数据分析实验报告册
- 格式:doc
- 大小:2.24 MB
- 文档页数:52

数据分析实验报告分析解析一、引言数据分析是当今信息时代中非常重要的一项技术,它通过收集、整理和解析数据,帮助我们揭示数据背后的规律和价值。
本文将对进行的数据分析实验进行分析解析,并探讨其应用和展望。
二、实验方法在本实验中,我们选择了一组销售数据进行分析。
首先,我们从公司数据库中提取了一段时间内的销售数据,包括销售额、销售量、产品属性等。
然后,我们使用了数据处理软件对这些数据进行了清洗、转化和整理,以便进一步的分析。
最后,我们使用了统计学和机器学习等数据分析方法对数据进行了解析和模型构建。
三、数据清洗与转化在进行数据分析之前,我们首先需要对数据进行清洗。
因为从数据库中提取的数据往往存在一些噪声和异常值,这些数据会对后续的分析结果产生影响。
因此,我们通过数据清洗的方式去除了这些干扰项,并确保数据的准确性和一致性。
针对销售数据中的异常值,我们采用了一些常用的统计方法进行处理。
例如,我们可以使用均值、中位数和众数等指标来判断某个数据点是否异常。
对于异常值,我们可以选择删除、修正或更换这些数据点,以消除其对整体数据的影响。
另外,数据转化也是数据清洗的重要环节。
在实际分析中,原始数据往往存在格式和类型的不匹配,需要进行一些转化操作。
例如,将字符型的日期转化为时间戳,将文本型的产品属性转化为数值型等。
通过数据转化,我们可以使得数据更加易于分析和理解。
四、数据分析与解析完成数据清洗与转化后,接下来我们对数据进行分析与解析。
数据分析的目的是从数据中提取有用的信息,揭示数据背后的规律和趋势。
在数据分析的过程中,我们可以使用多种方法和技术。
例如,统计学分析可以帮助我们了解数据的分布规律和关联性,以及进行假设检验和预测等。
机器学习方法可以通过构建模型来训练和预测数据,例如聚类分析、回归分析和分类算法等。
通过这些分析方法,我们可以深入挖掘数据的内在价值,并为业务决策提供参考依据。
在本实验中,我们使用了多种数据分析方法对销售数据进行了解析。

《数据分析》实验报告三一、实验目的本次数据分析实验旨在通过对给定数据集的深入分析,探索数据中的潜在规律和关系,以获取有价值的信息,并为决策提供支持。
具体目标包括:1、熟悉数据分析的流程和方法,包括数据收集、清理、预处理、分析和可视化。
2、运用统计学和数学知识,对数据进行描述性分析和推断性分析。
3、掌握数据挖掘技术,如分类、聚类等,发现数据中的隐藏模式。
4、培养解决实际问题的能力,通过数据分析为实际业务场景提供有效的建议和决策依据。
二、实验环境1、操作系统:Windows 102、数据分析工具:Python 38(包括 Pandas、NumPy、Matplotlib、Seaborn 等库)3、数据库管理系统:MySQL 80三、实验数据本次实验使用的数据集是一份关于某电商平台销售记录的数据集,包含了以下字段:订单号、商品名称、商品类别、销售价格、销售数量、销售日期、客户地区等。
数据量约为 10 万条。
四、实验步骤1、数据收集从给定的数据源中获取数据集,并将其导入到数据分析工具中。
2、数据清理(1)处理缺失值:检查数据集中各个字段是否存在缺失值。
对于数值型字段,使用平均值或中位数进行填充;对于字符型字段,使用最常见的值进行填充。
(2)处理重复值:删除数据集中的重复记录,以确保数据的唯一性。
(3)异常值处理:通过绘制箱线图等方法,识别数据中的异常值,并根据实际情况进行处理,如删除或修正。
3、数据预处理(1)数据标准化:对数值型字段进行标准化处理,使其具有相同的量纲,便于后续的分析和比较。
(2)特征工程:根据分析需求,对原始数据进行特征提取和构建,例如计算商品的销售额、销售均价等。
4、数据分析(1)描述性分析计算数据集中各个字段的统计指标,如均值、中位数、标准差、最小值、最大值等,以了解数据的集中趋势和离散程度。
绘制柱状图、折线图、饼图等,直观展示数据的分布情况和比例关系。
(2)推断性分析进行假设检验,例如检验不同商品类别之间的销售价格是否存在显著差异。

第1篇一、实验背景随着通信技术的飞速发展,通信数据量呈爆炸式增长。
如何有效地分析这些数据,挖掘其中的价值,对于提升通信网络的性能、优化资源配置、提高用户满意度等方面具有重要意义。
本实验旨在通过实践,学习通信数据分析的基本方法,掌握相关工具的使用,并对实际通信数据进行深入分析。
二、实验目的1. 熟悉通信数据的基本结构和特点。
2. 掌握通信数据分析的基本方法,包括数据预处理、特征提取、数据挖掘等。
3. 学会使用常用的通信数据分析工具,如Python、R等。
4. 通过实际案例分析,提高通信数据分析的实际应用能力。
三、实验内容1. 数据采集2. 数据预处理3. 特征提取4. 数据挖掘5. 实际案例分析四、实验步骤1. 数据采集本次实验采用某运营商提供的通信数据,数据包括用户ID、时间戳、通信流量、通信时长、网络类型等字段。
2. 数据预处理(1)数据清洗:去除重复数据、缺失数据,修正错误数据。
(2)数据转换:将时间戳转换为日期格式,对数据进行归一化处理。
3. 特征提取(1)时间特征:提取用户活跃时间段、通信密集时间段等。
(2)流量特征:计算用户平均通信流量、峰值流量等。
(3)时长特征:计算用户平均通信时长、峰值时长等。
