结构方程模型最简单易懂的教程
- 格式:ppt
- 大小:1019.50 KB
- 文档页数:33



建立结构方程模型是一种常用的统计方法,用于研究变量之间的关系。
通过结构方程模型,我们可以了解变量之间的直接和间接影响,从而揭示出变量之间的复杂关系。
在进行结构方程模型分析时,有一系列步骤需要遵循,下面将针对这些步骤进行详细介绍。
1. 研究目的与假设的设定在建立结构方程模型之前,首先需要明确研究的目的和建立的假设。
研究目的可以是探索性的,也可以是验证性的,对于不同的研究目的,选择适当的结构方程模型方法和技术是非常重要的。
需要明确研究中所涉及的变量及它们之间的假设关系,这有助于后续模型的建立和验证。
2. 模型变量的选择与测量选择适当的变量是建立结构方程模型的关键步骤之一。
需要考虑到研究的实际背景和需要,选取与研究问题相关的变量,并对这些变量进行测量。
测量变量时,需要注意选择合适的测量工具和方法,确保所得数据的可靠性和有效性。
3. 模型的理论基础建立在建立结构方程模型之前,需要确立模型的理论基础。
这包括对所研究的现象和变量之间关系的深入理解,以及构建理论模型的基础假设和逻辑。
4. 模型的建立与验证建立结构方程模型时,需要选择合适的模型建立方法,例如最小二乘法(OLS)或最大似然估计法(MLE),并进行模型参数的估计和检验。
在模型验证过程中,需要对模型的适配度进行评估,比如拟合指数(CFI)、均方差误差逼近指数(RMSEA)等指标,以判断模型与实际数据的拟合程度。
5. 模型的修正与改进基于模型验证的结果,需要对模型进行修正和改进。
这可能涉及到改变模型的结构、添加或删除变量、修正参数等操作,以使模型更好地符合实际数据的特点和逻辑要求。
6. 模型结果的解释与报告需要对建立的结构方程模型进行结果解释和报告。
这包括对模型各个部分的解释,变量间关系的说明,以及模型结果对研究问题的启示和影响。
还需要将模型的建立和验证过程进行详细的报告,以便他人对研究的可信度和科学性进行评估。
建立结构方程模型是一个系统性和复杂的过程,需要全面考虑研究的实际需求和要求,以及研究变量之间的关系和逻辑。


应用案例1第一节模型设定结构方程模型分析过程可以分为模型构建、模型运算、模型修正以及模型解释四个步骤。
下面以一个研究实例作为说明,使用Amos7软件2进行计算,阐述在实际应用中结构方程模型的构建、运算、修正与模型解释过程。
一、模型构建的思路本案例在著名的美国顾客满意度指数模型(ASCI)的基础上,提出了一个新的模型,并以此构建潜变量并建立模型结构。
根据构建的理论模型,通过设计问卷对某超市顾客购物服务满意度调查得到实际数据,然后利用对缺失值进行处理后的数据3进行分析,并对文中提出的模型进行拟合、修正和解释。
二、潜变量和可测变量的设定本文在继承ASCI模型核心概念的基础上,对模型作了一些改进,在模型中增加超市形象。
它包括顾客对超市总体形象及与其他超市相比的知名度。
它与顾客期望,感知价格和顾客满意有关,设计的模型见表7-1。
模型中共包含七个因素(潜变量):超市形象、质量期望、质量感知、感知价值、顾客满意、顾客抱怨、顾客忠诚,其中前四个要素是前提变量,后三个因素是结果变量,前提变量综合决定并影响着结果变量(Eugene W. Anderson & Claes Fornell,2000;殷荣伍,2000)。
表7-1 设计的结构路径图和基本路径假设2.1、顾客满意模型中各因素的具体范畴参考前面模型的总体构建情况、国外研究理论和其他行业实证结论,以及小范围甄别调查的结果,模型中各要素需要观测的具体范畴,见表7-2。
