单因素完全随机区组设计
- 格式:ppt
- 大小:2.56 MB
- 文档页数:24


单因素实验设计单因素实验设计是指在实验中只有一个研究因素,即研究者只分析一个因素对效应指标的作用,但单因素实验设计并不是意味着该实验中只有一个因素与效应指标有关联。
单因素实验设计的主要目标之一就是如何控制混杂因素对研究结果的影响。
常用的控制混杂因素的方法有完全随机设计、随机区组设计和拉丁方设计等。
一、完全随机设计1.概念与特点又称单因素设计或成组设计,是医学科研中最常用的一种研究设计方法,它是将同质的受试对象随机地分配到各处理组进行实验观察,或从不同总体中随机抽样进行对比研究。
该设计适用面广,不受组数的限制,且各组的样本含量可以相等,也可以不相等,但在总体样本量不变的情况下,各组样本量相同时的设计效率最高。
例如:为了研究煤矿粉尘作业环境对尘肺的影响,将18只大鼠随机分到甲、乙、丙3组,每组6只,分别在地面办公楼、煤炭仓库和矿井下染尘,12周后测量大鼠全肺湿重(g),通过评价不同环境下大鼠全肺平均湿重推断煤矿粉尘对作用尘肺的影响,具体的随机分组可以如下实施:第一步:将18只大鼠编号:1,2,3, (18)第二步:可任意设置种子数,但应作为实验档案记录保存(本例设置spss11.0软件的种子数为200);第三步:用计算机软件一次产生18个随机数,每个随意数对应一只老鼠(本例用spss11.0软件采用均匀分布最大值为18时产成的18个随机数);第四步:最小的6个随机数对应编号的大鼠为甲组,排序后的第7个至第12个随机数随因编号为乙组,最大的6个随机数对应编号的大鼠为丙组(结果见表1)。
表1 分配结果编号 1 2 3 4 5 6 7 8 93.75 8.75 16.29 11.12 5.49 3.98 13.64 16.71 1.69随机数组别甲乙丙乙乙甲丙丙甲编号10 11 12 13 14 15 16 17 1813.62 16.36 2.12 4.74 11.54 3.98 0.13 17.35 16.38 随机数组别丙丙甲乙乙甲甲丙丙2.随机数的产生方法(1)随机数字表:如附表13(马斌荣,医学统计学,第4版),这是一个由0~9十个数字组成60行25列的数字表。



心理学与教育研究中的多因素实验设计——————舒华第二章 几种基本的实验设计一、 基本特点适用于:研究中有一个自变量,自变量有两个或多于两个水平。
方法:把被试随机分配给自变量的各个水平,每个水平被试只接受一个水平的处理。
二、 计算与举例(一) 检验的问题与实验设计 (二) 实验数据及其计算()()()()()22i 22j T 2j ij j ss ss X X NX X ss n nNss ss n S X ss ss X X ss X =+=-=-=∙-=-=∙=-∑∑∑∑∑∑∑∑∑∑∑∑总变异组间组内总变异组间组内总变异组间一、 基本特点适用于:研究中有一个变量,自变量有两个或多个水平(P ≥2),研究中还有一个无关变量,也有两个或多个水平(n ≥2);并且自变量的水平与无关变量的水平之间没有交互作用。
适合检验的假说:(1)处理水平的总体平均数相等或处理效应为零;(2)区组的总体平均数相等或区组效应为零。
二、计算ss ss ss (ss SS ss =+=++总变异组间组内组间区组残差)三、优点:从实验中分离出了一个无关变量的效应,从而减少了实验误差。
一、 基本特点定义:是一个含P 行、P 列、把P 个字母分配给方格的管理方案,其中每个字母在每行中只出现一次。
适用于:(1)研究中自变量与无关变量的水平平均≥2,一个无关变量的水平被分配给P行,另一个则给P列;(2)假定处理水平与无关变量水平之间没有交互作用, (3)随即分配处理水平给2P 个方格单元,每个处理水平仅在每行,每列中出现一次。