(4)网络特征:统计不同网络类型的用户占比、通信成功率等。
4. 数据挖掘(1)关联规则挖掘:分析用户在特定时间段、特定网络类型下的通信行为,挖掘用户行为规律。
(2)聚类分析:根据用户特征,将用户分为不同的群体,分析不同群体的通信行为差异。
(3)分类预测:预测用户未来通信行为,为运营商提供决策依据。
5. 实际案例分析以某运营商为例,分析其通信数据,挖掘用户行为规律,优化网络资源配置。
五、实验结果与分析1. 用户活跃时间段主要集中在晚上7点到10点,峰值流量出现在晚上9点。
2. 高流量用户主要集中在网络覆盖较好的区域,低流量用户则分布在网络覆盖较差的区域。
3. 不同网络类型的用户占比:4G用户占比最高,其次是3G用户,2G用户占比最低。

数据与分析实验报告1. 引言数据分析是一种通过分析和解释数据来确定模式、关系以及其他有价值信息的过程。
在现代社会中,数据分析已经成为各个领域中不可或缺的工具。
本实验旨在通过对一个特定数据集的分析,展示数据分析的过程以及结果的解读和应用。
本实验选择了一组关于学业表现的数据进行分析,并探讨了学生的各项指标与其学习成绩之间的关系。
2. 数据集描述本次实验所使用的数据集是一个包含了1000名学生的学术成绩和相关指标的数据集。
数据集中包含了每位学生的性别、年龄、是否拥有本科学历、成绩等信息。
数据集以CSV格式提供。
3. 数据清洗与预处理在进行数据分析之前,首先需要进行数据清洗和预处理的工作,以保证后续分析的准确性和可靠性。
本实验中的数据集在经过初步检查后,发现存在一些缺失值和错误值。
为了保证数据的完整性,我们采取了以下措施进行数据清洗:- 删除缺失值:对于存在缺失值的数据,我们选择了删除含有缺失值的行。
- 纠正错误值:通过对每个指标的合理范围进行了限定,排除了存在明显错误值的数据。
此外,还进行了数据的标准化处理,以确保各项指标具有可比性。
4. 数据探索与分析4.1 性别与学习成绩的关系为了探究性别与学习成绩之间的关系,我们进行了如下分析:- 绘制了性别与学习成绩的散点图,并使用不同的颜色进行了标记。
通过观察散点图,我们可以初步得出性别与学习成绩之间存在一定的关系。
但由于性别只是一个二分类变量,为了更加准确地探究性别与学习成绩之间的关系,我们使用了ANOVA分析进行了验证。
4.2 年龄与学习成绩的关系为了探究年龄与学习成绩之间的关系,我们进行了如下分析:- 将学生按年龄分组,计算每个年龄组的平均成绩,并绘制了年龄与学习成绩的折线图。
通过观察折线图,我们可以发现年龄与学习成绩之间存在一定的曲线关系。
年龄在一定范围内的增长会对学习成绩产生积极影响,但随着年龄的增长,学习成绩会逐渐下降。
4.3 学历与学习成绩的关系为了探究学历与学习成绩之间的关系,我们进行了如下分析:- 计算了不同学历组的平均学习成绩,并绘制了学历与学习成绩的柱状图。

数据分析实习报告正文:一、引言数据分析是当今社会中一项重要且热门的技术,它能够帮助企业和组织更好地理解和利用大量的数据。
在本次实习中,我有幸参与了一家知名公司的数据分析团队,获得了宝贵的实践经验。
在本报告中,我将回顾我的实习经历,并分析我所参与的项目。
二、实习内容本次实习的主要工作是对该公司的销售数据进行分析,并给出相应的建议。
在实习开始之前,我首先对统计学和数据分析的基本概念进行了学习和巩固,以便更好地应对实际工作中的问题。
在实习期间,我主要使用了Python和R等软件来处理数据,并利用各种数据分析方法进行统计和可视化。
通过对销售数据的分析,我能够对产品销量、客户消费习惯、市场趋势等进行深入了解,并提供相关的报告和建议。
同时,我也了解了公司内部使用的一些数据分析工具和平台,例如Tableau和Power BI等。
三、实习成果在实习期间,我参与了一项关于产品销售增长的分析项目。
通过对过去一年的销售数据进行分析,我发现某些产品的销量有明显下降的趋势。
经过初步调查,我发现这些产品在市场竞争中存在一些问题,例如价格偏高、促销策略不明确等。
基于这些发现,我向团队提出了一些建议,帮助公司重新调整产品定价和促销策略,以提振销量。
此外,我还参与了一项关于客户购买行为的分析项目。
通过对客户购买记录的统计和分析,我发现不同地区的客户购买习惯存在一些差异。
例如,南方地区的客户更偏好购买高端产品,而北方地区的客户更偏好购买实惠型产品。
基于这些发现,我向团队提出了一些建议,帮助公司对不同地区的客户制定差异化的销售策略。
四、心得与收获通过这次实习,我深刻认识到数据分析在实际工作中的重要性和应用价值。
数据分析能够帮助企业和组织更好地了解市场需求,优化销售策略,提高竞争力。
同时,我也掌握了一些常用的数据分析方法和工具,提高了自己的实际操作能力。
在与团队成员的合作中,我学到了团队合作的重要性和沟通技巧。
在项目中,我们需要相互协调、共同解决问题,并及时与公司领导沟通和汇报。

广西大学数据分析实验报告学生姓名:谢丁丁学号:1111100227班级:信科111班完成时间:2014年6月8日实验内容:对数据集advert.sav作回归分析。
这是一个虚拟数据集,目的是研究广告费用和销售量之间的关系。
题意分析:变量之间的关系要么相关、要么不相关。
从学过的知识可知,定量数据的度量方法包括散点图和相关系数。
所以可从这里入手。