1关于该案例的操作也可结合书上第七章的相关内容来看。
2本案例是在Amos7中完成的。
3见spss数据文件“处理后的数据.sav”。
表7-2 模型变量对应表4正向的,采用Likert10级量度从“非常低”到“非常高”三、关于顾客满意调查数据的收集本次问卷调研的对象为居住在某大学校内的各类学生(包括全日制本科生、全日制硕士和博士研究生),并且近一个月内在校内某超市有购物体验的学生。
调查采用随机拦访的方式,并且为避免样本的同质性和重复填写,按照性别和被访者经常光顾的超市进行控制。

结构方程模型介绍
结构方程模型是一种统计方法,能够解决复杂的因果关系和变量之间的关系。
它可以通过估计和检验多个变量之间的关系和不同因素之间的因果关系来分析数据。
下面分步骤介绍结构方程模型。
第一步:概念理解
理解结构方程模型的本质是什么:它是一个统计方法,能够制定以及测试一个多个因变量作用下的预测模型。
第二步:了解结构方程模型有两种表达方法
一种是路径分析模型,它能够表达模型中所有变量的因果关系;一种是因子模型,它能够表达模型中诸如信念、态度、个性等隐含变量的因素。
第三步:理解结构方程模型涉及到几个步骤
1. 设计研究:这是一个关键的步骤,因为它会直接影响到模型的准确性。
2. 收集数据:可以使用问卷、观察等方法来收集数据。
3. 模型选择:选择最合适的结构方程模型(路径分析或因子分析)。
4. 参数估计:通过多元回归分析计算结构方程中各个变量的系数。
第四步:掌握结构方程模型的应用
1. 算法实践:使用结构方程模型算法来估计各个变量的系数。
2. 模型评估:通过不同的统计方法来评估模型的准确度及其可靠性。
3. 结论得出:得出结论性言论,使用结构方程模型分析不同数据样本之间的区别,以及模型中不同变量的统计学显著性在预测上的作用。
结构方程模型是统计学研究中非常重要的一种方法,能够帮助研究人员解决实际问题,并支持数据驱动的决策的。

应用案例1第一节模型设定结构方程模型分析过程可以分为模型构建、模型运算、模型修正以及模型解释四个步骤。
下面以一个研究实例作为说明,使用Amos7软件2进行计算,阐述在实际应用中结构方程模型的构建、运算、修正与模型解释过程。
模型构建的思路一、本案例在著名的美国顾客满意度指数模型(ASCI)的基础上,提出了一个新的模型,并以此构建潜变量并建立模型结构。
根据构建的理论模型,通过设计问卷对某超市顾客购物服务满意度调查得到实际数据,然后利用对缺失值进行处理后的数据3进行分析,并对文中提出的模型进行拟合、修正和解释。
二、潜变量和可测变量的设定本文在继承ASCI模型核心概念的基础上,对模型作了一些改进,在模型中增加超市形象。
它包括顾客对超市总体形象及与其他超市相比的知名度。
它与顾客期望,感知价格和顾客满意有关,设计的模型见表7-1。
模型中共包含七个因素(潜变量):超市形象、质量期望、质量感知、感知价值、顾客满意、顾客抱怨、顾客忠诚,其中前四个要素是前提变量,后三个因素是结果变量,前提变量综合决定并影响着结果变量(Eugene W.Anderson&ClaesFornell,2000;殷荣伍,2000)。
表7-1设计的结构路径图和基本路径假设2.1、顾客满意模型中各因素的具体范畴1关于该案例的操作也可结合书上第七章的相关内容来看。
2本案例是在Amos7中完成的。
3见spss数据文件“处理后的数据.sav”。
参考前面模型的总体构建情况、国外研究理论和其他行业实证结论,以及小范围甄别调查的结果,模型中各要素需要观测的具体范畴,见表7-2。
