第6章 图—数据结构
- 格式:pptx
- 大小:1015.31 KB
- 文档页数:66


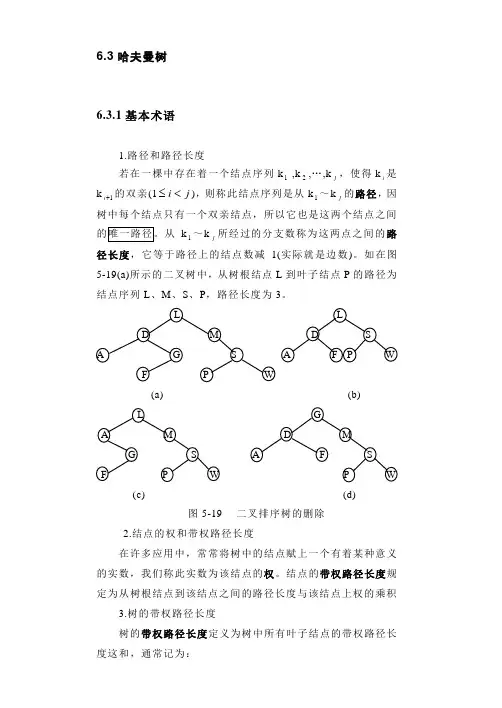
6.3哈夫曼树6.3.1基本术语1.路径和路径长度若在一棵中存在着一个结点序列k1 ,k2,…,kj,使得ki是k1+i 的双亲(1ji<≤),则称此结点序列是从k1~kj的路径,因树中每个结点只有一个双亲结点,所以它也是这两个结点之间k 1~kj所经过的分支数称为这两点之间的路径长度,它等于路径上的结点数减1(实际就是边数)。
如在图5-19(a)所示的二叉树中,从树根结点L到叶子结点P的路径为结点序列L、M、S、P,路径长度为3。
(a) (b)(c) (d)图5-19 二叉排序树的删除2.结点的权和带权路径长度在许多应用中,常常将树中的结点赋上一个有着某种意义的实数,我们称此实数为该结点的权。
结点的带权路径长度规定为从树根结点到该结点之间的路径长度与该结点上权的乘积3.树的带权路径长度树的带权路径长度定义为树中所有叶子结点的带权路径长度这和,通常记为:2 WPL = ∑=n i i i lw 1其中n 表示叶子结点的数目,i w 和i l 分别表示叶子结点i k 的权值和根到i k 之间的路径长度 。
4.哈夫曼树哈夫曼(Huffman)树又称最优二叉树。
它是n 个带权叶子结点构成的所有二叉树中,带权路径长度 WPL 最小的二叉树。
因为构造这种树的算法是最早由哈夫曼于1952年提出的,所以被称之为哈夫曼树。
例如,有四个叶子结点a 、b 、c 、d ,分别带权为9、4、5、2,由它们构成的三棵不同的二叉树(当然还有其它许多种)分别如图5-20(a)到图5-20(c)所示。
b ac a b cd d c a b d(a) (b) (c)图5-20 由四个叶子结点构成的三棵不同的带权二叉树 每一棵二叉树的带权路径长度WPL 分别为:(a) WPL = 9×2 + 4×2 + 5×2 + 2×2 = 40(b) WPL = 4×1 + 2×2 + 5×3 + 9×3 = 50(c) WPL = 9×1 + 5×2 + 4×3 + 2×3 = 37其中图5-20(c)树的WPL 最小,稍后便知,此树就是哈夫曼树。