实验过程与结果:1、画出散点图:选择菜单“Graph”—散点图……”,出现如下选项卡点击“定义”,出现界面如下,按如下选择:点击确定,即可得所需的散点图。
如下所示:散点图分析:从散点图可看出所画的点大致成一条从左下到右上的直线,由此可初步判断销售量和广告费用成正相关关系。
2、做相关系数分析选择菜单“Analyze”--“Correlate”--“Bivariate”,出现两变量相关分析选项卡。
讲“advert”与“sales”选入Variables列表。
选择相关系数,点击OK,过程和结果如下所示:Person相关系数:相关性Detrended sales Advertising spendingDetrended sales Pearson 相关性 1 .916**显著性(双侧).000N 24 24 Advertising spending Pearson 相关性.916** 1显著性(双侧).000N 24 24 **. 在.01 水平(双侧)上显著相关。
图1Kendall相关系数与Spearman相关系数:相关系数Detrended sales Advertising spendingKendall 的tau_b Detrended sales 相关系数 1.000 .717**Sig.(双侧). .000N 24 24 Advertising spending 相关系数.717** 1.000Sig.(双侧).000 .N 24 24 Spearman 的rho Detrended sales 相关系数 1.000 .889**Sig.(双侧). .000N 24 24 Advertising spending 相关系数.889** 1.000Sig.(双侧).000 .N 24 24 **. 在置信度(双测)为0.01 时,相关性是显著的。

数据整理与分析实验报告1. 实验目的本次实验旨在通过收集、整理、分析实验数据,以达到以下目的:- 学习掌握数据整理的基本概念和方法;- 掌握数据分析的基本过程和常用方法;- 培养对实验数据的分析和解读能力。
2. 实验材料与方法2.1 实验材料- 实验所需数据集:XX数据集(数据集的来源和内容简介)2.2 实验方法- 数据整理:使用XX软件对数据进行清洗、筛选、去重等操作,确保数据的准确性和完整性;- 数据分析:根据实验目的选择合适的数据分析方法进行分析,如描述性统计分析、变量相关性分析、回归分析等;- 结果呈现:采用图表、表格等形式将分析结果清晰地展示出来,以便读者理解。
3.实验过程3.1 数据整理- 确定数据集中的关键变量,对数据集进行初步查看和理解,了解数据的整体情况;- 清洗数据:对存在异常值、缺失值等的数据进行处理,例如删除异常值,填充缺失值等;- 数据转换:对数据进行必要的转换,如数据归一化、变量离散化等,以便后续的数据分析操作。
3.2 数据分析- 描述性统计分析:利用图表和统计指标对数据进行描述,如频数分布图、直方图、均值、方差等;- 变量相关性分析:通过计算变量之间的相关系数,如皮尔逊相关系数、斯皮尔曼等级相关系数等,来评估变量之间的相关性;- 回归分析:根据实验目的,选择合适的回归模型进行分析,计算回归系数、拟合度等来验证变量之间的关系。
4. 分析结果(以下为实验结果的样例,具体结果需要根据实际数据分析而定)4.1 描述性统计分析结果通过对数据集进行描述性统计分析,我们得到如下结果:- 变量A的平均值为X,标准差为X;- 变量B的频数分布如图1所示;- 变量C的最大值为X,最小值为X;- 变量D的均值差异在不同组别间存在显著性差异。
4.2 变量相关性分析结果通过计算变量之间的相关系数,我们得到如下结果:- 变量A与变量B之间的皮尔逊相关系数为X;- 变量C与变量D之间的斯皮尔曼等级相关系数为X。

数据分析实训报告1. 引言在数据科学与分析领域,数据分析实训是一种重要的学习和实践方法。
本文旨在总结并报告我们小组在数据分析实训中所做的工作和取得的成果。
2. 实训概述我们小组在数据分析实训中选择了一个关于销售数据的真实案例进行分析。
案例提供了一个包含多个维度的数据集,包括销售额、产品类别、时间等信息。
3. 数据清洗在开始分析之前,我们首先对数据进行了清洗。
这个过程包括去除重复数据、处理缺失值、纠正数据格式等。
通过数据清洗,我们确保了数据的质量和准确性,为后续的分析工作做好了准备。
4. 数据探索在数据清洗完成后,我们进行了数据的探索性分析。
通过统计和可视化方法,我们对数据集中的各个维度进行了分析,包括了以下几个方面:4.1 销售额分析我们对销售数据进行了统计分析,计算了总销售额、平均销售额以及销售额的分布情况等。
通过对销售额的分析,我们可以了解到销售的整体情况,并找出销售额高低的原因。
4.2 产品类别分析针对产品类别这个维度,我们进行了产品销售情况的分析。
通过对不同产品类别的销售额进行统计和比较,我们可以找出畅销产品和滞销产品,为销售策略的制定提供依据。
4.3 时间维度分析我们还对销售数据中的时间维度进行了分析。
通过对时间的分析,我们可以找出销售的季节性变化和趋势,为销售计划的制定提供支持。
5. 结果与讨论在数据分析过程中,我们得出了一些有价值的结果和结论。
通过对销售数据的分析,我们发现了以下几点:•某个产品类别的销售额占总销售额的比例较高,可以加大该产品的推广力度。
•某个时间段的销售额明显高于其他时间段,可以通过促销活动进一步提升销售额。