表7-2模型变量对应表三、关于顾客满意调查数据的收集本次问卷调研的对象为居住在某大学校内的各类学生(包括全日制本科生、全日制硕士和博士研究生),并且近一个月内在校内某超市有购物体验的学生。
调查采用随机拦访的方式,并且为避免样本的同质性和重复填写,按照性别和被访者经常光顾的超市进行控制。

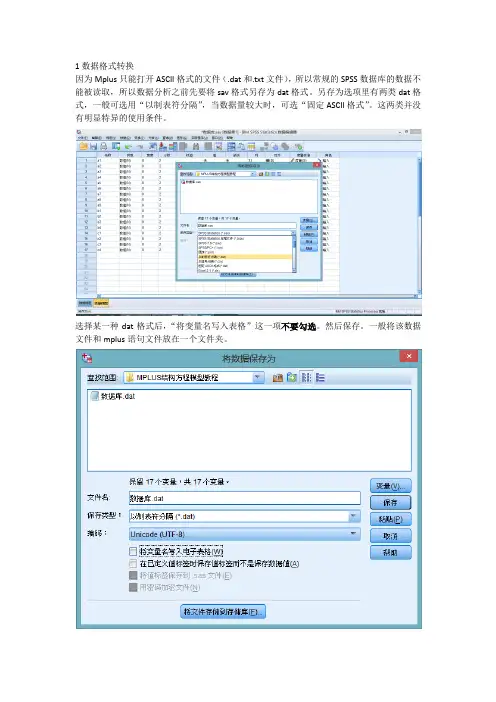
1数据格式转换因为Mplus只能打开ASCII格式的文件(.dat和.txt文件),所以常规的SPSS数据库的数据不能被读取,所以数据分析之前先要将sav格式另存为dat格式。
另存为选项里有两类dat格式,一般可选用“以制表符分隔”,当数据量较大时,可选“固定ASCII格式”。
这两类并没有明显特异的使用条件。
选择某一种dat格式后,“将变量名写入表格”这一项不要勾选。
然后保存。
一般将该数据文件和mplus语句文件放在一个文件夹。
2 打开mplus程序,建立新文件,即点击“new”。
当然,新打开Mplus程序也会默认这个界面。
3 编辑命令。
这是Mplus分析数据最核心的步骤3.1 首先我们可以给该分析起个名字(该步骤可有可无),例如:TITLE: example3.2 然后表明我们引用的数据库来自于哪里,也就是刚刚那个DAT文件。
命令为:DATA: FILE IS C:\Users\dell\Desktop\MPLUS结构方程模型教程\数据库.dat;这里面需要注意的是:DATA: FILE IS (或者DATA: FILE=)是固定句式,是必要的。
之后“C:\Users\dell\Desktop\MPLUS结构方程模型教程\数据库.dat”这是DAT文件的保存路径。
一般情况下,如果mplus语句文件和dat文件在同一个文件夹中,只需要DATA: FILE IS数据库.dat; 但实际上很多情况下,两者即使在同一个文件中,也很可能读不出来,所以必要的话,可将该DAT文件的保存路径写全,这样肯定是没错的。
另外,一个命令结束后,必须必须加上“;”即英文格式下的分号(除外TITLE)。
3.3 写出数据库中所有的变量名称以及本次分析需要的变量名称。
这需要按照spss数据库中变量名称顺序来写。
VARIABLE: NAMES ARE a1 a2 a3 a4 a5 a6 a7 a8 a9 b1 b2 b3 b4 c1 c2 c3 c4;USEVARIABLES ARES ARE a1 a2 a3 a4 a5 a6 a7 a8 a9 b1 b2 b3 b4 c1 c2 c3 c4;当然这是最基本繁琐的写法,可以直接写为:VARIABLE: NAMES ARE a1-a9 b1-b4 c1-c4;USEVARIABLES ARES ARE a1-a9 b1-b4 c1-c4;不同变量间有空格。

结构⽅程模型⼊门(纯⼲货!)⼀、结构⽅程模型的概念结构⽅程模型(Structural Equation Model,简称SEM)是基于变量的协⽅差矩阵来分析变量之间关系的⼀种统计⽅法,因此也称为协⽅差结构分析。
结构⽅程模型属于多变量统计分析,整合了因素分析与路径分析两种统计⽅法,同时可检验模型中的显变量(测量题⽬)、潜变量(测量题⽬表⽰的含义)和误差变量直接按的关系,从⽽活动⾃变量对因变量影响的直接效果、间接效果和总效果。
结构⽅程模型基本上是⼀种验证性的分析⽅法,因此通常需要有理论或者经验法则的⽀持,根据理论才能构建假设的模型图。
在构建模型图之后,检验模型的拟合度,观察模型是否可⽤,同时还需要检验各个路径是否达到显著,以确定⾃变量对因变量的影响是否显著。
