14),所以均值在67.31~80.14内,75包括在置信区间内,所以经理的话是可信的。
2、在某年级随机抽取35名大学生,调查他们每周的上网时间情况,得到的数据如下(单位:小时):(1)请利用SPSS对上表数据进行描述统计,并绘制相关的图形。
(2)基于上表数据,请利用SPSS给出大学生每周上网时间平均值的95%的置信区间。
(1)分析描述统计描述、频率(2)分析比较均值单样本T检验每周上网时间的样本平均值为27.5,标准差为10.7,总体均值95%的置信区间为23.8-31.2.3、经济学家认为决策者是对事实做出反应,不是对提出事实的方式做出反应。


《统计分析与SPSS的应用(第五版)》(薛薇)课后练习答案第2章SPSS数据文件的建立和管理1、SPSS中有哪两种基本的数据组织形式?各自的特点和应用场合是什么?SPSS中两个基本的数据组织方式:原始数据的组织方式和计数数据的组织方式。
●原始数据的组织方式:待分析的数据是一些原始的调查问卷数据,或是一些基本的统计指标。
●计数数据的组织方式:所采集的数据不是原始的调查问卷数据,而是经过分组汇总后的数据。
2、什么是SPSS的个案?什么SPSS的变量?个案:在原始数据的组织方式中,数据编辑器窗口中的一行称为一个个案或观测。
变量:数据编辑器窗口中的一列。
3、在定义SPSS数据结构时,默认的变量名和变量类型是什么?如果希望增强SPSS统计分析结果的易读性,还需要对数据结构的哪些方面进行必要说明?默认的变量名:VAR------;默认的变量类型:数值型。
变量名标签和变量值标签可增强统计分析结果的可读性。
4、收集到以下关于两种减肥产品试用情况的调查数据,请问在SPSS中应如何组织该份资料?体重变化情况产品类型明显减轻无明显变化第一种产品27 19第二种产品20 33问:在SPSS中应如何组织该数据?数据文件如图所示:5、什么是SPSS的用户缺失值?为什么要对用户缺失值进行定义?如何在SPSS中指定用户缺失值?缺失值分为用户缺失值(User Missing Value)和系统缺失值(System Missing Value)。
用户缺失值指在问卷调查中,将无回答的一些数据以及明显失真的数据当作缺失值来处理。
用户缺失值的编码一般用研究者自己能够识别的数字来表示,如“0”、“9”、“99”等。
系统缺失值主要指计算机默认的缺失方式,如果在输入数据时空缺了某些数据或输入了非法的字符,计算机就把其界定为缺失值,这时的数据标记为一个圆点“•”。
在变量视图中定义。
6、从计量尺度角度看,变量包括哪三种主要类型?请各举出一个相应的实际数据。
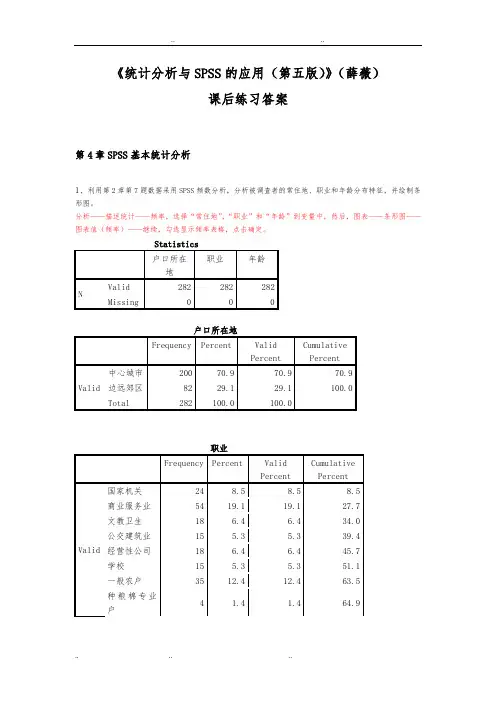
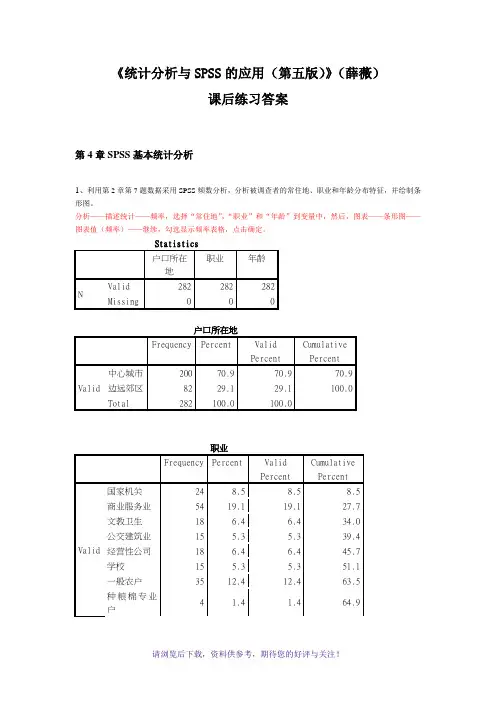
《统计分析与SPSS的应用(第五版)》(薛薇)课后练习答案第4章SPSS基本统计分析1、利用第2章第7题数据采用SPSS频数分析,分析被调查者的常住地、职业和年龄分布特征,并绘制条形图。
分析——描述统计——频率,选择“常住地”,“职业”和“年龄”到变量中,然后,图表——条形图——图表值(频率)——继续,勾选显示频率表格,点击确定。