•销售额与其他维度的关系存在一定的相关性,可以通过进一步的分析找出影响销售额的主要因素。
6. 结论通过数据分析实训,我们深入了解了数据分析过程中的各个环节,包括数据清洗、数据探索、结果分析等。
通过对销售数据的分析,我们得出了一些对业务决策有指导意义的结论。
我们相信,数据分析在实际业务中具有重要的应用价值,能够帮助企业做出更加明智的决策。

数据分析实习报告一、引言数据分析是现代企业中必不可少的一项工作,通过对大量的数据进行收集、整理、分析和解释,可以为企业决策提供有力的支持和指导。
在我的实习期间,我有幸参与了某公司的数据分析项目,并在实习过程中学到了许多宝贵的经验和知识。
本报告将对实习期间的主要工作内容和所取得的成果进行详细介绍和总结。
二、实习地点及背景实习地点为某互联网科技公司,该公司是行业内的领军企业之一,拥有海量的用户数据和丰富的业务场景。
公司注重数据的收集和分析,为决策提供切实可行的依据和建议。
实习过程中,我主要参与了两个项目的数据分析工作:用户行为分析和销售数据分析。
三、用户行为分析1.数据收集在用户行为分析项目中,主要针对公司的APP用户进行数据分析。
为了收集用户行为数据,我首先学习了数据收集工具的使用,包括在APP中嵌入埋点代码、设置事件跟踪和参数传递等。
通过这些工具,我成功地收集到了用户登录、浏览商品、下单等关键行为的数据,并将其存储到数据库中,为后续的分析工作做好了准备。
2.数据清洗和处理由于用户行为数据量较大且存在噪声,为了准确分析用户行为,需要进行数据清洗和处理。
在数据清洗过程中,我使用Python编程语言对数据进行去重、缺失值处理和异常值处理,确保数据的准确性和一致性;在数据处理时,我应用了统计学中的相关技术,例如计算用户的浏览时间、下单转化率等关键指标,并将其转化为可视化的报表和图表供上级和相关部门参考和分析。
3.用户行为分析基于清洗和处理后的数据,我使用Excel和Python的数据分析库进行用户行为分析。
我通过计算用户留存率、用户转化率、用户活跃度等指标,深入了解了用户的使用习惯、产品偏好以及潜在需求。
此外,我还使用K-means聚类算法对用户进行分群,进一步挖掘不同用户群体的特点和需求,为产品改进和市场推广提供了有益的思路和建议。
四、销售数据分析1.数据采集和清洗在销售数据分析项目中,我主要负责了解销售数据的获取方式和数据结构,并学习了SQL语言的基本知识和操作技巧。

实验名称:数据实验分析实验日期:2023年4月15日实验地点:XX大学计算机实验室实验人员:张三、李四、王五一、实验目的本次实验旨在通过数据分析方法,对一组实验数据进行处理和分析,掌握数据预处理、特征工程、模型选择和评估等基本步骤,并最终得出有意义的结论。
二、实验背景实验数据来源于XX公司,该数据集包含1000条记录,包括客户ID、购买时间、购买金额、商品类别、购买频率等字段。
通过对该数据集的分析,我们可以了解客户的购买行为,为公司的营销策略提供参考。
三、实验内容1. 数据预处理(1)数据清洗:删除缺失值、异常值,确保数据质量。
(2)数据转换:将日期字段转换为日期类型,将购买频率字段转换为数值类型。
(3)数据标准化:对购买金额字段进行标准化处理,消除量纲影响。
2. 特征工程(1)提取特征:根据业务需求,提取购买时间、商品类别等字段作为特征。
(2)特征选择:通过卡方检验、互信息等方法,筛选出对目标变量有显著影响的特征。
3. 模型选择(1)模型建立:采用决策树、随机森林、支持向量机等模型进行训练。
(2)模型评估:通过交叉验证等方法,评估模型的准确率、召回率、F1值等指标。
4. 结果分析根据实验结果,我们可以得出以下结论:(1)决策树模型的准确率为80%,召回率为70%,F1值为75%。
(2)随机森林模型的准确率为85%,召回率为75%,F1值为80%。
(3)支持向量机模型的准确率为82%,召回率为72%,F1值为78%。
(4)从上述结果可以看出,随机森林模型在准确率和F1值方面表现较好,但召回率略低于决策树模型。
四、实验总结1. 实验过程中,我们学会了如何进行数据预处理、特征工程、模型选择和评估等基本步骤。
2. 通过实验,我们掌握了不同模型的特点和适用场景,为实际业务提供了有价值的参考。
3. 在实验过程中,我们遇到了一些问题,如特征选择、模型调参等,通过查阅资料和与同学讨论,我们成功解决了这些问题。
数据分析的实验报告实验目的:通过对给定数据集的分析,探究数据分析的方法和技巧,并了解数据分析在实际问题中的应用。
实验原理:数据分析是一种基于统计学和计算机科学的技术,旨在通过收集、清洗、整理和解释数据来发现模式、关联和趋势。
数据分析的过程包括数据收集、数据清洗、数据探索、模型建立与评估等步骤。
实验步骤:1. 数据收集:从给定数据集中获取所需数据。
数据集包含某电商平台用户的购买记录,包括用户ID、购买日期、购买金额等信息。
2. 数据清洗:对收集到的数据进行清洗,去除重复数据、缺失数据,并进行格式统一和数据类型转换。
3. 数据探索:对清洗后的数据进行探索性分析,包括对数据的描述统计和可视化呈现。
常用的描述统计包括平均值、中位数、标准差等指标,通过绘制柱状图、折线图、散点图等方式,可以更直观地展示数据的分布、趋势等特征。