⽬前,结构⽅程模型的分析软件较多,如Lisrel、EQS、Amos、Mplus、 Smartpls等等,其中AMOS的使⽤率甚⾼,因此我们重点了解⼀下使⽤AMOS软件进⾏结构⽅程模型分析的过程。
⼆、结构⽅程模型的相关概念在构建模型假设图,我们⾸先需要了解⼀些有关的基本概念1、显变量显变量有多种称呼,如“观察变量”、“测量变量”、“显性变量”、“观测变量”等等。
从这些称呼中可以看到,显变量的主要含义就是:变量是实际测量的内容,也就是我们问卷上⾯的题⽬。
在Amos中,显变量使⽤长⽅形表⽰。
2、潜变量潜变量也叫潜在变量,是⽆法直接测量,但是可以通过多个题⽬进⾏表⽰的变量。
在Amos中,潜变量使⽤椭圆表⽰。
在使⽤的过程中,我们可以通过这样的⽅式区分显变量和潜变量:在数据⽂件中有具体值的变量就是显变量,没有具体值但可通过多个题⽬表⽰的则是潜变量。
3、误差变量误差变量是不具有实际测量的变量,但必不可少。
在调查中,显变量不可能百分之百的解释潜变量,总会存在误差,这反映在结构⽅程模型中就是误差变量,每⼀个显变量都会有误差变量。
在Amos中,误差变量使⽤圆形进⾏表⽰(与潜变量类似)。
结构方程模型的构建结构方程模型(StructuralEquationModeling,简称SEM)是一种基于统计学原理的分析方法,用于探究变量之间的关系。
它可以用于确定变量之间的因果关系,模拟复杂的系统和预测未来的趋势。
SEM的构建过程可以分为以下几个步骤:第一步,明确研究问题和目的。
根据研究问题和目的,确定需要考虑的变量和它们之间的关系。
例如,如果研究的是教育水平和职业成功之间的关系,那么需要考虑的变量可能包括教育程度、工作经验、工作成就感等。
第二步,制定研究假设和模型。
在这一步,需要根据研究问题和目的,提出具体的研究假设和模型。
例如,如果假设教育程度和工作经验对工作成就感有影响,那么可以构建一个包含这三个变量之间关系的模型。
第三步,收集数据。
根据研究假设和模型,设计合适的问卷或实验,并收集相关数据。
在收集数据的过程中,需要注意数据的准确性和可靠性,保证数据的质量。
第四步,选择合适的分析工具。
根据研究问题和目的,选择合适的SEM分析工具。
常用的分析工具包括AMOS、LISREL等。
第五步,进行模型拟合和分析。
在进行模型拟合和分析时,需要根据研究问题和目的,确定合适的拟合指标和分析方法。
例如,可以使用结构方程模型拟合指标(如χ、RMSEA、CFI等)来评估模型的拟合程度。
同时,可以使用路径系数和标准化系数等指标来分析变量之间的关系和影响程度。
第六步,解释和解读分析结果。
根据分析结果,解释变量之间的关系和影响程度。
如果模型拟合程度较好,可以用模型来预测未来趋势或进行政策决策。
总之,SEM是一种强大的分析工具,可以用于探究变量之间的关系和预测未来的趋势。
在构建SEM模型时,需要明确研究问题和目的,制定研究假设和模型,收集数据,选择合适的分析工具,进行模型拟合和分析,最终解释和解读分析结果。
业务资料之 密级: 结构方程式原理及操作指南作者:***二零零三年三月一日一、结构方程式的基本原理结构方程式是一种非常通用的、主要的线性统计建模技术。
实际上,它是计量经济学、计量社会学与计量心理学等领域的统计方法的综合。
结构方程式的本质是联立线性方程组求解,但是它没有很严格的假设限定条件,同时允许自变量和因变量存在测量误差。
上图是一个典型的结构方程式路径图,其中各组成部分的定义如下:结构方程式由外源潜变量、内源潜变量和变量之间的关系系数组成,与潜变量相联的箭头方向都向外的变量是外源潜变量,与潜变量相联的箭头方向有内有外的变量是内源潜变量。