1c 2c 3c 4c无关变量C的四个水平 无关变量B的四个水平 1b 自变量A的四个水平 2b3b4bA B C SS SS SS SS SS SS SS SS =+=++++处理间总变异处理内残差单元内()一、 基本特点:(也叫被试内设计) 基本方法:实验中每个被试接受所有的处理水平目 的:利用被试自己做控制,使被试的各方面特点在所有的处理中保持恒定,以最大限度地控制由被试的个体差异带来的变异。
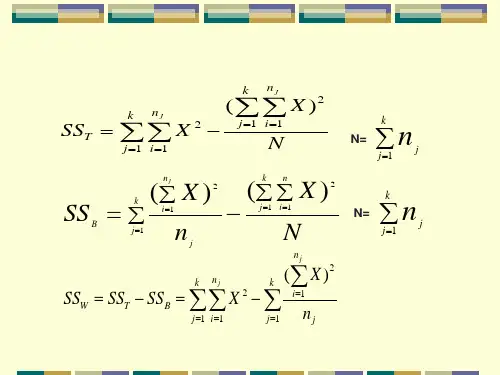

单因素实验设计单因素实验设计是指在实验中只有一个研究因素,即研究者只分析一个因素对效应指标的作用,但单因素实验设计并不是意味着该实验中只有一个因素与效应指标有关联。
单因素实验设计的主要目标之一就是如何控制混杂因素对研究结果的影响。
常用的控制混杂因素的方法有完全随机设计、随机区组设计和拉丁方设计等。
一、完全随机设计1.概念与特点又称单因素设计或成组设计,是医学科研中最常用的一种研究设计方法,它是将同质的受试对象随机地分配到各处理组进行实验观察,或从不同总体中随机抽样进行对比研究。
该设计适用面广,不受组数的限制,且各组的样本含量可以相等,也可以不相等,但在总体样本量不变的情况下,各组样本量相同时的设计效率最高。
例如:为了研究煤矿粉尘作业环境对尘肺的影响,将18只大鼠随机分到甲、乙、丙3组,每组6只,分别在地面办公楼、煤炭仓库和矿井下染尘,12周后测量大鼠全肺湿重(g),通过评价不同环境下大鼠全肺平均湿重推断煤矿粉尘对作用尘肺的影响,具体的随机分组可以如下实施:第一步:将18只大鼠编号:1,2,3, (18)第二步:可任意设置种子数,但应作为实验档案记录保存(本例设置spss11.0软件的种子数为200);第三步:用计算机软件一次产生18个随机数,每个随意数对应一只老鼠(本例用spss11.0软件采用均匀分布最大值为18时产成的18个随机数);第四步:最小的6个随机数对应编号的大鼠为甲组,排序后的第7个至第12个随机数随因编号为乙组,最大的6个随机数对应编号的大鼠为丙组(结果见表1)。
表1 分配结果编号 1 2 3 4 5 6 7 8 93.75 8.75 16.29 11.12 5.49 3.98 13.64 16.71 1.69随机数组别甲乙丙乙乙甲丙丙甲编号10 11 12 13 14 15 16 17 1813.62 16.36 2.12 4.74 11.54 3.98 0.13 17.35 16.38 随机数组别丙丙甲乙乙甲甲丙丙2.随机数的产生方法(1)随机数字表:如附表13(马斌荣,医学统计学,第4版),这是一个由0~9十个数字组成60行25列的数字表。


单因素随机区组实验设计一、单因素随机区组实验设计的基本特点心理和教育科学研究中,被试的个体差异是误差变异的重要来源。
它常常会混淆实验处理的效应,因此是无关变异。
随机区组设计使用区组方法减小误差变异,即用区组方法分离出由无关变量引起的变异,使它不出现在处理效应和误差变异中。
单因素随机区组设计适用于这样的情境:研究中有一个自变量,自变量有两个或多个水平(P ≥2),研究中还有一个无关变量,也有两个或多个水平(n ≥2),并且自变量的水平与无关变量的水平之间没有交互作用。
当无关变量是被试变量时,一般首先将被试在这个无关变量上进行匹配,然后将他们随机分配给不同的实验处理。
这样,区组内的被试在此无关变量上更加同质,他们接受不同的处理水平时,可看作不受无关变量的影响,主要受处理的影响而区组之间的变异反映了无关变量的影响,我们可以利用方差分析技术区分出这一部分变异,以减少误差变异,获得对处理效应的更精确的估价。