Statistics户口所在地职业年龄N Valid 282 282 282Missing 0 0 0户口所在地Frequency Percent ValidPercentCumulativePercentValid 中心城市200 70.9 70.9 70.9 边远郊区82 29.1 29.1 100.0 Total 282 100.0 100.0职业Frequency Percent ValidPercentCumulativePercentValid 国家机关24 8.5 8.5 8.5 商业服务业54 19.1 19.1 27.7 文教卫生18 6.4 6.4 34.0 公交建筑业15 5.3 5.3 39.4 经营性公司18 6.4 6.4 45.7 学校15 5.3 5.3 51.1 一般农户35 12.4 12.4 63.5 种粮棉专业户4 1.4 1.4 64.9种果菜专业户10 3.5 3.5 68.4 工商运专业户34 12.1 12.1 80.5 退役人员17 6.0 6.0 86.5 金融机构35 12.4 12.4 98.9 现役军人 3 1.1 1.1 100.0 Total 282 100.0 100.0年龄Frequency Percent ValidPercent Cumulative PercentValid 20岁以下 4 1.4 1.4 1.4 20~35岁146 51.8 51.8 53.2 35~50岁91 32.3 32.3 85.5 50岁以上41 14.5 14.5 100.0 Total 282 100.0 100.0分析:本次调查的有效样本为282份。
《统计分析与SPSS的应用(第五版)》(薛薇)课后练习答案第4章SPSS基本统计分析1、利用第2章第7题数据采用SPSS频数分析,分析被调查者的常住地、职业和年龄分布特征,并绘制条形图。
分析——描述统计——频率,选择“常住地”,“职业”和“年龄”到变量中,然后,图表——条形图——图表值(频率)——继续,勾选显示频率表格,点击确定。
Statistics户口所在地职业年龄N Valid 282 282 282Missing 0 0 0户口所在地Frequency Percent ValidPercentCumulativePercentValid 中心城市200 70.9 70.9 70.9 边远郊区82 29.1 29.1 100.0 Total 282 100.0 100.0职业Frequency Percent ValidPercentCumulativePercentValid 国家机关24 8.5 8.5 8.5 商业服务业54 19.1 19.1 27.7 文教卫生18 6.4 6.4 34.0 公交建筑业15 5.3 5.3 39.4 经营性公司18 6.4 6.4 45.7 学校15 5.3 5.3 51.1 一般农户35 12.4 12.4 63.5 种粮棉专业户4 1.4 1.4 64.9种果菜专业户10 3.5 3.5 68.4 工商运专业户34 12.1 12.1 80.5 退役人员17 6.0 6.0 86.5 金融机构35 12.4 12.4 98.9 现役军人 3 1.1 1.1 100.0 Total 282 100.0 100.0年龄Frequency Percent ValidPercent Cumulative PercentValid 20岁以下 4 1.4 1.4 1.4 20~35岁146 51.8 51.8 53.2 35~50岁91 32.3 32.3 85.5 50岁以上41 14.5 14.5 100.0 Total 282 100.0 100.0分析:本次调查的有效样本为282份。