外源潜变量的估测由测量模型,外源观测变量由外源潜变量和外源潜变量残差测量而得。
同理,内源潜变量的估测也由测量模型完成。
包括内源潜变量、内源潜变量残差,其中,内源潜变量可以由外源观测变量和外源潜变量残差测量而得。
(注:只有内源观测变量有残差,外源观测变量没有) 外源观测变量 内源观测变量 残差外源潜变量 内源潜变量 结构模型测量模型11简单来说,结构方程式模型可分可测量变量及潜变量两部分。
用方程表示这两个部分(可测量变量与潜变量之间的关系和内源潜变量与外生潜变量间的关系),即为: (1)内源潜变量与外源潜变量间的关系 η=βη+Γξ+ζ η——内源潜变量(endogenous,dependent) ξ——外源(自变)潜变量(exogenous,independent) β——内源潜变量间的关系 г——外源变项对内源变项的影响 ζ——模式内未能解释部分(即模式内所包含的变项及变项间关系所未能解释部分,用误差变量表示) (2)对于可测量变量与潜变量之间的关系,即测量模型部分: X=Λxξ+δ Y=Λyη+ε X,Y是外源及内源指标。
δ,ε是X,Y测量上的误差。
Λx是X指标与ξ潜变量的关系。
Λy是Y指标与η潜变量的关系 从模型的形式上看,内源潜变量与外源潜变量间的关系部分的结构方程模型与多元回归、通径分析相似;可测量变量与潜变量之间的关系部分的结构方程模型与因子分析方法相似。
Mplus结构方程模型步骤(入门)1数据格式转换因为Mplu只能打开ASCII格式的文件(.dat和.t某t文件),所以常规的SPSS数据库的数据不能被读取,所以数据分析之前先要将av格式另存为dat格式。
另存为选项里有两类dat格式,一般可选用“以制表符分隔”,当数据量较大时,可选“固定ASCII格式”。
这两类并没有明显特异的使用条件。
选择某一种dat格式后,“将变量名写入表格”这一项不要勾选。
然后保存。
一般将该数据文件和mplu语句文件放在一个文件夹。
2打开mplu程序,建立新文件,即点击“new”。
当然,新打开Mplu程序也会默认这个界面。
3编辑命令。
这是Mplu分析数据最核心的步骤3.1首先我们可以给该分析起个名字(该步骤可有可无),例如:TITLE:e某ample3.2然后表明我们引用的数据库来自于哪里,也就是刚刚那个DAT文件。
命令为:DATA:FILEISC:\\Uer\\dell\\Dektop\\MPLUS结构方程模型教程\\数据库.dat;这里面需要注意的是:DATA:FILEIS(或者DATA:FILE=)是固定句式,是必要的。
之后“C:\\Uer\\dell\\Dektop\\MPLUS结构方程模型教程\\数据库.dat”这是DAT文件的保存路径。
一般情况下,如果mplu语句文件和dat文件在同一个文件夹中,只需要DATA:FILEIS数据库.dat;但实际上很多情况下,两者即使在同一个文件中,也很可能读不出来,所以必要的话,可将该DAT文件的保存路径写全,这样肯定是没错的。
另外,一个命令结束后,必须必须加上“;”即英文格式下的分号(除外TITLE)。
3.3写出数据库中所有的变量名称以及本次分析需要的变量名称。
这需要按照p数据库中变量名称顺序来写。
VARIABLE:NAMESAREa1a2a3a4a5a6a7a8a9b1b2b3b4c1c2c3c4;USEVARIA BLESARESAREa1a2a3a4a5a6a7a8a9b1b2b3b4c1c2c3c4;当然这是最基本繁琐的写法,可以直接写为:VARIABLE:NAMESAREa1-a9b1-b4c1-c4;USEVARIABLESARESAREa1-a9b1-b4c1-c4;不同变量间有空格。