另外,环境因素也是潜在可考虑的区组变量,例如,每天的时间、每年的季节、地点、仪器等方面的因素也可以进行区组,以减少误差变异,时间是一个特别有效的区组变量,因为它常常还会带来一些附加的变量,如身体的生理周期、疲劳等等。
单因素随机区组实验设计适合检验的假说有两个: (1)处理水平的总体平均数相等,即:0.1.2.:P H μμμ==⋅⋅⋅⋅⋅⋅⋅=或处理效应等于0,即:0:0j H a =(2)区组的总体平均数相等,即:0.1.2.:n H μμμ==⋅⋅⋅⋅⋅⋅⋅=或区组效应等于0,即:20:0i H π=图中可以看出实验中有一个自变量,自变量有4个水平。
实验中还有一个无关变量,将16个被试在无关变量上进行匹配,分为4个区组,每个区组内4个同质被试,随机分配每个被试接受一个处理水平。
二、单因素随机区组实验设计与计算举例(一)研究的问题与实验设计我们仍然利用第一节中文章的生字密度对阅读理解影响的研究做例子。


常用实验设计方法(一)一、完全随机设计(c o m p l e t e l y r a n d o m d e s i g n)属于单因素实验设计,可为两或多个水平。
将受试对象按随机化方法分配到各处理组,各处理组例数可以相等或不等。
优点:简单易行缺点:①只能分析一个因素的效应;②需要足够的样本含量,使各组基线(混杂)均衡可比。
设计要点◆完全随机设计的两组比较◆完全随机设计的多组比较1.两组比较为实验“736”对肉瘤的抑制作用,将16只长出肉瘤的小鼠随机分为两组,实验组注射“736”,对照组注射同量的生理盐水,10天后解剖称瘤重,试问:①该实验为何种设计类型?②请写出相应的设计方案?③对资料进行统计分析?组别瘤重(克)给药组1.62.22.02.02.51.03.71.5对照组2.14.92.74.32.51.74.53.4随机分配方案:①动物编号1-16②分配随机数:随机排列表第6行取0-15,弃去16-19。
③规定:随机数奇数分配至“736”组,偶数为对照组1表示给药组“736”,0表示对照组(生理盐水)备注:常用的随机分配方案:①按随机数的奇偶分配至两组;②按随机数的余数分配至各组;③将随机数排序,等分成各区段,对应将研究对象分配至各组。
统计分析①数据录入(d a t a1.x l s/s h e e t1)g r o u p瘤重11.612.2121212.51113.711.502.104.902.704.302.501.704.503.4②统计分析结果解释:两组瘤重平均水平差异有统计学意义,给药组的瘤重低于对照组。
2.完全随机设计多组比较研究某药在机体内的杀虫效果,选取20只小鼠,用幼虫感染,8d后随机取15只分为三组分别给予该药的不同药量以杀灭蠕虫,另5只为对照,用药2d后,将所有的小鼠杀死计数体内成虫数。
获得资料如下:对照低剂量中剂量高剂量381279378172346338275235340334412230470198265282318303286250试问:①该实验为何种设计类型?②请写出相应的设计方案?③对资料进行统计分析?随机分配方案:①动物编号1-20②分配随机数:随机排列表第10行。
②随机区组设计。
又称被试内设计。
它先把被试按某些特质分到不同区组,使各区组内的被试更接近同质,而区组间的被试更加不同。
然后将各区组内的被试随机分派接受不同的处理,或按不同顺序接受所有的处理。
这样,对于一个区组来说是接受所有处理的。
这一点与完全随机化设计不同。
完全随机化设计中各组只分别接受各自所应该接受的处理。
Ⅴ是随机区组设计的基本模式。