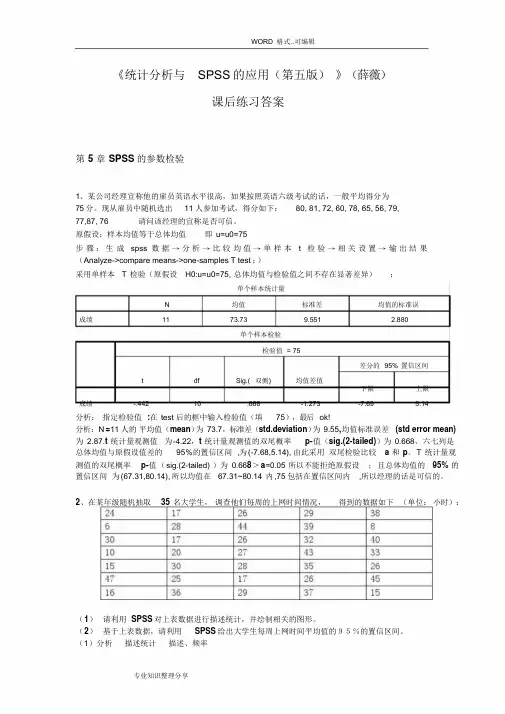
《统计分析与SPSS的应用(第五版)》(薛薇)课后练习答案第5 章SPSS的参数检验1、某公司经理宣称他的雇员英语水平很高,如果按照英语六级考试的话,一般平均得分为75分。
现从雇员中随机选出11人参加考试,得分如下:80, 81, 72, 60, 78, 65, 56, 79,77,87, 76 请问该经理的宣称是否可信。
原假设:样本均值等于总体均值即u=u0=75步骤:生成spss 数据→分析→比较均值→单样本t 检验→相关设置→输出结果(Analyze->compare means->one-samples T test ;)采用单样本T 检验(原假设H0:u=u0=75, 总体均值与检验值之间不存在显著差异);单个样本统计量N 均值标准差均值的标准误成绩11 73.73 9.551 2.880单个样本检验检验值= 75差分的95% 置信区间t df Sig.( 双侧) 均值差值下限上限成绩-.442 10 .668 -1.273 -7.69 5.14分析:指定检验值:在test 后的框中输入检验值(填75),最后ok!分析:N=11 人的平均值(mean)为73.7,标准差(std.deviation)为9.55,均值标准误差(std error mean) 为2.87.t 统计量观测值为-4.22,t 统计量观测值的双尾概率p-值(sig.(2-tailed))为0.668,六七列是总体均值与原假设值差的95%的置信区间,为(-7.68,5.14), 由此采用双尾检验比较 a 和p。
T 统计量观测值的双尾概率p-值(sig.(2-tailed) )为0.668>a=0.05 所以不能拒绝原假设;且总体均值的95% 的置信区间为(67.31,80.14), 所以均值在67.31~80.14 内,75 包括在置信区间内,所以经理的话是可信的。
2、在某年级随机抽取35 名大学生,调查他们每周的上网时间情况,得到的数据如下(单位:小时):(1)请利用SPSS 对上表数据进行描述统计,并绘制相关的图形。
第五单元spss的参数检验1、某公司经理宣称他的雇员英语水平很高,如果按照英语六级考试的话,一般平均得分为75分。
现从雇员中随机选出11人参加考试,得分如下: 80, 81, 72, 60, 78, 65, 56, 79, 77,87, 76 请问该经理的宣称是否可信。
原假设:样本均值等于总体均值即u=u0=75步骤:生成spss数据→分析→比较均值→单样本t检验→相关设置→输出结果(Analyze->comparemeans->one-samples T test;)分析:分析:N=11人的平均值(mean)为73.7,标准差(std.deviation)为9.55,均值标准误差(std error mean)为2.87.t统计量观测值为-4.22,t统计量观测值的双尾概率p-值(sig.(2-tailed))为0.668,六七列是总体均值与原假设值差的95%的置信区间,为(-7.68,5.14),由此采用双尾检验比较a和p。