结构方程模型自由度计算举例
这里以一个简单的结构方程模型为例,讲解结构方程模型自由度的计算方法:
结构方程模型自由度计算举例
我们设计一个简单的结构方程模型,包含3个潜在变量1、2、3,它们之间没有方向关系,只考虑方差协方差矩阵中的元素。
对于这个模型:
1. 每个潜在变量有1个方差待估计,因此方差数字是3。
2. 每两个潜在变量之间有1个协方差待估计。
三个变量之间有(3,2)=3个二元组合。
3. 总的待估计参数数为:方差数字3 + 协方差数字3 = 6
4. 每个观测值都会提供1个信息。
假设我们有100个观测样本,则数据能提供的信息量是100。
5. 结构方程模型自由度 = 信息量 - 待估计参数数
= 100 - 6
= 94
所以这个简单模型的自由度是94。
自由度较大表明模型还可以增加更多结构关系形成更复杂的模型结构。
以上是一个简单结构方程模型自由度计算的实例,希望能帮助大家初步了解结构方程模型分析中的这个重要概念。
文献解读:结构方程模型SEM基础,小白看这个就基本够了今天要解读的依然是一篇教学文献:The Basics of Structural Equation Modeling,文献作者是DianaSuhr, Ph.D. University of Northern Colorado。
概念结构方程模型是:用来检验显变量与潜变量关系假设的综合性的统计技巧用来表示,估计或者检验变量间理论关系的技巧用来探究一系列潜变量和显变量因果关系的统计技巧我们做结构方程模型主要是为了:1. 了解变量之间的共变关系2. 解释模型中变量尽可能多的变异上面给出了结构方程模型比较宏大的概念,具体地我们又可以细分:我们用路径分析探究变量之间的因果。
我们用验证性因子分析探究潜变量和显变量之间的关系。
我们用潜增长曲线模型(LGM)估计纵向数据的初始,变化,结构斜率和方差。
上面提到的方法统统都可以归于结构方程模型的特例。
结构方程模型和传统分析方法的不同首先SEM更加灵活,更加综合。
传统方法的模型是提前规定的或者说是默认的,而做结构方程的时候,它对变量关系的限制几乎没有,需要你自己根据理论知识设定变量之间的关系;SEM既包含显变量又有潜变量,而传统的方法只分析显变量;在SEM中我们认为误差是存在的,你甚至可以规定不同变量之间误差的关系是怎样的,但是传统的方法认为误差是没有的;传统方法能够输出变量间关系的直接的显著性检验结果,而SEM没有这样的结果,我们得用拟合指标来评价模型;另外,结构方程模型可以很好地容忍多重共线性。
SEM的统计指标chi-square:这个统计量表示预期协方差矩阵和数据的协方差矩阵的差异,卡方越小说明我们的模型和数据越符合Comparative Fit Index (CFI):这个指标表示调整了样本量后的ediscrepancy function,这个指标取值1~1,越大越好,建议大于0.9Root Mean Square Error of Approximation (RMSEA):这是一个和模型残差有关的指标,越小越好,一般要求小于0.06如果我们的模型做出来拟合指标还过的去,我们接下来就应该检验模型的参数,参数与其标准误的比值是服从z分布的,所以参数和其标准误的比值大于1.96的话,这个参数的p就小于0.05.当然啦,模型拟合指标不好的情况也是经常出现的,这个时候我们要很具合理的修正指数来修正我们的模型,比如你把原先固定的参数进行释放等等。