4. 模型建立与评估:根据实际问题的需求,选择合适的数据分析模型进行建立,并通过模型评估来验证模型的准确性和有效性。
常用的模型包括线性回归模型、决策树模型、聚类模型等。
实验结果:1. 数据收集:从给定数据集中成功提取了所需数据,包括用户ID、购买日期和购买金额。
2. 数据清洗:经过数据清洗,去除了重复数据和缺失数据,将购买日期字段转换为日期类型,并对购买金额进行了数据类型转换,确保数据的一致性和准确性。
3. 数据探索:对清洗后的数据进行了描述统计和可视化分析。
通过计算平均购买金额、购买金额的标准差等指标,可以对用户的购买行为有一个初步的了解。
通过绘制柱状图和折线图,可以观察到购买金额的分布情况和趋势。
4. 模型建立与评估:根据实际问题的需求,选择了线性回归模型来预测用户的购买金额。
通过模型评估,得出了模型的拟合优度和预测准确性,验证了模型的有效性。
实验结论:1. 通过对给定数据集的数据分析实验,我们对数据分析的方法和技巧有了更深入的了解,掌握了数据分析的基本步骤和常用模型。
2. 数据分析在实际问题中具有广泛的应用,可以帮助我们发现潜在的模式和趋势,从而做出更好的决策和预测。
数据分析实验报告实验⼀SAS系统的使⽤【实验类型】(验证性)【实验学时】2学时【实验⽬的】使学⽣了解SAS系统,熟练掌握SAS数据集的建⽴及⼀些必要的SAS语句。
【实验内容】1. 启动SAS系统,熟悉各个菜单的内容;在编辑窗⼝、⽇志窗⼝、输出窗⼝之间切换。
2. 建⽴数据集表1Name Sex Math Chinese EnglishAlice f908591Tom m958784Jenny f939083Mike m808580Fred m848589Kate f978382Alex m929091Cook m757876Bennie f827984Hellen f857484Wincelet f908287Butt m778179Geoge m868582Tod m898484Chris f898487Janet f8665871)通过编辑程序将表1读⼊数据集sasuser.score;2)将下⾯记事本中的数据读⼊SAS数据集,变量名为code name scale shareprice:000096 ⼴聚能源8500 0.059 1000 13.27000099 中信海直6000 0.028 2000 14.2000150 ST麦科特12600 -0.003 1500 7.12000151 中成股份10500 0.026 1300 10.08000153 新⼒药业2500 0.056 2000 22.753)将下⾯Excel表格中的数据导⼊SAS数据集work.gnp;name x1 x2 x3 x4 x5 x6 北京190.33 43.77 7.93 60.54 49.01 90.4 天津135.2 36.4 10.47 44.16 36.49 3.94 河北95.21 22.83 9.3 22.44 22.81 2.8 ⼭西104.78 25.11 6.46 9.89 18.17 3.25 内蒙古128.41 27.63 8.94 12.58 23.99 3.27 辽宁145.68 32.83 17.79 27.29 39.09 3.47 吉林159.37 33.38 18.37 11.81 25.29 5.22 ⿊龙江116.22 29.57 13.24 13.76 21.75 6.04 上海221.11 38.64 12.53 115.65 50.82 5.89 江苏144.98 29.12 11.67 42.6 27.3 5.74 浙江169.92 32.75 21.72 47.12 34.35 5 安徽153.11 23.09 15.62 23.54 18.18 6.39 福建144.92 21.26 16.96 19.52 21.75 6.73 江西140.54 21.59 17.64 19.19 15.97 4.94 ⼭东115.84 30.76 12.2 33.1 33.77 3.85 河南101.18 23.26 8.46 20.2 20.5 4.3 湖北140.64 28.26 12.35 18.53 20.95 6.23 湖南164.02 24.74 13.63 22.2 18.06 6.04 ⼴东182.55 20.52 18.32 42.4 36.97 11.68 ⼴西139.08 18.47 14.68 13.41 20.66 3.85 四川137.8 20.74 11.07 17.74 16.49 4.39 贵州121.67 21.53 12.58 14.49 12.18 4.57 云南124.27 19.81 8.89 14.22 15.53 3.03 陕西106.02 20.56 10.94 10.11 18 3.29 ⽢肃95.65 16.82 5.7 6.03 12.36 4.49 青海107.12 16.45 8.98 5.4 8.78 5.93 宁夏113.74 24.11 6.46 9.61 22.92 2.53新疆123.24 38 13.72 4.64 17.77 5.753. 将sasuser.score数据集的内容复制到⼀个临时数据集test,要求只包含变量name, sex, math。