T统计量观测值的双尾概率p-值(sig.(2-tailed))为0.668>a=0.05所以不能拒绝原假设;且总体均值的95%的置信区间为(67.31,80.14),所以均值在67.31~80.14内,75包括在置信区间内,所以经理的话是可信的。
2、经济学家认为决策者是对事实做出反应,不是对提出事实的方式做出反应。
然而心理学家则倾向于认为提出事实的方式是有关系的。
为验证哪种观点更站得住脚,调查者分别以下面两种不同的方式随机访问了足球球迷。
原假设:决策与提问方式无关,即u-u0=0步骤:生成spss数据→分析→比较均值→两独立样本t检验→相关设置→输出结果决策与提问方式有关。
由表5-4看出,独立样本在0.05的检验值为0,小于0.05,故拒绝原假设,认为决策者对事实所作出的反应与提问方式有关,心理学家的观点更站得住脚。
3、一种植物只开兰花和白花。
按照某权威建立的遗传模型,该植物杂交的后代有75%的几率开兰花,25%的几率开白花。
统计分析与S P S S的应用第五版课后练习答案第章Company number:【0089WT-8898YT-W8CCB-BUUT-202108】《统计分析与SPSS的应用(第五版)》(薛薇)课后练习答案第3章SPSS数据的预处理1、利用第2章第7题数据,采用SPSS数据筛选功能将数据分成两份文件。
其中,第一份数据文件存储常住地是“沿海或中心繁华城市”且本次存款金额在1000至5000之间的调查数据;第二份数据文件是按照简单随机抽样所选取的70%的样本数据。
第一份文件:选取数据数据——选择个案——如果条件满足——存款>=1000&存款<5000&常住地=沿海或中心繁华城市。
第二份文件:选取数据数据——选择个案——随机个案样本——输入70。
2、利用第2章第7题数据,将其按常住地(升序)、收入水平(升序)、存款金额(降序)进行多重排序。
排序数据——排序个案——把常住地、收入水平、存款金额作为排序依据分别设置排列顺序。
3、利用第2章第9题的完整数据,对每个学生计算得优课程数和得良课程数,并按得优课程数的降序排序。
计算转换——对个案内的值计数输入目标变量及目标标签,把所有课程选取到数字变量,定义值——设分数的区间,之后再排序。
4、利用第2章第9题的完整数据,计算每个学生课程的平均分以及标准差。
同时,计算男生和女生各科成绩的平均分。
方法一:利用描述性统计,数据——转置学号放在名称变量,全部课程放在变量框中,确定后,完成转置。
分析——描述统计——描述,将所有学生变量全选到变量框中,点击选项——勾选均值、标准差。
先拆分数据——拆分文件按性别拆分,分析——描述统计——描述,全部课程放在变量框中,选项——均值。
方法二:利用变量计算,转换——计算变量分别输入目标变量名称及标签——均值用函数mean完成平均分的计算,标准差用函数SD完成标准差的计算。
数据——分类汇总——性别作为分组变量、全部课程作为变量摘要、(创建只包含汇总变量的新数据集并命名)——确定5、利用第2章第7题数据,大致浏览存款金额的数据分布状况,并选择恰当的组限和组距进行组距分组。