《数据结构(C语言版第2版)》(严蔚敏著)第六章练习题答案第6章图1.选择题(1)在一个图中,所有顶点的度数之和等于图的边数的()倍。
A.1/2B.1C.2D.4答案:C(2)在一个有向图中,所有顶点的入度之和等于所有顶点的出度之和的()倍。
A.1/2B.1C.2D.4答案:B解释:有向图所有顶点入度之和等于所有顶点出度之和。
(3)具有n个顶点的有向图最多有()条边。
A.n B.n(n-1)C.n(n+1)D.n2答案:B解释:有向图的边有方向之分,即为从n个顶点中选取2个顶点有序排列,结果为n(n-1)。
(4)n个顶点的连通图用邻接距阵表示时,该距阵至少有()个非零元素。
A.n B.2(n-1)C.n/2D.n2答案:B所谓连通图一定是无向图,有向的叫做强连通图连通n个顶点,至少只需要n-1条边就可以了,或者说就是生成树由于无向图的每条边同时关联两个顶点,因此邻接矩阵中每条边被存储了两次(也就是说是对称矩阵),因此至少有2(n-1)个非零元素(5)G是一个非连通无向图,共有28条边,则该图至少有()个顶点。
A.7B.8C.9D.10答案:C解释:8个顶点的无向图最多有8*7/2=28条边,再添加一个点即构成非连通无向图,故至少有9个顶点。
(6)若从无向图的任意一个顶点出发进行一次深度优先搜索可以访问图中所有的顶点,则该图一定是()图。
A.非连通B.连通C.强连通D.有向答案:B解释:即从该无向图任意一个顶点出发有到各个顶点的路径,所以该无向图是连通图。
(7)下面()算法适合构造一个稠密图G的最小生成树。
A.Prim算法B.Kruskal算法C.Floyd算法D.Dijkstra算法答案:A解释:Prim算法适合构造一个稠密图G的最小生成树,Kruskal算法适合构造一个稀疏图G的最小生成树。
(8)用邻接表表示图进行广度优先遍历时,通常借助()来实现算法。
A.栈 B.队列 C.树D.图答案:B解释:广度优先遍历通常借助队列来实现算法,深度优先遍历通常借助栈来实现算法。


图1. 填空题⑴设无向图G中顶点数为n,则图G至少有()条边,至多有()条边;若G为有向图,则至少有()条边,至多有()条边。
【解答】0,n(n-1)/2,0,n(n-1)【分析】图的顶点集合是有穷非空的,而边集可以是空集;边数达到最多的图称为完全图,在完全图中,任意两个顶点之间都存在边。
⑵任何连通图的连通分量只有一个,即是()。
【解答】其自身⑶图的存储结构主要有两种,分别是()和()。
【解答】邻接矩阵,邻接表【分析】这是最常用的两种存储结构,此外,还有十字链表、邻接多重表、边集数组等。
⑷已知无向图G的顶点数为n,边数为e,其邻接表表示的空间复杂度为()。
【解答】O(n+e)【分析】在无向图的邻接表中,顶点表有n个结点,边表有2e个结点,共有n+2e个结点,其空间复杂度为O(n+2e)=O(n+e)。
⑸已知一个有向图的邻接矩阵表示,计算第j个顶点的入度的方法是()。
【解答】求第j列的所有元素之和⑹有向图G用邻接矩阵A[n][n]存储,其第i行的所有元素之和等于顶点i的()。
【解答】出度⑺图的深度优先遍历类似于树的()遍历,它所用到的数据结构是();图的广度优先遍历类似于树的()遍历,它所用到的数据结构是()。
【解答】前序,栈,层序,队列⑻对于含有n个顶点e条边的连通图,利用Prim算法求最小生成树的时间复杂度为(),利用Kruskal 算法求最小生成树的时间复杂度为()。
【解答】O(n2),O(elog2e)【分析】Prim算法采用邻接矩阵做存储结构,适合于求稠密图的最小生成树;Kruskal算法采用边集数组做存储结构,适合于求稀疏图的最小生成树。
⑼如果一个有向图不存在(),则该图的全部顶点可以排列成一个拓扑序列。
【解答】回路⑽在一个有向图中,若存在弧、、,则在其拓扑序列中,顶点vi, vj, vk的相对次序为()。
【解答】vi, vj, vk【分析】对由顶点vi, vj, vk组成的图进行拓扑排序。