它与完全随机化设计的不同还表现在把"区组'这一变量也纳入了实验设计。
这样,总变异就可以分成"处理间'、"区组间'及"误差'。
与完全随机化设计相比,它能把由个别差异造成的变异估计出来。
划分区组的依据与要考察的反应变量密切相关,即当同一区组的被试在第1个实验处理中得分高于其他区组时,在第2个处理中的得分也同样高。
因此,随机区组设计的统计方法一般用相关样本的t检验或方差分析。
另外,如果随机区组设计中的每一区组都进行所有的处理,便称为完全区组设计;如果每区组所进行的处理数小于总的处理数,则称为不完全区组设计。
后者虽然每一区组不进行所有的处理,但每一处理所在的区组数须相同。
大部分心理学家在实验中的处理数都不太多,基本上是用完全区组设计。
若处理数很多(农业实验中常遇到这种情况),由于实验的总实施次数很大,限于人力、财力及时间,则须采用不完全区组设计。
单因素设计与多因素设计这两种设计是根据实验中自变量的多少来划分的。
①单因素设计。
它的自变量只有一个,其他能影响结果的因素均作为无关变量而加以控制。
这种设计简明易行,但由于在实际生活中影响心理活动的因素常不止一个,所以当情况比较复杂时,最好使用多因素实验设计。
②多因素设计。
自变量为两个或两个以上的实验设计。
常用的多因素设计有完全随机化、随机区组和拉丁方等。
完全随机化多因素设计根据自变量及每个自变量的变化水平(处理)的多少进行随机分组。
在22因素设计中,有两个自变量因素A、B,每个因素又有两种水平,共有 4种可能的处理,即A1B1、A1B2、A2B1、A2B2。
方差分析(ANOVA)方差分析的应用范围单因素完全随机设计, 随机化区组设计,拉丁方设计多因素析因设计,裂区设计,交叉设计,正交设计多变量多元方差分析回归方程的假设检验第一节完全随机设计与资料分析方差分析目的:根据多个组间样本均数的差别推断总体均数是否存在差别。
一、方差分析的基本思想:表12.2 红细胞沉降率(mm/h)抗凝剂红细胞沉降率niX S2Σx Σx2甲17, 16, 16, 15 4 16.0 0.67 64 1026 乙10, 11, 12, 12 4 11.3 0.92 45 509 丙11, 9, 8, 9 4 9.3 1.58 37 347 合计12 12.2 3.17 146 1882观察值之间有变异,这变异可以用离均差平方和表示。
67.105)(112..=-=∑∑==GinjijTixxSS进一步分析,总变异中有两类变异:1. 组内变异,指各组内观察值的差异50.9)1()(12112.=-=-=∑∑∑===GiiiGinjiijWsnxxSS i2. 组间变异,指各组间样本均数与总均数的差异17.96)(12...=-=∑=GiiiBxxnSS由于组内变异完全是个体间的差异,因此可以认为是随机误差。
而组间变异反映组间均数的差异,其可能仅仅包含随机误差,这时零假设成立。
也可能除随机误差外,还包含处理的效应,这时则备择假设成立。
组间变异和组内变异的自由度不同,无可比性。
计算均方,再进行比较:37.4506.109.489/50.92/17.96)/()1/(====--=WBWBMSMSGnSSGSSF二、方差分析的基本步骤1. 方差分析的基本条件a. 各组观察值分别服从总体均数为μi的正态分布。
b. 各组观察值总体方差相等。
多组间的方差齐性检验检验假设:H0:σ21=σ22=…=σ2G,H1:σ2i不全相等,α=0.150.0])(111[)1(311)ln()1()/ln()(12122=----+---=∑∑==Gi iiGiicGnnGSnGSGnχ查表得p>0.75,差异无统计学意义,故认为各组间方差不齐。