实验课程:数据分析专业:信息与计算科学班级:学号:姓名:中北大学理学院实验一 SAS系统的使用【实验目的】了解SAS系统,熟练掌握SAS数据集的建立及一些必要的SAS语句。
【实验内容】1. 将SCORE数据集的内容复制到一个临时数据集test。
SCORE数据集Name Sex Math Chinese EnglishAlice f 90 85 91Tom m 95 87 84Jenny f 93 90 83Mike m 80 85 80Fred m 84 85 89Kate f 97 83 82Alex m 92 90 91Cook m 75 78 76Bennie f 82 79 84Hellen f 85 74 84Wincelet f 90 82 87Butt m 77 81 79Geoge m 86 85 82Tod m 89 84 84Chris f 89 84 87Janet f 86 65 872.将SCORE数据集中的记录按照math的高低拆分到3个不同的数据集:math 大于等于90的到good数据集,math在80到89之间的到normal数据集,math 在80以下的到bad数据集。
3.将3题中得到的good,normal,bad数据集合并。
【实验所使用的仪器设备与软件平台】SAS【实验方法与步骤】1:DATA SCORE;INPUT NAME $ Sex $ Math Chinese English;CARDS;Alice f 90 85 91Tom m 95 87 84Jenny f 93 90 83Mike m 80 85 80Fred m 84 85 89Kate f 97 83 82Alex m 92 90 91Cook m 75 78 76Bennie f 82 79 84Hellen f 85 74 84Wincelet f 90 82 87Butt m 77 81 79Geoge m 86 85 82Tod m 89 84 84Chris f 89 84 87Janet f 86 65 87;Run;PROC PRINT DATA=SCORE;DATA test;SET SCORE;2:DATA good normal bad;SET SCORE;SELECT;when(math>=90) output good;when(math>=80&math<90) output normal; when(math<80) output bad;end;Run;PROC PRINT DATA=good;PROC PRINT DATA=normal;PROC PRINT DATA=bad;3:DATA All;SET good normal bad;PROC PRINT DATA=All;Run;【实验结果】结果一:结果二:结果三:实验二上市公司的数据分析【实验目的】通过使用SAS软件对实验数据进行描述性分析和回归分析,熟悉数据分析方法,培养学生分析处理实际数据的综合能力。
数据分析实验报告实验报告:数据分析一、实验目的本实验旨在通过数据分析方法对提供的数据集进行分析,探索数据的特征和关联关系,挖掘潜在的模式和规律。
二、实验环境本实验使用Python编程语言以及相关的数据分析工具和库,包括但不限于Numpy、Pandas、Matplotlib等。
三、实验步骤1. 数据加载:首先,将提供的数据集加载到Python环境中,使用Pandas库的read_csv函数读取数据并存储为DataFrame格式。
2. 数据预处理:对加载的数据进行清洗和预处理,包括处理缺失值、异常值、重复值等问题,确保数据的质量。
3. 数据探索:对数据集进行探索性分析,包括统计描述、数据可视化等方法,了解数据的分布、变化趋势、关联关系等内容。
4. 特征工程:在数据探索的基础上,对数据进行特征选取、转换和构造,以提取更有价值的特征信息,为后续的建模和分析提供支持。
5. 数据建模:根据实验目的,选择适当的算法和模型对数据进行建模,训练模型并评估模型的性能和预测能力。
6. 结果分析:对模型建设和预测结果进行分析和解释,总结实验的结论和发现。
四、实验结果与讨论在实验过程中,对提供的数据集进行了全面的分析和建模,得到了有意义的结果和发现。
通过数据的探索和分析,可以得出某些特征与目标变量之间存在明显的相关性,为进一步的决策和应用提供了参考。
五、实验总结本实验通过数据分析的方法,对提供的数据集进行了全面的分析和建模。
实验结果显示,在数据探索和分析的过程中,可以发现数据的规律和潜在的模式。
这些发现对决策和应用有重要的指导意义。
同时,也指出了实验中存在的不足之处,提出了改进和进一步研究的建议。
六、参考文献[1] McKinney, W. (2010). Data structures for statistical computing in Python. In Proceedings of the 9th Python in Science Conference (pp. 51-56).[2] VanderPlas, J. (2016). Python data science handbook: Essential tools for working with data. O'Reilly Media.[3] Wes McKinney. Python for Data Analysis. O'Reilly Media, Inc. 2017.七、附录本实验的代码和数据集可以在附件中找到,并按照相关的实验步骤进行使用和调试。