图1. 填空题⑴ 设无向图G中顶点数为n,则图G至少有()条边,至多有()条边;若G为有向图,则至少有()条边,至多有()条边。
【解答】0,n(n-1)/2,0,n(n-1)【分析】图的顶点集合是有穷非空的,而边集可以是空集;边数达到最多的图称为完全图,在完全图中,任意两个顶点之间都存在边。
⑵ 任何连通图的连通分量只有一个,即是()。
【解答】其自身⑶ 图的存储结构主要有两种,分别是()和()。
【解答】邻接矩阵,邻接表【分析】这是最常用的两种存储结构,此外,还有十字链表、邻接多重表、边集数组等。
⑷ 已知无向图G的顶点数为n,边数为e,其邻接表表示的空间复杂度为()。
【解答】O(n+e)【分析】在无向图的邻接表中,顶点表有n个结点,边表有2e个结点,共有n+2e个结点,其空间复杂度为O(n+2e)=O(n+e)。
⑸ 已知一个有向图的邻接矩阵表示,计算第j个顶点的入度的方法是()。
【解答】求第j列的所有元素之和⑹ 有向图G用邻接矩阵A[n][n]存储,其第i行的所有元素之和等于顶点i的()。
【解答】出度⑺ 图的深度优先遍历类似于树的()遍历,它所用到的数据结构是();图的广度优先遍历类似于树的()遍历,它所用到的数据结构是()。
【解答】前序,栈,层序,队列⑻ 对于含有n个顶点e条边的连通图,利用Prim算法求最小生成树的时间复杂度为(),利用Kruskal 算法求最小生成树的时间复杂度为()。
【解答】O(n2),O(elog2e)【分析】Prim算法采用邻接矩阵做存储结构,适合于求稠密图的最小生成树;Kruskal算法采用边集数组做存储结构,适合于求稀疏图的最小生成树。
⑼ 如果一个有向图不存在(),则该图的全部顶点可以排列成一个拓扑序列。
【解答】回路⑽ 在一个有向图中,若存在弧、、,则在其拓扑序列中,顶点vi, vj, vk的相对次序为()。
【解答】vi, vj, vk【分析】对由顶点vi, vj, vk组成的图进行拓扑排序。


数据结构第6章图在计算机科学中,数据结构是组织和存储数据的方式,以便能够有效地进行操作和访问。
而图,作为数据结构中的一个重要概念,在解决许多实际问题中发挥着关键作用。
图是由一组顶点和一组连接这些顶点的边所组成。
顶点可以表示各种实体,比如城市、人、网页等等;边则表示顶点之间的关系,比如城市之间的道路连接、人与人之间的社交关系、网页之间的链接。
从形式上看,图可以分为无向图和有向图。
无向图中,边没有方向,也就是说,如果顶点 A 和顶点 B 之间有一条边,那么从 A 能到达 B,从 B 也能到达 A。
而在有向图中,边是有方向的,比如从顶点 A 指向顶点 B 的边,意味着只能从 A 到达 B,而不能反过来。
图的存储方式有多种,常见的有邻接矩阵和邻接表。
邻接矩阵是一个二维数组,如果顶点 i 和顶点 j 之间有边相连,那么数组中的第 i 行第 j 列和第 j 行第 i 列(对于无向图)或者第 i 行第 j 列(对于有向图)的值为 1,否则为 0。
邻接矩阵的优点是查询边的存在与否非常快速,但缺点是对于稀疏图(边的数量相对顶点数量较少的图)会浪费大量的存储空间。
邻接表则是为每个顶点建立一个链表,链表中存储与该顶点相邻的其他顶点。
这种方式对于稀疏图来说,能够节省大量的存储空间,但在查询边的存在时可能相对较慢。
在对图进行操作时,遍历是一个重要的算法。
常见的图遍历算法有深度优先遍历和广度优先遍历。
深度优先遍历就像是在一个迷宫中,选择一条路一直走到底,直到走不通了再回溯。
具体来说,从一个起始顶点开始,先访问该顶点,然后递归地访问其未被访问过的相邻顶点。
这种遍历方式能够深入探索图的结构,但可能会导致某些部分的图被较晚访问到。
广度优先遍历则像是以起始顶点为中心,逐层向外扩展访问。
首先访问起始顶点,然后依次访问其所有相邻顶点,再依次访问这些相邻顶点的相邻顶点,以此类推。
这种遍历方式能够先访问距离起始顶点较近的顶点。
图在实际应用中有着广泛的用途。