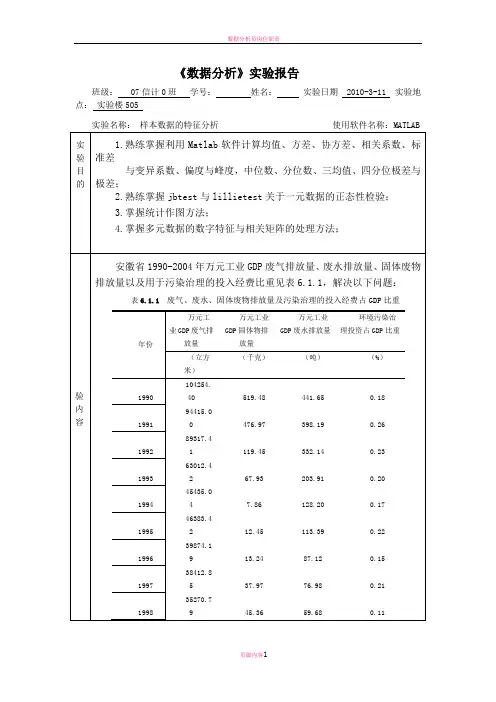
《数据分析》实验报告册20 15 - 20 16 学年第一学期班级:学号:姓名:授课教师:实验教师:目录实验一网上书店的数据库创建及其查询实验1-1 “响当当”网上书店的数据库创建实验1-2 “响当当”网上书店库存、图书和会员信息查询实验1-3 “响当当”网上书店会员分布和图书销售查询实验二企业销售数据的分类汇总分析实验2-1 Northwind公司客户特征分析实验2-2 “北风”贸易公司销售业绩观测板实验三餐饮公司经营数据时间序列预测实验3-1 “美食佳”公司半成品年销售量预测实验3-2 “美食佳”公司月管理费预测实验3-3 “美食佳”华东分公司销售额趋势预测实验3-4 “美食佳”公司会员卡发行量趋势预测实验3-5 “美食佳”火锅连锁店原料年度采购成本预测实验四住房建筑许可证数量的回归分析实验4-1 “家家有房”公司建筑许可证一元线性回归分析实验4-2 “家家有房”公司建筑许可证一元非线性回归分析实验4-3 “家家有房”公司建筑许可证多元线性回归分析实验4-4 “家家有房”公司建筑许可证多元非线性回归分析实验五手机用户消费习惯聚类分析实验六新产品价格敏感度测试模型分析实验一网上书店的数据库创建及其查询实验1-1 “响当当”网上书店的数据库创建实验类型:验证性实验学时:2实验目的:•理解数据库的概念;•理解关系(二维表)的概念以及关系数据库中数据的组织方式;•了解数据库创建方法。
实验步骤:这个实验我们没有直接做,只是了解了一下数据库的概念。
实验1-2 “响当当”网上书店库存、图书和会员信息查询实验目的•理解odbc的概念;•掌握利用microsoft query进行数据查询的方法。
实验步骤:1..建立odbc数据源:启动microsoft office query应用程序,在microsoft office query应用程序窗口中,执行“文件/新建”命令,出现“选择数据源”对话框,单击“确定”按钮,出现“创建新数据源”对话框,按照要求做相应的操作。
选择数据源对话框创建新数据源窗口做图上所示的选择odbc microsoft access安装对话框选择数据库对话框选择数据源对话框2.查询设计1—低库存量图书信息查询:选择“bookstore”数据源,点击“确定”,进入“添加表”窗口,添加书表后,在“查询设计”窗口的“表”窗格中,分别双击“书”表中需要查询的“书名”、“isbn”、“库存量”等字段,执行“视图/条件”命令,在“条件”窗格的“条件字段”行的第一列中选择“库存量”,并在下一行中输入“<10”后回车,即可在“查询结果”窗格中显示响当当网上书店中库存量小于10的图书信息。
选择bookstore数据源选择好表后点击“添加”查询设计窗口-查询的相关数据查询设计窗口-输入条件3.查询设计2—低库存量图书信息以及出版社信息查询:分别添加“书”和“出版社”表,双击“书”表的“书名”和“isbn”字段以及“出版社”表的“出版社名称”、“电话”和“地址”字段,再输入相应的条件即可进行查询。
添加了表后的查询设计窗口实验小结:因为我们没有尝试建立数据库,直接开始数据查询,所以实验时遇到了很多问题。
比如我们在选择数据源时就遇到了麻烦,弄了半天才开始查询设计,而且不是很熟练,一直做了四五个查询设计才慢慢熟练起来。
实验思考:1、在数据查询过程中,如果所选的某个表与其他表之间没有联系的话,会产生什么问题?答:所选的查询数据将会全部显示在查询窗口,与其它表的数据没有直接联系。
这样就不能表现出表与表数据之间的关联性,数据也就失去赋予的意义。
2、若“响当当个”网上书店的某个会员了解自己最近2年的图书订购情况,请为他设计一个查询。
答:分别添加“书”、“会员”、“订单明细”和“订单”表,双击“书”表的“书名”、“会员”表的“姓名”和“订单明细”表的“订购数量”以及“订单”表的“订购日期”字段,在向查询条件窗口中输入某一会员姓名以及相应的订购日期.实验1-3 “响当当”网上书店会员分布和图书销售查询实验目的•掌握复杂的数据查询方法:多表查询、计算字段和汇总查询实验步骤:1.查询设计1—会员分布信息查询:添加“会员”表到查询设计窗口,在“查询设计”窗口的“表”窗格中,双击“会员”表的“城市”和“会员号”字段。
然后双击“会员号”字段的列标,在“编辑列”对话框中输入列标“会员人数”,并选择汇总方式:“计数”,单击“确定”按钮后即可看到查询结果,其中显示了各城市的会员人数,再设置相应的条件,进行相应的查询。
选择汇总方式查询结果2.查询设计2—图书总订购量和总销售金额查询:添加“订单”、“订单明细”和“书”表。
在“查询设计”窗口的“表”窗格中,双击“订单”表的“订购日期”、“订单明细”表的“订购数量”字段。
另外还要构造一个计算字段“销售金额”,方法是直接在某空白列的列标中输入公式;在上面的字段中,“订购数量”和“销售金额”是汇总字段,分类字段是“订购年份”,双击“订购日期”列的列标,在编辑列对话框的字段项中输入公式“year(订购日期)”,在其中的列标项中输入“订购年份”然后分别双击“订购数量”和“订购数量*单价”字段的列标,在编辑列对话框的列标项中分别输入“总订购数量”和“总销售金额”字样,并在总计项中选择“求和”。
在“条件”窗格的“条件字段”行的第一列中选择“订购日期”,并在下一行中输入“>=2005-7-1 and <=2006-6-30”后回车,即可在“查询结果”窗格中显示2005上半年和2006下半年的图书总订购量和总销售金额。
此时,若想了解各月份的图书总订购量和总销售金额,只要再查询设计窗口中增加一个“订购月份”分类字段即可增加了订购月份后的查询结果排序对话框3.查询设计3—会员订购图书详细信息查询:添加“会员”、“订单”、“订单明细”和“书”表,在表之间建立合适的联系。
在“查询设计”窗口的“表”窗格中,双击“会员”表的“城市”、“会员号”、“姓名”字段,“订单”表的“订单号”字段、“书”表的“书名”字段和“订单明细”表的“订购数量”字段。
选择“记录”菜单的“排序”命令,在随后出现的“排序”对话框中设置排序方式查询结果共84条记录4.查询设计4—各城市会员图书订购数量和销售金额统计:添加“会员”、“订单”、“订单明细”和“书”表,在表之间建立合适的联系。
在“查询设计”窗口的“表”窗格中,双击“会员”表的“城市”、“订单明细”表的“订购数量”字段。
分别双击“订购数量”和“订购数量*单价”字段的列标,在编辑列对话框的列标项中分别输入“总订购数量”和“总销售金额”字样,并在总计项中选择“求和”。
按“确定”按钮后即可查看结果。
5.查询设计5—被订购图书的作者和出版社信息查询:添加“会员”、“订单”、“订单明细”、“书”、“作者”和“出版社”表。
在表之间建立合适的联系。
在“查询设计”窗口的“表”窗格中,双击“书”表的“书名”、“作者”表的“姓名”和“出版社”表的“出版社名称”字段。
在条件窗格中添加关于订购日期和会员姓名的条件。
可以查看到结果为会员“刘丹”在2007年共订购了7本图书。
实验小结:实验1-3的实验比较难,但是经过前面的练习还是比之前快一点,不过还是遇到一些困难,比如查看到结果为会员“刘丹”在2007年共订购了几本书的查询设计就在输入指令时卡住了,经过几个同学讨论还是做出来了。
一直到晚上天黑了才把一共十个实验做完。
实验思考:1、在进行汇总查询的过程中,如果被选择的字段除了分类字段以外还包含了其他字段。
查询结果是否正确?为什么?请举例说明。
答:不正确,如果被选择的字段除了分类字段以外还包含了其他字段,那么query将把多余的字段自动作为分类字段。
2、“响当当”网上书店的管理人员想了解最近2年中那位作者的书是最畅销,请你设计一个查询找到相关作者。
答:查询近两年的总订购量。
实验二企业销售数据的分类汇总分析实验2-1 North wind公司客户特征分析实验类型:验证性实验学时:2实验目的:• 理解数据分类汇总在企业中的作用与意义;• 掌握数据透视表工具的基本分类汇总功能;• 掌握建立分类汇总数据排行榜、生成时间序列、绘制praetor曲线图、计算各地区客户分布、统计各地区客户的平均销售额和大宗销售时间序列的方法和步骤。
实验步骤:一、汇总客户销售额排行榜为了汇总客户销售额的排行榜,首先要获得客户每笔销售的销售额、所购买产品的类别以及销售发生的时间,然后再利用数据透视表工具将销售额按照客户名称、产品类别和销售时间加以汇总。
步骤1:获取各客户每笔销售的销售额、销售产品的类别和时间。
在一张空白的工作表中,选择菜单“数据”→“数据透视表和数据透视图” →“外部数据源”,单击“获取数据按钮”,随后启动了Microsoft Query,选择所建立的连接到Northwind.mdb数据库的ODBC数据源——“NW”,并选择“确定”,选择“客户”表中的的“公司名称”、“订单”表中的“订购日期”、以及“类别”表中“类别名称”,随后Query弹出窗口“‘查询向导’无法继续,因为该表格无法链接到您的查询中。
您必须在Microsoft Query 中的表格之间拖动字段,人工链接。
”这是因为类别表无法同订单表建立联系。
单击“确定”。
要查询销售额,需要在Query中首先增加“订单明细”表,利用其中的“单价”、“数量”与“折扣”字段中的数据,才能计算销售额。
在数据窗格中,在一个空白字段的名称处输入公式:“订单明细.单价*数量*(1-折扣)”。
键入回车后就可以计算出销售额。
见图2-7。
随后,将“产品”表也添加到查询中,虽然查询结果中并不包括任何“产品”表中的字段,但是该表的能够建立“类别”表与“订单明细”表之间的联系(“订单明细”表指明所订购产品的ID,“产品”表指明该产品属于哪一个类别)。
此时,查询中的表都建立了正确的联系,并在查询结果中包括了汇总所需要的数据。
如图2-7。
图2-7 查询各客户每笔销售的销售额、销售产品的类别和时间将计算销售额的字段的列标命名为“销售额”。
选择Query菜单中的“文件”→“将数据返回Microsoft Office Excel” ,此时Query已经关闭,我们的操作对象回到了Excel,单击“下一步”,指定位置在“现有工作表”,单元格A3,单击完成。
步骤2:汇总客户销售额排行榜,并排序。
此时,在工作表的区域A1:G16的位置,出现了数据透视表的框架,数据透视表的浮动工具栏和数据透视表的字段列表。
为了能对销售的时间——“订购日期”进行组合以获得各年的销售额,首先将“订购日期”拖至行域,将“销售额”拖至数据域,“类别名称”拖至列域,得到如图2- 8所示的数据透视表。